 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quantifying the Resolution of a Template after Image Registration
Feb 27, 2024
In many image processing applications (e.g. computational anatomy) a groupwise registration is performed on a sample of images and a template image is simultaneously generated. From the template alone it is in general unclear to which extent the registered images are still misaligned, which means that some regions of the template represent the structural features in the sample images less reliably than others. In a sense, the template exhibits a lower resolution there. Guided by characteristic examples of misaligned image features in one dimension, we develop a visual measure to quantify the resolution at each location of a template which is based on the observation that misalignments between the registered sample images are reduced by smoothing with the strength of the smoothing being related to the magnitude of the misalignment. Finally the resulting resolution measure is applied to example datasets in two and three dimensions. The corresponding code is publicly available on GitHub.
Invisible Backdoor Attack Through Singular Value Decomposition
Mar 18, 2024
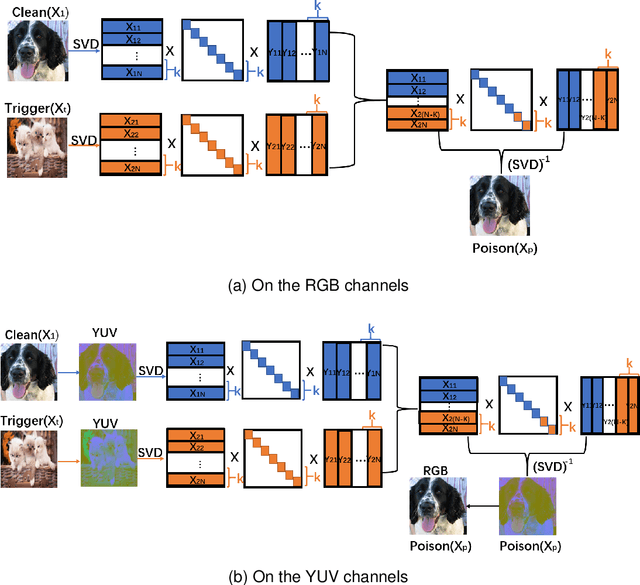

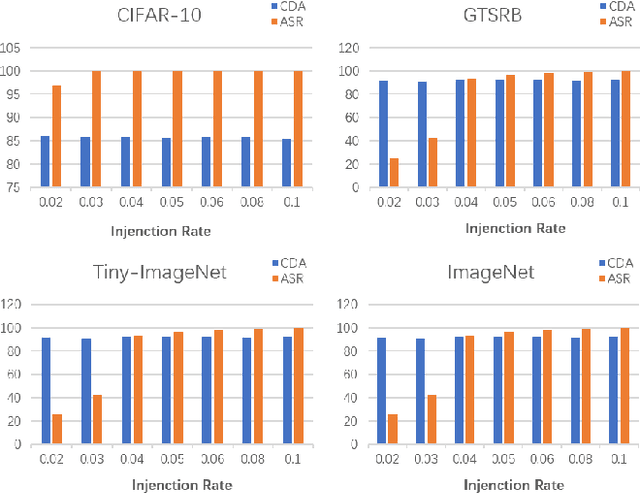
With the widespread application of deep learning across various domains, concerns about its security have grown significantly. Among these, backdoor attacks pose a serious security threat to deep neural networks (DNNs). In recent years, backdoor attacks on neural networks have become increasingly sophisticated, aiming to compromise the security and trustworthiness of models by implanting hidden, unauthorized functionalities or triggers, leading to misleading predictions or behaviors. To make triggers less perceptible and imperceptible, various invisible backdoor attacks have been proposed. However, most of them only consider invisibility in the spatial domain, making it easy for recent defense methods to detect the generated toxic images.To address these challenges, this paper proposes an invisible backdoor attack called DEBA. DEBA leverages the mathematical properties of Singular Value Decomposition (SVD) to embed imperceptible backdoors into models during the training phase, thereby causing them to exhibit predefined malicious behavior under specific trigger conditions. Specifically, we first perform SVD on images, and then replace the minor features of trigger images with those of clean images, using them as triggers to ensure the effectiveness of the attack. As minor features are scattered throughout the entire image, the major features of clean images are preserved, making poisoned images visually indistinguishable from clean ones. Extensive experimental evaluations demonstrate that DEBA is highly effective, maintaining high perceptual quality and a high attack success rate for poisoned images. Furthermore, we assess the performance of DEBA under existing defense measures, showing that it is robust and capable of significantly evading and resisting the effects of these defense measures.
3D-SceneDreamer: Text-Driven 3D-Consistent Scene Generation
Mar 14, 2024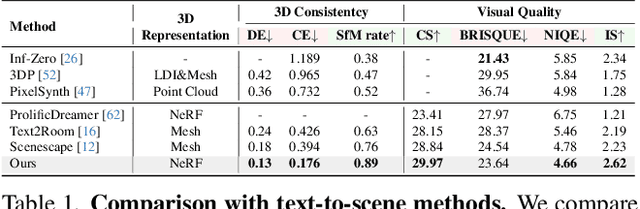
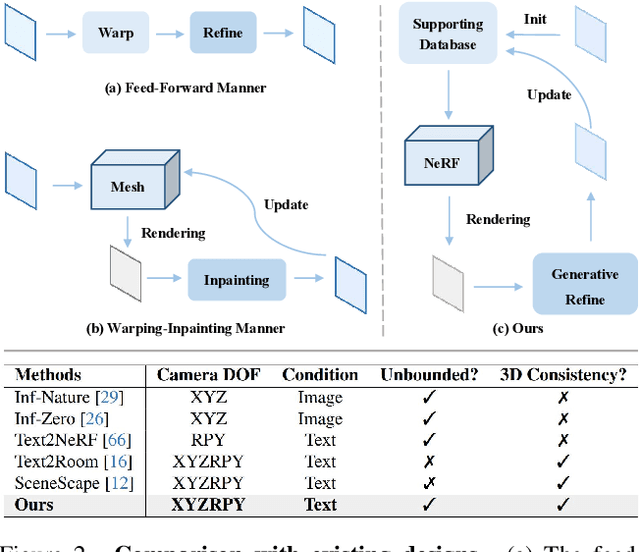
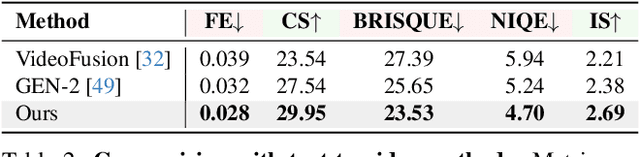
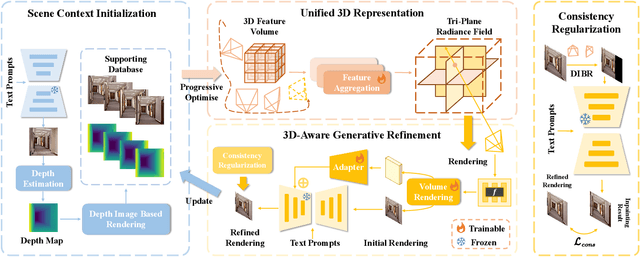
Text-driven 3D scene generation techniques have made rapid progress in recent years. Their success is mainly attributed to using existing generative models to iteratively perform image warping and inpainting to generate 3D scenes. However, these methods heavily rely on the outputs of existing models, leading to error accumulation in geometry and appearance that prevent the models from being used in various scenarios (e.g., outdoor and unreal scenarios). To address this limitation, we generatively refine the newly generated local views by querying and aggregating global 3D information, and then progressively generate the 3D scene. Specifically, we employ a tri-plane features-based NeRF as a unified representation of the 3D scene to constrain global 3D consistency, and propose a generative refinement network to synthesize new contents with higher quality by exploiting the natural image prior from 2D diffusion model as well as the global 3D information of the current scene. Our extensive experiments demonstrate that, in comparison to previous methods, our approach supports wide variety of scene generation and arbitrary camera trajectories with improved visual quality and 3D consistency.
Decomposing Disease Descriptions for Enhanced Pathology Detection: A Multi-Aspect Vision-Language Matching Framework
Mar 12, 2024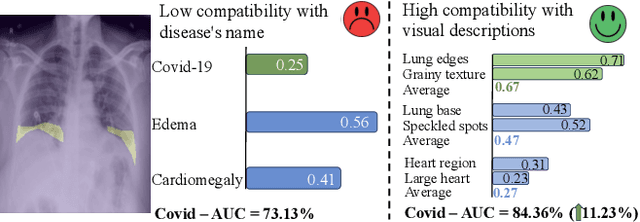
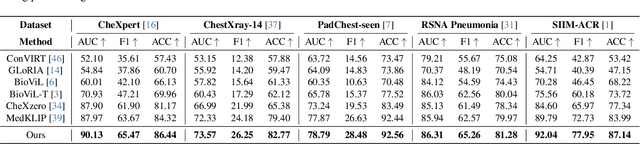

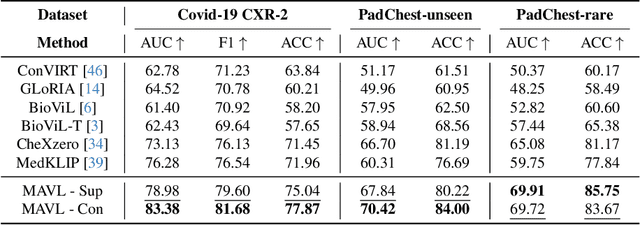
Medical vision language pre-training (VLP) has emerged as a frontier of research, enabling zero-shot pathological recognition by comparing the query image with the textual descriptions for each disease. Due to the complex semantics of biomedical texts, current methods struggle to align medical images with key pathological findings in unstructured reports. This leads to the misalignment with the target disease's textual representation. In this paper, we introduce a novel VLP framework designed to dissect disease descriptions into their fundamental aspects, leveraging prior knowledge about the visual manifestations of pathologies. This is achieved by consulting a large language model and medical experts. Integrating a Transformer module, our approach aligns an input image with the diverse elements of a disease, generating aspect-centric image representations. By consolidating the matches from each aspect, we improve the compatibility between an image and its associated disease. Additionally, capitalizing on the aspect-oriented representations, we present a dual-head Transformer tailored to process known and unknown diseases, optimizing the comprehensive detection efficacy. Conducting experiments on seven downstream datasets, ours outperforms recent methods by up to 8.07% and 11.23% in AUC scores for seen and novel categories, respectively. Our code is released at \href{https://github.com/HieuPhan33/MAVL}{https://github.com/HieuPhan33/MAVL}.
Stitching Gaps: Fusing Situated Perceptual Knowledge with Vision Transformers for High-Level Image Classification
Feb 29, 2024The increasing demand for automatic high-level image understanding, particularly in detecting abstract concepts (AC) within images, underscores the necessity for innovative and more interpretable approaches. These approaches need to harmonize traditional deep vision methods with the nuanced, context-dependent knowledge humans employ to interpret images at intricate semantic levels. In this work, we leverage situated perceptual knowledge of cultural images to enhance performance and interpretability in AC image classification. We automatically extract perceptual semantic units from images, which we then model and integrate into the ARTstract Knowledge Graph (AKG). This resource captures situated perceptual semantics gleaned from over 14,000 cultural images labeled with ACs. Additionally, we enhance the AKG with high-level linguistic frames. We compute KG embeddings and experiment with relative representations and hybrid approaches that fuse these embeddings with visual transformer embeddings. Finally, for interpretability, we conduct posthoc qualitative analyses by examining model similarities with training instances. Our results show that our hybrid KGE-ViT methods outperform existing techniques in AC image classification. The posthoc interpretability analyses reveal the visual transformer's proficiency in capturing pixel-level visual attributes, contrasting with our method's efficacy in representing more abstract and semantic scene elements. We demonstrate the synergy and complementarity between KGE embeddings' situated perceptual knowledge and deep visual model's sensory-perceptual understanding for AC image classification. This work suggests a strong potential of neuro-symbolic methods for knowledge integration and robust image representation for use in downstream intricate visual comprehension tasks. All the materials and code are available online.
Fully Distributed Cooperative Multi-agent Underwater Obstacle Avoidance Under Dog Walking Paradigm
Mar 16, 2024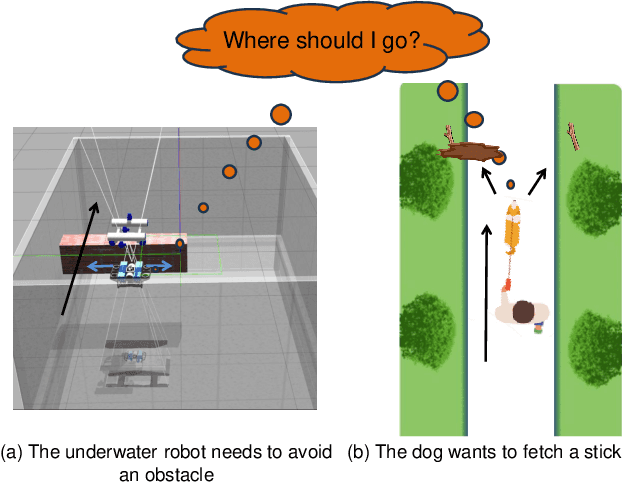
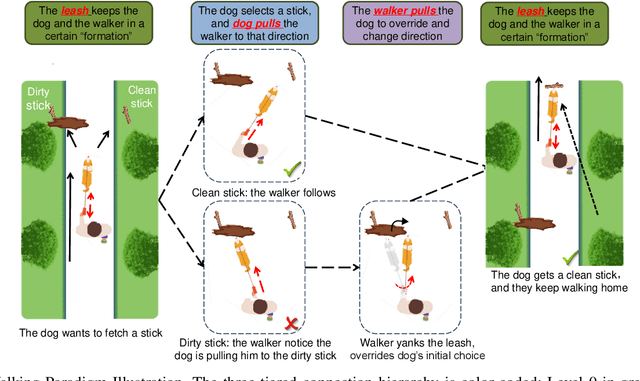
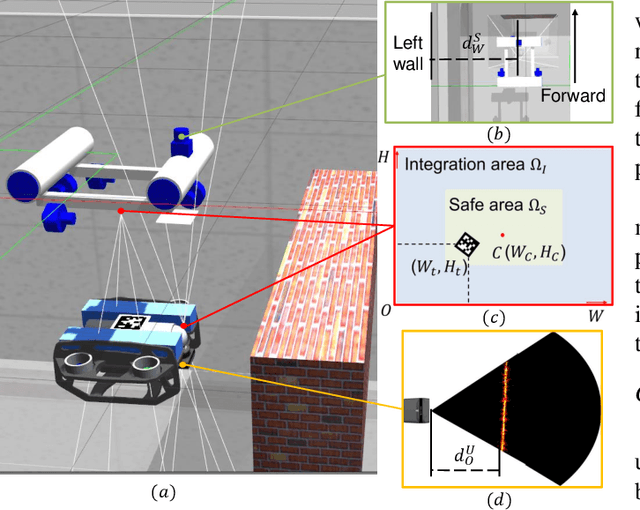
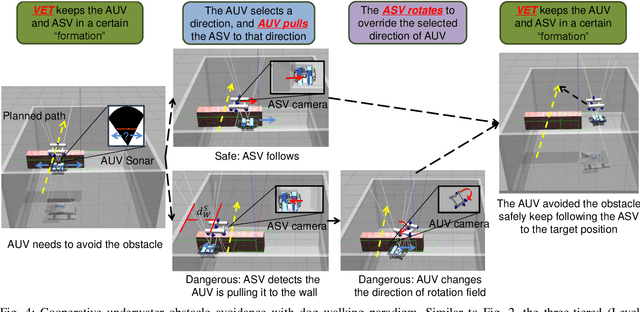
Navigation in cluttered underwater environments is challenging, especially when there are constraints on communication and self-localisation. Part of the fully distributed underwater navigation problem has been resolved by introducing multi-agent robot teams, however when the environment becomes cluttered, the problem remains unresolved. In this paper, we first studied the connection between everyday activity of dog walking and the cooperative underwater obstacle avoidance problem. Inspired by this analogy, we propose a novel dog walking paradigm and implement it in a multi-agent underwater system. Simulations were conducted across various scenarios, with performance benchmarked against traditional methods utilising Image-Based Visual Servoing in a multi-agent setup. Results indicate that our dog walking-inspired paradigm significantly enhances cooperative behavior among agents and outperforms the existing approach in navigating through obstacles.
Classes Are Not Equal: An Empirical Study on Image Recognition Fairness
Feb 28, 2024In this paper, we present an empirical study on image recognition fairness, i.e., extreme class accuracy disparity on balanced data like ImageNet. We experimentally demonstrate that classes are not equal and the fairness issue is prevalent for image classification models across various datasets, network architectures, and model capacities. Moreover, several intriguing properties of fairness are identified. First, the unfairness lies in problematic representation rather than classifier bias. Second, with the proposed concept of Model Prediction Bias, we investigate the origins of problematic representation during optimization. Our findings reveal that models tend to exhibit greater prediction biases for classes that are more challenging to recognize. It means that more other classes will be confused with harder classes. Then the False Positives (FPs) will dominate the learning in optimization, thus leading to their poor accuracy. Further, we conclude that data augmentation and representation learning algorithms improve overall performance by promoting fairness to some degree in image classification.
Diffusion Posterior Proximal Sampling for Image Restoration
Feb 25, 2024Diffusion models have demonstrated remarkable efficacy in generating high-quality samples. Existing diffusion-based image restoration algorithms exploit pre-trained diffusion models to leverage data priors, yet they still preserve elements inherited from the unconditional generation paradigm. These strategies initiate the denoising process with pure white noise and incorporate random noise at each generative step, leading to over-smoothed results. In this paper, we introduce a refined paradigm for diffusion-based image restoration. Specifically, we opt for a sample consistent with the measurement identity at each generative step, exploiting the sampling selection as an avenue for output stability and enhancement. Besides, we start the restoration process with an initialization combined with the measurement signal, providing supplementary information to better align the generative process. Extensive experimental results and analyses validate the effectiveness of our proposed approach across diverse image restoration tasks.
TAG: Guidance-free Open-Vocabulary Semantic Segmentation
Mar 17, 2024
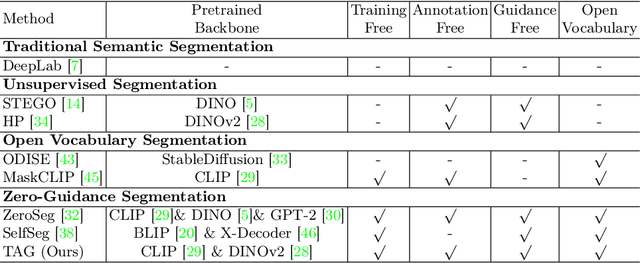
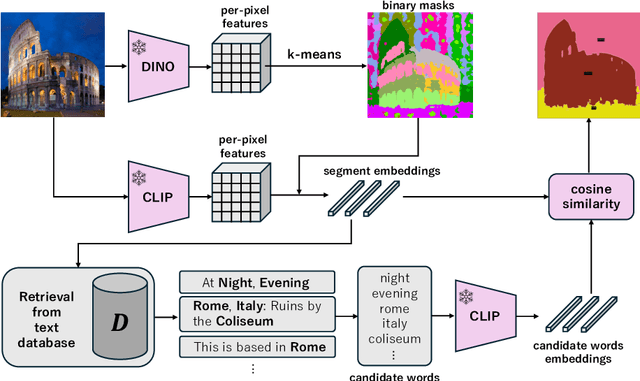
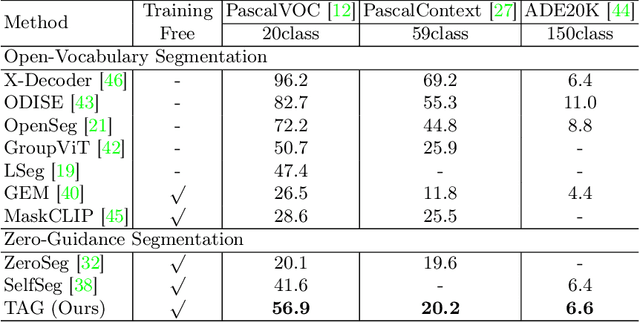
Semantic segmentation is a crucial task in computer vision, where each pixel in an image is classified into a category. However, traditional methods face significant challenges, including the need for pixel-level annotations and extensive training. Furthermore, because supervised learning uses a limited set of predefined categories, models typically struggle with rare classes and cannot recognize new ones. Unsupervised and open-vocabulary segmentation, proposed to tackle these issues, faces challenges, including the inability to assign specific class labels to clusters and the necessity of user-provided text queries for guidance. In this context, we propose a novel approach, TAG which achieves Training, Annotation, and Guidance-free open-vocabulary semantic segmentation. TAG utilizes pre-trained models such as CLIP and DINO to segment images into meaningful categories without additional training or dense annotations. It retrieves class labels from an external database, providing flexibility to adapt to new scenarios. Our TAG achieves state-of-the-art results on PascalVOC, PascalContext and ADE20K for open-vocabulary segmentation without given class names, i.e. improvement of +15.3 mIoU on PascalVOC. All code and data will be released at https://github.com/Valkyrja3607/TAG.
Cross-Modal Learning of Housing Quality in Amsterdam
Mar 13, 2024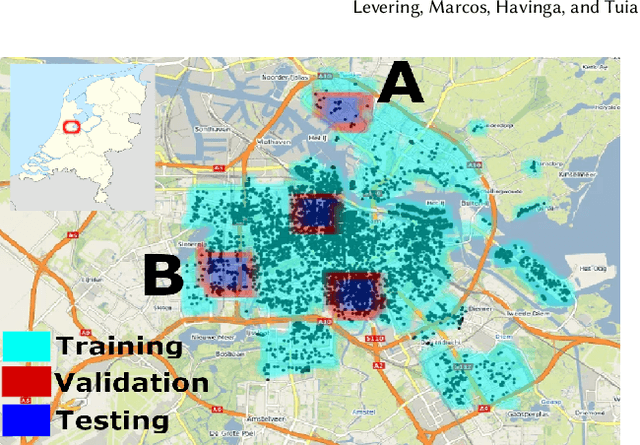
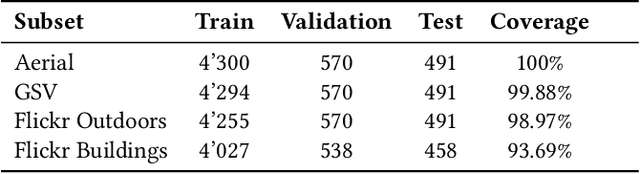
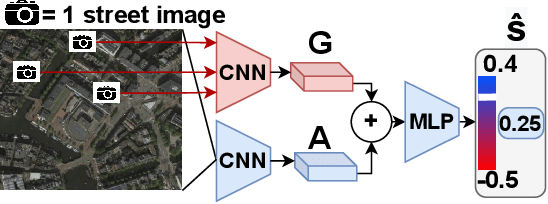

In our research we test data and models for the recognition of housing quality in the city of Amsterdam from ground-level and aerial imagery. For ground-level images we compare Google StreetView (GSV) to Flickr images. Our results show that GSV predicts the most accurate building quality scores, approximately 30% better than using only aerial images. However, we find that through careful filtering and by using the right pre-trained model, Flickr image features combined with aerial image features are able to halve the performance gap to GSV features from 30% to 15%. Our results indicate that there are viable alternatives to GSV for liveability factor prediction, which is encouraging as GSV images are more difficult to acquire and not always available.