 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interpretable Diabetic Retinopathy Diagnosis based on Biomarker Activation Map
Dec 13, 2022
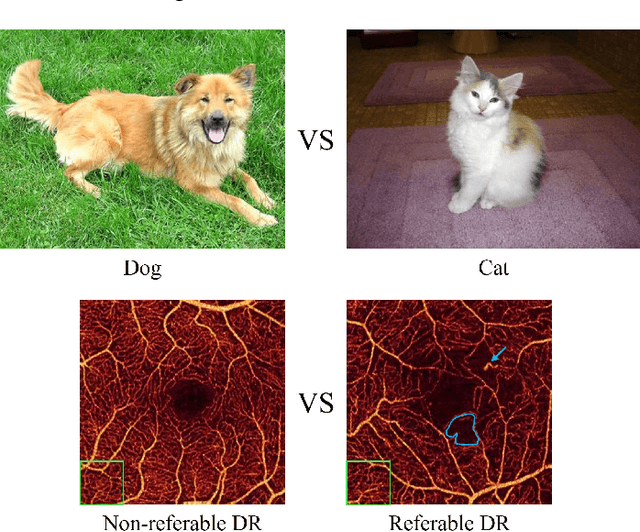
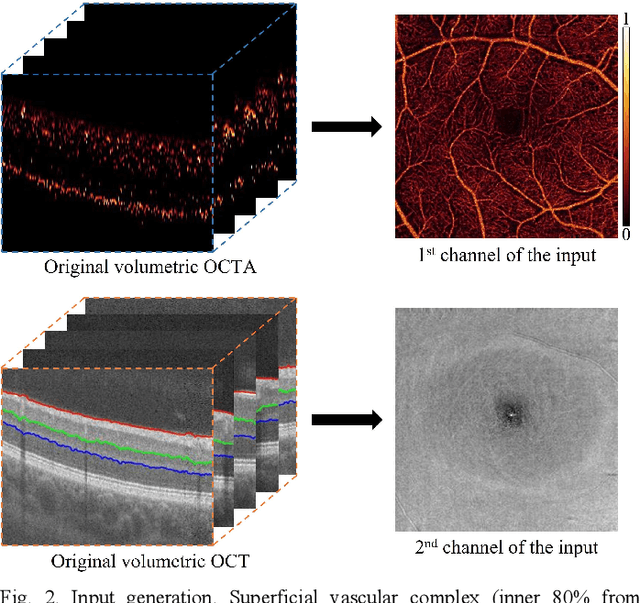
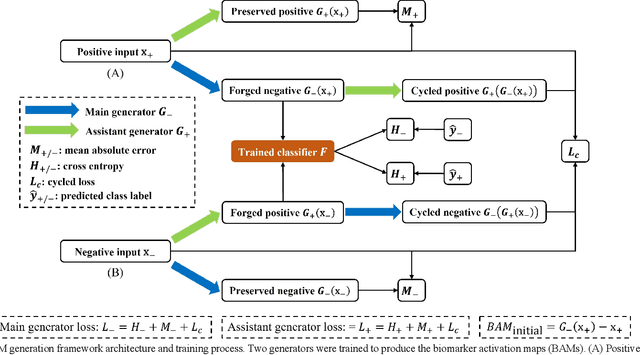
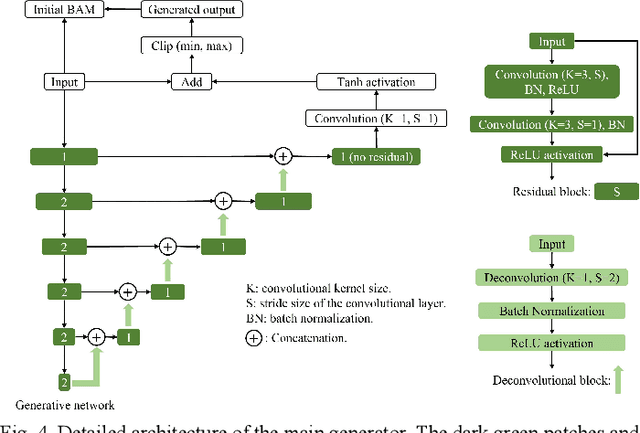
Deep learning classifiers provide the most accurate means of automatically diagnosing diabetic retinopathy (DR) based on optical coherence tomography (OCT) and its angiography (OCTA). The power of these models is attributable in part to the inclusion of hidden layers that provide the complexity required to achieve a desired task. However, hidden layers also render algorithm outputs difficult to interpret. Here we introduce a novel biomarker activation map (BAM) framework based on generative adversarial learning that allows clinicians to verify and understand classifiers decision-making. A data set including 456 macular scans were graded as non-referable or referable DR based on current clinical standards. A DR classifier that was used to evaluate our BAM was first trained based on this data set. The BAM generation framework was designed by combing two U-shaped generators to provide meaningful interpretability to this classifier. The main generator was trained to take referable scans as input and produce an output that would be classified by the classifier as non-referable. The BAM is then constructed as the difference image between the output and input of the main generator. To ensure that the BAM only highlights classifier-utilized biomarkers an assistant generator was trained to do the opposite, producing scans that would be classified as referable by the classifier from non-referable scans. The generated BAMs highlighted known pathologic features including nonperfusion area and retinal fluid. A fully interpretable classifier based on these highlights could help clinicians better utilize and verify automated DR diagnosis.
IMAGINE: An Integrated Model of Artificial Intelligence-Mediated Communication Effects
Dec 13, 2022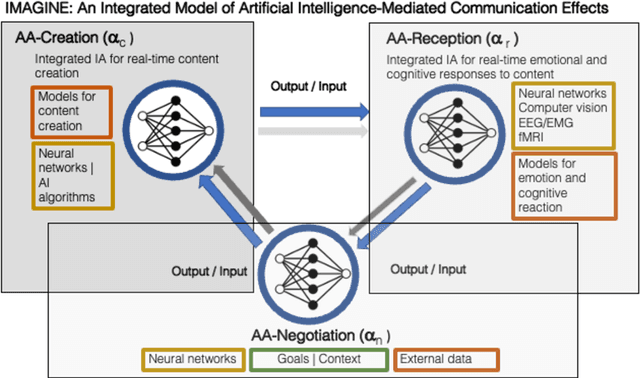


Artificial Intelligence (AI) is transforming all fields of knowledge and production. From surgery, autonomous driving, to image and video creation, AI seems to make possible hitherto unimaginable processes of automation and efficient creation. Media and communication are not an exception, and we are currently witnessing the dawn of powerful AI tools capable of creating artistic images from simple keywords, or to capture emotions from facial expression. These examples may be only the beginning of what can be in the future the engines for automatic AI real time creation of media content linked to the emotional and behavioural responses of individuals. Although it may seem we are still far from there, it is already the moment to adapt our theories about media to the hypothetical scenario in which content production can be done without human intervention, and governed by the controlled any reactions of the individual to the exposure to media content. Following that, I propose the definition of the Integrated Model of Artificial Intelligence-Mediated Communication Effects (IMAGINE), and its consequences on the way we understand media evolution (Scolari, 2012) and we think about media effects (Potter, 2010). The conceptual framework proposed is aimed to help scholars theorizing and doing research in a scenario of continuous real-time connection between AI measurement of people's responses to media, and the AI creation of content, with the objective of optimizing and maximizing the processes of influence. Parasocial interaction and real-time beautification are used as examples to model the functioning of the IMAGINE process.
Regularized Optimal Transport Layers for Generalized Global Pooling Operations
Dec 13, 2022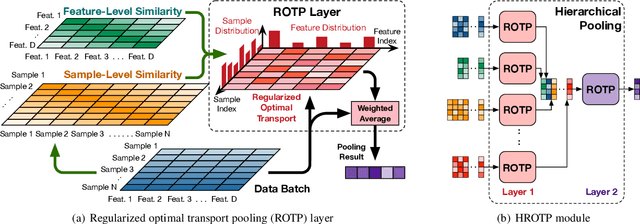
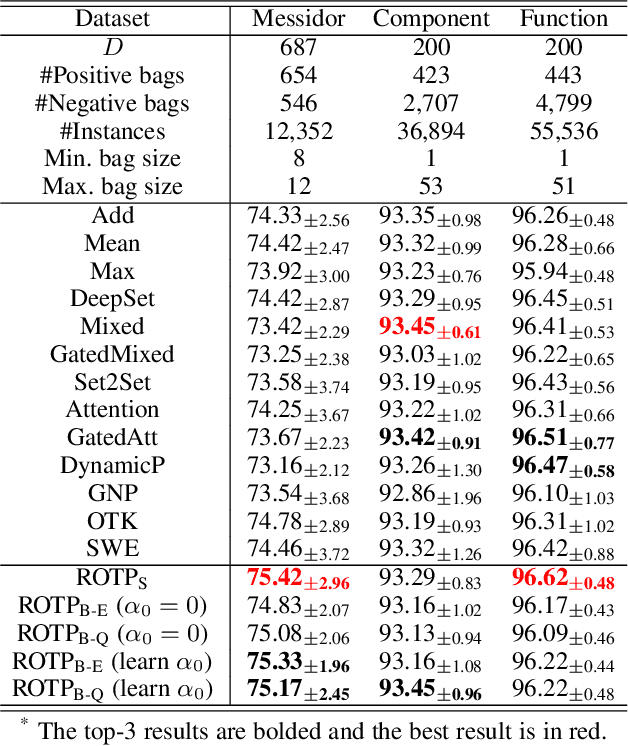
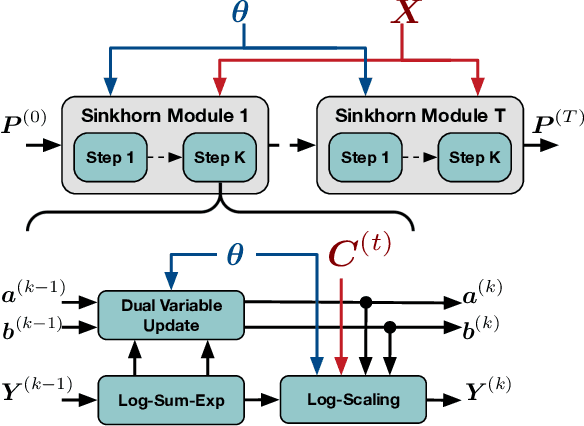
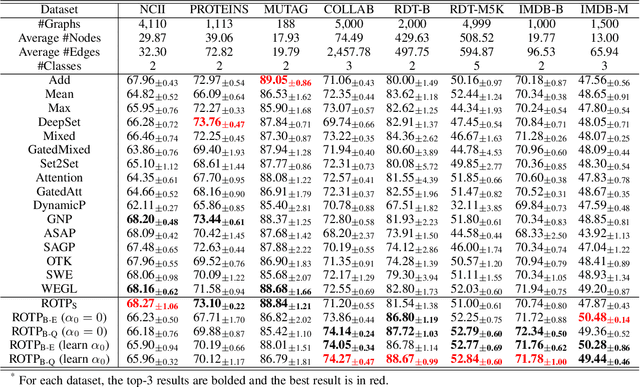
Global pooling is one of the most significant operations in many machine learning models and tasks, which works for information fusion and structured data (like sets and graphs) representation. However, without solid mathematical fundamentals, its practical implementations often depend on empirical mechanisms and thus lead to sub-optimal, even unsatisfactory performance. In this work, we develop a novel and generalized global pooling framework through the lens of optimal transport. The proposed framework is interpretable from the perspective of expectation-maximization. Essentially, it aims at learning an optimal transport across sample indices and feature dimensions, making the corresponding pooling operation maximize the conditional expectation of input data. We demonstrate that most existing pooling methods are equivalent to solving a regularized optimal transport (ROT) problem with different specializations, and more sophisticated pooling operations can be implemented by hierarchically solving multiple ROT problems. Making the parameters of the ROT problem learnable, we develop a family of regularized optimal transport pooling (ROTP) layers. We implement the ROTP layers as a new kind of deep implicit layer. Their model architectures correspond to different optimization algorithms. We test our ROTP layers in several representative set-level machine learning scenarios, including multi-instance learning (MIL), graph classification, graph set representation, and image classification. Experimental results show that applying our ROTP layers can reduce the difficulty of the design and selection of global pooling -- our ROTP layers may either imitate some existing global pooling methods or lead to some new pooling layers fitting data better. The code is available at \url{https://github.com/SDS-Lab/ROT-Pooling}.
Adversarial Attacks and Defences for Skin Cancer Classification
Dec 13, 2022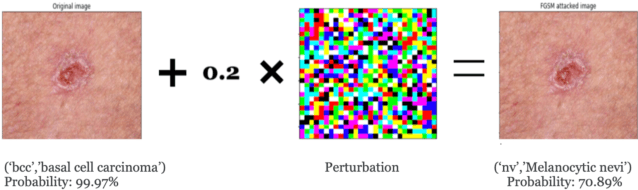


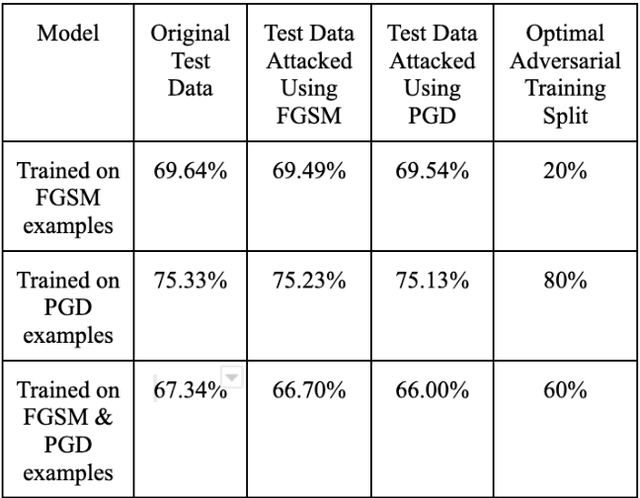
There has been a concurrent significant improvement in the medical images used to facilitate diagnosis and the performance of machine learning techniques to perform tasks such as classification, detection, and segmentation in recent years. As a result, a rapid increase in the usage of such systems can be observed in the healthcare industry, for instance in the form of medical image classification systems, where these models have achieved diagnostic parity with human physicians. One such application where this can be observed is in computer vision tasks such as the classification of skin lesions in dermatoscopic images. However, as stakeholders in the healthcare industry, such as insurance companies, continue to invest extensively in machine learning infrastructure, it becomes increasingly important to understand the vulnerabilities in such systems. Due to the highly critical nature of the tasks being carried out by these machine learning models, it is necessary to analyze techniques that could be used to take advantage of these vulnerabilities and methods to defend against them. This paper explores common adversarial attack techniques. The Fast Sign Gradient Method and Projected Descent Gradient are used against a Convolutional Neural Network trained to classify dermatoscopic images of skin lesions. Following that, it also discusses one of the most popular adversarial defense techniques, adversarial training. The performance of the model that has been trained on adversarial examples is then tested against the previously mentioned attacks, and recommendations to improve neural networks robustness are thus provided based on the results of the experiment.
A Targeted Sampling Strategy for Compressive Cryo Focused Ion Beam Scanning Electron Microscopy
Nov 07, 2022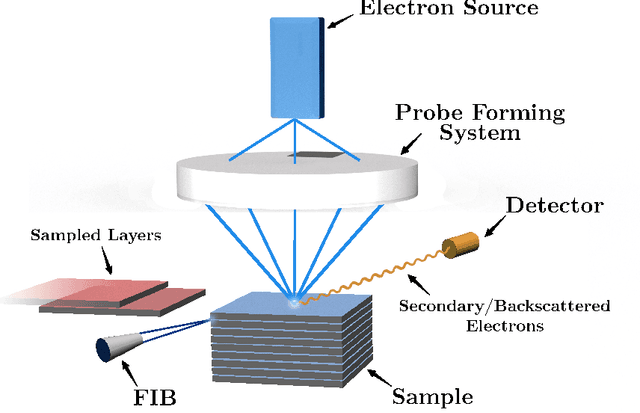
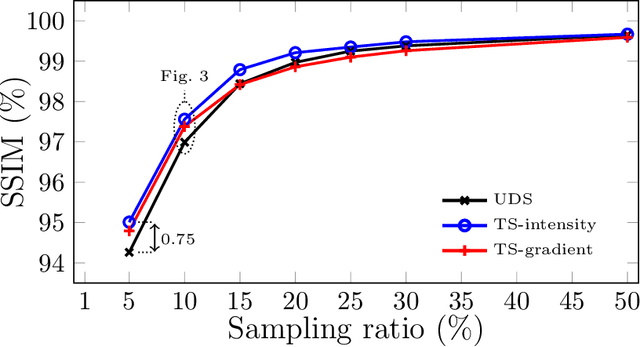

Cryo Focused Ion-Beam Scanning Electron Microscopy (cryo FIB-SEM) enables three-dimensional and nanoscale imaging of biological specimens via a slice and view mechanism. The FIB-SEM experiments are, however, limited by a slow (typically, several hours) acquisition process and the high electron doses imposed on the beam sensitive specimen can cause damage. In this work, we present a compressive sensing variant of cryo FIB-SEM capable of reducing the operational electron dose and increasing speed. We propose two Targeted Sampling (TS) strategies that leverage the reconstructed image of the previous sample layer as a prior for designing the next subsampling mask. Our image recovery is based on a blind Bayesian dictionary learning approach, i.e., Beta Process Factor Analysis (BPFA). This method is experimentally viable due to our ultra-fast GPU-based implementation of BPFA. Simulations on artificial compressive FIB-SEM measurements validate the success of proposed methods: the operational electron dose can be reduced by up to 20 times. These methods have large implications for the cryo FIB-SEM community, in which the imaging of beam sensitive biological materials without beam damage is crucial.
Towards Understanding and Boosting Adversarial Transferability from a Distribution Perspective
Oct 09, 2022
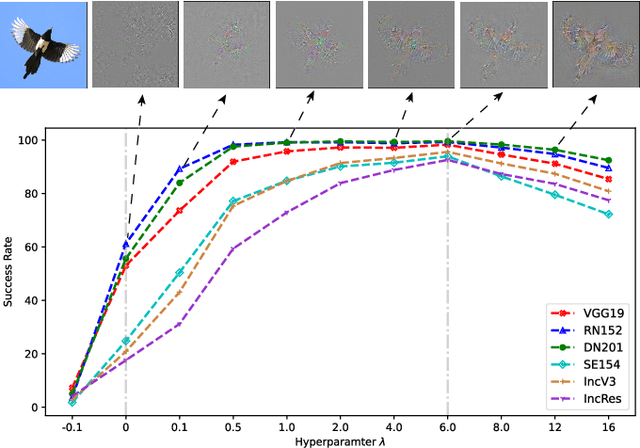
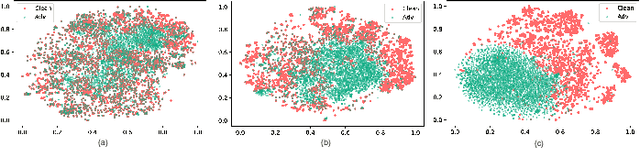
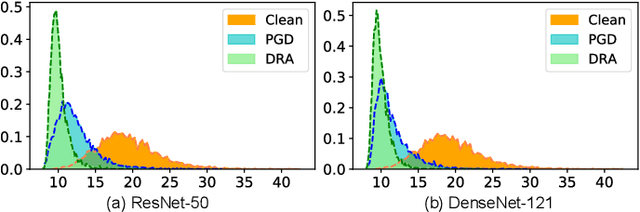
Transferable adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective, e.g., decision boundary, model architecture, and model capacity. adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective. Here, we investigate the transferability from the data distribution perspective and hypothesize that pushing the image away from its original distribution can enhance the adversarial transferability. To be specific, moving the image out of its original distribution makes different models hardly classify the image correctly, which benefits the untargeted attack, and dragging the image into the target distribution misleads the models to classify the image as the target class, which benefits the targeted attack. Towards this end, we propose a novel method that crafts adversarial examples by manipulating the distribution of the image. We conduct comprehensive transferable attacks against multiple DNNs to demonstrate the effectiveness of the proposed method. Our method can significantly improve the transferability of the crafted attacks and achieves state-of-the-art performance in both untargeted and targeted scenarios, surpassing the previous best method by up to 40$\%$ in some cases.
Invertible Rescaling Network and Its Extensions
Oct 09, 2022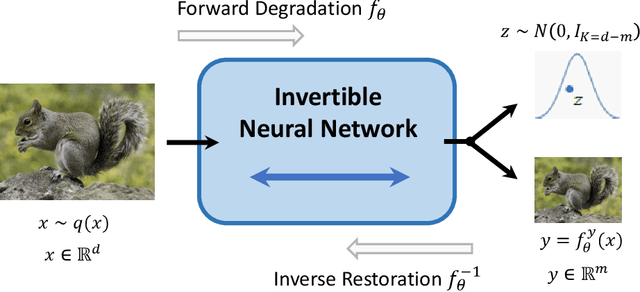
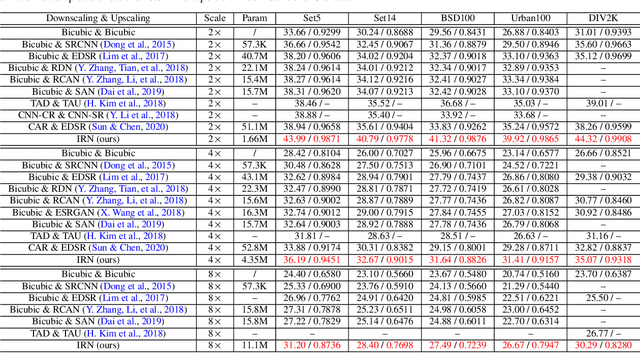
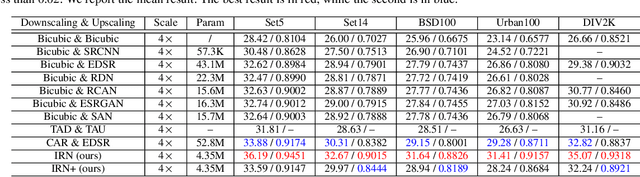
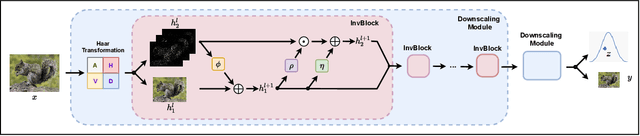
Image rescaling is a commonly used bidirectional operation, which first downscales high-resolution images to fit various display screens or to be storage- and bandwidth-friendly, and afterward upscales the corresponding low-resolution images to recover the original resolution or the details in the zoom-in images. However, the non-injective downscaling mapping discards high-frequency contents, leading to the ill-posed problem for the inverse restoration task. This can be abstracted as a general image degradation-restoration problem with information loss. In this work, we propose a novel invertible framework to handle this general problem, which models the bidirectional degradation and restoration from a new perspective, i.e. invertible bijective transformation. The invertibility enables the framework to model the information loss of pre-degradation in the form of distribution, which could mitigate the ill-posed problem during post-restoration. To be specific, we develop invertible models to generate valid degraded images and meanwhile transform the distribution of lost contents to the fixed distribution of a latent variable during the forward degradation. Then restoration is made tractable by applying the inverse transformation on the generated degraded image together with a randomly-drawn latent variable. We start from image rescaling and instantiate the model as Invertible Rescaling Network (IRN), which can be easily extended to the similar decolorization-colorization task. We further propose to combine the invertible framework with existing degradation methods such as image compression for wider applications. Experimental results demonstrate the significant improvement of our model over existing methods in terms of both quantitative and qualitative evaluations of upscaling and colorizing reconstruction from downscaled and decolorized images, and rate-distortion of image compression.
Concurrent Neural Tree and Data Preprocessing AutoML for Image Classification
May 25, 2022
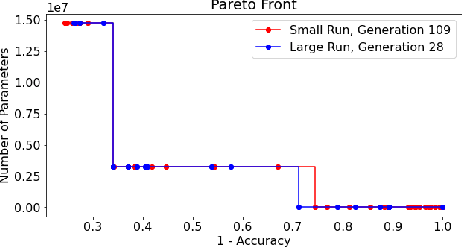

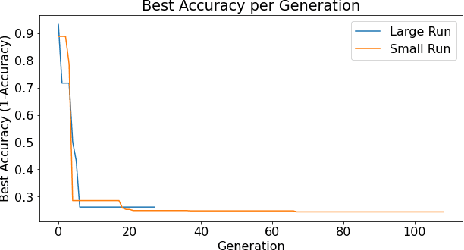
Deep Neural Networks (DNN's) are a widely-used solution for a variety of machine learning problems. However, it is often necessary to invest a significant amount of a data scientist's time to pre-process input data, test different neural network architectures, and tune hyper-parameters for optimal performance. Automated machine learning (autoML) methods automatically search the architecture and hyper-parameter space for optimal neural networks. However, current state-of-the-art (SOTA) methods do not include traditional methods for manipulating input data as part of the algorithmic search space. We adapt the Evolutionary Multi-objective Algorithm Design Engine (EMADE), a multi-objective evolutionary search framework for traditional machine learning methods, to perform neural architecture search. We also integrate EMADE's signal processing and image processing primitives. These primitives allow EMADE to manipulate input data before ingestion into the simultaneously evolved DNN. We show that including these methods as part of the search space shows potential to provide benefits to performance on the CIFAR-10 image classification benchmark dataset.
Rethinking Surgical Instrument Segmentation: A Background Image Can Be All You Need
Jun 30, 2022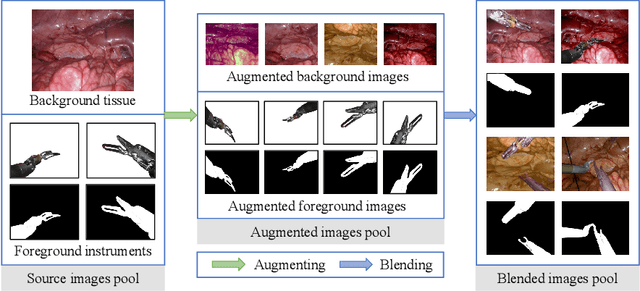
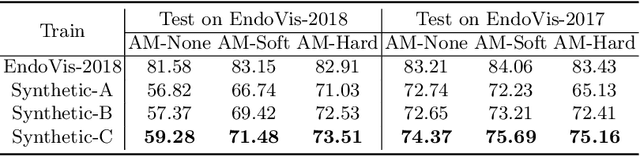


Data diversity and volume are crucial to the success of training deep learning models, while in the medical imaging field, the difficulty and cost of data collection and annotation are especially huge. Specifically in robotic surgery, data scarcity and imbalance have heavily affected the model accuracy and limited the design and deployment of deep learning-based surgical applications such as surgical instrument segmentation. Considering this, we rethink the surgical instrument segmentation task and propose a one-to-many data generation solution that gets rid of the complicated and expensive process of data collection and annotation from robotic surgery. In our method, we only utilize a single surgical background tissue image and a few open-source instrument images as the seed images and apply multiple augmentations and blending techniques to synthesize amounts of image variations. In addition, we also introduce the chained augmentation mixing during training to further enhance the data diversities. The proposed approach is evaluated on the real datasets of the EndoVis-2018 and EndoVis-2017 surgical scene segmentation. Our empirical analysis suggests that without the high cost of data collection and annotation, we can achieve decent surgical instrument segmentation performance. Moreover, we also observe that our method can deal with novel instrument prediction in the deployment domain. We hope our inspiring results will encourage researchers to emphasize data-centric methods to overcome demanding deep learning limitations besides data shortage, such as class imbalance, domain adaptation, and incremental learning. Our code is available at https://github.com/lofrienger/Single_SurgicalScene_For_Segmentation.
Maximum Spatial Perturbation Consistency for Unpaired Image-to-Image Translation
Mar 29, 2022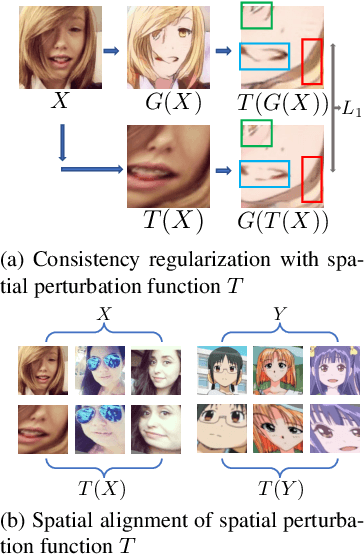
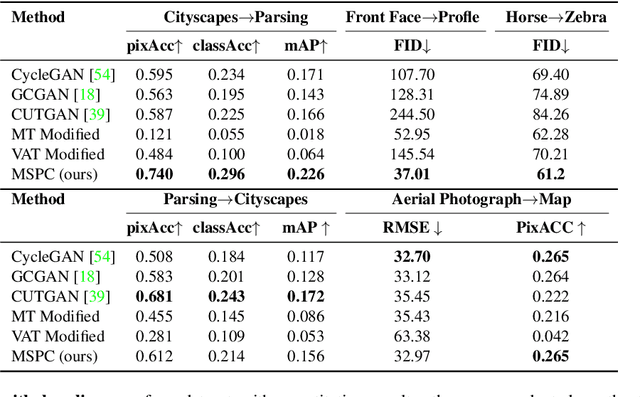
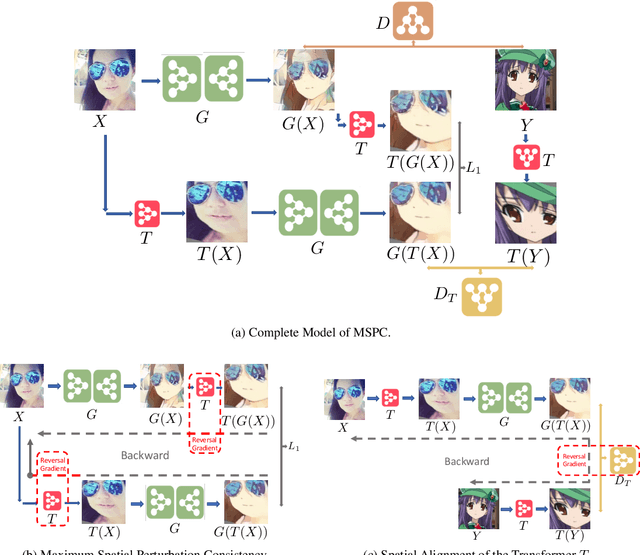

Unpaired image-to-image translation (I2I) is an ill-posed problem, as an infinite number of translation functions can map the source domain distribution to the target distribution. Therefore, much effort has been put into designing suitable constraints, e.g., cycle consistency (CycleGAN), geometry consistency (GCGAN), and contrastive learning-based constraints (CUTGAN), that help better pose the problem. However, these well-known constraints have limitations: (1) they are either too restrictive or too weak for specific I2I tasks; (2) these methods result in content distortion when there is a significant spatial variation between the source and target domains. This paper proposes a universal regularization technique called maximum spatial perturbation consistency (MSPC), which enforces a spatial perturbation function (T ) and the translation operator (G) to be commutative (i.e., TG = GT ). In addition, we introduce two adversarial training components for learning the spatial perturbation function. The first one lets T compete with G to achieve maximum perturbation. The second one lets G and T compete with discriminators to align the spatial variations caused by the change of object size, object distortion, background interruptions, etc. Our method outperforms the state-of-the-art methods on most I2I benchmarks. We also introduce a new benchmark, namely the front face to profile face dataset, to emphasize the underlying challenges of I2I for real-world applications. We finally perform ablation experiments to study the sensitivity of our method to the severity of spatial perturbation and its effectiveness for distribution alignment.