 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From a Bird's Eye View to See: Joint Camera and Subject Registration without the Camera Calibration
Dec 19, 2022

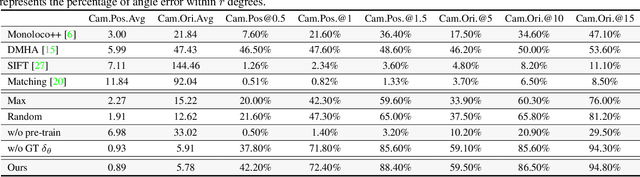
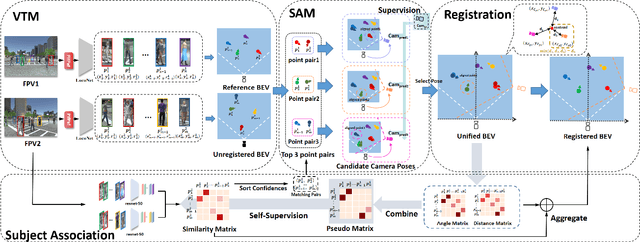
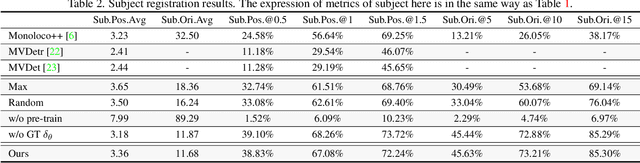
We tackle a new problem of multi-view camera and subject registration in the bird's eye view (BEV) without pre-given camera calibration. This is a very challenging problem since its only input is several RGB images from different first-person views (FPVs) for a multi-person scene, without the BEV image and the calibration of the FPVs, while the output is a unified plane with the localization and orientation of both the subjects and cameras in a BEV. We propose an end-to-end framework solving this problem, whose main idea can be divided into following parts: i) creating a view-transform subject detection module to transform the FPV to a virtual BEV including localization and orientation of each pedestrian, ii) deriving a geometric transformation based method to estimate camera localization and view direction, i.e., the camera registration in a unified BEV, iii) making use of spatial and appearance information to aggregate the subjects into the unified BEV. We collect a new large-scale synthetic dataset with rich annotations for evaluation. The experimental results show the remarkable effectiveness of our proposed method.
LayoutDETR: Detection Transformer Is a Good Multimodal Layout Designer
Dec 19, 2022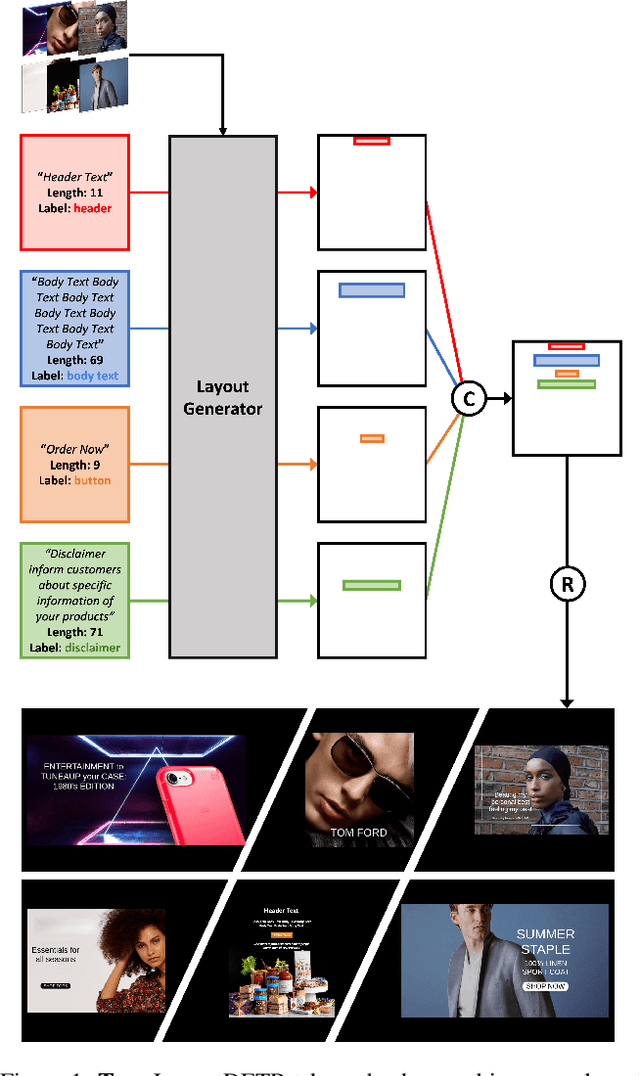
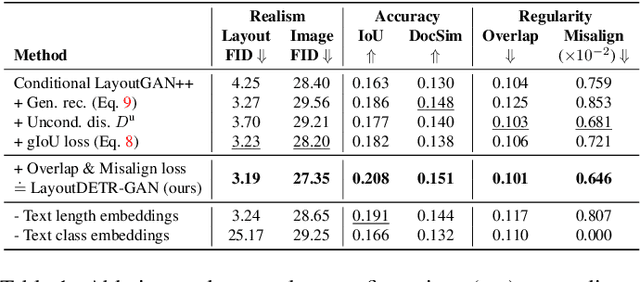
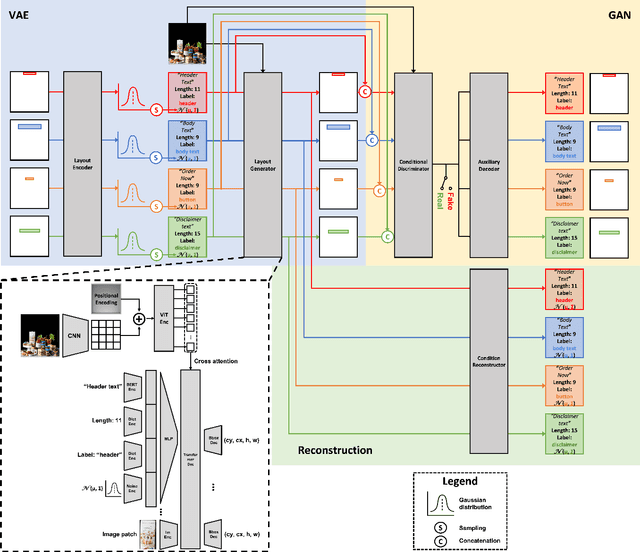
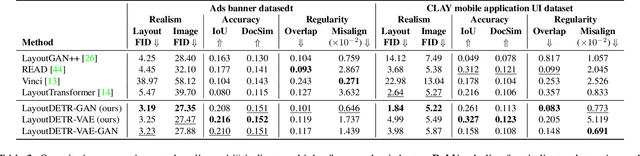
Graphic layout designs play an essential role in visual communication. Yet handcrafting layout designs are skill-demanding, time-consuming, and non-scalable to batch production. Although generative models emerge to make design automation no longer utopian, it remains non-trivial to customize designs that comply with designers' multimodal desires, i.e., constrained by background images and driven by foreground contents. In this study, we propose \textit{LayoutDETR} that inherits the high quality and realism from generative modeling, in the meanwhile reformulating content-aware requirements as a detection problem: we learn to detect in a background image the reasonable locations, scales, and spatial relations for multimodal elements in a layout. Experiments validate that our solution yields new state-of-the-art performance for layout generation on public benchmarks and on our newly-curated ads banner dataset. For practical usage, we build our solution into a graphical system that facilitates user studies. We demonstrate that our designs attract more subjective preference than baselines by significant margins. Our code, models, dataset, graphical system, and demos are available at https://github.com/salesforce/LayoutDETR.
MetaCLUE: Towards Comprehensive Visual Metaphors Research
Dec 19, 2022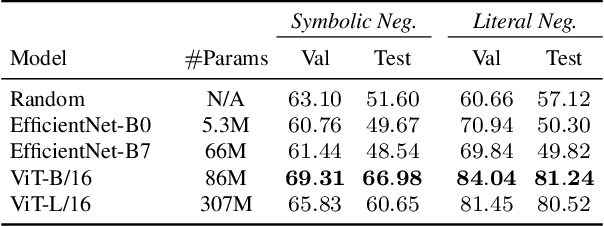


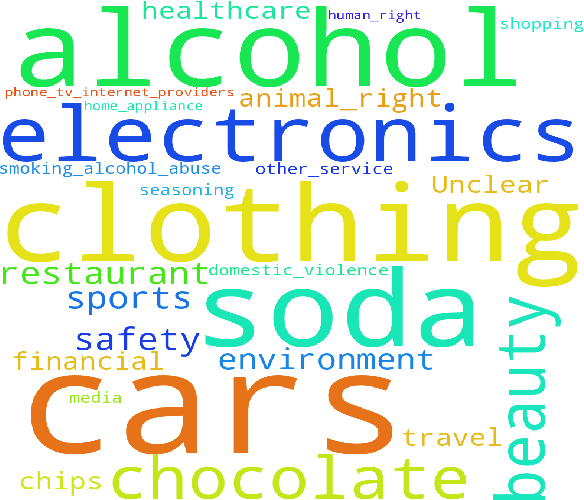
Creativity is an indispensable part of human cognition and also an inherent part of how we make sense of the world. Metaphorical abstraction is fundamental in communicating creative ideas through nuanced relationships between abstract concepts such as feelings. While computer vision benchmarks and approaches predominantly focus on understanding and generating literal interpretations of images, metaphorical comprehension of images remains relatively unexplored. Towards this goal, we introduce MetaCLUE, a set of vision tasks on visual metaphor. We also collect high-quality and rich metaphor annotations (abstract objects, concepts, relationships along with their corresponding object boxes) as there do not exist any datasets that facilitate the evaluation of these tasks. We perform a comprehensive analysis of state-of-the-art models in vision and language based on our annotations, highlighting strengths and weaknesses of current approaches in visual metaphor Classification, Localization, Understanding (retrieval, question answering, captioning) and gEneration (text-to-image synthesis) tasks. We hope this work provides a concrete step towards developing AI systems with human-like creative capabilities.
Deep Active Ensemble Sampling For Image Classification
Oct 11, 2022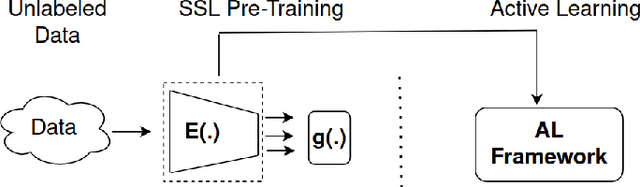
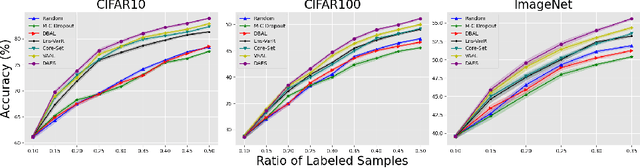
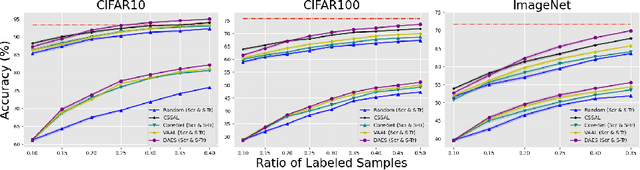
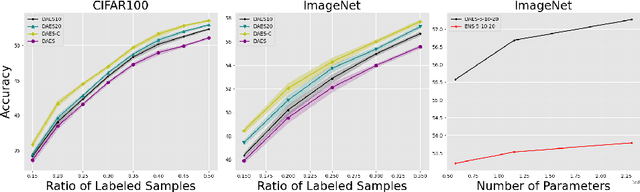
Conventional active learning (AL) frameworks aim to reduce the cost of data annotation by actively requesting the labeling for the most informative data points. However, introducing AL to data hungry deep learning algorithms has been a challenge. Some proposed approaches include uncertainty-based techniques, geometric methods, implicit combination of uncertainty-based and geometric approaches, and more recently, frameworks based on semi/self supervised techniques. In this paper, we address two specific problems in this area. The first is the need for efficient exploitation/exploration trade-off in sample selection in AL. For this, we present an innovative integration of recent progress in both uncertainty-based and geometric frameworks to enable an efficient exploration/exploitation trade-off in sample selection strategy. To this end, we build on a computationally efficient approximate of Thompson sampling with key changes as a posterior estimator for uncertainty representation. Our framework provides two advantages: (1) accurate posterior estimation, and (2) tune-able trade-off between computational overhead and higher accuracy. The second problem is the need for improved training protocols in deep AL. For this, we use ideas from semi/self supervised learning to propose a general approach that is independent of the specific AL technique being used. Taken these together, our framework shows a significant improvement over the state-of-the-art, with results that are comparable to the performance of supervised-learning under the same setting. We show empirical results of our framework, and comparative performance with the state-of-the-art on four datasets, namely, MNIST, CIFAR10, CIFAR100 and ImageNet to establish a new baseline in two different settings.
Zero-shot Visual Commonsense Immorality Prediction
Nov 10, 2022


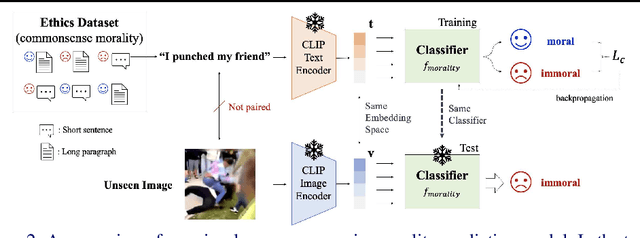
Artificial intelligence is currently powering diverse real-world applications. These applications have shown promising performance, but raise complicated ethical issues, i.e. how to embed ethics to make AI applications behave morally. One way toward moral AI systems is by imitating human prosocial behavior and encouraging some form of good behavior in systems. However, learning such normative ethics (especially from images) is challenging mainly due to a lack of data and labeling complexity. Here, we propose a model that predicts visual commonsense immorality in a zero-shot manner. We train our model with an ETHICS dataset (a pair of text and morality annotation) via a CLIP-based image-text joint embedding. In a testing phase, the immorality of an unseen image is predicted. We evaluate our model with existing moral/immoral image datasets and show fair prediction performance consistent with human intuitions. Further, we create a visual commonsense immorality benchmark with more general and extensive immoral visual contents. Codes and dataset are available at https://github.com/ku-vai/Zero-shot-Visual-Commonsense-Immorality-Prediction. Note that this paper might contain images and descriptions that are offensive in nature.
3D Room Layout Estimation from a Cubemap of Panorama Image via Deep Manhattan Hough Transform
Jul 19, 2022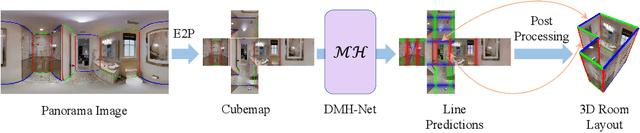
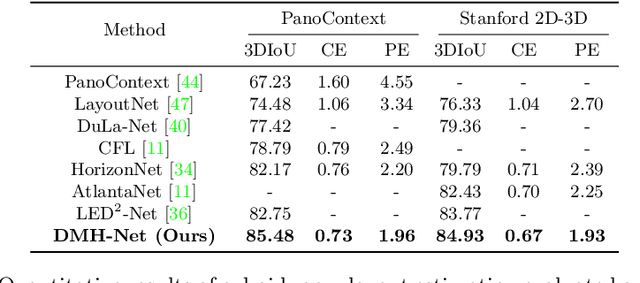
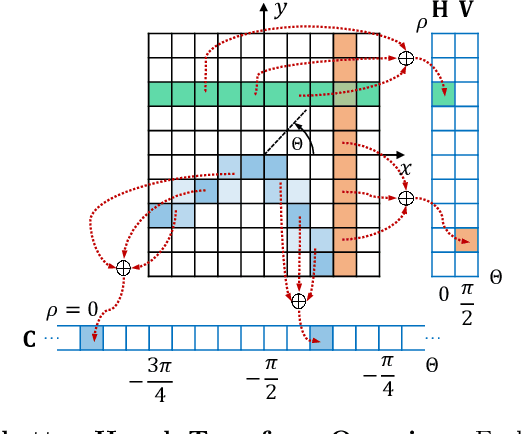
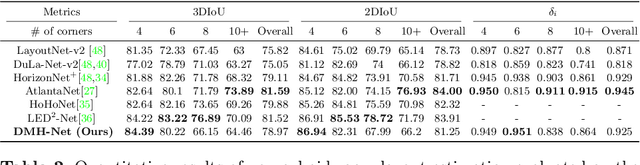
Significant geometric structures can be compactly described by global wireframes in the estimation of 3D room layout from a single panoramic image. Based on this observation, we present an alternative approach to estimate the walls in 3D space by modeling long-range geometric patterns in a learnable Hough Transform block. We transform the image feature from a cubemap tile to the Hough space of a Manhattan world and directly map the feature to the geometric output. The convolutional layers not only learn the local gradient-like line features, but also utilize the global information to successfully predict occluded walls with a simple network structure. Unlike most previous work, the predictions are performed individually on each cubemap tile, and then assembled to get the layout estimation. Experimental results show that we achieve comparable results with recent state-of-the-art in prediction accuracy and performance. Code is available at https://github.com/Starrah/DMH-Net.
Learning Graph Neural Networks for Image Style Transfer
Jul 24, 2022
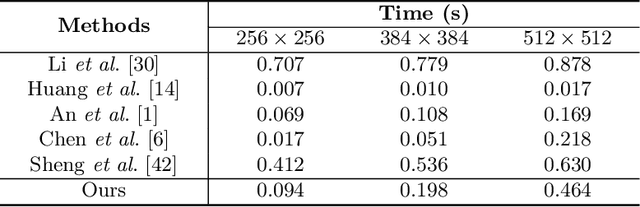
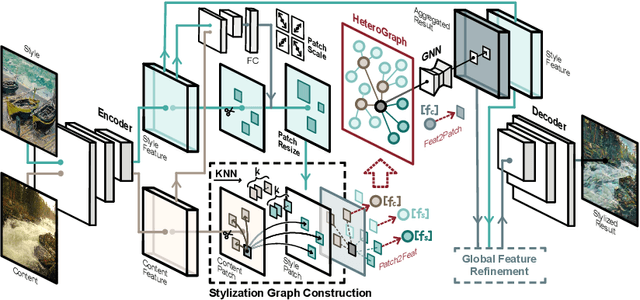

State-of-the-art parametric and non-parametric style transfer approaches are prone to either distorted local style patterns due to global statistics alignment, or unpleasing artifacts resulting from patch mismatching. In this paper, we study a novel semi-parametric neural style transfer framework that alleviates the deficiency of both parametric and non-parametric stylization. The core idea of our approach is to establish accurate and fine-grained content-style correspondences using graph neural networks (GNNs). To this end, we develop an elaborated GNN model with content and style local patches as the graph vertices. The style transfer procedure is then modeled as the attention-based heterogeneous message passing between the style and content nodes in a learnable manner, leading to adaptive many-to-one style-content correlations at the local patch level. In addition, an elaborated deformable graph convolutional operation is introduced for cross-scale style-content matching. Experimental results demonstrate that the proposed semi-parametric image stylization approach yields encouraging results on the challenging style patterns, preserving both global appearance and exquisite details. Furthermore, by controlling the number of edges at the inference stage, the proposed method also triggers novel functionalities like diversified patch-based stylization with a single model.
Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models
Dec 08, 2022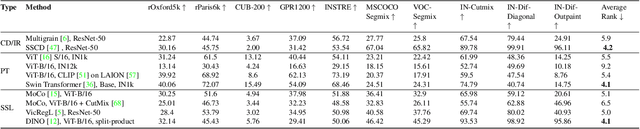


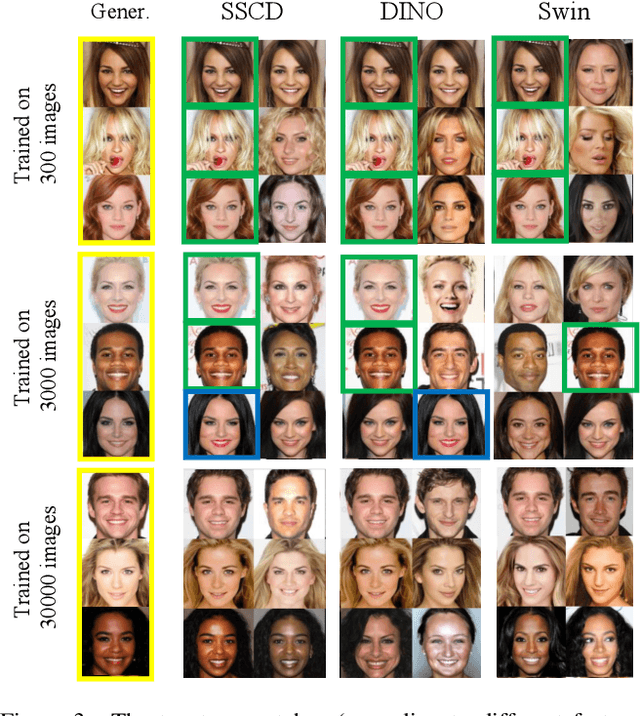
Cutting-edge diffusion models produce images with high quality and customizability, enabling them to be used for commercial art and graphic design purposes. But do diffusion models create unique works of art, or are they stealing content directly from their training sets? In this work, we study image retrieval frameworks that enable us to compare generated images with training samples and detect when content has been replicated. Applying our frameworks to diffusion models trained on multiple datasets including Oxford flowers, Celeb-A, ImageNet, and LAION, we discuss how factors such as training set size impact rates of content replication. We also identify cases where diffusion models, including the popular Stable Diffusion model, blatantly copy from their training data.
NAFSSR: Stereo Image Super-Resolution Using NAFNet
Apr 19, 2022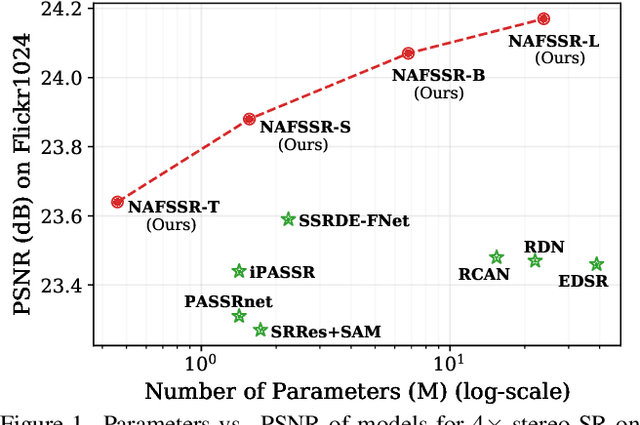
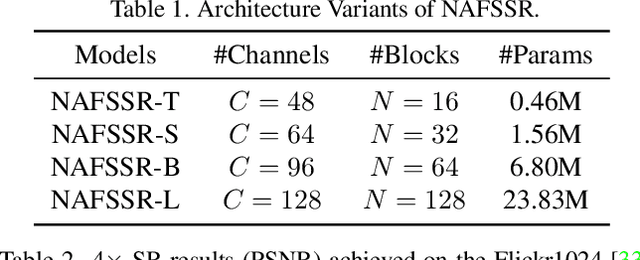
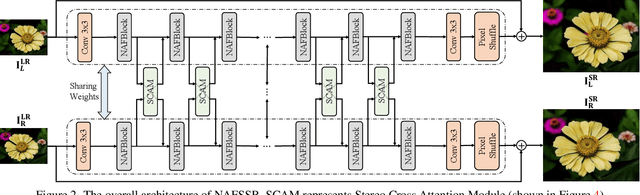
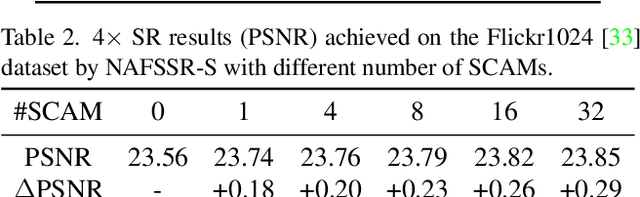
Stereo image super-resolution aims at enhancing the quality of super-resolution results by utilizing the complementary information provided by binocular systems. To obtain reasonable performance, most methods focus on finely designing modules, loss functions, and etc. to exploit information from another viewpoint. This has the side effect of increasing system complexity, making it difficult for researchers to evaluate new ideas and compare methods. This paper inherits a strong and simple image restoration model, NAFNet, for single-view feature extraction and extends it by adding cross attention modules to fuse features between views to adapt to binocular scenarios. The proposed baseline for stereo image super-resolution is noted as NAFSSR. Furthermore, training/testing strategies are proposed to fully exploit the performance of NAFSSR. Extensive experiments demonstrate the effectiveness of our method. In particular, NAFSSR outperforms the state-of-the-art methods on the KITTI 2012, KITTI 2015, Middlebury, and Flickr1024 datasets. With NAFSSR, we won 1st place in the NTIRE 2022 Stereo Image Super-resolution Challenge. Codes and models will be released at https://github.com/megvii-research/NAFNet.
YOLOV: Making Still Image Object Detectors Great at Video Object Detection
Aug 20, 2022
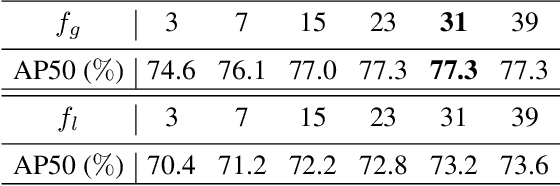
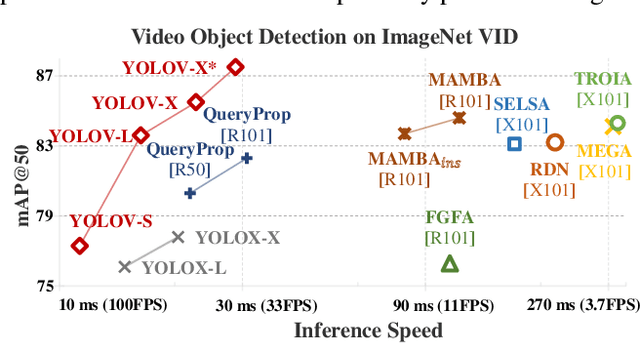

Video object detection (VID) is challenging because of the high variation of object appearance as well as the diverse deterioration in some frames. On the positive side, the detection in a certain frame of a video, compared with in a still image, can draw support from other frames. Hence, how to aggregate features across different frames is pivotal to the VID problem. Most of existing aggregation algorithms are customized for two-stage detectors. But, the detectors in this category are usually computationally expensive due to the two-stage nature. This work proposes a simple yet effective strategy to address the above concerns, which spends marginal overheads with significant gains in accuracy. Concretely, different from the traditional two-stage pipeline, we advocate putting the region-level selection after the one-stage detection to avoid processing massive low-quality candidates. Besides, a novel module is constructed to evaluate the relationship between a target frame and its reference ones, and guide the aggregation. Extensive experiments and ablation studies are conducted to verify the efficacy of our design, and reveal its superiority over other state-of-the-art VID approaches in both effectiveness and efficiency. Our YOLOX-based model can achieve promising performance (e.g., 87.5\% AP50 at over 30 FPS on the ImageNet VID dataset on a single 2080Ti GPU), making it attractive for large-scale or real-time applications. The implementation is simple, the demo code and models have been made available at https://github.com/YuHengsss/YOLOV .