 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Analysis of the Effect of Low-Overhead Lossy Image Compression on the Performance of Visual Crowd Counting for Smart City Applications
Jul 20, 2022


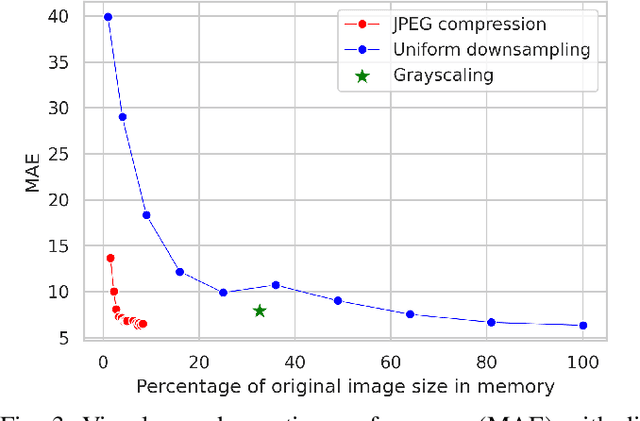
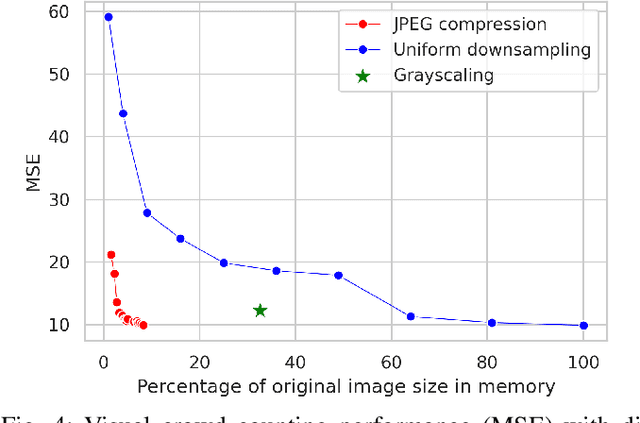
Images and video frames captured by cameras placed throughout smart cities are often transmitted over the network to a server to be processed by deep neural networks for various tasks. Transmission of raw images, i.e., without any form of compression, requires high bandwidth and can lead to congestion issues and delays in transmission. The use of lossy image compression techniques can reduce the quality of the images, leading to accuracy degradation. In this paper, we analyze the effect of applying low-overhead lossy image compression methods on the accuracy of visual crowd counting, and measure the trade-off between bandwidth reduction and the obtained accuracy.
Security and Interpretability in Automotive Systems
Dec 23, 2022The lack of any sender authentication mechanism in place makes CAN (Controller Area Network) vulnerable to security threats. For instance, an attacker can impersonate an ECU (Electronic Control Unit) on the bus and send spoofed messages unobtrusively with the identifier of the impersonated ECU. To address the insecure nature of the system, this thesis demonstrates a sender authentication technique that uses power consumption measurements of the electronic control units (ECUs) and a classification model to determine the transmitting states of the ECUs. The method's evaluation in real-world settings shows that the technique applies in a broad range of operating conditions and achieves good accuracy. A key challenge of machine learning-based security controls is the potential of false positives. A false-positive alert may induce panic in operators, lead to incorrect reactions, and in the long run cause alarm fatigue. For reliable decision-making in such a circumstance, knowing the cause for unusual model behavior is essential. But, the black-box nature of these models makes them uninterpretable. Therefore, another contribution of this thesis explores explanation techniques for inputs of type image and time series that (1) assign weights to individual inputs based on their sensitivity toward the target class, (2) and quantify the variations in the explanation by reconstructing the sensitive regions of the inputs using a generative model. In summary, this thesis (https://uwspace.uwaterloo.ca/handle/10012/18134) presents methods for addressing the security and interpretability in automotive systems, which can also be applied in other settings where safe, transparent, and reliable decision-making is crucial.
UnICLAM:Contrastive Representation Learning with Adversarial Masking for Unified and Interpretable Medical Vision Question Answering
Dec 23, 2022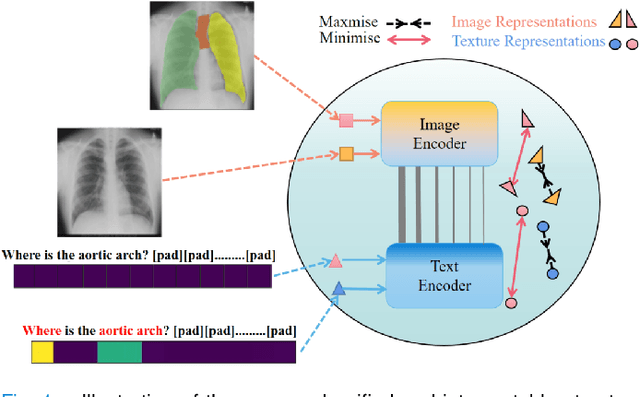
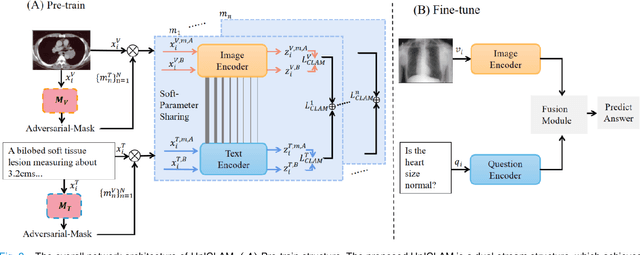
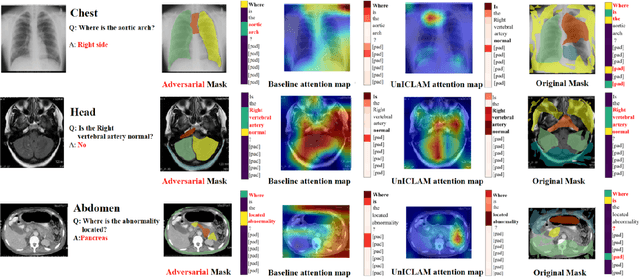
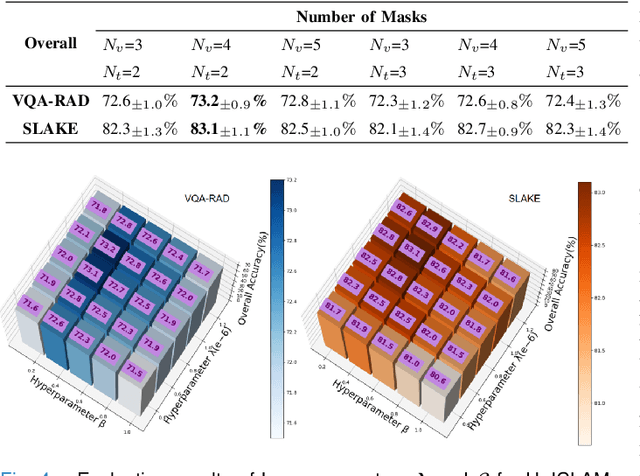
Medical Visual Question Answering (Medical-VQA) aims to to answer clinical questions regarding radiology images, assisting doctors with decision-making options. Nevertheless, current Medical-VQA models learn cross-modal representations through residing vision and texture encoders in dual separate spaces, which lead to indirect semantic alignment. In this paper, we propose UnICLAM, a Unified and Interpretable Medical-VQA model through Contrastive Representation Learning with Adversarial Masking. Specifically, to learn an aligned image-text representation, we first establish a unified dual-stream pre-training structure with the gradually soft-parameter sharing strategy. Technically, the proposed strategy learns a constraint for the vision and texture encoders to be close in a same space, which is gradually loosened as the higher number of layers. Moreover, for grasping the unified semantic representation, we extend the adversarial masking data augmentation to the contrastive representation learning of vision and text in a unified manner. Concretely, while the encoder training minimizes the distance between original and masking samples, the adversarial masking module keeps adversarial learning to conversely maximize the distance. Furthermore, we also intuitively take a further exploration to the unified adversarial masking augmentation model, which improves the potential ante-hoc interpretability with remarkable performance and efficiency. Experimental results on VQA-RAD and SLAKE public benchmarks demonstrate that UnICLAM outperforms existing 11 state-of-the-art Medical-VQA models. More importantly, we make an additional discussion about the performance of UnICLAM in diagnosing heart failure, verifying that UnICLAM exhibits superior few-shot adaption performance in practical disease diagnosis.
Motion and Appearance Adaptation for Cross-Domain Motion Transfer
Oct 06, 2022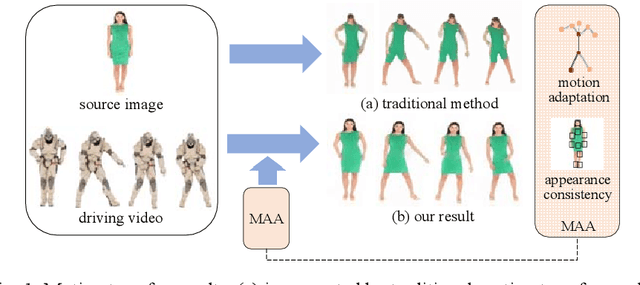
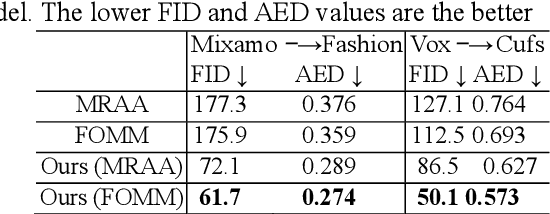
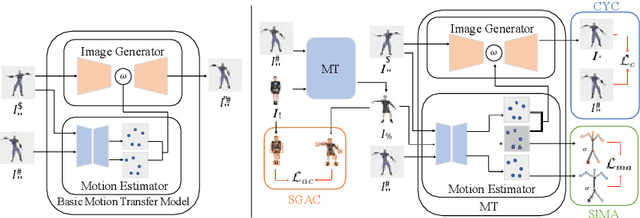
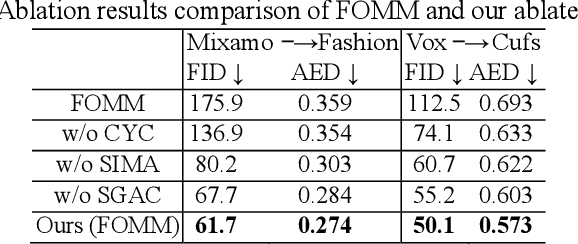
Motion transfer aims to transfer the motion of a driving video to a source image. When there are considerable differences between object in the driving video and that in the source image, traditional single domain motion transfer approaches often produce notable artifacts; for example, the synthesized image may fail to preserve the human shape of the source image (cf . Fig. 1 (a)). To address this issue, in this work, we propose a Motion and Appearance Adaptation (MAA) approach for cross-domain motion transfer, in which we regularize the object in the synthesized image to capture the motion of the object in the driving frame, while still preserving the shape and appearance of the object in the source image. On one hand, considering the object shapes of the synthesized image and the driving frame might be different, we design a shape-invariant motion adaptation module that enforces the consistency of the angles of object parts in two images to capture the motion information. On the other hand, we introduce a structure-guided appearance consistency module designed to regularize the similarity between the corresponding patches of the synthesized image and the source image without affecting the learned motion in the synthesized image. Our proposed MAA model can be trained in an end-to-end manner with a cyclic reconstruction loss, and ultimately produces a satisfactory motion transfer result (cf . Fig. 1 (b)). We conduct extensive experiments on human dancing dataset Mixamo-Video to Fashion-Video and human face dataset Vox-Celeb to Cufs; on both of these, our MAA model outperforms existing methods both quantitatively and qualitatively.
Co-training $2^L$ Submodels for Visual Recognition
Dec 09, 2022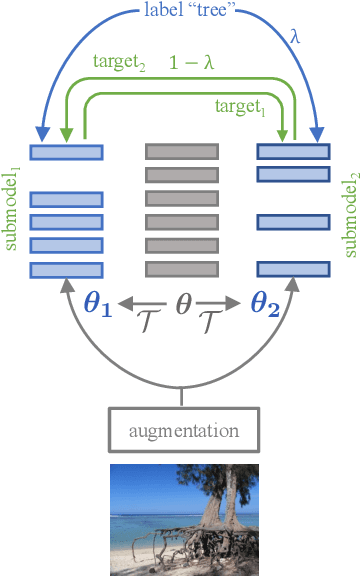
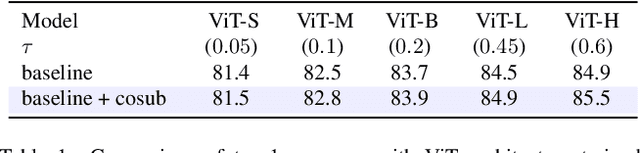

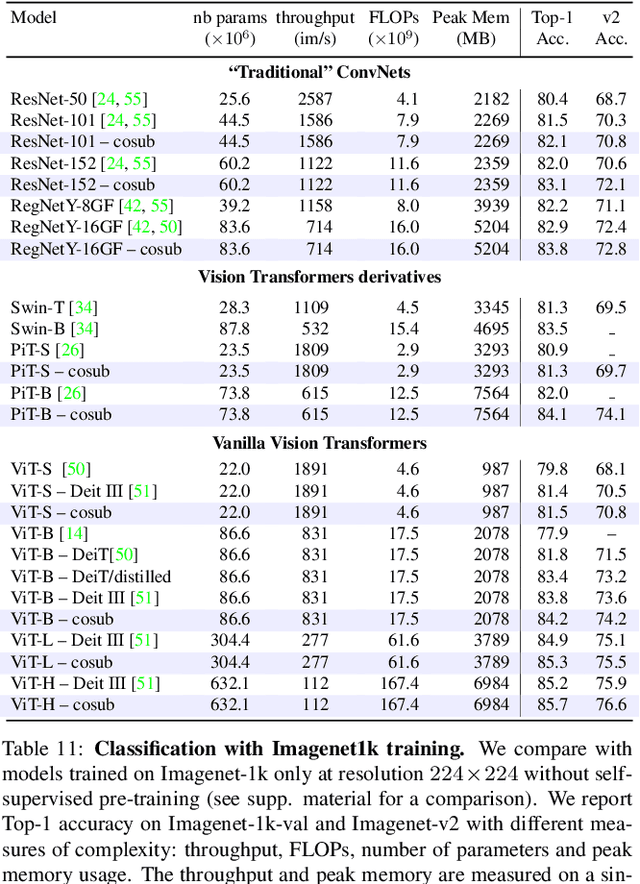
We introduce submodel co-training, a regularization method related to co-training, self-distillation and stochastic depth. Given a neural network to be trained, for each sample we implicitly instantiate two altered networks, ``submodels'', with stochastic depth: we activate only a subset of the layers. Each network serves as a soft teacher to the other, by providing a loss that complements the regular loss provided by the one-hot label. Our approach, dubbed cosub, uses a single set of weights, and does not involve a pre-trained external model or temporal averaging. Experimentally, we show that submodel co-training is effective to train backbones for recognition tasks such as image classification and semantic segmentation. Our approach is compatible with multiple architectures, including RegNet, ViT, PiT, XCiT, Swin and ConvNext. Our training strategy improves their results in comparable settings. For instance, a ViT-B pretrained with cosub on ImageNet-21k obtains 87.4% top-1 acc. @448 on ImageNet-val.
PIVOT: Prompting for Video Continual Learning
Dec 09, 2022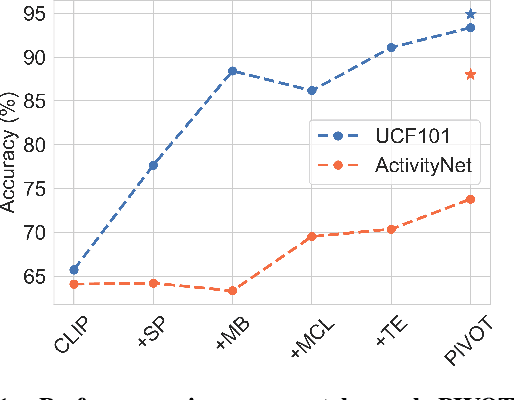
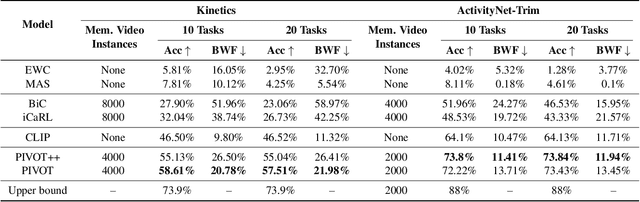
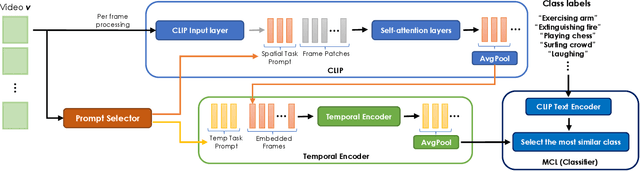
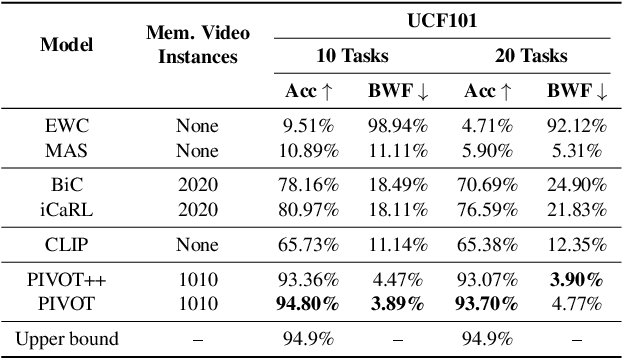
Modern machine learning pipelines are limited due to data availability, storage quotas, privacy regulations, and expensive annotation processes. These constraints make it difficult or impossible to maintain a large-scale model trained on growing annotation sets. Continual learning directly approaches this problem, with the ultimate goal of devising methods where a neural network effectively learns relevant patterns for new (unseen) classes without significantly altering its performance on previously learned ones. In this paper, we address the problem of continual learning for video data. We introduce PIVOT, a novel method that leverages the extensive knowledge in pre-trained models from the image domain, thereby reducing the number of trainable parameters and the associated forgetting. Unlike previous methods, ours is the first approach that effectively uses prompting mechanisms for continual learning without any in-domain pre-training. Our experiments show that PIVOT improves state-of-the-art methods by a significant 27% on the 20-task ActivityNet setup.
SrTR: Self-reasoning Transformer with Visual-linguistic Knowledge for Scene Graph Generation
Dec 19, 2022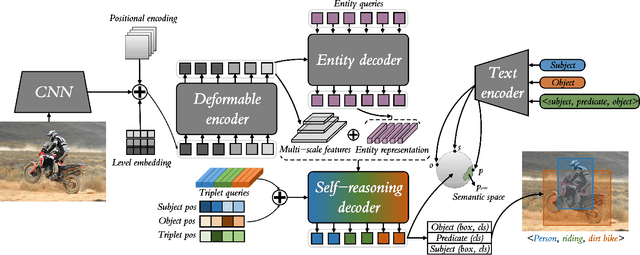
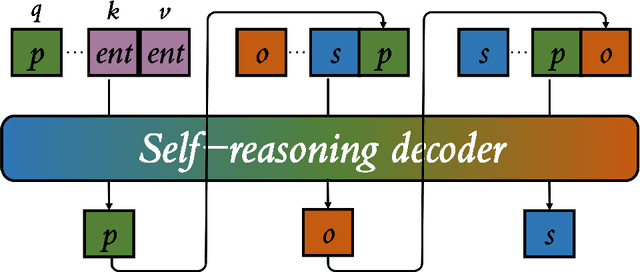


Objects in a scene are not always related. The execution efficiency of the one-stage scene graph generation approaches are quite high, which infer the effective relation between entity pairs using sparse proposal sets and a few queries. However, they only focus on the relation between subject and object in triplet set subject entity, predicate entity, object entity, ignoring the relation between subject and predicate or predicate and object, and the model lacks self-reasoning ability. In addition, linguistic modality has been neglected in the one-stage method. It is necessary to mine linguistic modality knowledge to improve model reasoning ability. To address the above-mentioned shortcomings, a Self-reasoning Transformer with Visual-linguistic Knowledge (SrTR) is proposed to add flexible self-reasoning ability to the model. An encoder-decoder architecture is adopted in SrTR, and a self-reasoning decoder is developed to complete three inferences of the triplet set, s+o-p, s+p-o and p+o-s. Inspired by the large-scale pre-training image-text foundation models, visual-linguistic prior knowledge is introduced and a visual-linguistic alignment strategy is designed to project visual representations into semantic spaces with prior knowledge to aid relational reasoning. Experiments on the Visual Genome dataset demonstrate the superiority and fast inference ability of the proposed method.
MIST: Multi-modal Iterative Spatial-Temporal Transformer for Long-form Video Question Answering
Dec 19, 2022
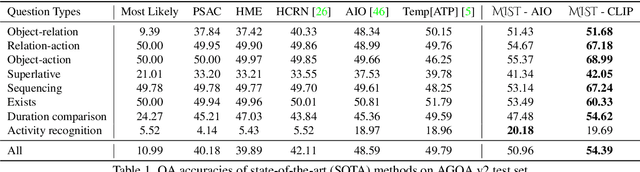
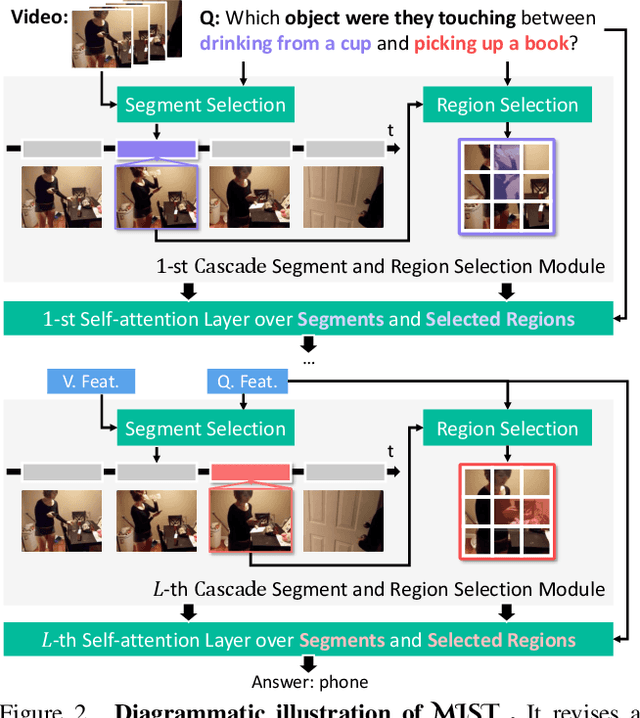
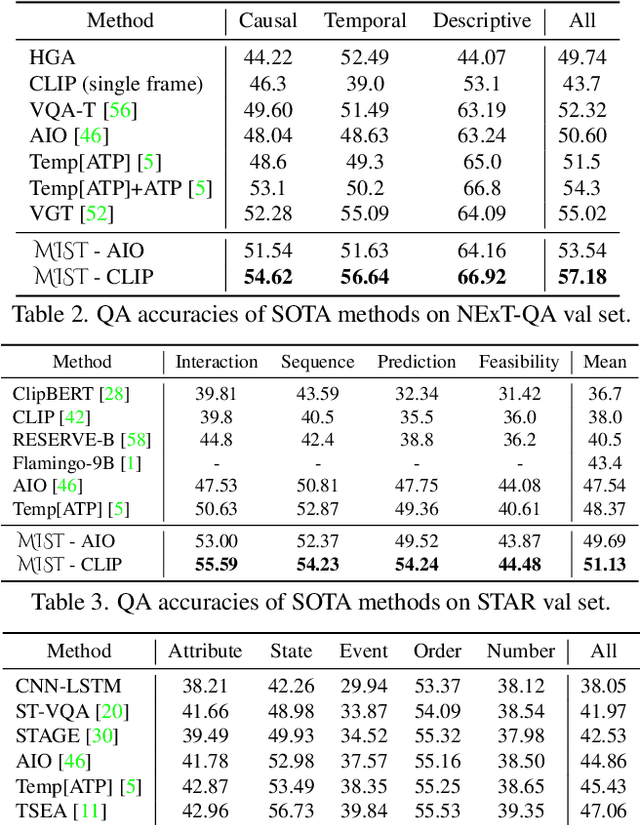
To build Video Question Answering (VideoQA) systems capable of assisting humans in daily activities, seeking answers from long-form videos with diverse and complex events is a must. Existing multi-modal VQA models achieve promising performance on images or short video clips, especially with the recent success of large-scale multi-modal pre-training. However, when extending these methods to long-form videos, new challenges arise. On the one hand, using a dense video sampling strategy is computationally prohibitive. On the other hand, methods relying on sparse sampling struggle in scenarios where multi-event and multi-granularity visual reasoning are required. In this work, we introduce a new model named Multi-modal Iterative Spatial-temporal Transformer (MIST) to better adapt pre-trained models for long-form VideoQA. Specifically, MIST decomposes traditional dense spatial-temporal self-attention into cascaded segment and region selection modules that adaptively select frames and image regions that are closely relevant to the question itself. Visual concepts at different granularities are then processed efficiently through an attention module. In addition, MIST iteratively conducts selection and attention over multiple layers to support reasoning over multiple events. The experimental results on four VideoQA datasets, including AGQA, NExT-QA, STAR, and Env-QA, show that MIST achieves state-of-the-art performance and is superior at computation efficiency and interpretability.
Semi-supervised atmospheric component learning in low-light image problem
Apr 15, 2022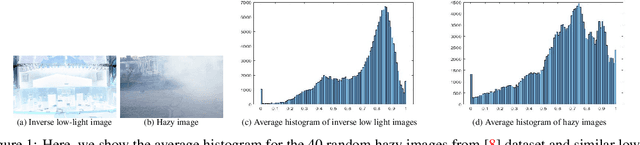
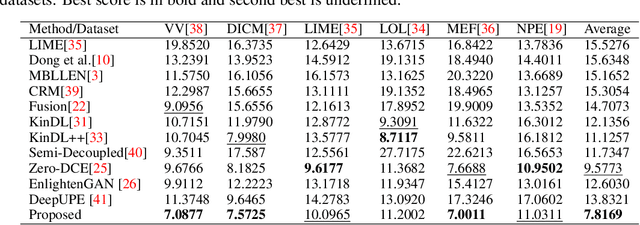

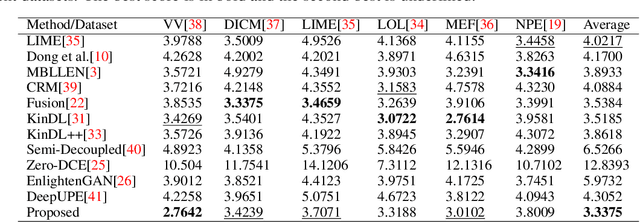
Ambient lighting conditions play a crucial role in determining the perceptual quality of images from photographic devices. In general, inadequate transmission light and undesired atmospheric conditions jointly degrade the image quality. If we know the desired ambient factors associated with the given low-light image, we can recover the enhanced image easily \cite{b1}. Typical deep networks perform enhancement mappings without investigating the light distribution and color formulation properties. This leads to a lack of image instance-adaptive performance in practice. On the other hand, physical model-driven schemes suffer from the need for inherent decompositions and multiple objective minimizations. Moreover, the above approaches are rarely data efficient or free of postprediction tuning. Influenced by the above issues, this study presents a semisupervised training method using no-reference image quality metrics for low-light image restoration. We incorporate the classical haze distribution model \cite{b2} to explore the physical properties of the given image in order to learn the effect of atmospheric components and minimize a single objective for restoration. We validate the performance of our network for six widely used low-light datasets. The experiments show that the proposed study achieves state-of-the-art or comparable performance.
High-fidelity Direct Contrast Synthesis from Magnetic Resonance Fingerprinting
Dec 21, 2022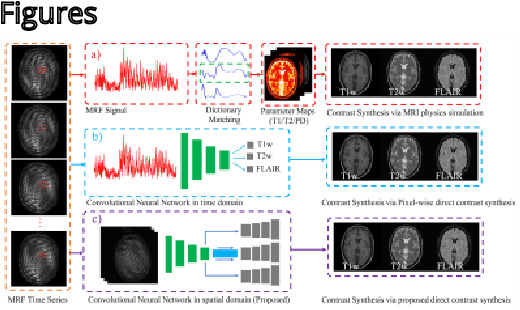
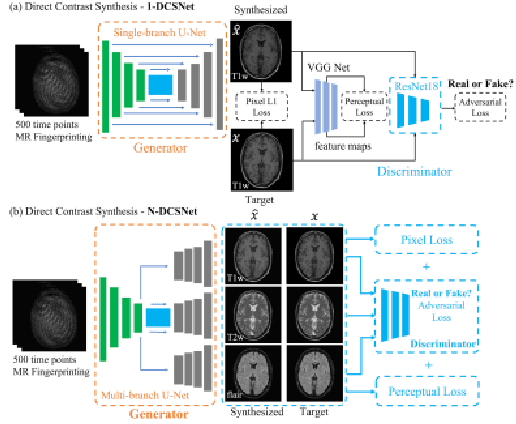
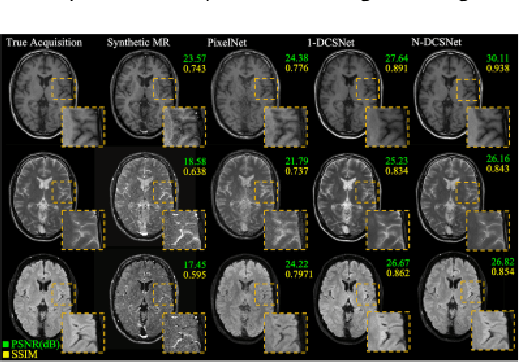
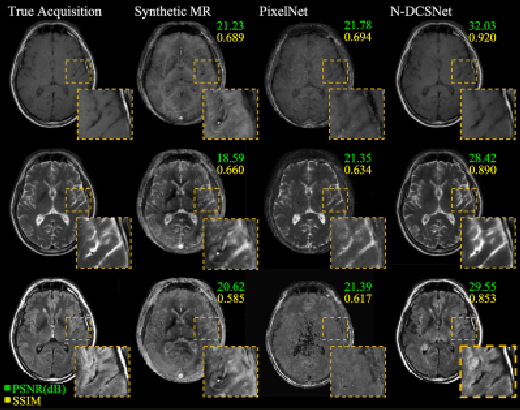
Magnetic Resonance Fingerprinting (MRF) is an efficient quantitative MRI technique that can extract important tissue and system parameters such as T1, T2, B0, and B1 from a single scan. This property also makes it attractive for retrospectively synthesizing contrast-weighted images. In general, contrast-weighted images like T1-weighted, T2-weighted, etc., can be synthesized directly from parameter maps through spin-dynamics simulation (i.e., Bloch or Extended Phase Graph models). However, these approaches often exhibit artifacts due to imperfections in the mapping, the sequence modeling, and the data acquisition. Here we propose a supervised learning-based method that directly synthesizes contrast-weighted images from the MRF data without going through the quantitative mapping and spin-dynamics simulation. To implement our direct contrast synthesis (DCS) method, we deploy a conditional Generative Adversarial Network (GAN) framework and propose a multi-branch U-Net as the generator. The input MRF data are used to directly synthesize T1-weighted, T2-weighted, and fluid-attenuated inversion recovery (FLAIR) images through supervised training on paired MRF and target spin echo-based contrast-weighted scans. In-vivo experiments demonstrate excellent image quality compared to simulation-based contrast synthesis and previous DCS methods, both visually as well as by quantitative metrics. We also demonstrate cases where our trained model is able to mitigate in-flow and spiral off-resonance artifacts that are typically seen in MRF reconstructions and thus more faithfully represent conventional spin echo-based contrast-weighted images.