 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SynCLay: Interactive Synthesis of Histology Images from Bespoke Cellular Layouts
Dec 28, 2022
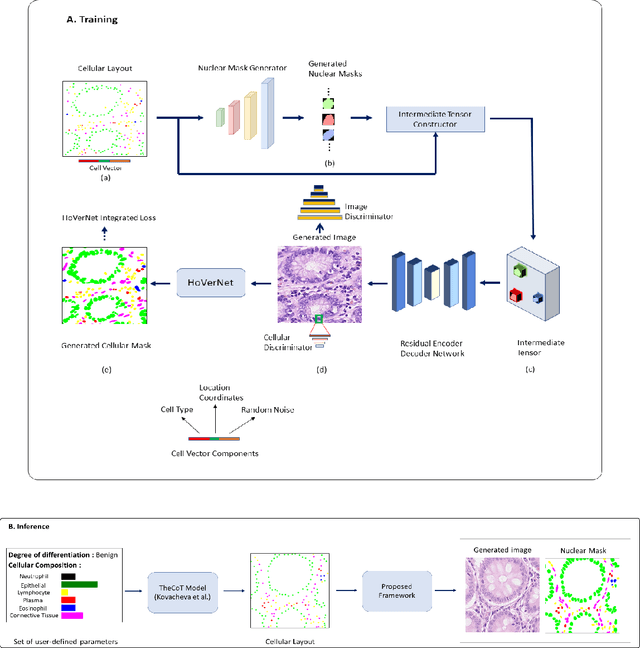
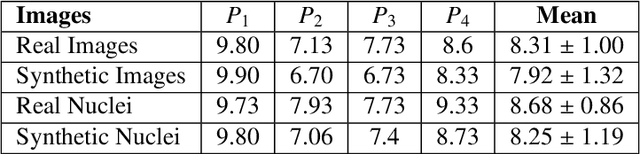
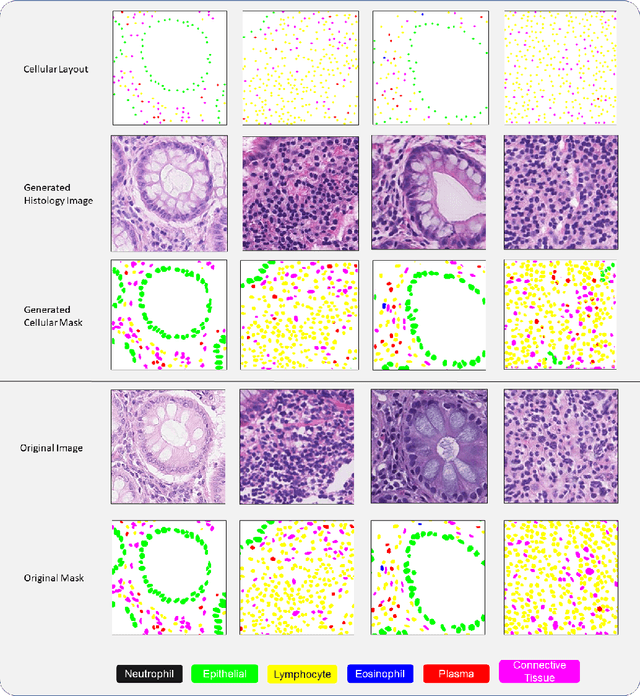
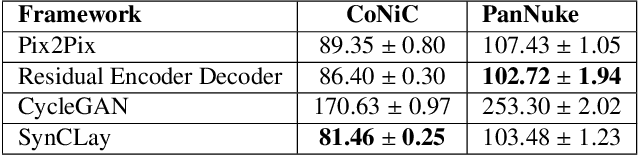
Automated synthesis of histology images has several potential applications in computational pathology. However, no existing method can generate realistic tissue images with a bespoke cellular layout or user-defined histology parameters. In this work, we propose a novel framework called SynCLay (Synthesis from Cellular Layouts) that can construct realistic and high-quality histology images from user-defined cellular layouts along with annotated cellular boundaries. Tissue image generation based on bespoke cellular layouts through the proposed framework allows users to generate different histological patterns from arbitrary topological arrangement of different types of cells. SynCLay generated synthetic images can be helpful in studying the role of different types of cells present in the tumor microenvironmet. Additionally, they can assist in balancing the distribution of cellular counts in tissue images for designing accurate cellular composition predictors by minimizing the effects of data imbalance. We train SynCLay in an adversarial manner and integrate a nuclear segmentation and classification model in its training to refine nuclear structures and generate nuclear masks in conjunction with synthetic images. During inference, we combine the model with another parametric model for generating colon images and associated cellular counts as annotations given the grade of differentiation and cell densities of different cells. We assess the generated images quantitatively and report on feedback from trained pathologists who assigned realism scores to a set of images generated by the framework. The average realism score across all pathologists for synthetic images was as high as that for the real images. We also show that augmenting limited real data with the synthetic data generated by our framework can significantly boost prediction performance of the cellular composition prediction task.
Lung-Net: A deep learning framework for lung tissue segmentation in three-dimensional thoracic CT images
Dec 28, 2022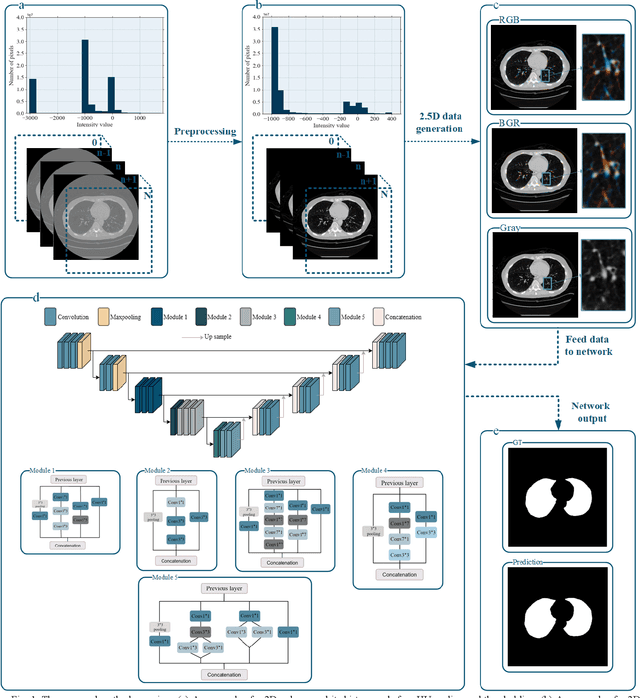
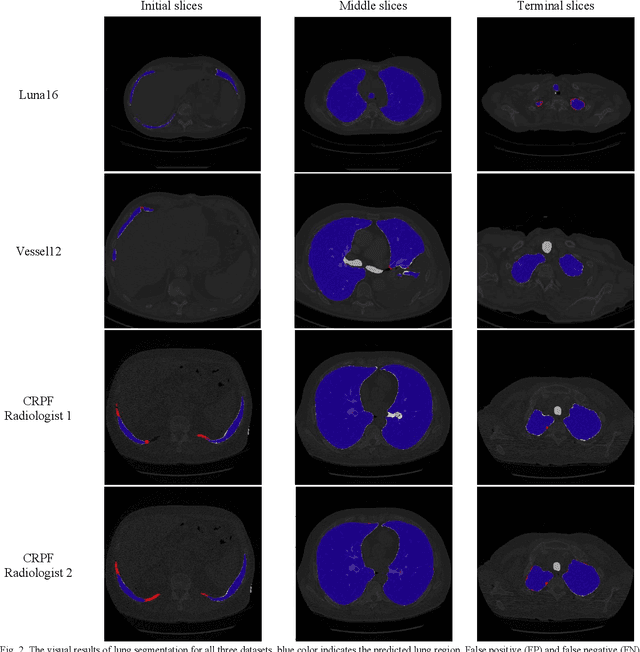
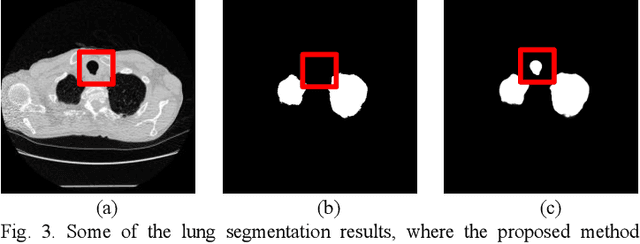
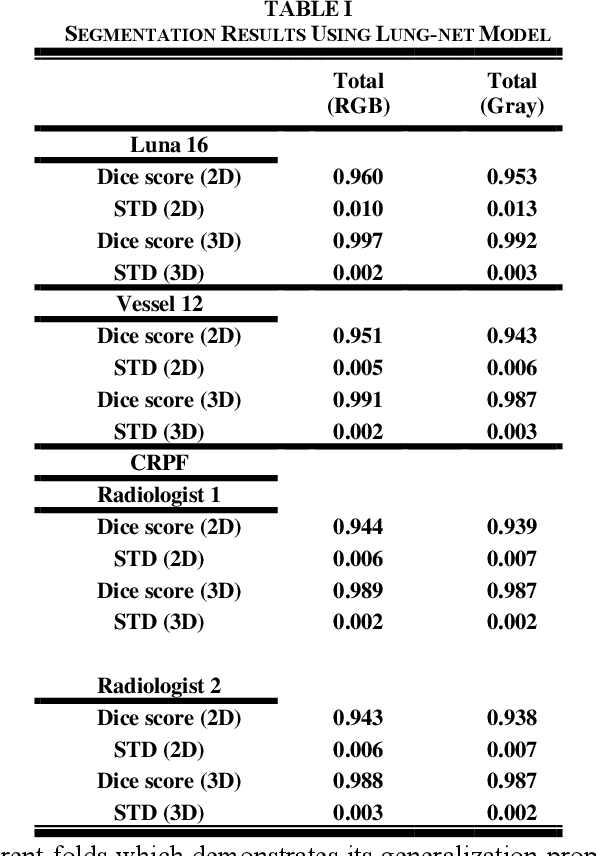
Segmentation of lung tissue in computed tomography (CT) images is a precursor to most pulmonary image analysis applications. Semantic segmentation methods using deep learning have exhibited top-tier performance in recent years. This paper presents a fully automatic method for identifying the lungs in three-dimensional (3D) pulmonary CT images, which we call it Lung-Net. We conjectured that a significant deeper network with inceptionV3 units can achieve a better feature representation of lung CT images without increasing the model complexity in terms of the number of trainable parameters. The method has three main advantages. First, a U-Net architecture with InceptionV3 blocks is developed to resolve the problem of performance degradation and parameter overload. Then, using information from consecutive slices, a new data structure is created to increase generalization potential, allowing more discriminating features to be extracted by making data representation as efficient as possible. Finally, the robustness of the proposed segmentation framework was quantitatively assessed using one public database to train and test the model (LUNA16) and two public databases (ISBI VESSEL12 challenge and CRPF dataset) only for testing the model; each database consists of 700, 23, and 40 CT images, respectively, that were acquired with a different scanner and protocol. Based on the experimental results, the proposed method achieved competitive results over the existing techniques with Dice coefficient of 99.7, 99.1, and 98.8 for LUNA16, VESSEL12, and CRPF datasets, respectively. For segmenting lung tissue in CT images, the proposed model is efficient in terms of time and parameters and outperforms other state-of-the-art methods. Additionally, this model is publicly accessible via a graphical user interface.
FlexIT: Towards Flexible Semantic Image Translation
Mar 09, 2022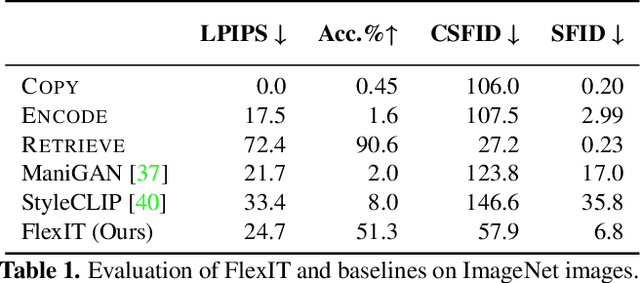
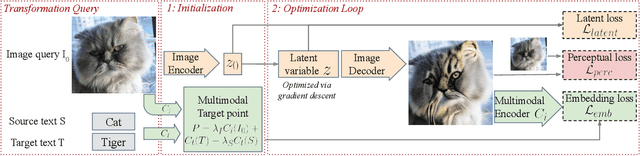

Deep generative models, like GANs, have considerably improved the state of the art in image synthesis, and are able to generate near photo-realistic images in structured domains such as human faces. Based on this success, recent work on image editing proceeds by projecting images to the GAN latent space and manipulating the latent vector. However, these approaches are limited in that only images from a narrow domain can be transformed, and with only a limited number of editing operations. We propose FlexIT, a novel method which can take any input image and a user-defined text instruction for editing. Our method achieves flexible and natural editing, pushing the limits of semantic image translation. First, FlexIT combines the input image and text into a single target point in the CLIP multimodal embedding space. Via the latent space of an auto-encoder, we iteratively transform the input image toward the target point, ensuring coherence and quality with a variety of novel regularization terms. We propose an evaluation protocol for semantic image translation, and thoroughly evaluate our method on ImageNet. Code will be made publicly available.
DQ-DETR: Dual Query Detection Transformer for Phrase Extraction and Grounding
Nov 30, 2022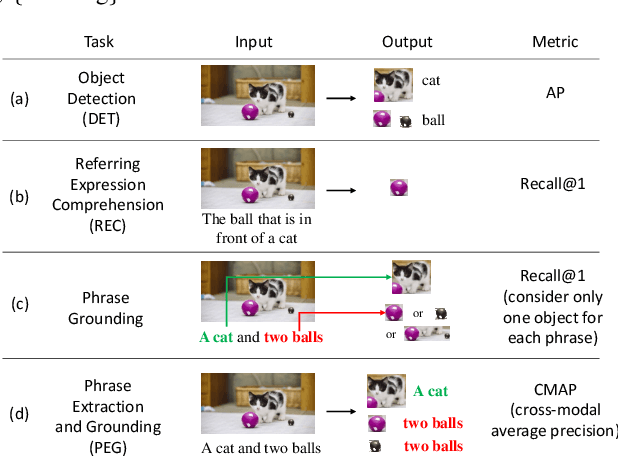

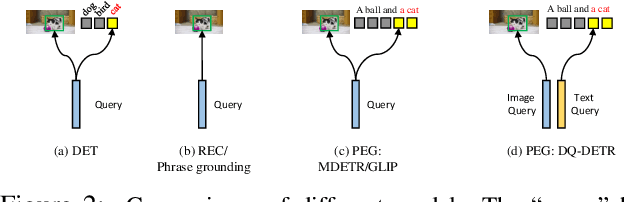
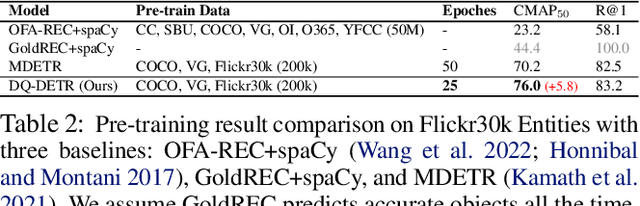
In this paper, we study the problem of visual grounding by considering both phrase extraction and grounding (PEG). In contrast to the previous phrase-known-at-test setting, PEG requires a model to extract phrases from text and locate objects from images simultaneously, which is a more practical setting in real applications. As phrase extraction can be regarded as a $1$D text segmentation problem, we formulate PEG as a dual detection problem and propose a novel DQ-DETR model, which introduces dual queries to probe different features from image and text for object prediction and phrase mask prediction. Each pair of dual queries is designed to have shared positional parts but different content parts. Such a design effectively alleviates the difficulty of modality alignment between image and text (in contrast to a single query design) and empowers Transformer decoder to leverage phrase mask-guided attention to improve performance. To evaluate the performance of PEG, we also propose a new metric CMAP (cross-modal average precision), analogous to the AP metric in object detection. The new metric overcomes the ambiguity of Recall@1 in many-box-to-one-phrase cases in phrase grounding. As a result, our PEG pre-trained DQ-DETR establishes new state-of-the-art results on all visual grounding benchmarks with a ResNet-101 backbone. For example, it achieves $91.04\%$ and $83.51\%$ in terms of recall rate on RefCOCO testA and testB with a ResNet-101 backbone. Code will be availabl at \url{https://github.com/IDEA-Research/DQ-DETR}.
Learning Knowledge Representation with Meta Knowledge Distillation for Single Image Super-Resolution
Jul 18, 2022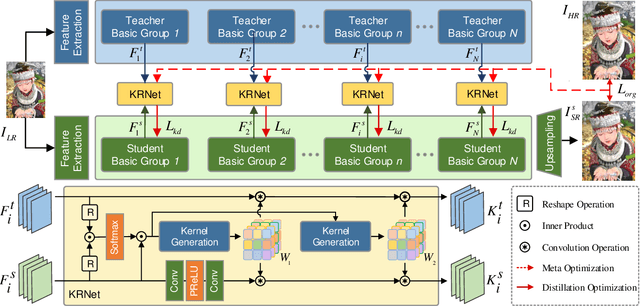
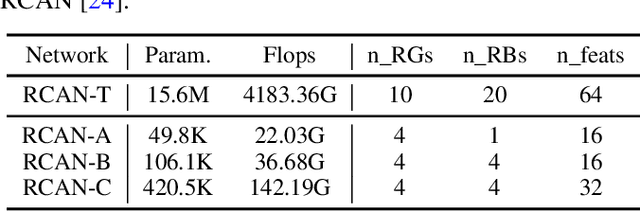
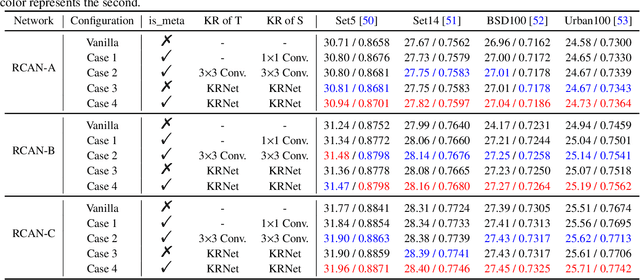
Knowledge distillation (KD), which can efficiently transfer knowledge from a cumbersome network (teacher) to a compact network (student), has demonstrated its advantages in some computer vision applications. The representation of knowledge is vital for knowledge transferring and student learning, which is generally defined in hand-crafted manners or uses the intermediate features directly. In this paper, we propose a model-agnostic meta knowledge distillation method under the teacher-student architecture for the single image super-resolution task. It provides a more flexible and accurate way to help the teachers transmit knowledge in accordance with the abilities of students via knowledge representation networks (KRNets) with learnable parameters. In order to improve the perception ability of knowledge representation to students' requirements, we propose to solve the transformation process from intermediate outputs to transferred knowledge by employing the student features and the correlation between teacher and student in the KRNets. Specifically, the texture-aware dynamic kernels are generated and then extract texture features to be improved and the corresponding teacher guidance so as to decompose the distillation problem into texture-wise supervision for further promoting the recovery quality of high-frequency details. In addition, the KRNets are optimized in a meta-learning manner to ensure the knowledge transferring and the student learning are beneficial to improving the reconstructed quality of the student. Experiments conducted on various single image super-resolution datasets demonstrate that our proposed method outperforms existing defined knowledge representation related distillation methods, and can help super-resolution algorithms achieve better reconstruction quality without introducing any inference complexity.
Hoyer regularizer is all you need for ultra low-latency spiking neural networks
Dec 20, 2022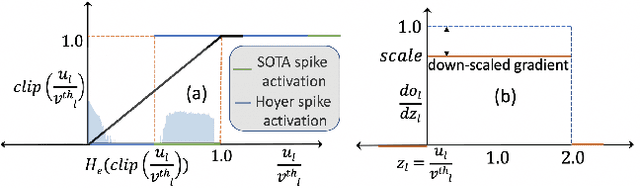
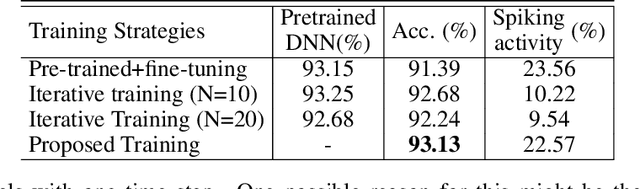
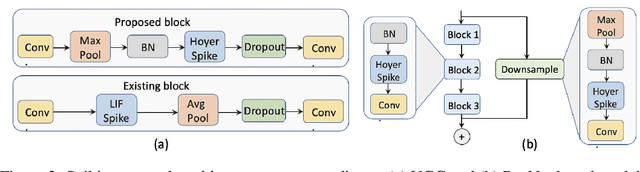
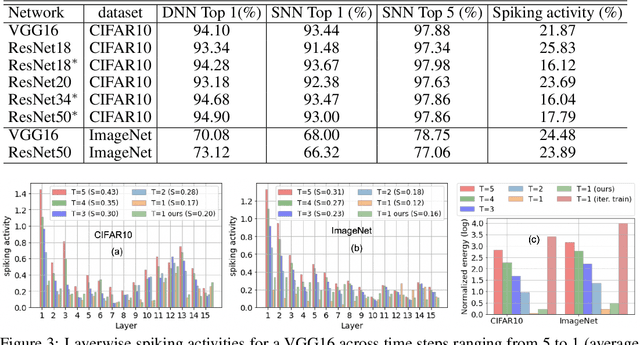
Spiking Neural networks (SNN) have emerged as an attractive spatio-temporal computing paradigm for a wide range of low-power vision tasks. However, state-of-the-art (SOTA) SNN models either incur multiple time steps which hinder their deployment in real-time use cases or increase the training complexity significantly. To mitigate this concern, we present a training framework (from scratch) for one-time-step SNNs that uses a novel variant of the recently proposed Hoyer regularizer. We estimate the threshold of each SNN layer as the Hoyer extremum of a clipped version of its activation map, where the clipping threshold is trained using gradient descent with our Hoyer regularizer. This approach not only downscales the value of the trainable threshold, thereby emitting a large number of spikes for weight update with a limited number of iterations (due to only one time step) but also shifts the membrane potential values away from the threshold, thereby mitigating the effect of noise that can degrade the SNN accuracy. Our approach outperforms existing spiking, binary, and adder neural networks in terms of the accuracy-FLOPs trade-off for complex image recognition tasks. Downstream experiments on object detection also demonstrate the efficacy of our approach.
Do language models have coherent mental models of everyday things?
Dec 20, 2022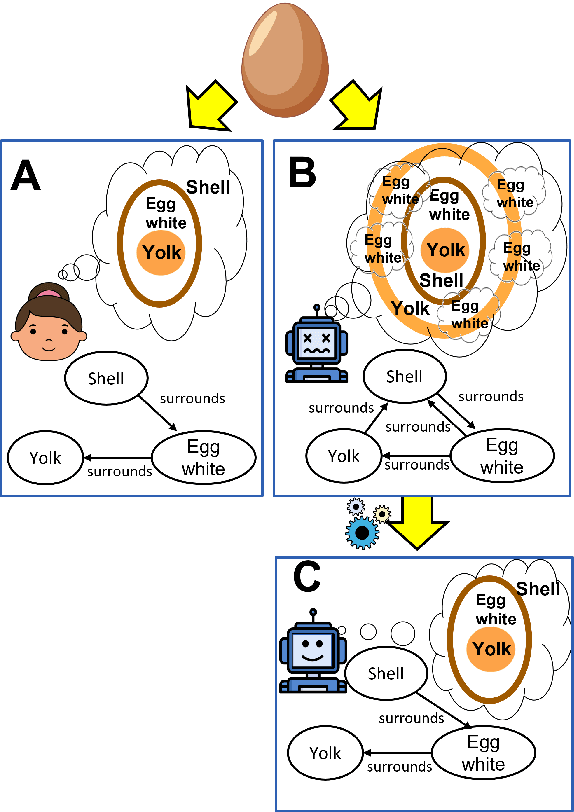
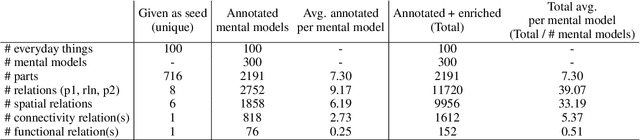
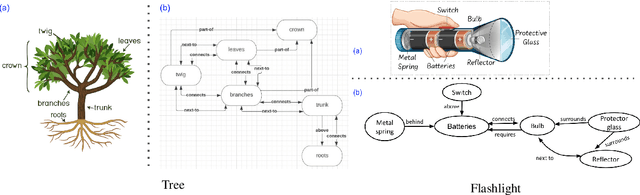

When people think of everyday things like an "egg," they typically have a mental image associated with it. This commonsense knowledge helps us understand how these everyday things work and how to interact with them. For example, when someone tries to make a fried egg, they know that it has a shell and that it can be cracked open to reveal the egg white and yolk inside. However, if a system does not have a coherent picture of such everyday things, thinking that the egg yolk surrounds the shell, then it might have to resort to ridiculous approaches such as trying to scrape the egg yolk off the shell into the pan. Do language models have a coherent picture of such everyday things? To investigate this, we propose a benchmark dataset consisting of 100 everyday things, their parts, and the relationships between these parts. We observe that state-of-the-art pre-trained language models (LMs) like GPT-3 and Macaw have fragments of knowledge about these entities, but they fail to produce consistent parts mental models. We propose a simple extension to these LMs where we apply a constraint satisfaction layer on top of raw predictions from LMs to produce more consistent and accurate parts mental models of everyday things.
Towards Unsupervised Visual Reasoning: Do Off-The-Shelf Features Know How to Reason?
Dec 20, 2022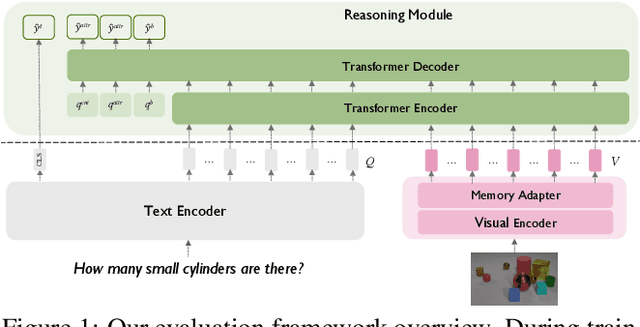
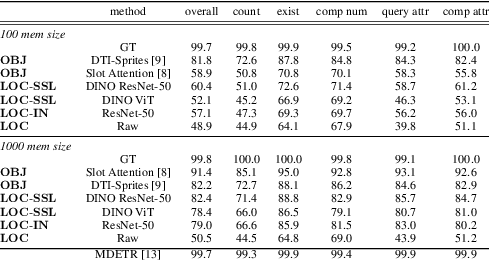
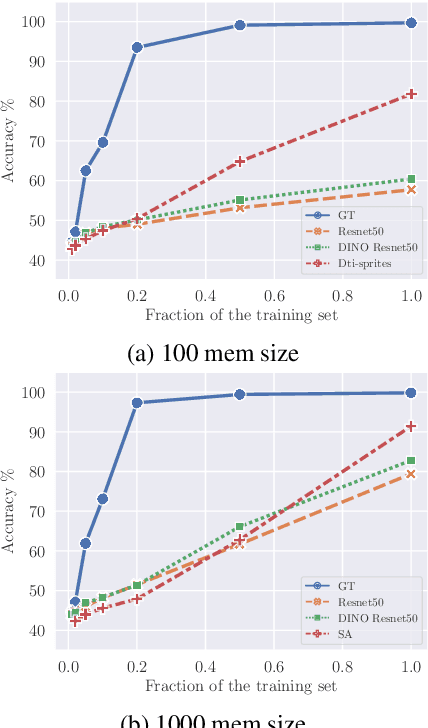

Recent advances in visual representation learning allowed to build an abundance of powerful off-the-shelf features that are ready-to-use for numerous downstream tasks. This work aims to assess how well these features preserve information about the objects, such as their spatial location, their visual properties and their relative relationships. We propose to do so by evaluating them in the context of visual reasoning, where multiple objects with complex relationships and different attributes are at play. More specifically, we introduce a protocol to evaluate visual representations for the task of Visual Question Answering. In order to decouple visual feature extraction from reasoning, we design a specific attention-based reasoning module which is trained on the frozen visual representations to be evaluated, in a spirit similar to standard feature evaluations relying on shallow networks. We compare two types of visual representations, densely extracted local features and object-centric ones, against the performances of a perfect image representation using ground truth. Our main findings are two-fold. First, despite excellent performances on classical proxy tasks, such representations fall short for solving complex reasoning problem. Second, object-centric features better preserve the critical information necessary to perform visual reasoning. In our proposed framework we show how to methodologically approach this evaluation.
Perceptual Learned Source-Channel Coding for High-Fidelity Image Semantic Transmission
May 26, 2022
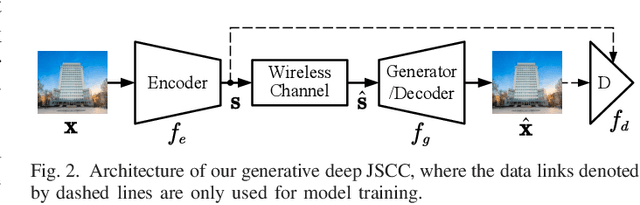
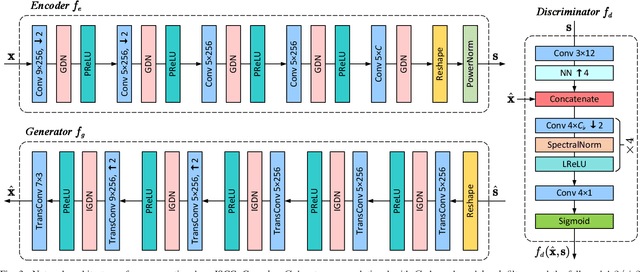
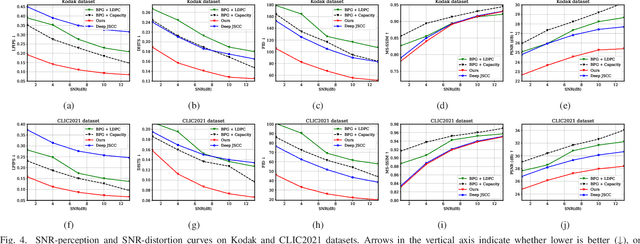
As one novel approach to realize end-to-end wireless image semantic transmission, deep learning-based joint source-channel coding (deep JSCC) method is emerging in both deep learning and communication communities. However, current deep JSCC image transmission systems are typically optimized for traditional distortion metrics such as peak signal-to-noise ratio (PSNR) or multi-scale structural similarity (MS-SSIM). But for low transmission rates, due to the imperfect wireless channel, these distortion metrics lose significance as they favor pixel-wise preservation. To account for human visual perception in semantic communications, it is of great importance to develop new deep JSCC systems optimized beyond traditional PSNR and MS-SSIM metrics. In this paper, we introduce adversarial losses to optimize deep JSCC, which tends to preserve global semantic information and local texture. Our new deep JSCC architecture combines encoder, wireless channel, decoder/generator, and discriminator, which are jointly learned under both perceptual and adversarial losses. Our method yields human visually much more pleasing results than state-of-the-art engineered image coded transmission systems and traditional deep JSCC systems. A user study confirms that achieving the perceptually similar end-to-end image transmission quality, the proposed method can save about 50\% wireless channel bandwidth cost.
Summary-Oriented Vision Modeling for Multimodal Abstractive Summarization
Dec 15, 2022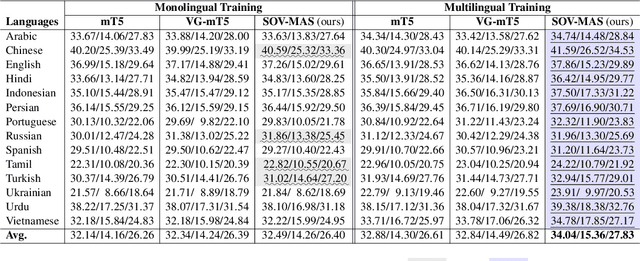
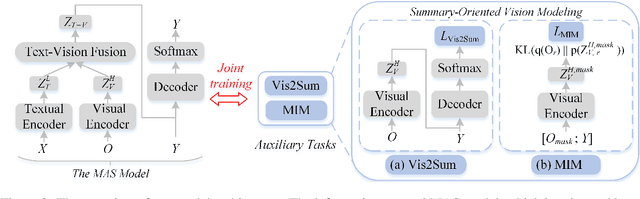
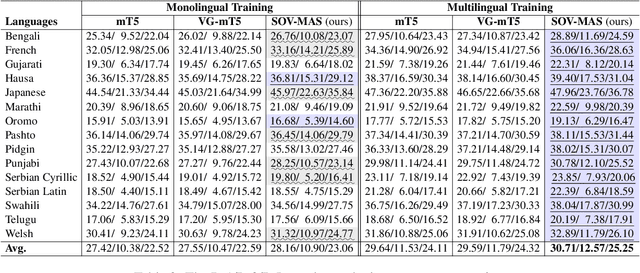
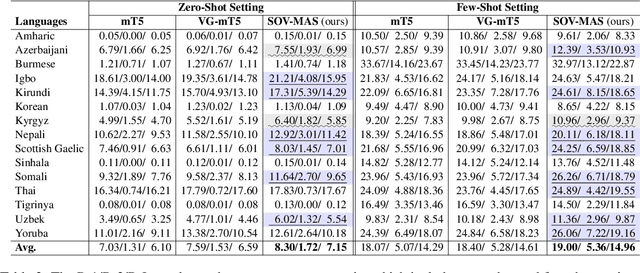
The goal of multimodal abstractive summarization (MAS) is to produce a concise summary given the multimodal data (text and vision). Existing studies on MAS mainly focus on how to effectively use the extracted visual features, having achieved impressive success on the high-resource English dataset. However, less attention has been paid to the quality of the visual features to the summary, which may limit the model performance especially in the low- and zero-resource scenarios. In this paper, we propose to improve the summary quality through summary-oriented visual features. To this end, we devise two auxiliary tasks including \emph{vision to summary task} and \emph{masked image modeling task}. Together with the main summarization task, we optimize the MAS model via the training objectives of all these tasks. By these means, the MAS model can be enhanced by capturing the summary-oriented visual features, thereby yielding more accurate summaries. Experiments on 44 languages, covering mid-high-, low-, and zero-resource scenarios, verify the effectiveness and superiority of the proposed approach, which achieves state-of-the-art performance under all scenarios.