 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SARS-CoV-2 Result Interpretation based on Image Analysis of Lateral Flow Devices
May 26, 2022
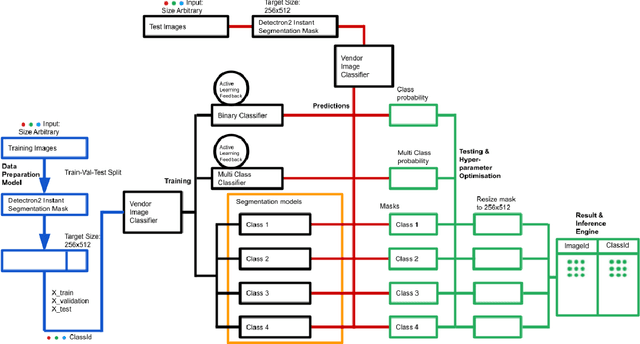


The widely used gene quantisation technique, Lateral Flow Device (LFD), is now commonly used to detect the presence of SARS-CoV-2. It is enabling the control and prevention of the spread of the virus. Depending on the viral load, LFD have different sensitivity and self-test for normal user present additional challenge to interpret the result. With the evolution of machine learning algorithms, image processing and analysis has seen unprecedented growth. In this interdisciplinary study, we employ novel image analysis methods of computer vision and machine learning field to study visual features of the control region of LFD. Here, we automatically derive results for any image containing LFD into positive, negative or inconclusive. This will reduce the burden of human involvement of health workers and perception bias.
Denoising-based image reconstruction from pixels located at non-integer positions
May 23, 2022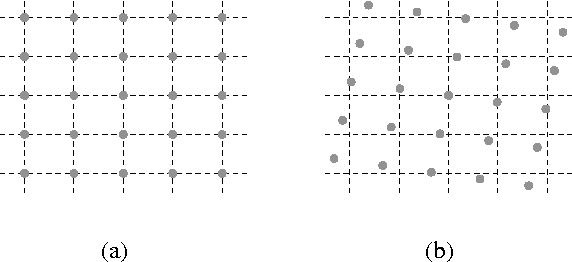

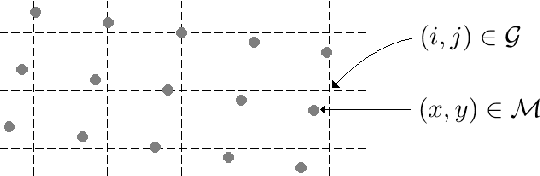
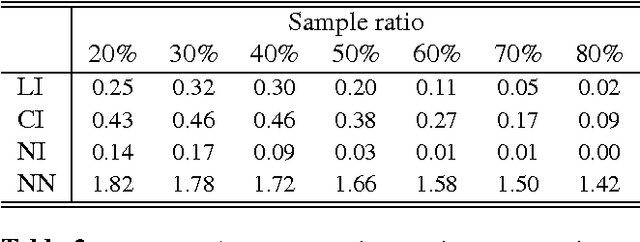
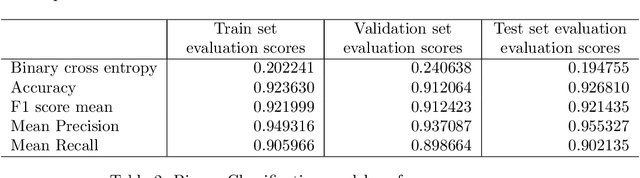
Digital images are commonly represented as regular 2D arrays, so pixels are organized in form of a matrix addressed by integers. However, there are many image processing operations, such as rotation or motion compensation, that produce pixels at non-integer positions. Typically, image reconstruction techniques cannot handle samples at non-integer positions. In this paper, we propose to use triangulation-based reconstruction as initial estimate that is later refined by a novel adaptive denoising framework. Simulations reveal that improvements of up to more than 1.8 dB (in terms of PSNR) are achieved with respect to the initial estimate.
* arXiv admin note: text overlap with arXiv:2205.10138
An Image Processing Pipeline for Camera Trap Time-Lapse Recordings
Jun 10, 2022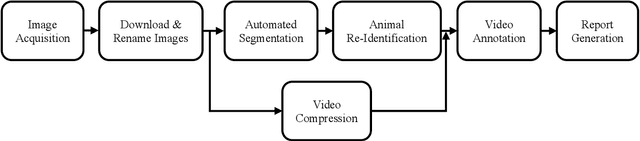
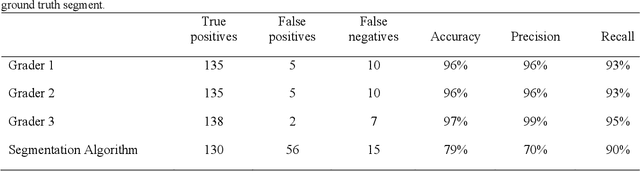

A new open-source image processing pipeline for analyzing camera trap time-lapse recordings is described. This pipeline includes machine learning models to assist human-in-the-loop video segmentation and animal re-identification. We present some performance results and observations on the utility of this pipeline after using it in a year-long project studying the spatial ecology and social behavior of the gopher tortoise.
Guided Nonlocal Patch Regularization and Efficient Filtering-Based Inversion for Multiband Fusion
Oct 09, 2022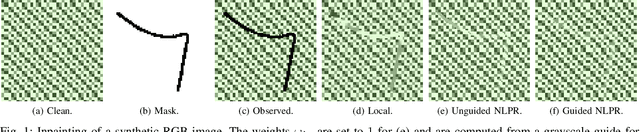

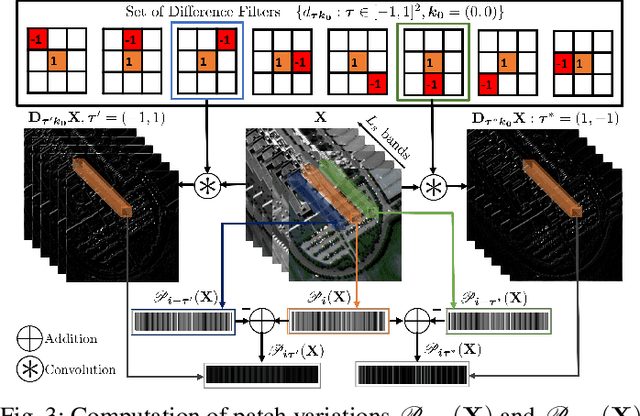
In multiband fusion, an image with a high spatial and low spectral resolution is combined with an image with a low spatial but high spectral resolution to produce a single multiband image having high spatial and spectral resolutions. This comes up in remote sensing applications such as pansharpening~(MS+PAN), hyperspectral sharpening~(HS+PAN), and HS-MS fusion~(HS+MS). Remote sensing images are textured and have repetitive structures. Motivated by nonlocal patch-based methods for image restoration, we propose a convex regularizer that (i) takes into account long-distance correlations, (ii) penalizes patch variation, which is more effective than pixel variation for capturing texture information, and (iii) uses the higher spatial resolution image as a guide image for weight computation. We come up with an efficient ADMM algorithm for optimizing the regularizer along with a standard least-squares loss function derived from the imaging model. The novelty of our algorithm is that by expressing patch variation as filtering operations and by judiciously splitting the original variables and introducing latent variables, we are able to solve the ADMM subproblems efficiently using FFT-based convolution and soft-thresholding. As far as the reconstruction quality is concerned, our method is shown to outperform state-of-the-art variational and deep learning techniques.
SEIL: Simulation-augmented Equivariant Imitation Learning
Oct 31, 2022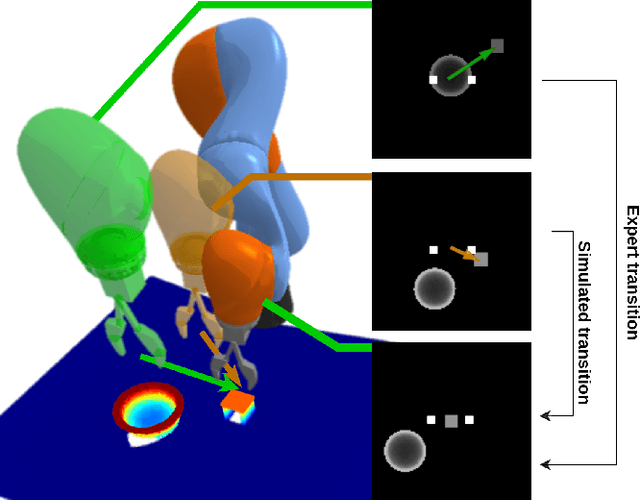

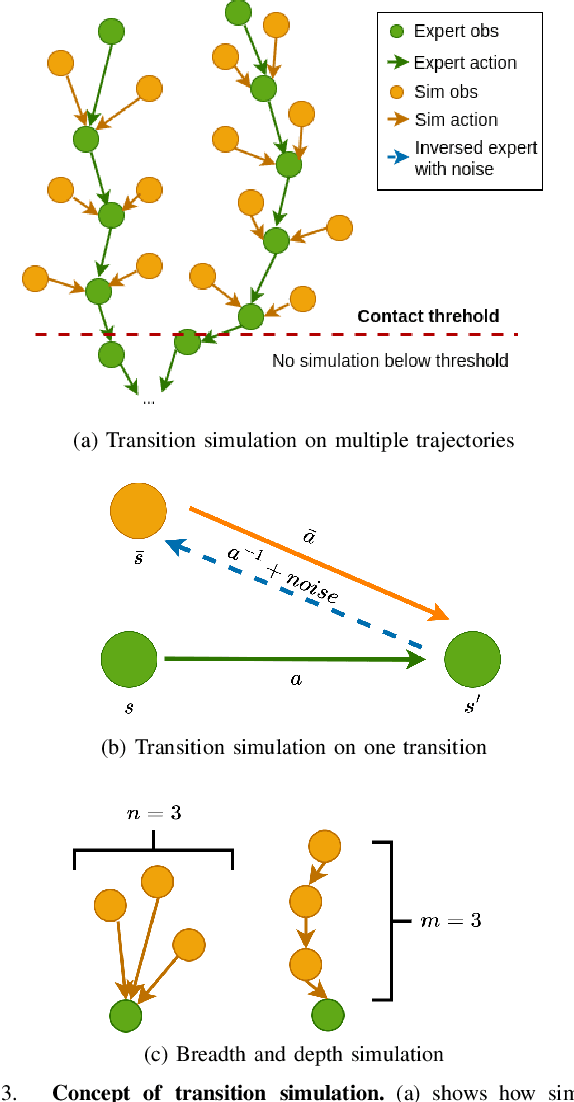
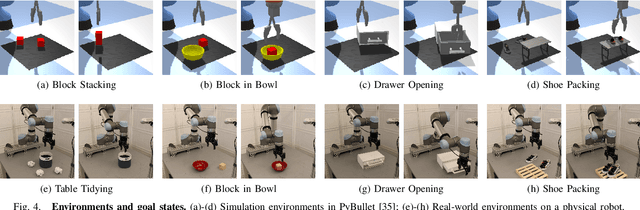
In robotic manipulation, acquiring samples is extremely expensive because it often requires interacting with the real world. Traditional image-level data augmentation has shown the potential to improve sample efficiency in various machine learning tasks. However, image-level data augmentation is insufficient for an imitation learning agent to learn good manipulation policies in a reasonable amount of demonstrations. We propose Simulation-augmented Equivariant Imitation Learning (SEIL), a method that combines a novel data augmentation strategy of supplementing expert trajectories with simulated transitions and an equivariant model that exploits the $\mathrm{O}(2)$ symmetry in robotic manipulation. Experimental evaluations demonstrate that our method can learn non-trivial manipulation tasks within ten demonstrations and outperforms the baselines with a significant margin.
Deformably-Scaled Transposed Convolution
Oct 17, 2022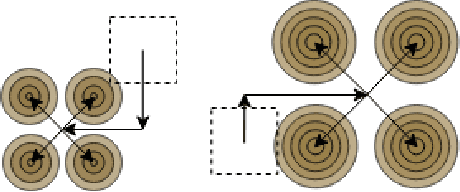

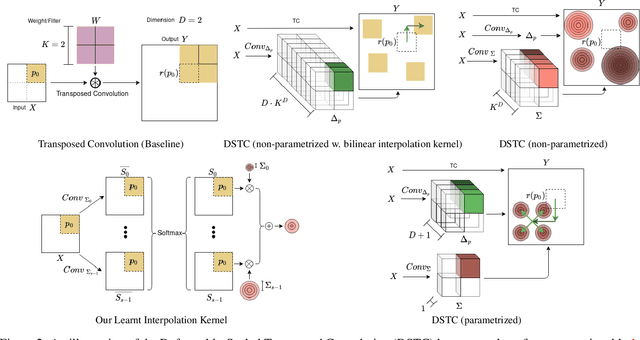
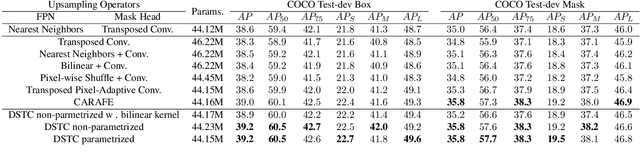
Transposed convolution is crucial for generating high-resolution outputs, yet has received little attention compared to convolution layers. In this work we revisit transposed convolution and introduce a novel layer that allows us to place information in the image selectively and choose the `stroke breadth' at which the image is synthesized, whilst incurring a small additional parameter cost. For this we introduce three ideas: firstly, we regress offsets to the positions where the transpose convolution results are placed; secondly we broadcast the offset weight locations over a learnable neighborhood; and thirdly we use a compact parametrization to share weights and restrict offsets. We show that simply substituting upsampling operators with our novel layer produces substantial improvements across tasks as diverse as instance segmentation, object detection, semantic segmentation, generative image modeling, and 3D magnetic resonance image enhancement, while outperforming all existing variants of transposed convolutions. Our novel layer can be used as a drop-in replacement for 2D and 3D upsampling operators and the code will be publicly available.
Learning Reward Functions for Robotic Manipulation by Observing Humans
Nov 16, 2022
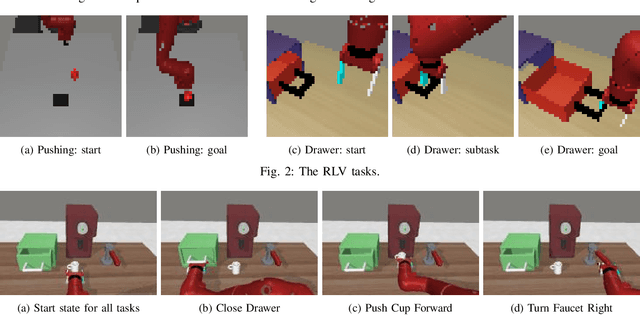
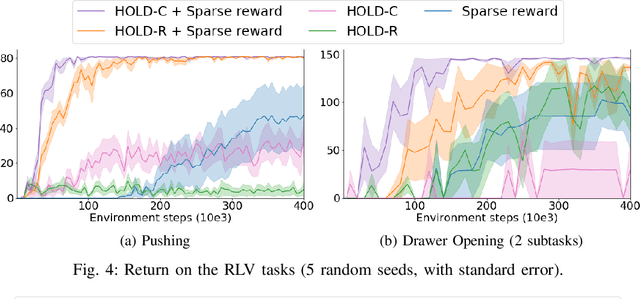
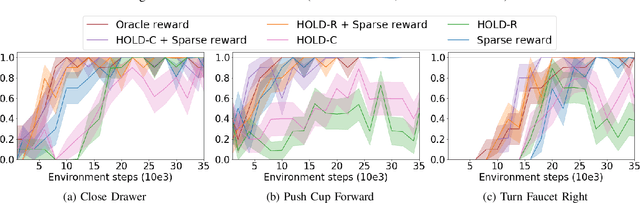
Observing a human demonstrator manipulate objects provides a rich, scalable and inexpensive source of data for learning robotic policies. However, transferring skills from human videos to a robotic manipulator poses several challenges, not least a difference in action and observation spaces. In this work, we use unlabeled videos of humans solving a wide range of manipulation tasks to learn a task-agnostic reward function for robotic manipulation policies. Thanks to the diversity of this training data, the learned reward function sufficiently generalizes to image observations from a previously unseen robot embodiment and environment to provide a meaningful prior for directed exploration in reinforcement learning. The learned rewards are based on distances to a goal in an embedding space learned using a time-contrastive objective. By conditioning the function on a goal image, we are able to reuse one model across a variety of tasks. Unlike prior work on leveraging human videos to teach robots, our method, Human Offline Learned Distances (HOLD) requires neither a priori data from the robot environment, nor a set of task-specific human demonstrations, nor a predefined notion of correspondence across morphologies, yet it is able to accelerate training of several manipulation tasks on a simulated robot arm compared to using only a sparse reward obtained from task completion.
TransCC: Transformer-based Multiple Illuminant Color Constancy Using Multitask Learning
Nov 16, 2022
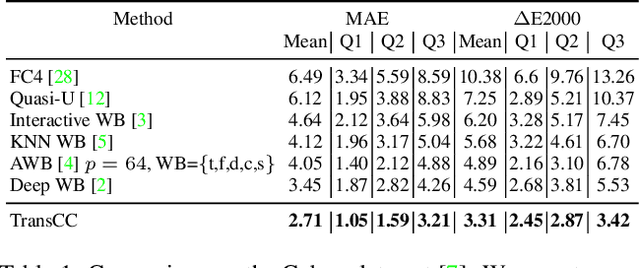
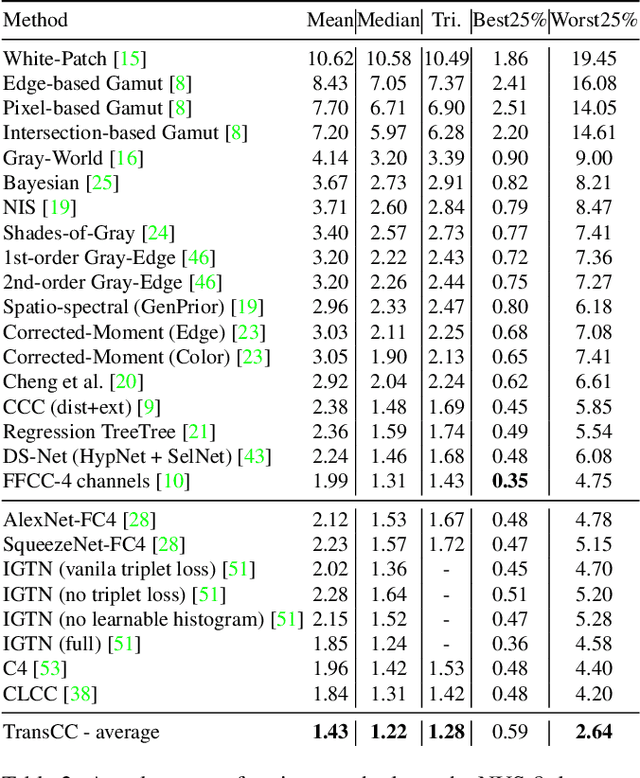
Multi-illuminant color constancy is a challenging problem with only a few existing methods. For example, one prior work used a small set of predefined white balance settings and spatially blended among them, limiting the solution to predefined illuminations. Another method proposed a generative adversarial network and an angular loss, yet the performance is suboptimal due to the lack of regularization for multi-illumination colors. This paper introduces a transformer-based multi-task learning method to estimate single and multiple light colors from a single input image. To help our deep learning model have better cues of the light colors, achromatic-pixel detection, and edge detection are used as auxiliary tasks in our multi-task learning setting. By exploiting extracted content features from the input image as tokens, illuminant color correlations between pixels are learned by leveraging contextual information in our transformer. Our transformer approach is further assisted via a contrastive loss defined between the input, output, and ground truth. We demonstrate that our proposed model achieves 40.7% improvement compared to a state-of-the-art multi-illuminant color constancy method on a multi-illuminant dataset (LSMI). Moreover, our model maintains a robust performance on the single illuminant dataset (NUS-8) and provides 22.3% improvement on the state-of-the-art single color constancy method.
Towards Transparency in Dermatology Image Datasets with Skin Tone Annotations by Experts, Crowds, and an Algorithm
Jul 06, 2022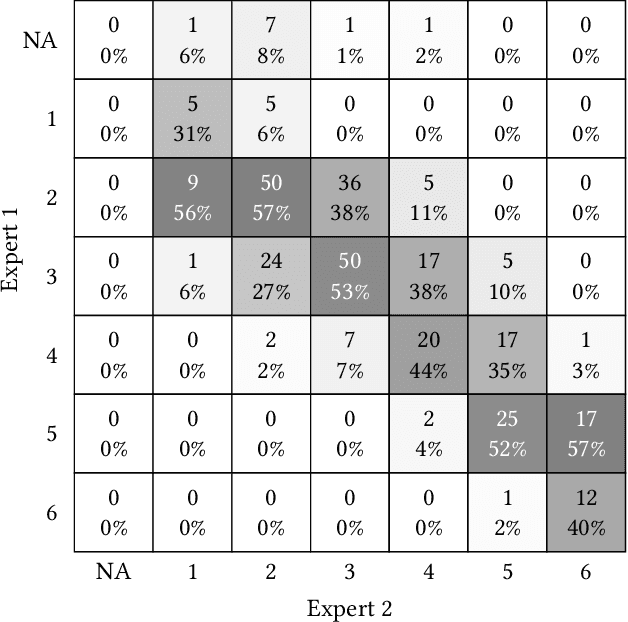
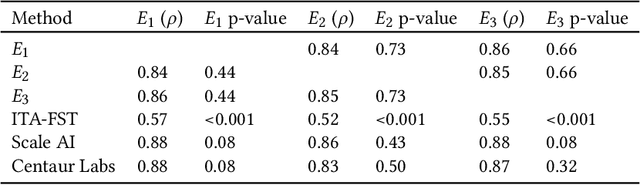
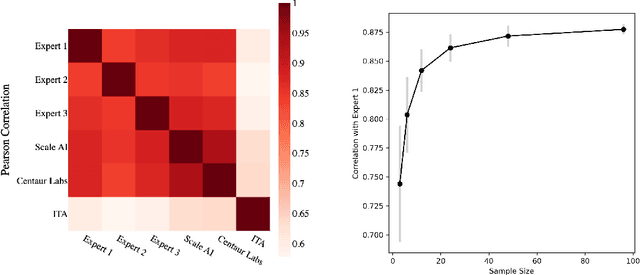
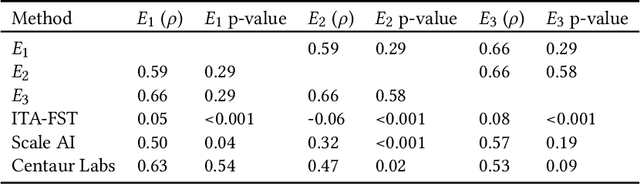
While artificial intelligence (AI) holds promise for supporting healthcare providers and improving the accuracy of medical diagnoses, a lack of transparency in the composition of datasets exposes AI models to the possibility of unintentional and avoidable mistakes. In particular, public and private image datasets of dermatological conditions rarely include information on skin color. As a start towards increasing transparency, AI researchers have appropriated the use of the Fitzpatrick skin type (FST) from a measure of patient photosensitivity to a measure for estimating skin tone in algorithmic audits of computer vision applications including facial recognition and dermatology diagnosis. In order to understand the variability of estimated FST annotations on images, we compare several FST annotation methods on a diverse set of 460 images of skin conditions from both textbooks and online dermatology atlases. We find the inter-rater reliability between three board-certified dermatologists is comparable to the inter-rater reliability between the board-certified dermatologists and two crowdsourcing methods. In contrast, we find that the Individual Typology Angle converted to FST (ITA-FST) method produces annotations that are significantly less correlated with the experts' annotations than the experts' annotations are correlated with each other. These results demonstrate that algorithms based on ITA-FST are not reliable for annotating large-scale image datasets, but human-centered, crowd-based protocols can reliably add skin type transparency to dermatology datasets. Furthermore, we introduce the concept of dynamic consensus protocols with tunable parameters including expert review that increase the visibility of crowdwork and provide guidance for future crowdsourced annotations of large image datasets.
AMICO: Amodal Instance Composition
Oct 11, 2022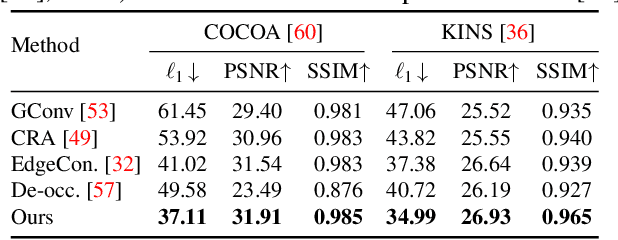
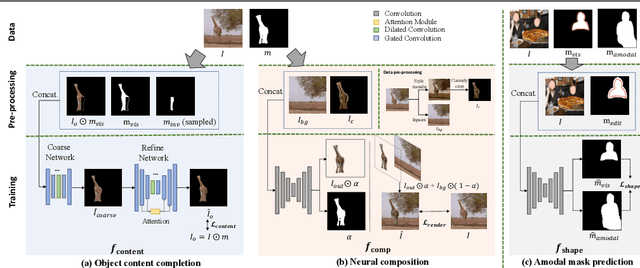


Image composition aims to blend multiple objects to form a harmonized image. Existing approaches often assume precisely segmented and intact objects. Such assumptions, however, are hard to satisfy in unconstrained scenarios. We present Amodal Instance Composition for compositing imperfect -- potentially incomplete and/or coarsely segmented -- objects onto a target image. We first develop object shape prediction and content completion modules to synthesize the amodal contents. We then propose a neural composition model to blend the objects seamlessly. Our primary technical novelty lies in using separate foreground/background representations and blending mask prediction to alleviate segmentation errors. Our results show state-of-the-art performance on public COCOA and KINS benchmarks and attain favorable visual results across diverse scenes. We demonstrate various image composition applications such as object insertion and de-occlusion.