 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-distillation Augmented Masked Autoencoders for Histopathological Image Classification
Mar 31, 2022
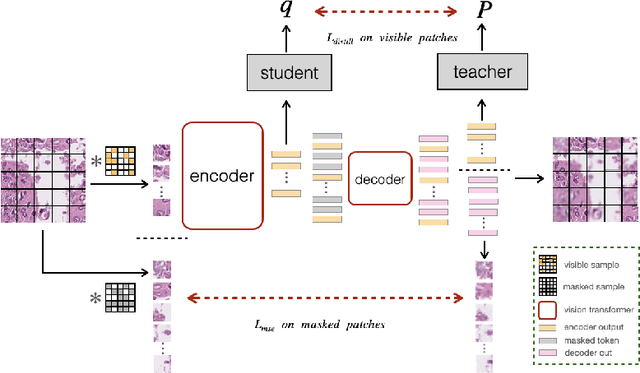
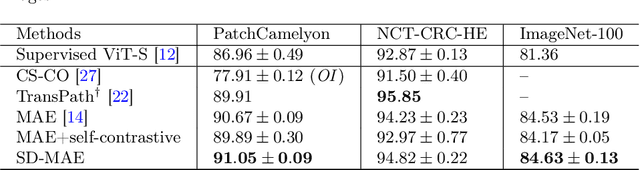
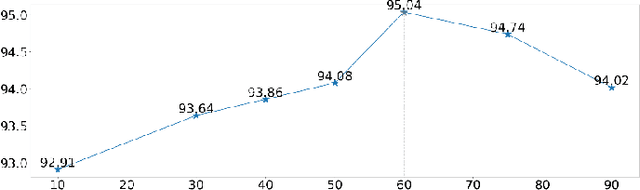

Self-supervised learning (SSL) has drawn increasing attention in pathological image analysis in recent years. However, the prevalent contrastive SSL is suboptimal in feature representation under this scenario due to the homogeneous visual appearance. Alternatively, masked autoencoders (MAE) build SSL from a generative paradigm. They are more friendly to pathological image modeling. In this paper, we firstly introduce MAE to pathological image analysis. A novel SD-MAE model is proposed to enable a self-distillation augmented SSL on top of the raw MAE. Besides the reconstruction loss on masked image patches, SD-MAE further imposes the self-distillation loss on visible patches. It guides the encoder to perceive high-level semantics that benefit downstream tasks. We apply SD-MAE to the image classification task on two pathological and one natural image datasets. Experiments demonstrate that SD-MAE performs highly competitive when compared with leading contrastive SSL methods. The results, which are pre-trained using a moderate size of pathological images, are also comparable to the method pre-trained with two orders of magnitude more images. Our code will be released soon.
Temporal error concealment for fisheye video sequences based on equisolid re-projection
Nov 21, 2022
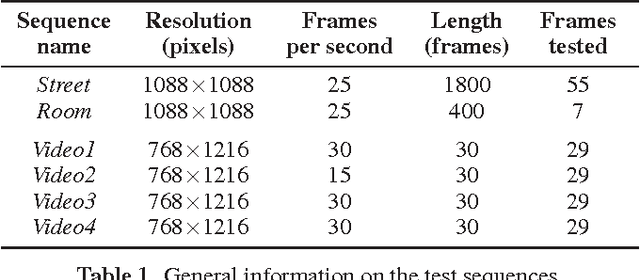
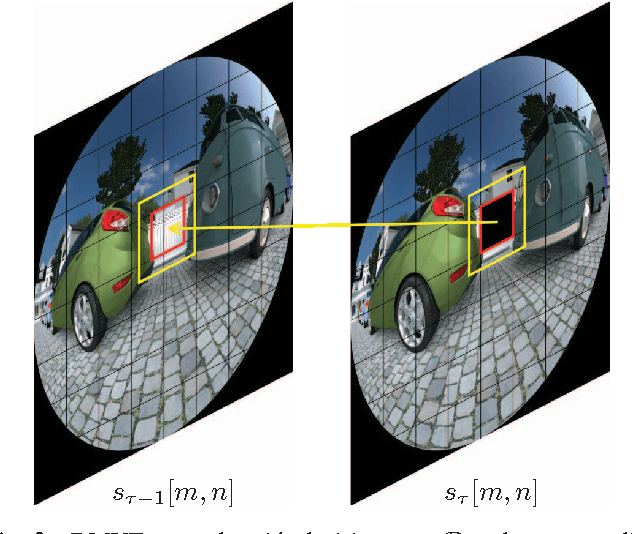
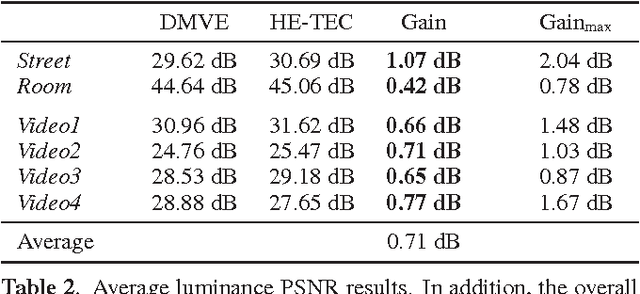
Wide-angle video sequences obtained by fisheye cameras exhibit characteristics that may not very well comply with standard image and video processing techniques such as error concealment. This paper introduces a temporal error concealment technique designed for the inherent characteristics of equisolid fisheye video sequences by applying a re-projection into the equisolid domain after conducting part of the error concealment in the perspective domain. Combining this technique with conventional decoder motion vector estimation achieves average gains of 0.71 dB compared against pure decoder motion vector estimation for the test sequences used. Maximum gains amount to up to 2.04 dB for selected frames.
Improving dermatology classifiers across populations using images generated by large diffusion models
Nov 23, 2022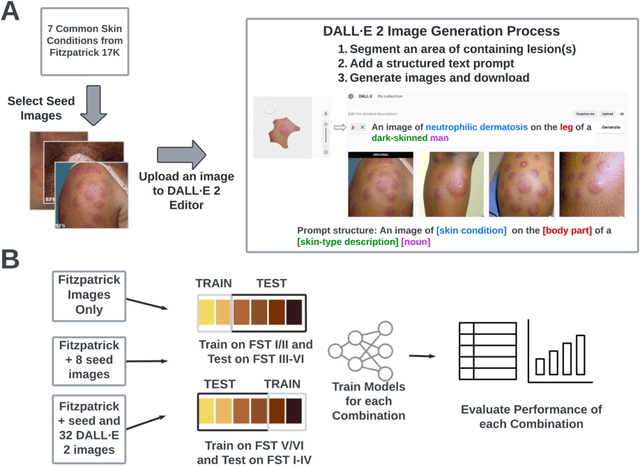
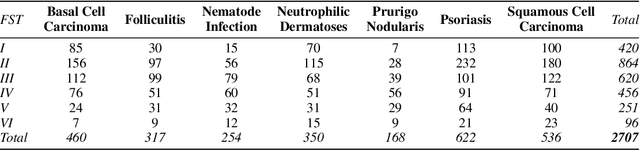
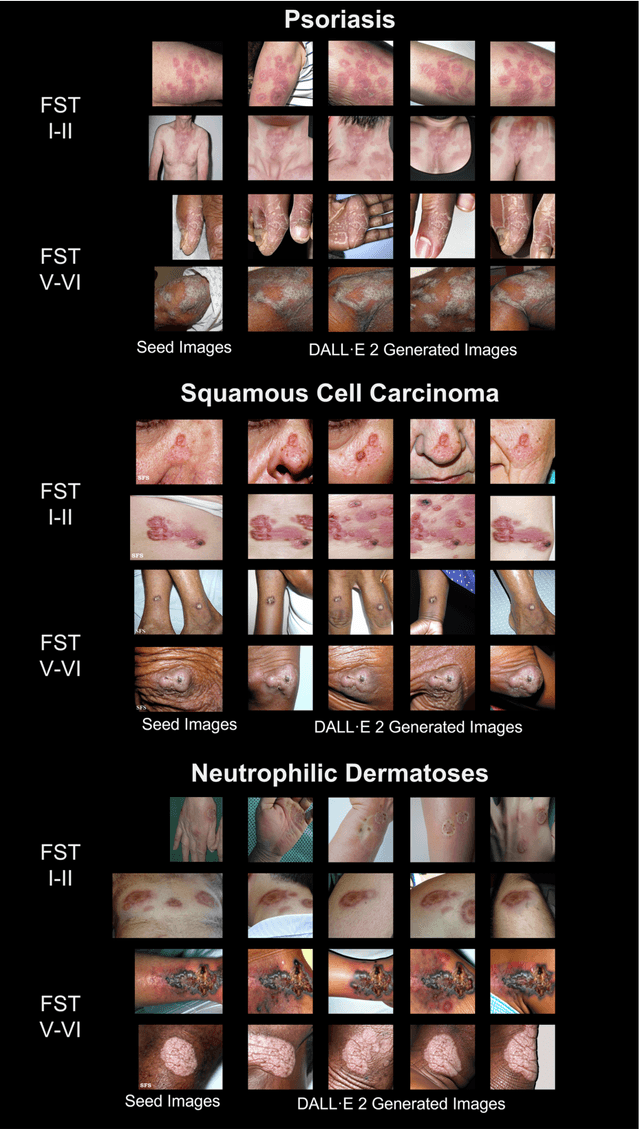
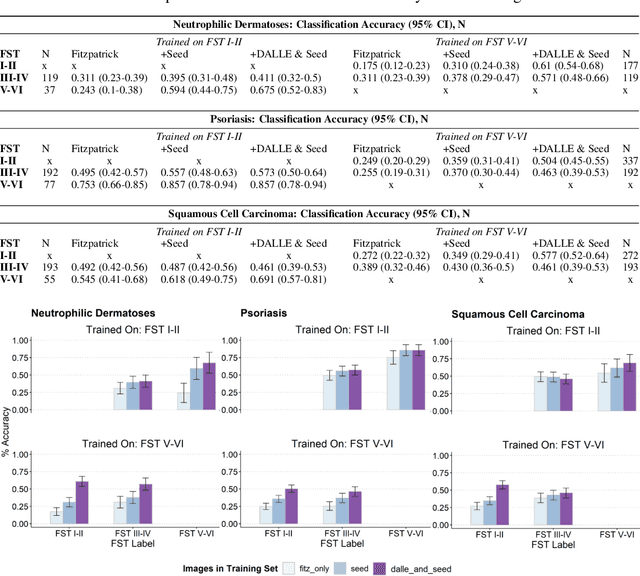
Dermatological classification algorithms developed without sufficiently diverse training data may generalize poorly across populations. While intentional data collection and annotation offer the best means for improving representation, new computational approaches for generating training data may also aid in mitigating the effects of sampling bias. In this paper, we show that DALL$\cdot$E 2, a large-scale text-to-image diffusion model, can produce photorealistic images of skin disease across skin types. Using the Fitzpatrick 17k dataset as a benchmark, we demonstrate that augmenting training data with DALL$\cdot$E 2-generated synthetic images improves classification of skin disease overall and especially for underrepresented groups.
PatchRot: A Self-Supervised Technique for Training Vision Transformers
Oct 27, 2022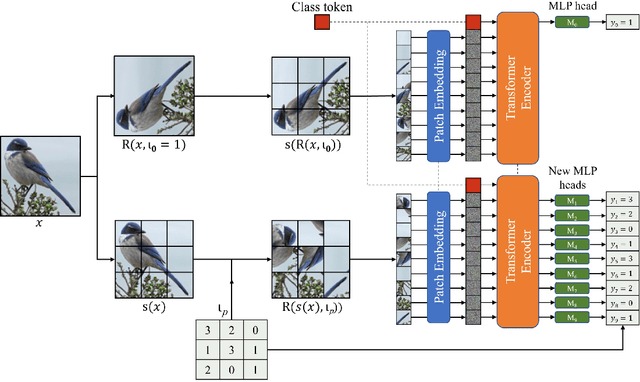
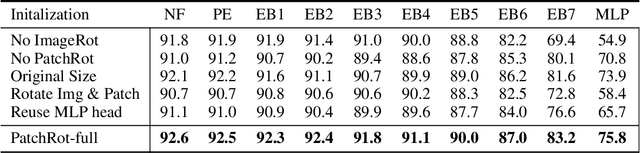
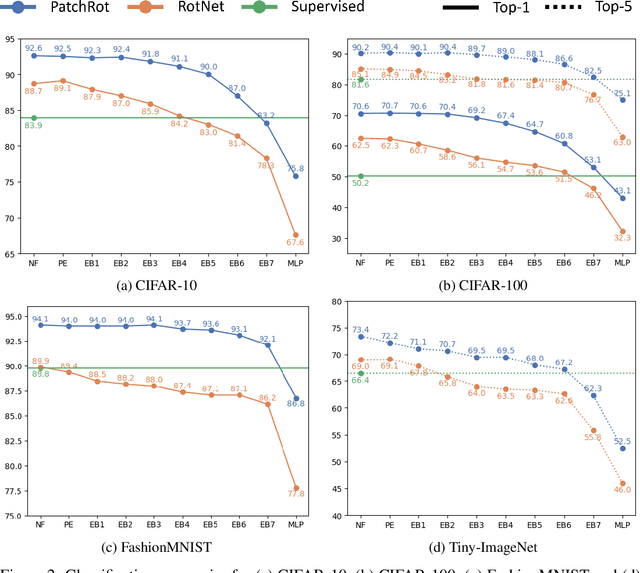
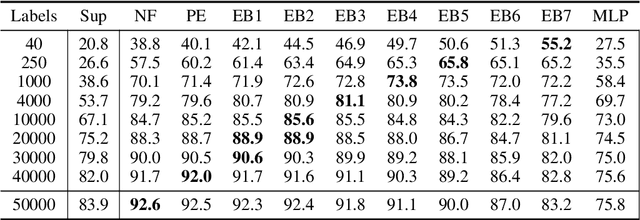
Vision transformers require a huge amount of labeled data to outperform convolutional neural networks. However, labeling a huge dataset is a very expensive process. Self-supervised learning techniques alleviate this problem by learning features similar to supervised learning in an unsupervised way. In this paper, we propose a self-supervised technique PatchRot that is crafted for vision transformers. PatchRot rotates images and image patches and trains the network to predict the rotation angles. The network learns to extract both global and local features from an image. Our extensive experiments on different datasets showcase PatchRot training learns rich features which outperform supervised learning and compared baseline.
LPT: Long-tailed Prompt Tuning for Image Classification
Oct 03, 2022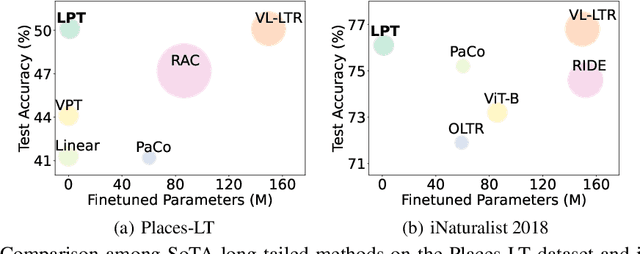
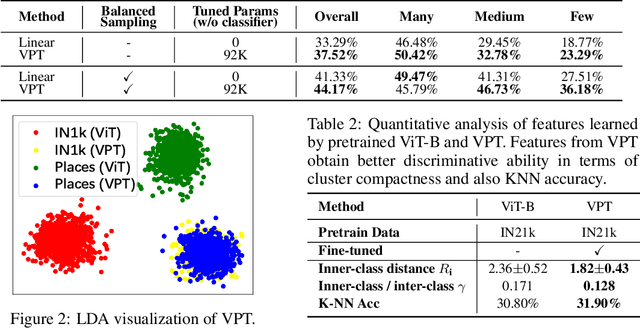
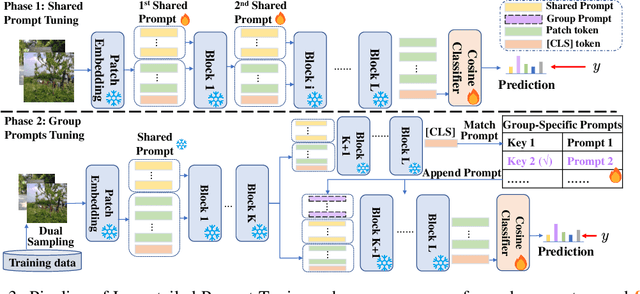
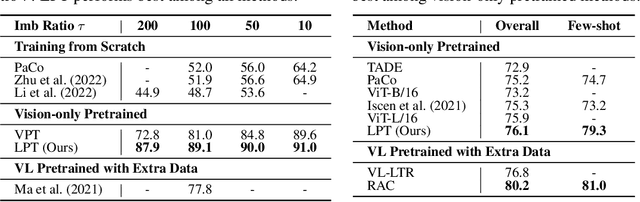
For long-tailed classification, most works often pretrain a big model on a large-scale dataset, and then fine-tune the whole model for adapting to long-tailed data. Though promising, fine-tuning the whole pretrained model tends to suffer from high cost in computation and deployment of different models for different tasks, as well as weakened generalization ability for overfitting to certain features of long-tailed data. To alleviate these issues, we propose an effective Long-tailed Prompt Tuning method for long-tailed classification. LPT introduces several trainable prompts into a frozen pretrained model to adapt it to long-tailed data. For better effectiveness, we divide prompts into two groups: 1) a shared prompt for the whole long-tailed dataset to learn general features and to adapt a pretrained model into target domain; and 2) group-specific prompts to gather group-specific features for the samples which have similar features and also to empower the pretrained model with discrimination ability. Then we design a two-phase training paradigm to learn these prompts. In phase 1, we train the shared prompt via supervised prompt tuning to adapt a pretrained model to the desired long-tailed domain. In phase 2, we use the learnt shared prompt as query to select a small best matched set for a group of similar samples from the group-specific prompt set to dig the common features of these similar samples, then optimize these prompts with dual sampling strategy and asymmetric GCL loss. By only fine-tuning a few prompts while fixing the pretrained model, LPT can reduce training and deployment cost by storing a few prompts, and enjoys a strong generalization ability of the pretrained model. Experiments show that on various long-tailed benchmarks, with only ~1.1% extra parameters, LPT achieves comparable performance than previous whole model fine-tuning methods, and is more robust to domain-shift.
Convolutional networks inherit frequency sensitivity from image statistics
Oct 03, 2022

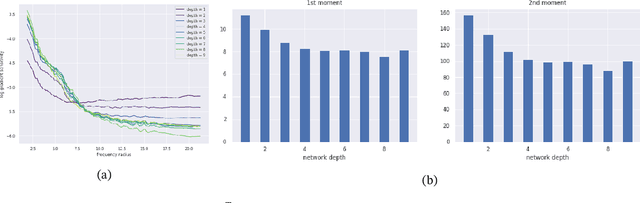
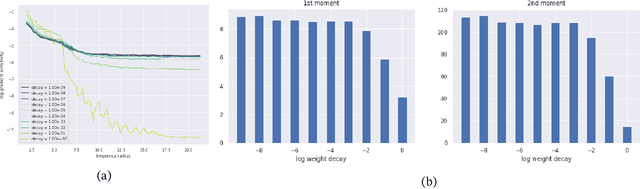
It is widely acknowledged that trained convolutional neural networks (CNNs) have different levels of sensitivity to signals of different frequency. In particular, a number of empirical studies have documented CNNs sensitivity to low-frequency signals. In this work we show with theory and experiments that this observed sensitivity is a consequence of the frequency distribution of natural images, which is known to have most of its power concentrated in low-to-mid frequencies. Our theoretical analysis relies on representations of the layers of a CNN in frequency space, an idea that has previously been used to accelerate computations and study implicit bias of network training algorithms, but to the best of our knowledge has not been applied in the domain of model robustness.
ViT-DeiT: An Ensemble Model for Breast Cancer Histopathological Images Classification
Nov 01, 2022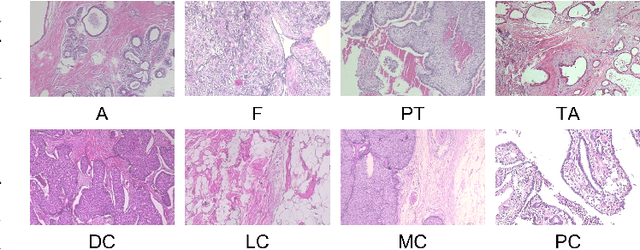
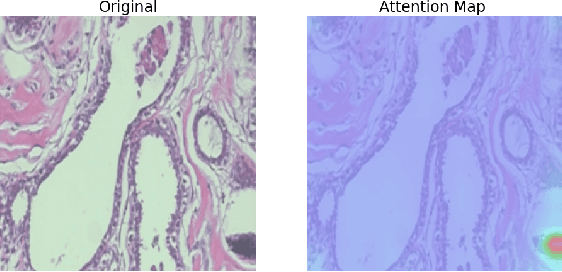
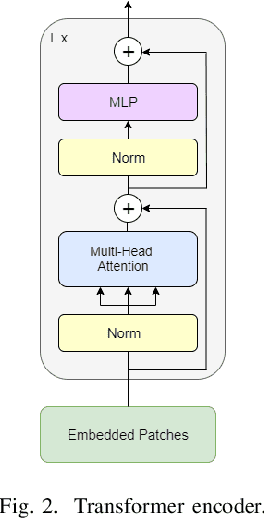
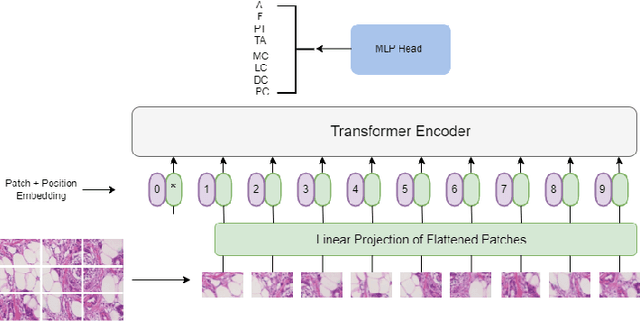
Breast cancer is the most common cancer in the world and the second most common type of cancer that causes death in women. The timely and accurate diagnosis of breast cancer using histopathological images is crucial for patient care and treatment. Pathologists can make more accurate diagnoses with the help of a novel approach based on image processing. This approach is an ensemble model of two types of pre-trained vision transformer models, namely, Vision Transformer and Data-Efficient Image Transformer. The proposed ensemble model classifies breast cancer histopathology images into eight classes, four of which are categorized as benign, whereas the others are categorized as malignant. A public dataset was used to evaluate the proposed model. The experimental results showed 98.17% accuracy, 98.18% precision, 98.08% recall, and a 98.12% F1 score.
Fast Algorithm for Constrained Linear Inverse Problems
Dec 06, 2022



We consider the constrained Linear Inverse Problem (LIP), where a certain atomic norm (like the $\ell_1 $ and the Nuclear norm) is minimized subject to a quadratic constraint. Typically, such cost functions are non-differentiable which makes them not amenable to the fast optimization methods existing in practice. We propose two equivalent reformulations of the constrained LIP with improved convex regularity: (i) a smooth convex minimization problem, and (ii) a strongly convex min-max problem. These problems could be solved by applying existing acceleration based convex optimization methods which provide better $ O \big( \frac{1}{k^2} \big) $ theoretical convergence guarantee. However, to fully exploit the utility of these reformulations, we also provide a novel algorithm, to which we refer as the Fast Linear Inverse Problem Solver (FLIPS), that is tailored to solve the reformulation of the LIP. We demonstrate the performance of FLIPS on the sparse coding problem arising in image processing tasks. In this setting, we observe that FLIPS consistently outperforms the Chambolle-Pock and C-SALSA algorithms--two of the current best methods in the literature.
Automated Segmentation of Computed Tomography Images with Submanifold Sparse Convolutional Networks
Dec 06, 2022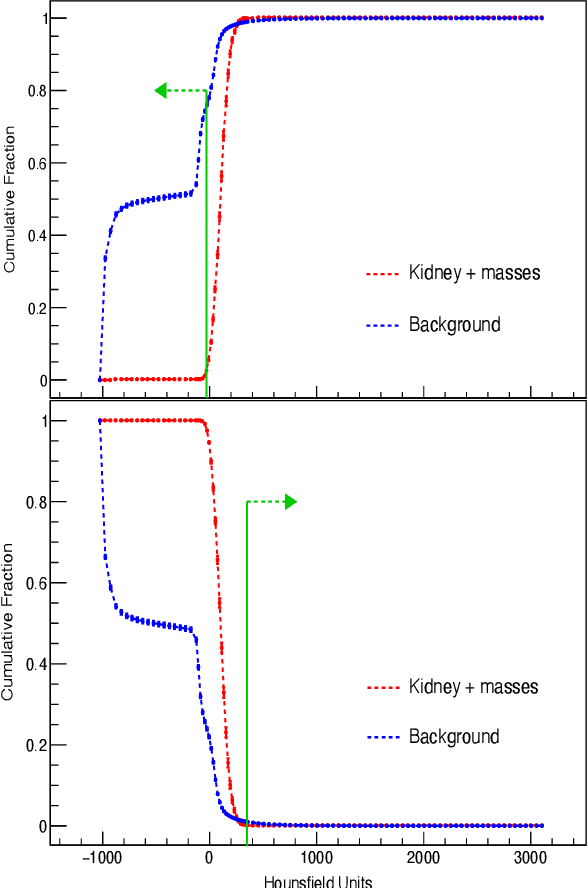
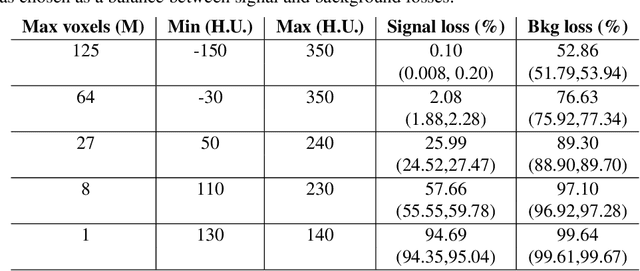
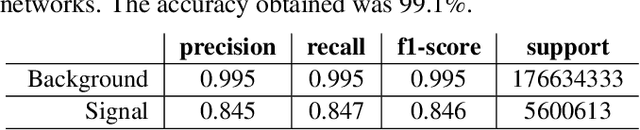
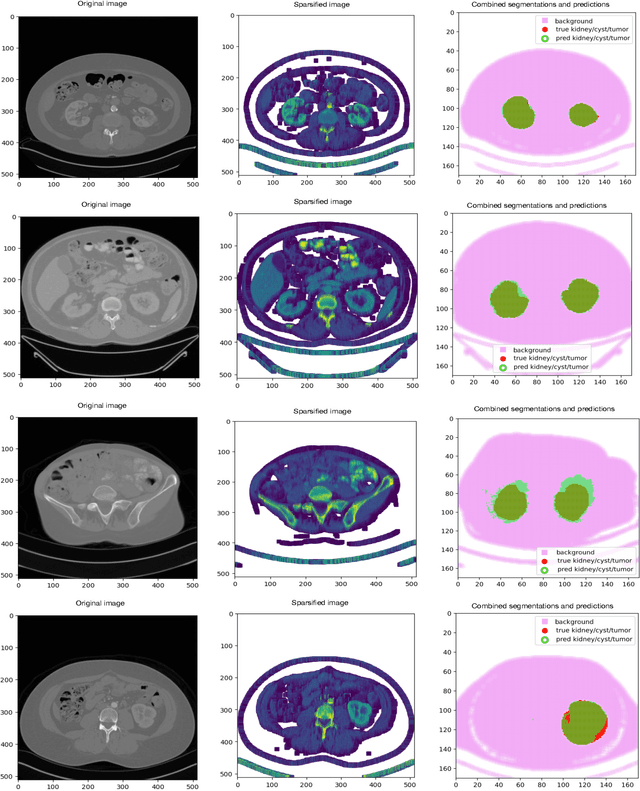
Quantitative cancer image analysis relies on the accurate delineation of tumours, a very specialised and time-consuming task. For this reason, methods for automated segmentation of tumours in medical imaging have been extensively developed in recent years, being Computed Tomography one of the most popular imaging modalities explored. However, the large amount of 3D voxels in a typical scan is prohibitive for the entire volume to be analysed at once in conventional hardware. To overcome this issue, the processes of downsampling and/or resampling are generally implemented when using traditional convolutional neural networks in medical imaging. In this paper, we propose a new methodology that introduces a process of sparsification of the input images and submanifold sparse convolutional networks as an alternative to downsampling. As a proof of concept, we applied this new methodology to Computed Tomography images of renal cancer patients, obtaining performances of segmentations of kidneys and tumours competitive with previous methods (~84.6% Dice similarity coefficient), while achieving a significant improvement in computation time (2-3 min per training epoch).
Differentiable optimization of the Debye-Wolf integral for light shaping and adaptive optics in two-photon microscopy
Nov 30, 2022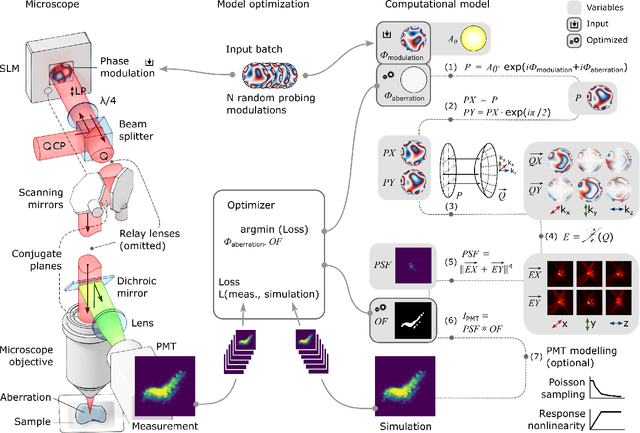
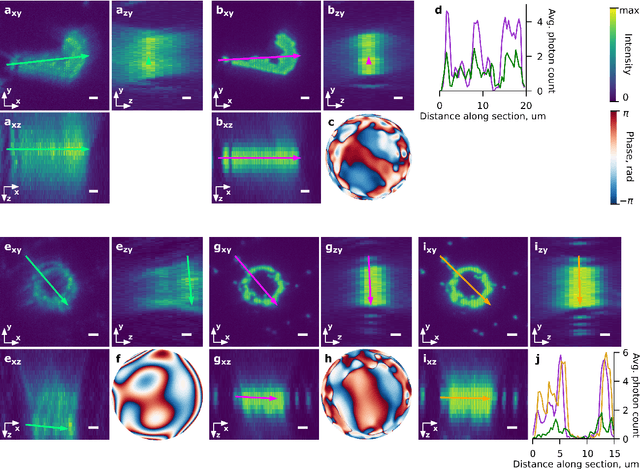
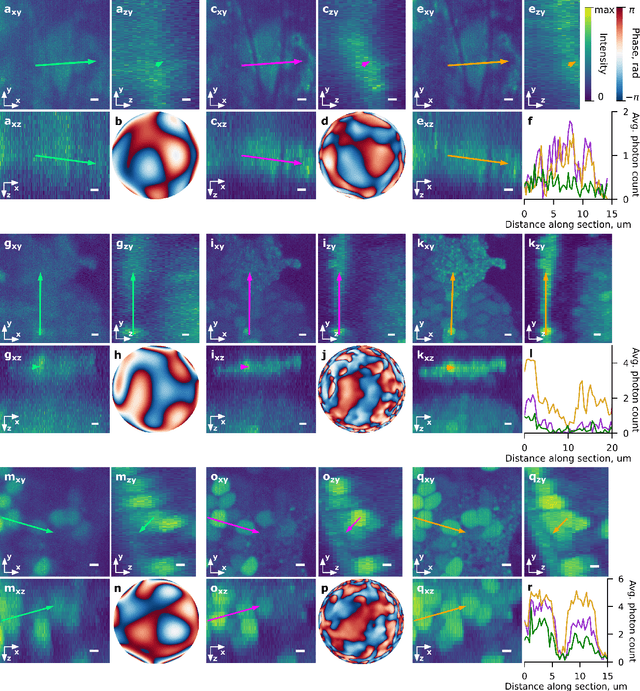
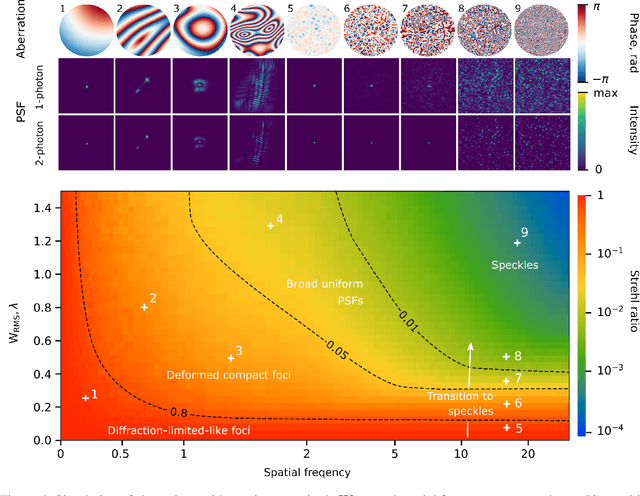
Control of light through a microscope objective with a high numerical aperture is a common requirement in applications such as optogenetics, adaptive optics, or laser processing. Light propagation, including polarization effects, can be described under these conditions using the Debye-Wolf diffraction integral. Here, we take advantage of differentiable optimization and machine learning for efficiently optimizing the Debye-Wolf integral for such applications. For light shaping we show that this optimization approach is suitable for engineering arbitrary three-dimensional point spread functions in a two-photon microscope. For differentiable model-based adaptive optics (DAO), the developed method can find aberration corrections with intrinsic image features, for example neurons labeled with genetically encoded calcium indicators, without requiring guide stars. Using computational modeling we further discuss the range of spatial frequencies and magnitudes of aberrations which can be corrected with this approach.