 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D Neural Field Generation using Triplane Diffusion
Nov 30, 2022
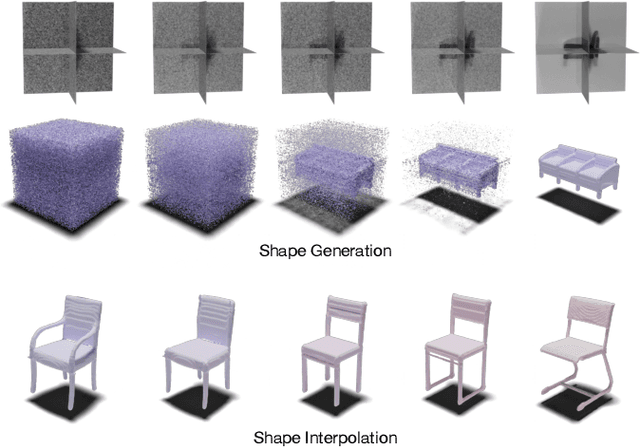
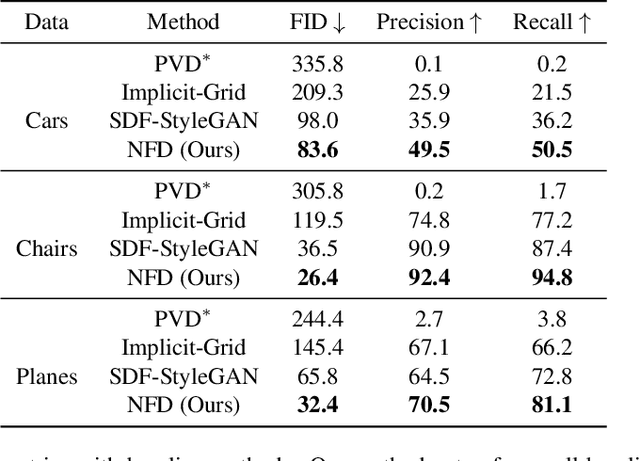

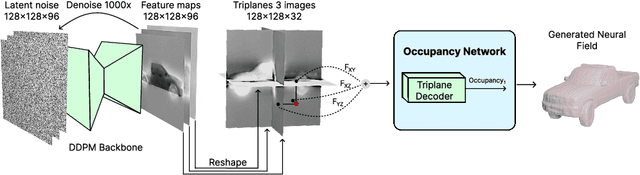
Diffusion models have emerged as the state-of-the-art for image generation, among other tasks. Here, we present an efficient diffusion-based model for 3D-aware generation of neural fields. Our approach pre-processes training data, such as ShapeNet meshes, by converting them to continuous occupancy fields and factoring them into a set of axis-aligned triplane feature representations. Thus, our 3D training scenes are all represented by 2D feature planes, and we can directly train existing 2D diffusion models on these representations to generate 3D neural fields with high quality and diversity, outperforming alternative approaches to 3D-aware generation. Our approach requires essential modifications to existing triplane factorization pipelines to make the resulting features easy to learn for the diffusion model. We demonstrate state-of-the-art results on 3D generation on several object classes from ShapeNet.
Differentiable optimization of the Debye-Wolf integral for light shaping and adaptive optics in two-photon microscopy
Nov 30, 2022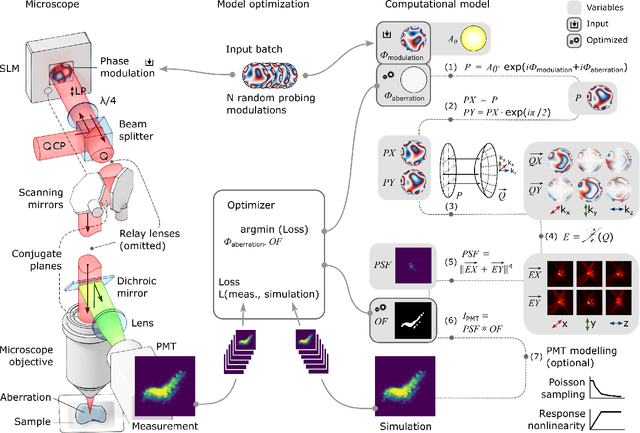
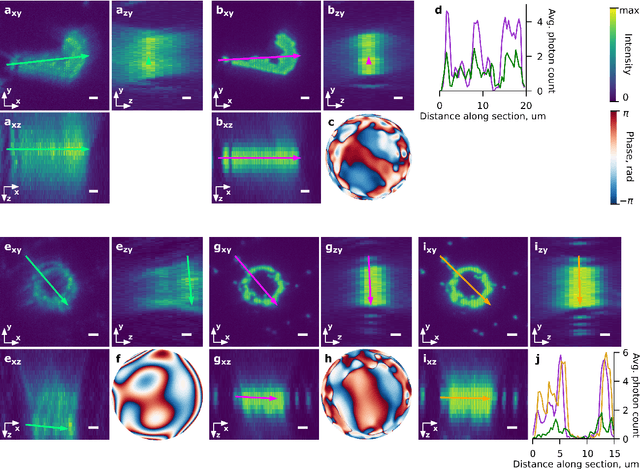
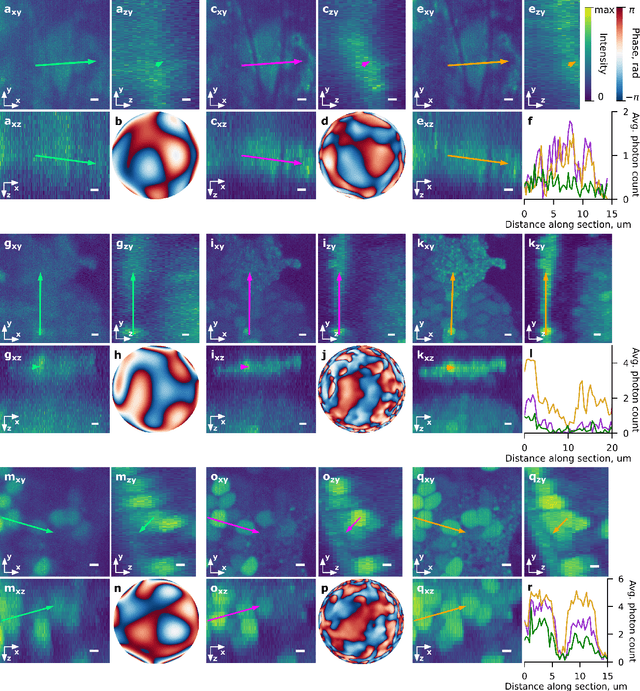
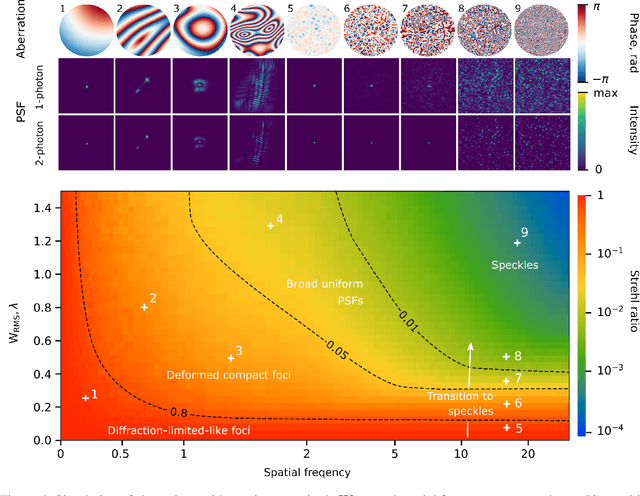
Control of light through a microscope objective with a high numerical aperture is a common requirement in applications such as optogenetics, adaptive optics, or laser processing. Light propagation, including polarization effects, can be described under these conditions using the Debye-Wolf diffraction integral. Here, we take advantage of differentiable optimization and machine learning for efficiently optimizing the Debye-Wolf integral for such applications. For light shaping we show that this optimization approach is suitable for engineering arbitrary three-dimensional point spread functions in a two-photon microscope. For differentiable model-based adaptive optics (DAO), the developed method can find aberration corrections with intrinsic image features, for example neurons labeled with genetically encoded calcium indicators, without requiring guide stars. Using computational modeling we further discuss the range of spatial frequencies and magnitudes of aberrations which can be corrected with this approach.
DeAR: A Deep-learning-based Audio Re-recording Resilient Watermarking
Dec 13, 2022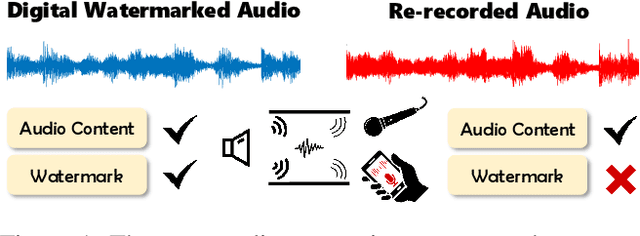

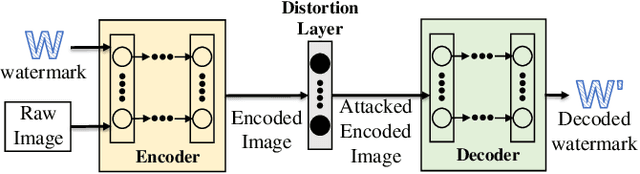

Audio watermarking is widely used for leaking source tracing. The robustness of the watermark determines the traceability of the algorithm. With the development of digital technology, audio re-recording (AR) has become an efficient and covert means to steal secrets. AR process could drastically destroy the watermark signal while preserving the original information. This puts forward a new requirement for audio watermarking at this stage, that is, to be robust to AR distortions. Unfortunately, none of the existing algorithms can effectively resist AR attacks due to the complexity of the AR process. To address this limitation, this paper proposes DeAR, a deep-learning-based audio re-recording resistant watermarking. Inspired by DNN-based image watermarking, we pioneer a deep learning framework for audio carriers, based on which the watermark signal can be effectively embedded and extracted. Meanwhile, in order to resist the AR attack, we delicately analyze the distortions that occurred in the AR process and design the corresponding distortion layer to cooperate with the proposed watermarking framework. Extensive experiments show that the proposed algorithm can resist not only common electronic channel distortions but also AR distortions. Under the premise of high-quality embedding (SNR=25.86dB), in the case of a common re-recording distance (20cm), the algorithm can effectively achieve an average bit recovery accuracy of 98.55%.
Towards Transparency in Dermatology Image Datasets with Skin Tone Annotations by Experts, Crowds, and an Algorithm
Jul 06, 2022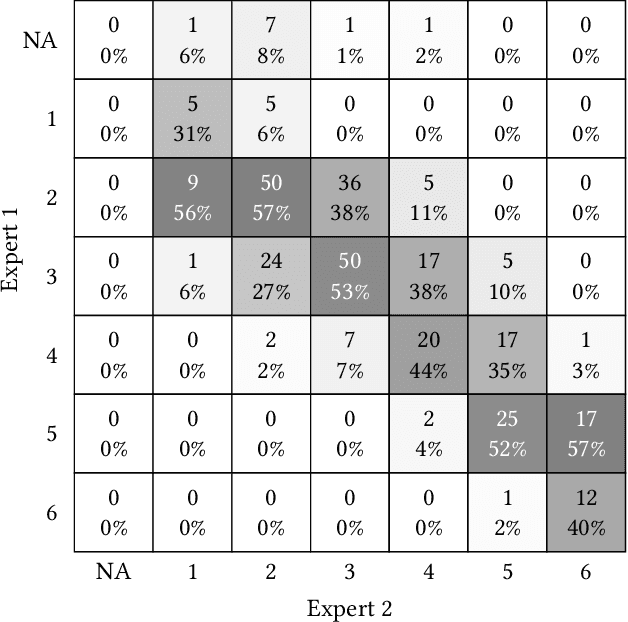
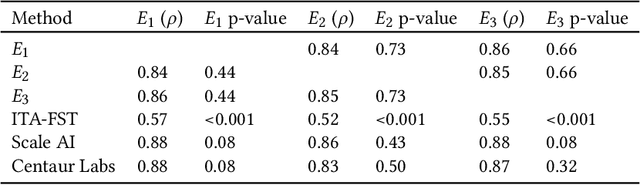
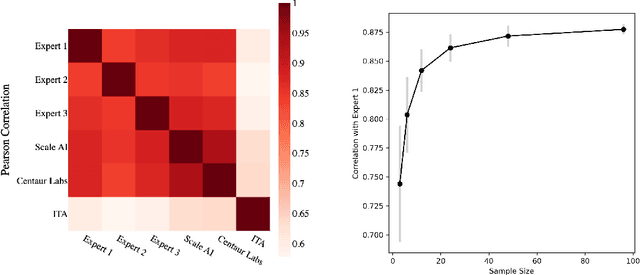
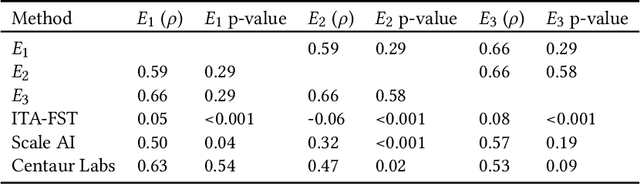
While artificial intelligence (AI) holds promise for supporting healthcare providers and improving the accuracy of medical diagnoses, a lack of transparency in the composition of datasets exposes AI models to the possibility of unintentional and avoidable mistakes. In particular, public and private image datasets of dermatological conditions rarely include information on skin color. As a start towards increasing transparency, AI researchers have appropriated the use of the Fitzpatrick skin type (FST) from a measure of patient photosensitivity to a measure for estimating skin tone in algorithmic audits of computer vision applications including facial recognition and dermatology diagnosis. In order to understand the variability of estimated FST annotations on images, we compare several FST annotation methods on a diverse set of 460 images of skin conditions from both textbooks and online dermatology atlases. We find the inter-rater reliability between three board-certified dermatologists is comparable to the inter-rater reliability between the board-certified dermatologists and two crowdsourcing methods. In contrast, we find that the Individual Typology Angle converted to FST (ITA-FST) method produces annotations that are significantly less correlated with the experts' annotations than the experts' annotations are correlated with each other. These results demonstrate that algorithms based on ITA-FST are not reliable for annotating large-scale image datasets, but human-centered, crowd-based protocols can reliably add skin type transparency to dermatology datasets. Furthermore, we introduce the concept of dynamic consensus protocols with tunable parameters including expert review that increase the visibility of crowdwork and provide guidance for future crowdsourced annotations of large image datasets.
Leveraging Angular Information Between Feature and Classifier for Long-tailed Learning: A Prediction Reformulation Approach
Dec 03, 2022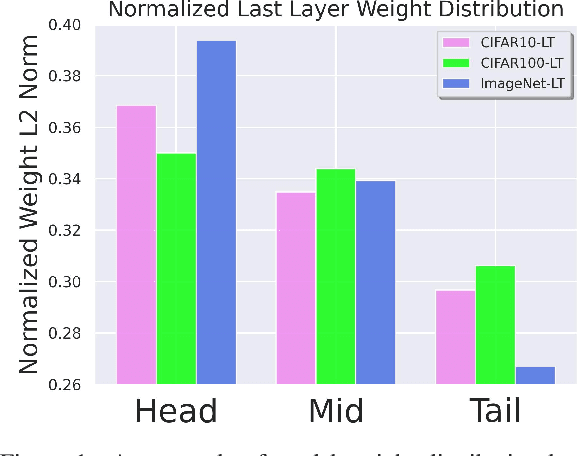
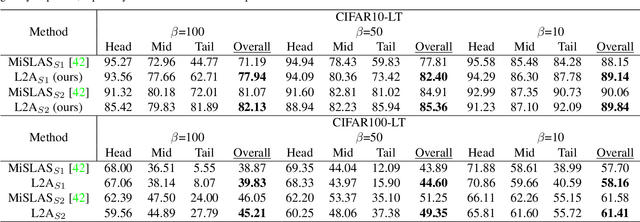
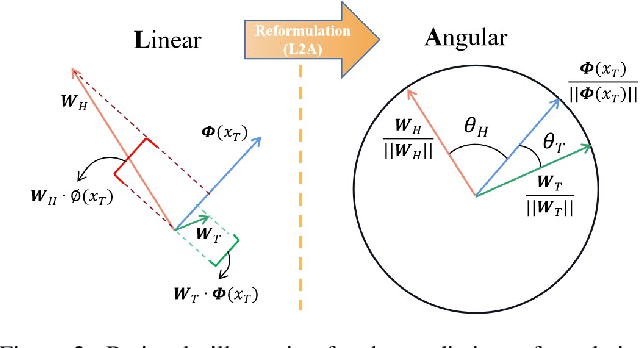
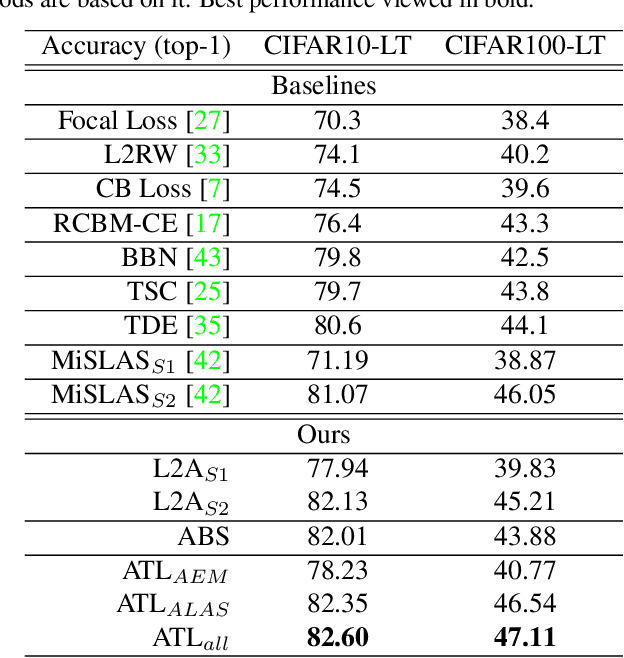
Deep neural networks still struggle on long-tailed image datasets, and one of the reasons is that the imbalance of training data across categories leads to the imbalance of trained model parameters. Motivated by the empirical findings that trained classifiers yield larger weight norms in head classes, we propose to reformulate the recognition probabilities through included angles without re-balancing the classifier weights. Specifically, we calculate the angles between the data feature and the class-wise classifier weights to obtain angle-based prediction results. Inspired by the performance improvement of the predictive form reformulation and the outstanding performance of the widely used two-stage learning framework, we explore the different properties of this angular prediction and propose novel modules to improve the performance of different components in the framework. Our method is able to obtain the best performance among peer methods without pretraining on CIFAR10/100-LT and ImageNet-LT. Source code will be made publicly available.
Robust Sensible Adversarial Learning of Deep Neural Networks for Image Classification
May 20, 2022
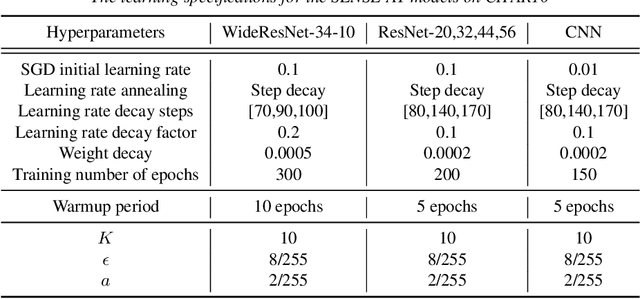

The idea of robustness is central and critical to modern statistical analysis. However, despite the recent advances of deep neural networks (DNNs), many studies have shown that DNNs are vulnerable to adversarial attacks. Making imperceptible changes to an image can cause DNN models to make the wrong classification with high confidence, such as classifying a benign mole as a malignant tumor and a stop sign as a speed limit sign. The trade-off between robustness and standard accuracy is common for DNN models. In this paper, we introduce sensible adversarial learning and demonstrate the synergistic effect between pursuits of standard natural accuracy and robustness. Specifically, we define a sensible adversary which is useful for learning a robust model while keeping high natural accuracy. We theoretically establish that the Bayes classifier is the most robust multi-class classifier with the 0-1 loss under sensible adversarial learning. We propose a novel and efficient algorithm that trains a robust model using implicit loss truncation. We apply sensible adversarial learning for large-scale image classification to a handwritten digital image dataset called MNIST and an object recognition colored image dataset called CIFAR10. We have performed an extensive comparative study to compare our method with other competitive methods. Our experiments empirically demonstrate that our method is not sensitive to its hyperparameter and does not collapse even with a small model capacity while promoting robustness against various attacks and keeping high natural accuracy.
Rethinking Surgical Instrument Segmentation: A Background Image Can Be All You Need
Jul 07, 2022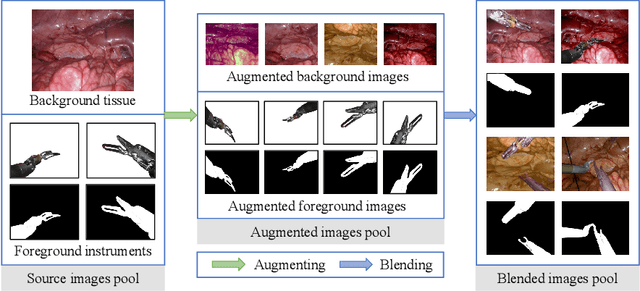
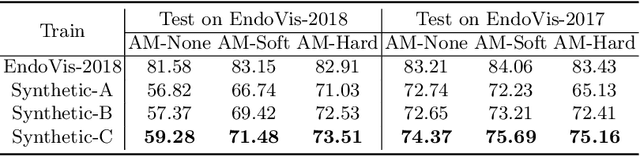


Data diversity and volume are crucial to the success of training deep learning models, while in the medical imaging field, the difficulty and cost of data collection and annotation are especially huge. Specifically in robotic surgery, data scarcity and imbalance have heavily affected the model accuracy and limited the design and deployment of deep learning-based surgical applications such as surgical instrument segmentation. Considering this, we rethink the surgical instrument segmentation task and propose a one-to-many data generation solution that gets rid of the complicated and expensive process of data collection and annotation from robotic surgery. In our method, we only utilize a single surgical background tissue image and a few open-source instrument images as the seed images and apply multiple augmentations and blending techniques to synthesize amounts of image variations. In addition, we also introduce the chained augmentation mixing during training to further enhance the data diversities. The proposed approach is evaluated on the real datasets of the EndoVis-2018 and EndoVis-2017 surgical scene segmentation. Our empirical analysis suggests that without the high cost of data collection and annotation, we can achieve decent surgical instrument segmentation performance. Moreover, we also observe that our method can deal with novel instrument prediction in the deployment domain. We hope our inspiring results will encourage researchers to emphasize data-centric methods to overcome demanding deep learning limitations besides data shortage, such as class imbalance, domain adaptation, and incremental learning. Our code is available at https://github.com/lofrienger/Single_SurgicalScene_For_Segmentation.
SCS-Co: Self-Consistent Style Contrastive Learning for Image Harmonization
Apr 29, 2022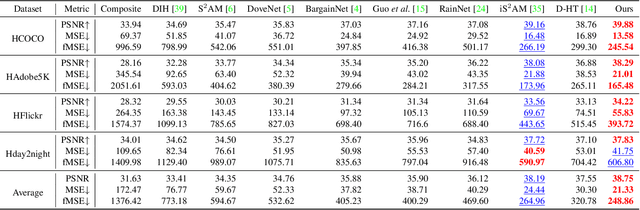
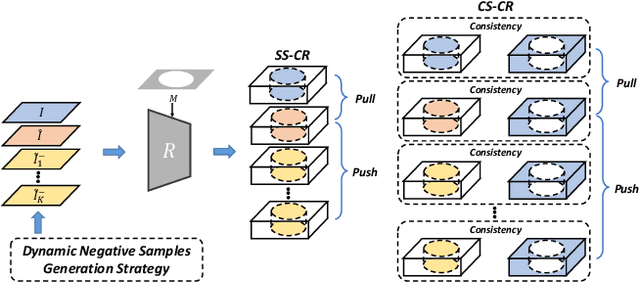
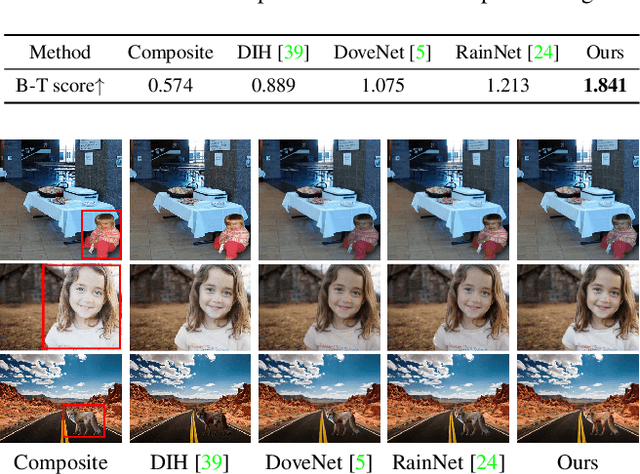
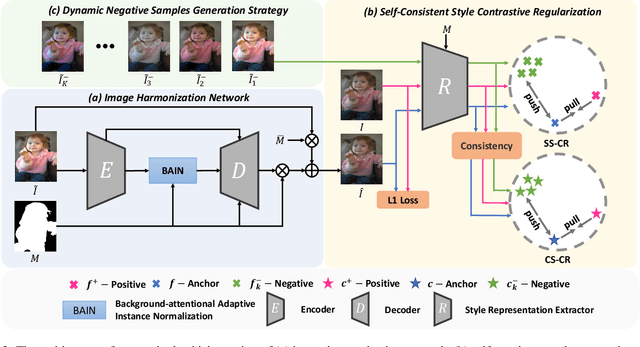
Image harmonization aims to achieve visual consistency in composite images by adapting a foreground to make it compatible with a background. However, existing methods always only use the real image as the positive sample to guide the training, and at most introduce the corresponding composite image as a single negative sample for an auxiliary constraint, which leads to limited distortion knowledge, and further causes a too large solution space, making the generated harmonized image distorted. Besides, none of them jointly constrain from the foreground self-style and foreground-background style consistency, which exacerbates this problem. Moreover, recent region-aware adaptive instance normalization achieves great success but only considers the global background feature distribution, making the aligned foreground feature distribution biased. To address these issues, we propose a self-consistent style contrastive learning scheme (SCS-Co). By dynamically generating multiple negative samples, our SCS-Co can learn more distortion knowledge and well regularize the generated harmonized image in the style representation space from two aspects of the foreground self-style and foreground-background style consistency, leading to a more photorealistic visual result. In addition, we propose a background-attentional adaptive instance normalization (BAIN) to achieve an attention-weighted background feature distribution according to the foreground-background feature similarity. Experiments demonstrate the superiority of our method over other state-of-the-art methods in both quantitative comparison and visual analysis.
Wavelet Knowledge Distillation: Towards Efficient Image-to-Image Translation
Mar 12, 2022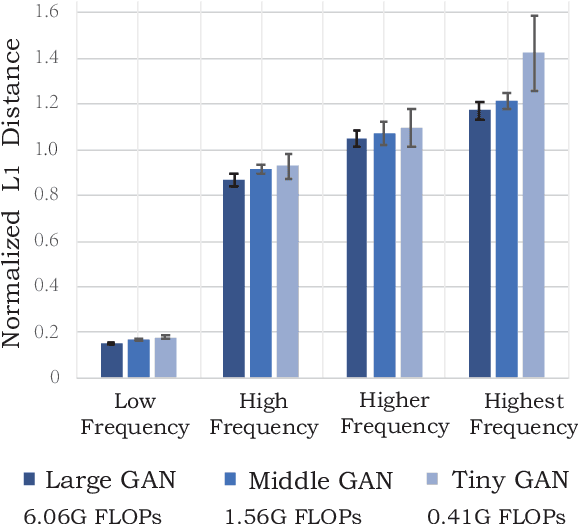
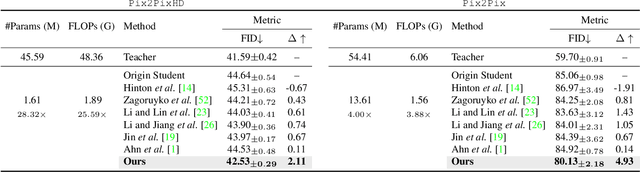
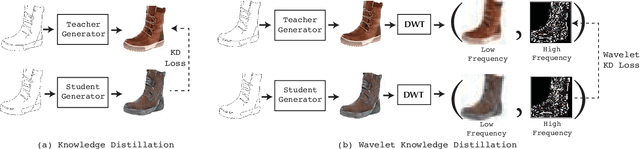
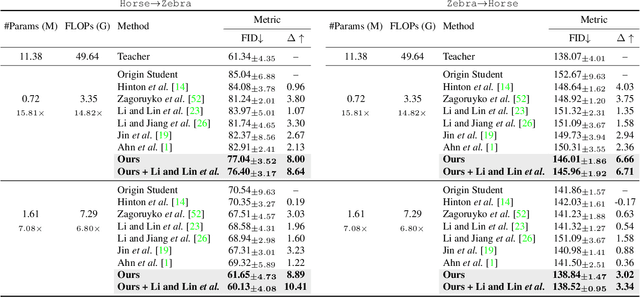
Remarkable achievements have been attained with Generative Adversarial Networks (GANs) in image-to-image translation. However, due to a tremendous amount of parameters, state-of-the-art GANs usually suffer from low efficiency and bulky memory usage. To tackle this challenge, firstly, this paper investigates GANs performance from a frequency perspective. The results show that GANs, especially small GANs lack the ability to generate high-quality high frequency information. To address this problem, we propose a novel knowledge distillation method referred to as wavelet knowledge distillation. Instead of directly distilling the generated images of teachers, wavelet knowledge distillation first decomposes the images into different frequency bands with discrete wavelet transformation and then only distills the high frequency bands. As a result, the student GAN can pay more attention to its learning on high frequency bands. Experiments demonstrate that our method leads to 7.08 times compression and 6.80 times acceleration on CycleGAN with almost no performance drop. Additionally, we have studied the relation between discriminators and generators which shows that the compression of discriminators can promote the performance of compressed generators.
An Image Processing Pipeline for Camera Trap Time-Lapse Recordings
Jun 10, 2022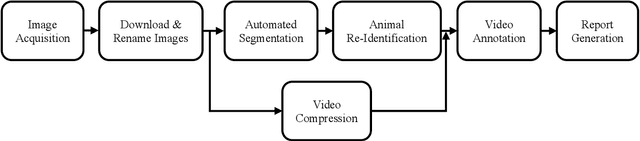
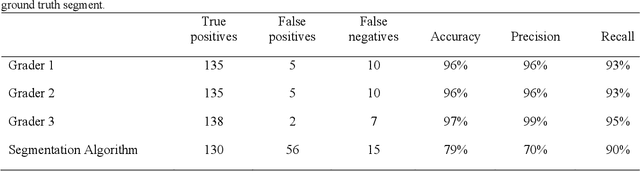

A new open-source image processing pipeline for analyzing camera trap time-lapse recordings is described. This pipeline includes machine learning models to assist human-in-the-loop video segmentation and animal re-identification. We present some performance results and observations on the utility of this pipeline after using it in a year-long project studying the spatial ecology and social behavior of the gopher tortoise.