 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CAE v2: Context Autoencoder with CLIP Target
Nov 17, 2022
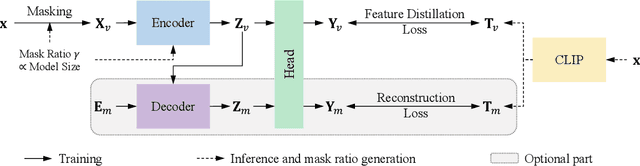
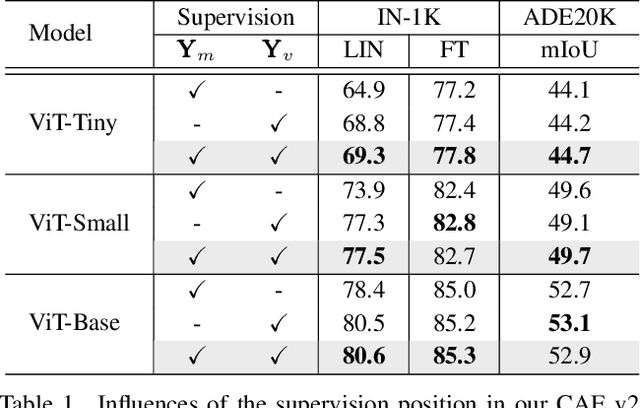
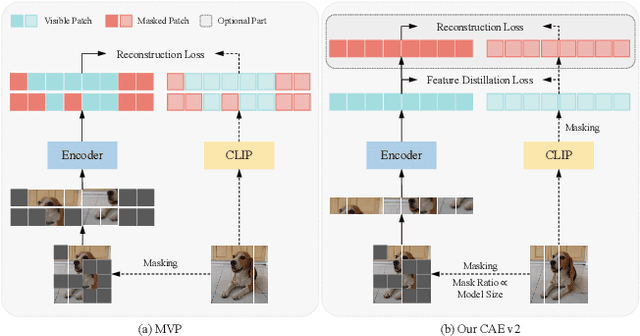
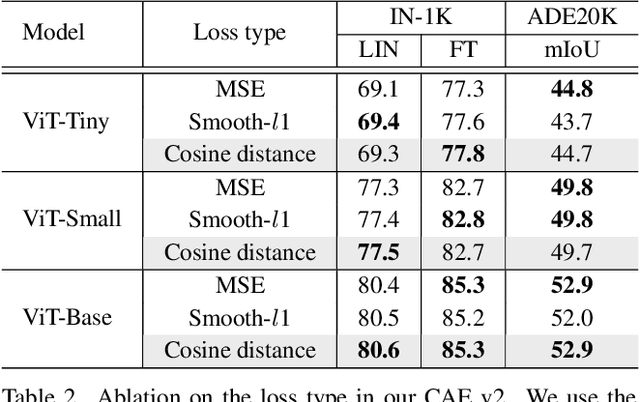
Masked image modeling (MIM) learns visual representation by masking and reconstructing image patches. Applying the reconstruction supervision on the CLIP representation has been proven effective for MIM. However, it is still under-explored how CLIP supervision in MIM influences performance. To investigate strategies for refining the CLIP-targeted MIM, we study two critical elements in MIM, i.e., the supervision position and the mask ratio, and reveal two interesting perspectives, relying on our developed simple pipeline, context autodecoder with CLIP target (CAE v2). Firstly, we observe that the supervision on visible patches achieves remarkable performance, even better than that on masked patches, where the latter is the standard format in the existing MIM methods. Secondly, the optimal mask ratio positively correlates to the model size. That is to say, the smaller the model, the lower the mask ratio needs to be. Driven by these two discoveries, our simple and concise approach CAE v2 achieves superior performance on a series of downstream tasks. For example, a vanilla ViT-Large model achieves 81.7% and 86.7% top-1 accuracy on linear probing and fine-tuning on ImageNet-1K, and 55.9% mIoU on semantic segmentation on ADE20K with the pre-training for 300 epochs. We hope our findings can be helpful guidelines for the pre-training in the MIM area, especially for the small-scale models.
Localizing Objects in 3D from Egocentric Videos with Visual Queries
Dec 14, 2022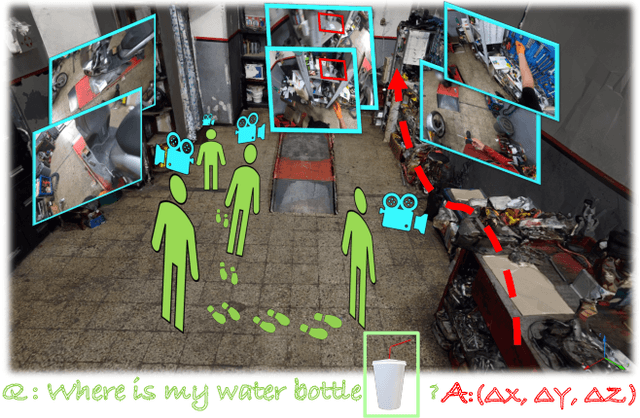

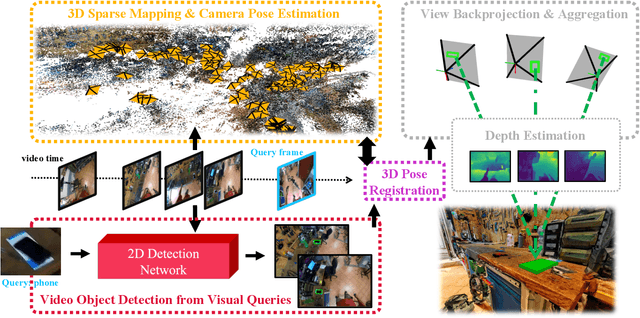
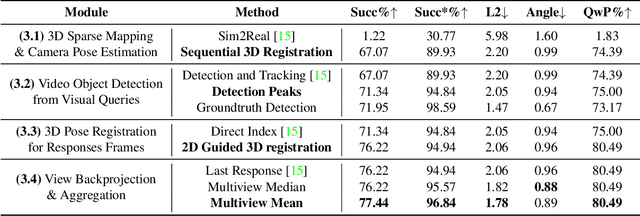
With the recent advances in video and 3D understanding, novel 4D spatio-temporal challenges fusing both concepts have emerged. Towards this direction, the Ego4D Episodic Memory Benchmark proposed a task for Visual Queries with 3D Localization (VQ3D). Given an egocentric video clip and an image crop depicting a query object, the goal is to localize the 3D position of the center of that query object with respect to the camera pose of a query frame. Current methods tackle the problem of VQ3D by lifting the 2D localization results of the sister task Visual Queries with 2D Localization (VQ2D) into a 3D reconstruction. Yet, we point out that the low number of Queries with Poses (QwP) from previous VQ3D methods severally hinders their overall success rate and highlights the need for further effort in 3D modeling to tackle the VQ3D task. In this work, we formalize a pipeline that better entangles 3D multiview geometry with 2D object retrieval from egocentric videos. We estimate more robust camera poses, leading to more successful object queries and substantially improved VQ3D performance. In practice, our method reaches a top-1 overall success rate of 86.36% on the Ego4D Episodic Memory Benchmark VQ3D, a 10x improvement over the previous state-of-the-art. In addition, we provide a complete empirical study highlighting the remaining challenges in VQ3D.
Improving Document Image Understanding with Reinforcement Finetuning
Sep 26, 2022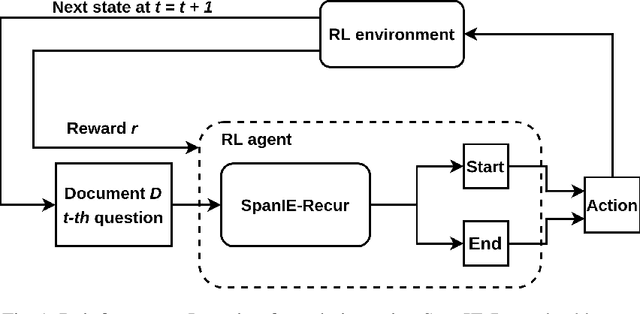
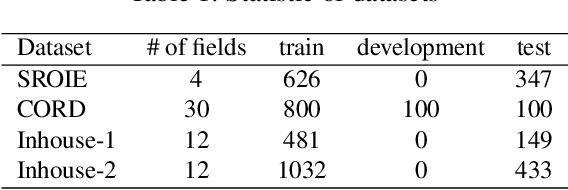
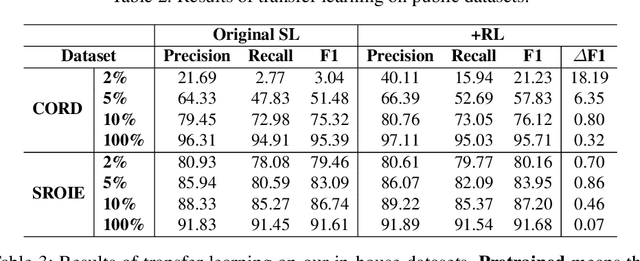
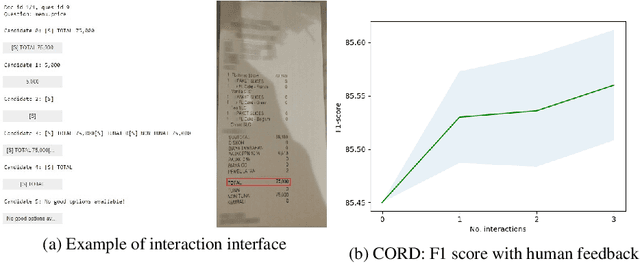
Successful Artificial Intelligence systems often require numerous labeled data to extract information from document images. In this paper, we investigate the problem of improving the performance of Artificial Intelligence systems in understanding document images, especially in cases where training data is limited. We address the problem by proposing a novel finetuning method using reinforcement learning. Our approach treats the Information Extraction model as a policy network and uses policy gradient training to update the model to maximize combined reward functions that complement the traditional cross-entropy losses. Our experiments on four datasets using labels and expert feedback demonstrate that our finetuning mechanism consistently improves the performance of a state-of-the-art information extractor, especially in the small training data regime.
Touch and Go: Learning from Human-Collected Vision and Touch
Nov 29, 2022

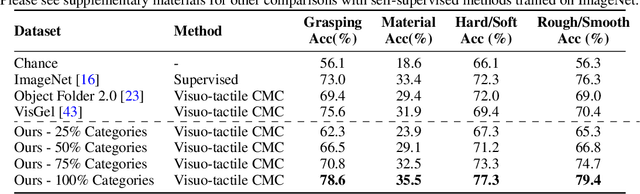

The ability to associate touch with sight is essential for tasks that require physically interacting with objects in the world. We propose a dataset with paired visual and tactile data called Touch and Go, in which human data collectors probe objects in natural environments using tactile sensors, while simultaneously recording egocentric video. In contrast to previous efforts, which have largely been confined to lab settings or simulated environments, our dataset spans a large number of "in the wild" objects and scenes. To demonstrate our dataset's effectiveness, we successfully apply it to a variety of tasks: 1) self-supervised visuo-tactile feature learning, 2) tactile-driven image stylization, i.e., making the visual appearance of an object more consistent with a given tactile signal, and 3) predicting future frames of a tactile signal from visuo-tactile inputs.
Mind the Gap: Scanner-induced domain shifts pose challenges for representation learning in histopathology
Nov 29, 2022
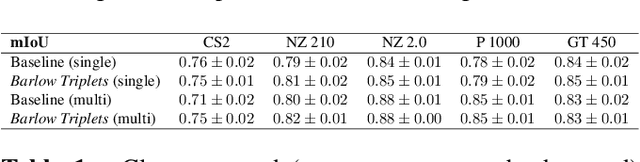
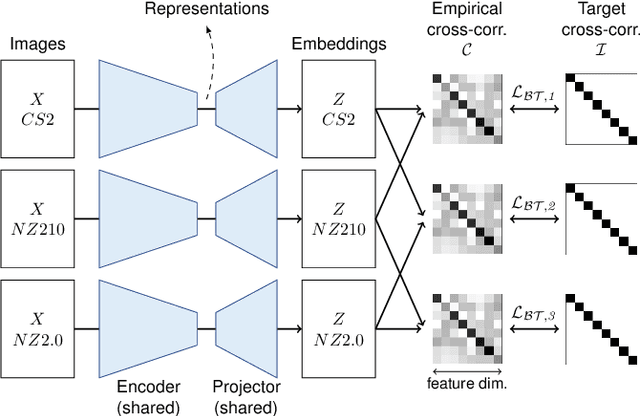
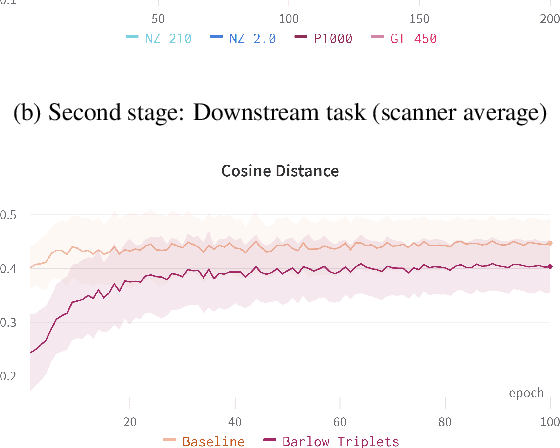
Computer-aided systems in histopathology are often challenged by various sources of domain shift that impact the performance of these algorithms considerably. We investigated the potential of using self-supervised pre-training to overcome scanner-induced domain shifts for the downstream task of tumor segmentation. For this, we present the Barlow Triplets to learn scanner-invariant representations from a multi-scanner dataset with local image correspondences. We show that self-supervised pre-training successfully aligned different scanner representations, which, interestingly only results in a limited benefit for our downstream task. We thereby provide insights into the influence of scanner characteristics for downstream applications and contribute to a better understanding of why established self-supervised methods have not yet shown the same success on histopathology data as they have for natural images.
A Multi-Modality Ovarian Tumor Ultrasound Image Dataset for Unsupervised Cross-Domain Semantic Segmentation
Jul 14, 2022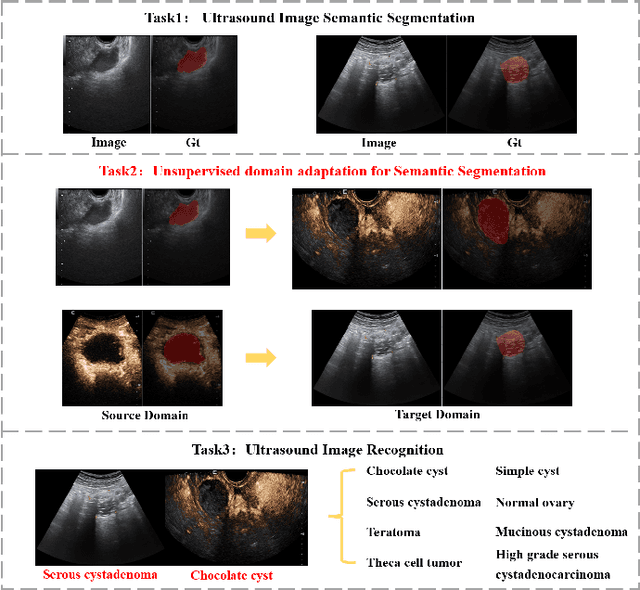
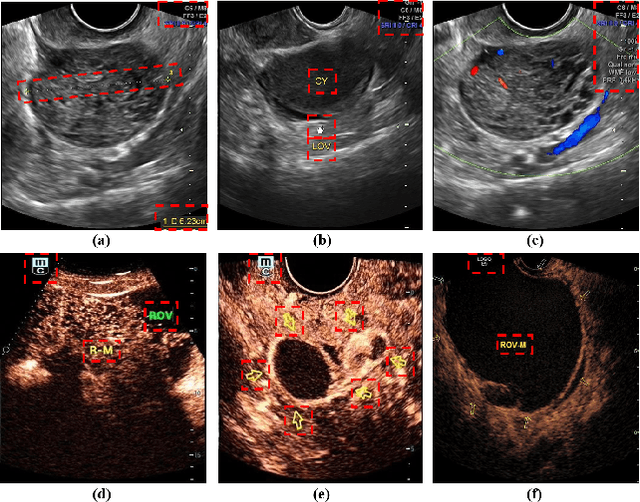
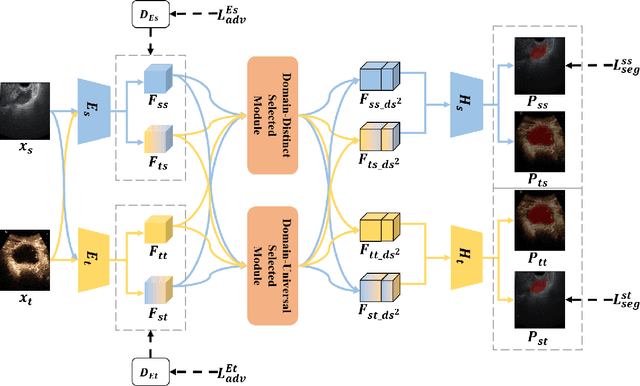
Ovarian cancer is one of the most harmful gynecological diseases. Detecting ovarian tumors in early stage with computer-aided techniques can efficiently decrease the mortality rate. With the improvement of medical treatment standard, ultrasound images are widely applied in clinical treatment. However, recent notable methods mainly focus on single-modality ultrasound ovarian tumor segmentation or recognition, which means there still lacks of researches on exploring the representation capability of multi-modality ultrasound ovarian tumor images. To solve this problem, we propose a Multi-Modality Ovarian Tumor Ultrasound (MMOTU) image dataset containing 1469 2d ultrasound images and 170 contrast enhanced ultrasonography (CEUS) images with pixel-wise and global-wise annotations. Based on MMOTU, we mainly focus on unsupervised cross-domain semantic segmentation task. To solve the domain shift problem, we propose a feature alignment based architecture named Dual-Scheme Domain-Selected Network (DS$^2$Net). Specifically, we first design source-encoder and target-encoder to extract two-style features of source and target images. Then, we propose Domain-Distinct Selected Module (DDSM) and Domain-Universal Selected Module (DUSM) to extract the distinct and universal features in two styles (source-style or target-style). Finally, we fuse these two kinds of features and feed them into the source-decoder and target-decoder to generate final predictions. Extensive comparison experiments and analysis on MMOTU image dataset show that DS$^2$Net can boost the segmentation performance for bidirectional cross-domain adaptation of 2d ultrasound images and CEUS images.
I saw, I conceived, I concluded: Progressive Concepts as Bottlenecks
Nov 19, 2022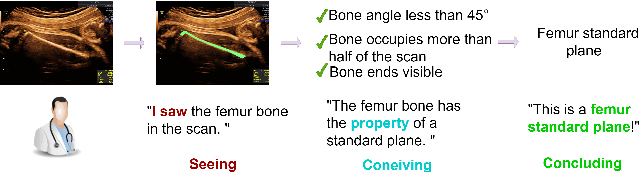
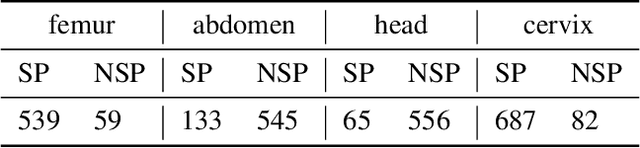
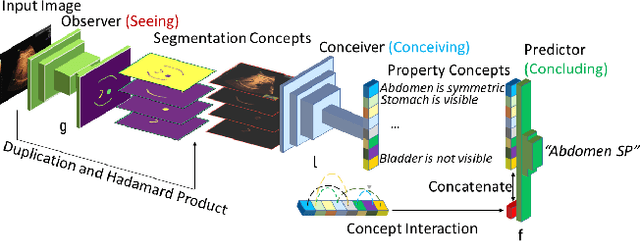
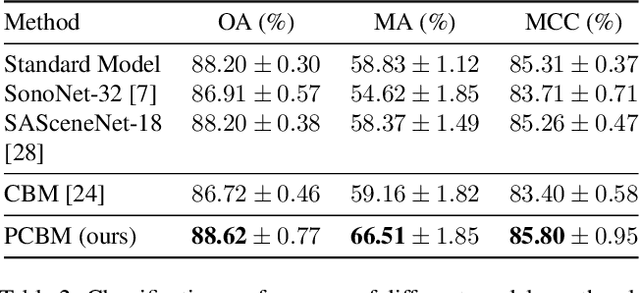
Concept bottleneck models (CBMs) include a bottleneck of human-interpretable concepts providing explainability and intervention during inference by correcting the predicted, intermediate concepts. This makes CBMs attractive for high-stakes decision-making. In this paper, we take the quality assessment of fetal ultrasound scans as a real-life use case for CBM decision support in healthcare. For this case, simple binary concepts are not sufficiently reliable, as they are mapped directly from images of highly variable quality, for which variable model calibration might lead to unstable binarized concepts. Moreover, scalar concepts do not provide the intuitive spatial feedback requested by users. To address this, we design a hierarchical CBM imitating the sequential expert decision-making process of "seeing", "conceiving" and "concluding". Our model first passes through a layer of visual, segmentation-based concepts, and next a second layer of property concepts directly associated with the decision-making task. We note that experts can intervene on both the visual and property concepts during inference. Additionally, we increase the bottleneck capacity by considering task-relevant concept interaction. Our application of ultrasound scan quality assessment is challenging, as it relies on balancing the (often poor) image quality against an assessment of the visibility and geometric properties of standardized image content. Our validation shows that -- in contrast with previous CBM models -- our CBM models actually outperform equivalent concept-free models in terms of predictive performance. Moreover, we illustrate how interventions can further improve our performance over the state-of-the-art.
Graph Neural Networks Extract High-Resolution Cultivated Land Maps from Sentinel-2 Image Series
Aug 03, 2022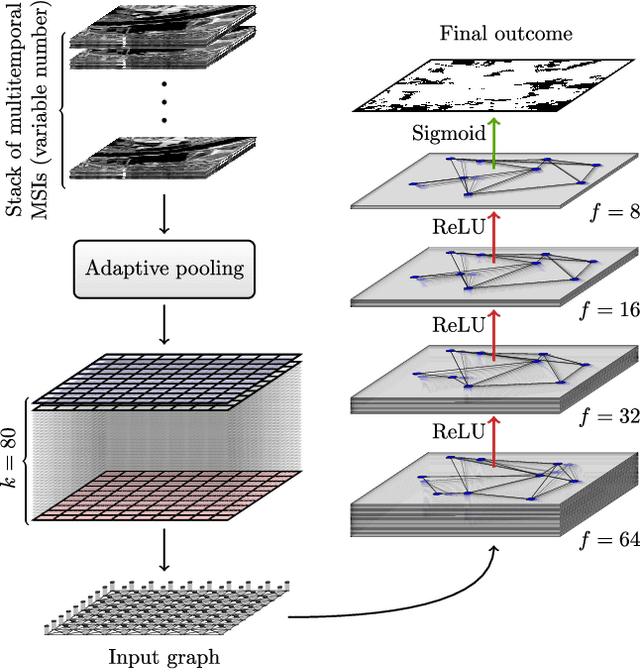

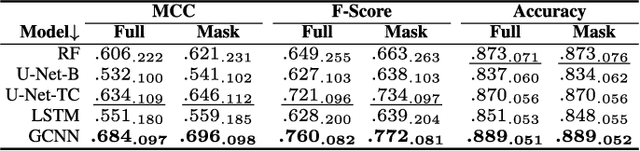
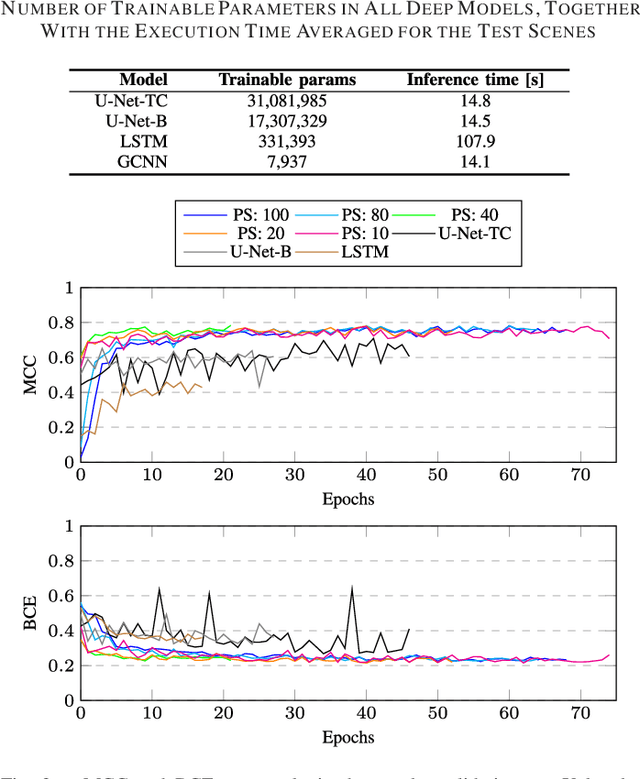
Maintaining farm sustainability through optimizing the agricultural management practices helps build more planet-friendly environment. The emerging satellite missions can acquire multi- and hyperspectral imagery which captures more detailed spectral information concerning the scanned area, hence allows us to benefit from subtle spectral features during the analysis process in agricultural applications. We introduce an approach for extracting 2.5 m cultivated land maps from 10 m Sentinel-2 multispectral image series which benefits from a compact graph convolutional neural network. The experiments indicate that our models not only outperform classical and deep machine learning techniques through delivering higher-quality segmentation maps, but also dramatically reduce the memory footprint when compared to U-Nets (almost 8k trainable parameters of our models, with up to 31M parameters of U-Nets). Such memory frugality is pivotal in the missions which allow us to uplink a model to the AI-powered satellite once it is in orbit, as sending large nets is impossible due to the time constraints.
* 7 pages (including supplementary material), published in IEEE Geoscience and Remote Sensing Letters
Insurgency as Complex Network: Image Co-Appearance and Hierarchy in the PKK
Jul 14, 2022
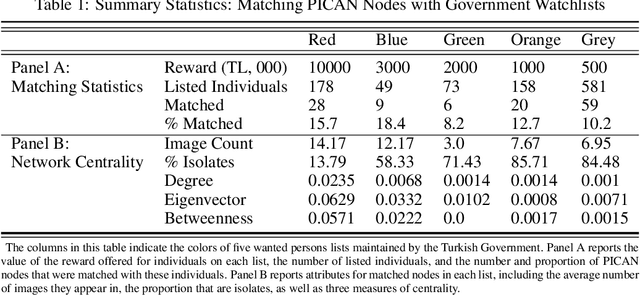
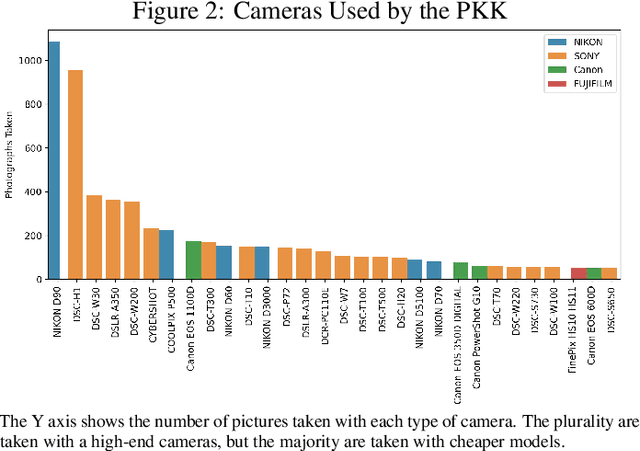
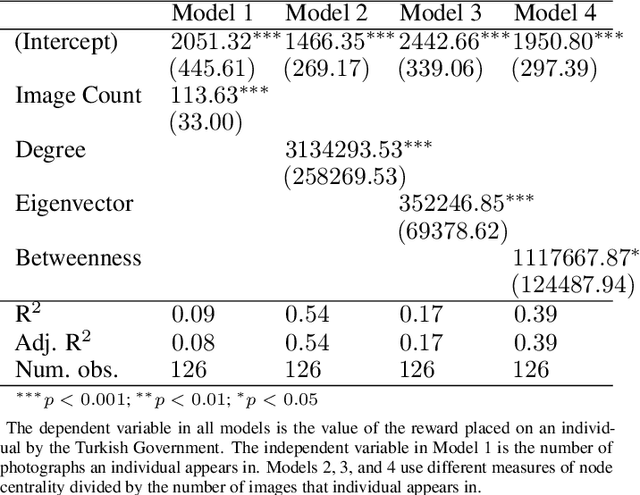
Despite a growing recognition of the importance of insurgent group structure on conflict outcomes, there is very little empirical research thereon. Though this problem is rooted in the inaccessibility of data on militant group structure, insurgents frequently publish large volumes of image data on the internet. In this paper, I develop a new methodology that leverages this abundant but underutilized source of data by automating the creation of a social network graph based on co-appearance in photographs using deep learning. Using a trove of 19,115 obituary images published online by the PKK, a Kurdish militant group in Turkey, I demonstrate that an individual's centrality in the resulting co-appearance network is closely correlated with their rank in the insurgent group.
Framework Construction of an Adversarial Federated Transfer Learning Classifier
Nov 09, 2022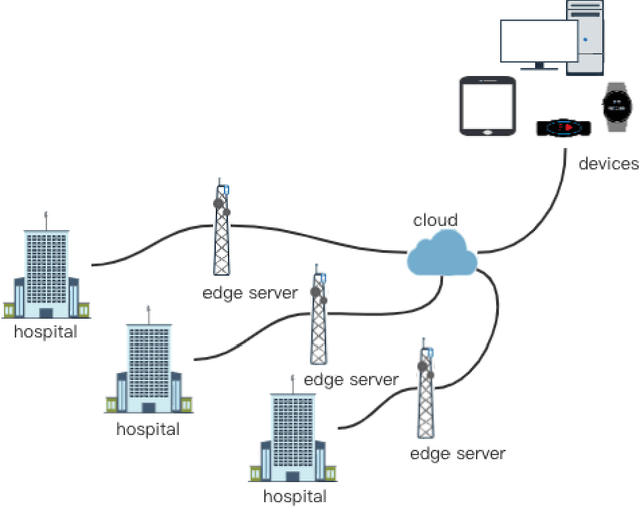
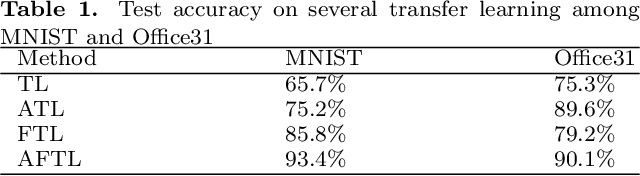
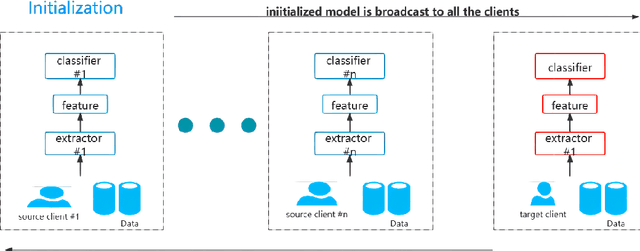
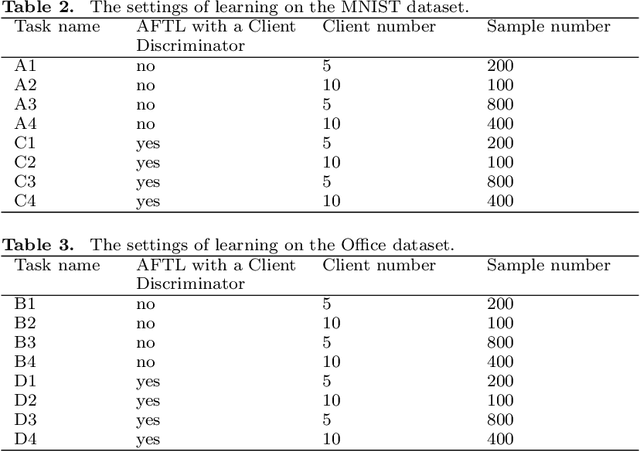
As the Internet grows in popularity, more and more classification jobs, such as IoT, finance industry and healthcare field, rely on mobile edge computing to advance machine learning. In the medical industry, however, good diagnostic accuracy necessitates the combination of large amounts of labeled data to train the model, which is difficult and expensive to collect and risks jeopardizing patients' privacy. In this paper, we offer a novel medical diagnostic framework that employs a federated learning platform to ensure patient data privacy by transferring classification algorithms acquired in a labeled domain to a domain with sparse or missing labeled data. Rather than using a generative adversarial network, our framework uses a discriminative model to build multiple classification loss functions with the goal of improving diagnostic accuracy. It also avoids the difficulty of collecting large amounts of labeled data or the high cost of generating large amount of sample data. Experiments on real-world image datasets demonstrates that the suggested adversarial federated transfer learning method is promising for real-world medical diagnosis applications that use image classification.