 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Losses over Labels: Weakly Supervised Learning via Direct Loss Construction
Dec 13, 2022
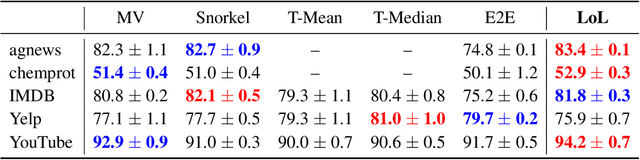

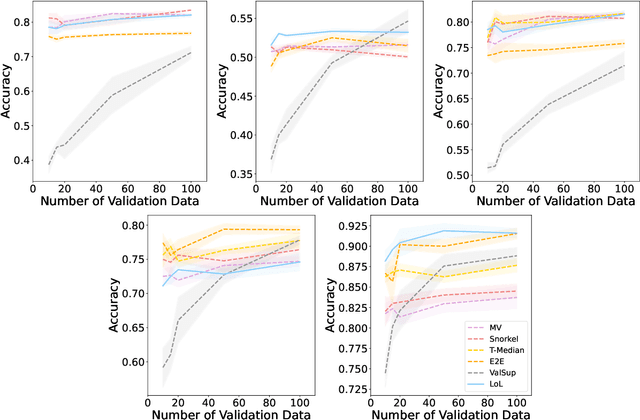
Owing to the prohibitive costs of generating large amounts of labeled data, programmatic weak supervision is a growing paradigm within machine learning. In this setting, users design heuristics that provide noisy labels for subsets of the data. These weak labels are combined (typically via a graphical model) to form pseudolabels, which are then used to train a downstream model. In this work, we question a foundational premise of the typical weakly supervised learning pipeline: given that the heuristic provides all ``label" information, why do we need to generate pseudolabels at all? Instead, we propose to directly transform the heuristics themselves into corresponding loss functions that penalize differences between our model and the heuristic. By constructing losses directly from the heuristics, we can incorporate more information than is used in the standard weakly supervised pipeline, such as how the heuristics make their decisions, which explicitly informs feature selection during training. We call our method Losses over Labels (LoL) as it creates losses directly from heuristics without going through the intermediate step of a label. We show that LoL improves upon existing weak supervision methods on several benchmark text and image classification tasks and further demonstrate that incorporating gradient information leads to better performance on almost every task.
Models Developed for Spiking Neural Networks
Dec 08, 2022
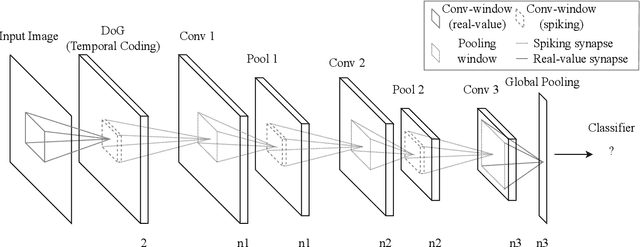
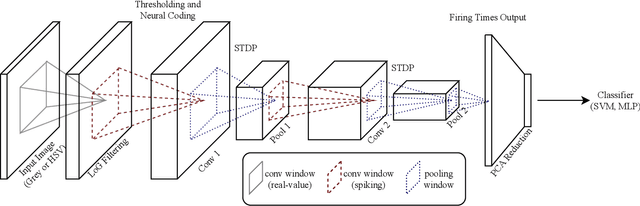
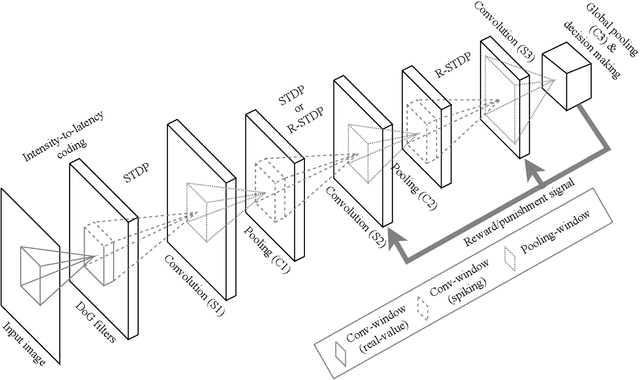
Emergence of deep neural networks (DNNs) has raised enormous attention towards artificial neural networks (ANNs) once again. They have become the state-of-the-art models and have won different machine learning challenges. Although these networks are inspired by the brain, they lack biological plausibility, and they have structural differences compared to the brain. Spiking neural networks (SNNs) have been around for a long time, and they have been investigated to understand the dynamics of the brain. However, their application in real-world and complicated machine learning tasks were limited. Recently, they have shown great potential in solving such tasks. Due to their energy efficiency and temporal dynamics there are many promises in their future development. In this work, we reviewed the structures and performances of SNNs on image classification tasks. The comparisons illustrate that these networks show great capabilities for more complicated problems. Furthermore, the simple learning rules developed for SNNs, such as STDP and R-STDP, can be a potential alternative to replace the backpropagation algorithm used in DNNs.
Learning Options via Compression
Dec 08, 2022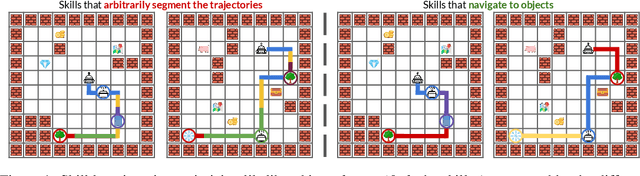
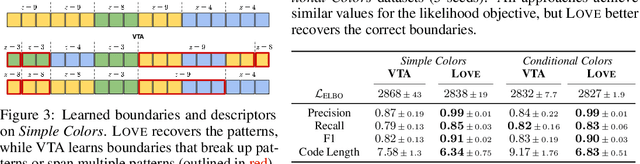
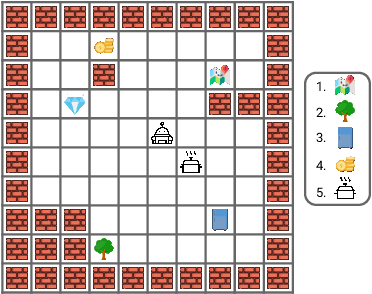
Identifying statistical regularities in solutions to some tasks in multi-task reinforcement learning can accelerate the learning of new tasks. Skill learning offers one way of identifying these regularities by decomposing pre-collected experiences into a sequence of skills. A popular approach to skill learning is maximizing the likelihood of the pre-collected experience with latent variable models, where the latent variables represent the skills. However, there are often many solutions that maximize the likelihood equally well, including degenerate solutions. To address this underspecification, we propose a new objective that combines the maximum likelihood objective with a penalty on the description length of the skills. This penalty incentivizes the skills to maximally extract common structures from the experiences. Empirically, our objective learns skills that solve downstream tasks in fewer samples compared to skills learned from only maximizing likelihood. Further, while most prior works in the offline multi-task setting focus on tasks with low-dimensional observations, our objective can scale to challenging tasks with high-dimensional image observations.
Fresnel Microfacet BRDF: Unification of Polari-Radiometric Surface-Body Reflection
Dec 08, 2022
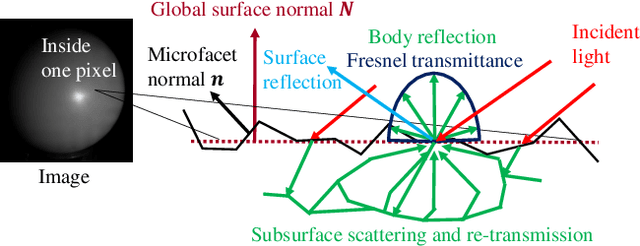
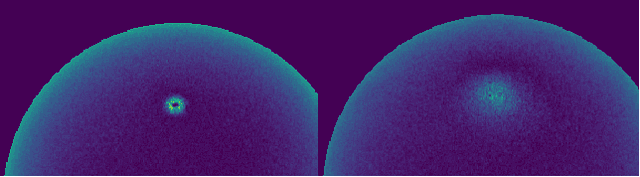
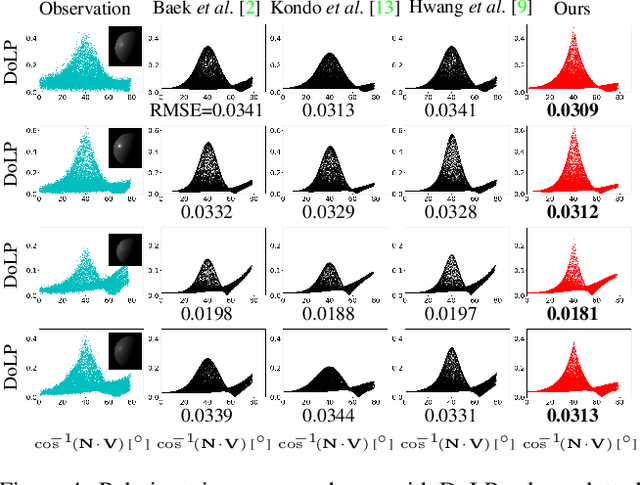
Computer vision applications have heavily relied on the linear combination of Lambertian diffuse and microfacet specular reflection models for representing reflected radiance, which turns out to be physically incompatible and limited in applicability. In this paper, we derive a novel analytical reflectance model, which we refer to as Fresnel Microfacet BRDF model, that is physically accurate and generalizes to various real-world surfaces. Our key idea is to model the Fresnel reflection and transmission of the surface microgeometry with a collection of oriented mirror facets, both for body and surface reflections. We carefully derive the Fresnel reflection and transmission for each microfacet as well as the light transport between them in the subsurface. This physically-grounded modeling also allows us to express the polarimetric behavior of reflected light in addition to its radiometric behavior. That is, FMBRDF unifies not only body and surface reflections but also light reflection in radiometry and polarization and represents them in a single model. Experimental results demonstrate its effectiveness in accuracy, expressive power, and image-based estimation.
Why is Winoground Hard? Investigating Failures in Visuolinguistic Compositionality
Nov 11, 2022
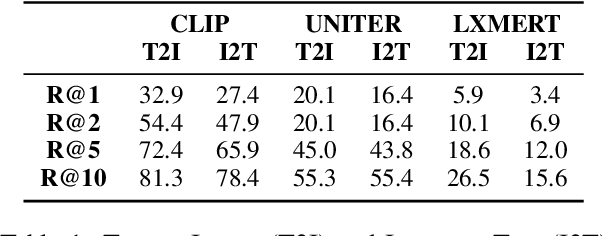
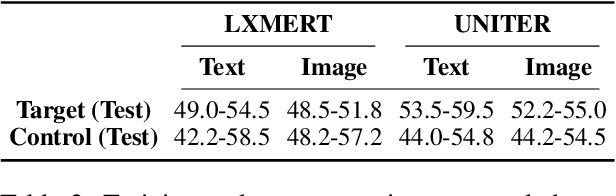
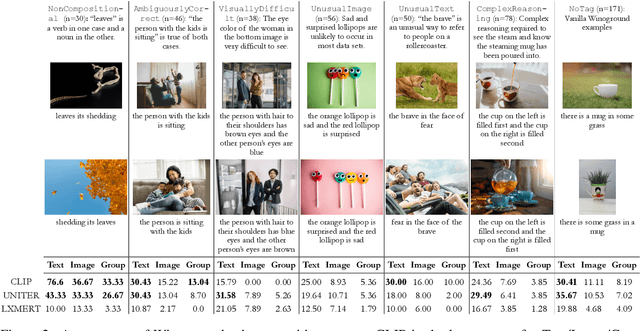
Recent visuolinguistic pre-trained models show promising progress on various end tasks such as image retrieval and video captioning. Yet, they fail miserably on the recently proposed Winoground dataset, which challenges models to match paired images and English captions, with items constructed to overlap lexically but differ in meaning (e.g., "there is a mug in some grass" vs. "there is some grass in a mug"). By annotating the dataset using new fine-grained tags, we show that solving the Winoground task requires not just compositional language understanding, but a host of other abilities like commonsense reasoning or locating small, out-of-focus objects in low-resolution images. In this paper, we identify the dataset's main challenges through a suite of experiments on related tasks (probing task, image retrieval task), data augmentation, and manual inspection of the dataset. Our analysis suggests that a main challenge in visuolinguistic models may lie in fusing visual and textual representations, rather than in compositional language understanding. We release our annotation and code at https://github.com/ajd12342/why-winoground-hard .
Progressive Motion Context Refine Network for Efficient Video Frame Interpolation
Nov 11, 2022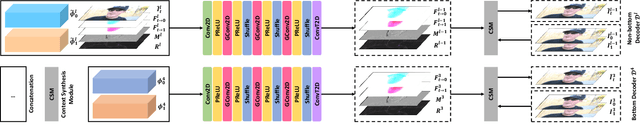
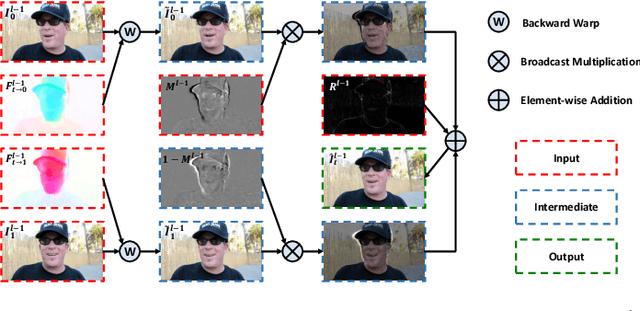

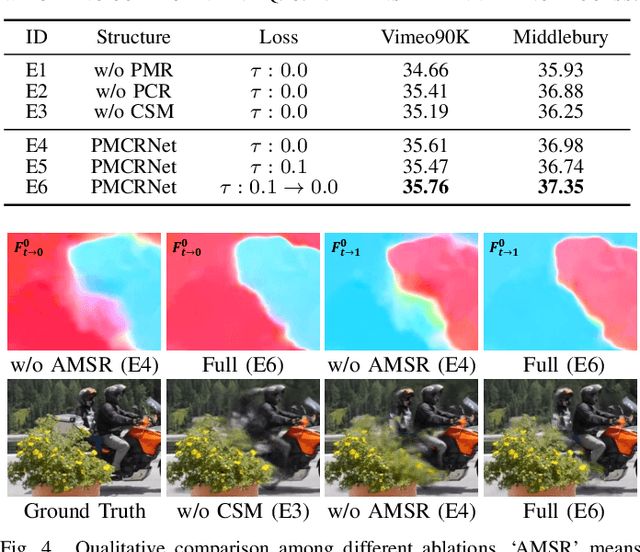
Recently, flow-based frame interpolation methods have achieved great success by first modeling optical flow between target and input frames, and then building synthesis network for target frame generation. However, above cascaded architecture can lead to large model size and inference delay, hindering them from mobile and real-time applications. To solve this problem, we propose a novel Progressive Motion Context Refine Network (PMCRNet) to predict motion fields and image context jointly for higher efficiency. Different from others that directly synthesize target frame from deep feature, we explore to simplify frame interpolation task by borrowing existing texture from adjacent input frames, which means that decoder in each pyramid level of our PMCRNet only needs to update easier intermediate optical flow, occlusion merge mask and image residual. Moreover, we introduce a new annealed multi-scale reconstruction loss to better guide the learning process of this efficient PMCRNet. Experiments on multiple benchmarks show that proposed approaches not only achieve favorable quantitative and qualitative results but also reduces current model size and running time significantly.
Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation
May 27, 2022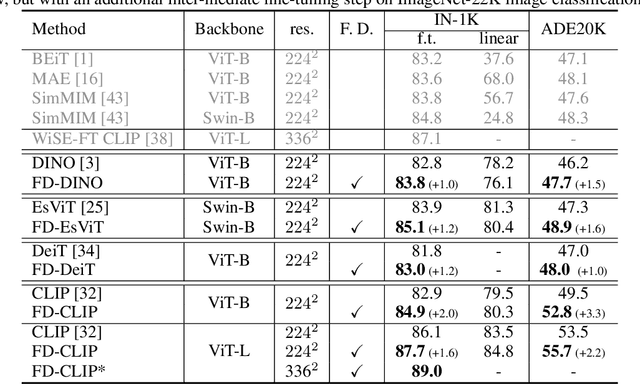
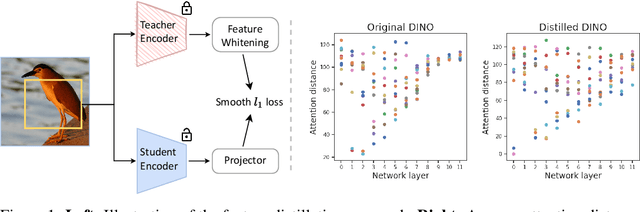
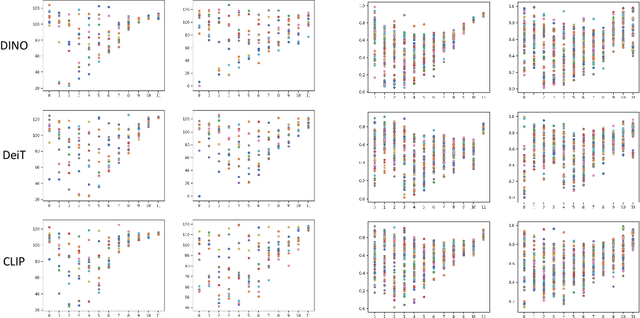
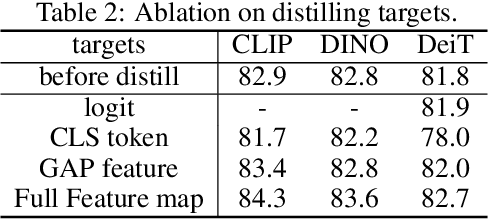
Masked image modeling (MIM) learns representations with remarkably good fine-tuning performances, overshadowing previous prevalent pre-training approaches such as image classification, instance contrastive learning, and image-text alignment. In this paper, we show that the inferior fine-tuning performance of these pre-training approaches can be significantly improved by a simple post-processing in the form of feature distillation (FD). The feature distillation converts the old representations to new representations that have a few desirable properties just like those representations produced by MIM. These properties, which we aggregately refer to as optimization friendliness, are identified and analyzed by a set of attention- and optimization-related diagnosis tools. With these properties, the new representations show strong fine-tuning performance. Specifically, the contrastive self-supervised learning methods are made as competitive in fine-tuning as the state-of-the-art masked image modeling (MIM) algorithms. The CLIP models' fine-tuning performance is also significantly improved, with a CLIP ViT-L model reaching 89.0% top-1 accuracy on ImageNet-1K classification. More importantly, our work provides a way for the future research to focus more effort on the generality and scalability of the learnt representations without being pre-occupied with optimization friendliness since it can be enhanced rather easily. The code will be available at https://github.com/SwinTransformer/Feature-Distillation.
Underwater Image Enhancement Using Pre-trained Transformer
Apr 08, 2022
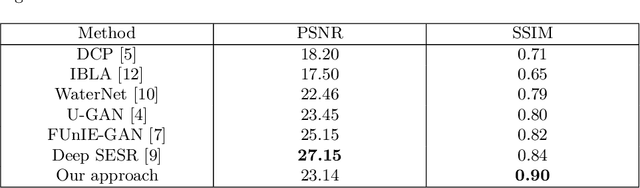
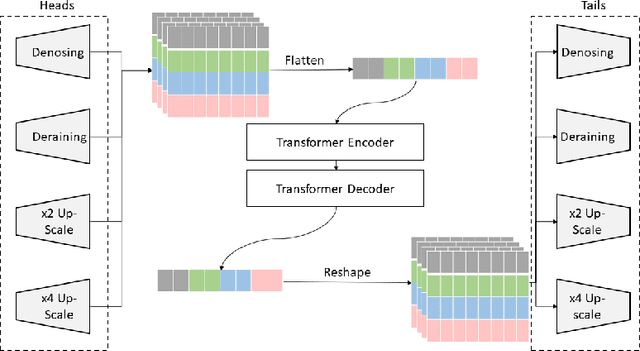
The goal of this work is to apply a denoising image transformer to remove the distortion from underwater images and compare it with other similar approaches. Automatic restoration of underwater images plays an important role since it allows to increase the quality of the images, without the need for more expensive equipment. This is a critical example of the important role of the machine learning algorithms to support marine exploration and monitoring, reducing the need for human intervention like the manual processing of the images, thus saving time, effort, and cost. This paper is the first application of the image transformer-based approach called "Pre-Trained Image Processing Transformer" to underwater images. This approach is tested on the UFO-120 dataset, containing 1500 images with the corresponding clean images.
ShuffleMixer: An Efficient ConvNet for Image Super-Resolution
May 30, 2022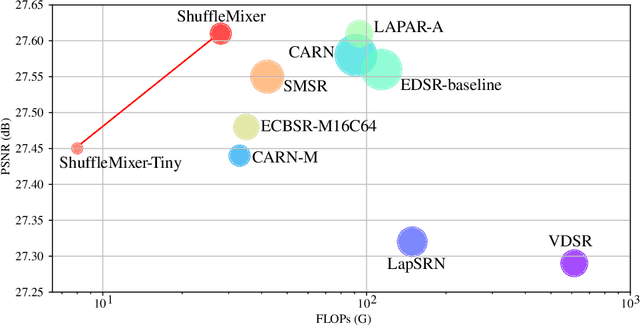
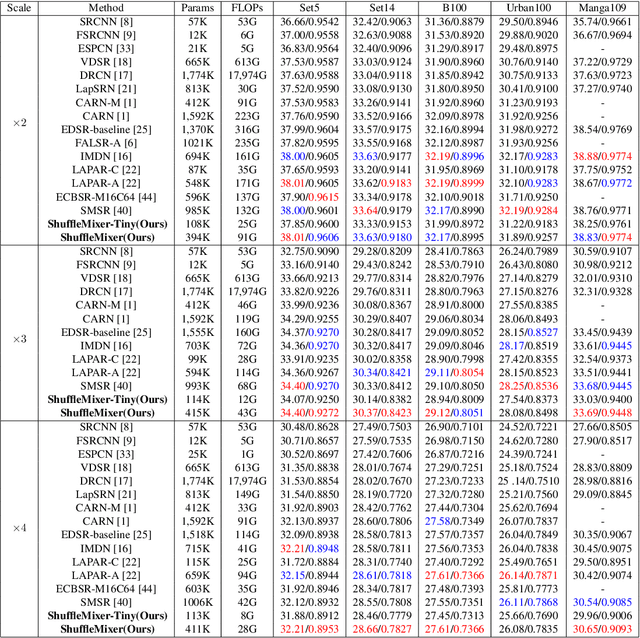
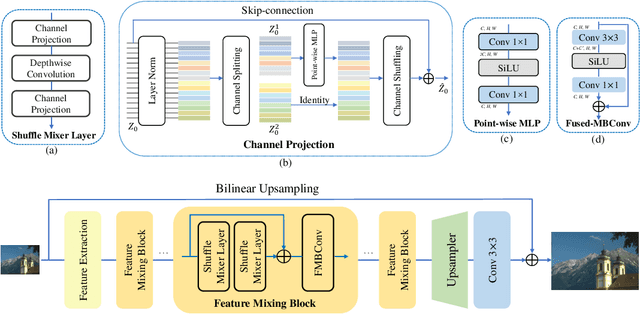
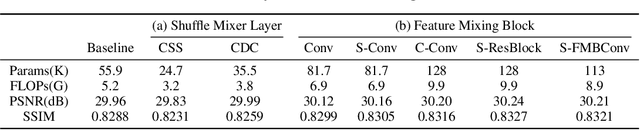
Lightweight and efficiency are critical drivers for the practical application of image super-resolution (SR) algorithms. We propose a simple and effective approach, ShuffleMixer, for lightweight image super-resolution that explores large convolution and channel split-shuffle operation. In contrast to previous SR models that simply stack multiple small kernel convolutions or complex operators to learn representations, we explore a large kernel ConvNet for mobile-friendly SR design. Specifically, we develop a large depth-wise convolution and two projection layers based on channel splitting and shuffling as the basic component to mix features efficiently. Since the contexts of natural images are strongly locally correlated, using large depth-wise convolutions only is insufficient to reconstruct fine details. To overcome this problem while maintaining the efficiency of the proposed module, we introduce Fused-MBConvs into the proposed network to model the local connectivity of different features. Experimental results demonstrate that the proposed ShuffleMixer is about 6x smaller than the state-of-the-art methods in terms of model parameters and FLOPs while achieving competitive performance. In NTIRE 2022, our primary method won the model complexity track of the Efficient Super-Resolution Challenge [23]. The code is available at https://github.com/sunny2109/MobileSR-NTIRE2022.
Relightable Neural Human Assets from Multi-view Gradient Illuminations
Dec 15, 2022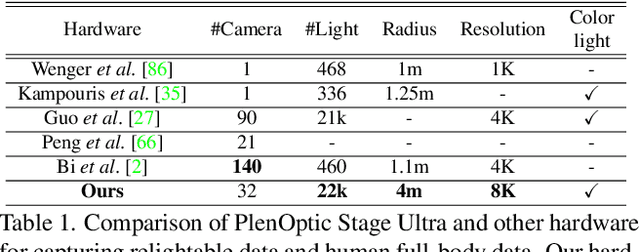

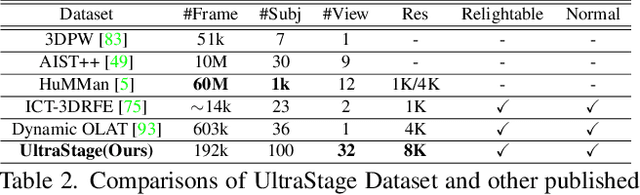
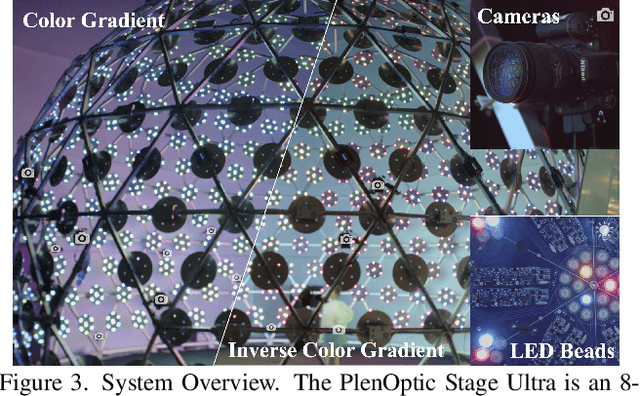
Human modeling and relighting are two fundamental problems in computer vision and graphics, where high-quality datasets can largely facilitate related research. However, most existing human datasets only provide multi-view human images captured under the same illumination. Although valuable for modeling tasks, they are not readily used in relighting problems. To promote research in both fields, in this paper, we present UltraStage, a new 3D human dataset that contains more than 2K high-quality human assets captured under both multi-view and multi-illumination settings. Specifically, for each example, we provide 32 surrounding views illuminated with one white light and two gradient illuminations. In addition to regular multi-view images, gradient illuminations help recover detailed surface normal and spatially-varying material maps, enabling various relighting applications. Inspired by recent advances in neural representation, we further interpret each example into a neural human asset which allows novel view synthesis under arbitrary lighting conditions. We show our neural human assets can achieve extremely high capture performance and are capable of representing fine details such as facial wrinkles and cloth folds. We also validate UltraStage in single image relighting tasks, training neural networks with virtual relighted data from neural assets and demonstrating realistic rendering improvements over prior arts. UltraStage will be publicly available to the community to stimulate significant future developments in various human modeling and rendering tasks.