 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel Stochastic Gradient Descent Algorithm for Learning Principal Subspaces
Dec 08, 2022
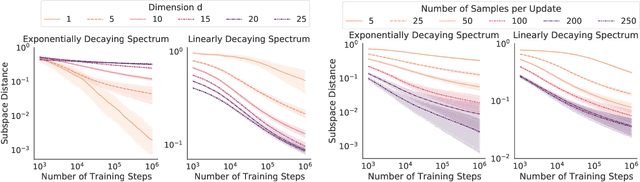
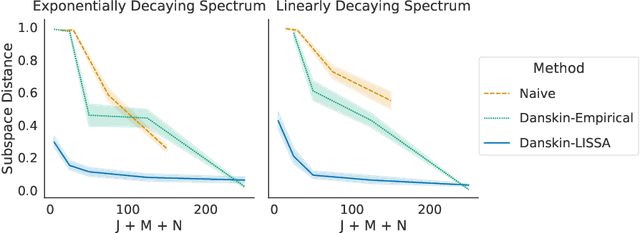

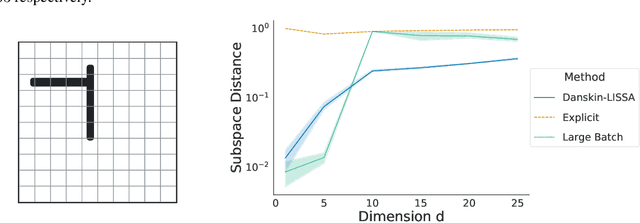
Many machine learning problems encode their data as a matrix with a possibly very large number of rows and columns. In several applications like neuroscience, image compression or deep reinforcement learning, the principal subspace of such a matrix provides a useful, low-dimensional representation of individual data. Here, we are interested in determining the $d$-dimensional principal subspace of a given matrix from sample entries, i.e. from small random submatrices. Although a number of sample-based methods exist for this problem (e.g. Oja's rule \citep{oja1982simplified}), these assume access to full columns of the matrix or particular matrix structure such as symmetry and cannot be combined as-is with neural networks \citep{baldi1989neural}. In this paper, we derive an algorithm that learns a principal subspace from sample entries, can be applied when the approximate subspace is represented by a neural network, and hence can be scaled to datasets with an effectively infinite number of rows and columns. Our method consists in defining a loss function whose minimizer is the desired principal subspace, and constructing a gradient estimate of this loss whose bias can be controlled. We complement our theoretical analysis with a series of experiments on synthetic matrices, the MNIST dataset \citep{lecun2010mnist} and the reinforcement learning domain PuddleWorld \citep{sutton1995generalization} demonstrating the usefulness of our approach.
OFASys: A Multi-Modal Multi-Task Learning System for Building Generalist Models
Dec 08, 2022
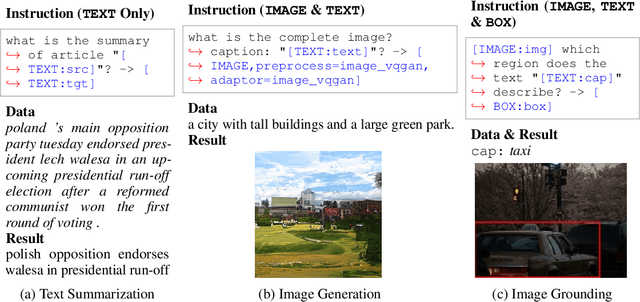
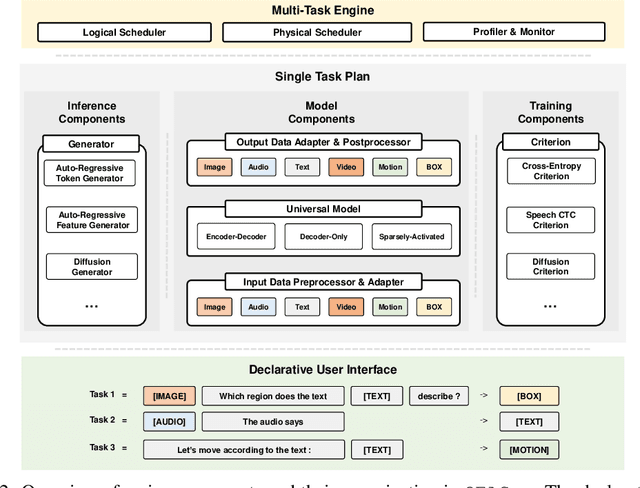

Generalist models, which are capable of performing diverse multi-modal tasks in a task-agnostic way within a single model, have been explored recently. Being, hopefully, an alternative to approaching general-purpose AI, existing generalist models are still at an early stage, where modality and task coverage is limited. To empower multi-modal task-scaling and speed up this line of research, we release a generalist model learning system, OFASys, built on top of a declarative task interface named multi-modal instruction. At the core of OFASys is the idea of decoupling multi-modal task representations from the underlying model implementations. In OFASys, a task involving multiple modalities can be defined declaratively even with just a single line of code. The system automatically generates task plans from such instructions for training and inference. It also facilitates multi-task training for diverse multi-modal workloads. As a starting point, we provide presets of 7 different modalities and 23 highly-diverse example tasks in OFASys, with which we also develop a first-in-kind, single model, OFA+, that can handle text, image, speech, video, and motion data. The single OFA+ model achieves 95% performance in average with only 16% parameters of 15 task-finetuned models, showcasing the performance reliability of multi-modal task-scaling provided by OFASys. Available at https://github.com/OFA-Sys/OFASys
Pose Estimation for Human Wearing Loose-Fitting Clothes: Obtaining Ground Truth Posture Using HFR Camera and Blinking LEDs
Dec 08, 2022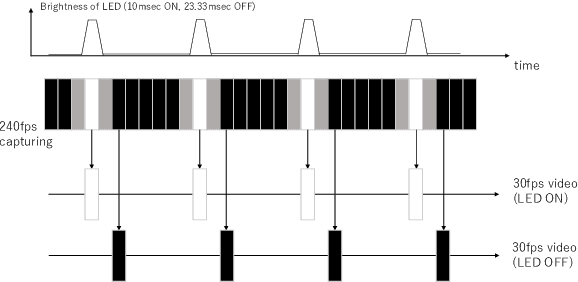

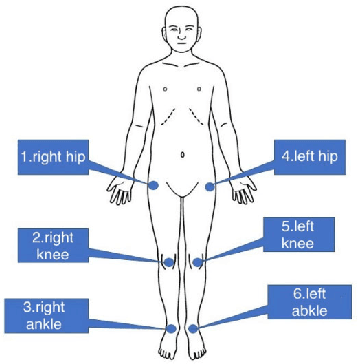

Human pose estimation, particularly in athletes, can help improve their performance. However, this estimation is difficult using existing methods, such as human annotation, if the subjects wear loose-fitting clothes such as ski/snowboard wears. This study developed a method for obtaining the ground truth data on two-dimensional (2D) poses of a human wearing loose-fitting clothes. This method uses fast-flushing light-emitting diodes (LEDs). The subjects were required to wear loose-fitting clothes and place the LED on the target joints. The LEDs were observed directly using a camera by selecting thin filmy loose-fitting clothes. The proposed method captures the scene at 240 fps by using a high-frame-rate camera and renders two 30 fps image sequences by extracting LED-on and -off frames. The temporal differences between the two video sequences can be ignored, considering the speed of human motion. The LED-on video was used to manually annotate the joints and thus obtain the ground truth data. Additionally, the LED-off video, equivalent to a standard video at 30 fps, confirmed the accuracy of existing machine learning-based methods and manual annotations. Experiments demonstrated that the proposed method can obtain ground truth data for standard RGB videos. Further, it was revealed that neither manual annotation nor the state-of-the-art pose estimator obtains the correct position of target joints.
CRAFT: Concept Recursive Activation FacTorization for Explainability
Nov 17, 2022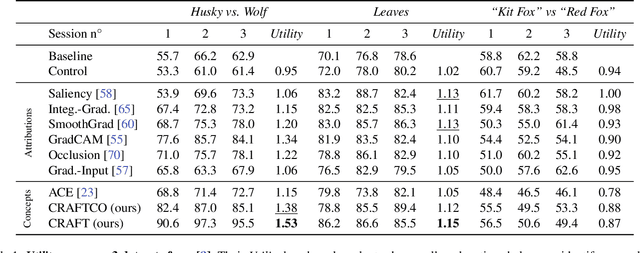

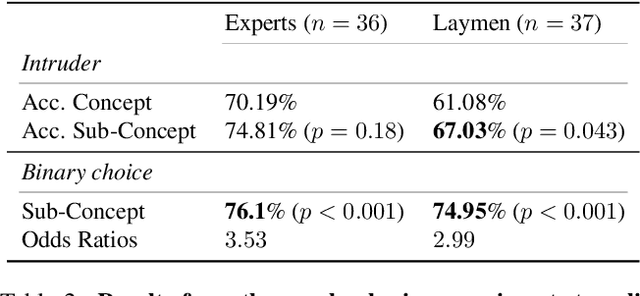
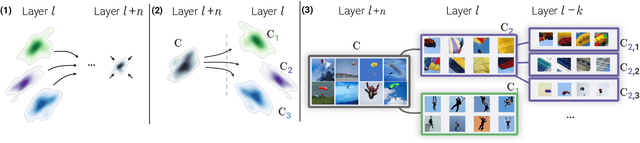
Attribution methods are a popular class of explainability methods that use heatmaps to depict the most important areas of an image that drive a model decision. Nevertheless, recent work has shown that these methods have limited utility in practice, presumably because they only highlight the most salient parts of an image (i.e., 'where' the model looked) and do not communicate any information about 'what' the model saw at those locations. In this work, we try to fill in this gap with CRAFT -- a novel approach to identify both 'what' and 'where' by generating concept-based explanations. We introduce 3 new ingredients to the automatic concept extraction literature: (i) a recursive strategy to detect and decompose concepts across layers, (ii) a novel method for a more faithful estimation of concept importance using Sobol indices, and (iii) the use of implicit differentiation to unlock Concept Attribution Maps. We conduct both human and computer vision experiments to demonstrate the benefits of the proposed approach. We show that our recursive decomposition generates meaningful and accurate concepts and that the proposed concept importance estimation technique is more faithful to the model than previous methods. When evaluating the usefulness of the method for human experimenters on a human-defined utility benchmark, we find that our approach significantly improves on two of the three test scenarios (while none of the current methods including ours help on the third). Overall, our study suggests that, while much work remains toward the development of general explainability methods that are useful in practical scenarios, the identification of meaningful concepts at the proper level of granularity yields useful and complementary information beyond that afforded by attribution methods.
Acquiring a Dynamic Light Field through a Single-Shot Coded Image
Apr 26, 2022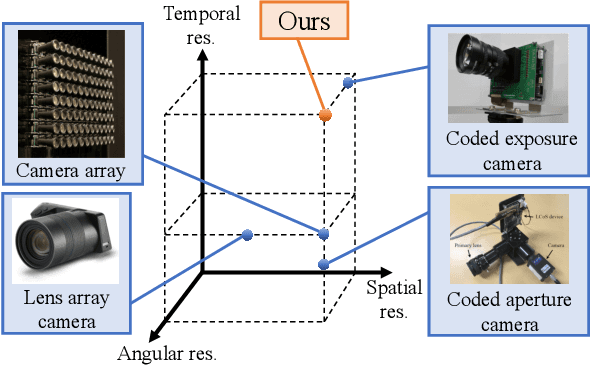
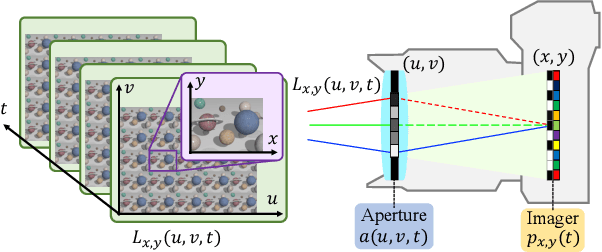
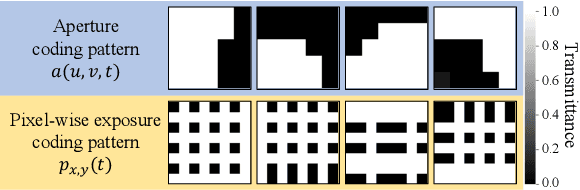

We propose a method for compressively acquiring a dynamic light field (a 5-D volume) through a single-shot coded image (a 2-D measurement). We designed an imaging model that synchronously applies aperture coding and pixel-wise exposure coding within a single exposure time. This coding scheme enables us to effectively embed the original information into a single observed image. The observed image is then fed to a convolutional neural network (CNN) for light-field reconstruction, which is jointly trained with the camera-side coding patterns. We also developed a hardware prototype to capture a real 3-D scene moving over time. We succeeded in acquiring a dynamic light field with 5x5 viewpoints over 4 temporal sub-frames (100 views in total) from a single observed image. Repeating capture and reconstruction processes over time, we can acquire a dynamic light field at 4x the frame rate of the camera. To our knowledge, our method is the first to achieve a finer temporal resolution than the camera itself in compressive light-field acquisition. Our software is available from our project webpage
HeartSpot: Privatized and Explainable Data Compression for Cardiomegaly Detection
Oct 05, 2022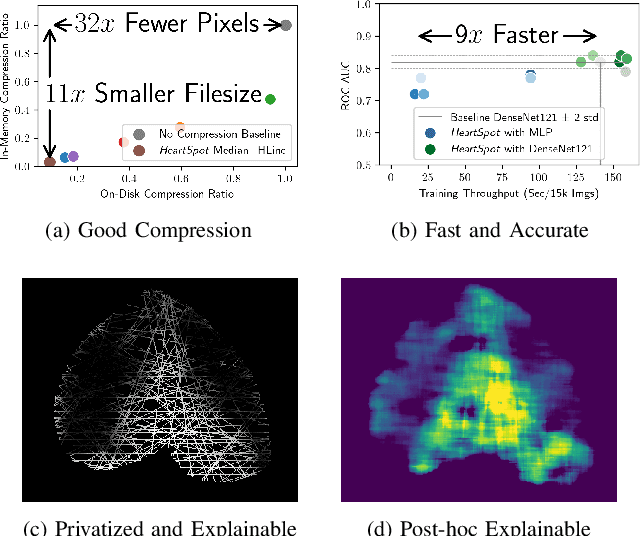

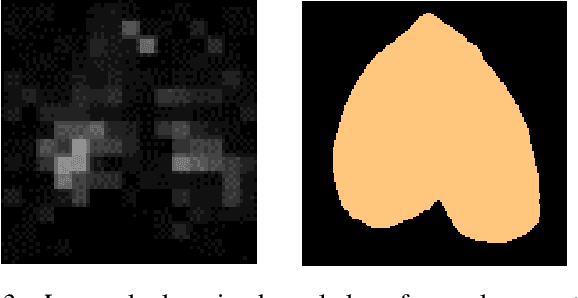
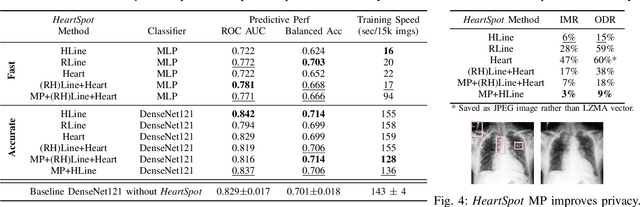
Advances in data-driven deep learning for chest X-ray image analysis underscore the need for explainability, privacy, large datasets and significant computational resources. We frame privacy and explainability as a lossy single-image compression problem to reduce both computational and data requirements without training. For Cardiomegaly detection in chest X-ray images, we propose HeartSpot and four spatial bias priors. HeartSpot priors define how to sample pixels based on domain knowledge from medical literature and from machines. HeartSpot privatizes chest X-ray images by discarding up to 97% of pixels, such as those that reveal the shape of the thoracic cage, bones, small lesions and other sensitive features. HeartSpot priors are ante-hoc explainable and give a human-interpretable image of the preserved spatial features that clearly outlines the heart. HeartSpot offers strong compression, with up to 32x fewer pixels and 11x smaller filesize. Cardiomegaly detectors using HeartSpot are up to 9x faster to train or at least as accurate (up to +.01 AUC ROC) when compared to a baseline DenseNet121. HeartSpot is post-hoc explainable by re-using existing attribution methods without requiring access to the original non-privatized image. In summary, HeartSpot improves speed and accuracy, reduces image size, improves privacy and ensures explainability. Source code: https://www.github.com/adgaudio/HeartSpot
A Particle-based Sparse Gaussian Process Optimizer
Nov 26, 2022
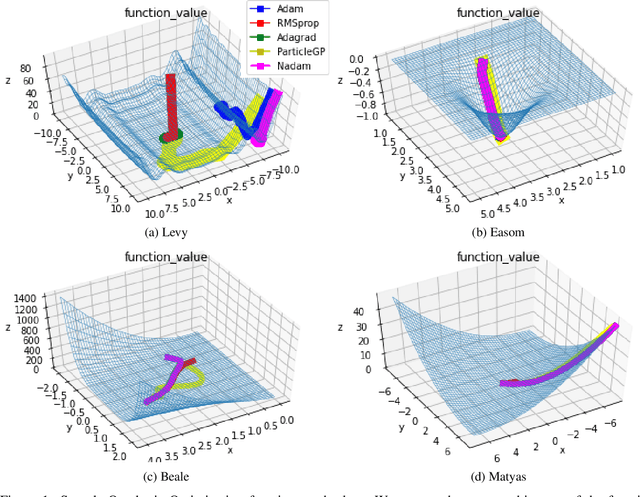

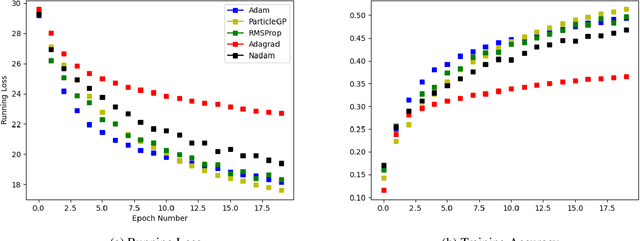
Task learning in neural networks typically requires finding a globally optimal minimizer to a loss function objective. Conventional designs of swarm based optimization methods apply a fixed update rule, with possibly an adaptive step-size for gradient descent based optimization. While these methods gain huge success in solving different optimization problems, there are some cases where these schemes are either inefficient or suffering from local-minimum. We present a new particle-swarm-based framework utilizing Gaussian Process Regression to learn the underlying dynamical process of descent. The biggest advantage of this approach is greater exploration around the current state before deciding a descent direction. Empirical results show our approach can escape from the local minima compare with the widely-used state-of-the-art optimizers when solving non-convex optimization problems. We also test our approach under high-dimensional parameter space case, namely, image classification task.
Predictive linguistic cues for fake news: a societal artificial intelligence problem
Nov 26, 2022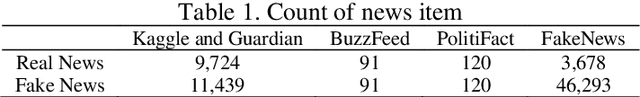

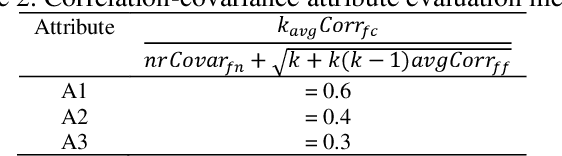

Media news are making a large part of public opinion and, therefore, must not be fake. News on web sites, blogs, and social media must be analyzed before being published. In this paper, we present linguistic characteristics of media news items to differentiate between fake news and real news using machine learning algorithms. Neural fake news generation, headlines created by machines, semantic incongruities in text and image captions generated by machine are other types of fake news problems. These problems use neural networks which mainly control distributional features rather than evidence. We propose applying correlation between features set and class, and correlation among the features to compute correlation attribute evaluation metric and covariance metric to compute variance of attributes over the news items. Features unique, negative, positive, and cardinal numbers with high values on the metrics are observed to provide a high area under the curve (AUC) and F1-score.
Palette: Image-to-Image Diffusion Models
Nov 10, 2021
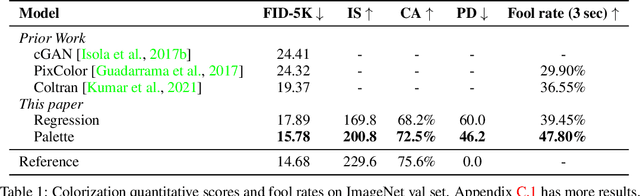

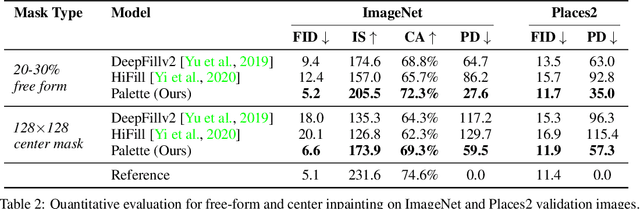
We introduce Palette, a simple and general framework for image-to-image translation using conditional diffusion models. On four challenging image-to-image translation tasks (colorization, inpainting, uncropping, and JPEG decompression), Palette outperforms strong GAN and regression baselines, and establishes a new state of the art. This is accomplished without task-specific hyper-parameter tuning, architecture customization, or any auxiliary loss, demonstrating a desirable degree of generality and flexibility. We uncover the impact of using $L_2$ vs. $L_1$ loss in the denoising diffusion objective on sample diversity, and demonstrate the importance of self-attention through empirical architecture studies. Importantly, we advocate a unified evaluation protocol based on ImageNet, and report several sample quality scores including FID, Inception Score, Classification Accuracy of a pre-trained ResNet-50, and Perceptual Distance against reference images for various baselines. We expect this standardized evaluation protocol to play a critical role in advancing image-to-image translation research. Finally, we show that a single generalist Palette model trained on 3 tasks (colorization, inpainting, JPEG decompression) performs as well or better than task-specific specialist counterparts.
Semantics-Guided Object Removal for Facial Images: with Broad Applicability and Robust Style Preservation
Sep 29, 2022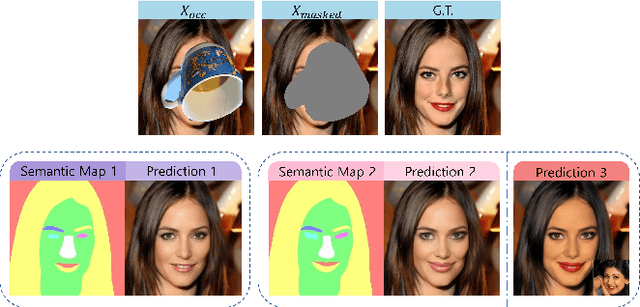

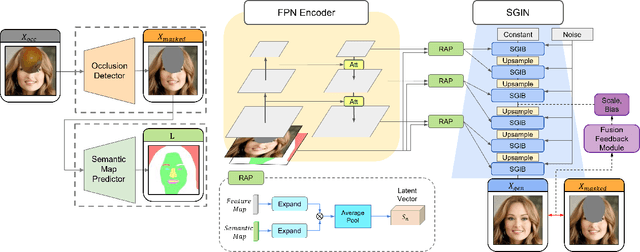
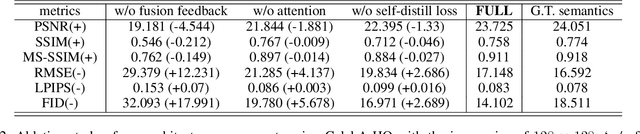
Object removal and image inpainting in facial images is a task in which objects that occlude a facial image are specifically targeted, removed, and replaced by a properly reconstructed facial image. Two different approaches utilizing U-net and modulated generator respectively have been widely endorsed for this task for their unique advantages but notwithstanding each method's innate disadvantages. U-net, a conventional approach for conditional GANs, retains fine details of unmasked regions but the style of the reconstructed image is inconsistent with the rest of the original image and only works robustly when the size of the occluding object is small enough. In contrast, the modulated generative approach can deal with a larger occluded area in an image and provides {a} more consistent style, yet it usually misses out on most of the detailed features. This trade-off between these two models necessitates an invention of a model that can be applied to any size of mask while maintaining a consistent style and preserving minute details of facial features. Here, we propose Semantics-Guided Inpainting Network (SGIN) which itself is a modification of the modulated generator, aiming to take advantage of its advanced generative capability and preserve the high-fidelity details of the original image. By using the guidance of a semantic map, our model is capable of manipulating facial features which grants direction to the one-to-many problem for further practicability.