 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Progressive Motion Context Refine Network for Efficient Video Frame Interpolation
Nov 11, 2022
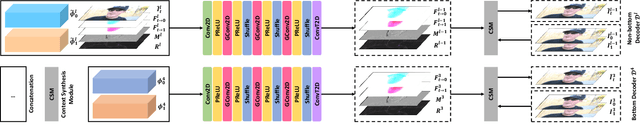
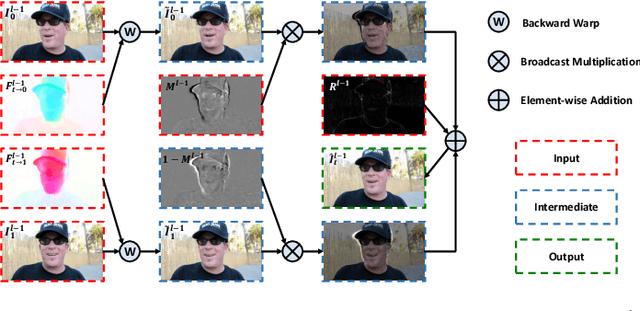

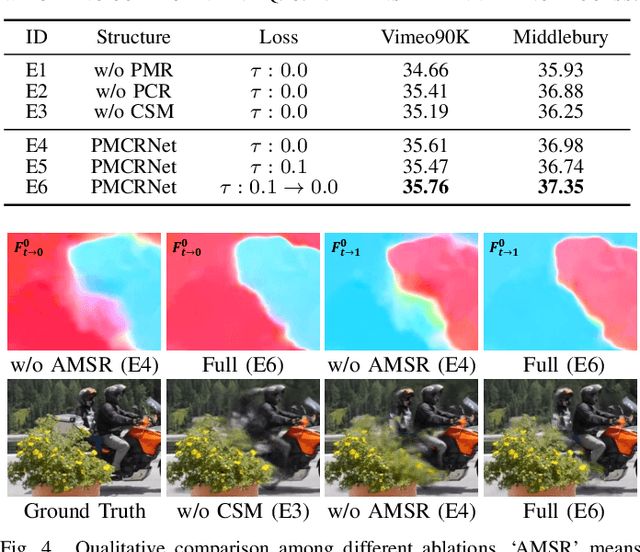
Recently, flow-based frame interpolation methods have achieved great success by first modeling optical flow between target and input frames, and then building synthesis network for target frame generation. However, above cascaded architecture can lead to large model size and inference delay, hindering them from mobile and real-time applications. To solve this problem, we propose a novel Progressive Motion Context Refine Network (PMCRNet) to predict motion fields and image context jointly for higher efficiency. Different from others that directly synthesize target frame from deep feature, we explore to simplify frame interpolation task by borrowing existing texture from adjacent input frames, which means that decoder in each pyramid level of our PMCRNet only needs to update easier intermediate optical flow, occlusion merge mask and image residual. Moreover, we introduce a new annealed multi-scale reconstruction loss to better guide the learning process of this efficient PMCRNet. Experiments on multiple benchmarks show that proposed approaches not only achieve favorable quantitative and qualitative results but also reduces current model size and running time significantly.
Embedding contrastive unsupervised features to cluster in- and out-of-distribution noise in corrupted image datasets
Jul 04, 2022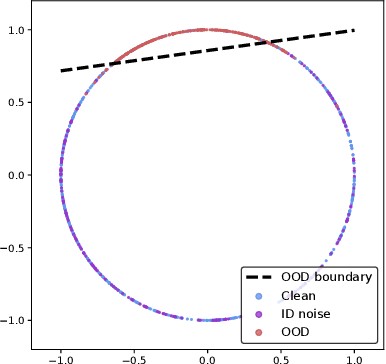
Using search engines for web image retrieval is a tempting alternative to manual curation when creating an image dataset, but their main drawback remains the proportion of incorrect (noisy) samples retrieved. These noisy samples have been evidenced by previous works to be a mixture of in-distribution (ID) samples, assigned to the incorrect category but presenting similar visual semantics to other classes in the dataset, and out-of-distribution (OOD) images, which share no semantic correlation with any category from the dataset. The latter are, in practice, the dominant type of noisy images retrieved. To tackle this noise duality, we propose a two stage algorithm starting with a detection step where we use unsupervised contrastive feature learning to represent images in a feature space. We find that the alignment and uniformity principles of contrastive learning allow OOD samples to be linearly separated from ID samples on the unit hypersphere. We then spectrally embed the unsupervised representations using a fixed neighborhood size and apply an outlier sensitive clustering at the class level to detect the clean and OOD clusters as well as ID noisy outliers. We finally train a noise robust neural network that corrects ID noise to the correct category and utilizes OOD samples in a guided contrastive objective, clustering them to improve low-level features. Our algorithm improves the state-of-the-art results on synthetic noise image datasets as well as real-world web-crawled data. Our work is fully reproducible [github].
Robust Sensible Adversarial Learning of Deep Neural Networks for Image Classification
May 20, 2022
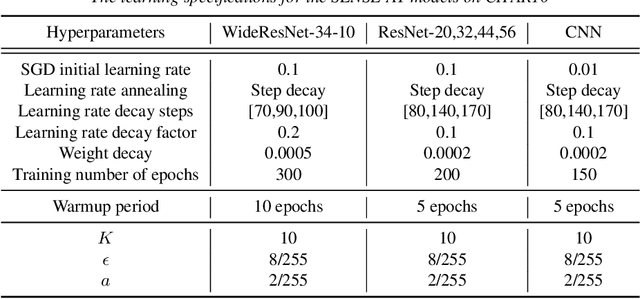

The idea of robustness is central and critical to modern statistical analysis. However, despite the recent advances of deep neural networks (DNNs), many studies have shown that DNNs are vulnerable to adversarial attacks. Making imperceptible changes to an image can cause DNN models to make the wrong classification with high confidence, such as classifying a benign mole as a malignant tumor and a stop sign as a speed limit sign. The trade-off between robustness and standard accuracy is common for DNN models. In this paper, we introduce sensible adversarial learning and demonstrate the synergistic effect between pursuits of standard natural accuracy and robustness. Specifically, we define a sensible adversary which is useful for learning a robust model while keeping high natural accuracy. We theoretically establish that the Bayes classifier is the most robust multi-class classifier with the 0-1 loss under sensible adversarial learning. We propose a novel and efficient algorithm that trains a robust model using implicit loss truncation. We apply sensible adversarial learning for large-scale image classification to a handwritten digital image dataset called MNIST and an object recognition colored image dataset called CIFAR10. We have performed an extensive comparative study to compare our method with other competitive methods. Our experiments empirically demonstrate that our method is not sensitive to its hyperparameter and does not collapse even with a small model capacity while promoting robustness against various attacks and keeping high natural accuracy.
Music Enhancement via Image Translation and Vocoding
Apr 28, 2022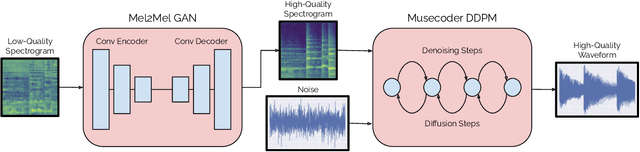
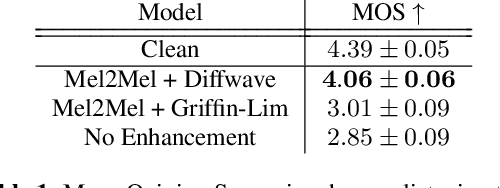


Consumer-grade music recordings such as those captured by mobile devices typically contain distortions in the form of background noise, reverb, and microphone-induced EQ. This paper presents a deep learning approach to enhance low-quality music recordings by combining (i) an image-to-image translation model for manipulating audio in its mel-spectrogram representation and (ii) a music vocoding model for mapping synthetically generated mel-spectrograms to perceptually realistic waveforms. We find that this approach to music enhancement outperforms baselines which use classical methods for mel-spectrogram inversion and an end-to-end approach directly mapping noisy waveforms to clean waveforms. Additionally, in evaluating the proposed method with a listening test, we analyze the reliability of common audio enhancement evaluation metrics when used in the music domain.
Image Compression and Actionable Intelligence With Deep Neural Networks
Mar 30, 2022
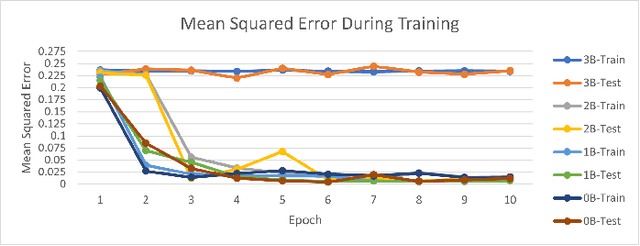

If a unit cannot receive intelligence from a source due to external factors, we consider them disadvantaged users. We categorize this as a preoccupied unit working on a low connectivity device on the edge. This case requires that we use a different approach to deliver intelligence, particularly satellite imagery information, than normally employed. To address this, we propose a survey of information reduction techniques to deliver the information from a satellite image in a smaller package. We investigate four techniques to aid in the reduction of delivered information: traditional image compression, neural network image compression, object detection image cutout, and image to caption. Each of these mechanisms have their benefits and tradeoffs when considered for a disadvantaged user.
RSVG: Exploring Data and Models for Visual Grounding on Remote Sensing Data
Oct 23, 2022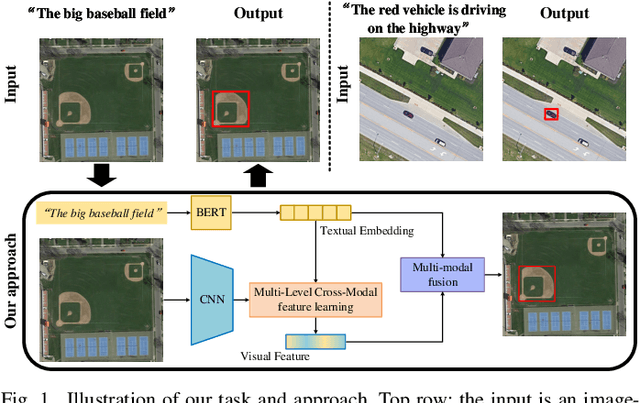
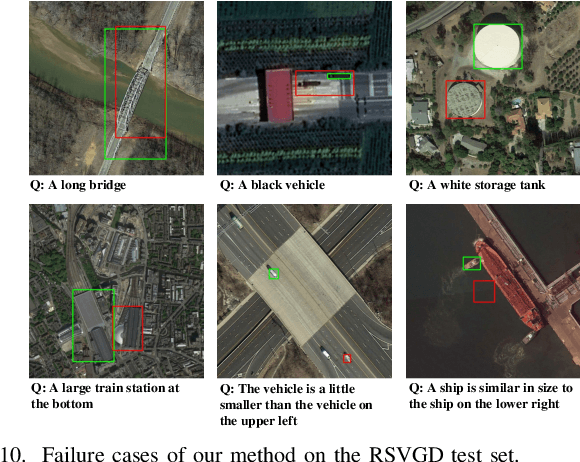

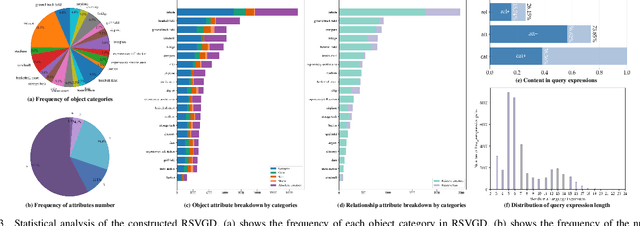
In this paper, we introduce the task of visual grounding for remote sensing data (RSVG). RSVG aims to localize the referred objects in remote sensing (RS) images with the guidance of natural language. To retrieve rich information from RS imagery using natural language, many research tasks, like RS image visual question answering, RS image captioning, and RS image-text retrieval have been investigated a lot. However, the object-level visual grounding on RS images is still under-explored. Thus, in this work, we propose to construct the dataset and explore deep learning models for the RSVG task. Specifically, our contributions can be summarized as follows. 1) We build the new large-scale benchmark dataset of RSVG, termed RSVGD, to fully advance the research of RSVG. This new dataset includes image/expression/box triplets for training and evaluating visual grounding models. 2) We benchmark extensive state-of-the-art (SOTA) natural image visual grounding methods on the constructed RSVGD dataset, and some insightful analyses are provided based on the results. 3) A novel transformer-based Multi-Level Cross-Modal feature learning (MLCM) module is proposed. Remotely-sensed images are usually with large scale variations and cluttered backgrounds. To deal with the scale-variation problem, the MLCM module takes advantage of multi-scale visual features and multi-granularity textual embeddings to learn more discriminative representations. To cope with the cluttered background problem, MLCM adaptively filters irrelevant noise and enhances salient features. In this way, our proposed model can incorporate more effective multi-level and multi-modal features to boost performance. Furthermore, this work also provides useful insights for developing better RSVG models. The dataset and code will be publicly available at https://github.com/ZhanYang-nwpu/RSVG-pytorch.
Efficient Image Super-Resolution using Vast-Receptive-Field Attention
Oct 12, 2022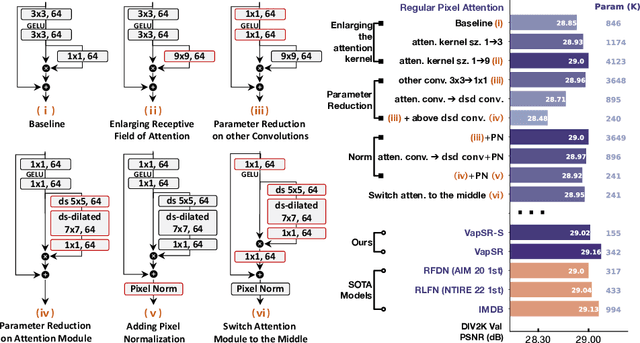
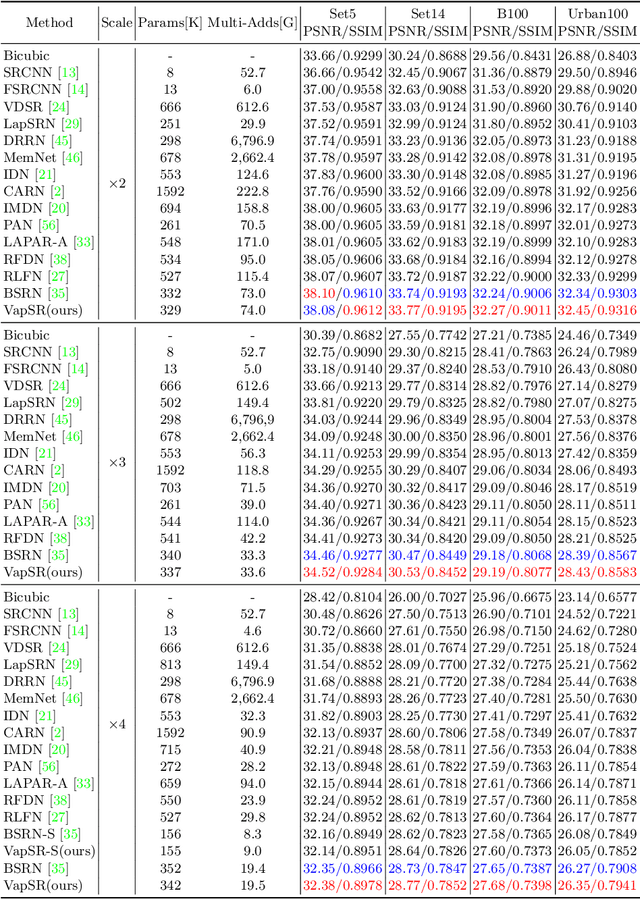
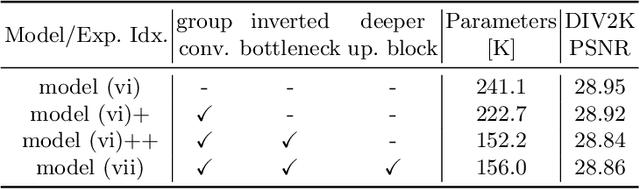
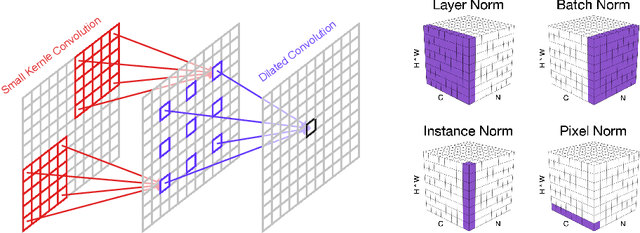
The attention mechanism plays a pivotal role in designing advanced super-resolution (SR) networks. In this work, we design an efficient SR network by improving the attention mechanism. We start from a simple pixel attention module and gradually modify it to achieve better super-resolution performance with reduced parameters. The specific approaches include: (1) increasing the receptive field of the attention branch, (2) replacing large dense convolution kernels with depth-wise separable convolutions, and (3) introducing pixel normalization. These approaches paint a clear evolutionary roadmap for the design of attention mechanisms. Based on these observations, we propose VapSR, the VAst-receptive-field Pixel attention network. Experiments demonstrate the superior performance of VapSR. VapSR outperforms the present lightweight networks with even fewer parameters. And the light version of VapSR can use only 21.68% and 28.18% parameters of IMDB and RFDN to achieve similar performances to those networks. The code and models are available at url{https://github.com/zhoumumu/VapSR.
SEIL: Simulation-augmented Equivariant Imitation Learning
Oct 31, 2022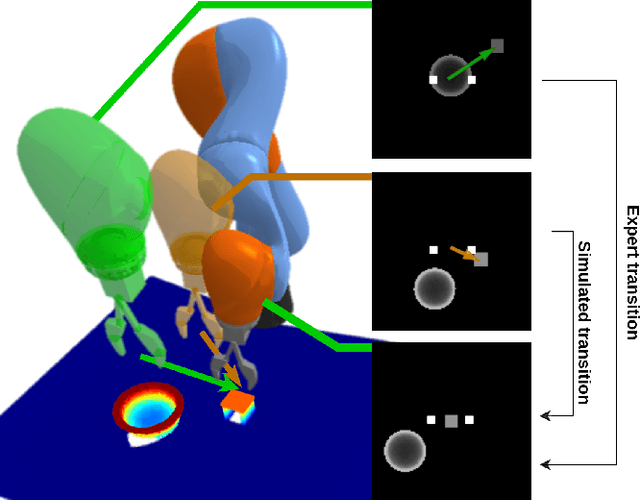

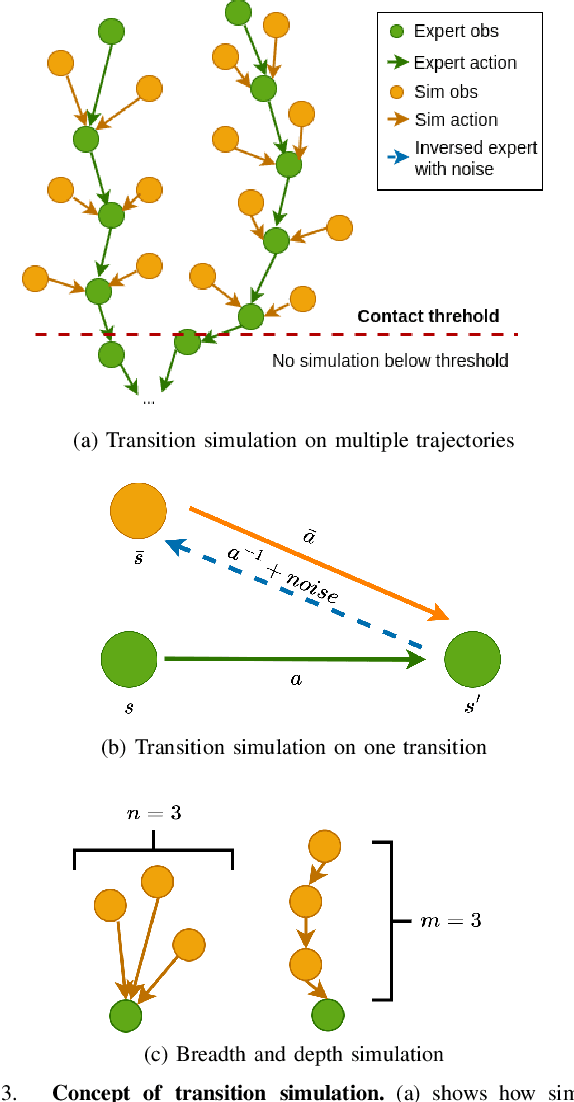
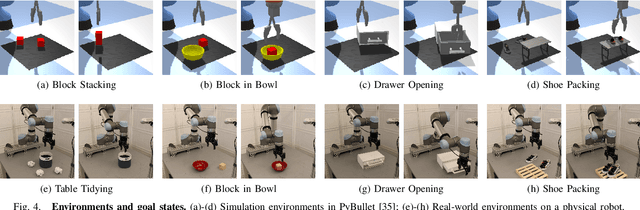
In robotic manipulation, acquiring samples is extremely expensive because it often requires interacting with the real world. Traditional image-level data augmentation has shown the potential to improve sample efficiency in various machine learning tasks. However, image-level data augmentation is insufficient for an imitation learning agent to learn good manipulation policies in a reasonable amount of demonstrations. We propose Simulation-augmented Equivariant Imitation Learning (SEIL), a method that combines a novel data augmentation strategy of supplementing expert trajectories with simulated transitions and an equivariant model that exploits the $\mathrm{O}(2)$ symmetry in robotic manipulation. Experimental evaluations demonstrate that our method can learn non-trivial manipulation tasks within ten demonstrations and outperforms the baselines with a significant margin.
Image Generation with Multimodal Priors using Denoising Diffusion Probabilistic Models
Jun 10, 2022



Image synthesis under multi-modal priors is a useful and challenging task that has received increasing attention in recent years. A major challenge in using generative models to accomplish this task is the lack of paired data containing all modalities (i.e. priors) and corresponding outputs. In recent work, a variational auto-encoder (VAE) model was trained in a weakly supervised manner to address this challenge. Since the generative power of VAEs is usually limited, it is difficult for this method to synthesize images belonging to complex distributions. To this end, we propose a solution based on a denoising diffusion probabilistic models to synthesise images under multi-model priors. Based on the fact that the distribution over each time step in the diffusion model is Gaussian, in this work we show that there exists a closed-form expression to the generate the image corresponds to the given modalities. The proposed solution does not require explicit retraining for all modalities and can leverage the outputs of individual modalities to generate realistic images according to different constraints. We conduct studies on two real-world datasets to demonstrate the effectiveness of our approach
Guided Nonlocal Patch Regularization and Efficient Filtering-Based Inversion for Multiband Fusion
Oct 09, 2022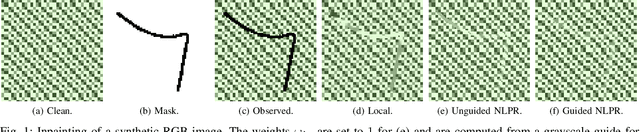

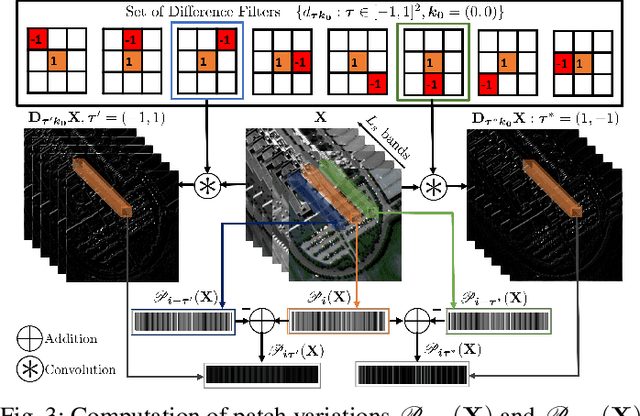
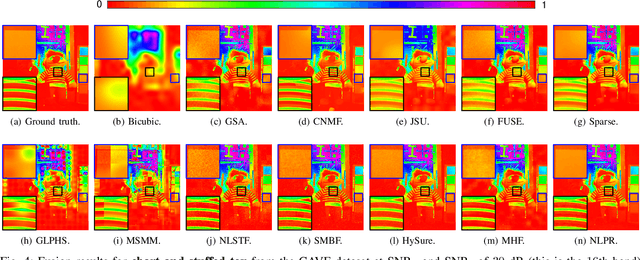
In multiband fusion, an image with a high spatial and low spectral resolution is combined with an image with a low spatial but high spectral resolution to produce a single multiband image having high spatial and spectral resolutions. This comes up in remote sensing applications such as pansharpening~(MS+PAN), hyperspectral sharpening~(HS+PAN), and HS-MS fusion~(HS+MS). Remote sensing images are textured and have repetitive structures. Motivated by nonlocal patch-based methods for image restoration, we propose a convex regularizer that (i) takes into account long-distance correlations, (ii) penalizes patch variation, which is more effective than pixel variation for capturing texture information, and (iii) uses the higher spatial resolution image as a guide image for weight computation. We come up with an efficient ADMM algorithm for optimizing the regularizer along with a standard least-squares loss function derived from the imaging model. The novelty of our algorithm is that by expressing patch variation as filtering operations and by judiciously splitting the original variables and introducing latent variables, we are able to solve the ADMM subproblems efficiently using FFT-based convolution and soft-thresholding. As far as the reconstruction quality is concerned, our method is shown to outperform state-of-the-art variational and deep learning techniques.