 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Vector-Valued Least-Squares Regression under Output Regularity Assumptions
Nov 16, 2022

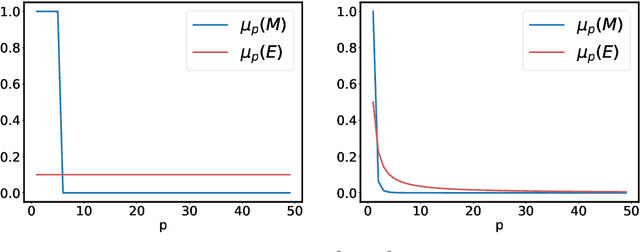
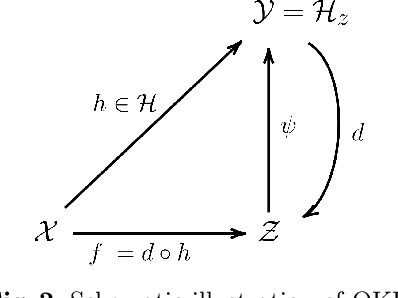

We propose and analyse a reduced-rank method for solving least-squares regression problems with infinite dimensional output. We derive learning bounds for our method, and study under which setting statistical performance is improved in comparison to full-rank method. Our analysis extends the interest of reduced-rank regression beyond the standard low-rank setting to more general output regularity assumptions. We illustrate our theoretical insights on synthetic least-squares problems. Then, we propose a surrogate structured prediction method derived from this reduced-rank method. We assess its benefits on three different problems: image reconstruction, multi-label classification, and metabolite identification.
3D-Aware Object Goal Navigation via Simultaneous Exploration and Identification
Dec 01, 2022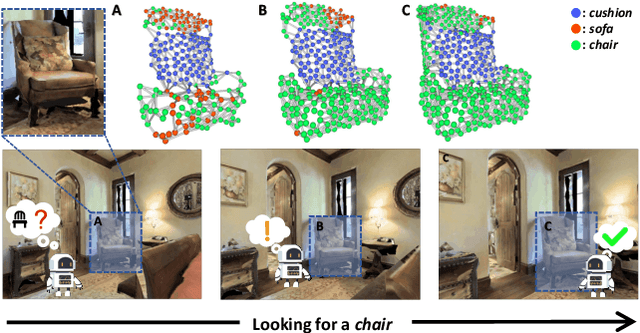
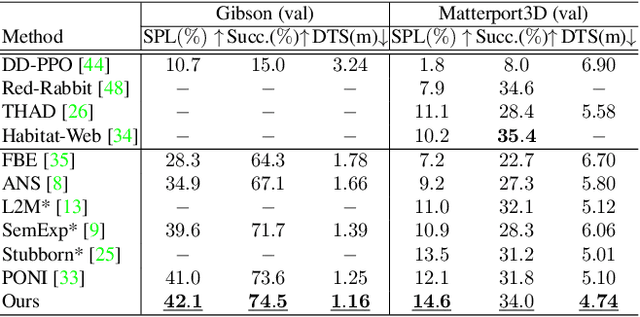
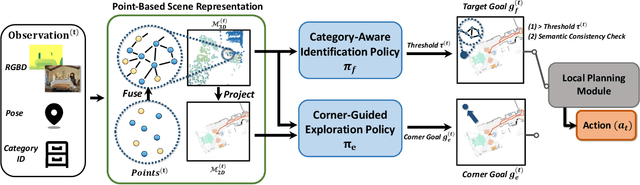
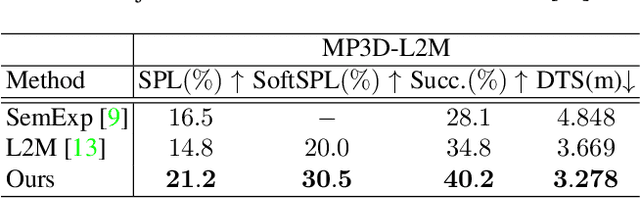
Object goal navigation (ObjectNav) in unseen environments is a fundamental task for Embodied AI. Agents in existing works learn ObjectNav policies based on 2D maps, scene graphs, or image sequences. Considering this task happens in 3D space, a 3D-aware agent can advance its ObjectNav capability via learning from fine-grained spatial information. However, leveraging 3D scene representation can be prohibitively unpractical for policy learning in this floor-level task, due to low sample efficiency and expensive computational cost. In this work, we propose a framework for the challenging 3D-aware ObjectNav based on two straightforward sub-policies. The two sub-polices, namely corner-guided exploration policy and category-aware identification policy, simultaneously perform by utilizing online fused 3D points as observation. Through extensive experiments, we show that this framework can dramatically improve the performance in ObjectNav through learning from 3D scene representation. Our framework achieves the best performance among all modular-based methods on the Matterport3D and Gibson datasets, while requiring (up to 30x) less computational cost for training.
Implicit Mixture of Interpretable Experts for Global and Local Interpretability
Dec 01, 2022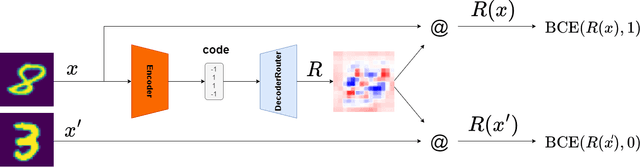
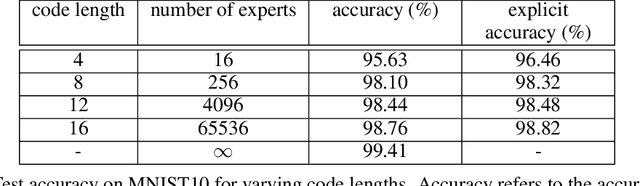
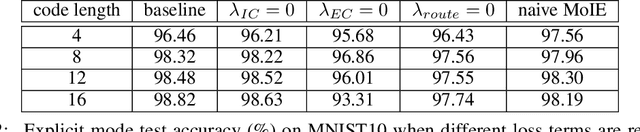
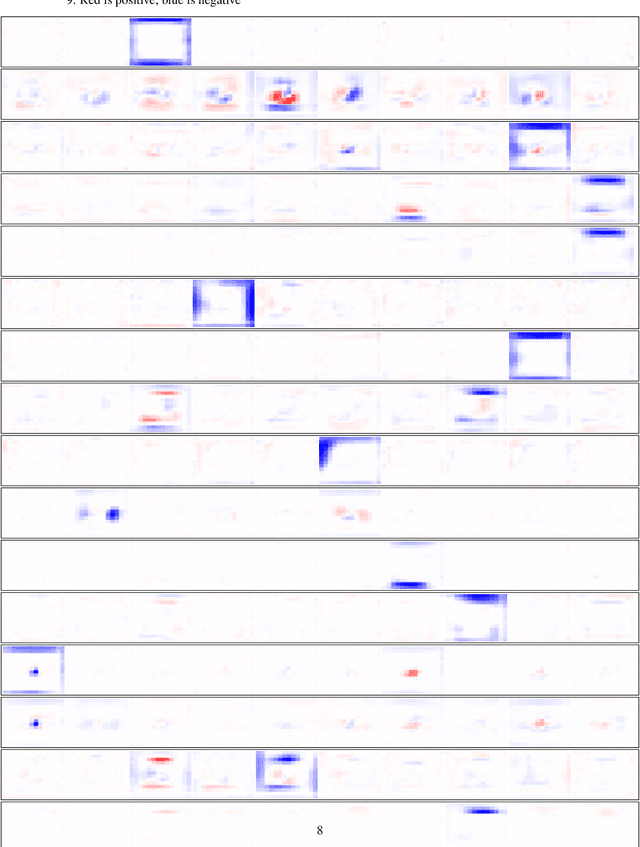
We investigate the feasibility of using mixtures of interpretable experts (MoIE) to build interpretable image classifiers on MNIST10. MoIE uses a black-box router to assign each input to one of many inherently interpretable experts, thereby providing insight into why a particular classification decision was made. We find that a naively trained MoIE will learn to 'cheat', whereby the black-box router will solve the classification problem by itself, with each expert simply learning a constant function for one particular class. We propose to solve this problem by introducing interpretable routers and training the black-box router's decisions to match the interpretable router. In addition, we propose a novel implicit parameterization scheme that allows us to build mixtures of arbitrary numbers of experts, allowing us to study how classification performance, local and global interpretability vary as the number of experts is increased. Our new model, dubbed Implicit Mixture of Interpretable Experts (IMoIE) can match state-of-the-art classification accuracy on MNIST10 while providing local interpretability, and can provide global interpretability albeit at the cost of reduced classification accuracy.
A novel TomoSAR imaging method with few observations based on nested array
Dec 01, 2022
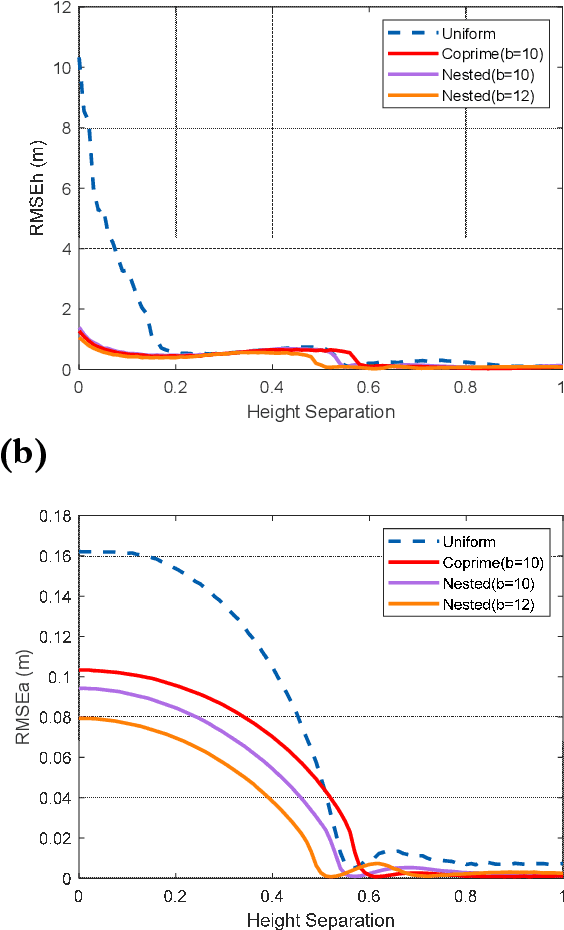
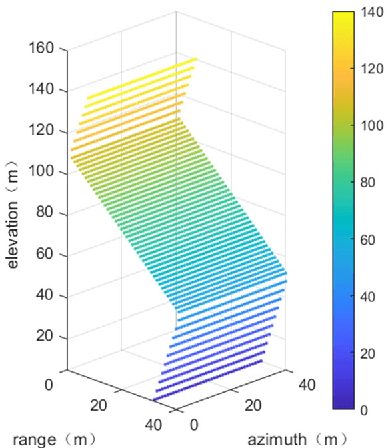
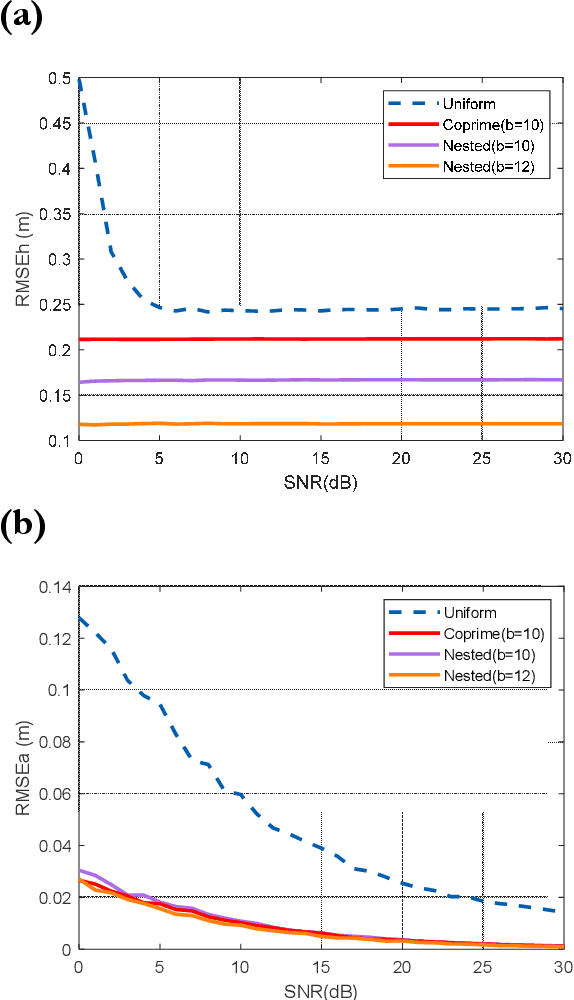
Synthetic aperture radar tomography (TomoSAR) baseline optimization technique is capable of reducing system complexity and improving the temporal coherence of data, which has become an important research in the field of TomoSAR. In this paper, we propose a nested TomoSAR technique, which introduces the nested array into TomoSAR as the baseline configuration. This technique obtains uniform and continuous difference co-array through nested array to increase the degrees of freedom (DoF) of the system and expands the virtual aperture along the elevation direction. In order to make full use of the difference co-array, covariance matrix of the echo needs to be obtained. Therefore, we propose a TomoSAR sparse reconstruction algorithm based on nested array, which uses adaptive covariance matrix estimation to improve the estimation performance in complex scenes. We demonstrate the effectiveness of the proposed method through simulated and real data experiments. Compared with traditional TomoSAR and coprime TomoSAR, the imaging results of our proposed method have a better anti-noise performance and retain more image information.
From CNNs to Shift-Invariant Twin Wavelet Models
Dec 01, 2022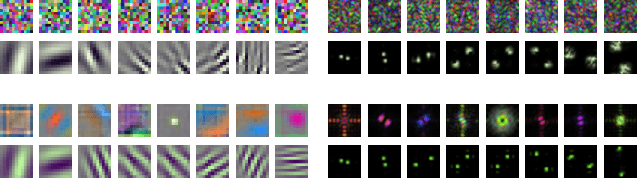

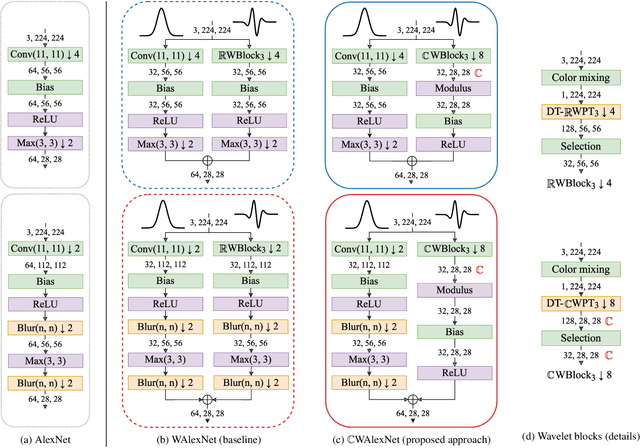
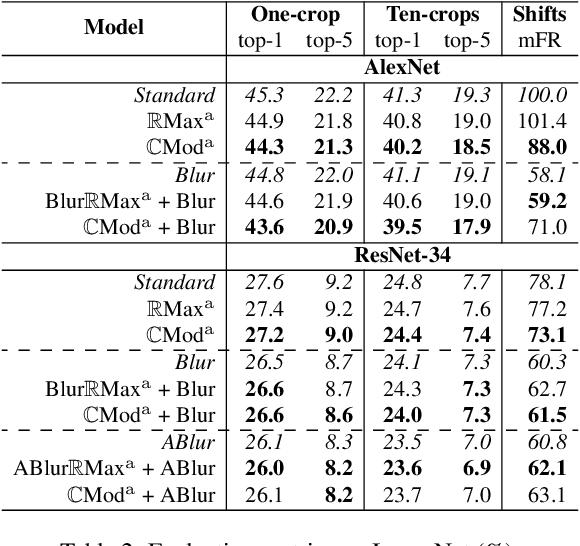
We propose a novel antialiasing method to increase shift invariance in convolutional neural networks (CNNs). More precisely, we replace the conventional combination "real-valued convolutions + max pooling" ($\mathbb R$Max) by "complex-valued convolutions + modulus" ($\mathbb C$Mod), which produce stable feature representations for band-pass filters with well-defined orientations. In a recent work, we proved that, for such filters, the two operators yield similar outputs. Therefore, $\mathbb C$Mod can be viewed as a stable alternative to $\mathbb R$Max. To separate band-pass filters from other freely-trained kernels, in this paper, we designed a "twin" architecture based on the dual-tree complex wavelet packet transform, which generates similar outputs as standard CNNs with fewer trainable parameters. In addition to improving stability to small shifts, our experiments on AlexNet and ResNet showed increased prediction accuracy on natural image datasets such as ImageNet and CIFAR10. Furthermore, our approach outperformed recent antialiasing methods based on low-pass filtering by preserving high-frequency information, while reducing memory usage.
Patch DCT vs LeNet
Nov 04, 2022
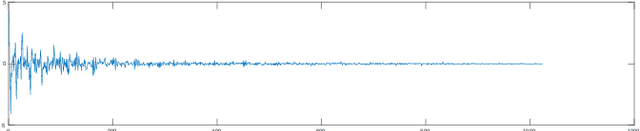

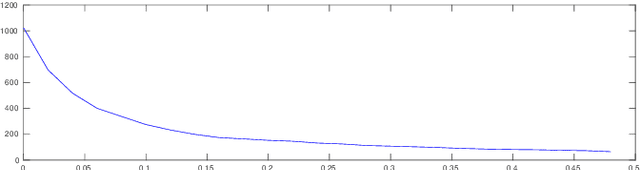
This paper compares the performance of a NN taking the output of a DCT (Discrete Cosine Transform) of an image patch with leNet for classifying MNIST hand written digits. The basis functions underlying the DCT bear a passing resemblance to some of the learned basis function of the Visual Transformer but are an order of magnitude faster to apply.
Enabling and Accelerating Dynamic Vision Transformer Inference for Real-Time Applications
Dec 06, 2022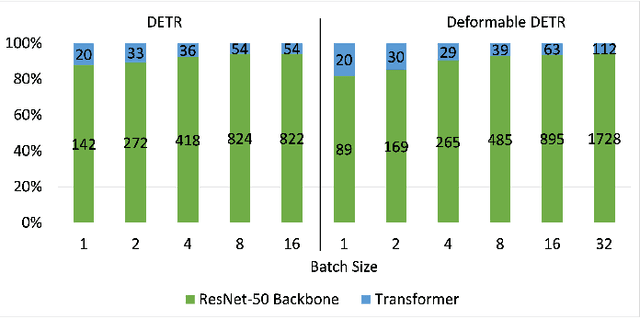
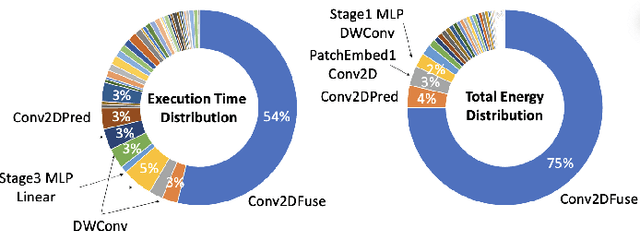
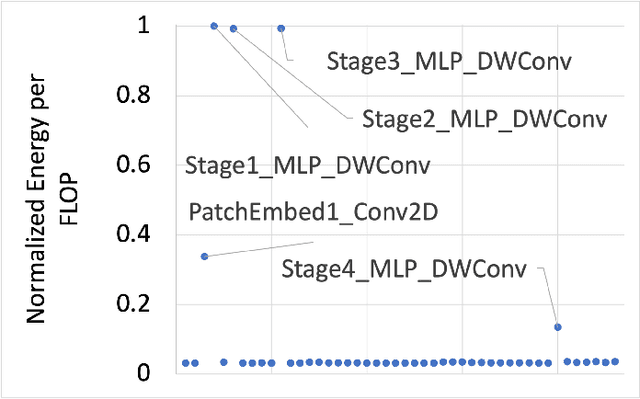
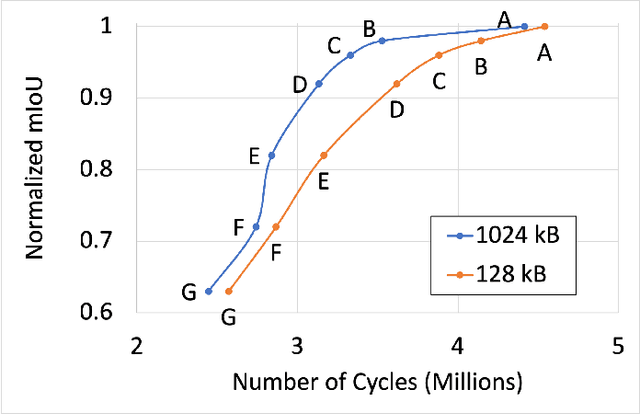
Many state-of-the-art deep learning models for computer vision tasks are based on the transformer architecture. Such models can be computationally expensive and are typically statically set to meet the deployment scenario. However, in real-time applications, the resources available for every inference can vary considerably and be smaller than what state-of-the-art models use. We can use dynamic models to adapt the model execution to meet real-time application resource constraints. While prior dynamic work has primarily minimized resource utilization for less complex input images while maintaining accuracy and focused on CNNs and early transformer models such as BERT, we adapt vision transformers to meet system dynamic resource constraints, independent of the input image. We find that unlike early transformer models, recent state-of-the-art vision transformers heavily rely on convolution layers. We show that pretrained models are fairly resilient to skipping computation in the convolution and self-attention layers, enabling us to create a low-overhead system for dynamic real-time inference without additional training. Finally, we create a optimized accelerator for these dynamic vision transformers in a 5nm technology. The PE array occupies 2.26mm$^2$ and is 17 times faster than a NVIDIA TITAN V GPU for state-of-the-art transformer-based models for semantic segmentation.
Semantic Communication for Internet of Vehicles: A Multi-User Cooperative Approach
Dec 06, 2022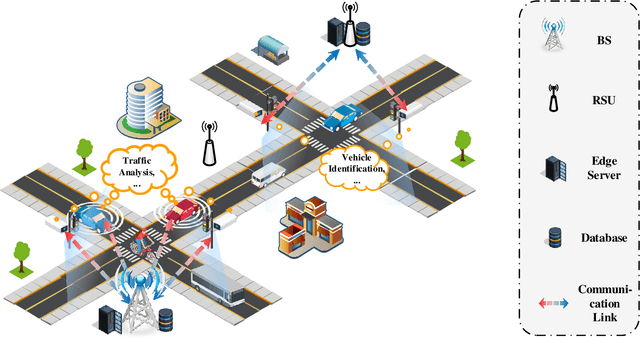
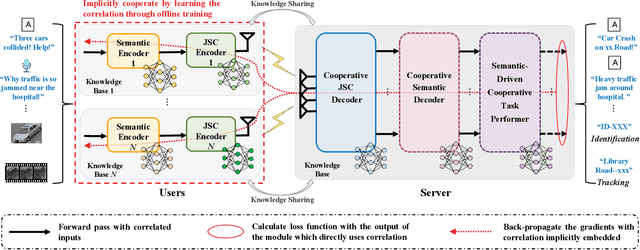
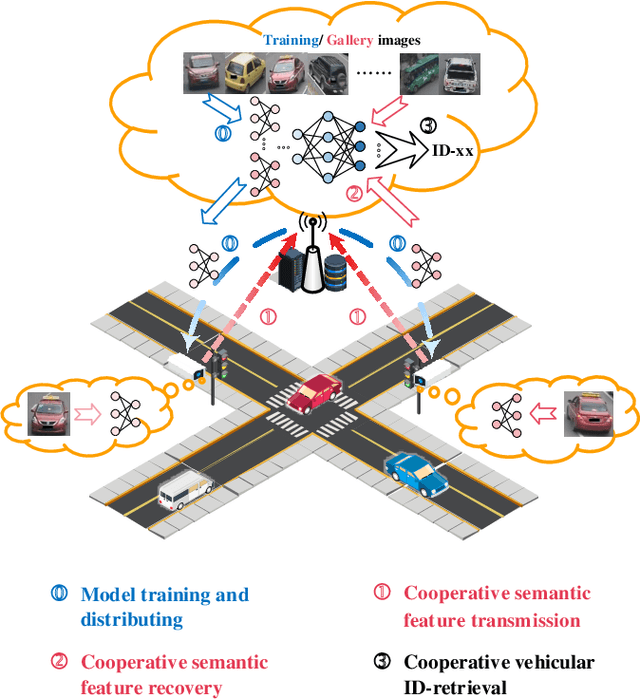
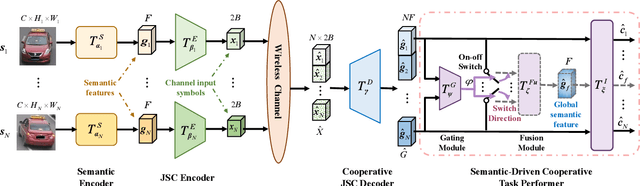
Internet of Vehicles (IoV) is expected to become the central infrastructure to provide advanced services to connected vehicles and users for higher transportation efficiency and security. A variety of emerging applications/services bring explosively growing demands for mobile data traffic between connected vehicles and roadside units (RSU), imposing the significant challenge of spectrum scarcity to IoV. In this paper, we propose a cooperative semantic-aware architecture to convey essential semantics from collaborated users to servers for lowering the data traffic. In contrast to current solutions that are mainly based on piling up highly complex signal processing techniques and multiple access capabilities in terms of syntactic communications, this paper puts forth the idea of semantic-aware content delivery in IoV. Specifically, the successful transmission of essential semantics of the source data is pursued, rather than the accurate reception of symbols regardless of its meaning as in conventional syntactic communications. To assess the benefits of the proposed architecture, we provide a case study of the image retrieval task for vehicles in intelligent transportation systems. Simulation results demonstrate that the proposed architecture outperforms the existing solutions with fewer radio resources, especially in a low signal-to-noise-ratio (SNR) regime, which can shed light on the potential of the proposed architecture in extending the applications in extreme environments.
One-shot recognition of any material anywhere using contrastive learning with physics-based rendering
Dec 14, 2022
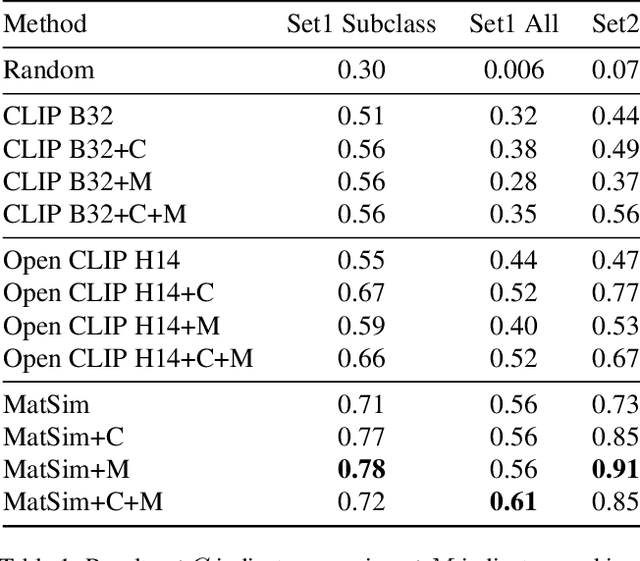

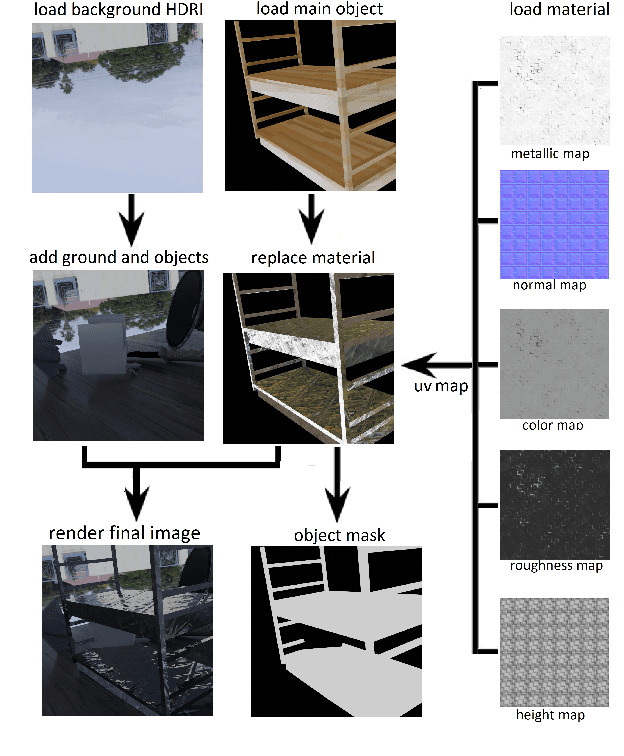
We present MatSim: a synthetic dataset, a benchmark, and a method for computer vision based recognition of similarities and transitions between materials and textures, focusing on identifying any material under any conditions using one or a few examples (one-shot learning). The visual recognition of materials is essential to everything from examining food while cooking to inspecting agriculture, chemistry, and industrial products. In this work, we utilize giant repositories used by computer graphics artists to generate a new CGI dataset for material similarity. We use physics-based rendering (PBR) repositories for visual material simulation, assign these materials random 3D objects, and render images with a vast range of backgrounds and illumination conditions (HDRI). We add a gradual transition between materials to support applications with a smooth transition between states (like gradually cooked food). We also render materials inside transparent containers to support beverage and chemistry lab use cases. We then train a contrastive learning network to generate a descriptor that identifies unfamiliar materials using a single image. We also present a new benchmark for a few-shot material recognition that contains a wide range of real-world examples, including the state of a chemical reaction, rotten/fresh fruits, states of food, different types of construction materials, types of ground, and many other use cases involving material states, transitions and subclasses. We show that a network trained on the MatSim synthetic dataset outperforms state-of-the-art models like Clip on the benchmark, despite being tested on material classes that were not seen during training. The dataset, benchmark, code and trained models are available online.
OpenScene: 3D Scene Understanding with Open Vocabularies
Nov 28, 2022
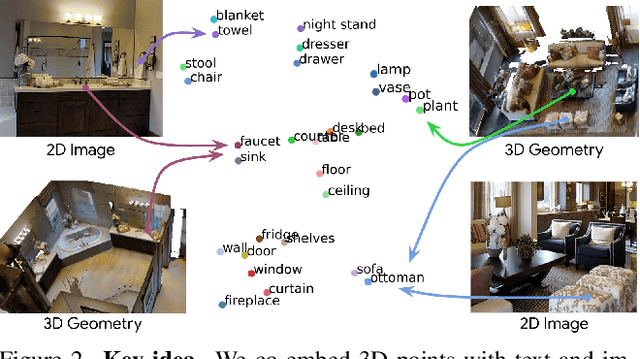
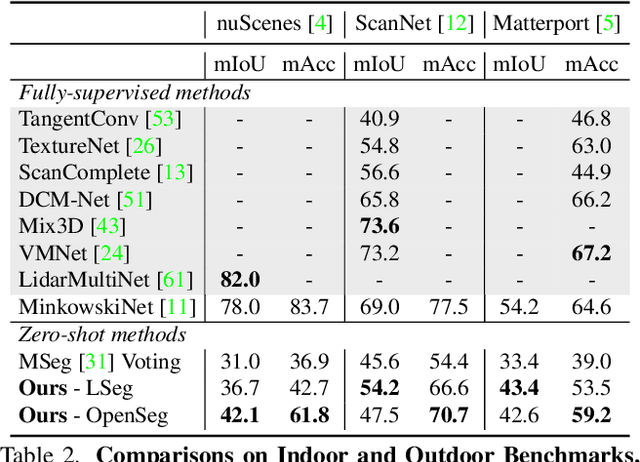
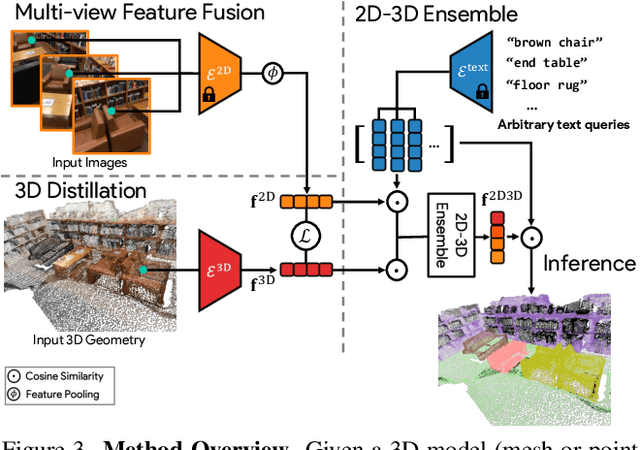
Traditional 3D scene understanding approaches rely on labeled 3D datasets to train a model for a single task with supervision. We propose OpenScene, an alternative approach where a model predicts dense features for 3D scene points that are co-embedded with text and image pixels in CLIP feature space. This zero-shot approach enables task-agnostic training and open-vocabulary queries. For example, to perform SOTA zero-shot 3D semantic segmentation it first infers CLIP features for every 3D point and later classifies them based on similarities to embeddings of arbitrary class labels. More interestingly, it enables a suite of open-vocabulary scene understanding applications that have never been done before. For example, it allows a user to enter an arbitrary text query and then see a heat map indicating which parts of a scene match. Our approach is effective at identifying objects, materials, affordances, activities, and room types in complex 3D scenes, all using a single model trained without any labeled 3D data.