 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Modulated Contrast for Versatile Image Synthesis
Mar 17, 2022
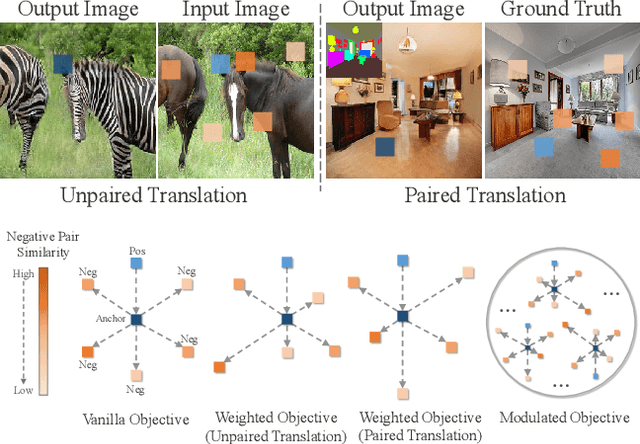
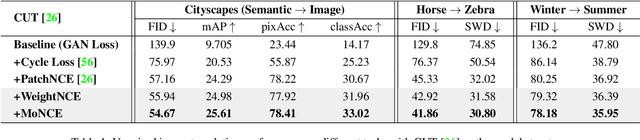

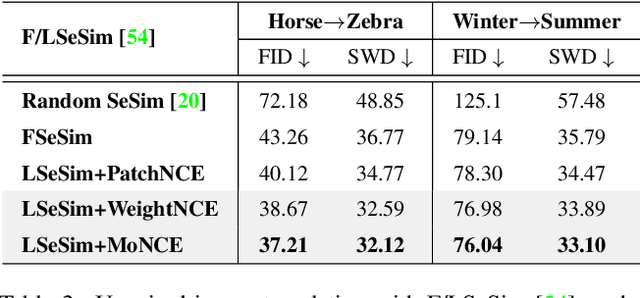
Perceiving the similarity between images has been a long-standing and fundamental problem underlying various visual generation tasks. Predominant approaches measure the inter-image distance by computing pointwise absolute deviations, which tends to estimate the median of instance distributions and leads to blurs and artifacts in the generated images. This paper presents MoNCE, a versatile metric that introduces image contrast to learn a calibrated metric for the perception of multifaceted inter-image distances. Unlike vanilla contrast which indiscriminately pushes negative samples from the anchor regardless of their similarity, we propose to re-weight the pushing force of negative samples adaptively according to their similarity to the anchor, which facilitates the contrastive learning from informative negative samples. Since multiple patch-level contrastive objectives are involved in image distance measurement, we introduce optimal transport in MoNCE to modulate the pushing force of negative samples collaboratively across multiple contrastive objectives. Extensive experiments over multiple image translation tasks show that the proposed MoNCE outperforms various prevailing metrics substantially. The code is available at https://github.com/fnzhan/MoNCE.
Motion and Context-Aware Audio-Visual Conditioned Video Prediction
Dec 09, 2022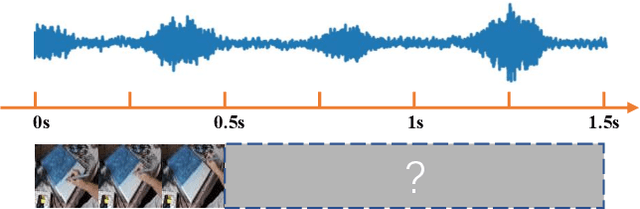



Existing state-of-the-art method for audio-visual conditioned video prediction uses the latent codes of the audio-visual frames from a multimodal stochastic network and a frame encoder to predict the next visual frame. However, a direct inference of per-pixel intensity for the next visual frame from the latent codes is extremely challenging because of the high-dimensional image space. To this end, we propose to decouple the audio-visual conditioned video prediction into motion and appearance modeling. The first part is the multimodal motion estimation module that learns motion information as optical flow from the given audio-visual clip. The second part is the context-aware refinement module that uses the predicted optical flow to warp the current visual frame into the next visual frame and refines it base on the given audio-visual context. Experimental results show that our method achieves competitive results on existing benchmarks.
When Spectral Modeling Meets Convolutional Networks: A Method for Discovering Reionization-era Lensed Quasars in Multi-band Imaging Data
Nov 26, 2022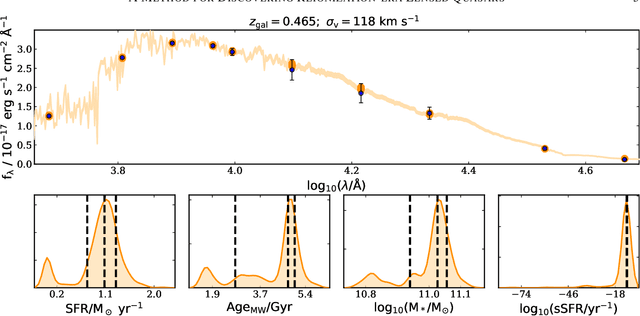
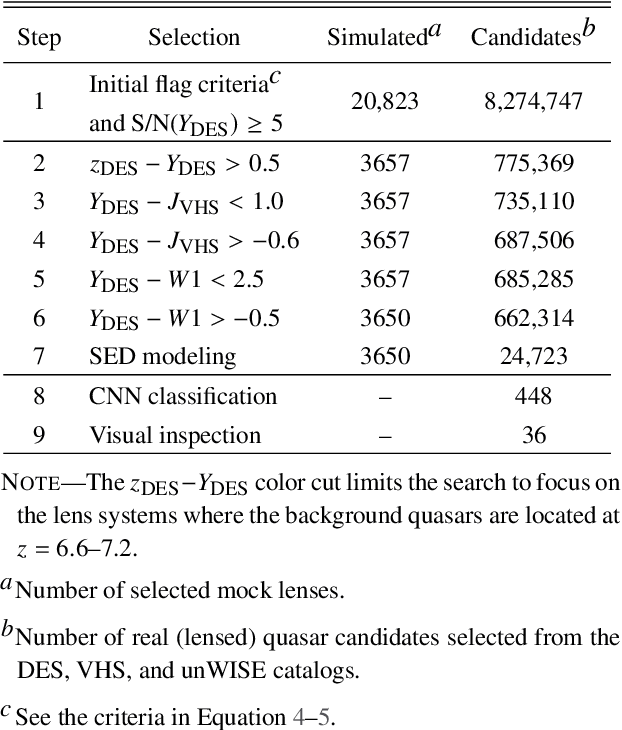
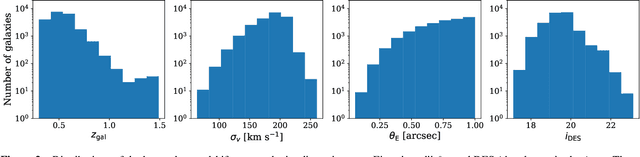
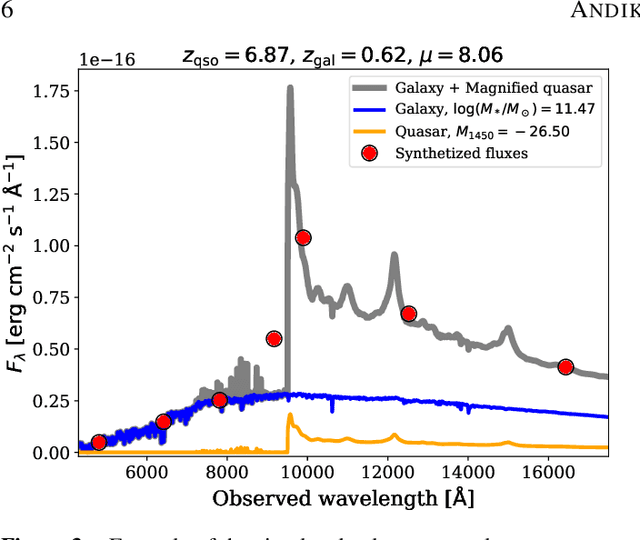
Over the last two decades, around three hundred quasars have been discovered at $z\gtrsim6$, yet only one was identified as being strong-gravitationally lensed. We explore a new approach, enlarging the permitted spectral parameter space while introducing a new spatial geometry veto criterion, implemented via image-based deep learning. We made the first application of this approach in a systematic search for reionization-era lensed quasars, using data from the Dark Energy Survey, the Visible and Infrared Survey Telescope for Astronomy Hemisphere Survey, and the Wide-field Infrared Survey Explorer. Our search method consists of two main parts: (i) pre-selection of the candidates based on their spectral energy distributions (SEDs) using catalog-level photometry and (ii) relative probabilities calculation of being a lens or some contaminant utilizing a convolutional neural network (CNN) classification. The training datasets are constructed by painting deflected point-source lights over actual galaxy images to generate realistic galaxy-quasar lens models, optimized to find systems with small image separations, i.e., Einstein radii of $\theta_\mathrm{E} \leq 1$ arcsec. Visual inspection is then performed for sources with CNN scores of $P_\mathrm{lens} > 0.1$, which led us to obtain 36 newly-selected lens candidates, waiting for spectroscopic confirmation. These findings show that automated SED modeling and deep learning pipelines, supported by modest human input, are a promising route for detecting strong lenses from large catalogs that can overcome the veto limitations of primarily dropout-based SED selection approaches.
Cross-domain Microscopy Cell Counting by Disentangled Transfer Learning
Nov 26, 2022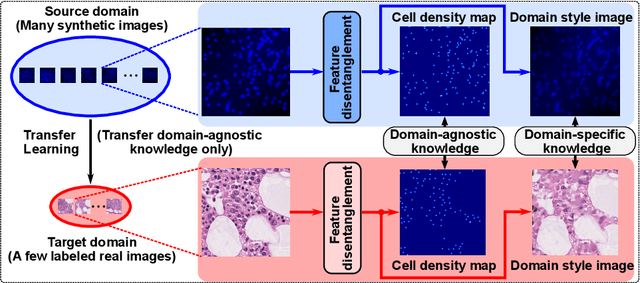
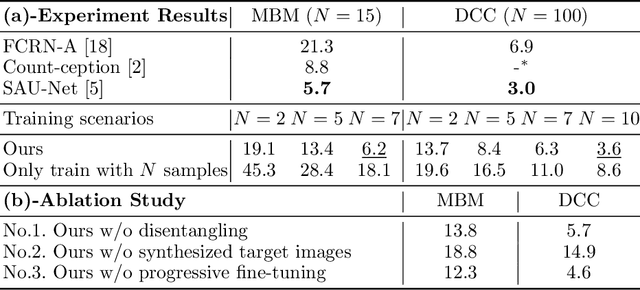
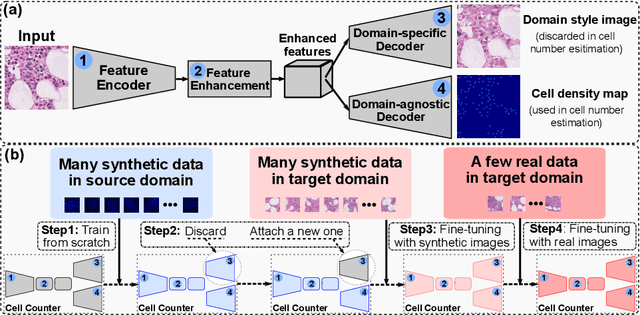
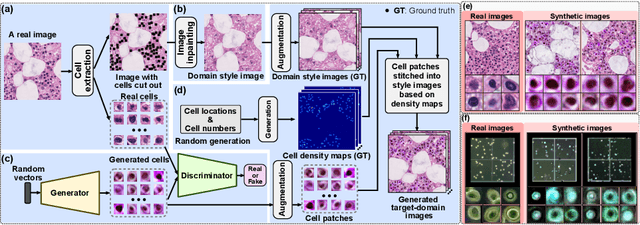
Microscopy cell images of biological experiments on different tissues/organs/imaging conditions usually contain cells with various shapes and appearances on different image backgrounds, making a cell counting model trained in a source domain hard to be transferred to a new target domain. Thus, costly manual annotation is required to train deep learning-based cell counting models across different domains. Instead, we propose a cross-domain cell counting approach with only a little human annotation effort. First, we design a cell counting network that can disentangle domain-specific knowledge and domain-agnostic knowledge in cell images, which are related to the generation of domain style images and cell density maps, respectively. Secondly, we propose an image synthesis method capable of synthesizing a large number of images based on a few annotated ones. Finally, we use a public dataset of synthetic cells, which has no annotation cost at all as the source domain to train our cell counting network; then, only the domain-agnostic knowledge in the trained model is transferred to a new target domain of real cell images, by progressively fine-tuning the trained model using synthesized target-domain images and a few annotated ones. Evaluated on two public target datasets of real cell images, our cross-domain cell counting approach that only needs annotation on a few images in a new target domain achieves good performance, compared to state-of-the-art methods that rely on fully annotated training images in the target domain.
Quantifying Societal Bias Amplification in Image Captioning
Mar 29, 2022
We study societal bias amplification in image captioning. Image captioning models have been shown to perpetuate gender and racial biases, however, metrics to measure, quantify, and evaluate the societal bias in captions are not yet standardized. We provide a comprehensive study on the strengths and limitations of each metric, and propose LIC, a metric to study captioning bias amplification. We argue that, for image captioning, it is not enough to focus on the correct prediction of the protected attribute, and the whole context should be taken into account. We conduct extensive evaluation on traditional and state-of-the-art image captioning models, and surprisingly find that, by only focusing on the protected attribute prediction, bias mitigation models are unexpectedly amplifying bias.
Denoising method for dynamic contrast-enhanced CT perfusion studies using three-dimensional deep image prior as a simultaneous spatial and temporal regularizer
Aug 31, 2022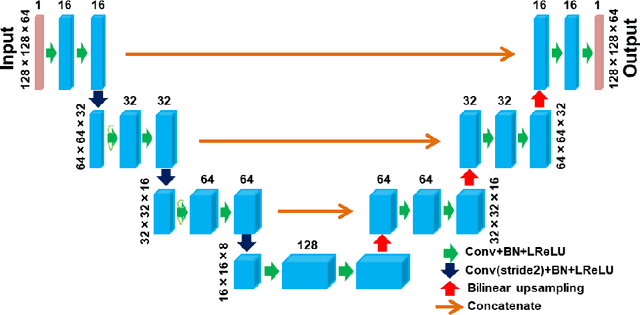
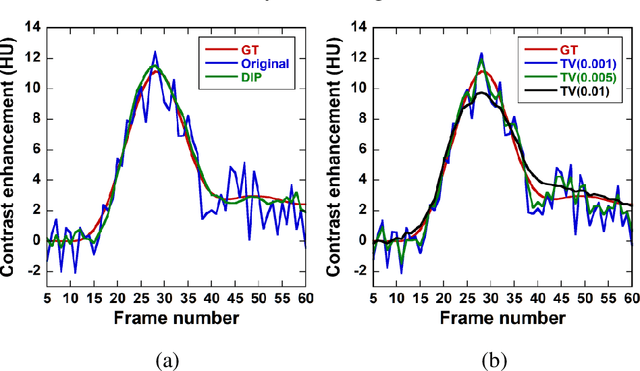
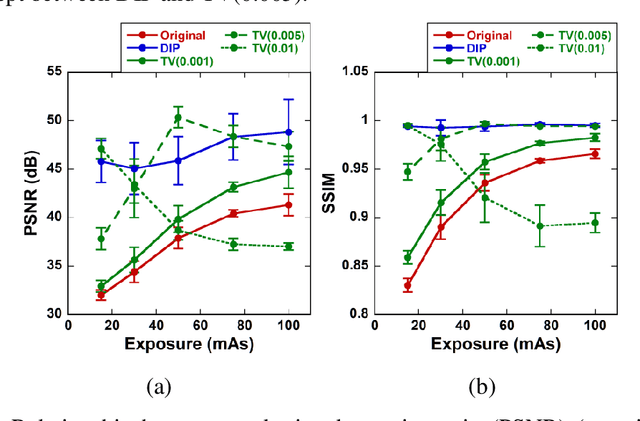
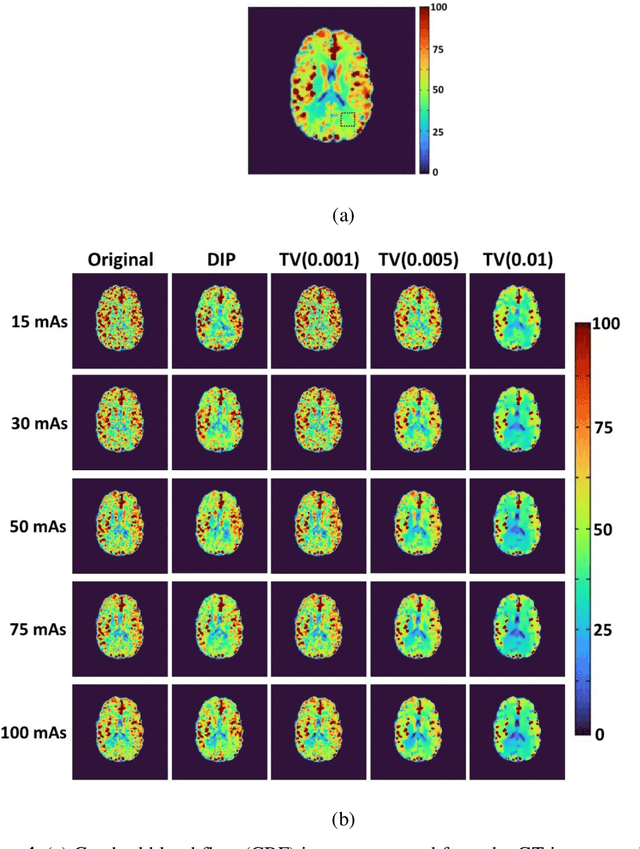
This study aimed to propose a denoising method for dynamic contrast-enhanced computed tomography (DCE-CT) perfusion studies using a three-dimensional deep image prior (DIP), and to investigate its usefulness in comparison with total variation (TV)-based methods with different regularization parameter (alpha) values through simulation studies. In the proposed DIP method, the DIP was incorporated into the constrained optimization problem for image denoising as a simultaneous spatial and temporal regularizer, which was solved using the alternating direction method of multipliers. In the simulation studies, DCE-CT images were generated using a digital brain phantom and their noise level was varied using the X-ray exposure noise model with different exposures (15, 30, 50, 75, and 100 mAs). Cerebral blood flow (CBF) images were generated from the original contrast enhancement (CE) images and those obtained by the DIP and TV methods using block-circulant singular value decomposition. The quality of the CE images was evaluated using the peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM). To compare the CBF images obtained by the different methods and those generated from the ground truth images, linear regression analysis was performed. When using the DIP method, the PSNR and SSIM were not significantly dependent on the exposure, and the SSIM was the highest for all exposures. When using the TV methods, they were significantly dependent on the exposure and alpha values. The results of the linear regression analysis suggested that the linearity of the CBF images obtained by the DIP method was superior to those obtained from the original CE images and by the TV methods. Our preliminary results suggest that the DIP method is useful for denoising DCE-CT images at ultra-low to low exposures and for improving the accuracy of the CBF images generated from them.
Three-dimensional Microstructural Image Synthesis from 2D Backscattered Electron Image of Cement Paste
Apr 04, 2022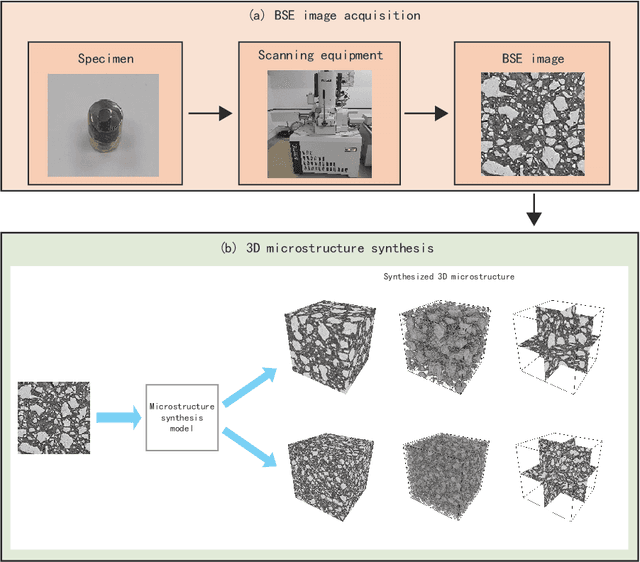
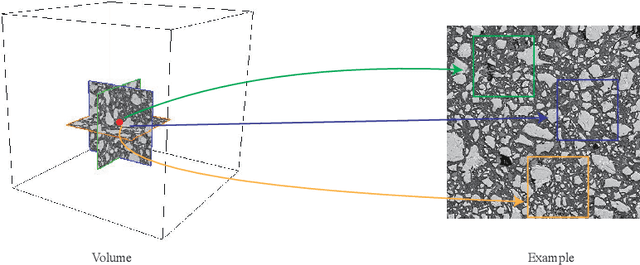
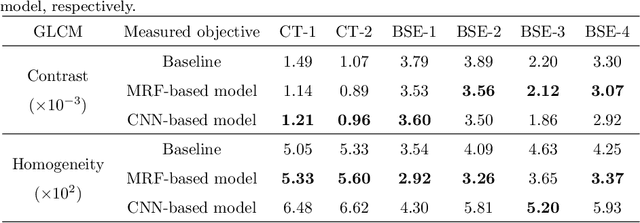
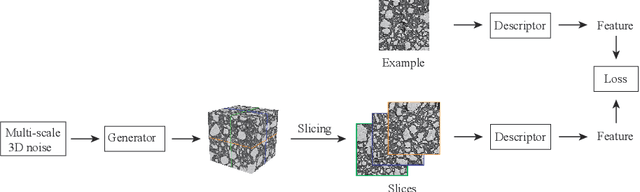
The microstructure is significant for exploring the physical properties of hardened cement paste. In general, the microstructures of hardened cement paste are obtained by microscopy. As a popular method, scanning electron microscopy (SEM) can acquire high-quality 2D images but fails to obtain 3D microstructures.Although several methods, such as microtomography (Micro-CT) and Focused Ion Beam Scanning Electron Microscopy (FIB-SEM), can acquire 3D microstructures, these fail to obtain high-quality 3D images or consume considerable cost. To address these issues, a method based on solid texture synthesis is proposed, synthesizing high-quality 3D microstructural image of hardened cement paste. This method includes 2D backscattered electron (BSE) image acquisition and 3D microstructure synthesis phases. In the approach, the synthesis model is based on solid texture synthesis, capturing microstructure information of the acquired 2D BSE image and generating high-quality 3D microstructures. In experiments, the method is verified on actual 3D Micro-CT images and 2D BSE images. Finally, qualitative experiments demonstrate that the 3D microstructures generated by our method have similar visual characteristics to the given 2D example. Furthermore, quantitative experiments prove that the synthetic 3D results are consistent with the actual instance in terms of porosity, particle size distribution, and grey scale co-occurrence matrix.
OutCast: Outdoor Single-image Relighting with Cast Shadows
Apr 20, 2022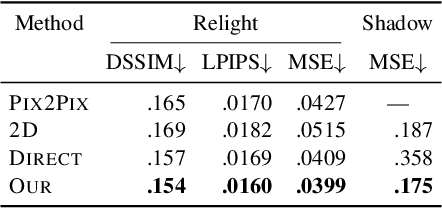
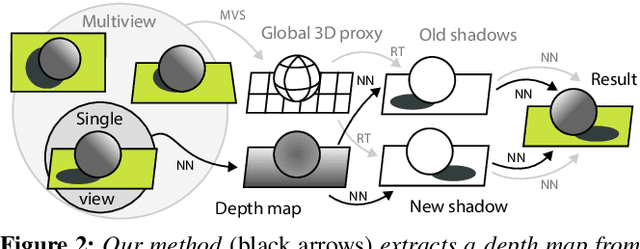
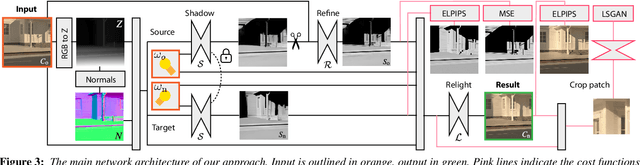
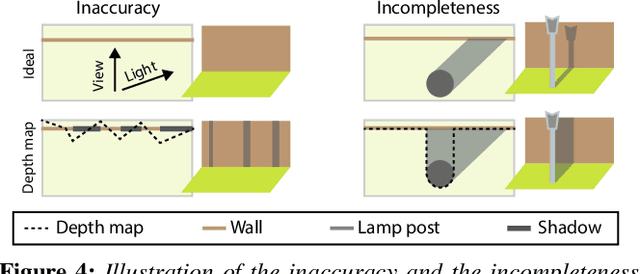
We propose a relighting method for outdoor images. Our method mainly focuses on predicting cast shadows in arbitrary novel lighting directions from a single image while also accounting for shading and global effects such the sun light color and clouds. Previous solutions for this problem rely on reconstructing occluder geometry, e.g. using multi-view stereo, which requires many images of the scene. Instead, in this work we make use of a noisy off-the-shelf single-image depth map estimation as a source of geometry. Whilst this can be a good guide for some lighting effects, the resulting depth map quality is insufficient for directly ray-tracing the shadows. Addressing this, we propose a learned image space ray-marching layer that converts the approximate depth map into a deep 3D representation that is fused into occlusion queries using a learned traversal. Our proposed method achieves, for the first time, state-of-the-art relighting results, with only a single image as input. For supplementary material visit our project page at: https://dgriffiths.uk/outcast.
Ultra-fast image categorization in vivo and in silico
May 12, 2022
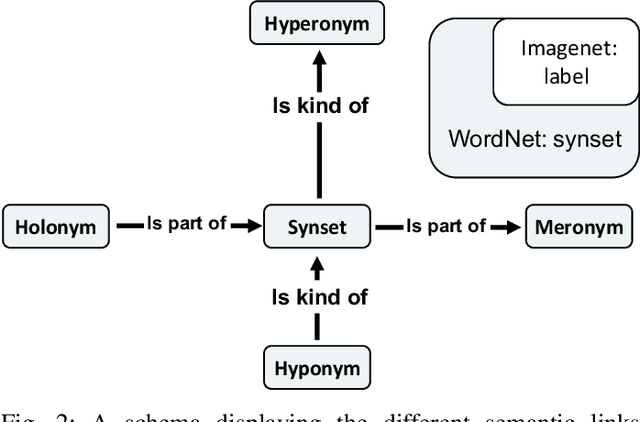
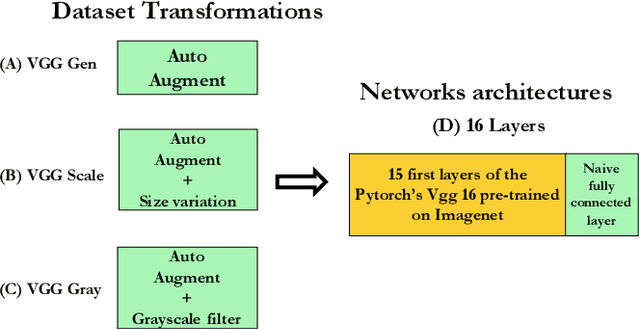
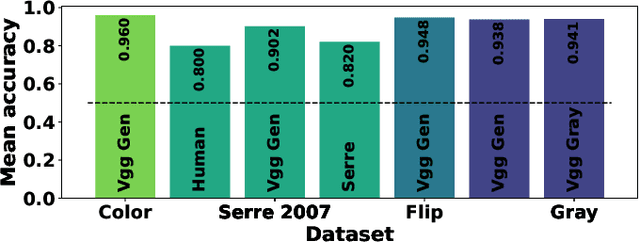
Humans are able to robustly categorize images and can, for instance, detect the presence of an animal in a briefly flashed image in as little as 120 ms. Initially inspired by neuroscience, deep-learning algorithms literally bloomed up in the last decade such that the accuracy of machines is at present superior to humans for visual recognition tasks. However, these artificial networks are usually trained and evaluated on very specific tasks, for instance on the 1000 separate categories of ImageNet. In that regard, biological visual systems are more flexible and efficient compared to artificial systems on generic ecological tasks. In order to deepen this comparison, we re-trained the standard VGG Convolutional Neural Network (CNN) on two independent tasks which are ecologically relevant for humans: one task defined as detecting the presence of an animal and the other as detecting the presence of an artifact. We show that retraining the network achieves human-like performance level which is reported in psychophysical tasks. We also compare the accuracy of the detection on an image-by-image basis. This showed in particular that the two models perform better when combining their outputs. Indeed, animals (e.g. lions) tend to be less present in photographs containing artifacts (e.g. buildings). These re-trained models could reproduce some unexpected behavioral observations from humans psychophysics such as the robustness to rotations (e.g. upside-down or slanted image) or to a grayscale transformation.
Perceptual Grouping in Vision-Language Models
Oct 18, 2022
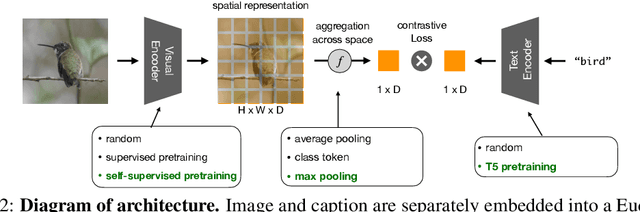
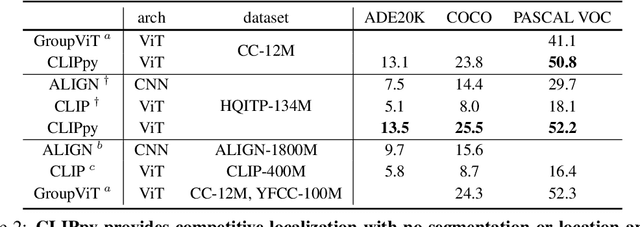
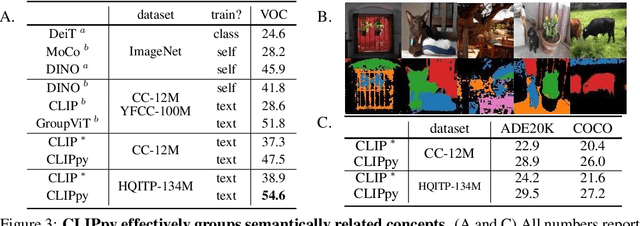
Recent advances in zero-shot image recognition suggest that vision-language models learn generic visual representations with a high degree of semantic information that may be arbitrarily probed with natural language phrases. Understanding an image, however, is not just about understanding what content resides within an image, but importantly, where that content resides. In this work we examine how well vision-language models are able to understand where objects reside within an image and group together visually related parts of the imagery. We demonstrate how contemporary vision and language representation learning models based on contrastive losses and large web-based data capture limited object localization information. We propose a minimal set of modifications that results in models that uniquely learn both semantic and spatial information. We measure this performance in terms of zero-shot image recognition, unsupervised bottom-up and top-down semantic segmentations, as well as robustness analyses. We find that the resulting model achieves state-of-the-art results in terms of unsupervised segmentation, and demonstrate that the learned representations are uniquely robust to spurious correlations in datasets designed to probe the causal behavior of vision models.