 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Creative divergent synthesis with generative models
Nov 16, 2022
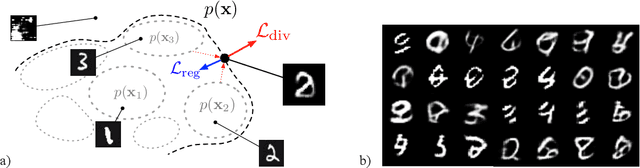

Machine learning approaches now achieve impressive generation capabilities in numerous domains such as image, audio or video. However, most training \& evaluation frameworks revolve around the idea of strictly modelling the original data distribution rather than trying to extrapolate from it. This precludes the ability of such models to diverge from the original distribution and, hence, exhibit some creative traits. In this paper, we propose various perspectives on how this complicated goal could ever be achieved, and provide preliminary results on our novel training objective called \textit{Bounded Adversarial Divergence} (BAD).
An open-source software package for on-the-fly deskewing and live viewing of volumetric lightsheet microscopy data
Oct 31, 2022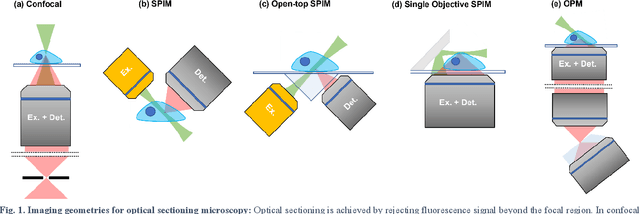
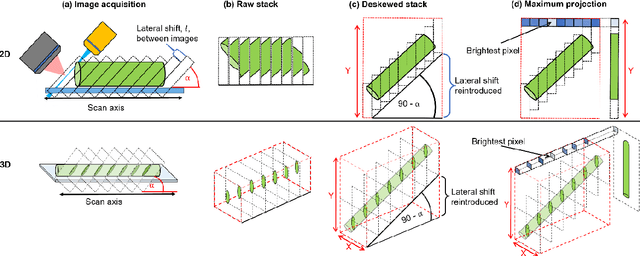
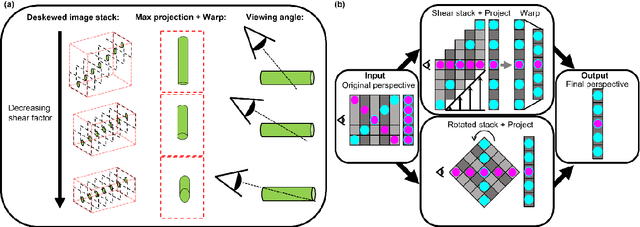
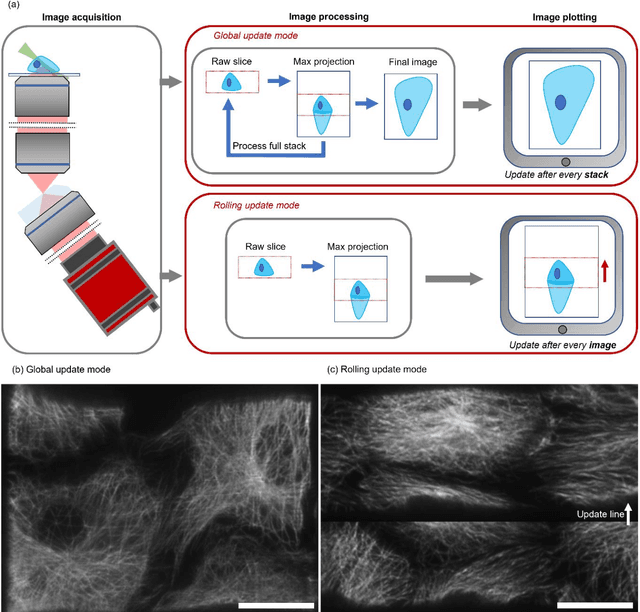
Oblique plane microscopy, OPM, is a form of lightsheet microscopy that permits volumetric imaging of biological samples at high temporal and spatial resolution. However, the imaging geometry of OPM, and related variants of light sheet microscopy, distorts the coordinate frame of the presented image sections with respect to real space coordinate frame in which the sample is moved to navigate to regions of interest. This makes live viewing and practical operation of such microscopes difficult. We present an open-source software package that utilises GPU acceleration and multiprocessing to transform the display of OPM imaging data in real time to produce live views that mimic that produced by standard widefield microscopes. Image stacks can be acquired, processed and plotted at rates of several Hz, making live operation of OPMs, and similar microscopes, more user friendly and intuitive.
Revisiting and Optimising a CNN Colour Constancy Method for Multi-Illuminant Estimation
Nov 03, 2022
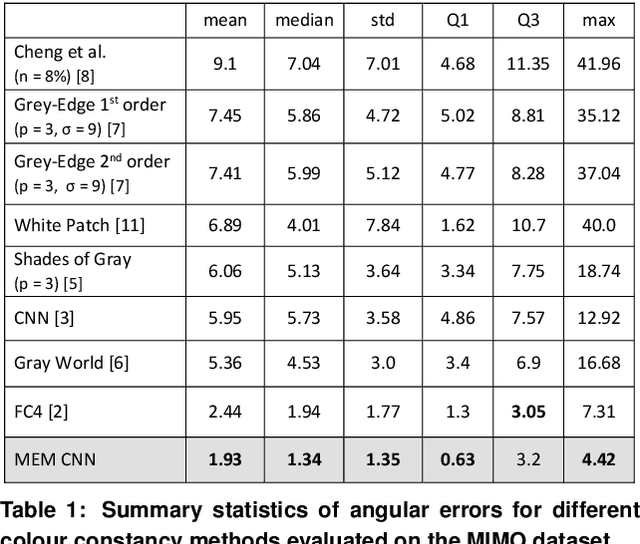
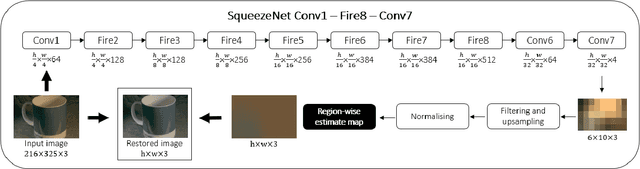

The aim of colour constancy is to discount the effect of the scene illumination from the image colours and restore the colours of the objects as captured under a 'white' illuminant. For the majority of colour constancy methods, the first step is to estimate the scene illuminant colour. Generally, it is assumed that the illumination is uniform in the scene. However, real world scenes have multiple illuminants, like sunlight and spot lights all together in one scene. We present in this paper a simple yet very effective framework using a deep CNN-based method to estimate and use multiple illuminants for colour constancy. Our approach works well in both the multi and single illuminant cases. The output of the CNN method is a region-wise estimate map of the scene which is smoothed and divided out from the image to perform colour constancy. The method that we propose outperforms other recent and state of the art methods and has promising visual results.
NaRPA: Navigation and Rendering Pipeline for Astronautics
Nov 03, 2022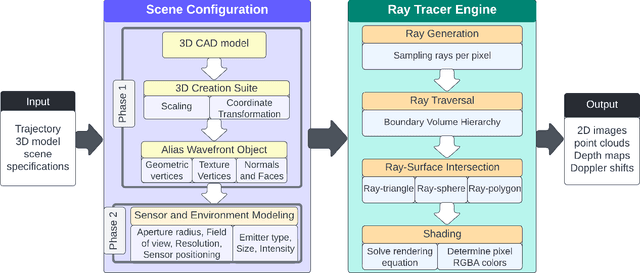
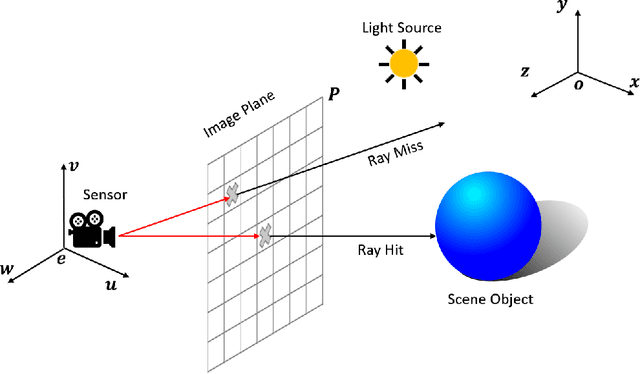
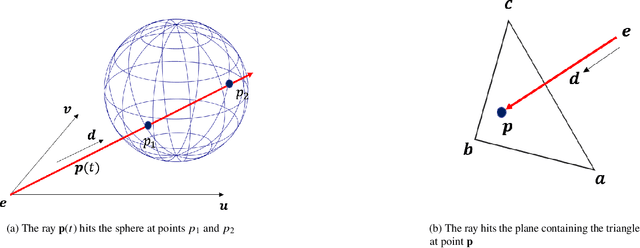
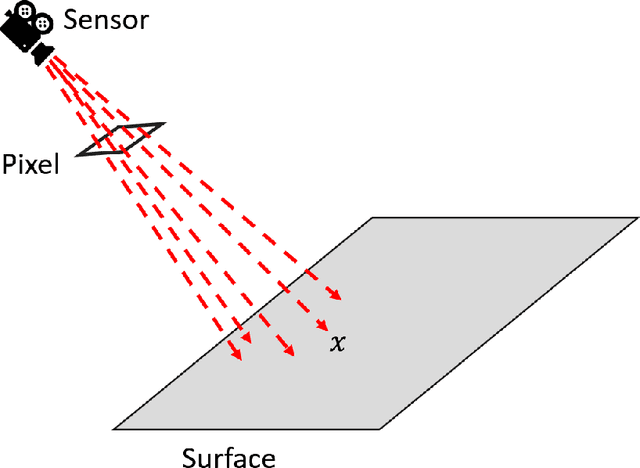
This paper presents Navigation and Rendering Pipeline for Astronautics (NaRPA) - a novel ray-tracing-based computer graphics engine to model and simulate light transport for space-borne imaging. NaRPA incorporates lighting models with attention to atmospheric and shading effects for the synthesis of space-to-space and ground-to-space virtual observations. In addition to image rendering, the engine also possesses point cloud, depth, and contour map generation capabilities to simulate passive and active vision-based sensors and to facilitate the designing, testing, or verification of visual navigation algorithms. Physically based rendering capabilities of NaRPA and the efficacy of the proposed rendering algorithm are demonstrated using applications in representative space-based environments. A key demonstration includes NaRPA as a tool for generating stereo imagery and application in 3D coordinate estimation using triangulation. Another prominent application of NaRPA includes a novel differentiable rendering approach for image-based attitude estimation is proposed to highlight the efficacy of the NaRPA engine for simulating vision-based navigation and guidance operations.
Trusted Multi-Scale Classification Framework for Whole Slide Image
Jul 12, 2022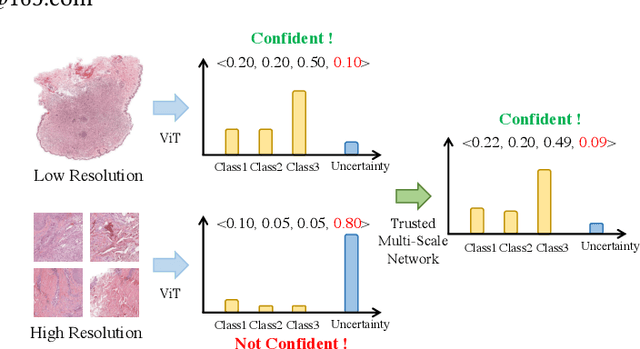


Despite remarkable efforts been made, the classification of gigapixels whole-slide image (WSI) is severely restrained from either the constrained computing resources for the whole slides, or limited utilizing of the knowledge from different scales. Moreover, most of the previous attempts lacked of the ability of uncertainty estimation. Generally, the pathologists often jointly analyze WSI from the different magnifications. If the pathologists are uncertain by using single magnification, then they will change the magnification repeatedly to discover various features of the tissues. Motivated by the diagnose process of the pathologists, in this paper, we propose a trusted multi-scale classification framework for the WSI. Leveraging the Vision Transformer as the backbone for multi branches, our framework can jointly classification modeling, estimating the uncertainty of each magnification of a microscope and integrate the evidence from different magnification. Moreover, to exploit discriminative patches from WSIs and reduce the requirement for computation resources, we propose a novel patch selection schema using attention rollout and non-maximum suppression. To empirically investigate the effectiveness of our approach, empirical experiments are conducted on our WSI classification tasks, using two benchmark databases. The obtained results suggest that the trusted framework can significantly improve the WSI classification performance compared with the state-of-the-art methods.
Clarity: an improved gradient method for producing quality visual counterfactual explanations
Nov 22, 2022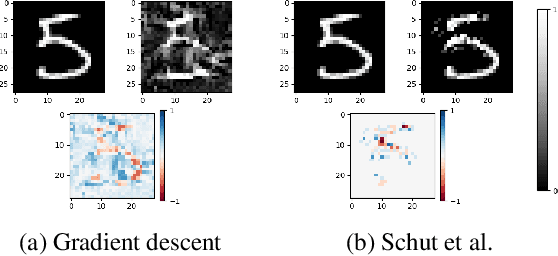

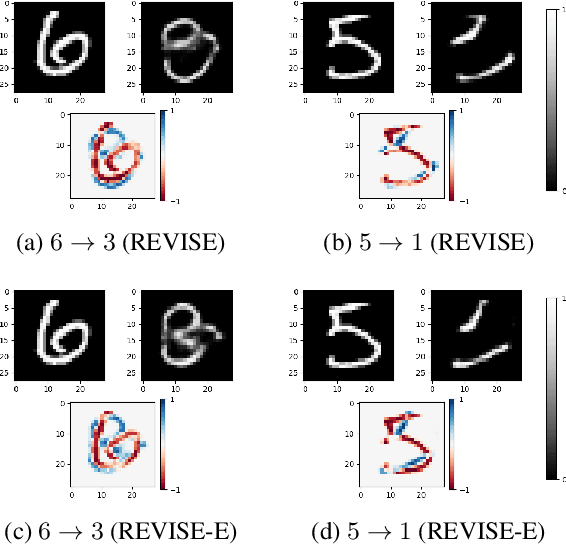

Visual counterfactual explanations identify modifications to an image that would change the prediction of a classifier. We propose a set of techniques based on generative models (VAE) and a classifier ensemble directly trained in the latent space, which all together, improve the quality of the gradient required to compute visual counterfactuals. These improvements lead to a novel classification model, Clarity, which produces realistic counterfactual explanations over all images. We also present several experiments that give insights on why these techniques lead to better quality results than those in the literature. The explanations produced are competitive with the state-of-the-art and emphasize the importance of selecting a meaningful input space for training.
Can denoising diffusion probabilistic models generate realistic astrophysical fields?
Nov 22, 2022
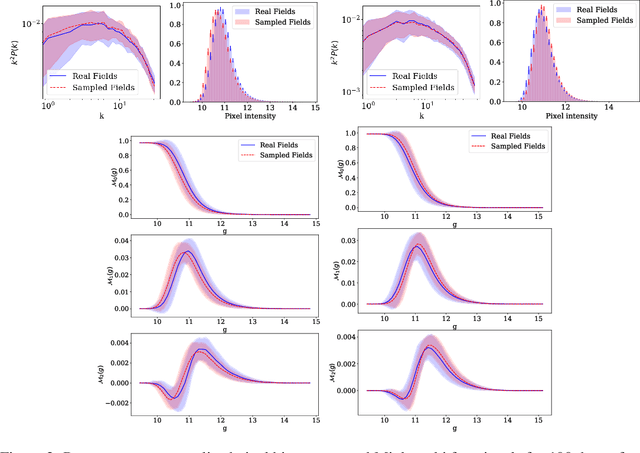
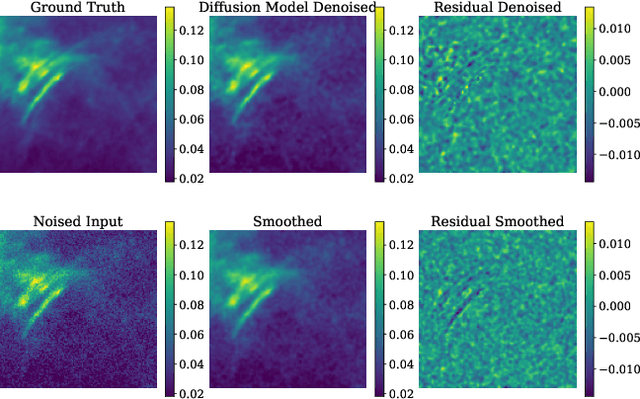
Score-based generative models have emerged as alternatives to generative adversarial networks (GANs) and normalizing flows for tasks involving learning and sampling from complex image distributions. In this work we investigate the ability of these models to generate fields in two astrophysical contexts: dark matter mass density fields from cosmological simulations and images of interstellar dust. We examine the fidelity of the sampled cosmological fields relative to the true fields using three different metrics, and identify potential issues to address. We demonstrate a proof-of-concept application of the model trained on dust in denoising dust images. To our knowledge, this is the first application of this class of models to the interstellar medium.
Adversarially Robust Medical Classification via Attentive Convolutional Neural Networks
Oct 26, 2022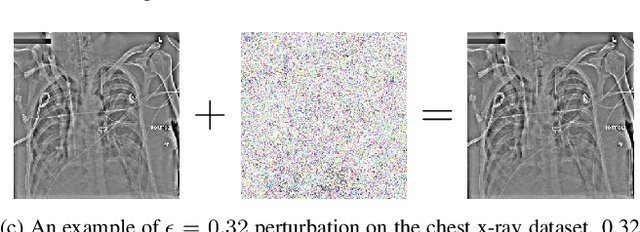
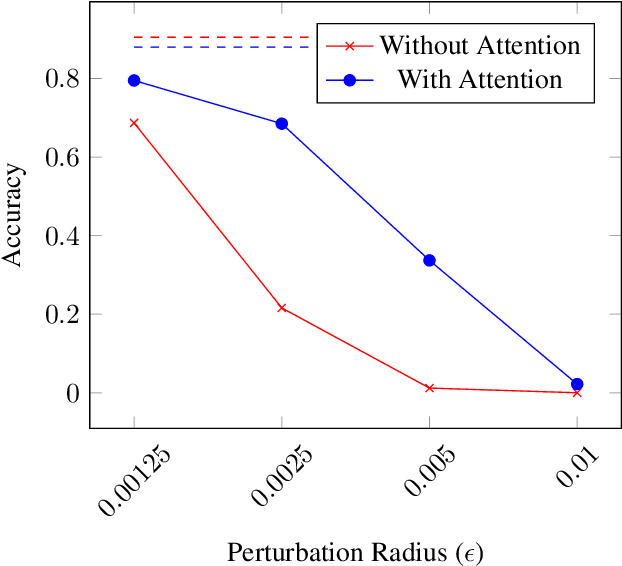
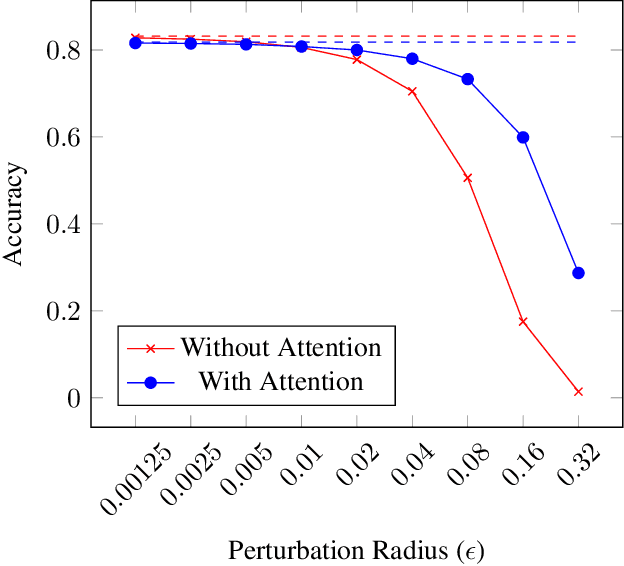
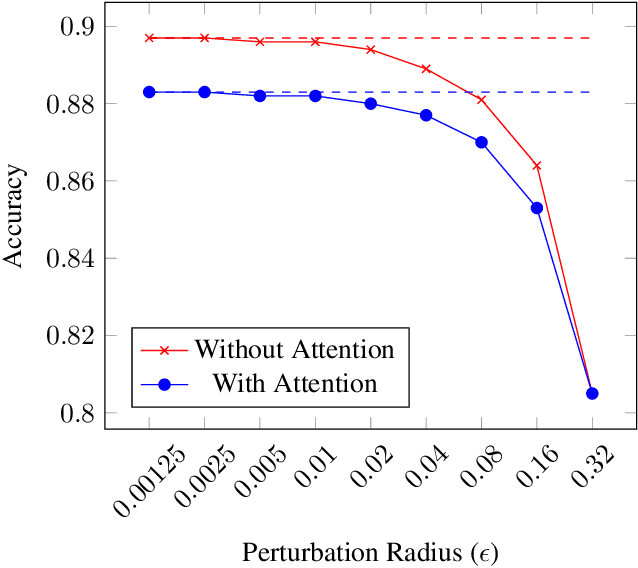
Convolutional neural network-based medical image classifiers have been shown to be especially susceptible to adversarial examples. Such instabilities are likely to be unacceptable in the future of automated diagnoses. Though statistical adversarial example detection methods have proven to be effective defense mechanisms, additional research is necessary that investigates the fundamental vulnerabilities of deep-learning-based systems and how best to build models that jointly maximize traditional and robust accuracy. This paper presents the inclusion of attention mechanisms in CNN-based medical image classifiers as a reliable and effective strategy for increasing robust accuracy without sacrifice. This method is able to increase robust accuracy by up to 16% in typical adversarial scenarios and up to 2700% in extreme cases.
Autoregressive Image Generation using Residual Quantization
Mar 09, 2022
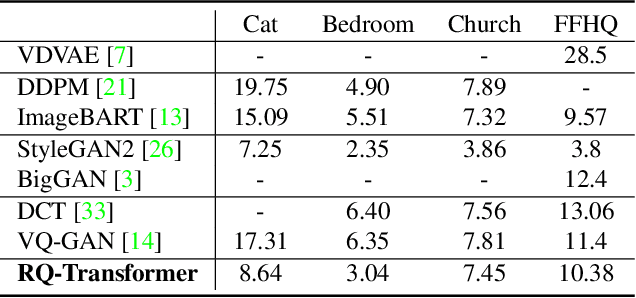
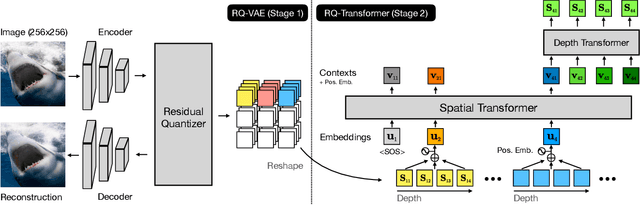

For autoregressive (AR) modeling of high-resolution images, vector quantization (VQ) represents an image as a sequence of discrete codes. A short sequence length is important for an AR model to reduce its computational costs to consider long-range interactions of codes. However, we postulate that previous VQ cannot shorten the code sequence and generate high-fidelity images together in terms of the rate-distortion trade-off. In this study, we propose the two-stage framework, which consists of Residual-Quantized VAE (RQ-VAE) and RQ-Transformer, to effectively generate high-resolution images. Given a fixed codebook size, RQ-VAE can precisely approximate a feature map of an image and represent the image as a stacked map of discrete codes. Then, RQ-Transformer learns to predict the quantized feature vector at the next position by predicting the next stack of codes. Thanks to the precise approximation of RQ-VAE, we can represent a 256$\times$256 image as 8$\times$8 resolution of the feature map, and RQ-Transformer can efficiently reduce the computational costs. Consequently, our framework outperforms the existing AR models on various benchmarks of unconditional and conditional image generation. Our approach also has a significantly faster sampling speed than previous AR models to generate high-quality images.
Self-Guided Diffusion Models
Oct 12, 2022

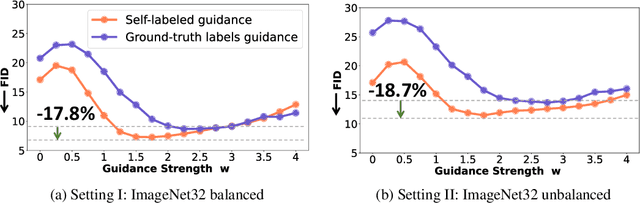

Diffusion models have demonstrated remarkable progress in image generation quality, especially when guidance is used to control the generative process. However, guidance requires a large amount of image-annotation pairs for training and is thus dependent on their availability, correctness and unbiasedness. In this paper, we eliminate the need for such annotation by instead leveraging the flexibility of self-supervision signals to design a framework for self-guided diffusion models. By leveraging a feature extraction function and a self-annotation function, our method provides guidance signals at various image granularities: from the level of holistic images to object boxes and even segmentation masks. Our experiments on single-label and multi-label image datasets demonstrate that self-labeled guidance always outperforms diffusion models without guidance and may even surpass guidance based on ground-truth labels, especially on unbalanced data. When equipped with self-supervised box or mask proposals, our method further generates visually diverse yet semantically consistent images, without the need for any class, box, or segment label annotation. Self-guided diffusion is simple, flexible and expected to profit from deployment at scale.