 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep neural network techniques for monaural speech enhancement: state of the art analysis
Dec 01, 2022
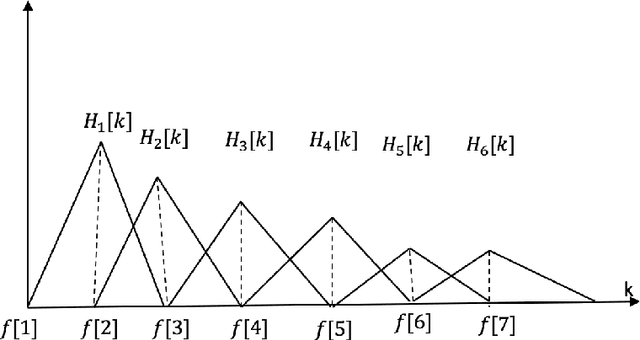
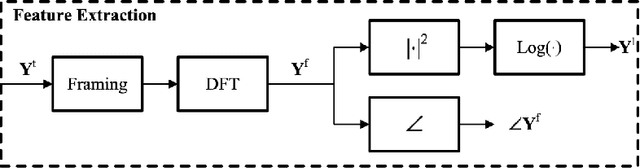

Deep neural networks (DNN) techniques have become pervasive in domains such as natural language processing and computer vision. They have achieved great success in these domains in task such as machine translation and image generation. Due to their success, these data driven techniques have been applied in audio domain. More specifically, DNN models have been applied in speech enhancement domain to achieve denosing, dereverberation and multi-speaker separation in monaural speech enhancement. In this paper, we review some dominant DNN techniques being employed to achieve speech separation. The review looks at the whole pipeline of speech enhancement from feature extraction, how DNN based tools are modelling both global and local features of speech and model training (supervised and unsupervised). We also review the use of speech-enhancement pre-trained models to boost speech enhancement process. The review is geared towards covering the dominant trends with regards to DNN application in speech enhancement in speech obtained via a single speaker.
Neural Representations Reveal Distinct Modes of Class Fitting in Residual Convolutional Networks
Dec 01, 2022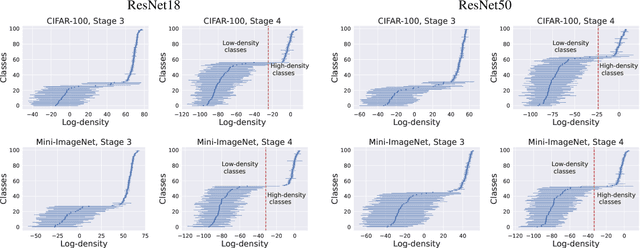
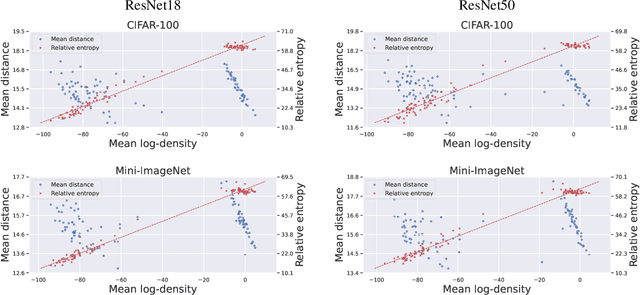
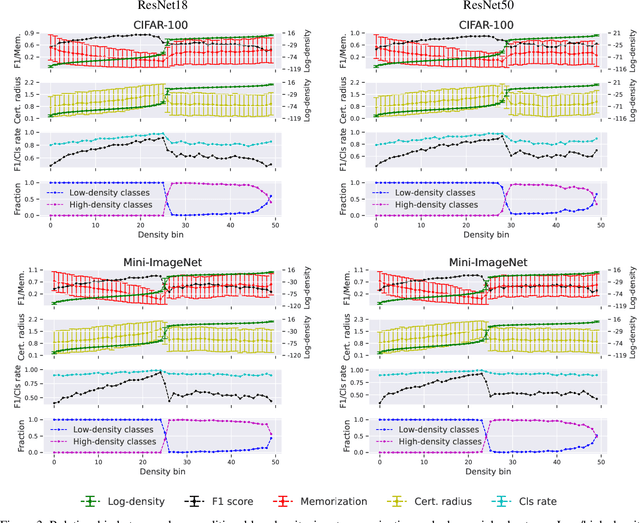
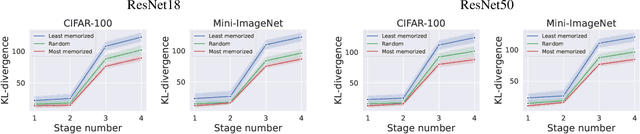
We leverage probabilistic models of neural representations to investigate how residual networks fit classes. To this end, we estimate class-conditional density models for representations learned by deep ResNets. We then use these models to characterize distributions of representations across learned classes. Surprisingly, we find that classes in the investigated models are not fitted in an uniform way. On the contrary: we uncover two groups of classes that are fitted with markedly different distributions of representations. These distinct modes of class-fitting are evident only in the deeper layers of the investigated models, indicating that they are not related to low-level image features. We show that the uncovered structure in neural representations correlate with memorization of training examples and adversarial robustness. Finally, we compare class-conditional distributions of neural representations between memorized and typical examples. This allows us to uncover where in the network structure class labels arise for memorized and standard inputs.
Dataset-free Deep learning Method for Low-Dose CT Image Reconstruction
May 01, 2022

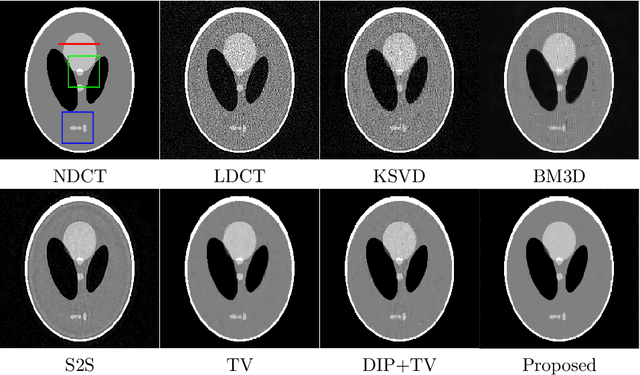
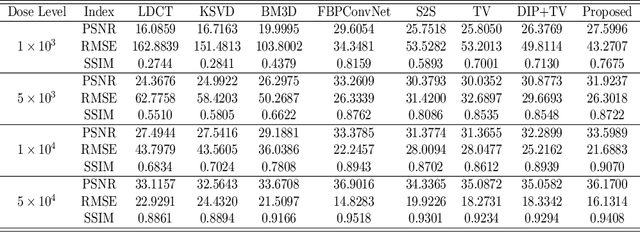
Low-dose CT (LDCT) imaging attracted a considerable interest for the reduction of the object's exposure to X-ray radiation. In recent years, supervised deep learning has been extensively studied for LDCT image reconstruction, which trains a network over a dataset containing many pairs of normal-dose and low-dose images. However, the challenge on collecting many such pairs in the clinical setup limits the application of such supervised-learning-based methods for LDCT image reconstruction in practice. Aiming at addressing the challenges raised by the collection of training dataset, this paper proposed a unsupervised deep learning method for LDCT image reconstruction, which does not require any external training data. The proposed method is built on a re-parametrization technique for Bayesian inference via deep network with random weights, combined with additional total variational (TV) regularization. The experiments show that the proposed method noticeably outperforms existing dataset-free image reconstruction methods on the test data.
LSEH: Semantically Enhanced Hard Negatives for Cross-modal Information Retrieval
Oct 10, 2022
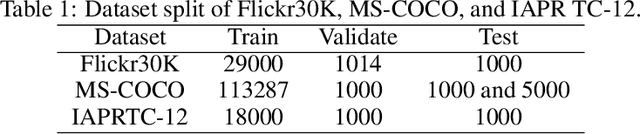
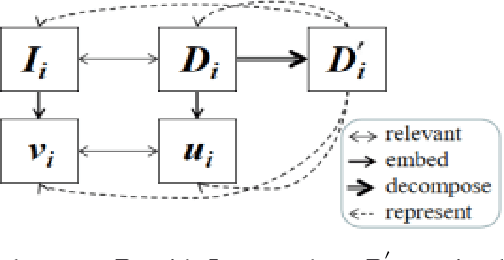
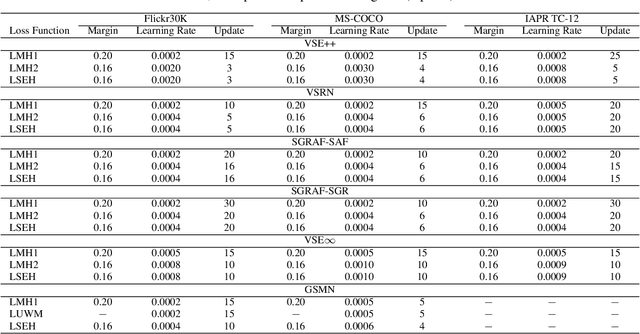
Visual Semantic Embedding (VSE) aims to extract the semantics of images and their descriptions, and embed them into the same latent space for cross-modal information retrieval. Most existing VSE networks are trained by adopting a hard negatives loss function which learns an objective margin between the similarity of relevant and irrelevant image-description embedding pairs. However, the objective margin in the hard negatives loss function is set as a fixed hyperparameter that ignores the semantic differences of the irrelevant image-description pairs. To address the challenge of measuring the optimal similarities between image-description pairs before obtaining the trained VSE networks, this paper presents a novel approach that comprises two main parts: (1) finds the underlying semantics of image descriptions; and (2) proposes a novel semantically enhanced hard negatives loss function, where the learning objective is dynamically determined based on the optimal similarity scores between irrelevant image-description pairs. Extensive experiments were carried out by integrating the proposed methods into five state-of-the-art VSE networks that were applied to three benchmark datasets for cross-modal information retrieval tasks. The results revealed that the proposed methods achieved the best performance and can also be adopted by existing and future VSE networks.
PiPa: Pixel- and Patch-wise Self-supervised Learning for Domain Adaptative Semantic Segmentation
Nov 14, 2022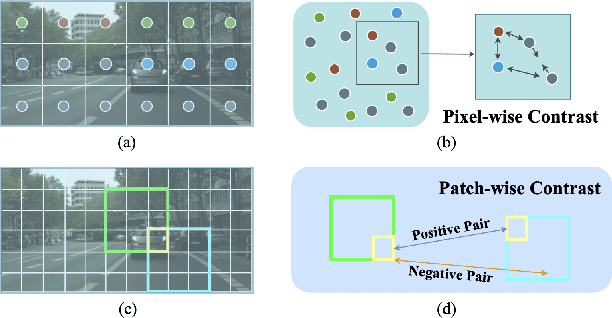
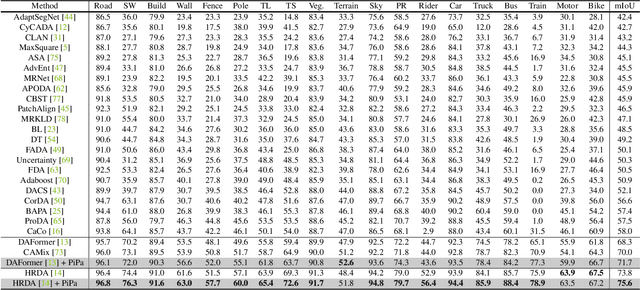
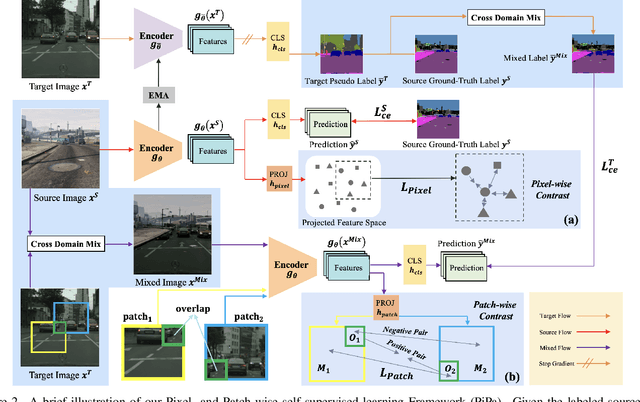
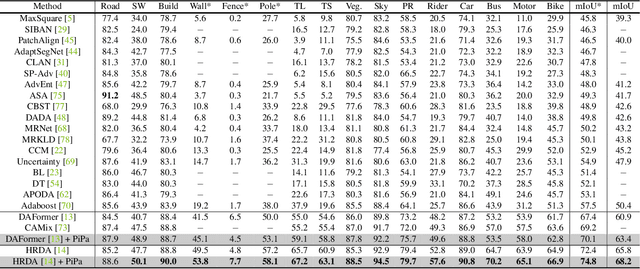
Unsupervised Domain Adaptation (UDA) aims to enhance the generalization of the learned model to other domains. The domain-invariant knowledge is transferred from the model trained on labeled source domain, e.g., video game, to unlabeled target domains, e.g., real-world scenarios, saving annotation expenses. Existing UDA methods for semantic segmentation usually focus on minimizing the inter-domain discrepancy of various levels, e.g., pixels, features, and predictions, for extracting domain-invariant knowledge. However, the primary intra-domain knowledge, such as context correlation inside an image, remains underexplored. In an attempt to fill this gap, we propose a unified pixel- and patch-wise self-supervised learning framework, called PiPa, for domain adaptive semantic segmentation that facilitates intra-image pixel-wise correlations and patch-wise semantic consistency against different contexts. The proposed framework exploits the inherent structures of intra-domain images, which: (1) explicitly encourages learning the discriminative pixel-wise features with intra-class compactness and inter-class separability, and (2) motivates the robust feature learning of the identical patch against different contexts or fluctuations. Extensive experiments verify the effectiveness of the proposed method, which obtains competitive accuracy on the two widely-used UDA benchmarks, i.e., 75.6 mIoU on GTA to Cityscapes and 68.2 mIoU on Synthia to Cityscapes. Moreover, our method is compatible with other UDA approaches to further improve the performance without introducing extra parameters.
Mixed Supervision of Histopathology Improves Prostate Cancer Classification from MRI
Dec 13, 2022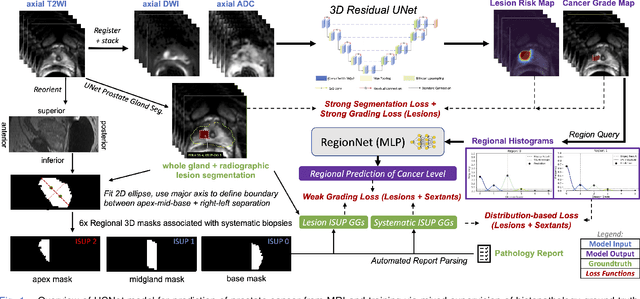
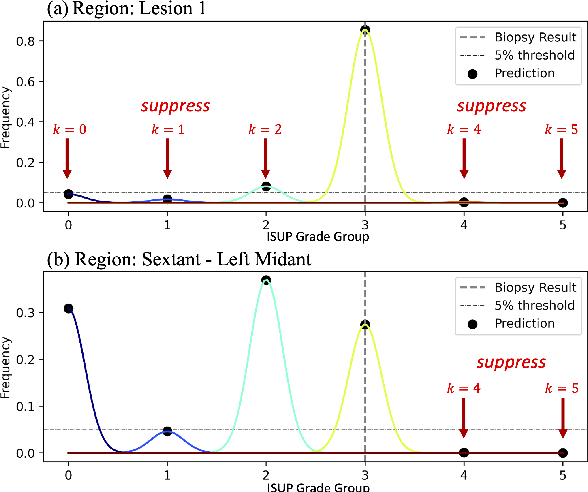
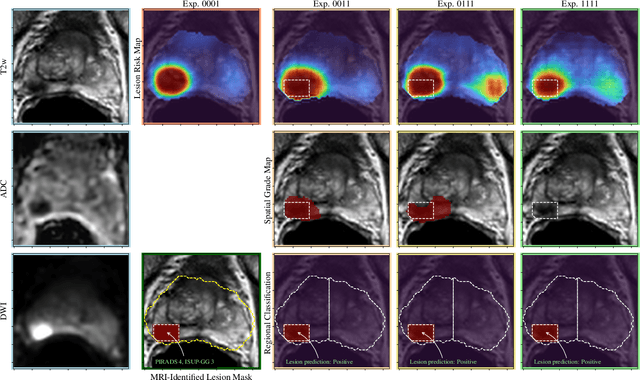
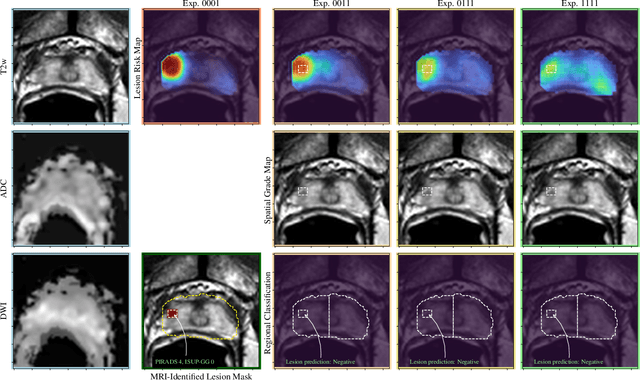
Non-invasive prostate cancer detection from MRI has the potential to revolutionize patient care by providing early detection of clinically-significant disease (ISUP grade group >= 2), but has thus far shown limited positive predictive value. To address this, we present an MRI-based deep learning method for predicting clinically significant prostate cancer applicable to a patient population with subsequent ground truth biopsy results ranging from benign pathology to ISUP grade group~5. Specifically, we demonstrate that mixed supervision via diverse histopathological ground truth improves classification performance despite the cost of reduced concordance with image-based segmentation. That is, where prior approaches have utilized pathology results as ground truth derived from targeted biopsies and whole-mount prostatectomy to strongly supervise the localization of clinically significant cancer, our approach also utilizes weak supervision signals extracted from nontargeted systematic biopsies with regional localization to improve overall performance. Our key innovation is performing regression by distribution rather than simply by value, enabling use of additional pathology findings traditionally ignored by deep learning strategies. We evaluated our model on a dataset of 973 (testing n=160) multi-parametric prostate MRI exams collected at UCSF from 2015-2018 followed by MRI/ultrasound fusion (targeted) biopsy and systematic (nontargeted) biopsy of the prostate gland, demonstrating that deep networks trained with mixed supervision of histopathology can significantly exceed the performance of the Prostate Imaging-Reporting and Data System (PI-RADS) clinical standard for prostate MRI interpretation.
CNN-transformer mixed model for object detection
Dec 13, 2022
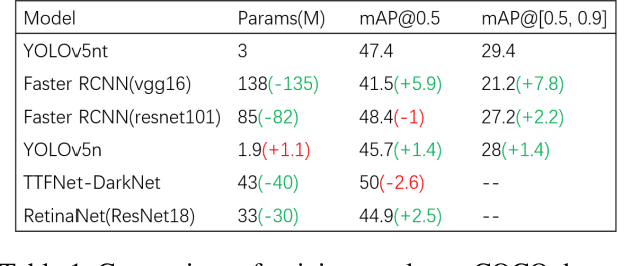
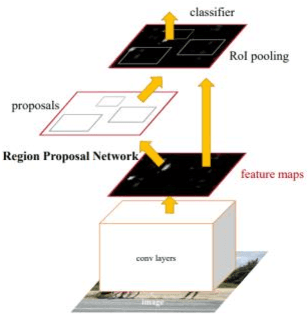

Object detection, one of the three main tasks of computer vision, has been used in various applications. The main process is to use deep neural networks to extract the features of an image and then use the features to identify the class and location of an object. Therefore, the main direction to improve the accuracy of object detection tasks is to improve the neural network to extract features better. In this paper, I propose a convolutional module with a transformer[1], which aims to improve the recognition accuracy of the model by fusing the detailed features extracted by CNN[2] with the global features extracted by a transformer and significantly reduce the computational effort of the transformer module by deflating the feature mAP. The main execution steps are convolutional downsampling to reduce the feature map size, then self-attention calculation and upsampling, and finally concatenation with the initial input. In the experimental part, after splicing the block to the end of YOLOv5n[3] and training 300 epochs on the coco dataset, the mAP improved by 1.7% compared with the previous YOLOv5n, and the mAP curve did not show any saturation phenomenon, so there is still potential for improvement. After 100 rounds of training on the Pascal VOC dataset, the accuracy of the results reached 81%, which is 4.6 better than the faster RCNN[4] using resnet101[5] as the backbone, but the number of parameters is less than one-twentieth of it.
2T-UNET: A Two-Tower UNet with Depth Clues for Robust Stereo Depth Estimation
Oct 27, 2022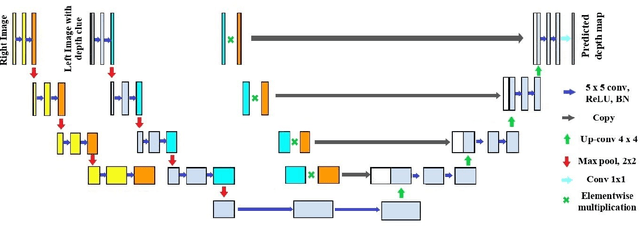
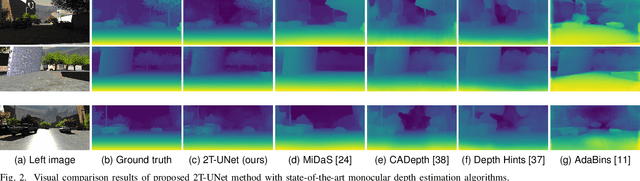
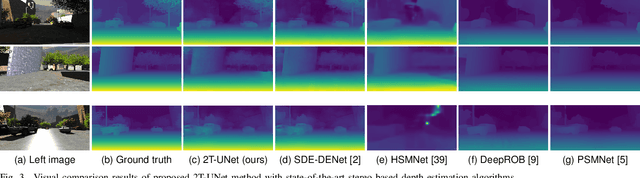

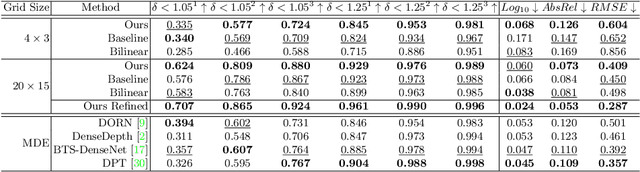
Stereo correspondence matching is an essential part of the multi-step stereo depth estimation process. This paper revisits the depth estimation problem, avoiding the explicit stereo matching step using a simple two-tower convolutional neural network. The proposed algorithm is entitled as 2T-UNet. The idea behind 2T-UNet is to replace cost volume construction with twin convolution towers. These towers have an allowance for different weights between them. Additionally, the input for twin encoders in 2T-UNet are different compared to the existing stereo methods. Generally, a stereo network takes a right and left image pair as input to determine the scene geometry. However, in the 2T-UNet model, the right stereo image is taken as one input and the left stereo image along with its monocular depth clue information, is taken as the other input. Depth clues provide complementary suggestions that help enhance the quality of predicted scene geometry. The 2T-UNet surpasses state-of-the-art monocular and stereo depth estimation methods on the challenging Scene flow dataset, both quantitatively and qualitatively. The architecture performs incredibly well on complex natural scenes, highlighting its usefulness for various real-time applications. Pretrained weights and code will be made readily available.
CAMANet: Class Activation Map Guided Attention Network for Radiology Report Generation
Nov 02, 2022
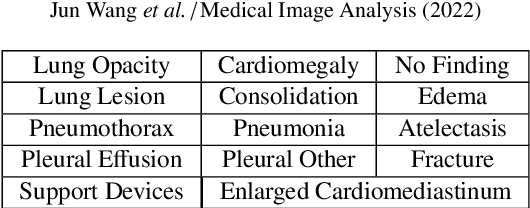
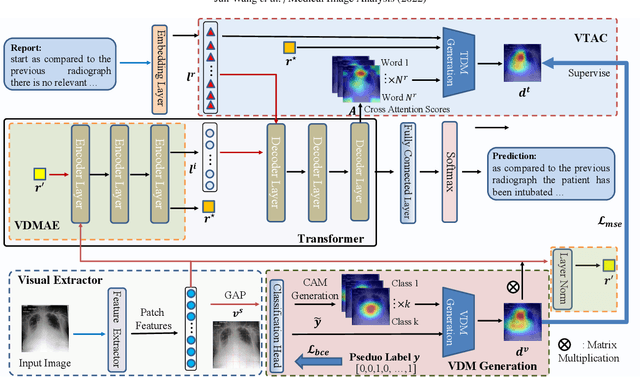
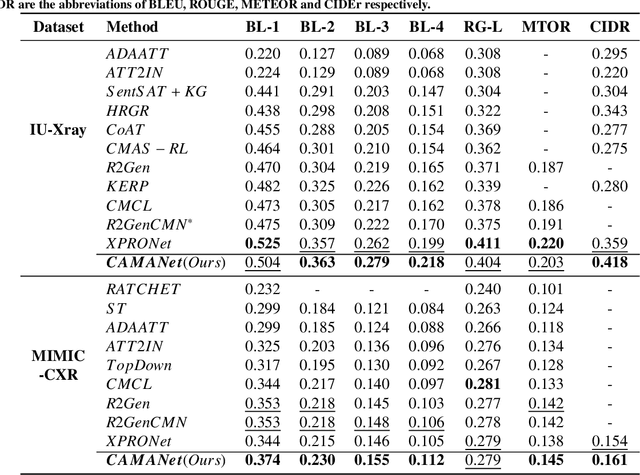
Radiology report generation (RRG) has gained increasing research attention because of its huge potential to mitigate medical resource shortages and aid the process of disease decision making by radiologists. Recent advancements in Radiology Report Generation (RRG) are largely driven by improving models' capabilities in encoding single-modal feature representations, while few studies explore explicitly the cross-modal alignment between image regions and words. Radiologists typically focus first on abnormal image regions before they compose the corresponding text descriptions, thus cross-modal alignment is of great importance to learn an abnormality-aware RRG model. Motivated by this, we propose a Class Activation Map guided Attention Network (CAMANet) which explicitly promotes cross-modal alignment by employing the aggregated class activation maps to supervise the cross-modal attention learning, and simultaneously enriches the discriminative information. Experimental results demonstrate that CAMANet outperforms previous SOTA methods on two commonly used RRG benchmarks.
3D Scene Inference from Transient Histograms
Nov 09, 2022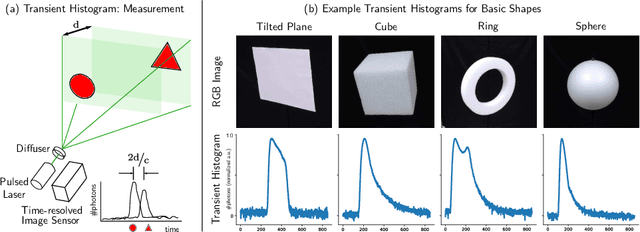
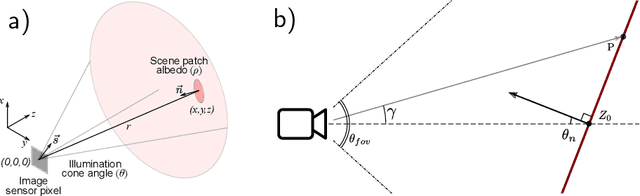
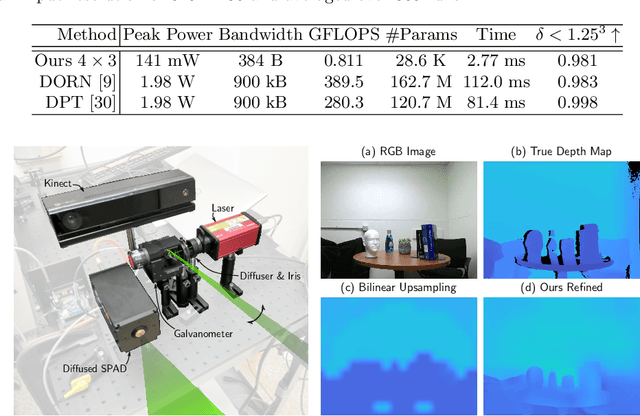
Time-resolved image sensors that capture light at pico-to-nanosecond timescales were once limited to niche applications but are now rapidly becoming mainstream in consumer devices. We propose low-cost and low-power imaging modalities that capture scene information from minimal time-resolved image sensors with as few as one pixel. The key idea is to flood illuminate large scene patches (or the entire scene) with a pulsed light source and measure the time-resolved reflected light by integrating over the entire illuminated area. The one-dimensional measured temporal waveform, called \emph{transient}, encodes both distances and albedoes at all visible scene points and as such is an aggregate proxy for the scene's 3D geometry. We explore the viability and limitations of the transient waveforms by themselves for recovering scene information, and also when combined with traditional RGB cameras. We show that plane estimation can be performed from a single transient and that using only a few more it is possible to recover a depth map of the whole scene. We also show two proof-of-concept hardware prototypes that demonstrate the feasibility of our approach for compact, mobile, and budget-limited applications.