 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
How Real is Real: Evaluating the Robustness of Real-World Super Resolution
Oct 22, 2022

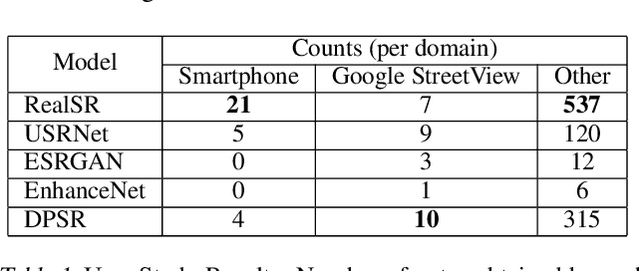

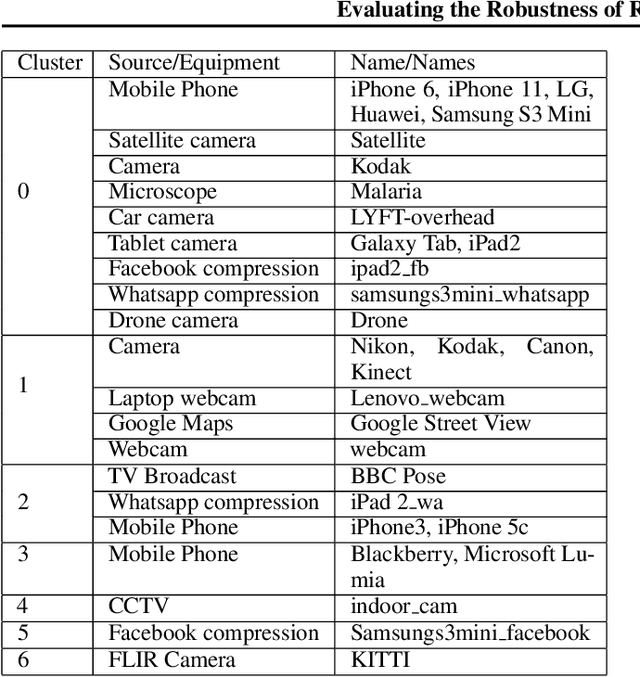
Image super-resolution (SR) is a field in computer vision that focuses on reconstructing high-resolution images from the respective low-resolution image. However, super-resolution is a well-known ill-posed problem as most methods rely on the downsampling method performed on the high-resolution image to form the low-resolution image to be known. Unfortunately, this is not something that is available in real-life super-resolution applications such as increasing the quality of a photo taken on a mobile phone. In this paper we will evaluate multiple state-of-the-art super-resolution methods and gauge their performance when presented with various types of real-life images and discuss the benefits and drawbacks of each method. We also introduce a novel dataset, WideRealSR, containing real images from a wide variety of sources. Finally, through careful experimentation and evaluation, we will present a potential solution to alleviate the generalization problem which is imminent in most state-of-the-art super-resolution models.
Recursive Neural Programs: Variational Learning of Image Grammars and Part-Whole Hierarchies
Jun 26, 2022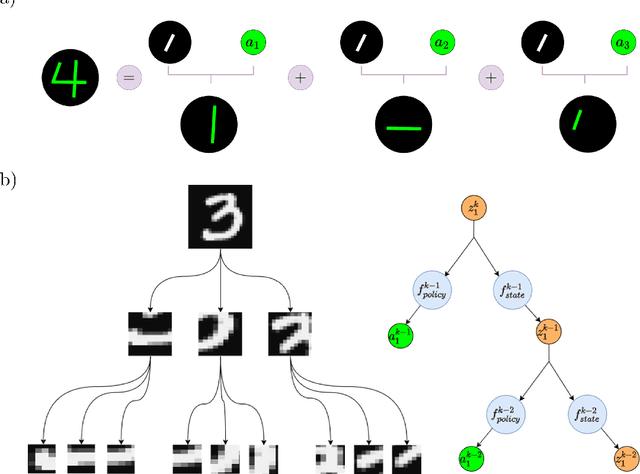
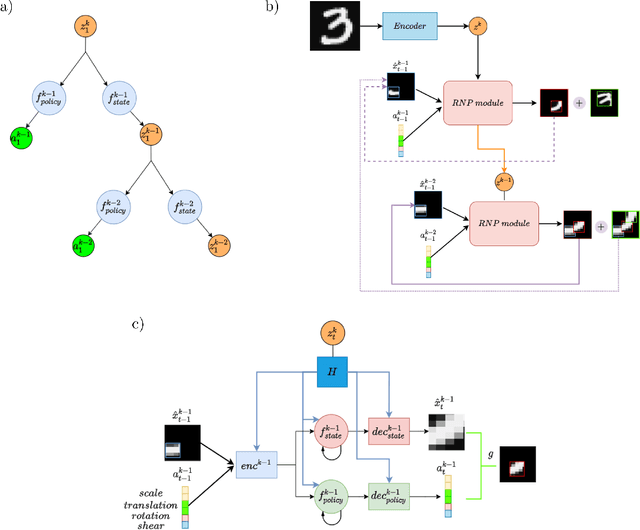


Human vision involves parsing and representing objects and scenes using structured representations based on part-whole hierarchies. Computer vision and machine learning researchers have recently sought to emulate this capability using capsule networks, reference frames and active predictive coding, but a generative model formulation has been lacking. We introduce Recursive Neural Programs (RNPs), which, to our knowledge, is the first neural generative model to address the part-whole hierarchy learning problem. RNPs model images as hierarchical trees of probabilistic sensory-motor programs that recursively reuse learned sensory-motor primitives to model an image within different reference frames, forming recursive image grammars. We express RNPs as structured variational autoencoders (sVAEs) for inference and sampling, and demonstrate parts-based parsing, sampling and one-shot transfer learning for MNIST, Omniglot and Fashion-MNIST datasets, demonstrating the model's expressive power. Our results show that RNPs provide an intuitive and explainable way of composing objects and scenes, allowing rich compositionality and intuitive interpretations of objects in terms of part-whole hierarchies.
Extracting Image Characteristics to Predict Crowdfunding Success
Mar 28, 2022
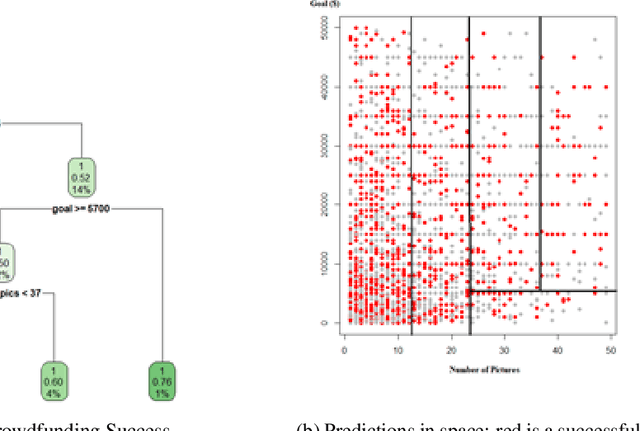
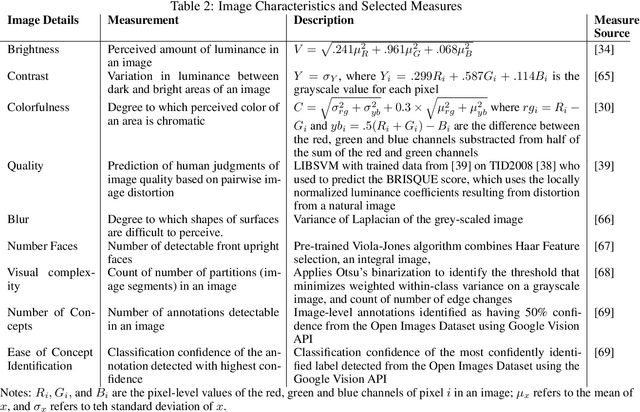
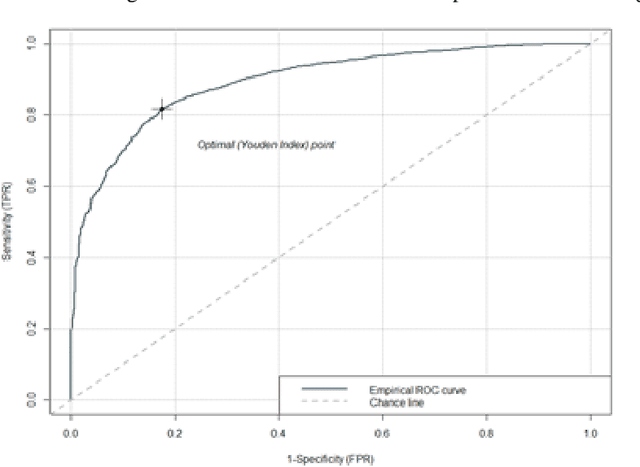
Despite an increase in the empirical study of crowdfunding platforms and the prevalence of visual information, operations management and marketing literature has yet to explore the role that image characteristics play in crowdfunding success. The authors of this manuscript begin by synthesizing literature on visual processing to identify several image characteristics that are likely to shape crowdfunding success. After detailing measures for each image characteristic, they use them as part of a machine-learning algorithm (Bayesian additive trees), along with project characteristics and textual information, to predict crowdfunding success. Results show that the inclusion of these image characteristics substantially improves prediction over baseline project variables, as well as textual features. Furthermore, image characteristic variables exhibit high importance, similar to variables linked to the number of pictures and number of videos. This research therefore offers valuable resources to researchers and managers who are interested in the role of visual information in ensuring new product success.
DR-GAN: Distribution Regularization for Text-to-Image Generation
Apr 17, 2022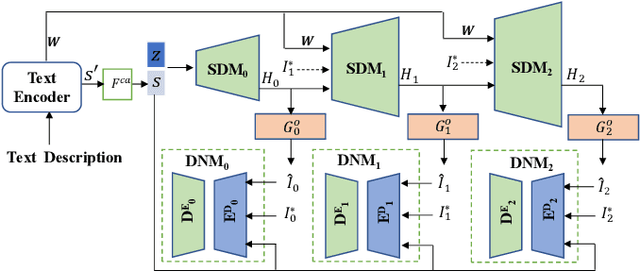
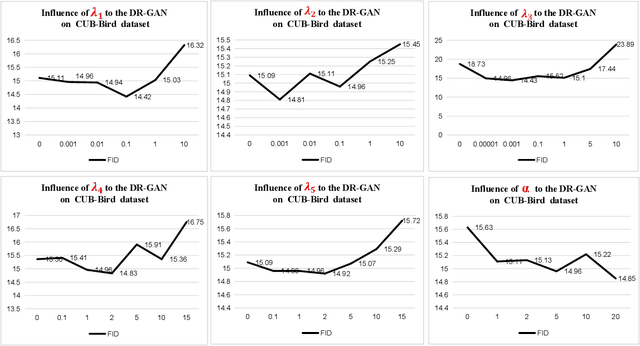

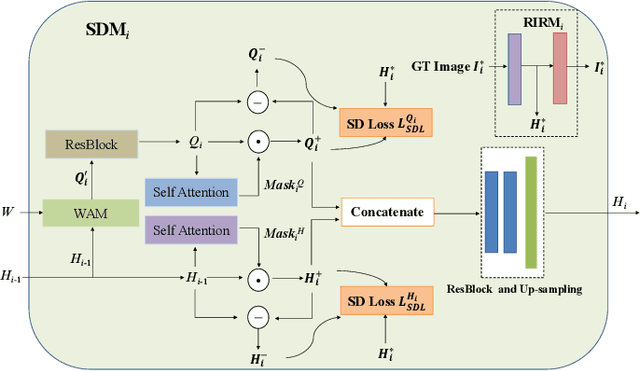
This paper presents a new Text-to-Image generation model, named Distribution Regularization Generative Adversarial Network (DR-GAN), to generate images from text descriptions from improved distribution learning. In DR-GAN, we introduce two novel modules: a Semantic Disentangling Module (SDM) and a Distribution Normalization Module (DNM). SDM combines the spatial self-attention mechanism and a new Semantic Disentangling Loss (SDL) to help the generator distill key semantic information for the image generation. DNM uses a Variational Auto-Encoder (VAE) to normalize and denoise the image latent distribution, which can help the discriminator better distinguish synthesized images from real images. DNM also adopts a Distribution Adversarial Loss (DAL) to guide the generator to align with normalized real image distributions in the latent space. Extensive experiments on two public datasets demonstrated that our DR-GAN achieved a competitive performance in the Text-to-Image task.
Human Face Recognition from Part of a Facial Image based on Image Stitching
Mar 10, 2022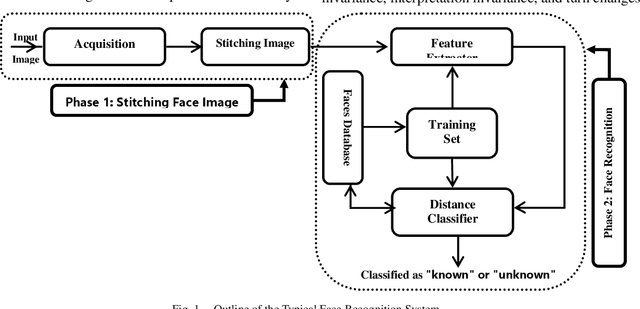
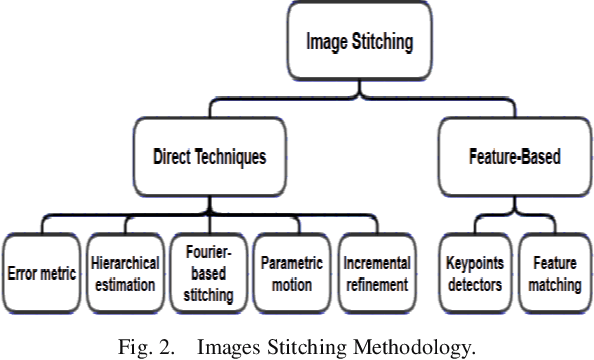


Most of the current techniques for face recognition require the presence of a full face of the person to be recognized, and this situation is difficult to achieve in practice, the required person may appear with a part of his face, which requires prediction of the part that did not appear. Most of the current forecasting processes are done by what is known as image interpolation, which does not give reliable results, especially if the missing part is large. In this work, we adopted the process of stitching the face by completing the missing part with the flipping of the part shown in the picture, depending on the fact that the human face is characterized by symmetry in most cases. To create a complete model, two facial recognition methods were used to prove the efficiency of the algorithm. The selected face recognition algorithms that are applied here are Eigenfaces and geometrical methods. Image stitching is the process during which distinctive photographic images are combined to make a complete scene or a high-resolution image. Several images are integrated to form a wide-angle panoramic image. The quality of the image stitching is determined by calculating the similarity among the stitched image and original images and by the presence of the seam lines through the stitched images. The Eigenfaces approach utilizes PCA calculation to reduce the feature vector dimensions. It provides an effective approach for discovering the lower-dimensional space. In addition, to enable the proposed algorithm to recognize the face, it also ensures a fast and effective way of classifying faces. The phase of feature extraction is followed by the classifier phase.
Degenerate Swin to Win: Plain Window-based Transformer without Sophisticated Operations
Nov 25, 2022

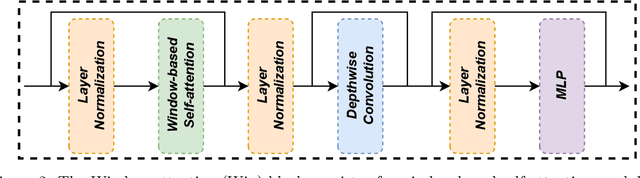
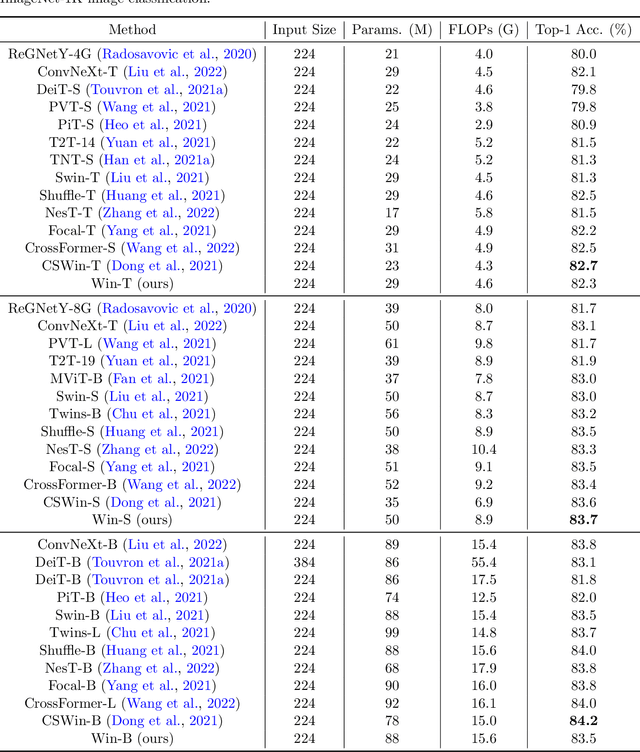
The formidable accomplishment of Transformers in natural language processing has motivated the researchers in the computer vision community to build Vision Transformers. Compared with the Convolution Neural Networks (CNN), a Vision Transformer has a larger receptive field which is capable of characterizing the long-range dependencies. Nevertheless, the large receptive field of Vision Transformer is accompanied by the huge computational cost. To boost efficiency, the window-based Vision Transformers emerge. They crop an image into several local windows, and the self-attention is conducted within each window. To bring back the global receptive field, window-based Vision Transformers have devoted a lot of efforts to achieving cross-window communications by developing several sophisticated operations. In this work, we check the necessity of the key design element of Swin Transformer, the shifted window partitioning. We discover that a simple depthwise convolution is sufficient for achieving effective cross-window communications. Specifically, with the existence of the depthwise convolution, the shifted window configuration in Swin Transformer cannot lead to an additional performance improvement. Thus, we degenerate the Swin Transformer to a plain Window-based (Win) Transformer by discarding sophisticated shifted window partitioning. The proposed Win Transformer is conceptually simpler and easier for implementation than Swin Transformer. Meanwhile, our Win Transformer achieves consistently superior performance than Swin Transformer on multiple computer vision tasks, including image recognition, semantic segmentation, and object detection.
A Deep Model for Partial Multi-Label Image Classification with Curriculum Based Disambiguation
Jul 06, 2022
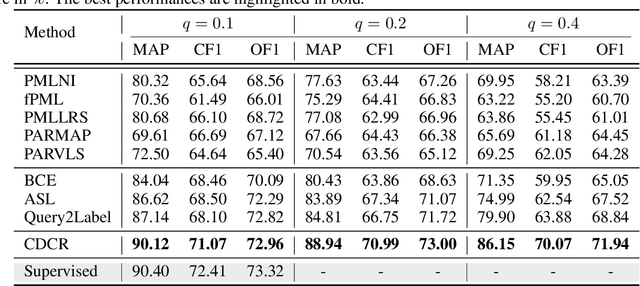
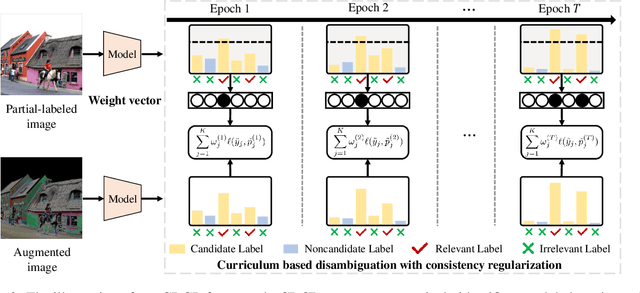
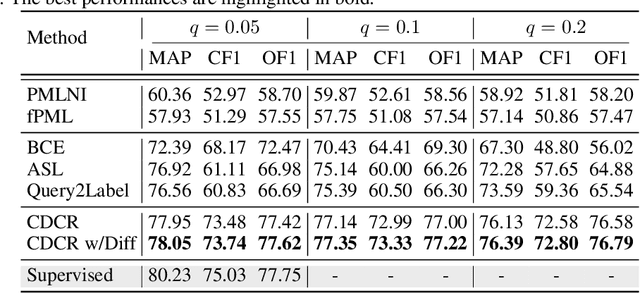
In this paper, we study the partial multi-label (PML) image classification problem, where each image is annotated with a candidate label set consists of multiple relevant labels and other noisy labels. Existing PML methods typically design a disambiguation strategy to filter out noisy labels by utilizing prior knowledge with extra assumptions, which unfortunately is unavailable in many real tasks. Furthermore, because the objective function for disambiguation is usually elaborately designed on the whole training set, it can be hardly optimized in a deep model with SGD on mini-batches. In this paper, for the first time we propose a deep model for PML to enhance the representation and discrimination ability. On one hand, we propose a novel curriculum based disambiguation strategy to progressively identify ground-truth labels by incorporating the varied difficulties of different classes. On the other hand, a consistency regularization is introduced for model retraining to balance fitting identified easy labels and exploiting potential relevant labels. Extensive experimental results on the commonly used benchmark datasets show the proposed method significantly outperforms the SOTA methods.
Graph Learning: A Comprehensive Survey and Future Directions
Dec 17, 2022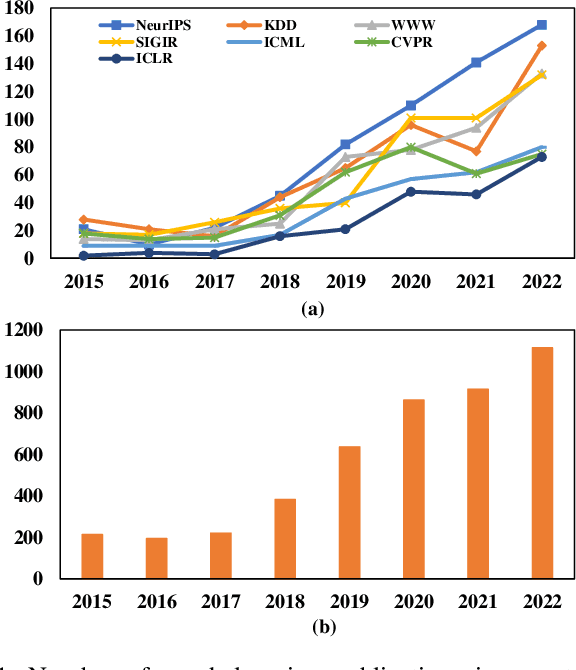
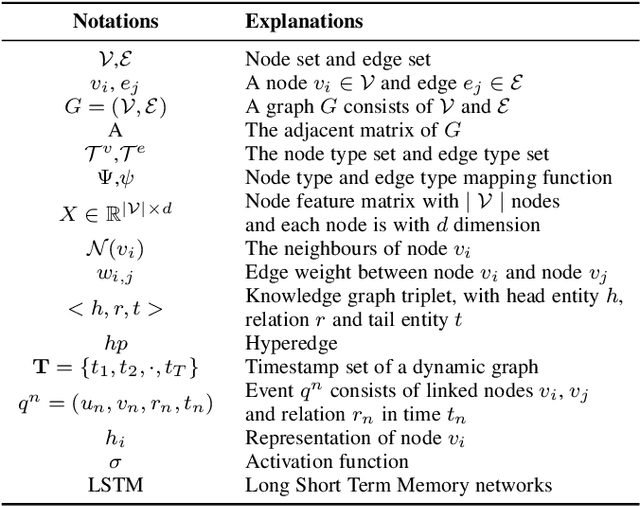
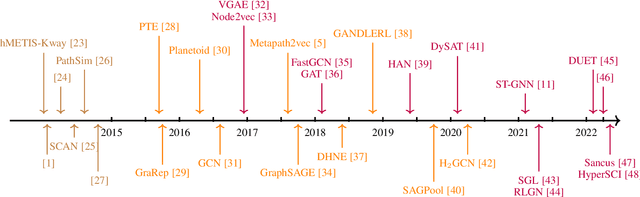

Graph learning aims to learn complex relationships among nodes and the topological structure of graphs, such as social networks, academic networks and e-commerce networks, which are common in the real world. Those relationships make graphs special compared with traditional tabular data in which nodes are dependent on non-Euclidean space and contain rich information to explore. Graph learning developed from graph theory to graph data mining and now is empowered with representation learning, making it achieve great performances in various scenarios, even including text, image, chemistry, and biology. Due to the broad application prospects in the real world, graph learning has become a popular and promising area in machine learning. Thousands of works have been proposed to solve various kinds of problems in graph learning and is appealing more and more attention in academic community, which makes it pivotal to survey previous valuable works. Although some of the researchers have noticed this phenomenon and finished impressive surveys on graph learning. However, they failed to link related objectives, methods and applications in a more logical way and cover current ample scenarios as well as challenging problems due to the rapid expansion of the graph learning.
Shape Aware Automatic Region-of-Interest Subdivisions
Dec 17, 2022
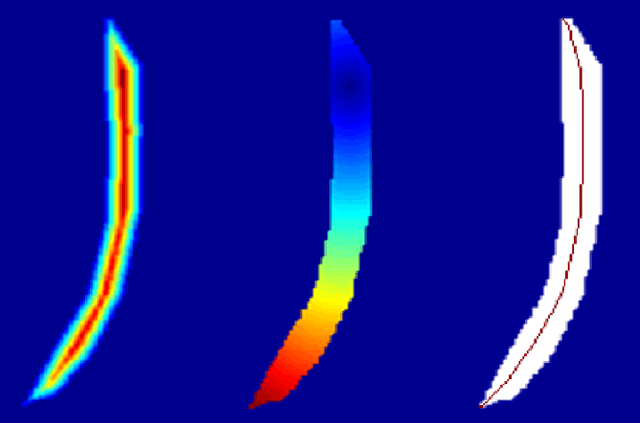
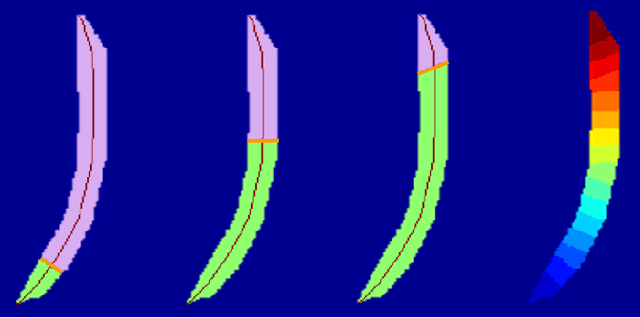
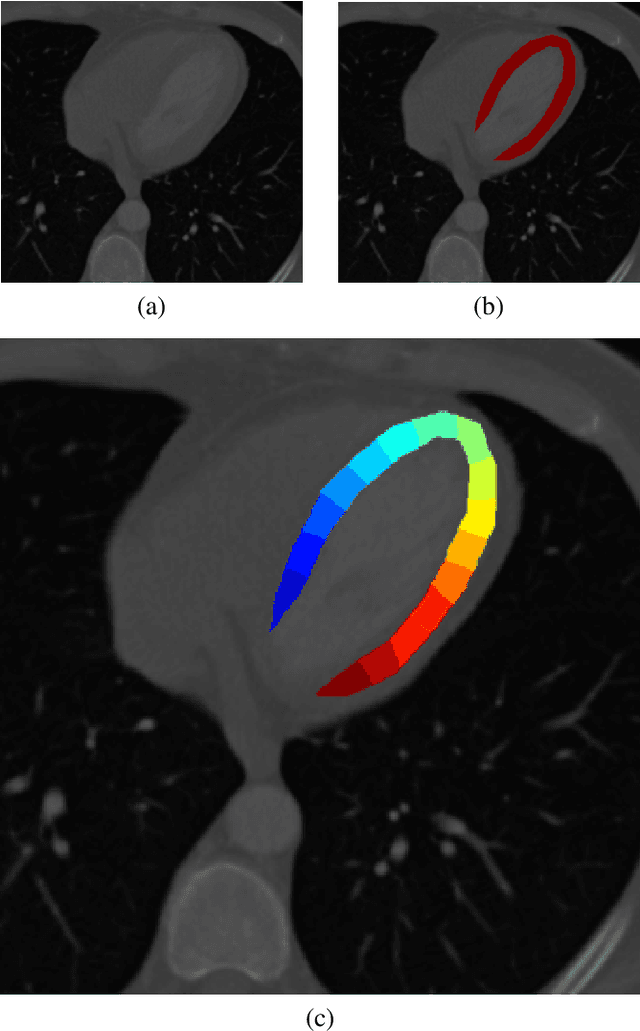
In a wide variety of fields, analysis of images involves defining a region and measuring its inherent properties. Such measurements include a region's surface area, curvature, volume, average gray and/or color scale, and so on. Furthermore, the subsequent subdivision of these regions is sometimes performed. These subdivisions are then used to measure local information, at even finer scales. However, simple griding or manual editing methods are typically used to subdivide a region into smaller units. The resulting subdivisions can therefore either not relate well to the actual shape or property of the region being studied (i.e., gridding methods), or be time consuming and based on user subjectivity (i.e., manual methods). The method discussed in this work extracts subdivisional units based on a region's general shape information. We present the results of applying our method to the medical image analysis of nested regions-of-interest of myocardial wall, where the subdivisions are used to study temporal and/or spatial heterogeneity of myocardial perfusion. This method is of particular interest for creating subdivision regions-of-interest (SROIs) when no variable intensity or other criteria within a region need be used to separate a particular region into subunits.
Asymmetric Distillation Post-Segmentation Method for Image Anomaly Detection
Oct 19, 2022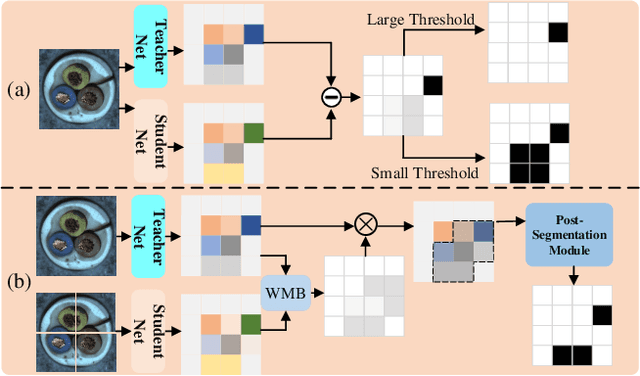
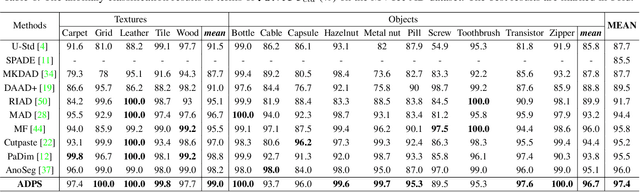
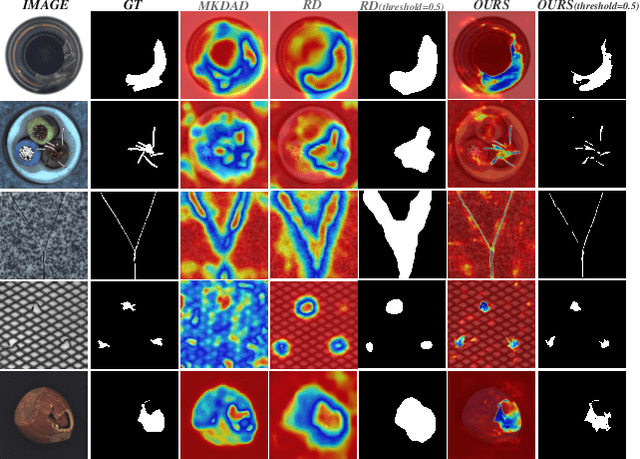
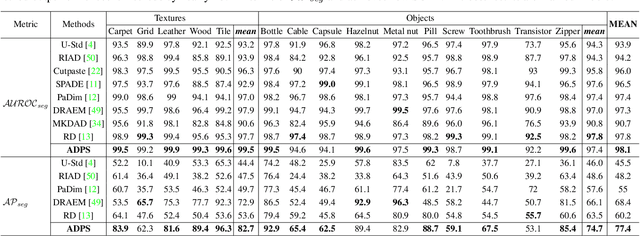
Knowledge distillation-based anomaly detection methods generate same outputs for unknown classes due to the symmetric form of the input and ignore the powerful semantic information of the output of the teacher network since it is only used as a "reference standard". Towards this end, this work proposes a novel Asymmetric Distillation Post-Segmentation (ADPS) method to effectively explore the asymmetric structure of the input and the discriminative features of the teacher network. Specifically, a simple yet effective asymmetric input approach is proposed to make different data flows through the teacher and student networks. The student network enables to have different inductive and expressive abilities, which can generate different outputs in anomalous regions. Besides, to further explore the semantic information of the teacher network and obtain effective discriminative boundaries, the Weight Mask Block (WMB) and the post-segmentation module are proposede. WMB leverages a weighted strategy by exploring teacher-student feature maps to highlight anomalous features. The post-segmentation module further learns the anomalous features and obtains valid discriminative boundaries. Experimental results on three benchmark datasets demonstrate that the proposed ADPS achieves state-of-the-art anomaly segmentation results.