 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Strengthening Multimodal Large Language Model with Bootstrapped Preference Optimization
Mar 13, 2024
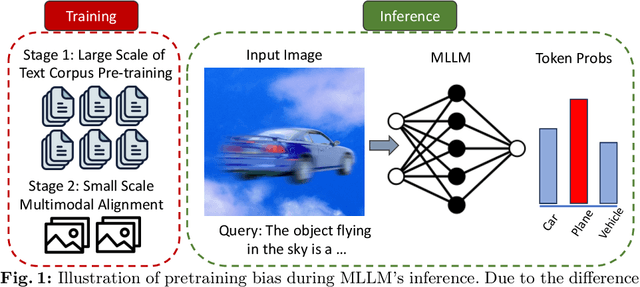


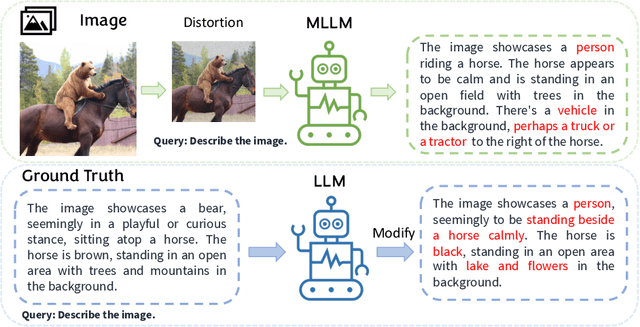
Multimodal Large Language Models (MLLMs) excel in generating responses based on visual inputs. However, they often suffer from a bias towards generating responses similar to their pretraining corpus, overshadowing the importance of visual information. We treat this bias as a "preference" for pretraining statistics, which hinders the model's grounding in visual input. To mitigate this issue, we propose Bootstrapped Preference Optimization (BPO), which conducts preference learning with datasets containing negative responses bootstrapped from the model itself. Specifically, we propose the following two strategies: 1) using distorted image inputs to the MLLM for eliciting responses that contain signified pretraining bias; 2) leveraging text-based LLM to explicitly inject erroneous but common elements into the original response. Those undesirable responses are paired with original annotated responses from the datasets to construct the preference dataset, which is subsequently utilized to perform preference learning. Our approach effectively suppresses pretrained LLM bias, enabling enhanced grounding in visual inputs. Extensive experimentation demonstrates significant performance improvements across multiple benchmarks, advancing the state-of-the-art in multimodal conversational systems.
TNF: Tri-branch Neural Fusion for Multimodal Medical Data Classification
Mar 10, 2024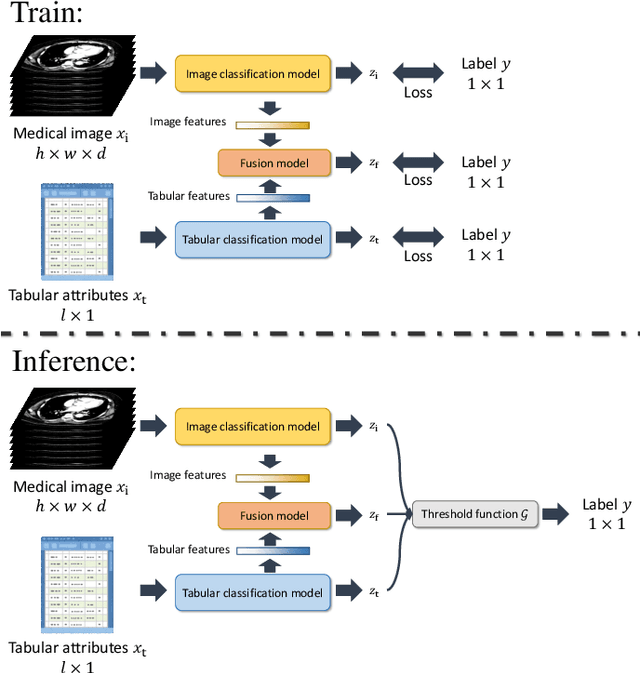
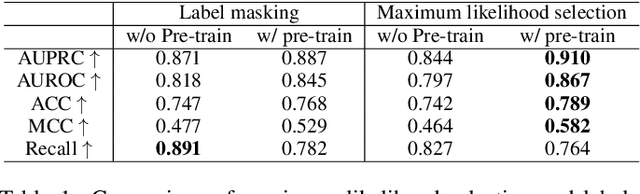
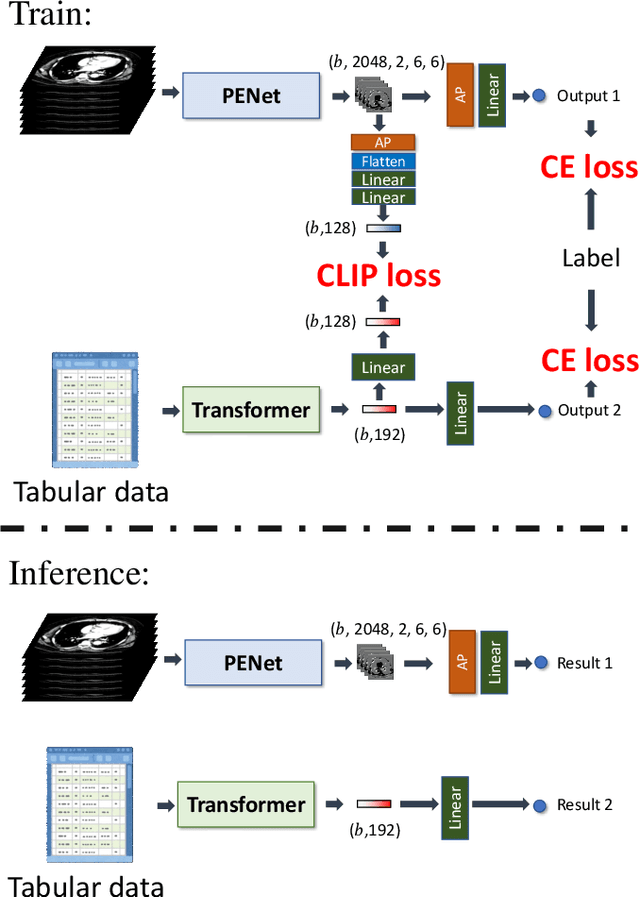
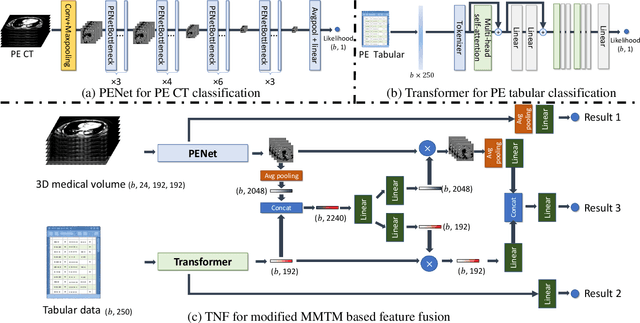
This paper presents a Tri-branch Neural Fusion (TNF) approach designed for classifying multimodal medical images and tabular data. It also introduces two solutions to address the challenge of label inconsistency in multimodal classification. Traditional methods in multi-modality medical data classification often rely on single-label approaches, typically merging features from two distinct input modalities. This becomes problematic when features are mutually exclusive or labels differ across modalities, leading to reduced accuracy. To overcome this, our TNF approach implements a tri-branch framework that manages three separate outputs: one for image modality, another for tabular modality, and a third hybrid output that fuses both image and tabular data. The final decision is made through an ensemble method that integrates likelihoods from all three branches. We validate the effectiveness of TNF through extensive experiments, which illustrate its superiority over traditional fusion and ensemble methods in various convolutional neural networks and transformer-based architectures across multiple datasets.
BLO-SAM: Bi-level Optimization Based Overfitting-Preventing Finetuning of SAM
Mar 11, 2024The Segment Anything Model (SAM), a foundation model pretrained on millions of images and segmentation masks, has significantly advanced semantic segmentation, a fundamental task in computer vision. Despite its strengths, SAM encounters two major challenges. Firstly, it struggles with segmenting specific objects autonomously, as it relies on users to manually input prompts like points or bounding boxes to identify targeted objects. Secondly, SAM faces challenges in excelling at specific downstream tasks, like medical imaging, due to a disparity between the distribution of its pretraining data, which predominantly consists of general-domain images, and the data used in downstream tasks. Current solutions to these problems, which involve finetuning SAM, often lead to overfitting, a notable issue in scenarios with very limited data, like in medical imaging. To overcome these limitations, we introduce BLO-SAM, which finetunes SAM based on bi-level optimization (BLO). Our approach allows for automatic image segmentation without the need for manual prompts, by optimizing a learnable prompt embedding. Furthermore, it significantly reduces the risk of overfitting by training the model's weight parameters and the prompt embedding on two separate subsets of the training dataset, each at a different level of optimization. We apply BLO-SAM to diverse semantic segmentation tasks in general and medical domains. The results demonstrate BLO-SAM's superior performance over various state-of-the-art image semantic segmentation methods.
A Converting Autoencoder Toward Low-latency and Energy-efficient DNN Inference at the Edge
Mar 11, 2024
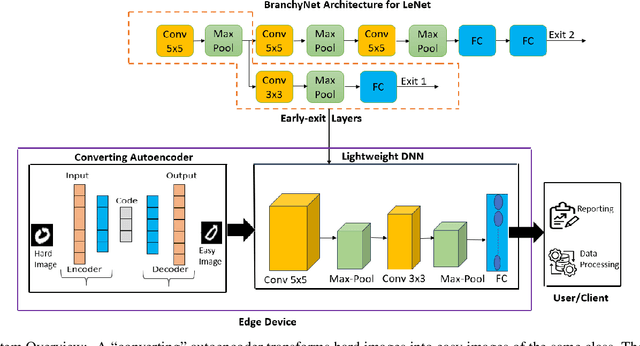
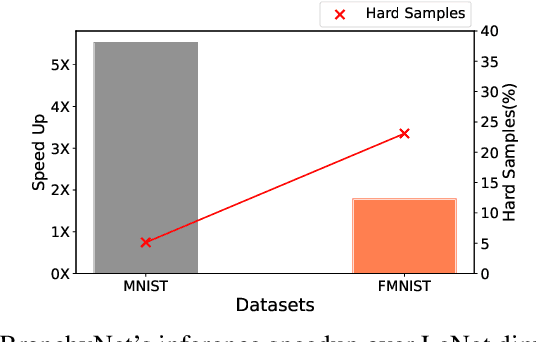
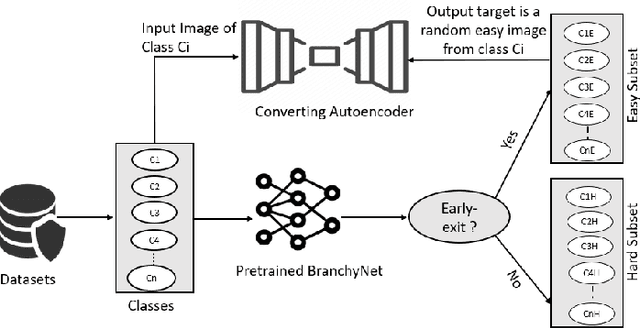
Reducing inference time and energy usage while maintaining prediction accuracy has become a significant concern for deep neural networks (DNN) inference on resource-constrained edge devices. To address this problem, we propose a novel approach based on "converting" autoencoder and lightweight DNNs. This improves upon recent work such as early-exiting framework and DNN partitioning. Early-exiting frameworks spend different amounts of computation power for different input data depending upon their complexity. However, they can be inefficient in real-world scenarios that deal with many hard image samples. On the other hand, DNN partitioning algorithms that utilize the computation power of both the cloud and edge devices can be affected by network delays and intermittent connections between the cloud and the edge. We present CBNet, a low-latency and energy-efficient DNN inference framework tailored for edge devices. It utilizes a "converting" autoencoder to efficiently transform hard images into easy ones, which are subsequently processed by a lightweight DNN for inference. To the best of our knowledge, such autoencoder has not been proposed earlier. Our experimental results using three popular image-classification datasets on a Raspberry Pi 4, a Google Cloud instance, and an instance with Nvidia Tesla K80 GPU show that CBNet achieves up to 4.8x speedup in inference latency and 79% reduction in energy usage compared to competing techniques while maintaining similar or higher accuracy.
A Cognitive Evaluation Benchmark of Image Reasoning and Description for Large Vision Language Models
Feb 29, 2024Large Vision Language Models (LVLMs), despite their recent success, are hardly comprehensively tested for their cognitive abilities. Inspired by the prevalent use of the "Cookie Theft" task in human cognition test, we propose a novel evaluation benchmark to evaluate high-level cognitive ability of LVLMs using images with rich semantics. It defines eight reasoning capabilities and consists of an image description task and a visual question answering task. Our evaluation on well-known LVLMs shows that there is still a large gap in cognitive ability between LVLMs and humans.
FedLPPA: Learning Personalized Prompt and Aggregation for Federated Weakly-supervised Medical Image Segmentation
Feb 27, 2024Federated learning (FL) effectively mitigates the data silo challenge brought about by policies and privacy concerns, implicitly harnessing more data for deep model training. However, traditional centralized FL models grapple with diverse multi-center data, especially in the face of significant data heterogeneity, notably in medical contexts. In the realm of medical image segmentation, the growing imperative to curtail annotation costs has amplified the importance of weakly-supervised techniques which utilize sparse annotations such as points, scribbles, etc. A pragmatic FL paradigm shall accommodate diverse annotation formats across different sites, which research topic remains under-investigated. In such context, we propose a novel personalized FL framework with learnable prompt and aggregation (FedLPPA) to uniformly leverage heterogeneous weak supervision for medical image segmentation. In FedLPPA, a learnable universal knowledge prompt is maintained, complemented by multiple learnable personalized data distribution prompts and prompts representing the supervision sparsity. Integrated with sample features through a dual-attention mechanism, those prompts empower each local task decoder to adeptly adjust to both the local distribution and the supervision form. Concurrently, a dual-decoder strategy, predicated on prompt similarity, is introduced for enhancing the generation of pseudo-labels in weakly-supervised learning, alleviating overfitting and noise accumulation inherent to local data, while an adaptable aggregation method is employed to customize the task decoder on a parameter-wise basis. Extensive experiments on three distinct medical image segmentation tasks involving different modalities underscore the superiority of FedLPPA, with its efficacy closely parallels that of fully supervised centralized training. Our code and data will be available.
SpikeReveal: Unlocking Temporal Sequences from Real Blurry Inputs with Spike Streams
Mar 14, 2024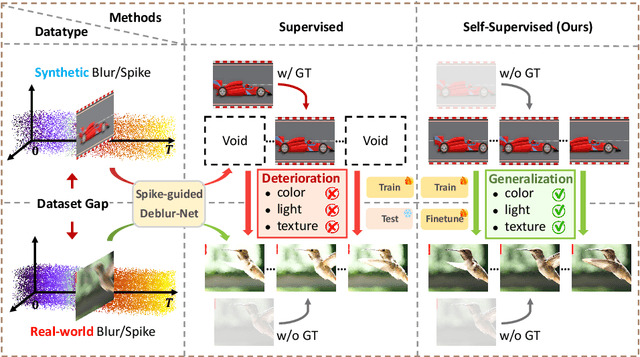
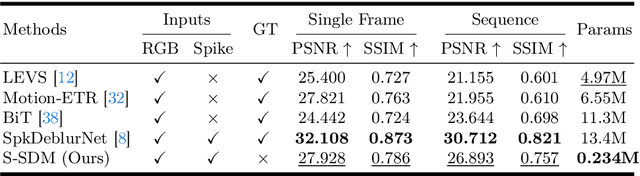
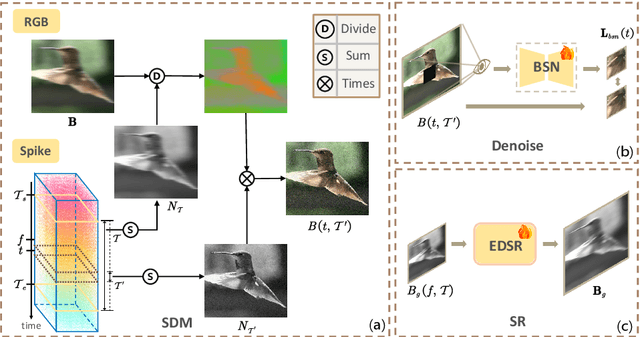
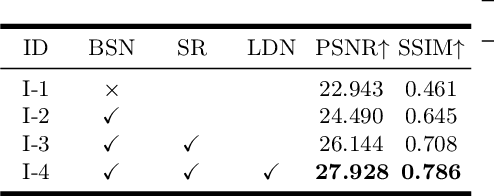
Reconstructing a sequence of sharp images from the blurry input is crucial for enhancing our insights into the captured scene and poses a significant challenge due to the limited temporal features embedded in the image. Spike cameras, sampling at rates up to 40,000 Hz, have proven effective in capturing motion features and beneficial for solving this ill-posed problem. Nonetheless, existing methods fall into the supervised learning paradigm, which suffers from notable performance degradation when applied to real-world scenarios that diverge from the synthetic training data domain. Moreover, the quality of reconstructed images is capped by the generated images based on motion analysis interpolation, which inherently differs from the actual scene, affecting the generalization ability of these methods in real high-speed scenarios. To address these challenges, we propose the first self-supervised framework for the task of spike-guided motion deblurring. Our approach begins with the formulation of a spike-guided deblurring model that explores the theoretical relationships among spike streams, blurry images, and their corresponding sharp sequences. We subsequently develop a self-supervised cascaded framework to alleviate the issues of spike noise and spatial-resolution mismatching encountered in the deblurring model. With knowledge distillation and re-blurring loss, we further design a lightweight deblur network to generate high-quality sequences with brightness and texture consistency with the original input. Quantitative and qualitative experiments conducted on our real-world and synthetic datasets with spikes validate the superior generalization of the proposed framework. Our code, data and trained models will be available at \url{https://github.com/chenkang455/S-SDM}.
Intention-driven Ego-to-Exo Video Generation
Mar 14, 2024

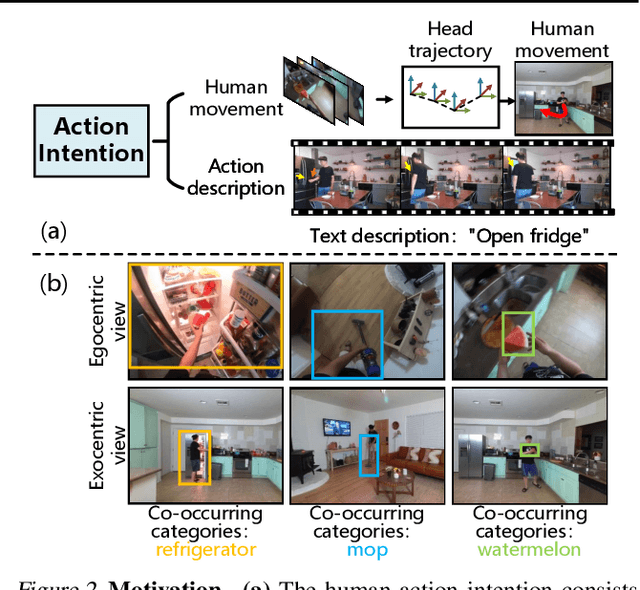
Ego-to-exo video generation refers to generating the corresponding exocentric video according to the egocentric video, providing valuable applications in AR/VR and embodied AI. Benefiting from advancements in diffusion model techniques, notable progress has been achieved in video generation. However, existing methods build upon the spatiotemporal consistency assumptions between adjacent frames, which cannot be satisfied in the ego-to-exo scenarios due to drastic changes in views. To this end, this paper proposes an Intention-Driven Ego-to-exo video generation framework (IDE) that leverages action intention consisting of human movement and action description as view-independent representation to guide video generation, preserving the consistency of content and motion. Specifically, the egocentric head trajectory is first estimated through multi-view stereo matching. Then, cross-view feature perception module is introduced to establish correspondences between exo- and ego- views, guiding the trajectory transformation module to infer human full-body movement from the head trajectory. Meanwhile, we present an action description unit that maps the action semantics into the feature space consistent with the exocentric image. Finally, the inferred human movement and high-level action descriptions jointly guide the generation of exocentric motion and interaction content (i.e., corresponding optical flow and occlusion maps) in the backward process of the diffusion model, ultimately warping them into the corresponding exocentric video. We conduct extensive experiments on the relevant dataset with diverse exo-ego video pairs, and our IDE outperforms state-of-the-art models in both subjective and objective assessments, demonstrating its efficacy in ego-to-exo video generation.
FastSAM3D: An Efficient Segment Anything Model for 3D Volumetric Medical Images
Mar 14, 2024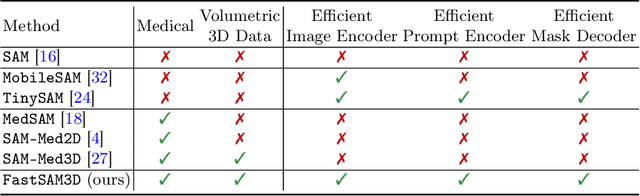
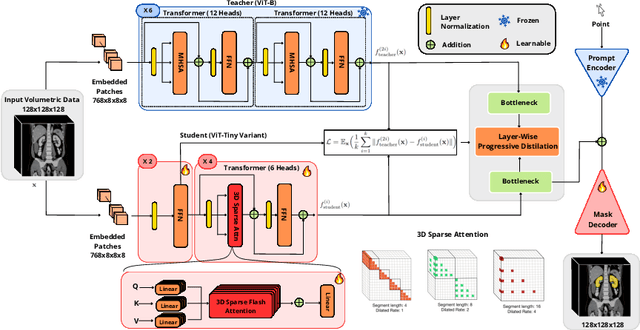
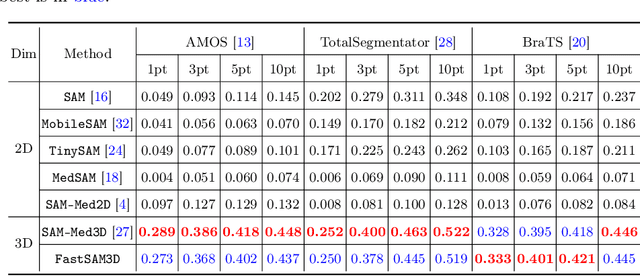
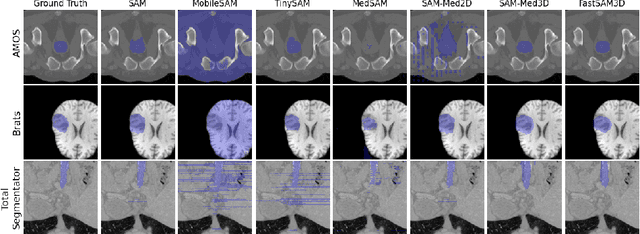
Segment anything models (SAMs) are gaining attention for their zero-shot generalization capability in segmenting objects of unseen classes and in unseen domains when properly prompted. Interactivity is a key strength of SAMs, allowing users to iteratively provide prompts that specify objects of interest to refine outputs. However, to realize the interactive use of SAMs for 3D medical imaging tasks, rapid inference times are necessary. High memory requirements and long processing delays remain constraints that hinder the adoption of SAMs for this purpose. Specifically, while 2D SAMs applied to 3D volumes contend with repetitive computation to process all slices independently, 3D SAMs suffer from an exponential increase in model parameters and FLOPS. To address these challenges, we present FastSAM3D which accelerates SAM inference to 8 milliseconds per 128*128*128 3D volumetric image on an NVIDIA A100 GPU. This speedup is accomplished through 1) a novel layer-wise progressive distillation scheme that enables knowledge transfer from a complex 12-layer ViT-B to a lightweight 6-layer ViT-Tiny variant encoder without training from scratch; and 2) a novel 3D sparse flash attention to replace vanilla attention operators, substantially reducing memory needs and improving parallelization. Experiments on three diverse datasets reveal that FastSAM3D achieves a remarkable speedup of 527.38x compared to 2D SAMs and 8.75x compared to 3D SAMs on the same volumes without significant performance decline. Thus, FastSAM3D opens the door for low-cost truly interactive SAM-based 3D medical imaging segmentation with commonly used GPU hardware. Code is available at https://github.com/arcadelab/FastSAM3D.
DuDoUniNeXt: Dual-domain unified hybrid model for single and multi-contrast undersampled MRI reconstruction
Mar 08, 2024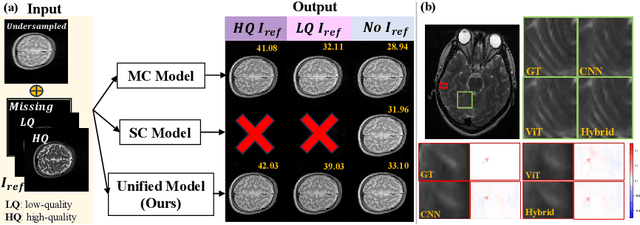
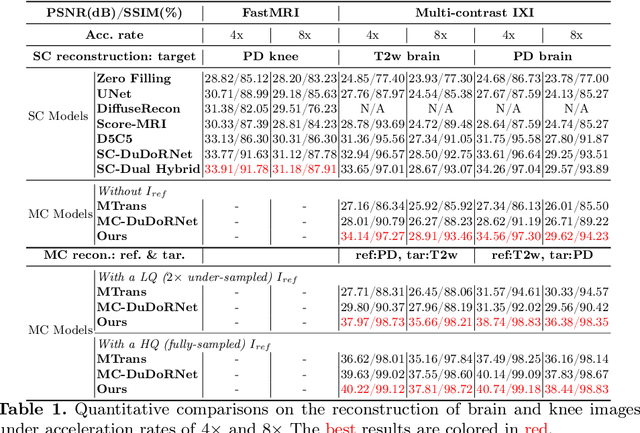

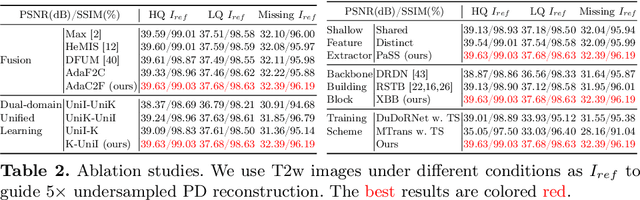
Multi-contrast (MC) Magnetic Resonance Imaging (MRI) reconstruction aims to incorporate a reference image of auxiliary modality to guide the reconstruction process of the target modality. Known MC reconstruction methods perform well with a fully sampled reference image, but usually exhibit inferior performance, compared to single-contrast (SC) methods, when the reference image is missing or of low quality. To address this issue, we propose DuDoUniNeXt, a unified dual-domain MRI reconstruction network that can accommodate to scenarios involving absent, low-quality, and high-quality reference images. DuDoUniNeXt adopts a hybrid backbone that combines CNN and ViT, enabling specific adjustment of image domain and k-space reconstruction. Specifically, an adaptive coarse-to-fine feature fusion module (AdaC2F) is devised to dynamically process the information from reference images of varying qualities. Besides, a partially shared shallow feature extractor (PaSS) is proposed, which uses shared and distinct parameters to handle consistent and discrepancy information among contrasts. Experimental results demonstrate that the proposed model surpasses state-of-the-art SC and MC models significantly. Ablation studies show the effectiveness of the proposed hybrid backbone, AdaC2F, PaSS, and the dual-domain unified learning scheme.