 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Image Processing Pipeline for Camera Trap Time-Lapse Recordings
Jun 10, 2022
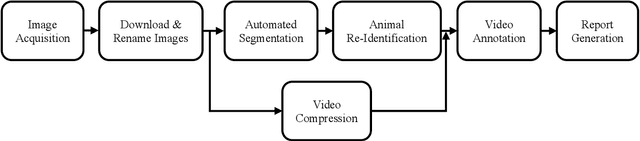
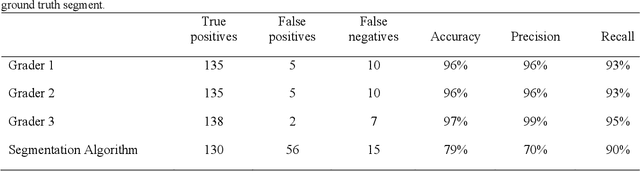

A new open-source image processing pipeline for analyzing camera trap time-lapse recordings is described. This pipeline includes machine learning models to assist human-in-the-loop video segmentation and animal re-identification. We present some performance results and observations on the utility of this pipeline after using it in a year-long project studying the spatial ecology and social behavior of the gopher tortoise.
Relightable Neural Human Assets from Multi-view Gradient Illuminations
Dec 15, 2022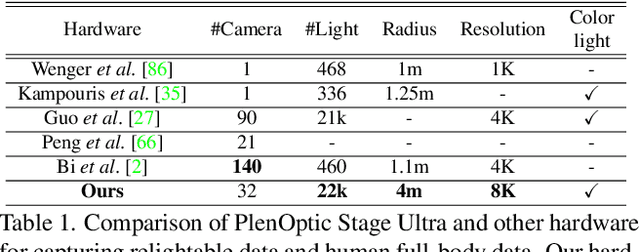

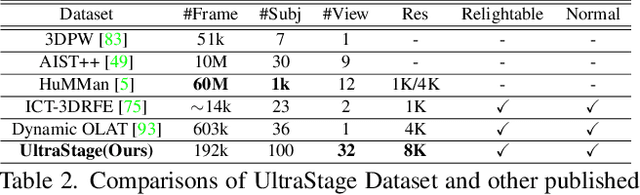
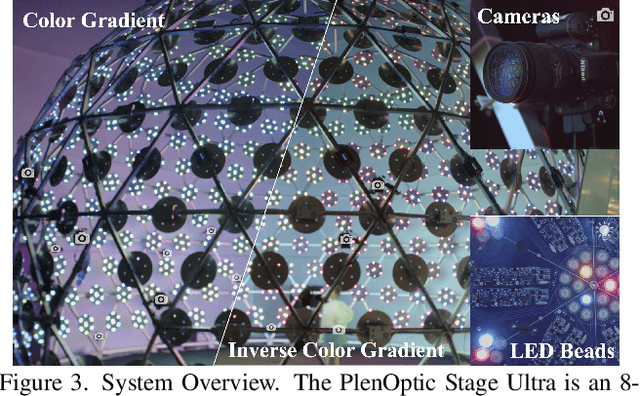
Human modeling and relighting are two fundamental problems in computer vision and graphics, where high-quality datasets can largely facilitate related research. However, most existing human datasets only provide multi-view human images captured under the same illumination. Although valuable for modeling tasks, they are not readily used in relighting problems. To promote research in both fields, in this paper, we present UltraStage, a new 3D human dataset that contains more than 2K high-quality human assets captured under both multi-view and multi-illumination settings. Specifically, for each example, we provide 32 surrounding views illuminated with one white light and two gradient illuminations. In addition to regular multi-view images, gradient illuminations help recover detailed surface normal and spatially-varying material maps, enabling various relighting applications. Inspired by recent advances in neural representation, we further interpret each example into a neural human asset which allows novel view synthesis under arbitrary lighting conditions. We show our neural human assets can achieve extremely high capture performance and are capable of representing fine details such as facial wrinkles and cloth folds. We also validate UltraStage in single image relighting tasks, training neural networks with virtual relighted data from neural assets and demonstrating realistic rendering improvements over prior arts. UltraStage will be publicly available to the community to stimulate significant future developments in various human modeling and rendering tasks.
Solve the Puzzle of Instance Segmentation in Videos: A Weakly Supervised Framework with Spatio-Temporal Collaboration
Dec 15, 2022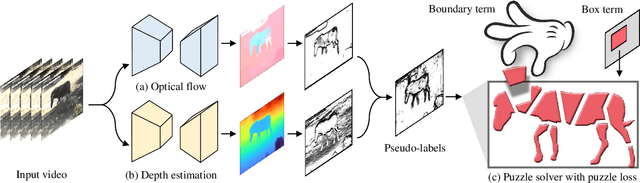
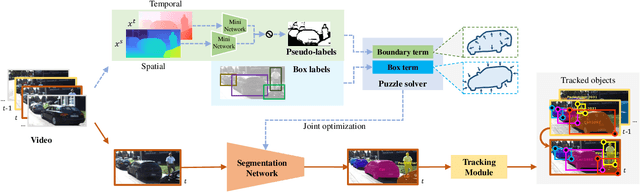
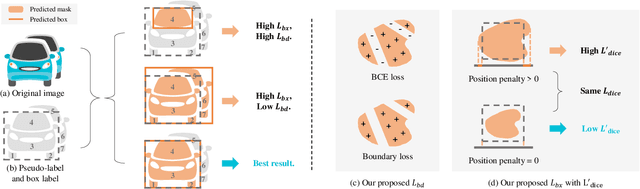
Instance segmentation in videos, which aims to segment and track multiple objects in video frames, has garnered a flurry of research attention in recent years. In this paper, we present a novel weakly supervised framework with \textbf{S}patio-\textbf{T}emporal \textbf{C}ollaboration for instance \textbf{Seg}mentation in videos, namely \textbf{STC-Seg}. Concretely, STC-Seg demonstrates four contributions. First, we leverage the complementary representations from unsupervised depth estimation and optical flow to produce effective pseudo-labels for training deep networks and predicting high-quality instance masks. Second, to enhance the mask generation, we devise a puzzle loss, which enables end-to-end training using box-level annotations. Third, our tracking module jointly utilizes bounding-box diagonal points with spatio-temporal discrepancy to model movements, which largely improves the robustness to different object appearances. Finally, our framework is flexible and enables image-level instance segmentation methods to operate the video-level task. We conduct an extensive set of experiments on the KITTI MOTS and YT-VIS datasets. Experimental results demonstrate that our method achieves strong performance and even outperforms fully supervised TrackR-CNN and MaskTrack R-CNN. We believe that STC-Seg can be a valuable addition to the community, as it reflects the tip of an iceberg about the innovative opportunities in the weakly supervised paradigm for instance segmentation in videos.
Decomposing a Recurrent Neural Network into Modules for Enabling Reusability and Replacement
Dec 15, 2022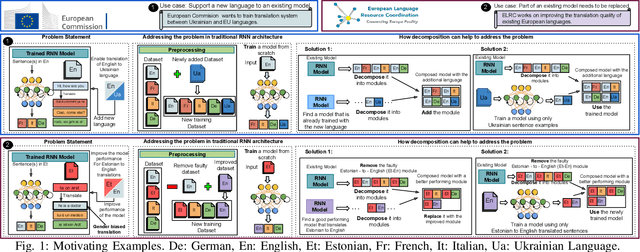
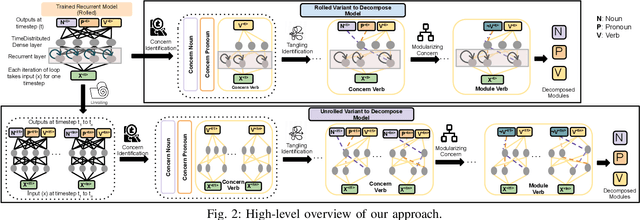

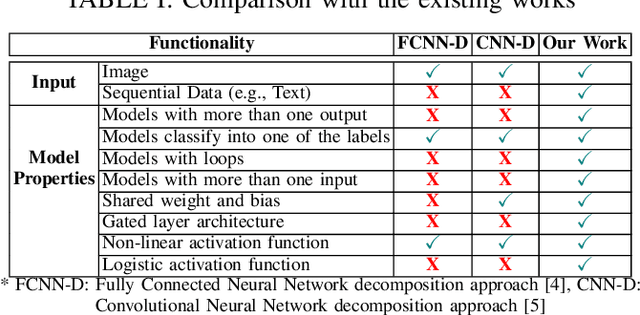
Can we take a recurrent neural network (RNN) trained to translate between languages and augment it to support a new natural language without retraining the model from scratch? Can we fix the faulty behavior of the RNN by replacing portions associated with the faulty behavior? Recent works on decomposing a fully connected neural network (FCNN) and convolutional neural network (CNN) into modules have shown the value of engineering deep models in this manner, which is standard in traditional SE but foreign for deep learning models. However, prior works focus on the image-based multiclass classification problems and cannot be applied to RNN due to (a) different layer structures, (b) loop structures, (c) different types of input-output architectures, and (d) usage of both nonlinear and logistic activation functions. In this work, we propose the first approach to decompose an RNN into modules. We study different types of RNNs, i.e., Vanilla, LSTM, and GRU. Further, we show how such RNN modules can be reused and replaced in various scenarios. We evaluate our approach against 5 canonical datasets (i.e., Math QA, Brown Corpus, Wiki-toxicity, Clinc OOS, and Tatoeba) and 4 model variants for each dataset. We found that decomposing a trained model has a small cost (Accuracy: -0.6%, BLEU score: +0.10%). Also, the decomposed modules can be reused and replaced without needing to retrain.
In Defense of Image Pre-Training for Spatiotemporal Recognition
May 03, 2022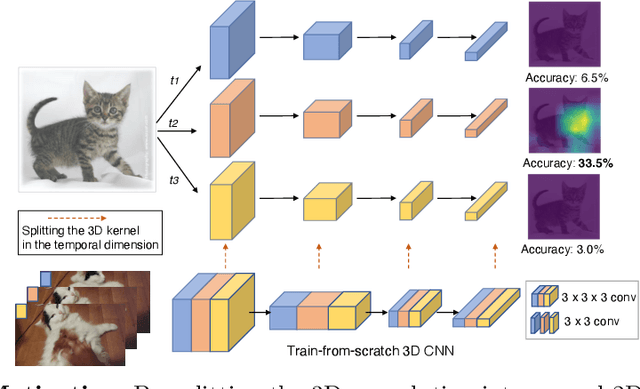
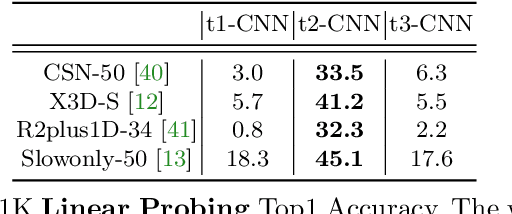
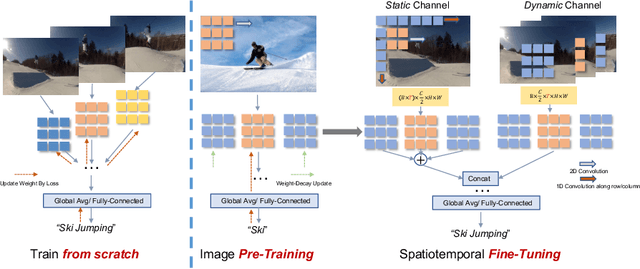

Image pre-training, the current de-facto paradigm for a wide range of visual tasks, is generally less favored in the field of video recognition. By contrast, a common strategy is to directly train with spatiotemporal convolutional neural networks (CNNs) from scratch. Nonetheless, interestingly, by taking a closer look at these from-scratch learned CNNs, we note there exist certain 3D kernels that exhibit much stronger appearance modeling ability than others, arguably suggesting appearance information is already well disentangled in learning. Inspired by this observation, we hypothesize that the key to effectively leveraging image pre-training lies in the decomposition of learning spatial and temporal features, and revisiting image pre-training as the appearance prior to initializing 3D kernels. In addition, we propose Spatial-Temporal Separable (STS) convolution, which explicitly splits the feature channels into spatial and temporal groups, to further enable a more thorough decomposition of spatiotemporal features for fine-tuning 3D CNNs. Our experiments show that simply replacing 3D convolution with STS notably improves a wide range of 3D CNNs without increasing parameters and computation on both Kinetics-400 and Something-Something V2. Moreover, this new training pipeline consistently achieves better results on video recognition with significant speedup. For instance, we achieve +0.6% top-1 of Slowfast on Kinetics-400 over the strong 256-epoch 128-GPU baseline while fine-tuning for only 50 epochs with 4 GPUs. The code and models are available at https://github.com/UCSC-VLAA/Image-Pretraining-for-Video.
Denoising-based image reconstruction from pixels located at non-integer positions
May 23, 2022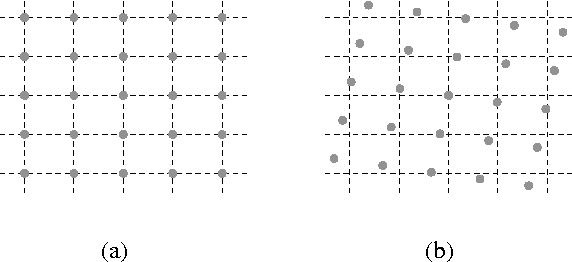

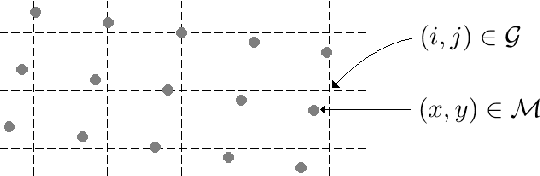
Digital images are commonly represented as regular 2D arrays, so pixels are organized in form of a matrix addressed by integers. However, there are many image processing operations, such as rotation or motion compensation, that produce pixels at non-integer positions. Typically, image reconstruction techniques cannot handle samples at non-integer positions. In this paper, we propose to use triangulation-based reconstruction as initial estimate that is later refined by a novel adaptive denoising framework. Simulations reveal that improvements of up to more than 1.8 dB (in terms of PSNR) are achieved with respect to the initial estimate.
* arXiv admin note: text overlap with arXiv:2205.10138
Transformer Compressed Sensing via Global Image Tokens
Mar 27, 2022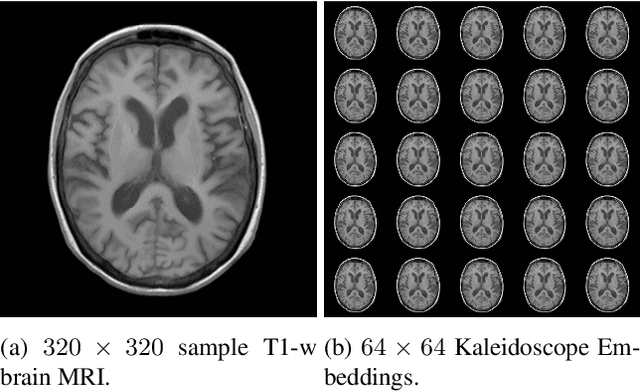

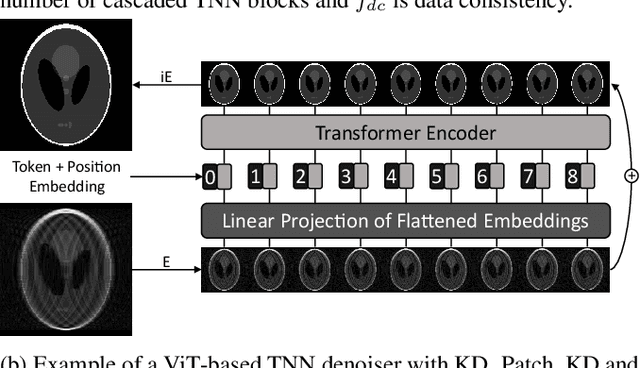
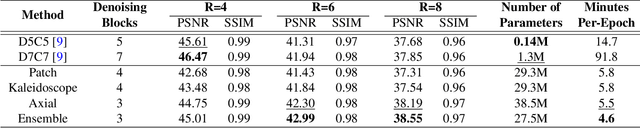
Convolutional neural networks (CNN) have demonstrated outstanding Compressed Sensing (CS) performance compared to traditional, hand-crafted methods. However, they are broadly limited in terms of generalisability, inductive bias and difficulty to model long distance relationships. Transformer neural networks (TNN) overcome such issues by implementing an attention mechanism designed to capture dependencies between inputs. However, high-resolution tasks typically require vision Transformers (ViT) to decompose an image into patch-based tokens, limiting inputs to inherently local contexts. We propose a novel image decomposition that naturally embeds images into low-resolution inputs. These Kaleidoscope tokens (KD) provide a mechanism for global attention, at the same computational cost as a patch-based approach. To showcase this development, we replace CNN components in a well-known CS-MRI neural network with TNN blocks and demonstrate the improvements afforded by KD. We also propose an ensemble of image tokens, which enhance overall image quality and reduces model size. Supplementary material is available: https://github.com/uqmarlonbran/TCS.git
Towards Transparency in Dermatology Image Datasets with Skin Tone Annotations by Experts, Crowds, and an Algorithm
Jul 06, 2022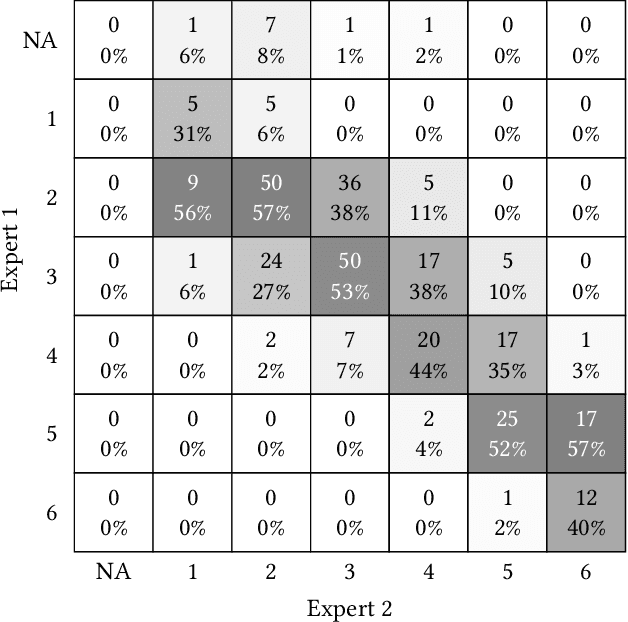
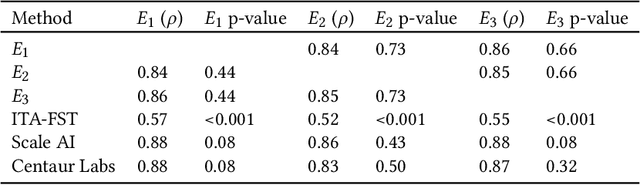
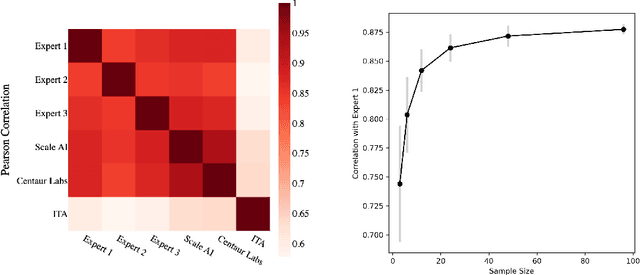
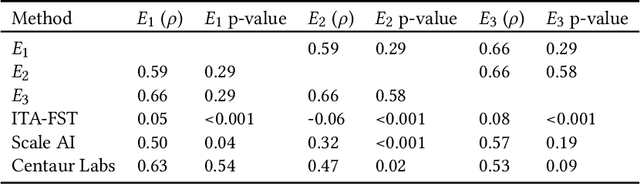
While artificial intelligence (AI) holds promise for supporting healthcare providers and improving the accuracy of medical diagnoses, a lack of transparency in the composition of datasets exposes AI models to the possibility of unintentional and avoidable mistakes. In particular, public and private image datasets of dermatological conditions rarely include information on skin color. As a start towards increasing transparency, AI researchers have appropriated the use of the Fitzpatrick skin type (FST) from a measure of patient photosensitivity to a measure for estimating skin tone in algorithmic audits of computer vision applications including facial recognition and dermatology diagnosis. In order to understand the variability of estimated FST annotations on images, we compare several FST annotation methods on a diverse set of 460 images of skin conditions from both textbooks and online dermatology atlases. We find the inter-rater reliability between three board-certified dermatologists is comparable to the inter-rater reliability between the board-certified dermatologists and two crowdsourcing methods. In contrast, we find that the Individual Typology Angle converted to FST (ITA-FST) method produces annotations that are significantly less correlated with the experts' annotations than the experts' annotations are correlated with each other. These results demonstrate that algorithms based on ITA-FST are not reliable for annotating large-scale image datasets, but human-centered, crowd-based protocols can reliably add skin type transparency to dermatology datasets. Furthermore, we introduce the concept of dynamic consensus protocols with tunable parameters including expert review that increase the visibility of crowdwork and provide guidance for future crowdsourced annotations of large image datasets.
Fully and Weakly Supervised Referring Expression Segmentation with End-to-End Learning
Dec 17, 2022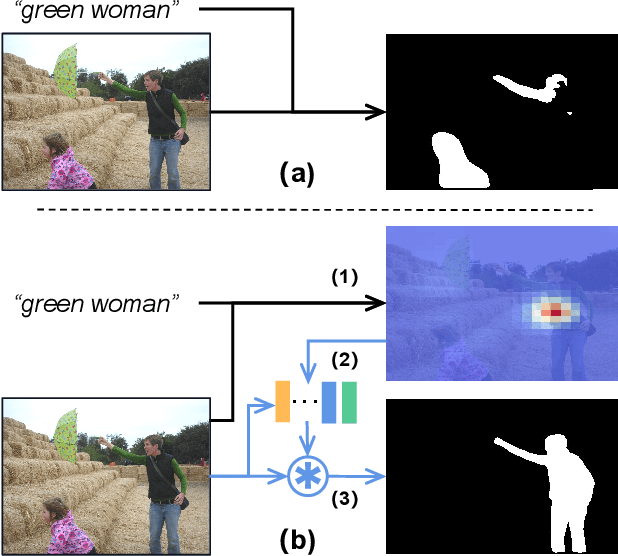

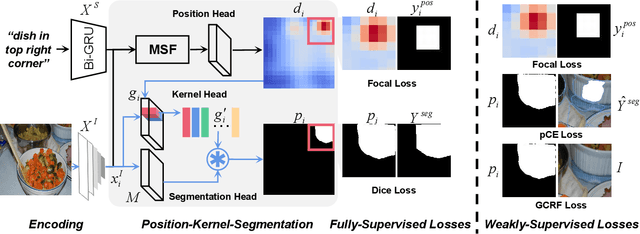
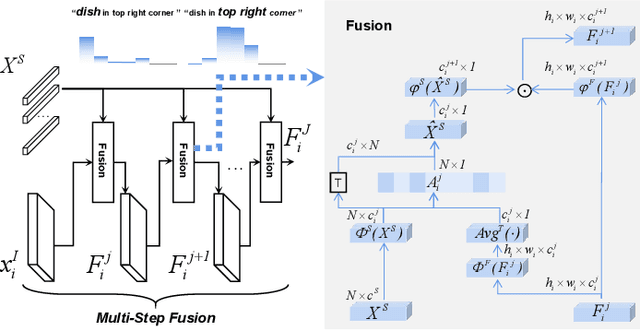
Referring Expression Segmentation (RES), which is aimed at localizing and segmenting the target according to the given language expression, has drawn increasing attention. Existing methods jointly consider the localization and segmentation steps, which rely on the fused visual and linguistic features for both steps. We argue that the conflict between the purpose of identifying an object and generating a mask limits the RES performance. To solve this problem, we propose a parallel position-kernel-segmentation pipeline to better isolate and then interact the localization and segmentation steps. In our pipeline, linguistic information will not directly contaminate the visual feature for segmentation. Specifically, the localization step localizes the target object in the image based on the referring expression, and then the visual kernel obtained from the localization step guides the segmentation step. This pipeline also enables us to train RES in a weakly-supervised way, where the pixel-level segmentation labels are replaced by click annotations on center and corner points. The position head is fully-supervised and trained with the click annotations as supervision, and the segmentation head is trained with weakly-supervised segmentation losses. To validate our framework on a weakly-supervised setting, we annotated three RES benchmark datasets (RefCOCO, RefCOCO+ and RefCOCOg) with click annotations.Our method is simple but surprisingly effective, outperforming all previous state-of-the-art RES methods on fully- and weakly-supervised settings by a large margin. The benchmark code and datasets will be released.
Pattern Attention Transformer with Doughnut Kernel
Nov 30, 2022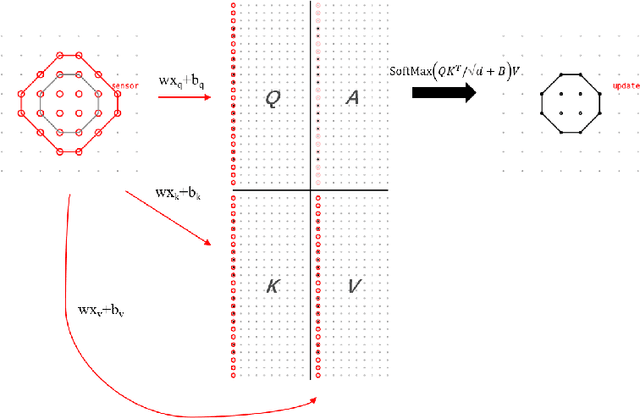

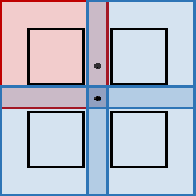
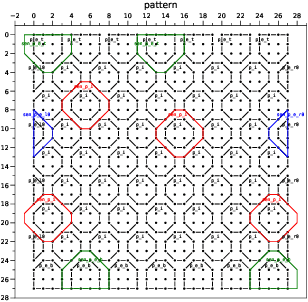
We present in this paper a new architecture, the Pattern Attention Transformer (PAT), that is composed of the new doughnut kernel. Compared with tokens in the NLP field, Transformer in computer vision has the problem of handling the high resolution of pixels in images. Inheriting the patch/window idea from ViT and its follow-ups, the doughnut kernel enhances the design of patches. It replaces the line-cut boundaries with two types of areas: sensor and updating, which is based on the comprehension of self-attention (named QKVA grid). The doughnut kernel also brings a new topic about the shape of kernels. To verify its performance on image classification, PAT is designed with Transformer blocks of regular octagon shape doughnut kernels. Its performance on ImageNet 1K surpasses the Swin Transformer (+0.7 acc1).