 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative Adversarial Networks for Image Super-Resolution: A Survey
Apr 28, 2022
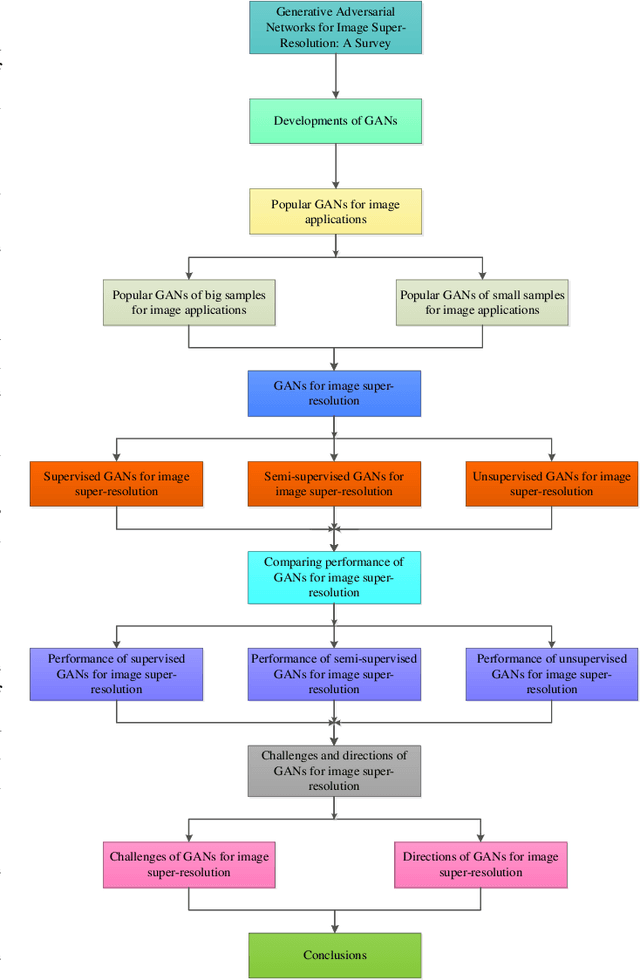
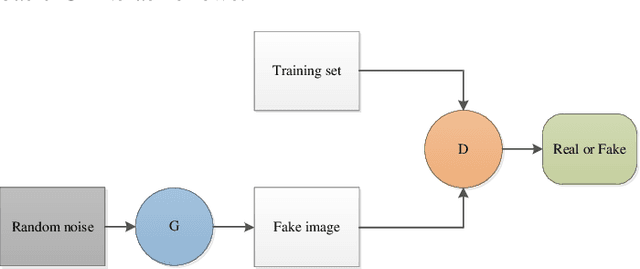
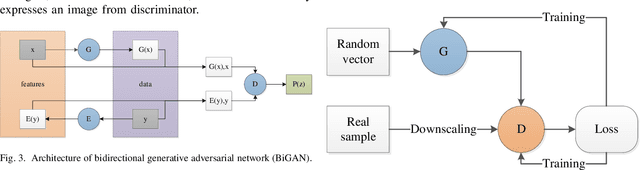
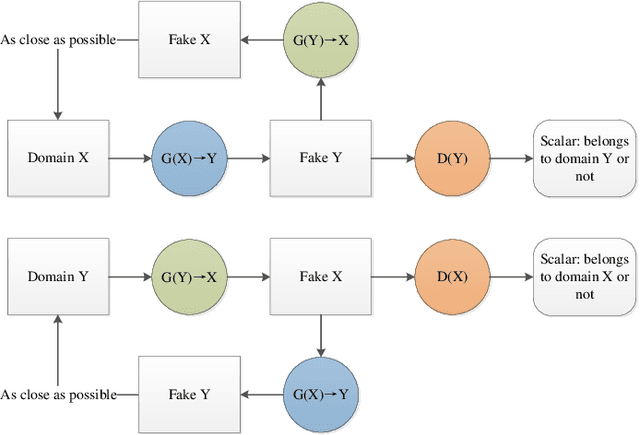
Single image super-resolution (SISR) has played an important role in the field of image processing. Recent generative adversarial networks (GANs) can achieve excellent results on low-resolution images with small samples. However, there are little literatures summarizing different GANs in SISR. In this paper, we conduct a comparative study of GANs from different perspectives. We first take a look at developments of GANs. Second, we present popular architectures for GANs in big and small samples for image applications. Then, we analyze motivations, implementations and differences of GANs based optimization methods and discriminative learning for image super-resolution in terms of supervised, semi-supervised and unsupervised manners. Next, we compare performance of these popular GANs on public datasets via quantitative and qualitative analysis in SISR. Finally, we highlight challenges of GANs and potential research points for SISR.
Empirical Study of Quality Image Assessment for Synthesis of Fetal Head Ultrasound Imaging with DCGANs
Jun 01, 2022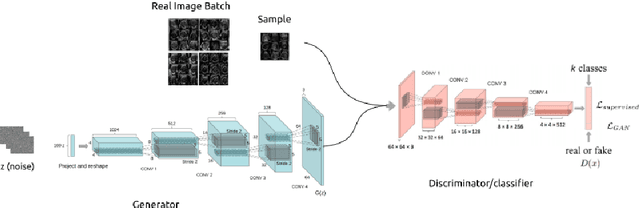
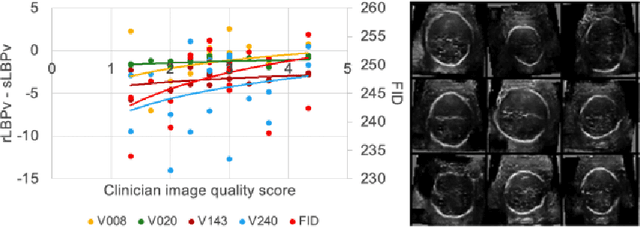
In this work, we present an empirical study of DCGANs for synthetic generation of fetal head ultrasound, consisting of hyperparameter heuristics and image quality assessment. We present experiments to show the impact of different image sizes, epochs, data size input, and learning rates for quality image assessment on four metrics: mutual information (MI), fr\'echet inception distance (FID), peak-signal-to-noise ratio (PSNR), and local binary pattern vector (LBPv). The results show that FID and LBPv have stronger relationship with clinical image quality scores. The resources to reproduce this work are available at \url{https://github.com/xfetus/miua2022}.
Utility-Oriented Underwater Image Quality Assessment Based on Transfer Learning
May 07, 2022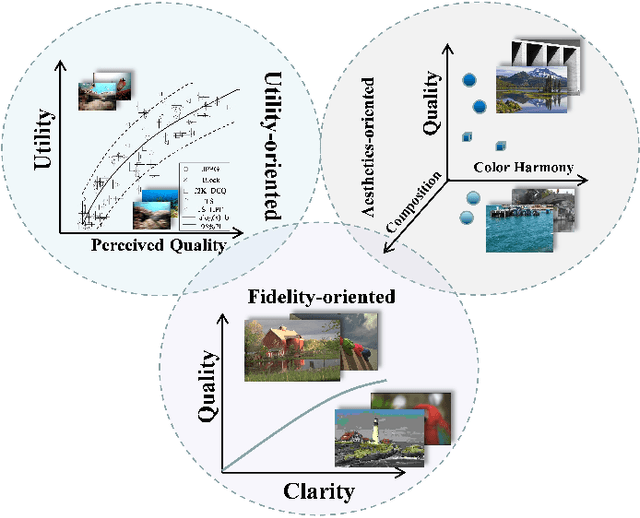

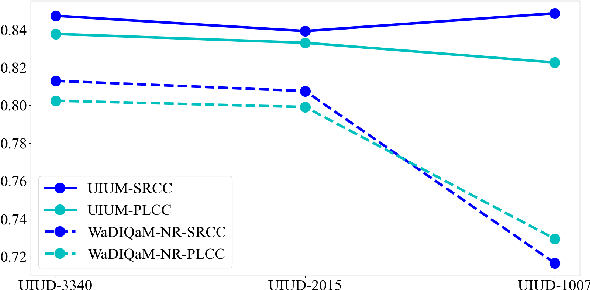
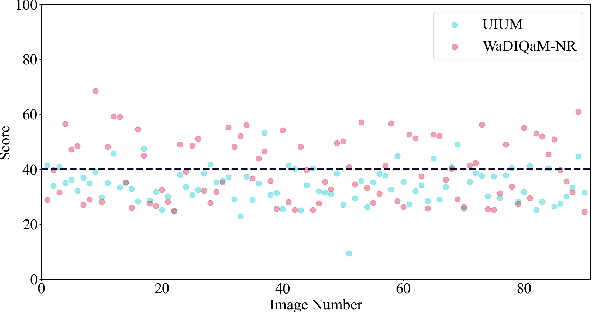
The widespread image applications have greatly promoted the vision-based tasks, in which the Image Quality Assessment (IQA) technique has become an increasingly significant issue. For user enjoyment in multimedia systems, the IQA exploits image fidelity and aesthetics to characterize user experience; while for other tasks such as popular object recognition, there exists a low correlation between utilities and perceptions. In such cases, the fidelity-based and aesthetics-based IQA methods cannot be directly applied. To address this issue, this paper proposes a utility-oriented IQA in object recognition. In particular, we initialize our research in the scenario of underwater fish detection, which is a critical task that has not yet been perfectly addressed. Based on this task, we build an Underwater Image Utility Database (UIUD) and a learning-based Underwater Image Utility Measure (UIUM). Inspired by the top-down design of fidelity-based IQA, we exploit the deep models of object recognition and transfer their features to our UIUM. Experiments validate that the proposed transfer-learning-based UIUM achieves promising performance in the recognition task. We envision our research provides insights to bridge the researches of IQA and computer vision.
Exploring Patch-wise Semantic Relation for Contrastive Learning in Image-to-Image Translation Tasks
Mar 03, 2022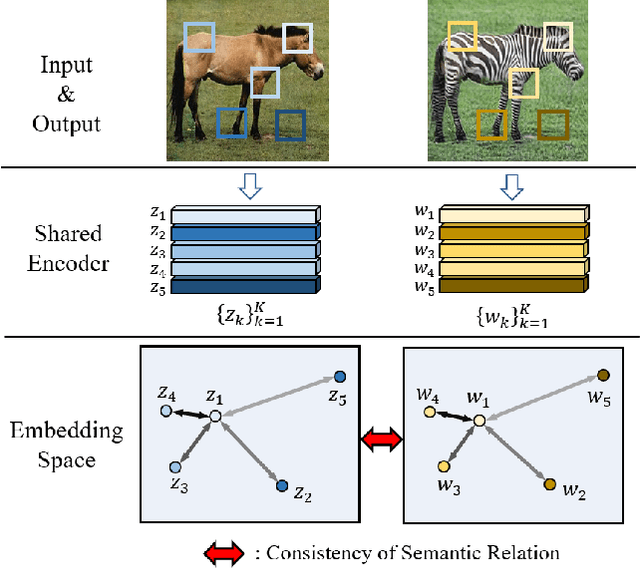
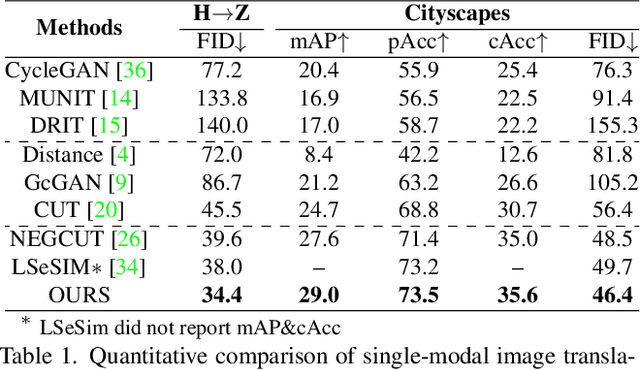
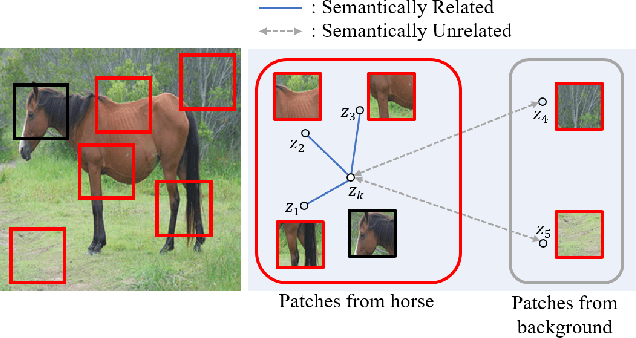
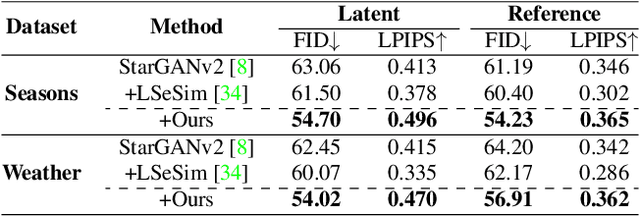
Recently, contrastive learning-based image translation methods have been proposed, which contrasts different spatial locations to enhance the spatial correspondence. However, the methods often ignore the diverse semantic relation within the images. To address this, here we propose a novel semantic relation consistency (SRC) regularization along with the decoupled contrastive learning, which utilize the diverse semantics by focusing on the heterogeneous semantics between the image patches of a single image. To further improve the performance, we present a hard negative mining by exploiting the semantic relation. We verified our method for three tasks: single-modal and multi-modal image translations, and GAN compression task for image translation. Experimental results confirmed the state-of-art performance of our method in all the three tasks.
JigsawHSI: a network for Hyperspectral Image classification
Jun 06, 2022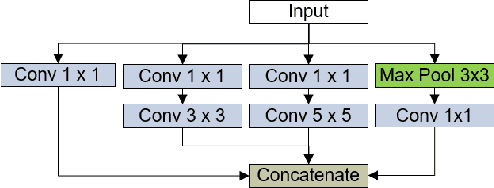
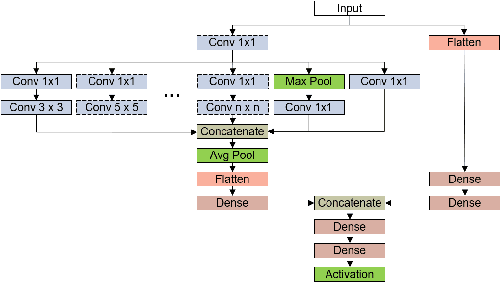
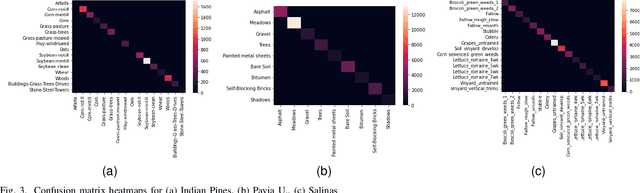
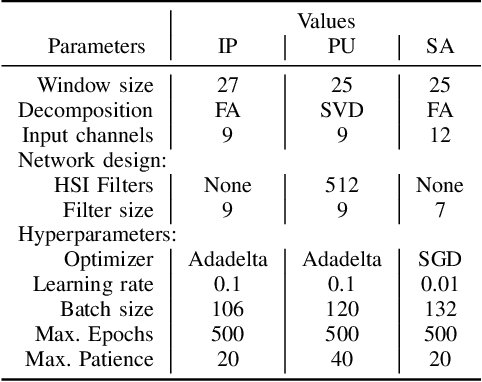
This article describes the performance of JigsawHSI,a convolutional neural network (CNN) based on Inception but tailored for geoscientific analyses, on classification with the Indian Pines, Pavia University and Salinas hyperspectral image data sets. The network is compared against HybridSN, a spectral-spatial 3D-CNN followed by 2D-CNN that achieves state-of-the-art results in the datasets. This short article proves that JigsawHSI is able to meet or exceed HybridSN performance in all three cases. Additionally, the code and toolkit are made available.
Dynamic Feature Pruning and Consolidation for Occluded Person Re-Identification
Nov 27, 2022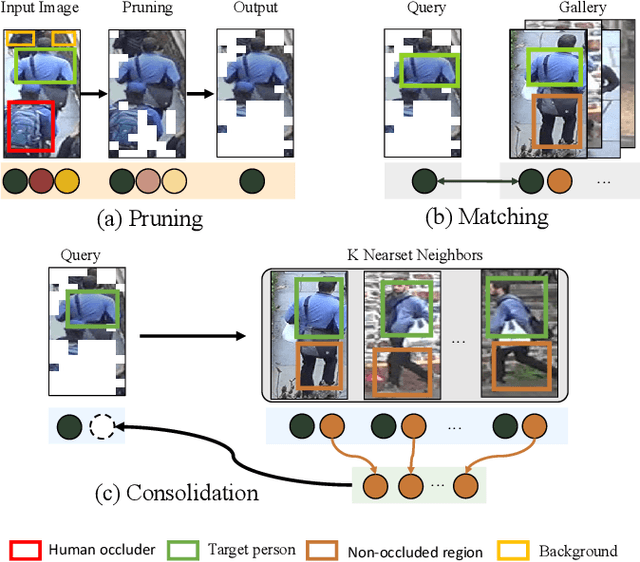
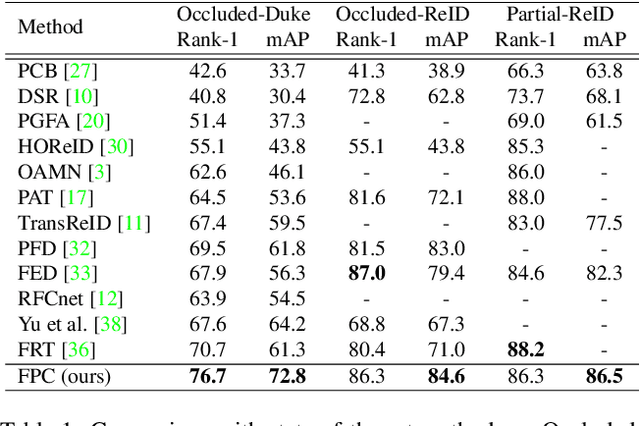
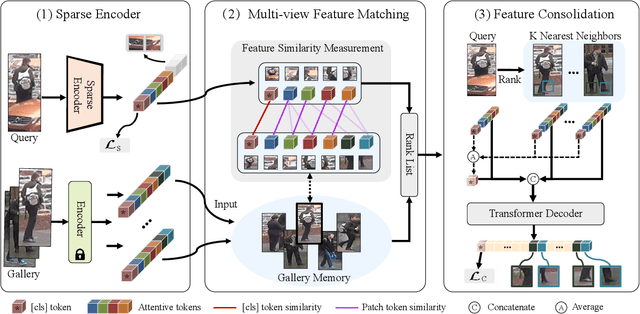
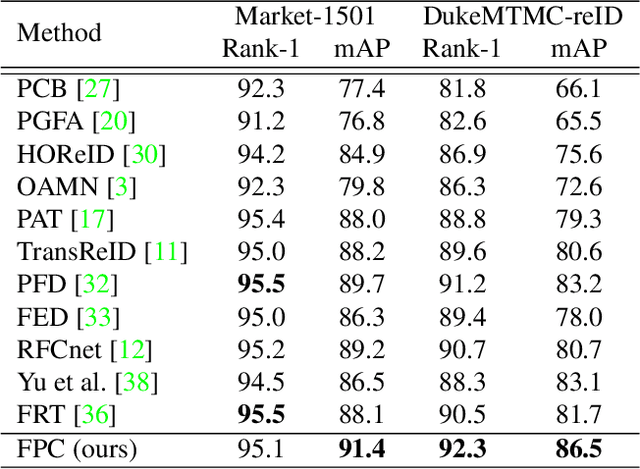
Occluded person re-identification (ReID) is a challenging problem due to contamination from occluders, and existing approaches address the issue with prior knowledge cues, eg human body key points, semantic segmentations and etc, which easily fails in the presents of heavy occlusion and other humans as occluders. In this paper, we propose a feature pruning and consolidation (FPC) framework to circumvent explicit human structure parse, which mainly consists of a sparse encoder, a global and local feature ranking module, and a feature consolidation decoder. Specifically, the sparse encoder drops less important image tokens (mostly related to background noise and occluders) solely according to correlation within the class token attention instead of relying on prior human shape information. Subsequently, the ranking stage relies on the preserved tokens produced by the sparse encoder to identify k-nearest neighbors from a pre-trained gallery memory by measuring the image and patch-level combined similarity. Finally, we use the feature consolidation module to compensate pruned features using identified neighbors for recovering essential information while disregarding disturbance from noise and occlusion. Experimental results demonstrate the effectiveness of our proposed framework on occluded, partial and holistic Re-ID datasets. In particular, our method outperforms state-of-the-art results by at least 8.6% mAP and 6.0% Rank-1 accuracy on the challenging Occluded-Duke dataset.
Scrape, Cut, Paste and Learn: Automated Dataset Generation Applied to Parcel Logistics
Oct 18, 2022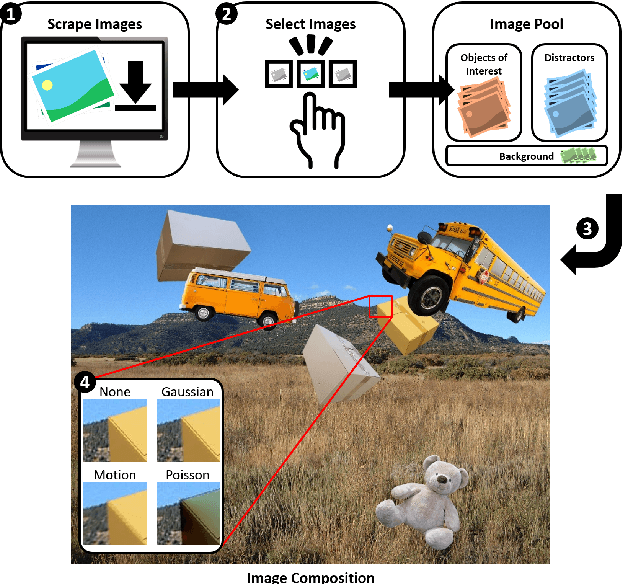


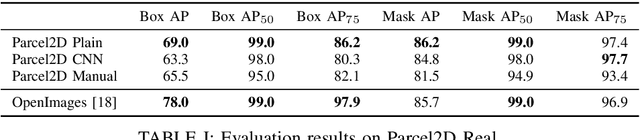
State-of-the-art approaches in computer vision heavily rely on sufficiently large training datasets. For real-world applications, obtaining such a dataset is usually a tedious task. In this paper, we present a fully automated pipeline to generate a synthetic dataset for instance segmentation in four steps. In contrast to existing work, our pipeline covers every step from data acquisition to the final dataset. We first scrape images for the objects of interest from popular image search engines and since we rely only on text-based queries the resulting data comprises a wide variety of images. Hence, image selection is necessary as a second step. This approach of image scraping and selection relaxes the need for a real-world domain-specific dataset that must be either publicly available or created for this purpose. We employ an object-agnostic background removal model and compare three different methods for image selection: Object-agnostic pre-processing, manual image selection and CNN-based image selection. In the third step, we generate random arrangements of the object of interest and distractors on arbitrary backgrounds. Finally, the composition of the images is done by pasting the objects using four different blending methods. We present a case study for our dataset generation approach by considering parcel segmentation. For the evaluation we created a dataset of parcel photos that were annotated automatically. We find that (1) our dataset generation pipeline allows a successful transfer to real test images (Mask AP 86.2), (2) a very accurate image selection process - in contrast to human intuition - is not crucial and a broader category definition can help to bridge the domain gap, (3) the usage of blending methods is beneficial compared to simple copy-and-paste. We made our full code for scraping, image composition and training publicly available at https://a-nau.github.io/parcel2d.
Current State of Community-Driven Radiological AI Deployment in Medical Imaging
Dec 29, 2022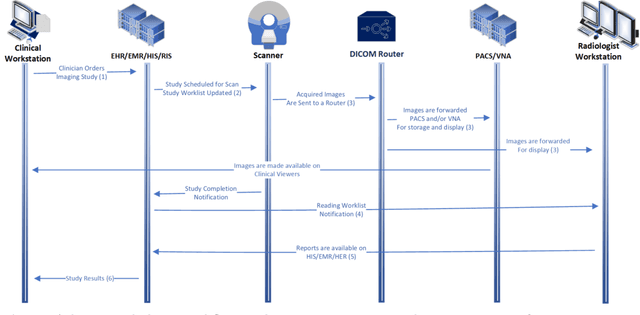
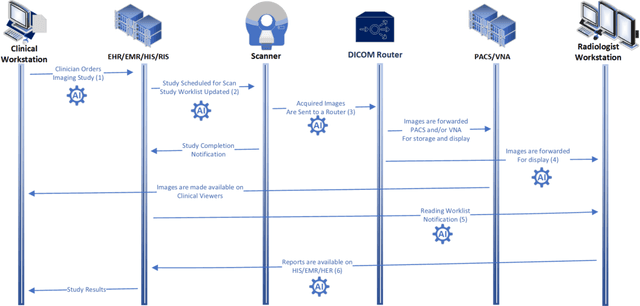
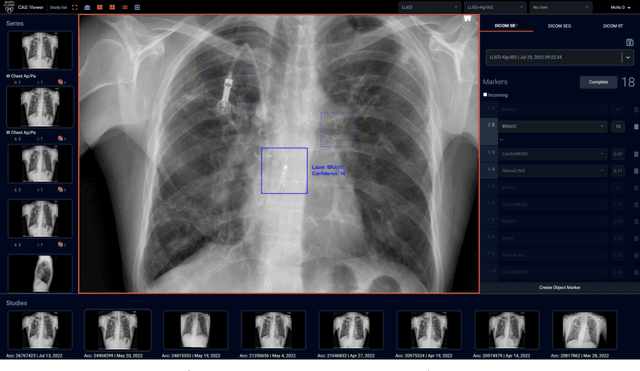
Artificial Intelligence (AI) has become commonplace to solve routine everyday tasks. Because of the exponential growth in medical imaging data volume and complexity, the workload on radiologists is steadily increasing. We project that the gap between the number of imaging exams and the number of expert radiologist readers required to cover this increase will continue to expand, consequently introducing a demand for AI-based tools that improve the efficiency with which radiologists can comfortably interpret these exams. AI has been shown to improve efficiency in medical-image generation, processing, and interpretation, and a variety of such AI models have been developed across research labs worldwide. However, very few of these, if any, find their way into routine clinical use, a discrepancy that reflects the divide between AI research and successful AI translation. To address the barrier to clinical deployment, we have formed MONAI Consortium, an open-source community which is building standards for AI deployment in healthcare institutions, and developing tools and infrastructure to facilitate their implementation. This report represents several years of weekly discussions and hands-on problem solving experience by groups of industry experts and clinicians in the MONAI Consortium. We identify barriers between AI-model development in research labs and subsequent clinical deployment and propose solutions. Our report provides guidance on processes which take an imaging AI model from development to clinical implementation in a healthcare institution. We discuss various AI integration points in a clinical Radiology workflow. We also present a taxonomy of Radiology AI use-cases. Through this report, we intend to educate the stakeholders in healthcare and AI (AI researchers, radiologists, imaging informaticists, and regulators) about cross-disciplinary challenges and possible solutions.
U-Flow: A U-shaped Normalizing Flow for Anomaly Detection with Unsupervised Threshold
Nov 22, 2022
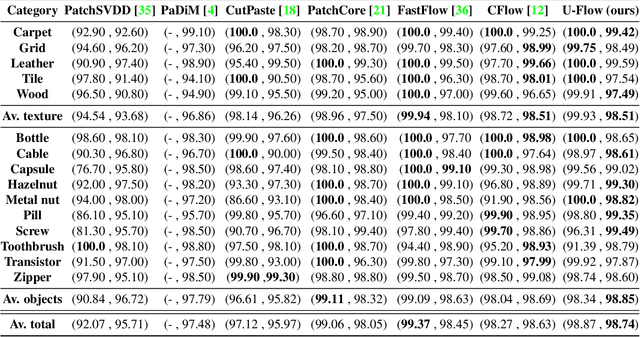
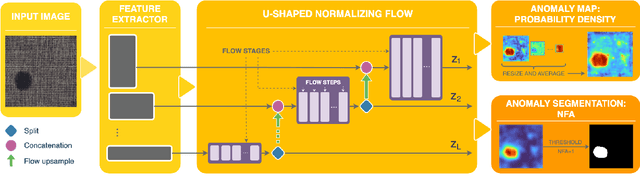
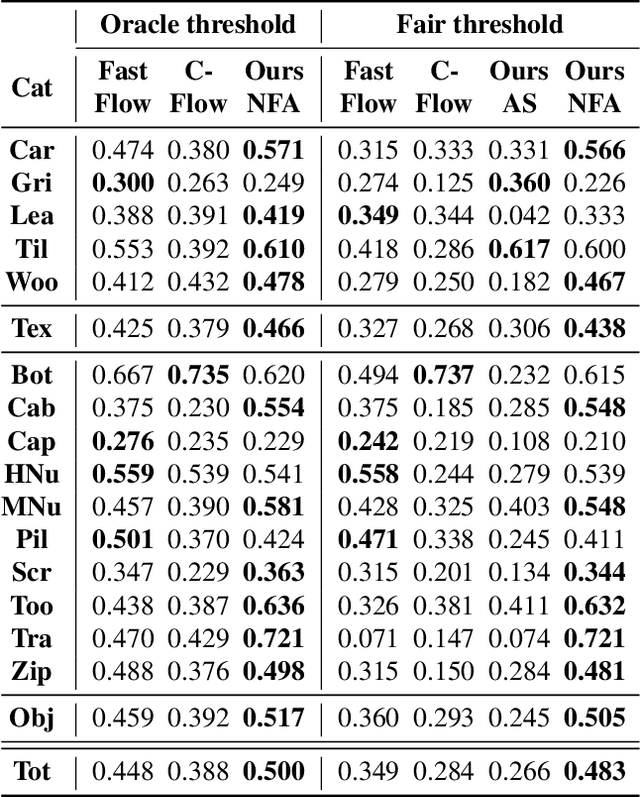
In this work we propose a non-contrastive method for anomaly detection and segmentation in images, that benefits both from a modern machine learning approach and a more classic statistical detection theory. The method consists of three phases. First, features are extracted by making use of a multi-scale image Transformer architecture. Then, these features are fed into a U-shaped Normalizing Flow that lays the theoretical foundations for the last phase, which computes a pixel-level anomaly map, and performs a segmentation based on the a contrario framework. This multiple hypothesis testing strategy permits to derive a robust automatic detection threshold, which is key in many real-world applications, where an operational point is needed. The segmentation results are evaluated using the Intersection over Union (IoU) metric, and for assessing the generated anomaly maps we report the area under the Receiver Operating Characteristic curve (ROC-AUC) at both image and pixel level. For both metrics, the proposed approach produces state-of-the-art results, ranking first in most MvTec-AD categories, with a mean pixel-level ROC- AUC of 98.74%. Code and trained models are available at https://github.com/mtailanian/uflow.
Underwater Images Super-Resolution Using Generative Adversarial Network-based Model
Nov 07, 2022

Single image super-resolution (SISR) methods can enhance the resolution and quality of underwater images. Enhancing the resolution of underwater images leads to better performance of autonomous underwater vehicles. In this work, we fine-tune the Real-Enhanced Super-Resolution Generative Adversarial Network (Real-ESRGAN) model to increase the resolution of underwater images. In our proposed approach, the pre-trained generator and discriminator networks of the Real-ESRGAN model are fine-tuned using underwater image datasets. We used the USR-248 and UFO-120 datasets to fine-tune the Real-ESRGAN model. Our fine-tuned model produces images with better resolution and quality compared to the original model.