 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Myth of Culturally Agnostic AI Models
Nov 29, 2022

The paper discusses the potential of large vision-language models as objects of interest for empirical cultural studies. Focusing on the comparative analysis of outputs from two popular text-to-image synthesis models, DALL-E 2 and Stable Diffusion, the paper tries to tackle the pros and cons of striving towards culturally agnostic vs. culturally specific AI models. The paper discusses several examples of memorization and bias in generated outputs which showcase the trade-off between risk mitigation and cultural specificity, as well as the overall impossibility of developing culturally agnostic models.
Open-Vocabulary 3D Detection via Image-level Class and Debiased Cross-modal Contrastive Learning
Jul 05, 2022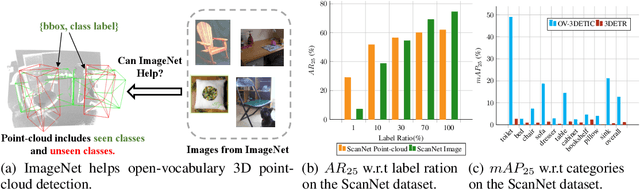
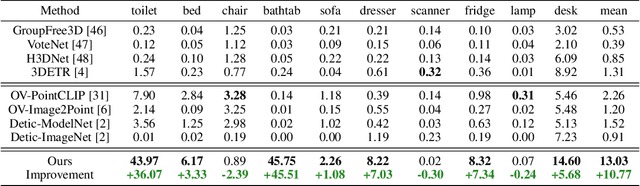
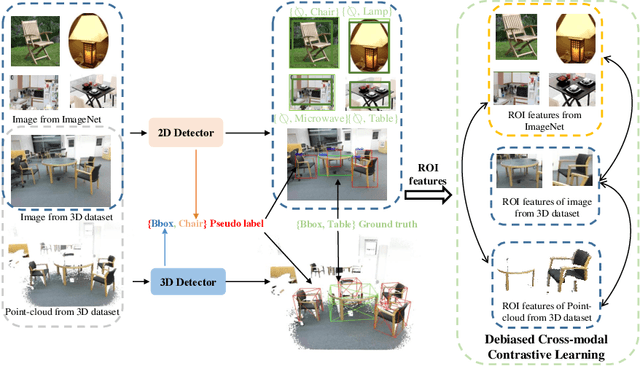
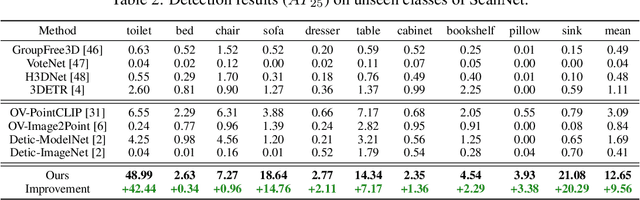
Current point-cloud detection methods have difficulty detecting the open-vocabulary objects in the real world, due to their limited generalization capability. Moreover, it is extremely laborious and expensive to collect and fully annotate a point-cloud detection dataset with numerous classes of objects, leading to the limited classes of existing point-cloud datasets and hindering the model to learn general representations to achieve open-vocabulary point-cloud detection. As far as we know, we are the first to study the problem of open-vocabulary 3D point-cloud detection. Instead of seeking a point-cloud dataset with full labels, we resort to ImageNet1K to broaden the vocabulary of the point-cloud detector. We propose OV-3DETIC, an Open-Vocabulary 3D DETector using Image-level Class supervision. Specifically, we take advantage of two modalities, the image modality for recognition and the point-cloud modality for localization, to generate pseudo labels for unseen classes. Then we propose a novel debiased cross-modal contrastive learning method to transfer the knowledge from image modality to point-cloud modality during training. Without hurting the latency during inference, OV-3DETIC makes the point-cloud detector capable of achieving open-vocabulary detection. Extensive experiments demonstrate that the proposed OV-3DETIC achieves at least 10.77 % mAP improvement (absolute value) and 9.56 % mAP improvement (absolute value) by a wide range of baselines on the SUN-RGBD dataset and ScanNet dataset, respectively. Besides, we conduct sufficient experiments to shed light on why the proposed OV-3DETIC works.
Large-Kernel Attention for 3D Medical Image Segmentation
Jul 19, 2022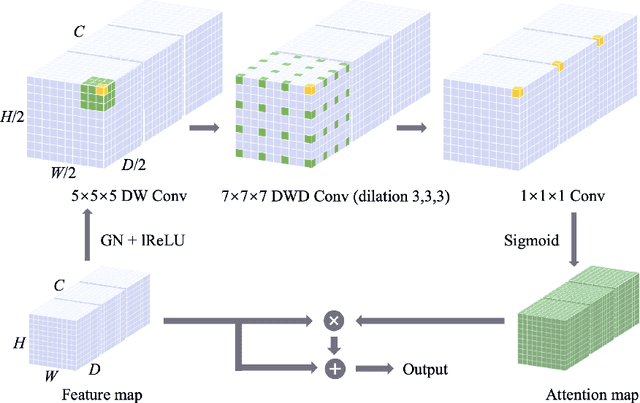
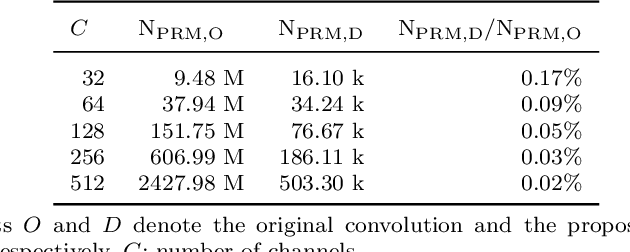
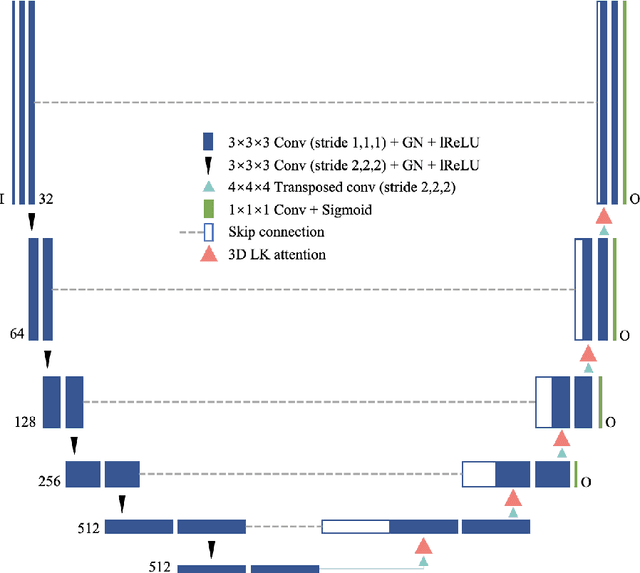

Automatic segmentation of multiple organs and tumors from 3D medical images such as magnetic resonance imaging (MRI) and computed tomography (CT) scans using deep learning methods can aid in diagnosing and treating cancer. However, organs often overlap and are complexly connected, characterized by extensive anatomical variation and low contrast. In addition, the diversity of tumor shape, location, and appearance, coupled with the dominance of background voxels, makes accurate 3D medical image segmentation difficult. In this paper, a novel large-kernel (LK) attention module is proposed to address these problems to achieve accurate multi-organ segmentation and tumor segmentation. The advantages of convolution and self-attention are combined in the proposed LK attention module, including local contextual information, long-range dependence, and channel adaptation. The module also decomposes the LK convolution to optimize the computational cost and can be easily incorporated into FCNs such as U-Net. Comprehensive ablation experiments demonstrated the feasibility of convolutional decomposition and explored the most efficient and effective network design. Among them, the best Mid-type LK attention-based U-Net network was evaluated on CT-ORG and BraTS 2020 datasets, achieving state-of-the-art segmentation performance. The performance improvement due to the proposed LK attention module was also statistically validated.
Siamese based Neural Network for Offline Writer Identification on word level data
Nov 17, 2022
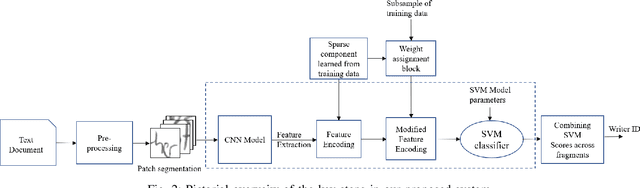
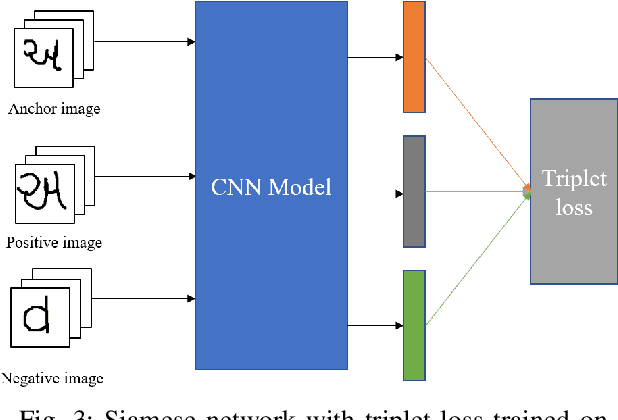
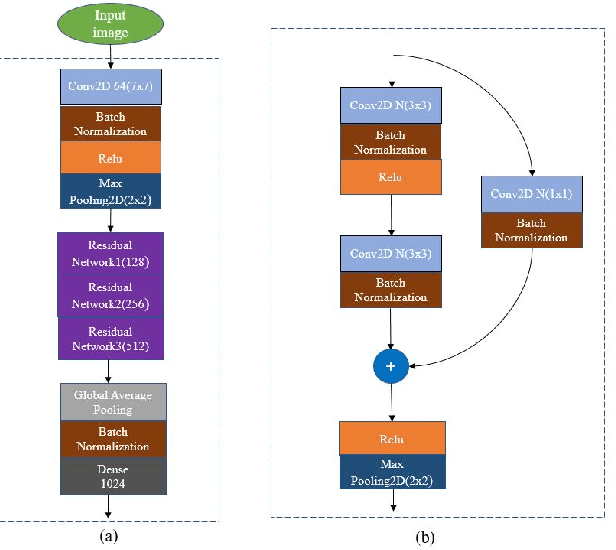
Handwriting recognition is one of the desirable attributes of document comprehension and analysis. It is concerned with the documents writing style and characteristics that distinguish the authors. The diversity of text images, notably in images with varying handwriting, makes the process of learning good features difficult in cases where little data is available. In this paper, we propose a novel scheme to identify the author of a document based on the input word image. Our method is text independent and does not impose any constraint on the size of the input image under examination. To begin with, we detect crucial components in handwriting and extract regions surrounding them using Scale Invariant Feature Transform (SIFT). These patches are designed to capture individual writing features (including allographs, characters, or combinations of characters) that are likely to be unique for an individual writer. These features are then passed through a deep Convolutional Neural Network (CNN) in which the weights are learned by applying the concept of Similarity learning using Siamese network. Siamese network enhances the discrimination power of CNN by mapping similarity between different pairs of input image. Features learned at different scales of the extracted SIFT key-points are encoded using Sparse PCA, each components of the Sparse PCA is assigned a saliency score signifying its level of significance in discriminating different writers effectively. Finally, the weighted Sparse PCA corresponding to each SIFT key-points is combined to arrive at a final classification score for each writer. The proposed algorithm was evaluated on two publicly available databases (namely IAM and CVL) and is able to achieve promising result, when compared with other deep learning based algorithm.
Semantics-Consistent Feature Search for Self-Supervised Visual Representation Learning
Dec 13, 2022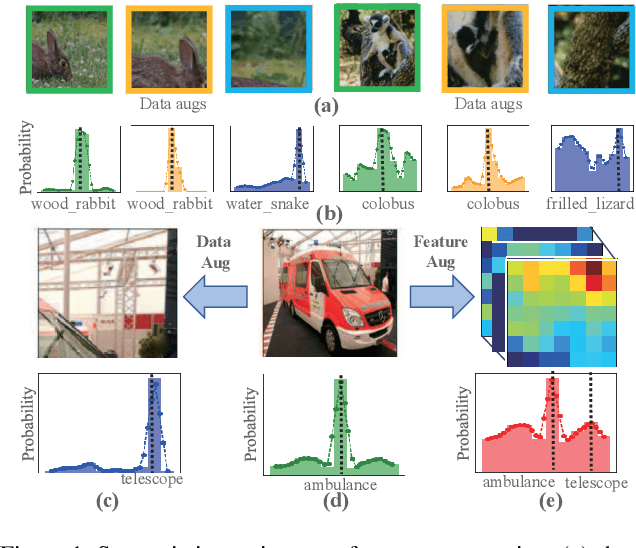
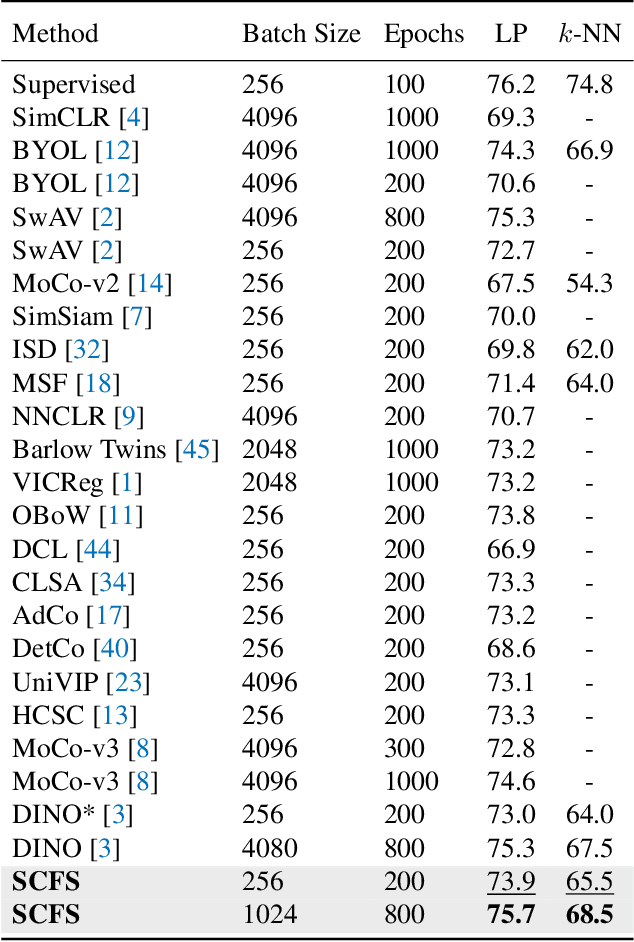
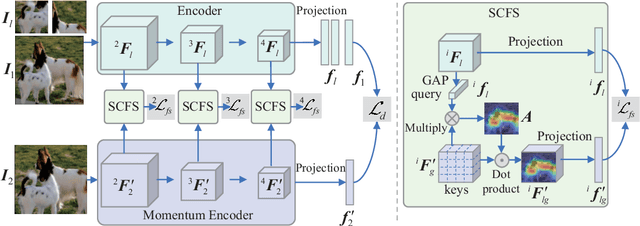
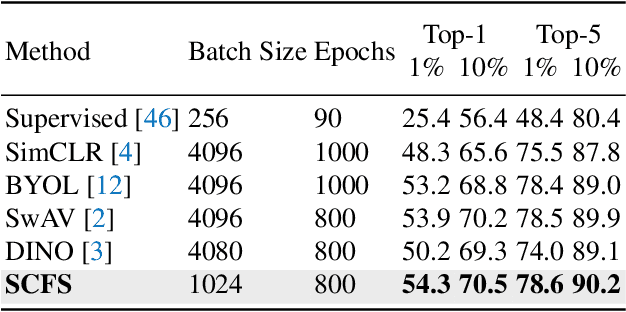
In contrastive self-supervised learning, the common way to learn discriminative representation is to pull different augmented "views" of the same image closer while pushing all other images further apart, which has been proven to be effective. However, it is unavoidable to construct undesirable views containing different semantic concepts during the augmentation procedure. It would damage the semantic consistency of representation to pull these augmentations closer in the feature space indiscriminately. In this study, we introduce feature-level augmentation and propose a novel semantics-consistent feature search (SCFS) method to mitigate this negative effect. The main idea of SCFS is to adaptively search semantics-consistent features to enhance the contrast between semantics-consistent regions in different augmentations. Thus, the trained model can learn to focus on meaningful object regions, improving the semantic representation ability. Extensive experiments conducted on different datasets and tasks demonstrate that SCFS effectively improves the performance of self-supervised learning and achieves state-of-the-art performance on different downstream tasks.
Score-based Generative Modeling Secretly Minimizes the Wasserstein Distance
Dec 13, 2022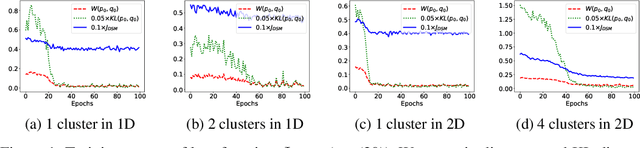
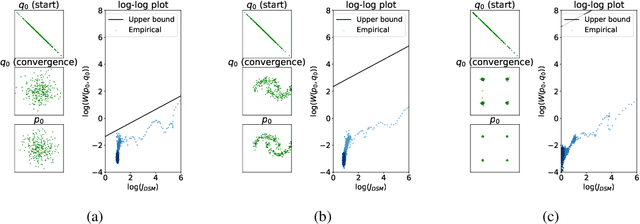
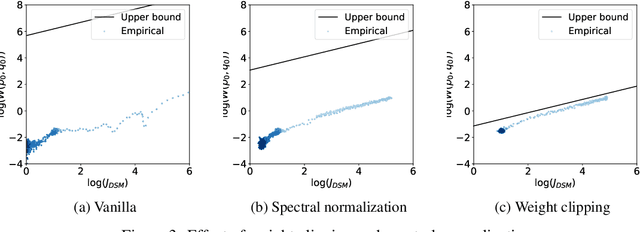
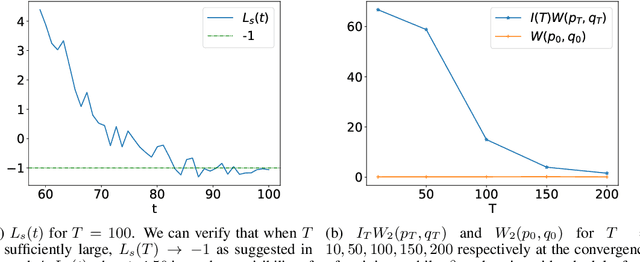
Score-based generative models are shown to achieve remarkable empirical performances in various applications such as image generation and audio synthesis. However, a theoretical understanding of score-based diffusion models is still incomplete. Recently, Song et al. showed that the training objective of score-based generative models is equivalent to minimizing the Kullback-Leibler divergence of the generated distribution from the data distribution. In this work, we show that score-based models also minimize the Wasserstein distance between them under suitable assumptions on the model. Specifically, we prove that the Wasserstein distance is upper bounded by the square root of the objective function up to multiplicative constants and a fixed constant offset. Our proof is based on a novel application of the theory of optimal transport, which can be of independent interest to the society. Our numerical experiments support our findings. By analyzing our upper bounds, we provide a few techniques to obtain tighter upper bounds.
Investigating the Role of Image Retrieval for Visual Localization -- An exhaustive benchmark
May 31, 2022Visual localization, i.e., camera pose estimation in a known scene, is a core component of technologies such as autonomous driving and augmented reality. State-of-the-art localization approaches often rely on image retrieval techniques for one of two purposes: (1) provide an approximate pose estimate or (2) determine which parts of the scene are potentially visible in a given query image. It is common practice to use state-of-the-art image retrieval algorithms for both of them. These algorithms are often trained for the goal of retrieving the same landmark under a large range of viewpoint changes which often differs from the requirements of visual localization. In order to investigate the consequences for visual localization, this paper focuses on understanding the role of image retrieval for multiple visual localization paradigms. First, we introduce a novel benchmark setup and compare state-of-the-art retrieval representations on multiple datasets using localization performance as metric. Second, we investigate several definitions of "ground truth" for image retrieval. Using these definitions as upper bounds for the visual localization paradigms, we show that there is still sgnificant room for improvement. Third, using these tools and in-depth analysis, we show that retrieval performance on classical landmark retrieval or place recognition tasks correlates only for some but not all paradigms to localization performance. Finally, we analyze the effects of blur and dynamic scenes in the images. We conclude that there is a need for retrieval approaches specifically designed for localization paradigms. Our benchmark and evaluation protocols are available at https://github.com/naver/kapture-localization.
Deep Demosaicing for Polarimetric Filter Array Cameras
Nov 24, 2022
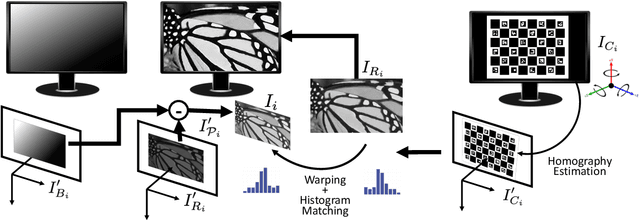
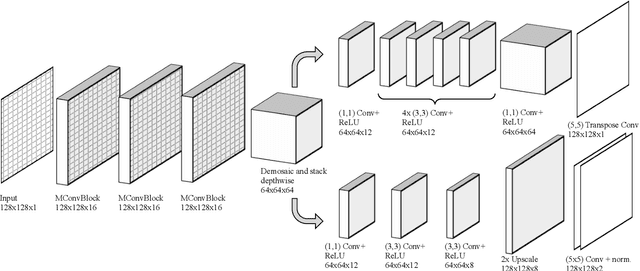
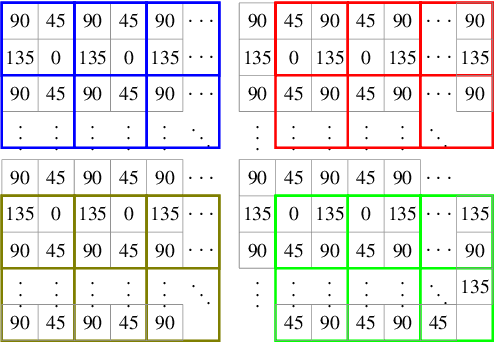
Polarisation Filter Array (PFA) cameras allow the analysis of light polarisation state in a simple and cost-effective manner. Such filter arrays work as the Bayer pattern for colour cameras, sharing similar advantages and drawbacks. Among the others, the raw image must be demosaiced considering the local variations of the PFA and the characteristics of the imaged scene. Non-linear effects, like the cross-talk among neighbouring pixels, are difficult to explicitly model and suggest the potential advantage of a data-driven learning approach. However, the PFA cannot be removed from the sensor, making it difficult to acquire the ground-truth polarization state for training. In this work we propose a novel CNN-based model which directly demosaics the raw camera image to a per-pixel Stokes vector. Our contribution is twofold. First, we propose a network architecture composed by a sequence of Mosaiced Convolutions operating coherently with the local arrangement of the different filters. Second, we introduce a new method, employing a consumer LCD screen, to effectively acquire real-world data for training. The process is designed to be invariant by monitor gamma and external lighting conditions. We extensively compared our method against algorithmic and learning-based demosaicing techniques, obtaining a consistently lower error especially in terms of polarisation angle.
Robust Online Video Instance Segmentation with Track Queries
Nov 16, 2022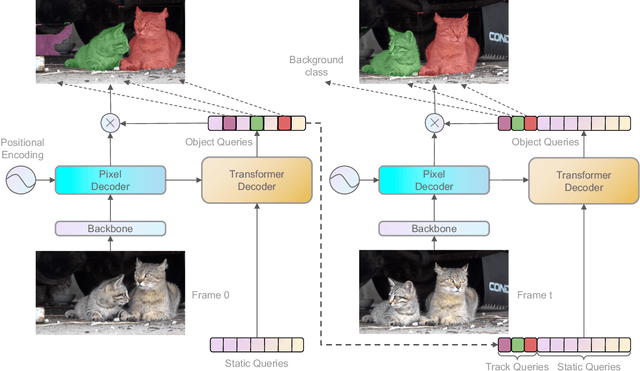
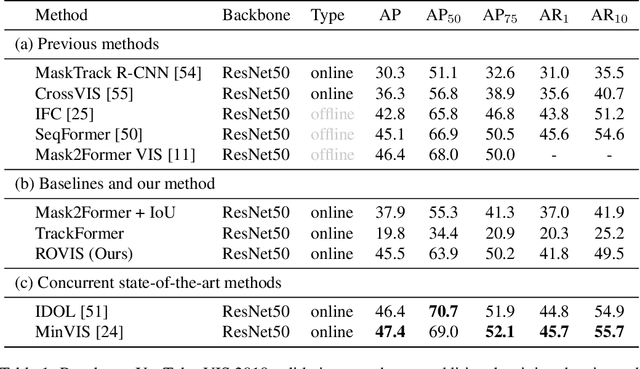

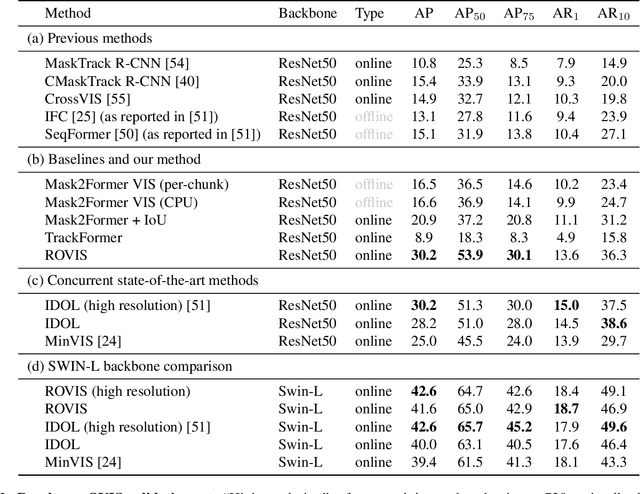
Recently, transformer-based methods have achieved impressive results on Video Instance Segmentation (VIS). However, most of these top-performing methods run in an offline manner by processing the entire video clip at once to predict instance mask volumes. This makes them incapable of handling the long videos that appear in challenging new video instance segmentation datasets like UVO and OVIS. We propose a fully online transformer-based video instance segmentation model that performs comparably to top offline methods on the YouTube-VIS 2019 benchmark and considerably outperforms them on UVO and OVIS. This method, called Robust Online Video Segmentation (ROVIS), augments the Mask2Former image instance segmentation model with track queries, a lightweight mechanism for carrying track information from frame to frame, originally introduced by the TrackFormer method for multi-object tracking. We show that, when combined with a strong enough image segmentation architecture, track queries can exhibit impressive accuracy while not being constrained to short videos.
Energy Reconstruction in Analysis of Cherenkov Telescopes Images in TAIGA Experiment Using Deep Learning Methods
Nov 16, 2022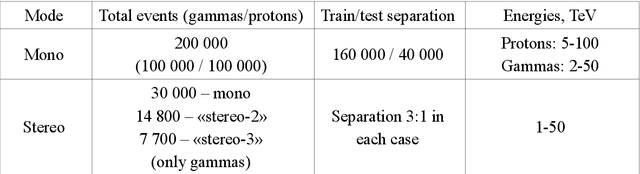
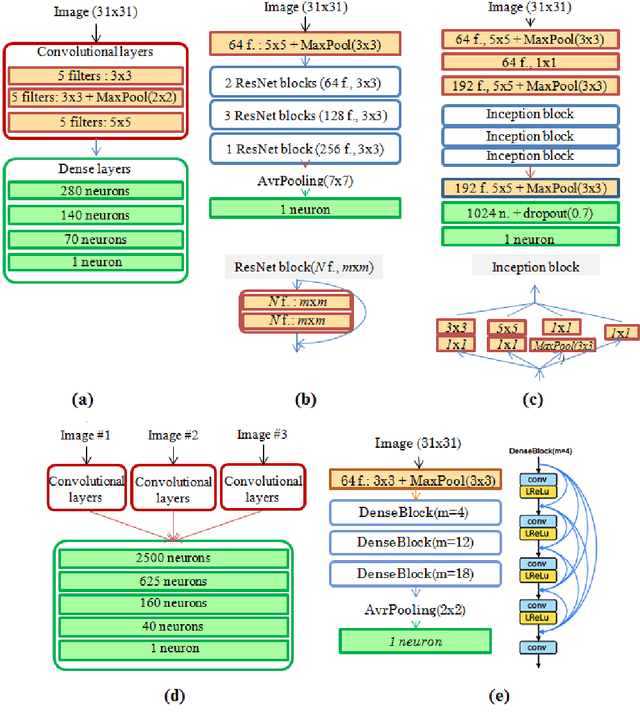
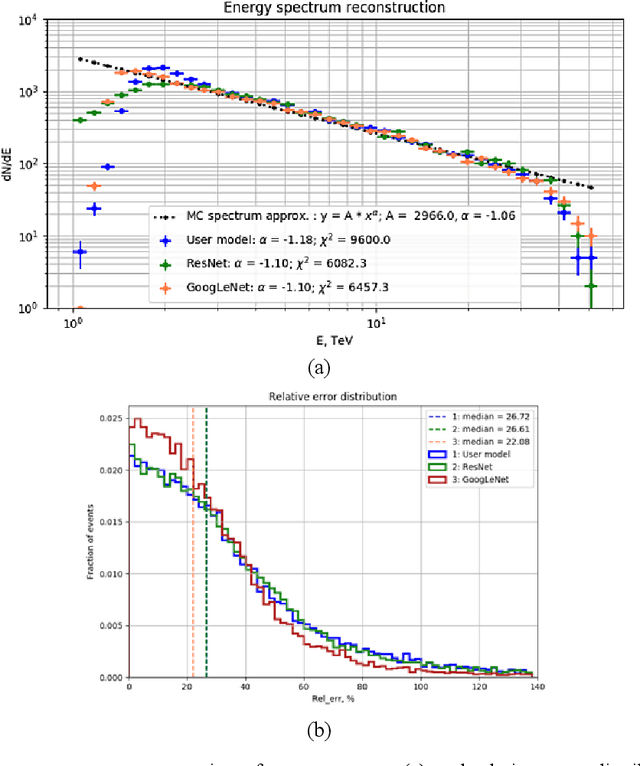
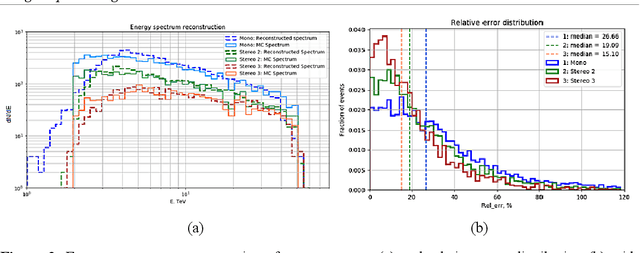
Imaging Atmospheric Cherenkov Telescopes (IACT) of TAIGA astrophysical complex allow to observe high energy gamma radiation helping to study many astrophysical objects and processes. TAIGA-IACT enables us to select gamma quanta from the total cosmic radiation flux and recover their primary parameters, such as energy and direction of arrival. The traditional method of processing the resulting images is an image parameterization - so-called the Hillas parameters method. At the present time Machine Learning methods, in particular Deep Learning methods have become actively used for IACT image processing. This paper presents the analysis of simulated Monte Carlo images by several Deep Learning methods for a single telescope (mono-mode) and multiple IACT telescopes (stereo-mode). The estimation of the quality of energy reconstruction was carried out and their energy spectra were analyzed using several types of neural networks. Using the developed methods the obtained results were also compared with the results obtained by traditional methods based on the Hillas parameters.