 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Analysis of the Effect of Low-Overhead Lossy Image Compression on the Performance of Visual Crowd Counting for Smart City Applications
Jul 20, 2022


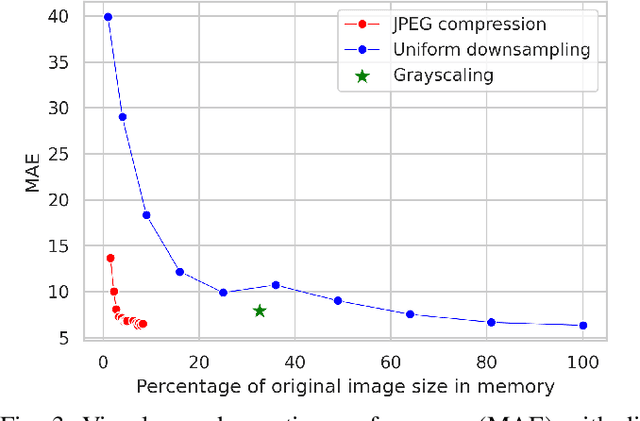
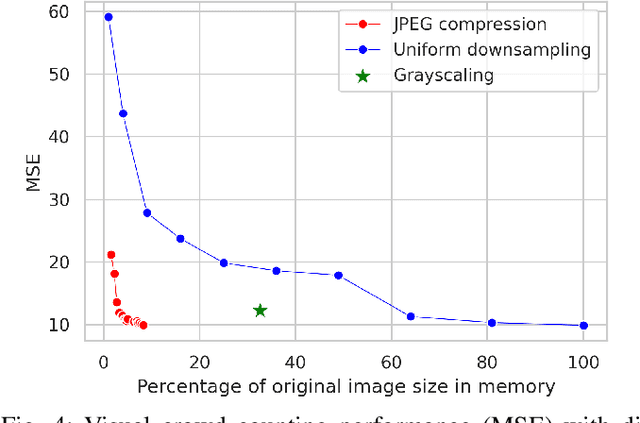
Images and video frames captured by cameras placed throughout smart cities are often transmitted over the network to a server to be processed by deep neural networks for various tasks. Transmission of raw images, i.e., without any form of compression, requires high bandwidth and can lead to congestion issues and delays in transmission. The use of lossy image compression techniques can reduce the quality of the images, leading to accuracy degradation. In this paper, we analyze the effect of applying low-overhead lossy image compression methods on the accuracy of visual crowd counting, and measure the trade-off between bandwidth reduction and the obtained accuracy.
QFF: Quantized Fourier Features for Neural Field Representations
Dec 02, 2022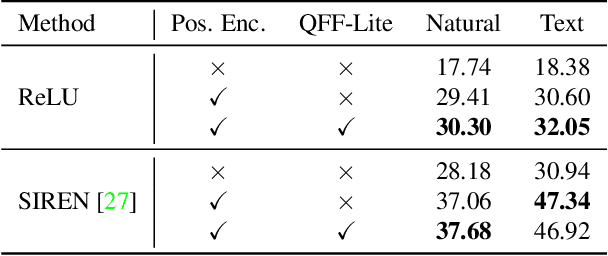
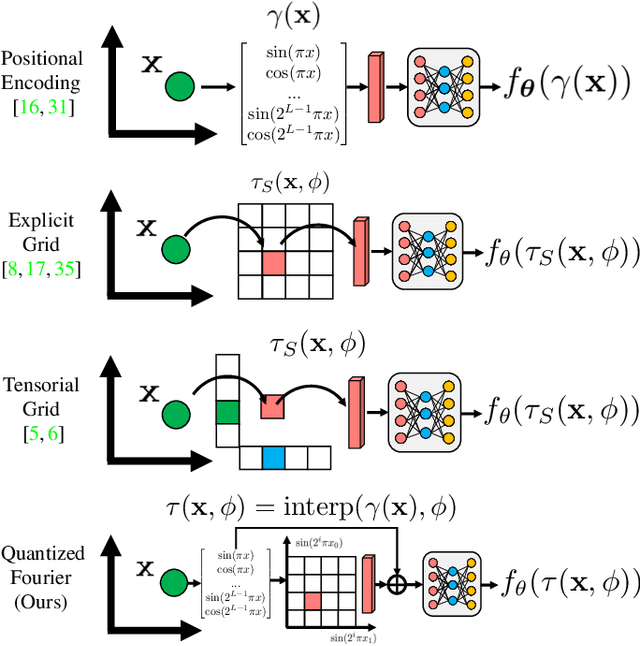
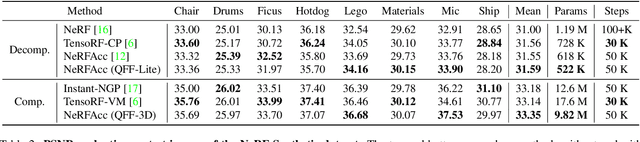
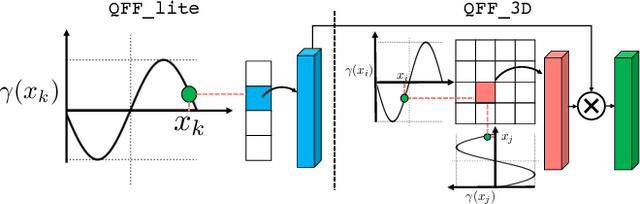
Multilayer perceptrons (MLPs) learn high frequencies slowly. Recent approaches encode features in spatial bins to improve speed of learning details, but at the cost of larger model size and loss of continuity. Instead, we propose to encode features in bins of Fourier features that are commonly used for positional encoding. We call these Quantized Fourier Features (QFF). As a naturally multiresolution and periodic representation, our experiments show that using QFF can result in smaller model size, faster training, and better quality outputs for several applications, including Neural Image Representations (NIR), Neural Radiance Field (NeRF) and Signed Distance Function (SDF) modeling. QFF are easy to code, fast to compute, and serve as a simple drop-in addition to many neural field representations.
Instance-level Heterogeneous Domain Adaptation for Limited-labeled Sketch-to-Photo Retrieval
Nov 26, 2022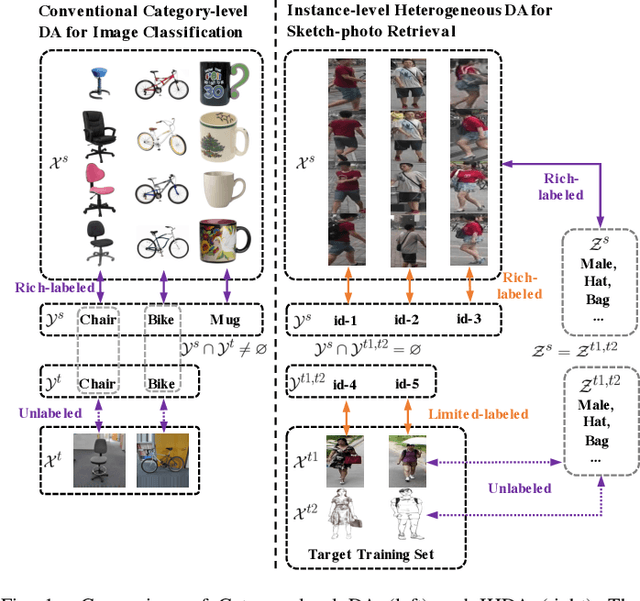
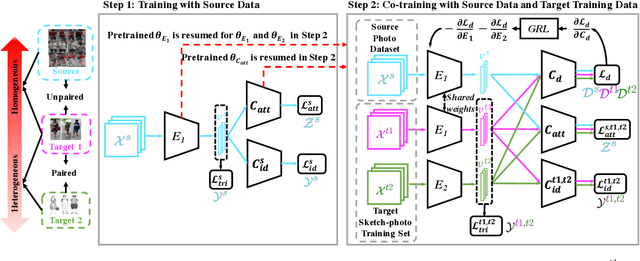

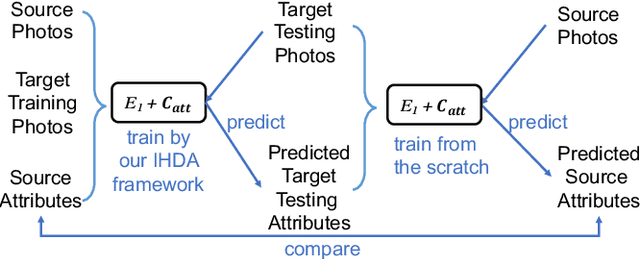
Although sketch-to-photo retrieval has a wide range of applications, it is costly to obtain paired and rich-labeled ground truth. Differently, photo retrieval data is easier to acquire. Therefore, previous works pre-train their models on rich-labeled photo retrieval data (i.e., source domain) and then fine-tune them on the limited-labeled sketch-to-photo retrieval data (i.e., target domain). However, without co-training source and target data, source domain knowledge might be forgotten during the fine-tuning process, while simply co-training them may cause negative transfer due to domain gaps. Moreover, identity label spaces of source data and target data are generally disjoint and therefore conventional category-level Domain Adaptation (DA) is not directly applicable. To address these issues, we propose an Instance-level Heterogeneous Domain Adaptation (IHDA) framework. We apply the fine-tuning strategy for identity label learning, aiming to transfer the instance-level knowledge in an inductive transfer manner. Meanwhile, labeled attributes from the source data are selected to form a shared label space for source and target domains. Guided by shared attributes, DA is utilized to bridge cross-dataset domain gaps and heterogeneous domain gaps, which transfers instance-level knowledge in a transductive transfer manner. Experiments show that our method has set a new state of the art on three sketch-to-photo image retrieval benchmarks without extra annotations, which opens the door to train more effective models on limited-labeled heterogeneous image retrieval tasks. Related codes are available at \url{https://github.com/fandulu/IHDA.
Prompting through Prototype: A Prototype-based Prompt Learning on Pretrained Vision-Language Models
Oct 19, 2022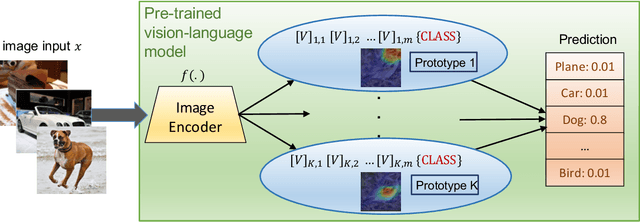
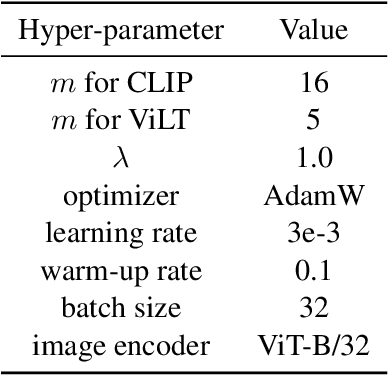
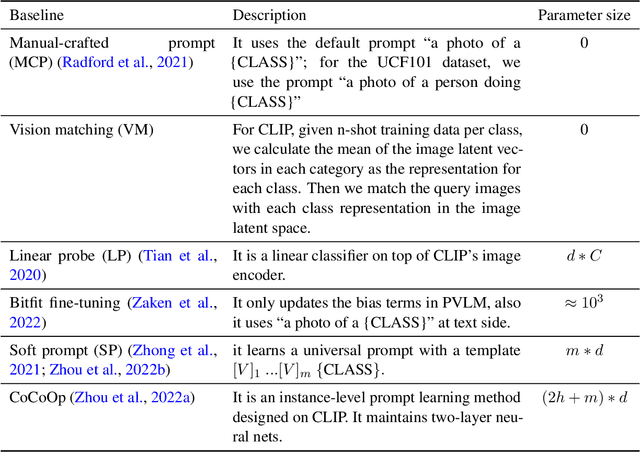
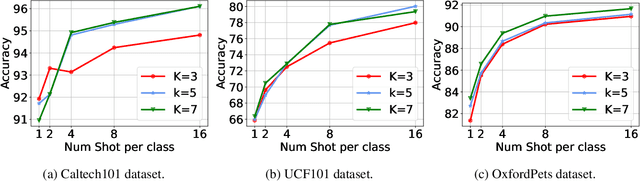
Prompt learning is a new learning paradigm which reformulates downstream tasks as similar pretraining tasks on pretrained models by leveraging textual prompts. Recent works have demonstrated that prompt learning is particularly useful for few-shot learning, where there is limited training data. Depending on the granularity of prompts, those methods can be roughly divided into task-level prompting and instance-level prompting. Task-level prompting methods learn one universal prompt for all input samples, which is efficient but ineffective to capture subtle differences among different classes. Instance-level prompting methods learn a specific prompt for each input, though effective but inefficient. In this work, we develop a novel prototype-based prompt learning method to overcome the above limitations. In particular, we focus on few-shot image recognition tasks on pretrained vision-language models (PVLMs) and develop a method of prompting through prototype (PTP), where we define $K$ image prototypes and $K$ prompt prototypes. In PTP, the image prototype represents a centroid of a certain image cluster in the latent space and a prompt prototype is defined as a soft prompt in the continuous space. The similarity between a query image and an image prototype determines how much this prediction relies on the corresponding prompt prototype. Hence, in PTP, similar images will utilize similar prompting ways. Through extensive experiments on seven real-world benchmarks, we show that PTP is an effective method to leverage the latent knowledge and adaptive to various PVLMs. Moreover, through detailed analysis, we discuss pros and cons for prompt learning and parameter-efficient fine-tuning under the context of few-shot learning.
Language models are good pathologists: using attention-based sequence reduction and text-pretrained transformers for efficient WSI classification
Nov 14, 2022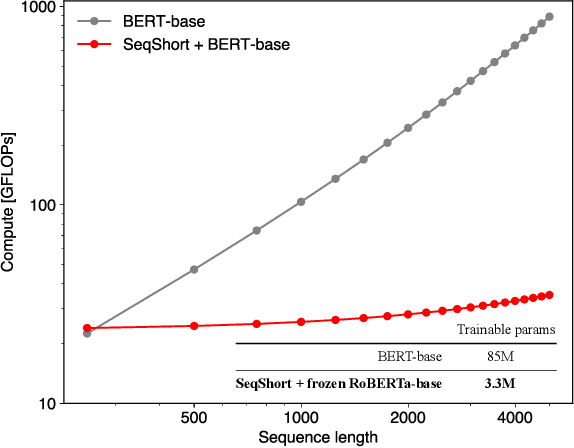
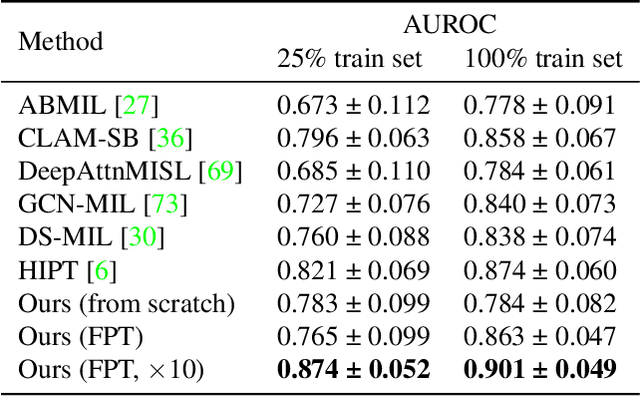
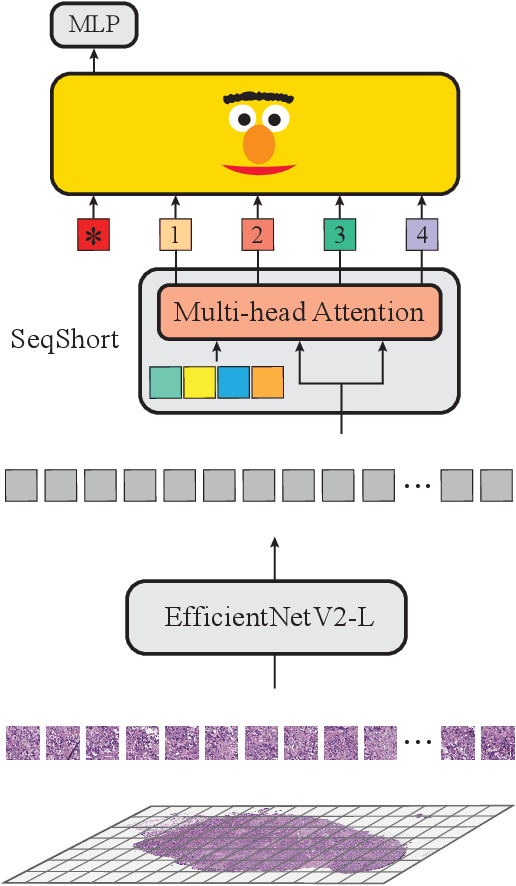

In digital pathology, Whole Slide Image (WSI) analysis is usually formulated as a Multiple Instance Learning (MIL) problem. Although transformer-based architectures have been used for WSI classification, these methods require modifications to adapt them to specific challenges of this type of image data. Despite their power across domains, reference transformer models in classical Computer Vision (CV) and Natural Language Processing (NLP) tasks are not used for pathology slide analysis. In this work we demonstrate the use of standard, frozen, text-pretrained, transformer language models in application to WSI classification. We propose SeqShort, a multi-head attention-based sequence reduction input layer to summarize each WSI in a fixed and short size sequence of instances. This allows us to reduce the computational costs of self-attention on long sequences, and to include positional information that is unavailable in other MIL approaches. We demonstrate the effectiveness of our methods in the task of cancer subtype classification, without the need of designing a WSI-specific transformer or performing in-domain self-supervised pretraining, while keeping a reduced compute budget and number of trainable parameters.
The Lighter The Better: Rethinking Transformers in Medical Image Segmentation Through Adaptive Pruning
Jun 29, 2022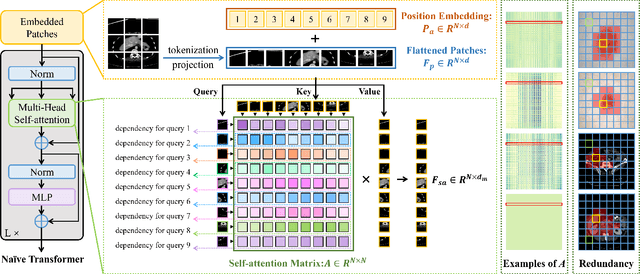
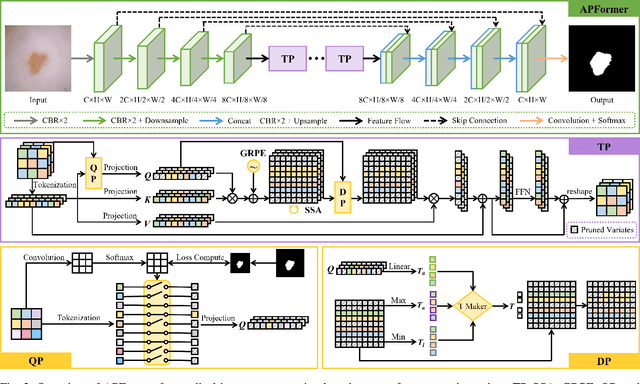

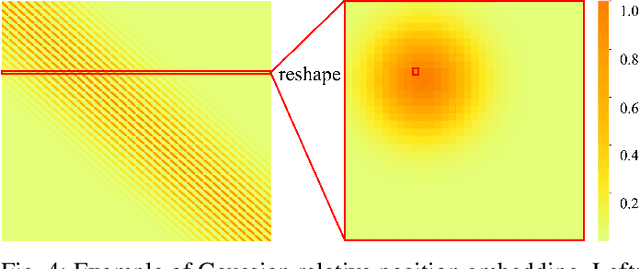
Vision transformers have recently set off a new wave in the field of medical image analysis due to their remarkable performance on various computer vision tasks. However, recent hybrid-/transformer-based approaches mainly focus on the benefits of transformers in capturing long-range dependency while ignoring the issues of their daunting computational complexity, high training costs, and redundant dependency. In this paper, we propose to employ adaptive pruning to transformers for medical image segmentation and propose a lightweight and effective hybrid network APFormer. To our best knowledge, this is the first work on transformer pruning for medical image analysis tasks. The key features of APFormer mainly are self-supervised self-attention (SSA) to improve the convergence of dependency establishment, Gaussian-prior relative position embedding (GRPE) to foster the learning of position information, and adaptive pruning to eliminate redundant computations and perception information. Specifically, SSA and GRPE consider the well-converged dependency distribution and the Gaussian heatmap distribution separately as the prior knowledge of self-attention and position embedding to ease the training of transformers and lay a solid foundation for the following pruning operation. Then, adaptive transformer pruning, both query-wise and dependency-wise, is performed by adjusting the gate control parameters for both complexity reduction and performance improvement. Extensive experiments on two widely-used datasets demonstrate the prominent segmentation performance of APFormer against the state-of-the-art methods with much fewer parameters and lower GFLOPs. More importantly, we prove, through ablation studies, that adaptive pruning can work as a plug-n-play module for performance improvement on other hybrid-/transformer-based methods. Code is available at https://github.com/xianlin7/APFormer.
Efficient Conditionally Invariant Representation Learning
Dec 16, 2022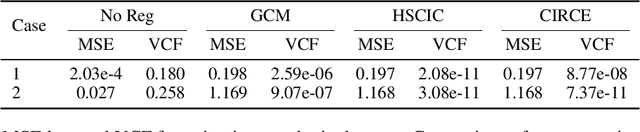
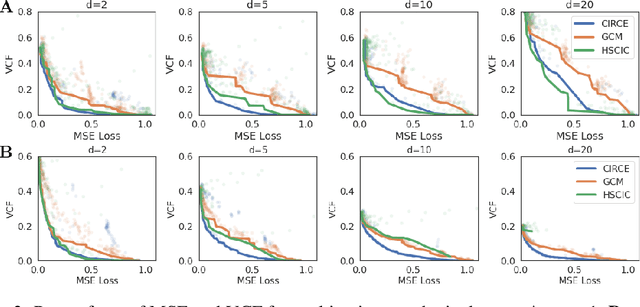

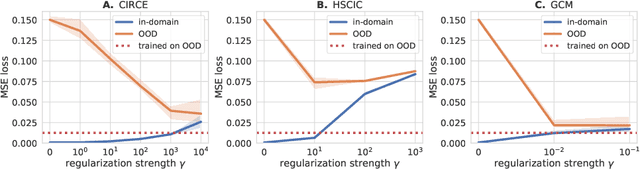
We introduce the Conditional Independence Regression CovariancE (CIRCE), a measure of conditional independence for multivariate continuous-valued variables. CIRCE applies as a regularizer in settings where we wish to learn neural features $\varphi(X)$ of data $X$ to estimate a target $Y$, while being conditionally independent of a distractor $Z$ given $Y$. Both $Z$ and $Y$ are assumed to be continuous-valued but relatively low dimensional, whereas $X$ and its features may be complex and high dimensional. Relevant settings include domain-invariant learning, fairness, and causal learning. The procedure requires just a single ridge regression from $Y$ to kernelized features of $Z$, which can be done in advance. It is then only necessary to enforce independence of $\varphi(X)$ from residuals of this regression, which is possible with attractive estimation properties and consistency guarantees. By contrast, earlier measures of conditional feature dependence require multiple regressions for each step of feature learning, resulting in more severe bias and variance, and greater computational cost. When sufficiently rich features are used, we establish that CIRCE is zero if and only if $\varphi(X) \perp \!\!\! \perp Z \mid Y$. In experiments, we show superior performance to previous methods on challenging benchmarks, including learning conditionally invariant image features.
Geometric Rectification of Creased Document Images based on Isometric Mapping
Dec 16, 2022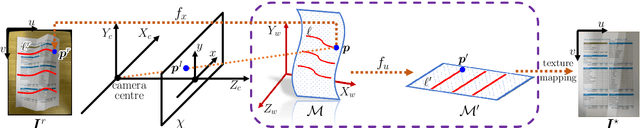

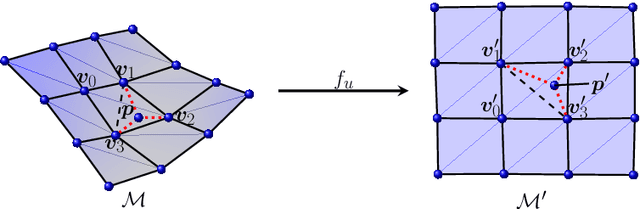
Geometric rectification of images of distorted documents finds wide applications in document digitization and Optical Character Recognition (OCR). Although smoothly curved deformations have been widely investigated by many works, the most challenging distortions, e.g. complex creases and large foldings, have not been studied in particular. The performance of existing approaches, when applied to largely creased or folded documents, is far from satisfying, leaving substantial room for improvement. To tackle this task, knowledge about document rectification should be incorporated into the computation, among which the developability of 3D document models and particular textural features in the images, such as straight lines, are the most essential ones. For this purpose, we propose a general framework of document image rectification in which a computational isometric mapping model is utilized for expressing a 3D document model and its flattening in the plane. Based on this framework, both model developability and textural features are considered in the computation. The experiments and comparisons to the state-of-the-art approaches demonstrated the effectiveness and outstanding performance of the proposed method. Our method is also flexible in that the rectification results can be enhanced by any other methods that extract high-quality feature lines in the images.
Feature Dropout: Revisiting the Role of Augmentations in Contrastive Learning
Dec 16, 2022


What role do augmentations play in contrastive learning? Recent work suggests that good augmentations are label-preserving with respect to a specific downstream task. We complicate this picture by showing that label-destroying augmentations can be useful in the foundation model setting, where the goal is to learn diverse, general-purpose representations for multiple downstream tasks. We perform contrastive learning experiments on a range of image and audio datasets with multiple downstream tasks (e.g. for digits superimposed on photographs, predicting the class of one vs. the other). We find that Viewmaker Networks, a recently proposed model for learning augmentations for contrastive learning, produce label-destroying augmentations that stochastically destroy features needed for different downstream tasks. These augmentations are interpretable (e.g. altering shapes, digits, or letters added to images) and surprisingly often result in better performance compared to expert-designed augmentations, despite not preserving label information. To support our empirical results, we theoretically analyze a simple contrastive learning setting with a linear model. In this setting, label-destroying augmentations are crucial for preventing one set of features from suppressing the learning of features useful for another downstream task. Our results highlight the need for analyzing the interaction between multiple downstream tasks when trying to explain the success of foundation models.
UVCGAN: UNet Vision Transformer cycle-consistent GAN for unpaired image-to-image translation
Mar 04, 2022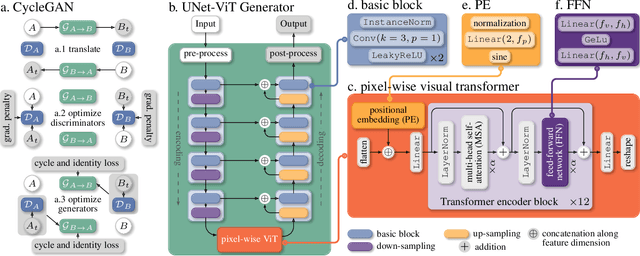


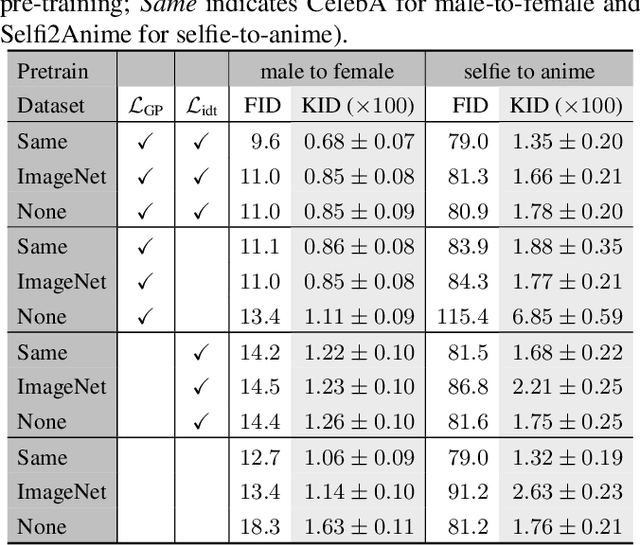
Image-to-image translation has broad applications in art, design, and scientific simulations. The original CycleGAN model emphasizes one-to-one mapping via a cycle-consistent loss, while more recent works promote one-to-many mapping to boost the diversity of the translated images. With scientific simulation and one-to-one needs in mind, this work examines if equipping CycleGAN with a vision transformer (ViT) and employing advanced generative adversarial network (GAN) training techniques can achieve better performance. The resulting UNet ViT Cycle-consistent GAN (UVCGAN) model is compared with previous best-performing models on open benchmark image-to-image translation datasets, Selfie2Anime and CelebA. UVCGAN performs better and retains a strong correlation between the original and translated images. An accompanying ablation study shows that the gradient penalty and BERT-like pre-training also contribute to the improvement.~To promote reproducibility and open science, the source code, hyperparameter configurations, and pre-trained model will be made available at: https://github.com/LS4GAN/uvcga.