 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Unsupervised Visual Reasoning: Do Off-The-Shelf Features Know How to Reason?
Dec 20, 2022
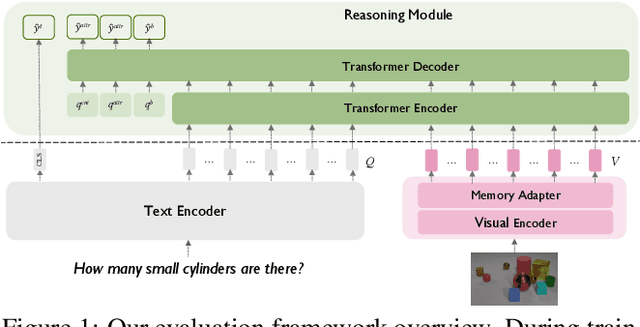
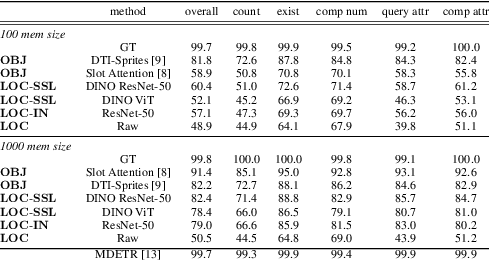
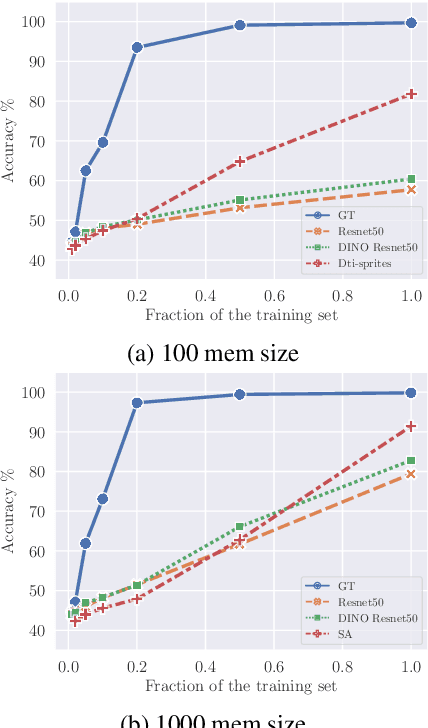

Recent advances in visual representation learning allowed to build an abundance of powerful off-the-shelf features that are ready-to-use for numerous downstream tasks. This work aims to assess how well these features preserve information about the objects, such as their spatial location, their visual properties and their relative relationships. We propose to do so by evaluating them in the context of visual reasoning, where multiple objects with complex relationships and different attributes are at play. More specifically, we introduce a protocol to evaluate visual representations for the task of Visual Question Answering. In order to decouple visual feature extraction from reasoning, we design a specific attention-based reasoning module which is trained on the frozen visual representations to be evaluated, in a spirit similar to standard feature evaluations relying on shallow networks. We compare two types of visual representations, densely extracted local features and object-centric ones, against the performances of a perfect image representation using ground truth. Our main findings are two-fold. First, despite excellent performances on classical proxy tasks, such representations fall short for solving complex reasoning problem. Second, object-centric features better preserve the critical information necessary to perform visual reasoning. In our proposed framework we show how to methodologically approach this evaluation.
Improving Pixel-Level Contrastive Learning by Leveraging Exogenous Depth Information
Nov 18, 2022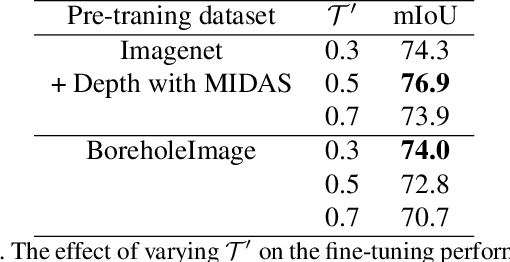
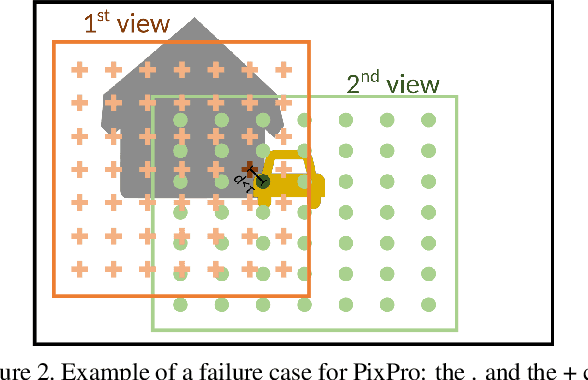
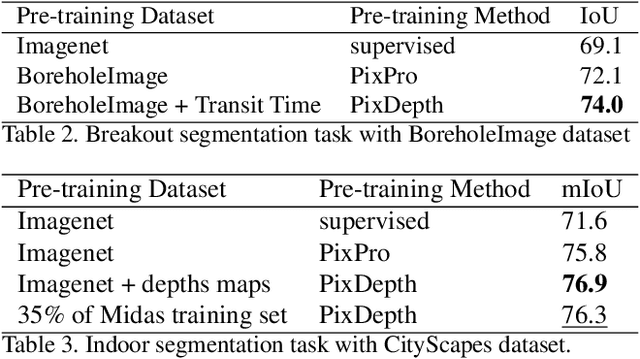
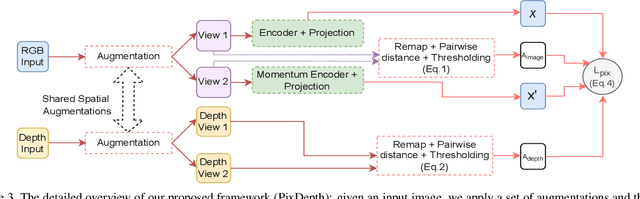
Self-supervised representation learning based on Contrastive Learning (CL) has been the subject of much attention in recent years. This is due to the excellent results obtained on a variety of subsequent tasks (in particular classification), without requiring a large amount of labeled samples. However, most reference CL algorithms (such as SimCLR and MoCo, but also BYOL and Barlow Twins) are not adapted to pixel-level downstream tasks. One existing solution known as PixPro proposes a pixel-level approach that is based on filtering of pairs of positive/negative image crops of the same image using the distance between the crops in the whole image. We argue that this idea can be further enhanced by incorporating semantic information provided by exogenous data as an additional selection filter, which can be used (at training time) to improve the selection of the pixel-level positive/negative samples. In this paper we will focus on the depth information, which can be obtained by using a depth estimation network or measured from available data (stereovision, parallax motion, LiDAR, etc.). Scene depth can provide meaningful cues to distinguish pixels belonging to different objects based on their depth. We show that using this exogenous information in the contrastive loss leads to improved results and that the learned representations better follow the shapes of objects. In addition, we introduce a multi-scale loss that alleviates the issue of finding the training parameters adapted to different object sizes. We demonstrate the effectiveness of our ideas on the Breakout Segmentation on Borehole Images where we achieve an improvement of 1.9\% over PixPro and nearly 5\% over the supervised baseline. We further validate our technique on the indoor scene segmentation tasks with ScanNet and outdoor scenes with CityScapes ( 1.6\% and 1.1\% improvement over PixPro respectively).
DeepMB: Deep neural network for real-time model-based optoacoustic image reconstruction with adjustable speed of sound
Jun 29, 2022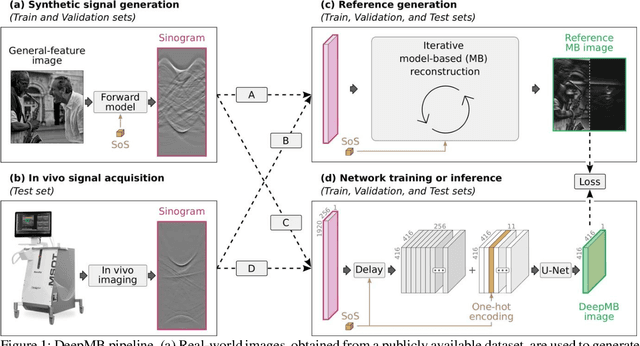
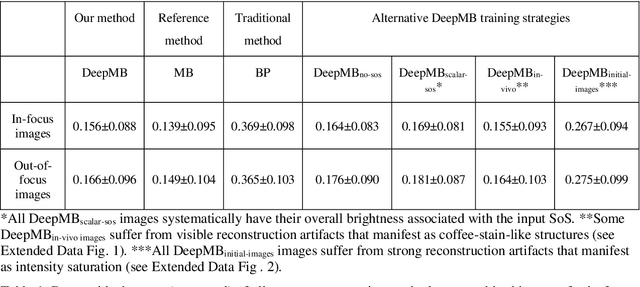

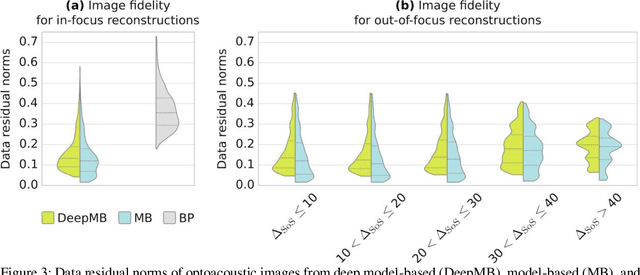
Multispectral optoacoustic tomography (MSOT) is a high-resolution functional imaging modality that can non-invasively access a broad range of pathophysiological phenomena by quantifying the contrast of endogenous chromophores in tissue. Real-time imaging is imperative to translate MSOT into clinical imaging, visualize dynamic pathophysiological changes associated with disease progression, and enable in situ diagnoses. Model-based reconstruction affords state-of-the-art optoacoustic images; however, the advanced image quality provided by model-based reconstruction remains inaccessible during real-time imaging because the algorithm is iterative and computationally demanding. Deep-learning may afford faster reconstructions for real-time optoacoustic imaging, but existing approaches only support oversimplified imaging settings and fail to generalize to in vivo data. In this work, we introduce a novel deep-learning framework, termed DeepMB, to learn the model-based reconstruction operator and infer optoacoustic images with state-of-the-art quality in less than 10 ms per image. DeepMB accurately generalizes to in vivo data after training on synthesized sinograms that are derived from real-world images. The framework affords in-focus images for a broad range of anatomical locations because it supports dynamic adjustment of the reconstruction speed of sound during imaging. Furthermore, DeepMB is compatible with the data rates and image sizes of modern multispectral optoacoustic tomography scanners. We evaluate DeepMB on a diverse dataset of in vivo images and demonstrate that the framework reconstructs images 3000 times faster than the iterative model-based reference method while affording near-identical image qualities. Accurate and real-time image reconstructions with DeepMB can enable full access to the high-resolution and multispectral contrast of handheld optoacoustic tomography.
Summary-Oriented Vision Modeling for Multimodal Abstractive Summarization
Dec 15, 2022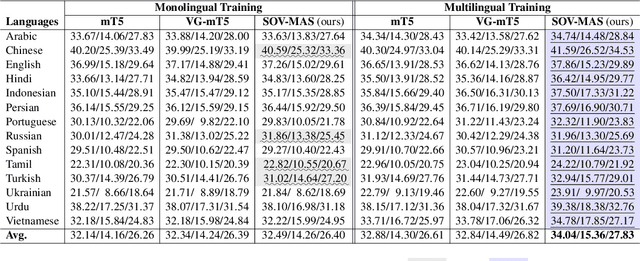
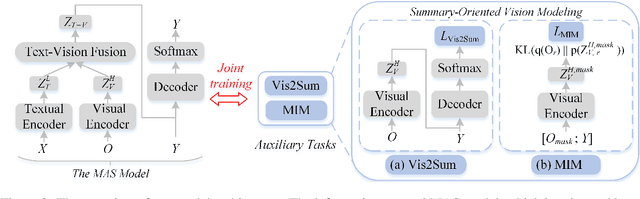
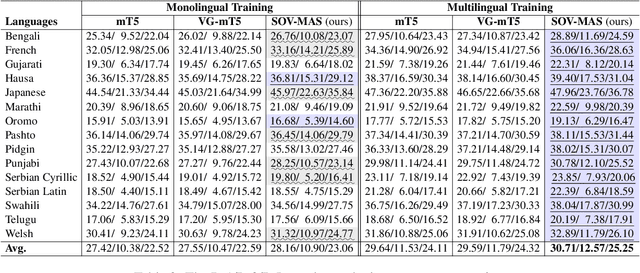
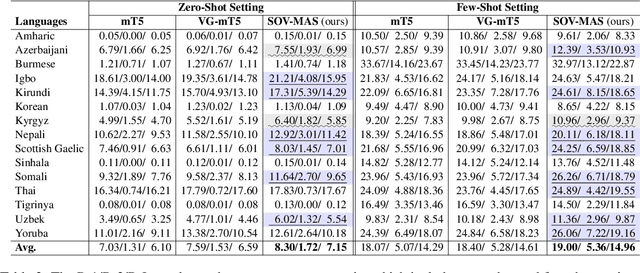
The goal of multimodal abstractive summarization (MAS) is to produce a concise summary given the multimodal data (text and vision). Existing studies on MAS mainly focus on how to effectively use the extracted visual features, having achieved impressive success on the high-resource English dataset. However, less attention has been paid to the quality of the visual features to the summary, which may limit the model performance especially in the low- and zero-resource scenarios. In this paper, we propose to improve the summary quality through summary-oriented visual features. To this end, we devise two auxiliary tasks including \emph{vision to summary task} and \emph{masked image modeling task}. Together with the main summarization task, we optimize the MAS model via the training objectives of all these tasks. By these means, the MAS model can be enhanced by capturing the summary-oriented visual features, thereby yielding more accurate summaries. Experiments on 44 languages, covering mid-high-, low-, and zero-resource scenarios, verify the effectiveness and superiority of the proposed approach, which achieves state-of-the-art performance under all scenarios.
Unsupervised Object Localization: Observing the Background to Discover Objects
Dec 15, 2022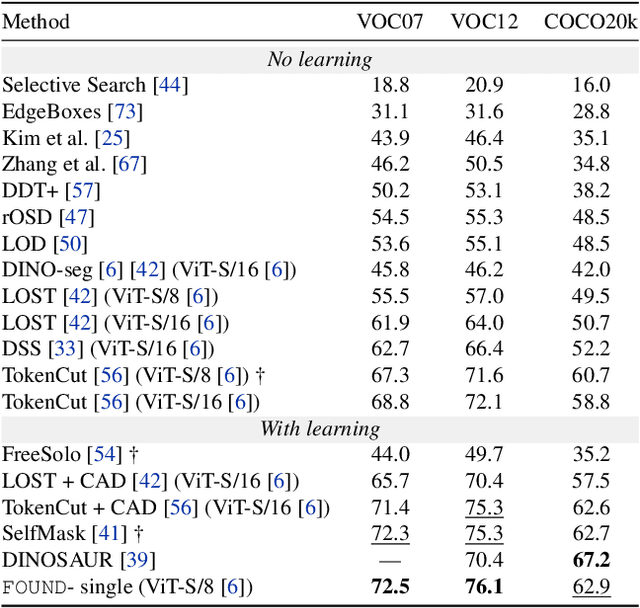
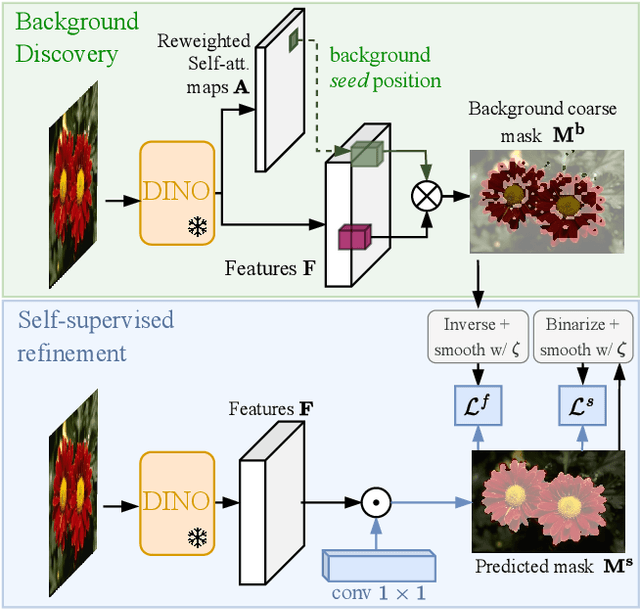
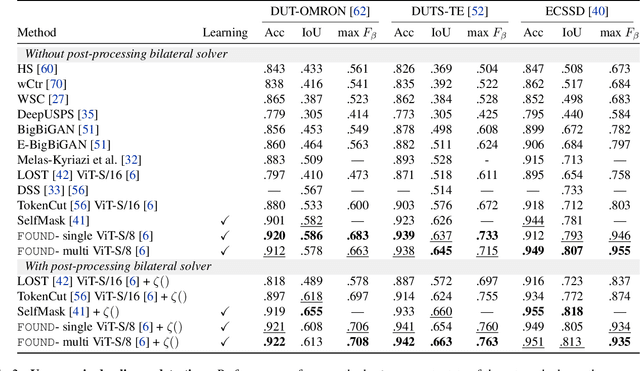

Recent advances in self-supervised visual representation learning have paved the way for unsupervised methods tackling tasks such as object discovery and instance segmentation. However, discovering objects in an image with no supervision is a very hard task; what are the desired objects, when to separate them into parts, how many are there, and of what classes? The answers to these questions depend on the tasks and datasets of evaluation. In this work, we take a different approach and propose to look for the background instead. This way, the salient objects emerge as a by-product without any strong assumption on what an object should be. We propose FOUND, a simple model made of a single $conv1\times1$ initialized with coarse background masks extracted from self-supervised patch-based representations. After fast training and refining these seed masks, the model reaches state-of-the-art results on unsupervised saliency detection and object discovery benchmarks. Moreover, we show that our approach yields good results in the unsupervised semantic segmentation retrieval task. The code to reproduce our results is available at https://github.com/valeoai/FOUND.
FlexiViT: One Model for All Patch Sizes
Dec 15, 2022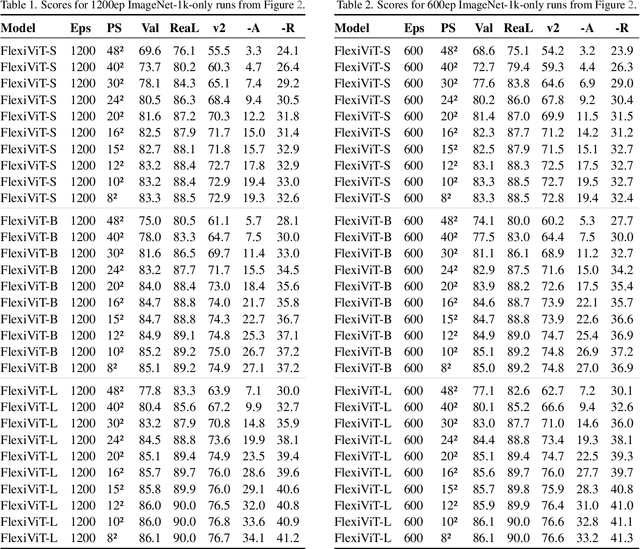
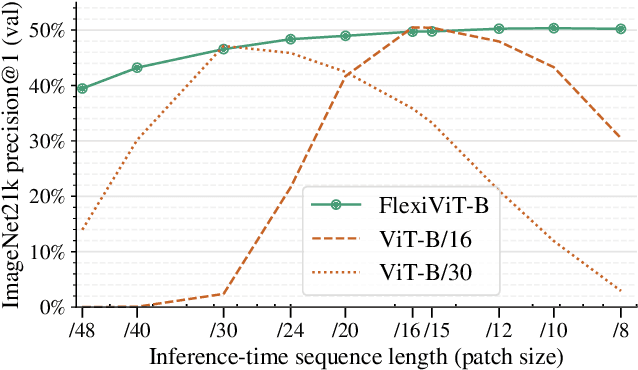
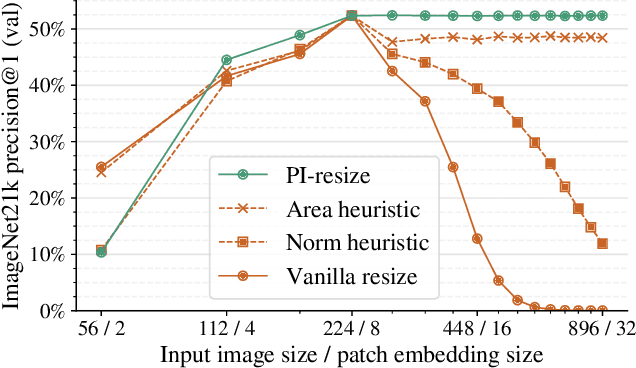
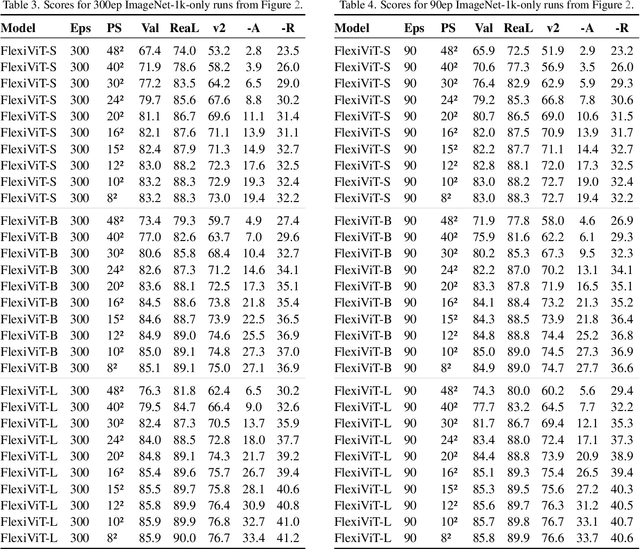
Vision Transformers convert images to sequences by slicing them into patches. The size of these patches controls a speed/accuracy tradeoff, with smaller patches leading to higher accuracy at greater computational cost, but changing the patch size typically requires retraining the model. In this paper, we demonstrate that simply randomizing the patch size at training time leads to a single set of weights that performs well across a wide range of patch sizes, making it possible to tailor the model to different compute budgets at deployment time. We extensively evaluate the resulting model, which we call FlexiViT, on a wide range of tasks, including classification, image-text retrieval, open-world detection, panoptic segmentation, and semantic segmentation, concluding that it usually matches, and sometimes outperforms, standard ViT models trained at a single patch size in an otherwise identical setup. Hence, FlexiViT training is a simple drop-in improvement for ViT that makes it easy to add compute-adaptive capabilities to most models relying on a ViT backbone architecture. Code and pre-trained models are available at https://github.com/google-research/big_vision
MetaPortrait: Identity-Preserving Talking Head Generation with Fast Personalized Adaptation
Dec 15, 2022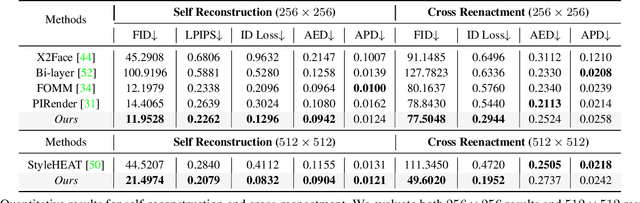
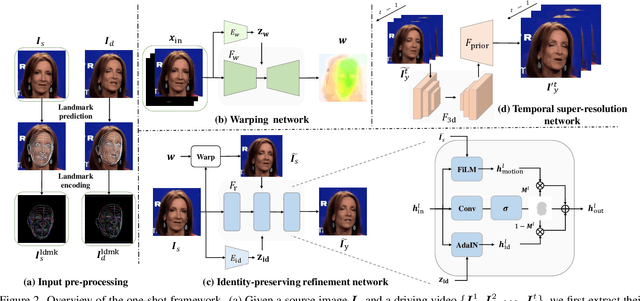
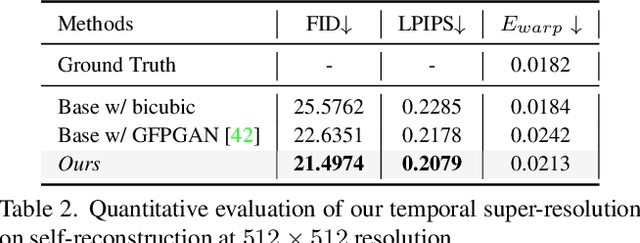
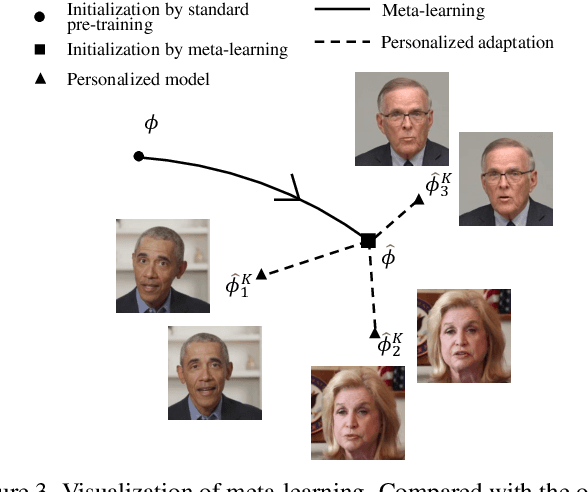
In this work, we propose an ID-preserving talking head generation framework, which advances previous methods in two aspects. First, as opposed to interpolating from sparse flow, we claim that dense landmarks are crucial to achieving accurate geometry-aware flow fields. Second, inspired by face-swapping methods, we adaptively fuse the source identity during synthesis, so that the network better preserves the key characteristics of the image portrait. Although the proposed model surpasses prior generation fidelity on established benchmarks, to further make the talking head generation qualified for real usage, personalized fine-tuning is usually needed. However, this process is rather computationally demanding that is unaffordable to standard users. To solve this, we propose a fast adaptation model using a meta-learning approach. The learned model can be adapted to a high-quality personalized model as fast as 30 seconds. Last but not the least, a spatial-temporal enhancement module is proposed to improve the fine details while ensuring temporal coherency. Extensive experiments prove the significant superiority of our approach over the state of the arts in both one-shot and personalized settings.
Examining the Difference Among Transformers and CNNs with Explanation Methods
Dec 15, 2022We propose a methodology that systematically applies deep explanation algorithms on a dataset-wide basis, to compare different types of visual recognition backbones, such as convolutional networks (CNNs), global attention networks, and local attention networks. Examination of both qualitative visualizations and quantitative statistics across the dataset helps us to gain intuitions that are not just anecdotal, but are supported by the statistics computed on the entire dataset. Specifically, we propose two methods. The first one, sub-explanation counting, systematically searches for minimally-sufficient explanations of all images and count the amount of sub-explanations for each network. The second one, called cross-testing, computes salient regions using one network and then evaluates the performance by only showing these regions as an image to other networks. Through a combination of qualitative insights and quantitative statistics, we illustrate that 1) there are significant differences between the salient features of CNNs and attention models; 2) the occlusion-robustness in local attention models and global attention models may come from different decision-making mechanisms.
Marginal Contrastive Correspondence for Guided Image Generation
Apr 01, 2022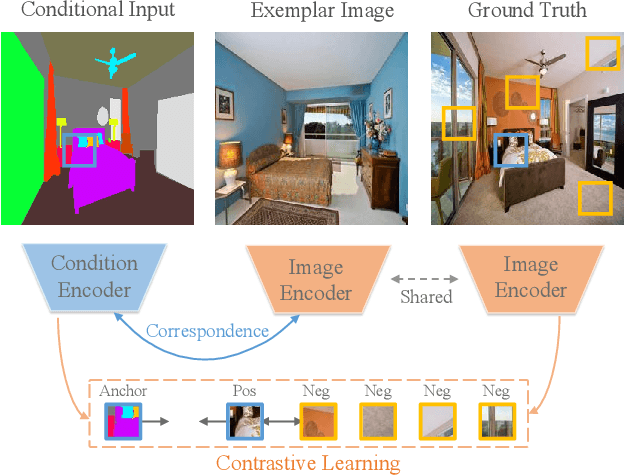
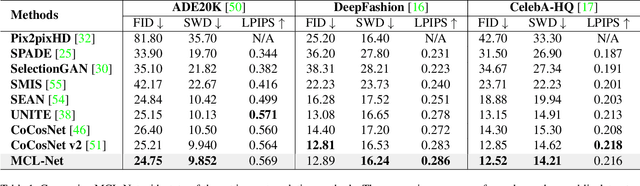
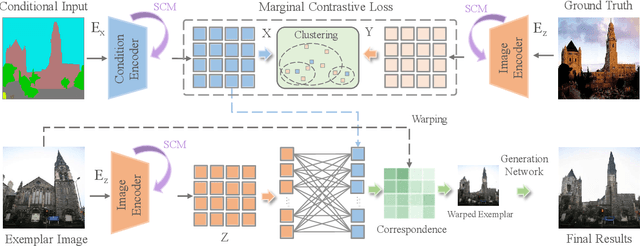
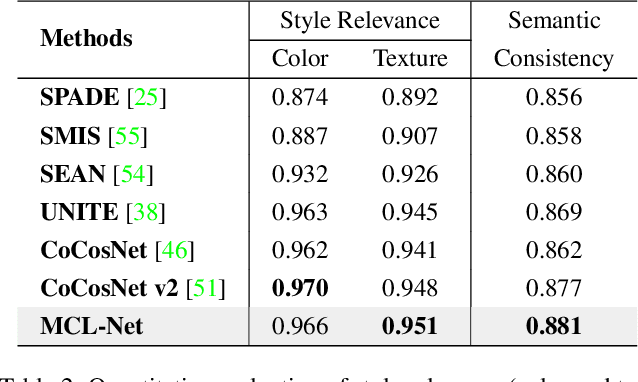
Exemplar-based image translation establishes dense correspondences between a conditional input and an exemplar (from two different domains) for leveraging detailed exemplar styles to achieve realistic image translation. Existing work builds the cross-domain correspondences implicitly by minimizing feature-wise distances across the two domains. Without explicit exploitation of domain-invariant features, this approach may not reduce the domain gap effectively which often leads to sub-optimal correspondences and image translation. We design a Marginal Contrastive Learning Network (MCL-Net) that explores contrastive learning to learn domain-invariant features for realistic exemplar-based image translation. Specifically, we design an innovative marginal contrastive loss that guides to establish dense correspondences explicitly. Nevertheless, building correspondence with domain-invariant semantics alone may impair the texture patterns and lead to degraded texture generation. We thus design a Self-Correlation Map (SCM) that incorporates scene structures as auxiliary information which improves the built correspondences substantially. Quantitative and qualitative experiments on multifarious image translation tasks show that the proposed method outperforms the state-of-the-art consistently.
Distortion-Corrected Image Reconstruction with Deep Learning on an MRI-Linac
May 23, 2022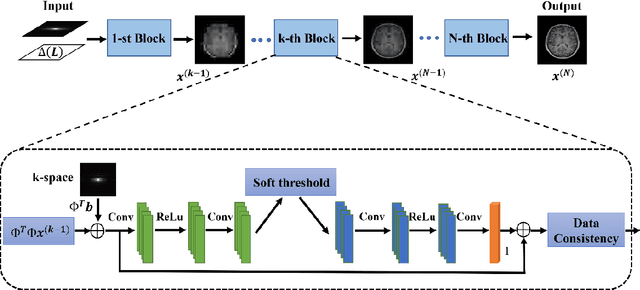

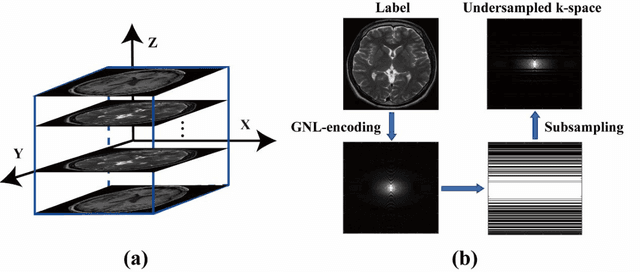
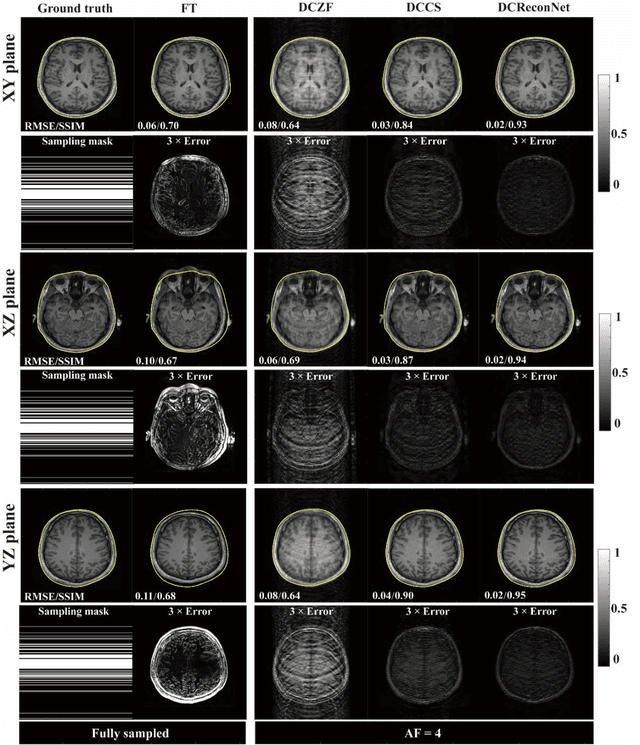
Magnetic resonance imaging (MRI) is increasingly utilized for image-guided radiotherapy due to its outstanding soft-tissue contrast and lack of ionizing radiation. However, geometric distortions caused by gradient nonlinearity (GNL) limit anatomical accuracy, potentially compromising the quality of tumour treatments. In addition, slow MR acquisition and reconstruction limit the potential for real-time image guidance. Here, we demonstrate a deep learning-based method that rapidly reconstructs distortion-corrected images from raw k-space data for real-time MR-guided radiotherapy applications. We leverage recent advances in interpretable unrolling networks to develop a Distortion-Corrected Reconstruction Network (DCReconNet) that applies convolutional neural networks (CNNs) to learn effective regularizations and nonuniform fast Fourier transforms for GNL-encoding. DCReconNet was trained on a public MR brain dataset from eleven healthy volunteers for fully sampled and accelerated techniques including parallel imaging (PI) and compressed sensing (CS). The performance of DCReconNet was tested on phantom and volunteer brain data acquired on a 1.0T MRI-Linac. The DCReconNet, CS- and PI-based reconstructed image quality was measured by structural similarity (SSIM) and root-mean-squared error (RMSE) for numerical comparisons. The computation time for each method was also reported. Phantom and volunteer results demonstrated that DCReconNet better preserves image structure when compared to CS- and PI-based reconstruction methods. DCReconNet resulted in highest SSIM (0.95 median value) and lowest RMSE (<0.04) on simulated brain images with four times acceleration. DCReconNet is over 100-times faster than iterative, regularized reconstruction methods. DCReconNet provides fast and geometrically accurate image reconstruction and has potential for real-time MRI-guided radiotherapy applications.