 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Average degree of the essential variety
Dec 03, 2022
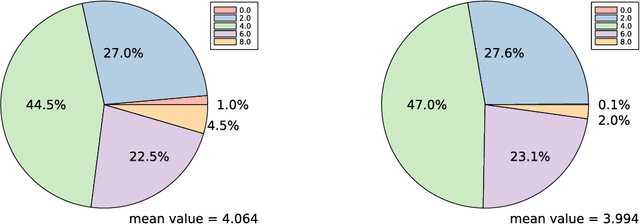
The essential variety is an algebraic subvariety of dimension $5$ in real projective space $\mathbb{R}\mathrm{P}^{8}$ which encodes the relative pose of two calibrated pinhole cameras. The $5$-point algorithm in computer vision computes the real points in the intersection of the essential variety with a linear space of codimension $5$. The degree of the essential variety is $10$, so this intersection consists of 10 complex points in general. We compute the expected number of real intersection points when the linear space is random. We focus on two probability distributions for linear spaces. The first distribution is invariant under the action of the orthogonal group $\mathrm{O}(9)$ acting on linear spaces in $\mathbb{R}\mathrm{P}^{8}$. In this case, the expected number of real intersection points is equal to $4$. The second distribution is motivated from computer vision and is defined by choosing 5 point correspondences in the image planes $\mathbb{R}\mathrm{P}^2\times \mathbb{R}\mathrm{P}^2$ uniformly at random. A Monte Carlo computation suggests that with high probability the expected value lies in the interval $(3.95 - 0.05,\ 3.95 + 0.05)$.
CRAFT: Concept Recursive Activation FacTorization for Explainability
Nov 17, 2022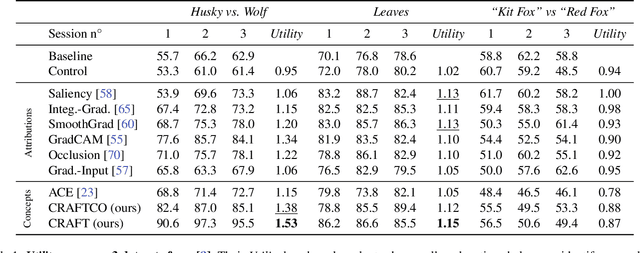

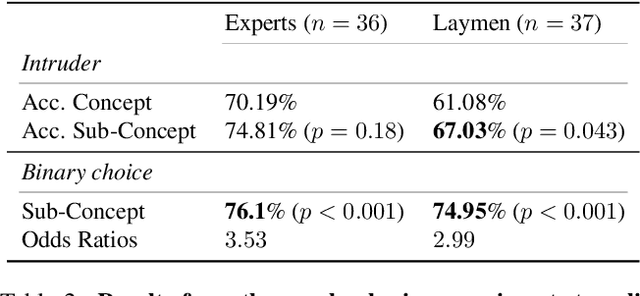
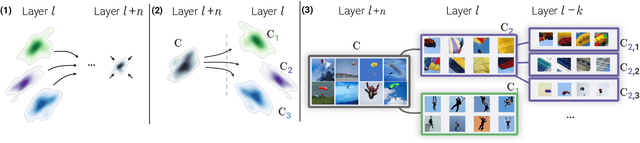
Attribution methods are a popular class of explainability methods that use heatmaps to depict the most important areas of an image that drive a model decision. Nevertheless, recent work has shown that these methods have limited utility in practice, presumably because they only highlight the most salient parts of an image (i.e., 'where' the model looked) and do not communicate any information about 'what' the model saw at those locations. In this work, we try to fill in this gap with CRAFT -- a novel approach to identify both 'what' and 'where' by generating concept-based explanations. We introduce 3 new ingredients to the automatic concept extraction literature: (i) a recursive strategy to detect and decompose concepts across layers, (ii) a novel method for a more faithful estimation of concept importance using Sobol indices, and (iii) the use of implicit differentiation to unlock Concept Attribution Maps. We conduct both human and computer vision experiments to demonstrate the benefits of the proposed approach. We show that our recursive decomposition generates meaningful and accurate concepts and that the proposed concept importance estimation technique is more faithful to the model than previous methods. When evaluating the usefulness of the method for human experimenters on a human-defined utility benchmark, we find that our approach significantly improves on two of the three test scenarios (while none of the current methods including ours help on the third). Overall, our study suggests that, while much work remains toward the development of general explainability methods that are useful in practical scenarios, the identification of meaningful concepts at the proper level of granularity yields useful and complementary information beyond that afforded by attribution methods.
A Particle-based Sparse Gaussian Process Optimizer
Nov 26, 2022
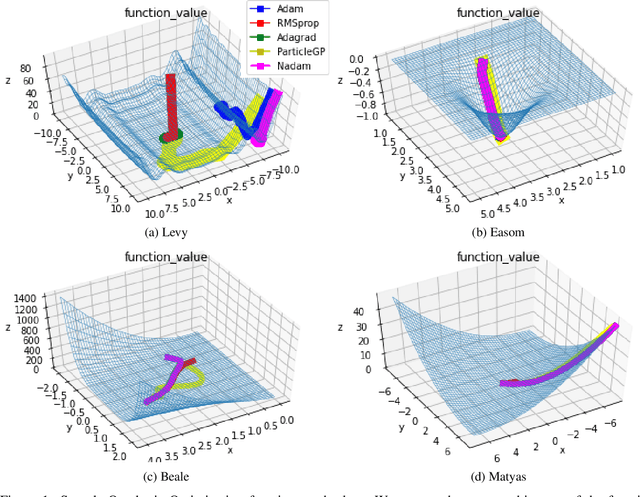

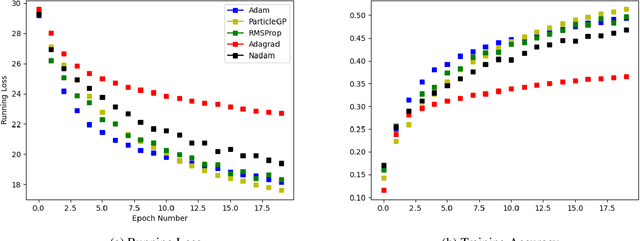
Task learning in neural networks typically requires finding a globally optimal minimizer to a loss function objective. Conventional designs of swarm based optimization methods apply a fixed update rule, with possibly an adaptive step-size for gradient descent based optimization. While these methods gain huge success in solving different optimization problems, there are some cases where these schemes are either inefficient or suffering from local-minimum. We present a new particle-swarm-based framework utilizing Gaussian Process Regression to learn the underlying dynamical process of descent. The biggest advantage of this approach is greater exploration around the current state before deciding a descent direction. Empirical results show our approach can escape from the local minima compare with the widely-used state-of-the-art optimizers when solving non-convex optimization problems. We also test our approach under high-dimensional parameter space case, namely, image classification task.
Predictive linguistic cues for fake news: a societal artificial intelligence problem
Nov 26, 2022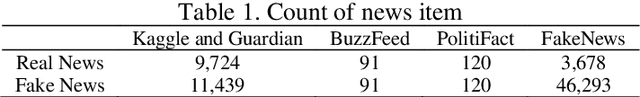

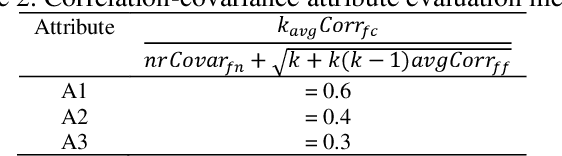

Media news are making a large part of public opinion and, therefore, must not be fake. News on web sites, blogs, and social media must be analyzed before being published. In this paper, we present linguistic characteristics of media news items to differentiate between fake news and real news using machine learning algorithms. Neural fake news generation, headlines created by machines, semantic incongruities in text and image captions generated by machine are other types of fake news problems. These problems use neural networks which mainly control distributional features rather than evidence. We propose applying correlation between features set and class, and correlation among the features to compute correlation attribute evaluation metric and covariance metric to compute variance of attributes over the news items. Features unique, negative, positive, and cardinal numbers with high values on the metrics are observed to provide a high area under the curve (AUC) and F1-score.
Analysis of convolutional neural network image classifiers in a rotationally symmetric model
May 11, 2022
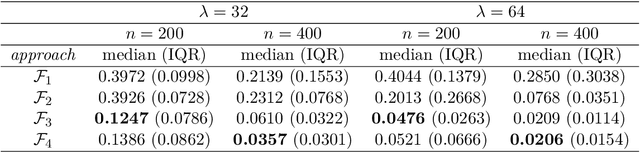
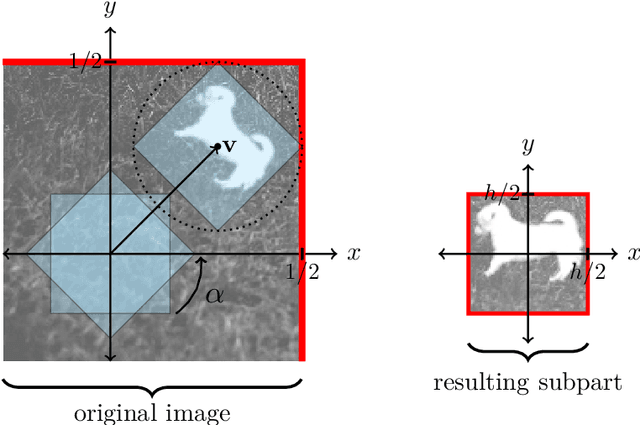
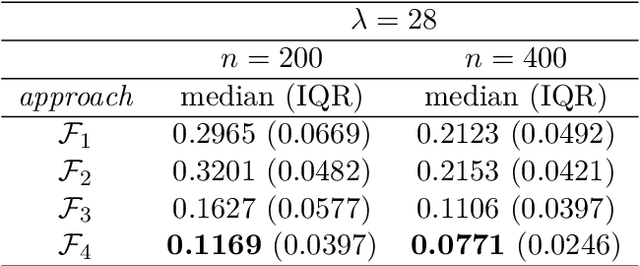
Convolutional neural network image classifiers are defined and the rate of convergence of the misclassification risk of the estimates towards the optimal misclassification risk is analyzed. Here we consider images as random variables with values in some functional space, where we only observe discrete samples as function values on some finite grid. Under suitable structural and smoothness assumptions on the functional a posteriori probability, which includes some kind of symmetry against rotation of subparts of the input image, it is shown that least squares plug-in classifiers based on convolutional neural networks are able to circumvent the curse of dimensionality in binary image classification if we neglect a resolution-dependent error term. The finite sample size behavior of the classifier is analyzed by applying it to simulated and real data.
Unsupervised Image Registration Towards Enhancing Performance and Explainability in Cardiac And Brain Image Analysis
Mar 07, 2022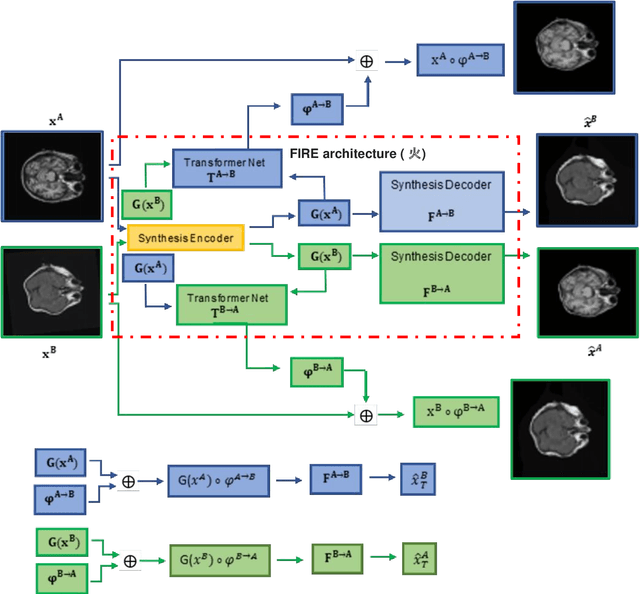
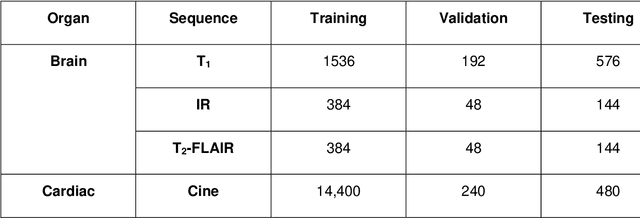
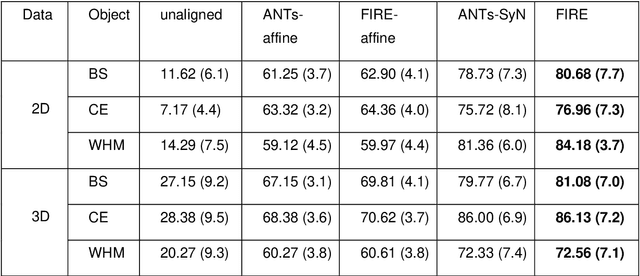
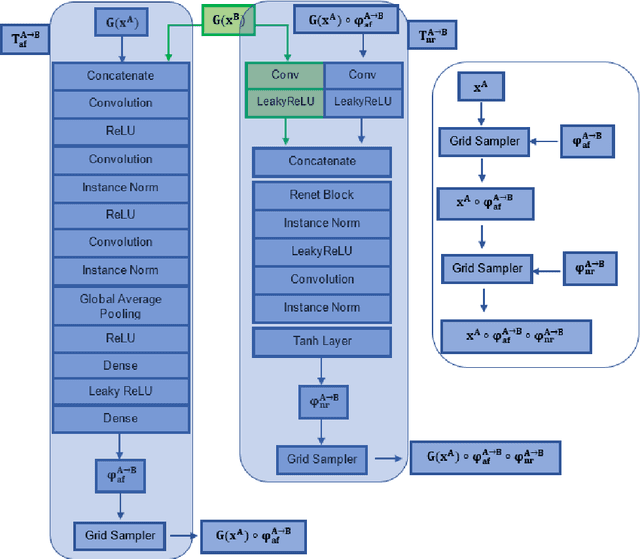
Magnetic Resonance Imaging (MRI) typically recruits multiple sequences (defined here as "modalities"). As each modality is designed to offer different anatomical and functional clinical information, there are evident disparities in the imaging content across modalities. Inter- and intra-modality affine and non-rigid image registration is an essential medical image analysis process in clinical imaging, as for example before imaging biomarkers need to be derived and clinically evaluated across different MRI modalities, time phases and slices. Although commonly needed in real clinical scenarios, affine and non-rigid image registration is not extensively investigated using a single unsupervised model architecture. In our work, we present an un-supervised deep learning registration methodology which can accurately model affine and non-rigid trans-formations, simultaneously. Moreover, inverse-consistency is a fundamental inter-modality registration property that is not considered in deep learning registration algorithms. To address inverse-consistency, our methodology performs bi-directional cross-modality image synthesis to learn modality-invariant latent rep-resentations, while involves two factorised transformation networks and an inverse-consistency loss to learn topology-preserving anatomical transformations. Overall, our model (named "FIRE") shows improved performances against the reference standard baseline method on multi-modality brain 2D and 3D MRI and intra-modality cardiac 4D MRI data experiments.
Physics-Informed Neural Networks for Material Model Calibration from Full-Field Displacement Data
Dec 15, 2022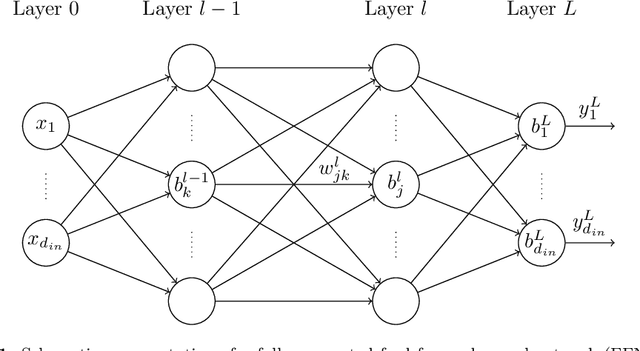
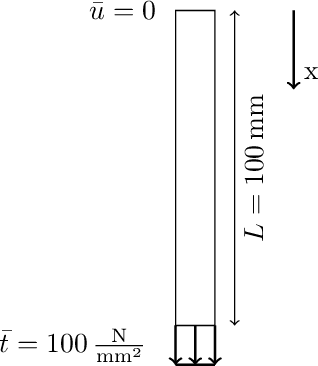
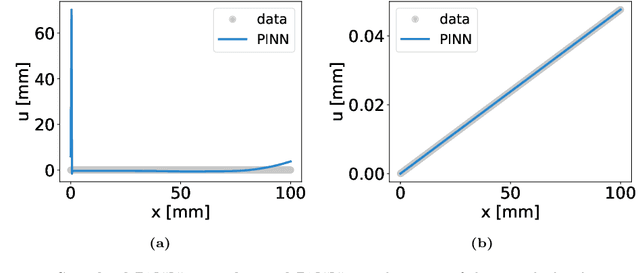
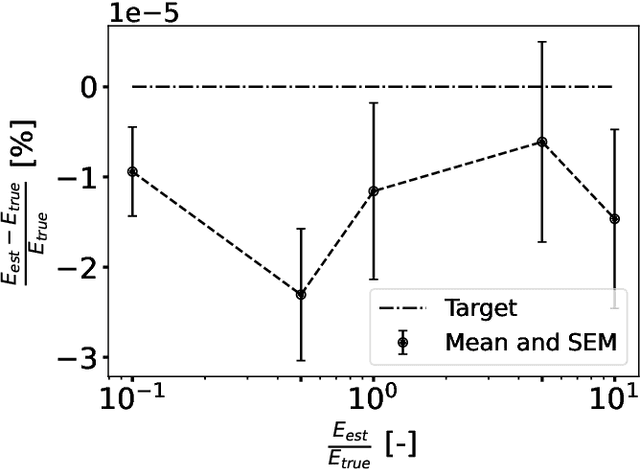
The identification of material parameters occurring in constitutive models has a wide range of applications in practice. One of these applications is the monitoring and assessment of the actual condition of infrastructure buildings, as the material parameters directly reflect the resistance of the structures to external impacts. Physics-informed neural networks (PINNs) have recently emerged as a suitable method for solving inverse problems. The advantages of this method are a straightforward inclusion of observation data. Unlike grid-based methods, such as the finite element method updating (FEMU) approach, no computational grid and no interpolation of the data is required. In the current work, we aim to further develop PINNs towards the calibration of the linear-elastic constitutive model from full-field displacement and global force data in a realistic regime. We show that normalization and conditioning of the optimization problem play a crucial role in this process. Therefore, among others, we identify the material parameters for initial estimates and balance the individual terms in the loss function. In order to reduce the dependence of the identified material parameters on local errors in the displacement approximation, we base the identification not on the stress boundary conditions but instead on the global balance of internal and external work. In addition, we found that we get a better posed inverse problem if we reformulate it in terms of bulk and shear modulus instead of Young's modulus and Poisson's ratio. We demonstrate that the enhanced PINNs are capable of identifying material parameters from both experimental one-dimensional data and synthetic full-field displacement data in a realistic regime. Since displacement data measured by, e.g., a digital image correlation (DIC) system is noisy, we additionally investigate the robustness of the method to different levels of noise.
Learning Inception Attention for Image Synthesis and Image Recognition
Dec 29, 2021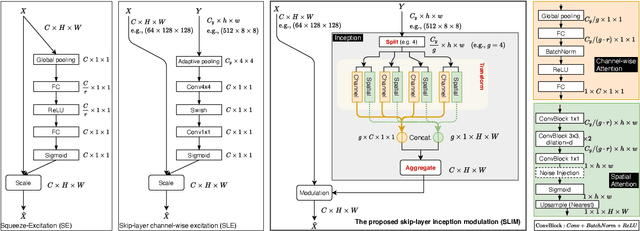

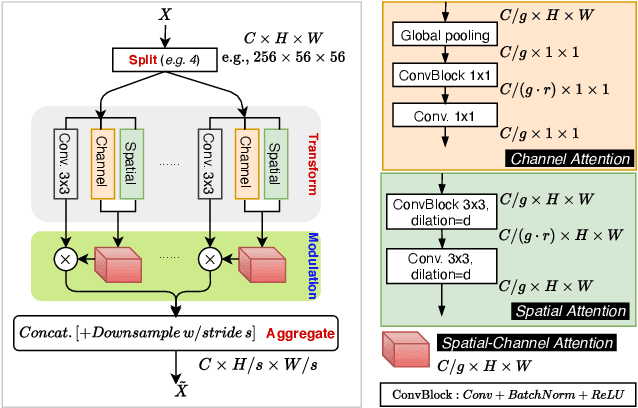

Image synthesis and image recognition have witnessed remarkable progress, but often at the expense of computationally expensive training and inference. Learning lightweight yet expressive deep model has emerged as an important and interesting direction. Inspired by the well-known split-transform-aggregate design heuristic in the Inception building block, this paper proposes a Skip-Layer Inception Module (SLIM) that facilitates efficient learning of image synthesis models, and a same-layer variant (dubbed as SLIM too) as a stronger alternative to the well-known ResNeXts for image recognition. In SLIM, the input feature map is first split into a number of groups (e.g., 4).Each group is then transformed to a latent style vector(via channel-wise attention) and a latent spatial mask (via spatial attention). The learned latent masks and latent style vectors are aggregated to modulate the target feature map. For generative learning, SLIM is built on a recently proposed lightweight Generative Adversarial Networks (i.e., FastGANs) which present a skip-layer excitation(SLE) module. For few-shot image synthesis tasks, the proposed SLIM achieves better performance than the SLE work and other related methods. For one-shot image synthesis tasks, it shows stronger capability of preserving images structures than prior arts such as the SinGANs. For image classification tasks, the proposed SLIM is used as a drop-in replacement for convolution layers in ResNets (resulting in ResNeXt-like models) and achieves better accuracy in theImageNet-1000 dataset, with significantly smaller model complexity
High-Quality Pluralistic Image Completion via Code Shared VQGAN
Apr 05, 2022
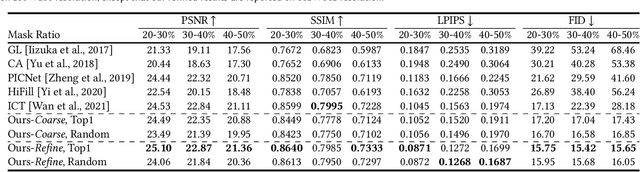


PICNet pioneered the generation of multiple and diverse results for image completion task, but it required a careful balance between $\mathcal{KL}$ loss (diversity) and reconstruction loss (quality), resulting in a limited diversity and quality . Separately, iGPT-based architecture has been employed to infer distributions in a discrete space derived from a pixel-level pre-clustered palette, which however cannot generate high-quality results directly. In this work, we present a novel framework for pluralistic image completion that can achieve both high quality and diversity at much faster inference speed. The core of our design lies in a simple yet effective code sharing mechanism that leads to a very compact yet expressive image representation in a discrete latent domain. The compactness and the richness of the representation further facilitate the subsequent deployment of a transformer to effectively learn how to composite and complete a masked image at the discrete code domain. Based on the global context well-captured by the transformer and the available visual regions, we are able to sample all tokens simultaneously, which is completely different from the prevailing autoregressive approach of iGPT-based works, and leads to more than 100$\times$ faster inference speed. Experiments show that our framework is able to learn semantically-rich discrete codes efficiently and robustly, resulting in much better image reconstruction quality. Our diverse image completion framework significantly outperforms the state-of-the-art both quantitatively and qualitatively on multiple benchmark datasets.
LW-ISP: A Lightweight Model with ISP and Deep Learning
Oct 08, 2022

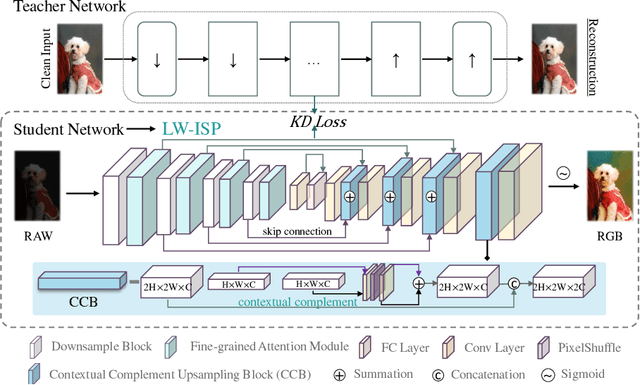

The deep learning (DL)-based methods of low-level tasks have many advantages over the traditional camera in terms of hardware prospects, error accumulation and imaging effects. Recently, the application of deep learning to replace the image signal processing (ISP) pipeline has appeared one after another; however, there is still a long way to go towards real landing. In this paper, we show the possibility of learning-based method to achieve real-time high-performance processing in the ISP pipeline. We propose LW-ISP, a novel architecture designed to implicitly learn the image mapping from RAW data to RGB image. Based on U-Net architecture, we propose the fine-grained attention module and a plug-and-play upsampling block suitable for low-level tasks. In particular, we design a heterogeneous distillation algorithm to distill the implicit features and reconstruction information of the clean image, so as to guide the learning of the student model. Our experiments demonstrate that LW-ISP has achieved a 0.38 dB improvement in PSNR compared to the previous best method, while the model parameters and calculation have been reduced by 23 times and 81 times. The inference efficiency has been accelerated by at least 15 times. Without bells and whistles, LW-ISP has achieved quite competitive results in ISP subtasks including image denoising and enhancement.