 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Design-time Fashion Popularity Forecasting in VR Environments
Dec 14, 2022

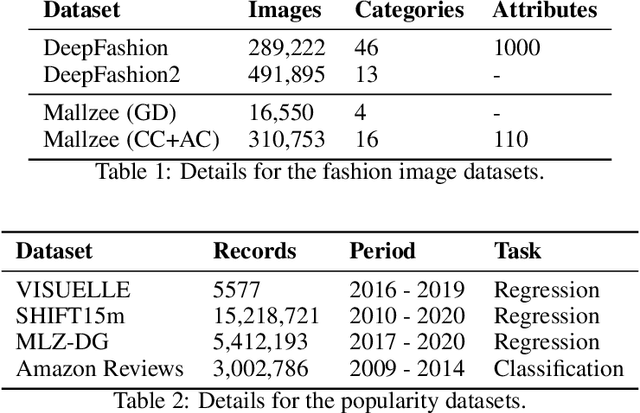
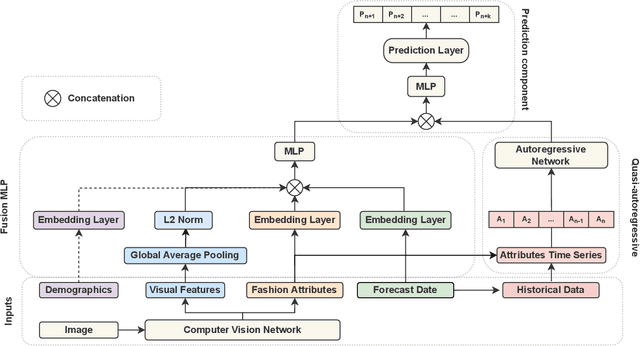
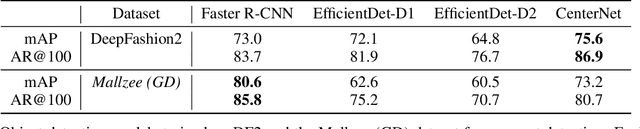
Being able to forecast the popularity of new garment designs is very important in an industry as fast paced as fashion, both in terms of profitability and reducing the problem of unsold inventory. Here, we attempt to address this task in order to provide informative forecasts to fashion designers within a virtual reality designer application that will allow them to fine tune their creations based on current consumer preferences within an interactive and immersive environment. To achieve this we have to deal with the following central challenges: (1) the proposed method should not hinder the creative process and thus it has to rely only on the garment's visual characteristics, (2) the new garment lacks historical data from which to extrapolate their future popularity and (3) fashion trends in general are highly dynamical. To this end, we develop a computer vision pipeline fine tuned on fashion imagery in order to extract relevant visual features along with the category and attributes of the garment. We propose a hierarchical label sharing (HLS) pipeline for automatically capturing hierarchical relations among fashion categories and attributes. Moreover, we propose MuQAR, a Multimodal Quasi-AutoRegressive neural network that forecasts the popularity of new garments by combining their visual features and categorical features while an autoregressive neural network is modelling the popularity time series of the garment's category and attributes. Both the proposed HLS and MuQAR prove capable of surpassing the current state-of-the-art in key benchmark datasets, DeepFashion for image classification and VISUELLE for new garment sales forecasting.
Dual-branch Cross-Patch Attention Learning for Group Affect Recognition
Dec 14, 2022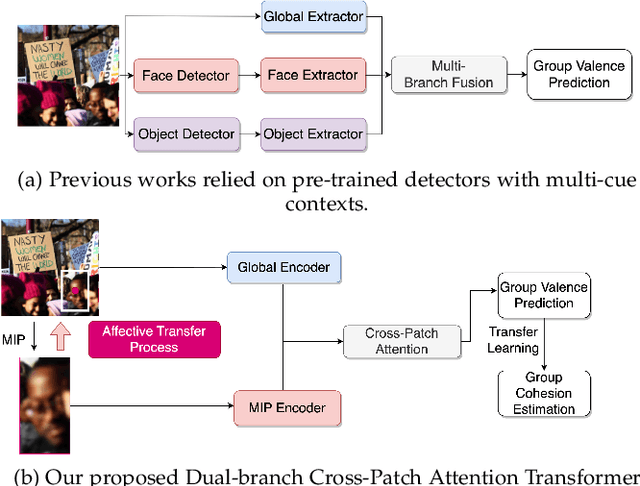
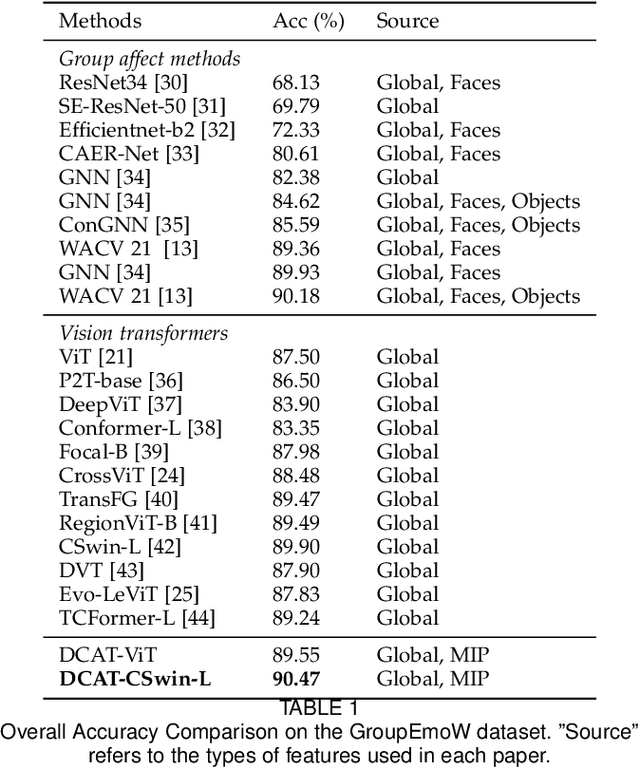

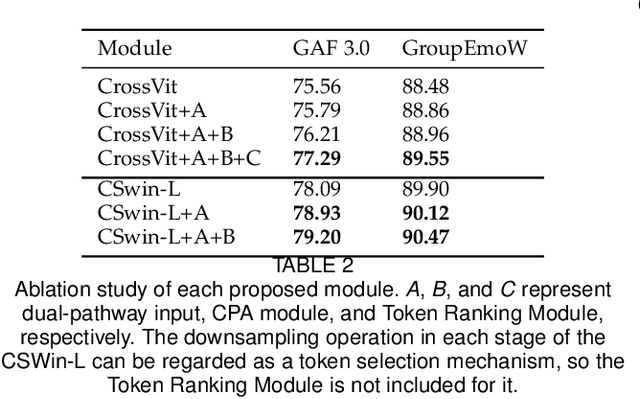
Group affect refers to the subjective emotion that is evoked by an external stimulus in a group, which is an important factor that shapes group behavior and outcomes. Recognizing group affect involves identifying important individuals and salient objects among a crowd that can evoke emotions. Most of the existing methods are proposed to detect faces and objects using pre-trained detectors and summarize the results into group emotions by specific rules. However, such affective region selection mechanisms are heuristic and susceptible to imperfect faces and objects from the pre-trained detectors. Moreover, faces and objects on group-level images are often contextually relevant. There is still an open question about how important faces and objects can be interacted with. In this work, we incorporate the psychological concept called Most Important Person (MIP). It represents the most noteworthy face in the crowd and has an affective semantic meaning. We propose the Dual-branch Cross-Patch Attention Transformer (DCAT) which uses global image and MIP together as inputs. Specifically, we first learn the informative facial regions produced by the MIP and the global context separately. Then, the Cross-Patch Attention module is proposed to fuse the features of MIP and global context together to complement each other. With parameters less than 10x, the proposed DCAT outperforms state-of-the-art methods on two datasets of group valence prediction, GAF 3.0 and GroupEmoW datasets. Moreover, our proposed model can be transferred to another group affect task, group cohesion, and shows comparable results.
Reverse Engineering of Imperceptible Adversarial Image Perturbations
Apr 01, 2022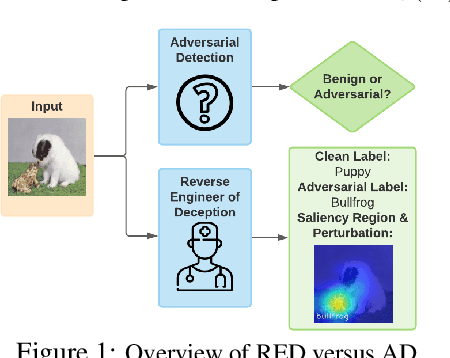
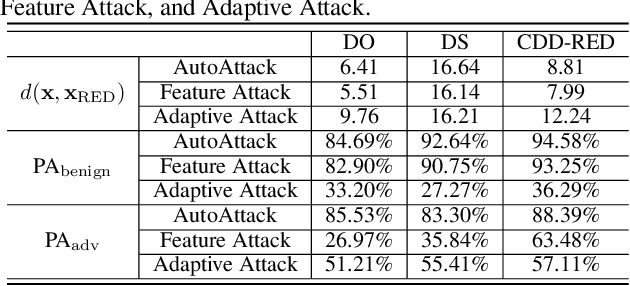
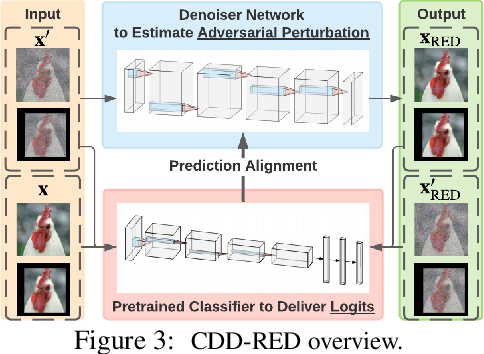
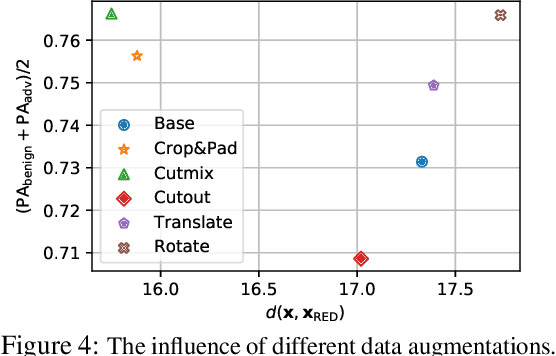
It has been well recognized that neural network based image classifiers are easily fooled by images with tiny perturbations crafted by an adversary. There has been a vast volume of research to generate and defend such adversarial attacks. However, the following problem is left unexplored: How to reverse-engineer adversarial perturbations from an adversarial image? This leads to a new adversarial learning paradigm--Reverse Engineering of Deceptions (RED). If successful, RED allows us to estimate adversarial perturbations and recover the original images. However, carefully crafted, tiny adversarial perturbations are difficult to recover by optimizing a unilateral RED objective. For example, the pure image denoising method may overfit to minimizing the reconstruction error but hardly preserve the classification properties of the true adversarial perturbations. To tackle this challenge, we formalize the RED problem and identify a set of principles crucial to the RED approach design. Particularly, we find that prediction alignment and proper data augmentation (in terms of spatial transformations) are two criteria to achieve a generalizable RED approach. By integrating these RED principles with image denoising, we propose a new Class-Discriminative Denoising based RED framework, termed CDD-RED. Extensive experiments demonstrate the effectiveness of CDD-RED under different evaluation metrics (ranging from the pixel-level, prediction-level to the attribution-level alignment) and a variety of attack generation methods (e.g., FGSM, PGD, CW, AutoAttack, and adaptive attacks).
Prior image-based medical image reconstruction using a style-based generative adversarial network
Feb 17, 2022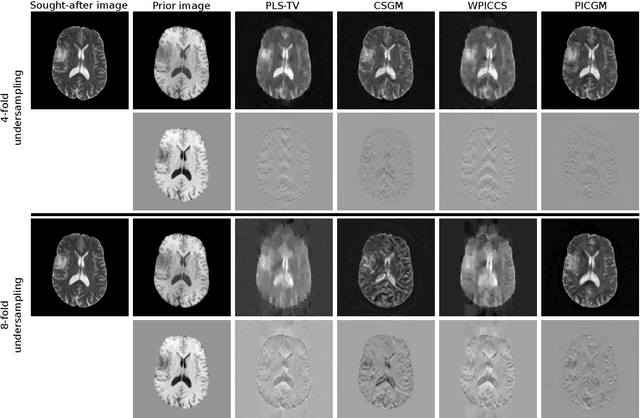
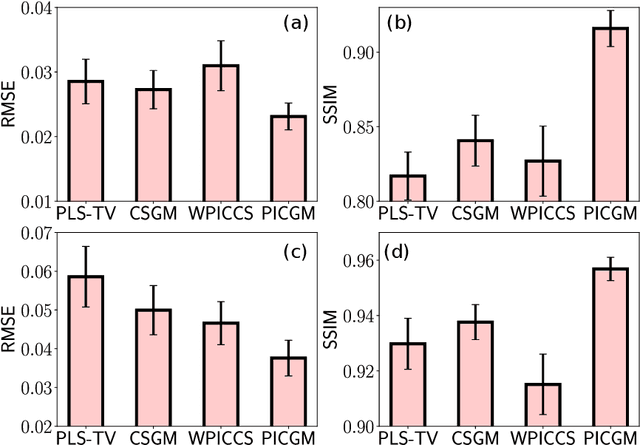
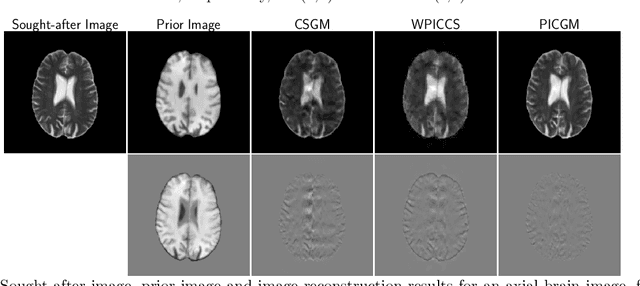
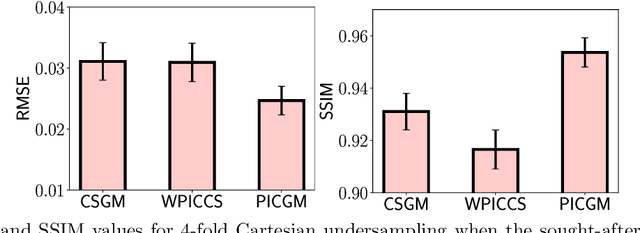
Computed medical imaging systems require a computational reconstruction procedure for image formation. In order to recover a useful estimate of the object to-be-imaged when the recorded measurements are incomplete, prior knowledge about the nature of object must be utilized. In order to improve the conditioning of an ill-posed imaging inverse problem, deep learning approaches are being actively investigated for better representing object priors and constraints. This work proposes to use a style-based generative adversarial network (StyleGAN) to constrain an image reconstruction problem in the case where additional information in the form of a prior image of the sought-after object is available. An optimization problem is formulated in the intermediate latent-space of a StyleGAN, that is disentangled with respect to meaningful image attributes or "styles", such as the contrast used in magnetic resonance imaging (MRI). Discrepancy between the sought-after and prior images is measured in the disentangled latent-space, and is used to regularize the inverse problem in the form of constraints on specific styles of the disentangled latent-space. A stylized numerical study inspired by MR imaging is designed, where the sought-after and the prior image are structurally similar, but belong to different contrast mechanisms. The presented numerical studies demonstrate the superiority of the proposed approach as compared to classical approaches in the form of traditional metrics.
CACTI: A Framework for Scalable Multi-Task Multi-Scene Visual Imitation Learning
Dec 12, 2022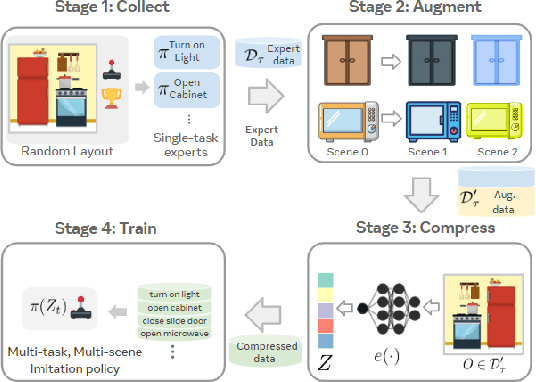

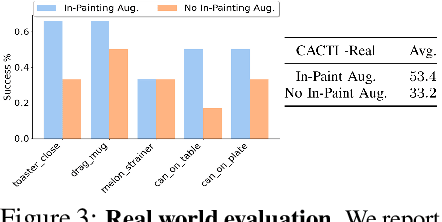
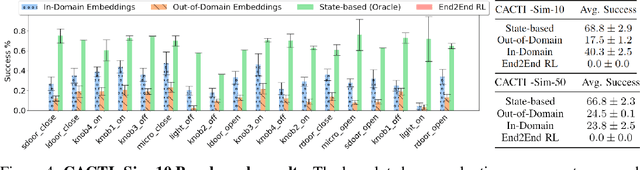
Developing robots that are capable of many skills and generalization to unseen scenarios requires progress on two fronts: efficient collection of large and diverse datasets, and training of high-capacity policies on the collected data. While large datasets have propelled progress in other fields like computer vision and natural language processing, collecting data of comparable scale is particularly challenging for physical systems like robotics. In this work, we propose a framework to bridge this gap and better scale up robot learning, under the lens of multi-task, multi-scene robot manipulation in kitchen environments. Our framework, named CACTI, has four stages that separately handle data collection, data augmentation, visual representation learning, and imitation policy training. In the CACTI framework, we highlight the benefit of adapting state-of-the-art models for image generation as part of the augmentation stage, and the significant improvement of training efficiency by using pretrained out-of-domain visual representations at the compression stage. Experimentally, we demonstrate that 1) on a real robot setup, CACTI enables efficient training of a single policy capable of 10 manipulation tasks involving kitchen objects, and robust to varying layouts of distractor objects; 2) in a simulated kitchen environment, CACTI trains a single policy on 18 semantic tasks across up to 50 layout variations per task. The simulation task benchmark and augmented datasets in both real and simulated environments will be released to facilitate future research.
CTT-Net: A Multi-view Cross-token Transformer for Cataract Postoperative Visual Acuity Prediction
Dec 12, 2022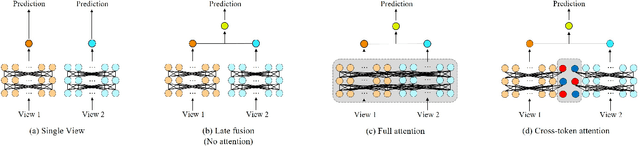
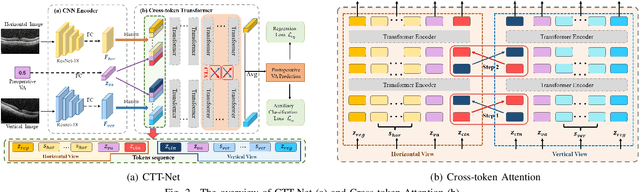
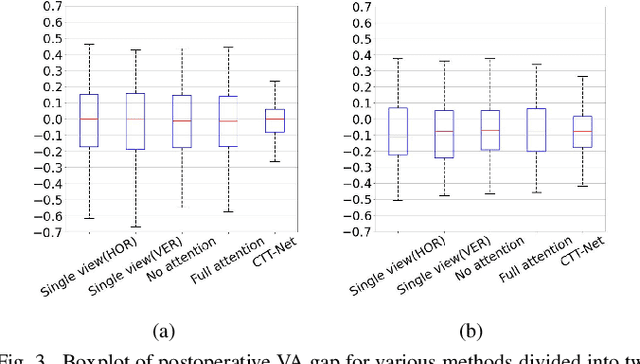

Surgery is the only viable treatment for cataract patients with visual acuity (VA) impairment. Clinically, to assess the necessity of cataract surgery, accurately predicting postoperative VA before surgery by analyzing multi-view optical coherence tomography (OCT) images is crucially needed. Unfortunately, due to complicated fundus conditions, determining postoperative VA remains difficult for medical experts. Deep learning methods for this problem were developed in recent years. Although effective, these methods still face several issues, such as not efficiently exploring potential relations between multi-view OCT images, neglecting the key role of clinical prior knowledge (e.g., preoperative VA value), and using only regression-based metrics which are lacking reference. In this paper, we propose a novel Cross-token Transformer Network (CTT-Net) for postoperative VA prediction by analyzing both the multi-view OCT images and preoperative VA. To effectively fuse multi-view features of OCT images, we develop cross-token attention that could restrict redundant/unnecessary attention flow. Further, we utilize the preoperative VA value to provide more information for postoperative VA prediction and facilitate fusion between views. Moreover, we design an auxiliary classification loss to improve model performance and assess VA recovery more sufficiently, avoiding the limitation by only using the regression metrics. To evaluate CTT-Net, we build a multi-view OCT image dataset collected from our collaborative hospital. A set of extensive experiments validate the effectiveness of our model compared to existing methods in various metrics. Code is available at: https://github.com/wjh892521292/Cataract OCT.
Towards Understanding and Boosting Adversarial Transferability from a Distribution Perspective
Oct 09, 2022
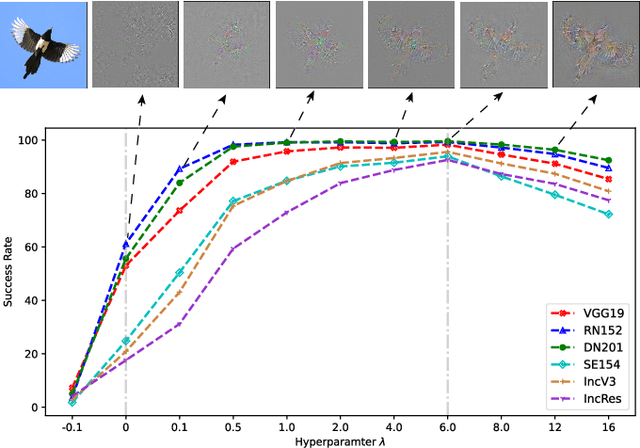
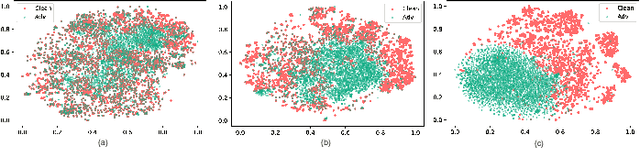
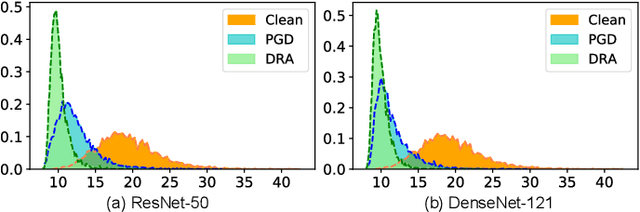
Transferable adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective, e.g., decision boundary, model architecture, and model capacity. adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective. Here, we investigate the transferability from the data distribution perspective and hypothesize that pushing the image away from its original distribution can enhance the adversarial transferability. To be specific, moving the image out of its original distribution makes different models hardly classify the image correctly, which benefits the untargeted attack, and dragging the image into the target distribution misleads the models to classify the image as the target class, which benefits the targeted attack. Towards this end, we propose a novel method that crafts adversarial examples by manipulating the distribution of the image. We conduct comprehensive transferable attacks against multiple DNNs to demonstrate the effectiveness of the proposed method. Our method can significantly improve the transferability of the crafted attacks and achieves state-of-the-art performance in both untargeted and targeted scenarios, surpassing the previous best method by up to 40$\%$ in some cases.
Invertible Rescaling Network and Its Extensions
Oct 09, 2022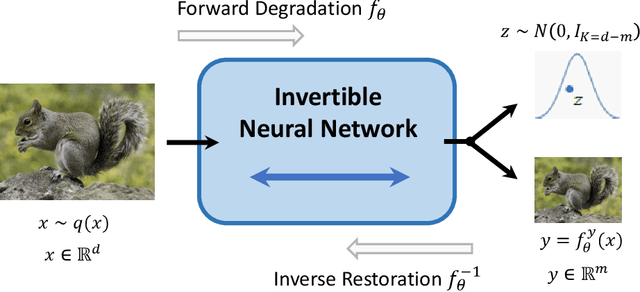
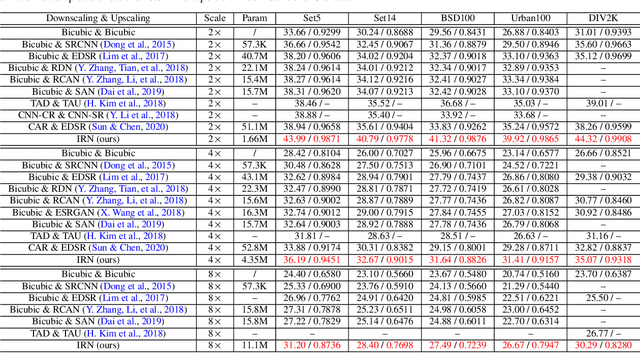
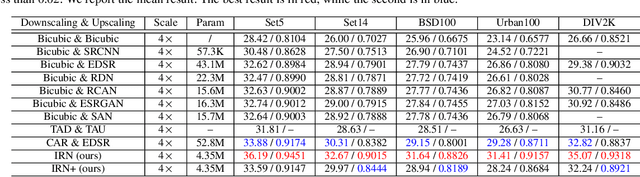
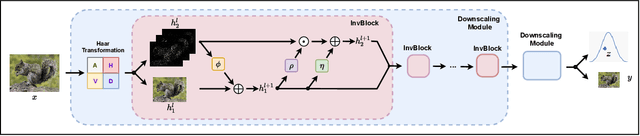
Image rescaling is a commonly used bidirectional operation, which first downscales high-resolution images to fit various display screens or to be storage- and bandwidth-friendly, and afterward upscales the corresponding low-resolution images to recover the original resolution or the details in the zoom-in images. However, the non-injective downscaling mapping discards high-frequency contents, leading to the ill-posed problem for the inverse restoration task. This can be abstracted as a general image degradation-restoration problem with information loss. In this work, we propose a novel invertible framework to handle this general problem, which models the bidirectional degradation and restoration from a new perspective, i.e. invertible bijective transformation. The invertibility enables the framework to model the information loss of pre-degradation in the form of distribution, which could mitigate the ill-posed problem during post-restoration. To be specific, we develop invertible models to generate valid degraded images and meanwhile transform the distribution of lost contents to the fixed distribution of a latent variable during the forward degradation. Then restoration is made tractable by applying the inverse transformation on the generated degraded image together with a randomly-drawn latent variable. We start from image rescaling and instantiate the model as Invertible Rescaling Network (IRN), which can be easily extended to the similar decolorization-colorization task. We further propose to combine the invertible framework with existing degradation methods such as image compression for wider applications. Experimental results demonstrate the significant improvement of our model over existing methods in terms of both quantitative and qualitative evaluations of upscaling and colorizing reconstruction from downscaled and decolorized images, and rate-distortion of image compression.
LiePoseNet: Heterogeneous Loss Function Based on Lie Group for Significant Speed-up of PoseNet Training Process
Nov 15, 2022

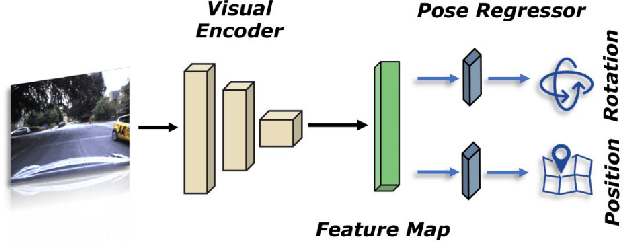
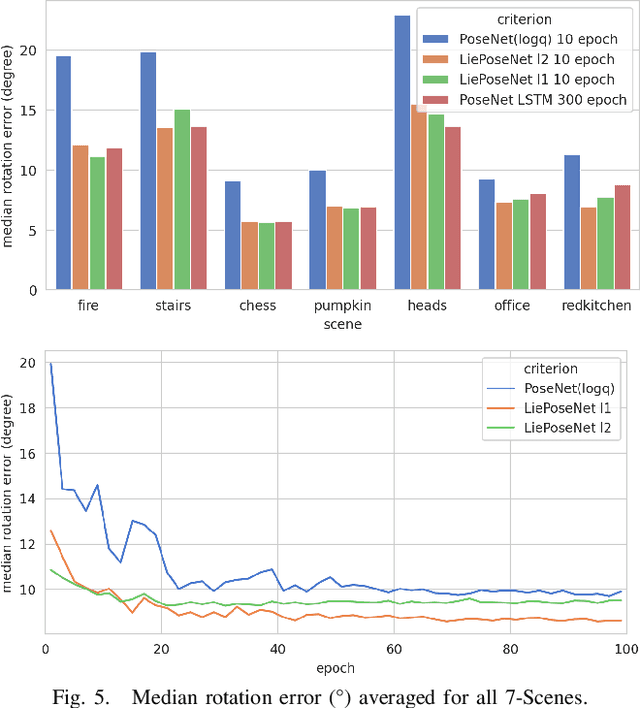
Visual localization is an essential modern technology for robotics and computer vision. Popular approaches for solving this task are image-based methods. Nowadays, these methods have low accuracy and a long training time. The reasons are the lack of rigid-body and projective geometry awareness, landmark symmetry, and homogeneous error assumption. We propose a heterogeneous loss function based on concentrated Gaussian distribution with the Lie group to overcome these difficulties. Following our experiment, the proposed method allows us to speed up the training process significantly (from 300 to 10 epochs) with acceptable error values.
Pixel-Aligned Non-parametric Hand Mesh Reconstruction
Oct 17, 2022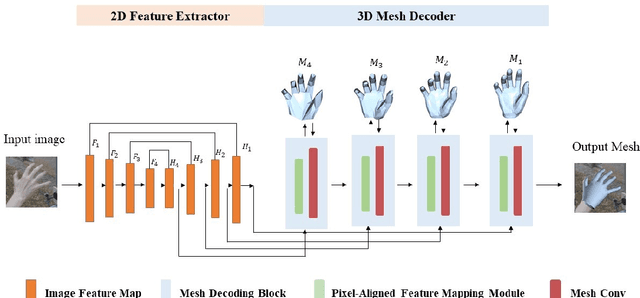
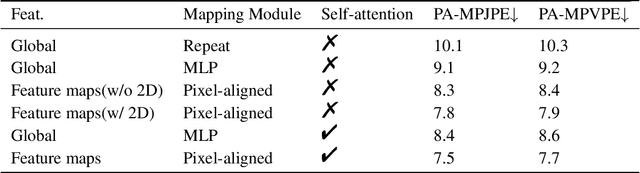
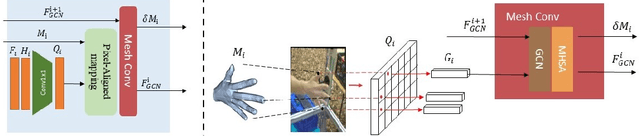

Non-parametric mesh reconstruction has recently shown significant progress in 3D hand and body applications. In these methods, mesh vertices and edges are visible to neural networks, enabling the possibility to establish a direct mapping between 2D image pixels and 3D mesh vertices. In this paper, we seek to establish and exploit this mapping with a simple and compact architecture. The network is designed with these considerations: 1) aggregating both local 2D image features from the encoder and 3D geometric features captured in the mesh decoder; 2) decoding coarse-to-fine meshes along the decoding layers to make the best use of the hierarchical multi-scale information. Specifically, we propose an end-to-end pipeline for hand mesh recovery tasks which consists of three phases: a 2D feature extractor constructing multi-scale feature maps, a feature mapping module transforming local 2D image features to 3D vertex features via 3D-to-2D projection, and a mesh decoder combining the graph convolution and self-attention to reconstruct mesh. The decoder aggregate both local image features in pixels and geometric features in vertices. It also regresses the mesh vertices in a coarse-to-fine manner, which can leverage multi-scale information. By exploiting the local connection and designing the mesh decoder, Our approach achieves state-of-the-art for hand mesh reconstruction on the public FreiHAND dataset.