 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Assessing the ability of generative adversarial networks to learn canonical medical image statistics
Apr 27, 2022
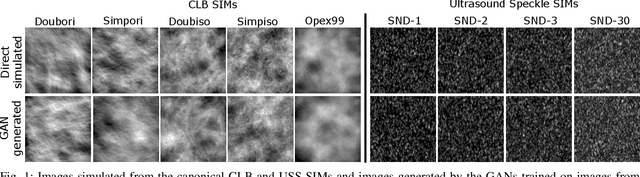
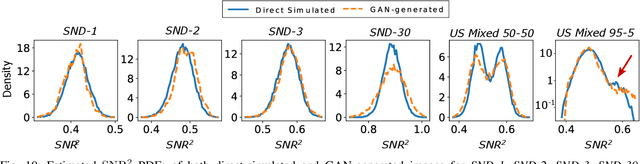
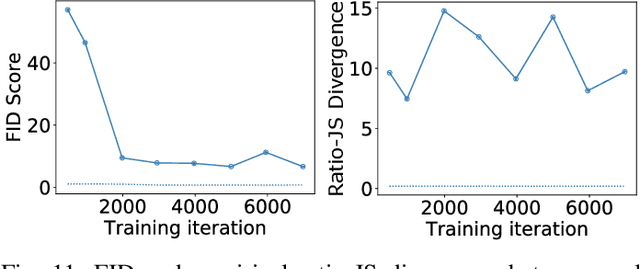
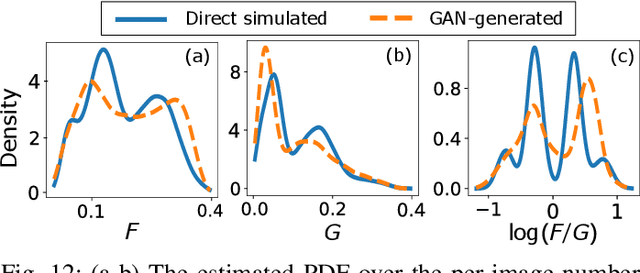
In recent years, generative adversarial networks (GANs) have gained tremendous popularity for potential applications in medical imaging, such as medical image synthesis, restoration, reconstruction, translation, as well as objective image quality assessment. Despite the impressive progress in generating high-resolution, perceptually realistic images, it is not clear if modern GANs reliably learn the statistics that are meaningful to a downstream medical imaging application. In this work, the ability of a state-of-the-art GAN to learn the statistics of canonical stochastic image models (SIMs) that are relevant to objective assessment of image quality is investigated. It is shown that although the employed GAN successfully learned several basic first- and second-order statistics of the specific medical SIMs under consideration and generated images with high perceptual quality, it failed to correctly learn several per-image statistics pertinent to the these SIMs, highlighting the urgent need to assess medical image GANs in terms of objective measures of image quality.
MSTRIQ: No Reference Image Quality Assessment Based on Swin Transformer with Multi-Stage Fusion
May 23, 2022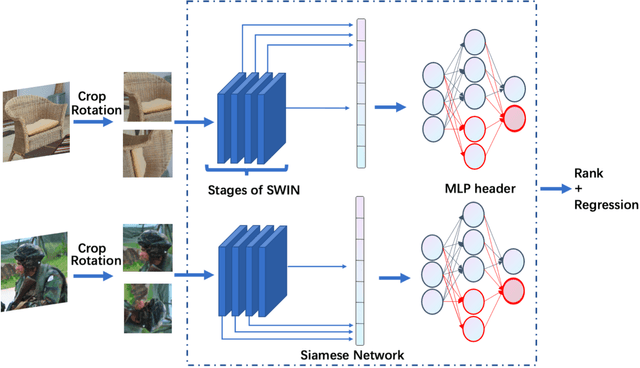
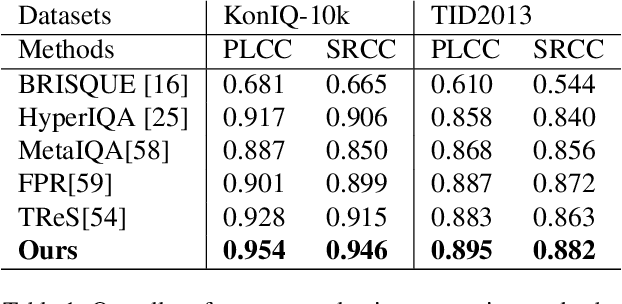
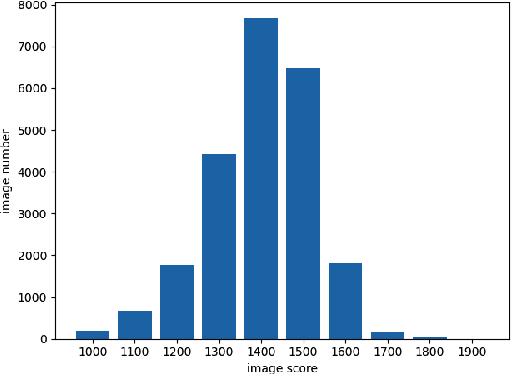
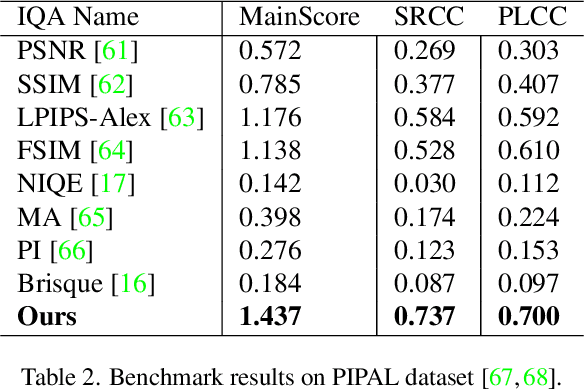
Measuring the perceptual quality of images automatically is an essential task in the area of computer vision, as degradations on image quality can exist in many processes from image acquisition, transmission to enhancing. Many Image Quality Assessment(IQA) algorithms have been designed to tackle this problem. However, it still remains un settled due to the various types of image distortions and the lack of large-scale human-rated datasets. In this paper, we propose a novel algorithm based on the Swin Transformer [31] with fused features from multiple stages, which aggregates information from both local and global features to better predict the quality. To address the issues of small-scale datasets, relative rankings of images have been taken into account together with regression loss to simultaneously optimize the model. Furthermore, effective data augmentation strategies are also used to improve the performance. In comparisons with previous works, experiments are carried out on two standard IQA datasets and a challenge dataset. The results demonstrate the effectiveness of our work. The proposed method outperforms other methods on standard datasets and ranks 2nd in the no-reference track of NTIRE 2022 Perceptual Image Quality Assessment Challenge [53]. It verifies that our method is promising in solving diverse IQA problems and thus can be used to real-word applications.
Tree Structure-Aware Few-Shot Image Classification via Hierarchical Aggregation
Jul 14, 2022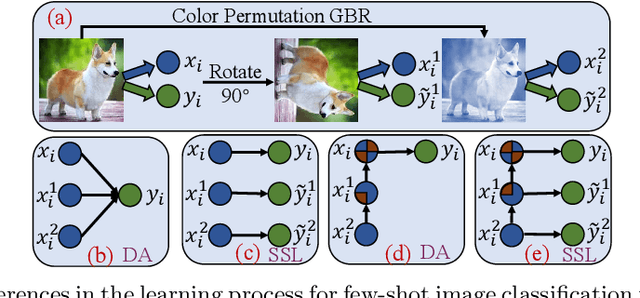
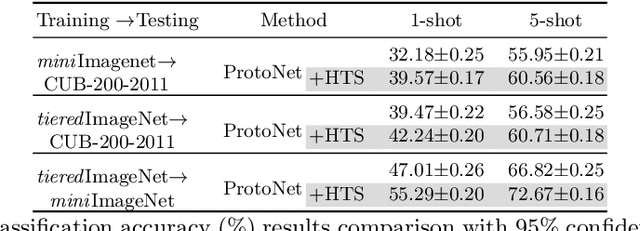
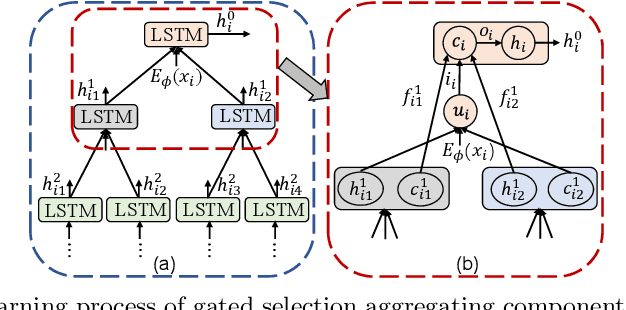
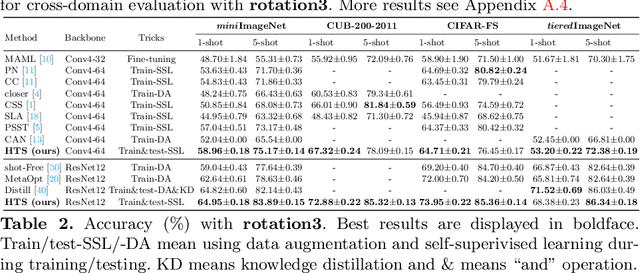
In this paper, we mainly focus on the problem of how to learn additional feature representations for few-shot image classification through pretext tasks (e.g., rotation or color permutation and so on). This additional knowledge generated by pretext tasks can further improve the performance of few-shot learning (FSL) as it differs from human-annotated supervision (i.e., class labels of FSL tasks). To solve this problem, we present a plug-in Hierarchical Tree Structure-aware (HTS) method, which not only learns the relationship of FSL and pretext tasks, but more importantly, can adaptively select and aggregate feature representations generated by pretext tasks to maximize the performance of FSL tasks. A hierarchical tree constructing component and a gated selection aggregating component is introduced to construct the tree structure and find richer transferable knowledge that can rapidly adapt to novel classes with a few labeled images. Extensive experiments show that our HTS can significantly enhance multiple few-shot methods to achieve new state-of-the-art performance on four benchmark datasets. The code is available at: https://github.com/remiMZ/HTS-ECCV22.
GlassesGAN: Eyewear Personalization using Synthetic Appearance Discovery and Targeted Subspace Modeling
Oct 24, 2022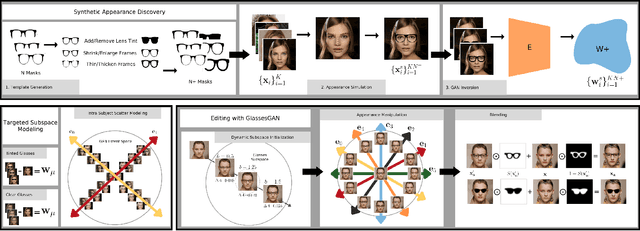
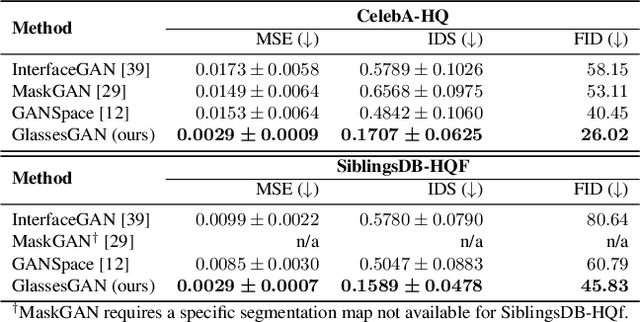
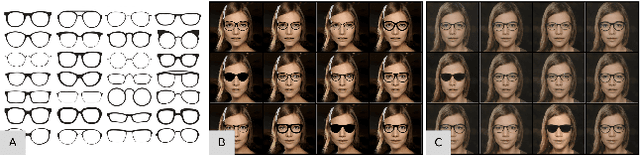

We present GlassesGAN, a novel image editing framework for custom design of glasses, that sets a new standard in terms of image quality, edit realism, and continuous multi-style edit capability. To facilitate the editing process with GlassesGAN, we propose a Targeted Subspace Modelling (TSM) procedure that, based on a novel mechanism for (synthetic) appearance discovery in the latent space of a pre-trained GAN generator, constructs an eyeglasses-specific (latent) subspace that the editing framework can utilize. To improve the reliability of our learned edits, we also introduce an appearance-constrained subspace initialization (SI) technique able to center the latent representation of a given input image in the well-defined part of the constructed subspace. We test GlassesGAN on three diverse datasets (CelebA-HQ, SiblingsDB-HQf, and MetFaces) and compare it against three state-of-the-art competitors, i.e., InterfaceGAN, GANSpace, and MaskGAN. Our experimental results show that GlassesGAN achieves photo-realistic, multi-style edits to eyeglasses while comparing favorably to its competitors. The source code is made freely available.
Self-Configuring nnU-Nets Detect Clouds in Satellite Images
Oct 24, 2022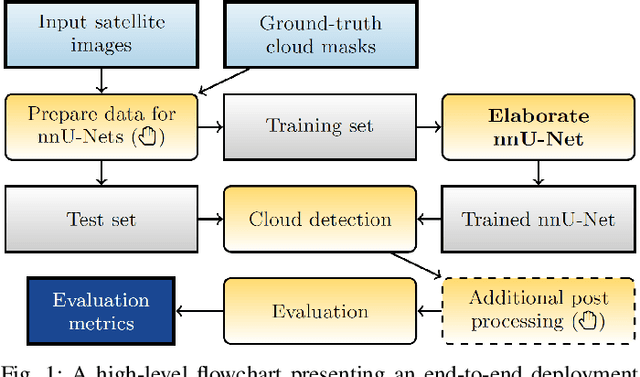



Cloud detection is a pivotal satellite image pre-processing step that can be performed both on the ground and on board a satellite to tag useful images. In the latter case, it can help to reduce the amount of data to downlink by pruning the cloudy areas, or to make a satellite more autonomous through data-driven acquisition re-scheduling of the cloudy areas. We approach this important task with nnU-Nets, a self-reconfigurable framework able to perform meta-learning of a segmentation network over various datasets. Our experiments, performed over Sentinel-2 and Landsat-8 multispectral images revealed that nnU-Nets deliver state-of-the-art cloud segmentation performance without any manual design. Our approach was ranked within the top 7% best solutions (across 847 participating teams) in the On Cloud N: Cloud Cover Detection Challenge, where we reached the Jaccard index of 0.882 over more than 10k unseen Sentinel-2 image patches (the winners obtained 0.897, whereas the baseline U-Net with the ResNet-34 backbone used as an encoder: 0.817, and the classic Sentinel-2 image thresholding: 0.652).
Learning Latent Structural Causal Models
Oct 24, 2022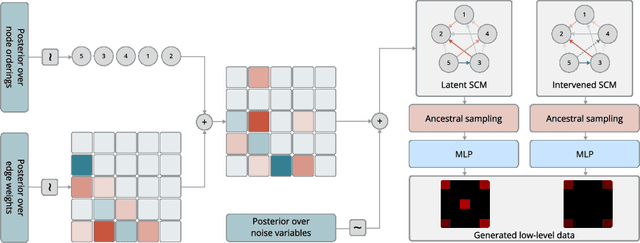
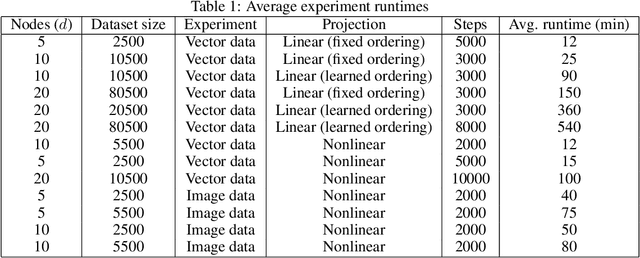
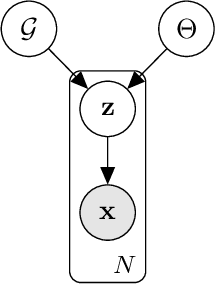
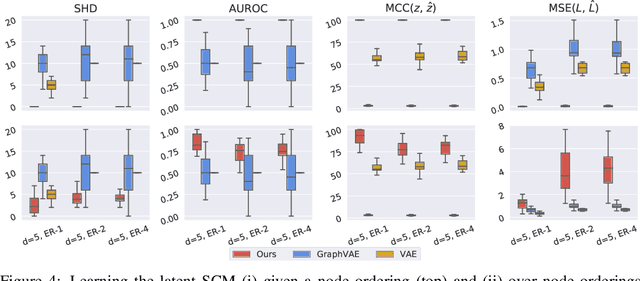
Causal learning has long concerned itself with the accurate recovery of underlying causal mechanisms. Such causal modelling enables better explanations of out-of-distribution data. Prior works on causal learning assume that the high-level causal variables are given. However, in machine learning tasks, one often operates on low-level data like image pixels or high-dimensional vectors. In such settings, the entire Structural Causal Model (SCM) -- structure, parameters, \textit{and} high-level causal variables -- is unobserved and needs to be learnt from low-level data. We treat this problem as Bayesian inference of the latent SCM, given low-level data. For linear Gaussian additive noise SCMs, we present a tractable approximate inference method which performs joint inference over the causal variables, structure and parameters of the latent SCM from random, known interventions. Experiments are performed on synthetic datasets and a causally generated image dataset to demonstrate the efficacy of our approach. We also perform image generation from unseen interventions, thereby verifying out of distribution generalization for the proposed causal model.
The Lottery Ticket Hypothesis for Vision Transformers
Nov 02, 2022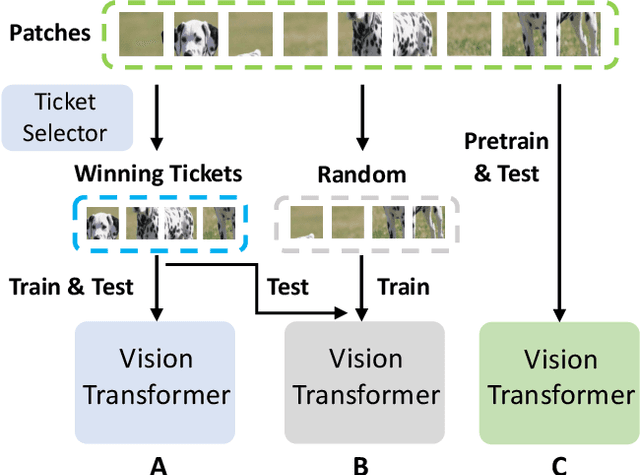
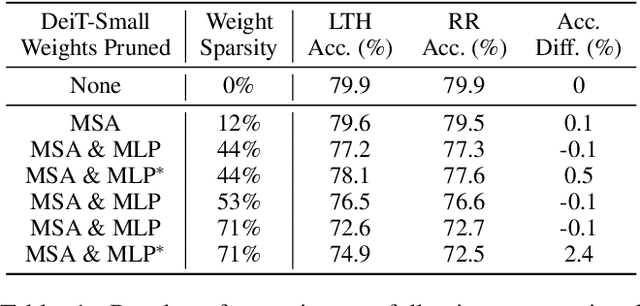
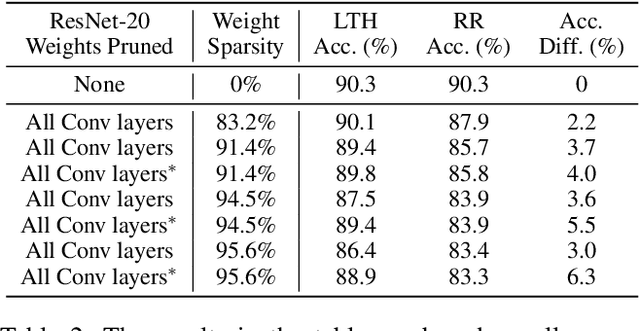
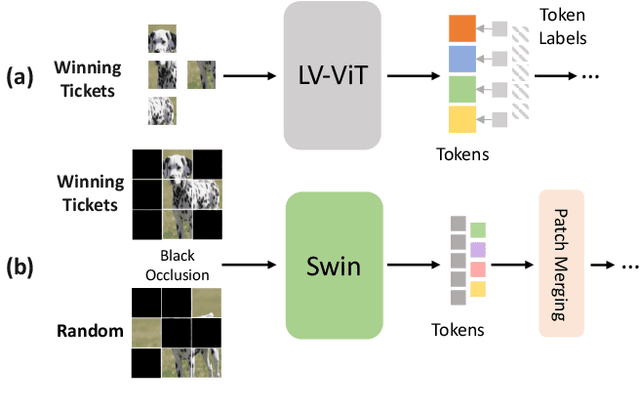
The conventional lottery ticket hypothesis (LTH) claims that there exists a sparse subnetwork within a dense neural network and a proper random initialization method, called the winning ticket, such that it can be trained from scratch to almost as good as the dense counterpart. Meanwhile, the research of LTH in vision transformers (ViTs) is scarcely evaluated. In this paper, we first show that the conventional winning ticket is hard to find at weight level of ViTs by existing methods. Then, we generalize the LTH for ViTs to input images consisting of image patches inspired by the input dependence of ViTs. That is, there exists a subset of input image patches such that a ViT can be trained from scratch by using only this subset of patches and achieve similar accuracy to the ViTs trained by using all image patches. We call this subset of input patches the winning tickets, which represent a significant amount of information in the input. Furthermore, we present a simple yet effective method to find the winning tickets in input patches for various types of ViT, including DeiT, LV-ViT, and Swin Transformers. More specifically, we use a ticket selector to generate the winning tickets based on the informativeness of patches. Meanwhile, we build another randomly selected subset of patches for comparison, and the experiments show that there is clear difference between the performance of models trained with winning tickets and randomly selected subsets.
Contrastive pretraining for semantic segmentation is robust to noisy positive pairs
Nov 24, 2022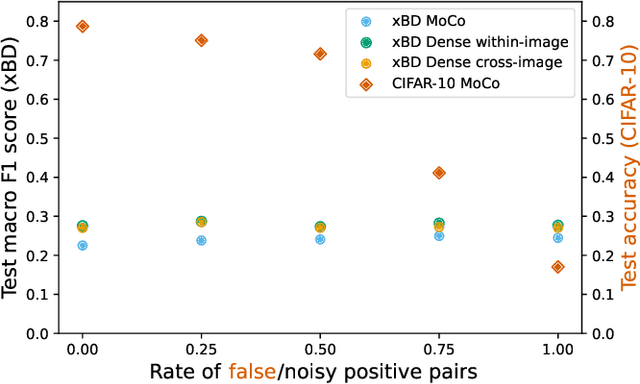

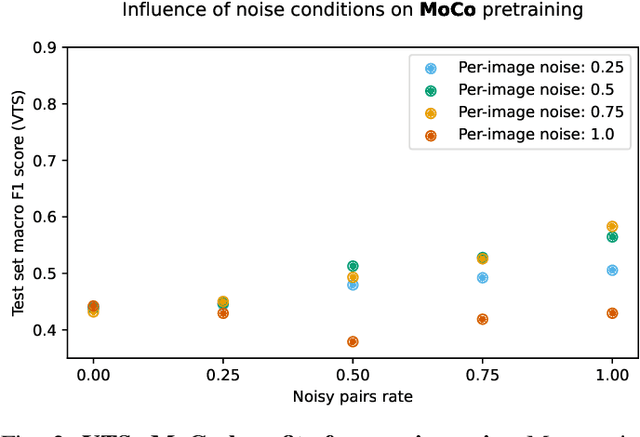
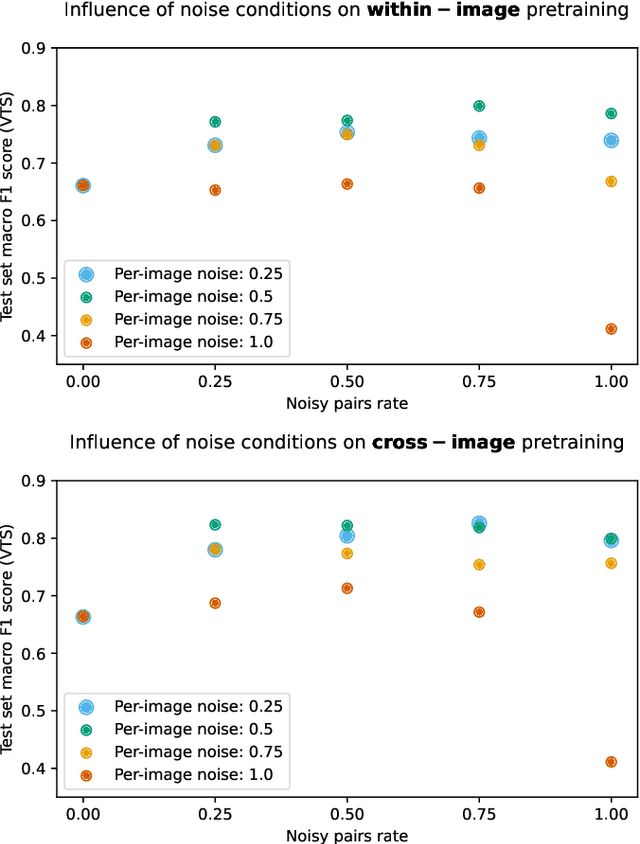
Domain-specific variants of contrastive learning can construct positive pairs from two distinct images, as opposed to augmenting the same image twice. Unlike in traditional contrastive methods, this can result in positive pairs not matching perfectly. Similar to false negative pairs, this could impede model performance. Surprisingly, we find that downstream semantic segmentation is either robust to the noisy pairs or even benefits from them. The experiments are conducted on the remote sensing dataset xBD, and a synthetic segmentation dataset, on which we have full control over the noise parameters. As a result, practitioners should be able to use such domain-specific contrastive methods without having to filter their positive pairs beforehand.
Deep learning applied to computational mechanics: A comprehensive review, state of the art, and the classics
Dec 18, 2022
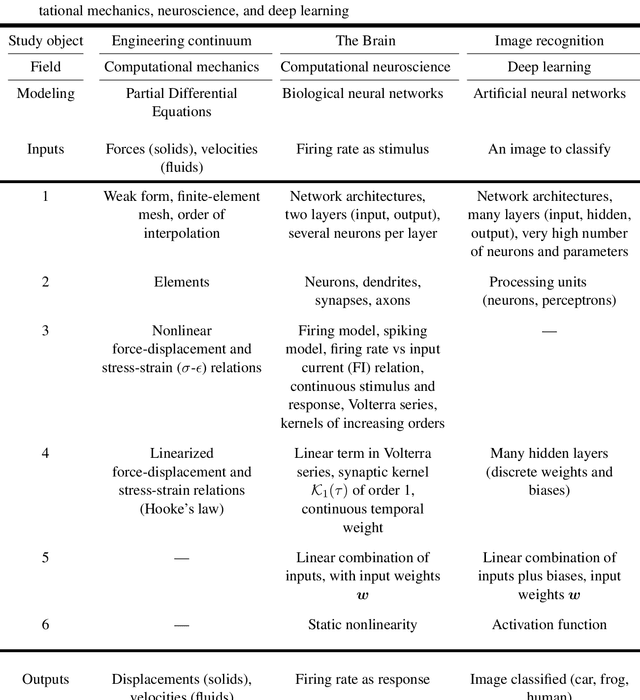


Three recent breakthroughs due to AI in arts and science serve as motivation: An award winning digital image, protein folding, fast matrix multiplication. Many recent developments in artificial neural networks, particularly deep learning (DL), applied and relevant to computational mechanics (solid, fluids, finite-element technology) are reviewed in detail. Both hybrid and pure machine learning (ML) methods are discussed. Hybrid methods combine traditional PDE discretizations with ML methods either (1) to help model complex nonlinear constitutive relations, (2) to nonlinearly reduce the model order for efficient simulation (turbulence), or (3) to accelerate the simulation by predicting certain components in the traditional integration methods. Here, methods (1) and (2) relied on Long-Short-Term Memory (LSTM) architecture, with method (3) relying on convolutional neural networks.. Pure ML methods to solve (nonlinear) PDEs are represented by Physics-Informed Neural network (PINN) methods, which could be combined with attention mechanism to address discontinuous solutions. Both LSTM and attention architectures, together with modern and generalized classic optimizers to include stochasticity for DL networks, are extensively reviewed. Kernel machines, including Gaussian processes, are provided to sufficient depth for more advanced works such as shallow networks with infinite width. Not only addressing experts, readers are assumed familiar with computational mechanics, but not with DL, whose concepts and applications are built up from the basics, aiming at bringing first-time learners quickly to the forefront of research. History and limitations of AI are recounted and discussed, with particular attention at pointing out misstatements or misconceptions of the classics, even in well-known references. Positioning and pointing control of a large-deformable beam is given as an example.
Brain Tumor MRI Classification using a Novel Deep Residual and Regional CNN
Dec 10, 2022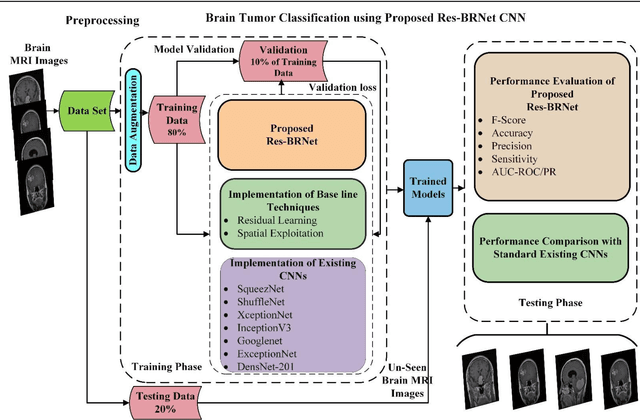
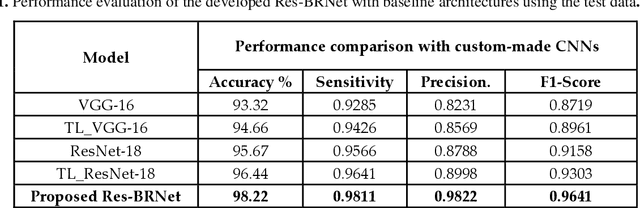
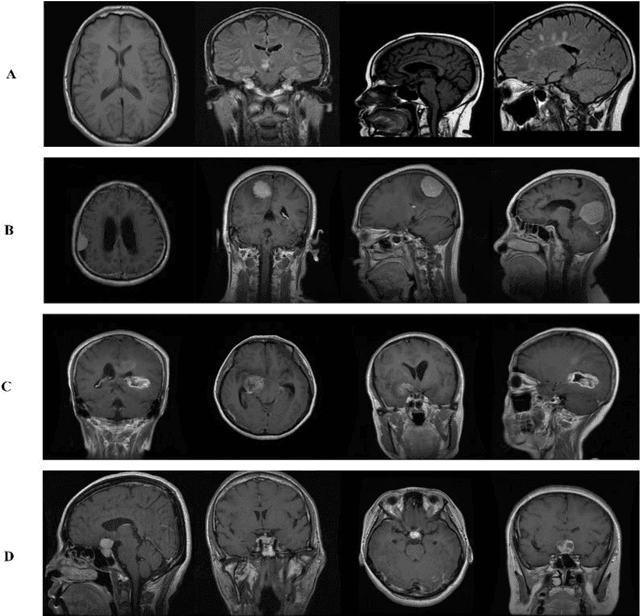
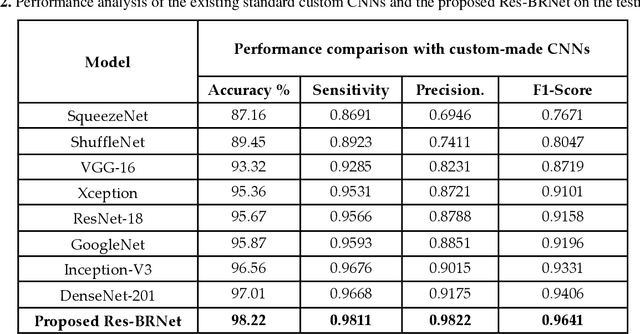
Brain tumor classification is crucial for clinical analysis and an effective treatment plan to cure patients. Deep learning models help radiologists to accurately and efficiently analyze tumors without manual intervention. However, brain tumor analysis is challenging because of its complex structure, texture, size, location, and appearance. Therefore, a novel deep residual and regional-based Res-BRNet Convolutional Neural Network (CNN) is developed for effective brain tumor (Magnetic Resonance Imaging) MRI classification. The developed Res-BRNet employed Regional and boundary-based operations in a systematic order within the modified spatial and residual blocks. Moreover, the spatial block extract homogeneity and boundary-defined features at the abstract level. Furthermore, the residual blocks employed at the target level significantly learn local and global texture variations of different classes of brain tumors. The efficiency of the developed Res-BRNet is evaluated on a standard dataset; collected from Kaggle and Figshare containing various tumor categories, including meningioma, glioma, pituitary, and healthy images. Experiments prove that the developed Res-BRNet outperforms the standard CNN models and attained excellent performances (accuracy: 98.22%, sensitivity: 0.9811, F-score: 0.9841, and precision: 0.9822) on challenging datasets. Additionally, the performance of the proposed Res-BRNet indicates a strong potential for medical image-based disease analyses.