 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Temporal Output Discrepancy for Loss Estimation-based Active Learning
Dec 20, 2022
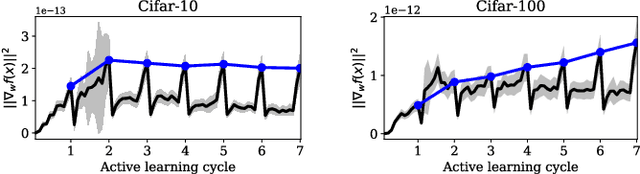
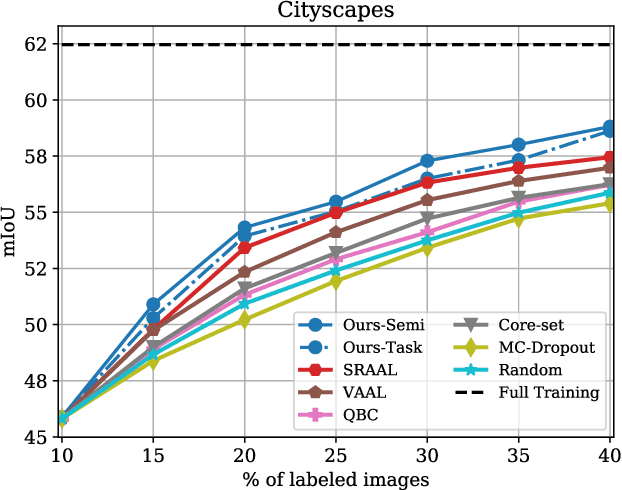
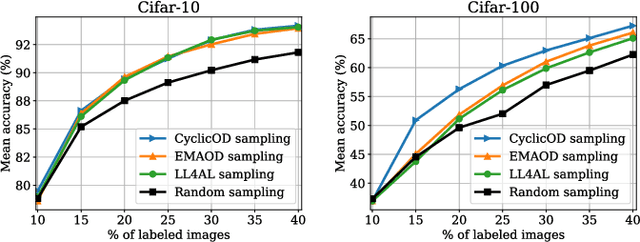
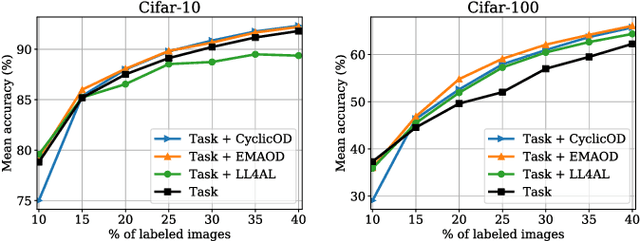
While deep learning succeeds in a wide range of tasks, it highly depends on the massive collection of annotated data which is expensive and time-consuming. To lower the cost of data annotation, active learning has been proposed to interactively query an oracle to annotate a small proportion of informative samples in an unlabeled dataset. Inspired by the fact that the samples with higher loss are usually more informative to the model than the samples with lower loss, in this paper we present a novel deep active learning approach that queries the oracle for data annotation when the unlabeled sample is believed to incorporate high loss. The core of our approach is a measurement Temporal Output Discrepancy (TOD) that estimates the sample loss by evaluating the discrepancy of outputs given by models at different optimization steps. Our theoretical investigation shows that TOD lower-bounds the accumulated sample loss thus it can be used to select informative unlabeled samples. On basis of TOD, we further develop an effective unlabeled data sampling strategy as well as an unsupervised learning criterion for active learning. Due to the simplicity of TOD, our methods are efficient, flexible, and task-agnostic. Extensive experimental results demonstrate that our approach achieves superior performances than the state-of-the-art active learning methods on image classification and semantic segmentation tasks. In addition, we show that TOD can be utilized to select the best model of potentially the highest testing accuracy from a pool of candidate models.
Calibrating Deep Neural Networks using Explicit Regularisation and Dynamic Data Pruning
Dec 20, 2022
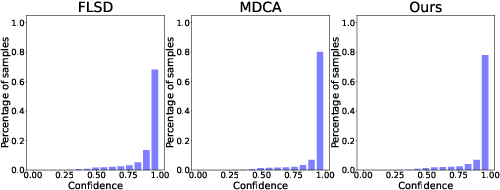
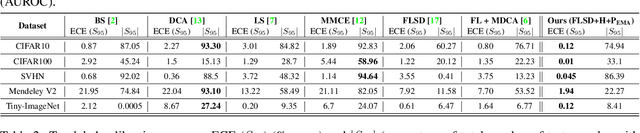

Deep neural networks (DNN) are prone to miscalibrated predictions, often exhibiting a mismatch between the predicted output and the associated confidence scores. Contemporary model calibration techniques mitigate the problem of overconfident predictions by pushing down the confidence of the winning class while increasing the confidence of the remaining classes across all test samples. However, from a deployment perspective, an ideal model is desired to (i) generate well-calibrated predictions for high-confidence samples with predicted probability say >0.95, and (ii) generate a higher proportion of legitimate high-confidence samples. To this end, we propose a novel regularization technique that can be used with classification losses, leading to state-of-the-art calibrated predictions at test time; From a deployment standpoint in safety-critical applications, only high-confidence samples from a well-calibrated model are of interest, as the remaining samples have to undergo manual inspection. Predictive confidence reduction of these potentially ``high-confidence samples'' is a downside of existing calibration approaches. We mitigate this by proposing a dynamic train-time data pruning strategy that prunes low-confidence samples every few epochs, providing an increase in "confident yet calibrated samples". We demonstrate state-of-the-art calibration performance across image classification benchmarks, reducing training time without much compromise in accuracy. We provide insights into why our dynamic pruning strategy that prunes low-confidence training samples leads to an increase in high-confidence samples at test time.
CHAIRS: Towards Full-Body Articulated Human-Object Interaction
Dec 20, 2022

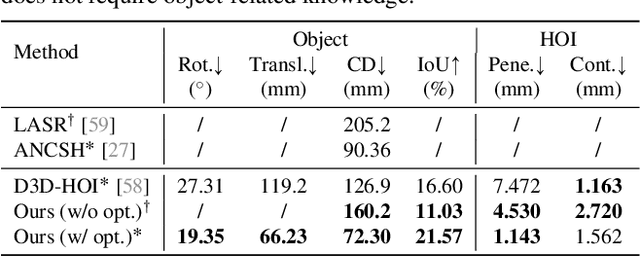
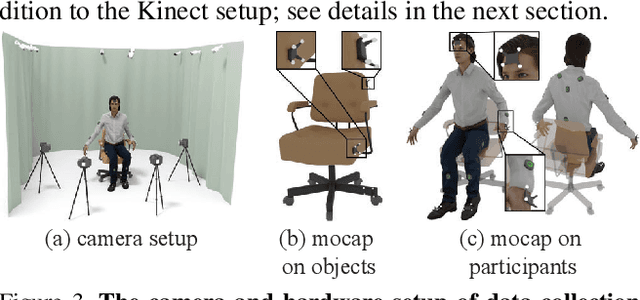
Fine-grained capturing of 3D HOI boosts human activity understanding and facilitates downstream visual tasks, including action recognition, holistic scene reconstruction, and human motion synthesis. Despite its significance, existing works mostly assume that humans interact with rigid objects using only a few body parts, limiting their scope. In this paper, we address the challenging problem of f-AHOI, wherein the whole human bodies interact with articulated objects, whose parts are connected by movable joints. We present CHAIRS, a large-scale motion-captured f-AHOI dataset, consisting of 16.2 hours of versatile interactions between 46 participants and 81 articulated and rigid sittable objects. CHAIRS provides 3D meshes of both humans and articulated objects during the entire interactive process, as well as realistic and physically plausible full-body interactions. We show the value of CHAIRS with object pose estimation. By learning the geometrical relationships in HOI, we devise the very first model that leverage human pose estimation to tackle the estimation of articulated object poses and shapes during whole-body interactions. Given an image and an estimated human pose, our model first reconstructs the pose and shape of the object, then optimizes the reconstruction according to a learned interaction prior. Under both evaluation settings (e.g., with or without the knowledge of objects' geometries/structures), our model significantly outperforms baselines. We hope CHAIRS will promote the community towards finer-grained interaction understanding. We will make the data/code publicly available.
OBMO: One Bounding Box Multiple Objects for Monocular 3D Object Detection
Dec 20, 2022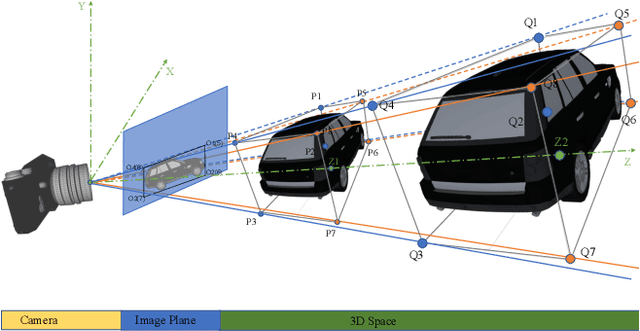
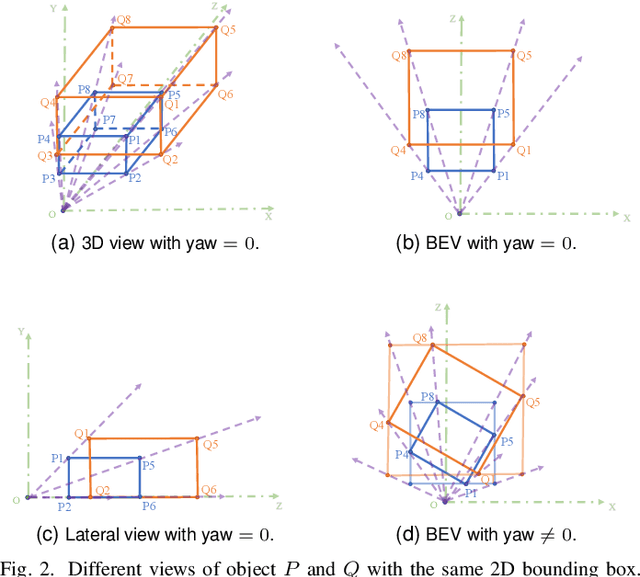
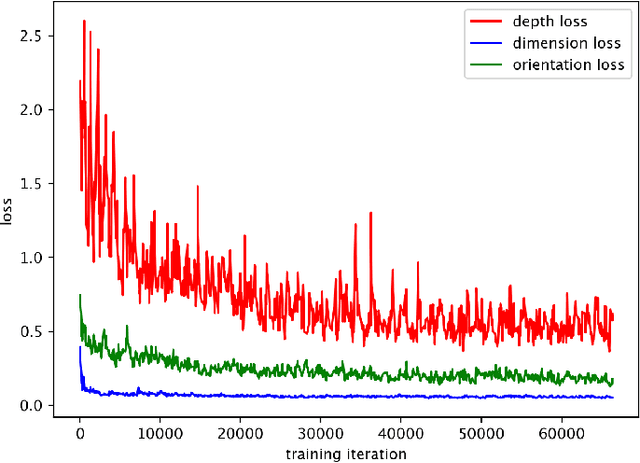
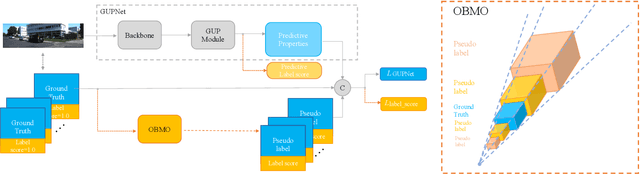
Compared to typical multi-sensor systems, monocular 3D object detection has attracted much attention due to its simple configuration. However, there is still a significant gap between LiDAR-based and monocular-based methods. In this paper, we find that the ill-posed nature of monocular imagery can lead to depth ambiguity. Specifically, objects with different depths can appear with the same bounding boxes and similar visual features in the 2D image. Unfortunately, the network cannot accurately distinguish different depths from such non-discriminative visual features, resulting in unstable depth training. To facilitate depth learning, we propose a simple yet effective plug-and-play module, One Bounding Box Multiple Objects (OBMO). Concretely, we add a set of suitable pseudo labels by shifting the 3D bounding box along the viewing frustum. To constrain the pseudo-3D labels to be reasonable, we carefully design two label scoring strategies to represent their quality. In contrast to the original hard depth labels, such soft pseudo labels with quality scores allow the network to learn a reasonable depth range, boosting training stability and thus improving final performance. Extensive experiments on KITTI and Waymo benchmarks show that our method significantly improves state-of-the-art monocular 3D detectors by a significant margin (The improvements under the moderate setting on KITTI validation set are $\mathbf{1.82\sim 10.91\%}$ mAP in BEV and $\mathbf{1.18\sim 9.36\%}$ mAP in 3D}. Codes have been released at https://github.com/mrsempress/OBMO.
Ultra-fast image categorization in vivo and in silico
May 12, 2022
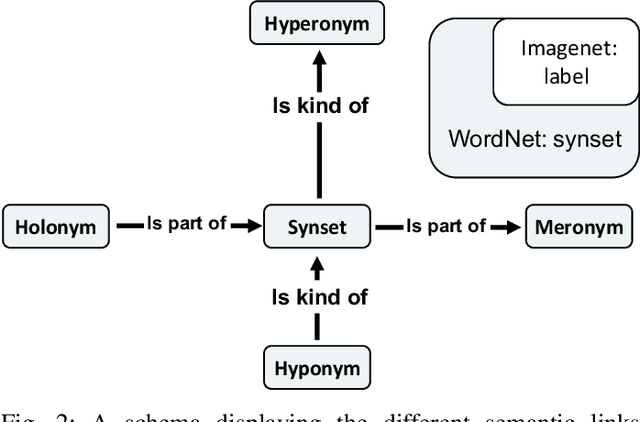
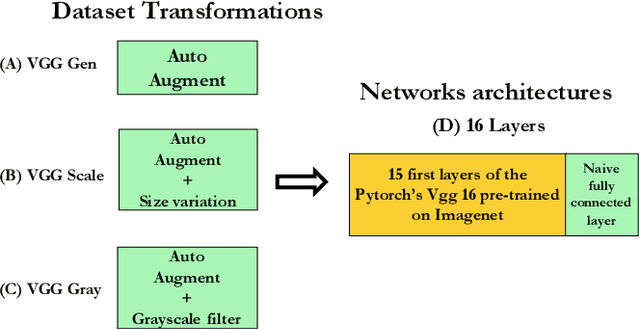
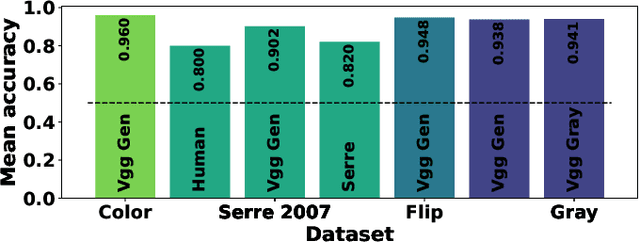
Humans are able to robustly categorize images and can, for instance, detect the presence of an animal in a briefly flashed image in as little as 120 ms. Initially inspired by neuroscience, deep-learning algorithms literally bloomed up in the last decade such that the accuracy of machines is at present superior to humans for visual recognition tasks. However, these artificial networks are usually trained and evaluated on very specific tasks, for instance on the 1000 separate categories of ImageNet. In that regard, biological visual systems are more flexible and efficient compared to artificial systems on generic ecological tasks. In order to deepen this comparison, we re-trained the standard VGG Convolutional Neural Network (CNN) on two independent tasks which are ecologically relevant for humans: one task defined as detecting the presence of an animal and the other as detecting the presence of an artifact. We show that retraining the network achieves human-like performance level which is reported in psychophysical tasks. We also compare the accuracy of the detection on an image-by-image basis. This showed in particular that the two models perform better when combining their outputs. Indeed, animals (e.g. lions) tend to be less present in photographs containing artifacts (e.g. buildings). These re-trained models could reproduce some unexpected behavioral observations from humans psychophysics such as the robustness to rotations (e.g. upside-down or slanted image) or to a grayscale transformation.
A Survey of Automated Data Augmentation Algorithms for Deep Learning-based Image Classication Tasks
Jun 14, 2022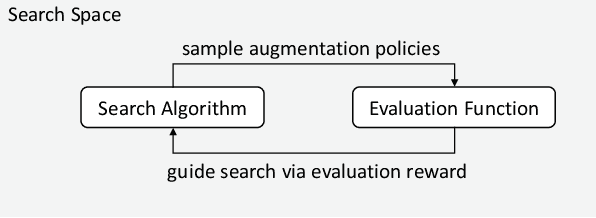
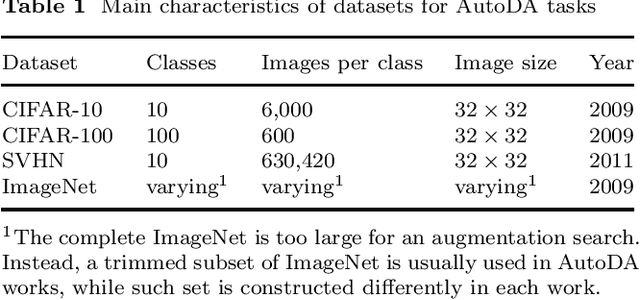
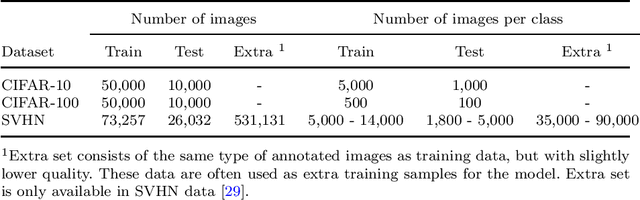
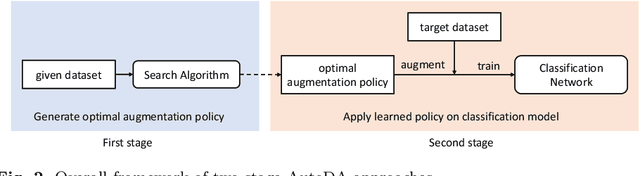
In recent years, one of the most popular techniques in the computer vision community has been the deep learning technique. As a data-driven technique, deep model requires enormous amounts of accurately labelled training data, which is often inaccessible in many real-world applications. A data-space solution is Data Augmentation (DA), that can artificially generate new images out of original samples. Image augmentation strategies can vary by dataset, as different data types might require different augmentations to facilitate model training. However, the design of DA policies has been largely decided by the human experts with domain knowledge, which is considered to be highly subjective and error-prone. To mitigate such problem, a novel direction is to automatically learn the image augmentation policies from the given dataset using Automated Data Augmentation (AutoDA) techniques. The goal of AutoDA models is to find the optimal DA policies that can maximize the model performance gains. This survey discusses the underlying reasons of the emergence of AutoDA technology from the perspective of image classification. We identify three key components of a standard AutoDA model: a search space, a search algorithm and an evaluation function. Based on their architecture, we provide a systematic taxonomy of existing image AutoDA approaches. This paper presents the major works in AutoDA field, discussing their pros and cons, and proposing several potential directions for future improvements.
This changes to that : Combining causal and non-causal explanations to generate disease progression in capsule endoscopy
Dec 05, 2022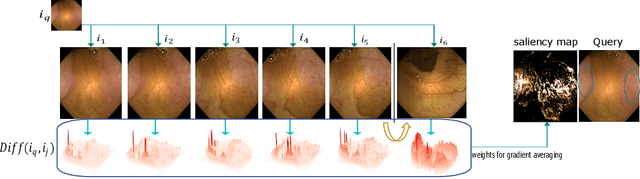
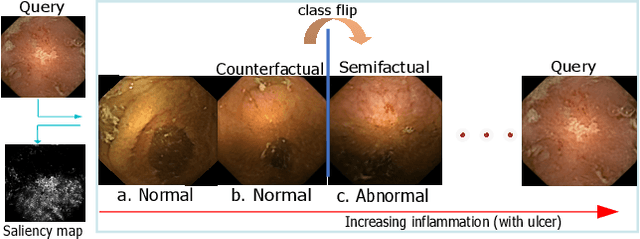
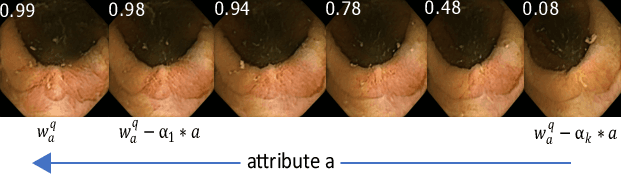
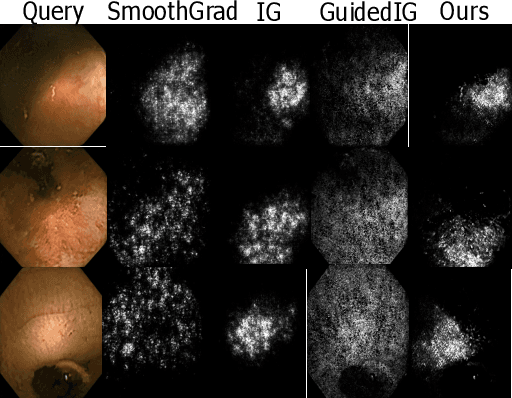
Due to the unequivocal need for understanding the decision processes of deep learning networks, both modal-dependent and model-agnostic techniques have become very popular. Although both of these ideas provide transparency for automated decision making, most methodologies focus on either using the modal-gradients (model-dependent) or ignoring the model internal states and reasoning with a model's behavior/outcome (model-agnostic) to instances. In this work, we propose a unified explanation approach that given an instance combines both model-dependent and agnostic explanations to produce an explanation set. The generated explanations are not only consistent in the neighborhood of a sample but can highlight causal relationships between image content and the outcome. We use Wireless Capsule Endoscopy (WCE) domain to illustrate the effectiveness of our explanations. The saliency maps generated by our approach are comparable or better on the softmax information score.
OutCast: Outdoor Single-image Relighting with Cast Shadows
Apr 20, 2022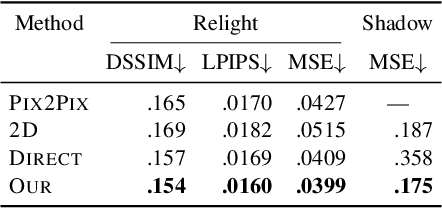
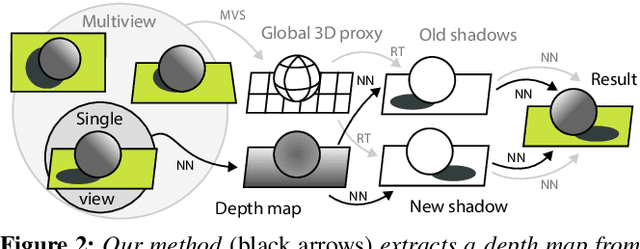
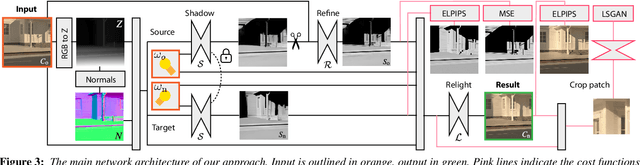
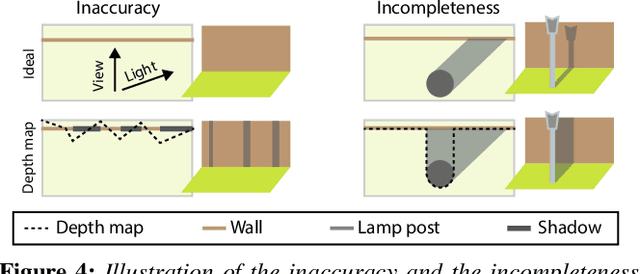
We propose a relighting method for outdoor images. Our method mainly focuses on predicting cast shadows in arbitrary novel lighting directions from a single image while also accounting for shading and global effects such the sun light color and clouds. Previous solutions for this problem rely on reconstructing occluder geometry, e.g. using multi-view stereo, which requires many images of the scene. Instead, in this work we make use of a noisy off-the-shelf single-image depth map estimation as a source of geometry. Whilst this can be a good guide for some lighting effects, the resulting depth map quality is insufficient for directly ray-tracing the shadows. Addressing this, we propose a learned image space ray-marching layer that converts the approximate depth map into a deep 3D representation that is fused into occlusion queries using a learned traversal. Our proposed method achieves, for the first time, state-of-the-art relighting results, with only a single image as input. For supplementary material visit our project page at: https://dgriffiths.uk/outcast.
Three-dimensional Microstructural Image Synthesis from 2D Backscattered Electron Image of Cement Paste
Apr 04, 2022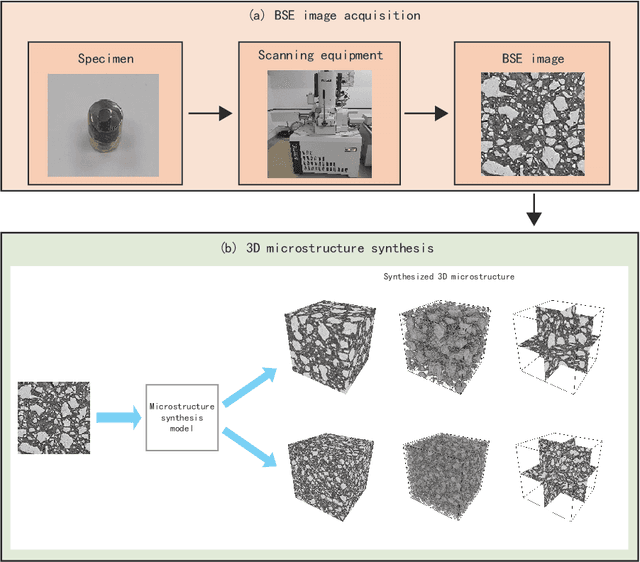
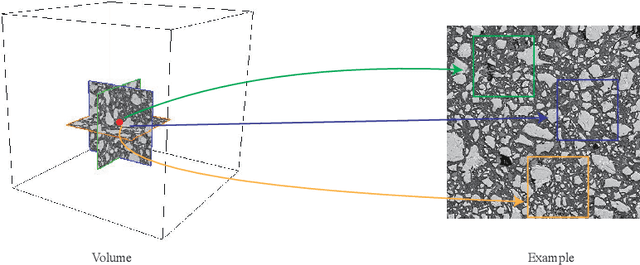
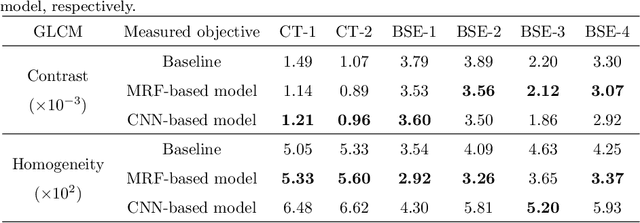
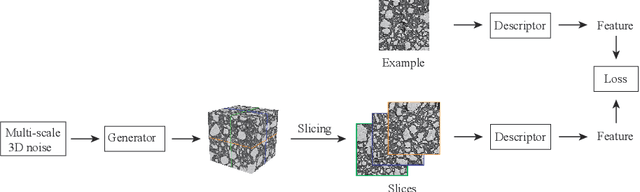
The microstructure is significant for exploring the physical properties of hardened cement paste. In general, the microstructures of hardened cement paste are obtained by microscopy. As a popular method, scanning electron microscopy (SEM) can acquire high-quality 2D images but fails to obtain 3D microstructures.Although several methods, such as microtomography (Micro-CT) and Focused Ion Beam Scanning Electron Microscopy (FIB-SEM), can acquire 3D microstructures, these fail to obtain high-quality 3D images or consume considerable cost. To address these issues, a method based on solid texture synthesis is proposed, synthesizing high-quality 3D microstructural image of hardened cement paste. This method includes 2D backscattered electron (BSE) image acquisition and 3D microstructure synthesis phases. In the approach, the synthesis model is based on solid texture synthesis, capturing microstructure information of the acquired 2D BSE image and generating high-quality 3D microstructures. In experiments, the method is verified on actual 3D Micro-CT images and 2D BSE images. Finally, qualitative experiments demonstrate that the 3D microstructures generated by our method have similar visual characteristics to the given 2D example. Furthermore, quantitative experiments prove that the synthetic 3D results are consistent with the actual instance in terms of porosity, particle size distribution, and grey scale co-occurrence matrix.
Language models are good pathologists: using attention-based sequence reduction and text-pretrained transformers for efficient WSI classification
Nov 14, 2022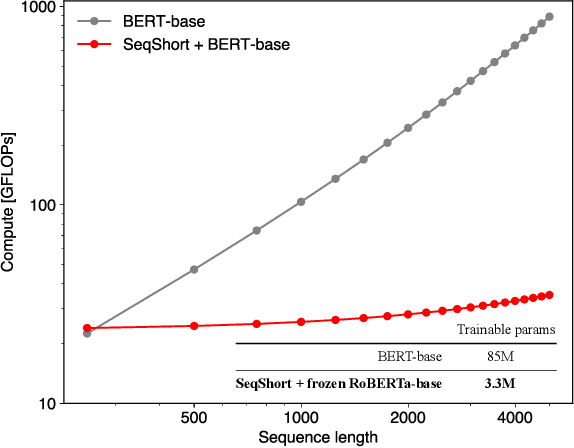
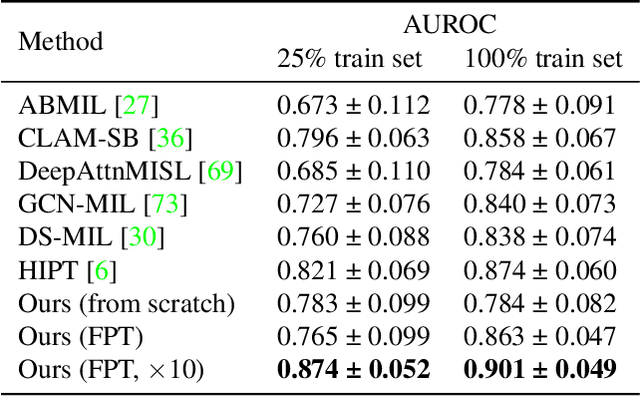
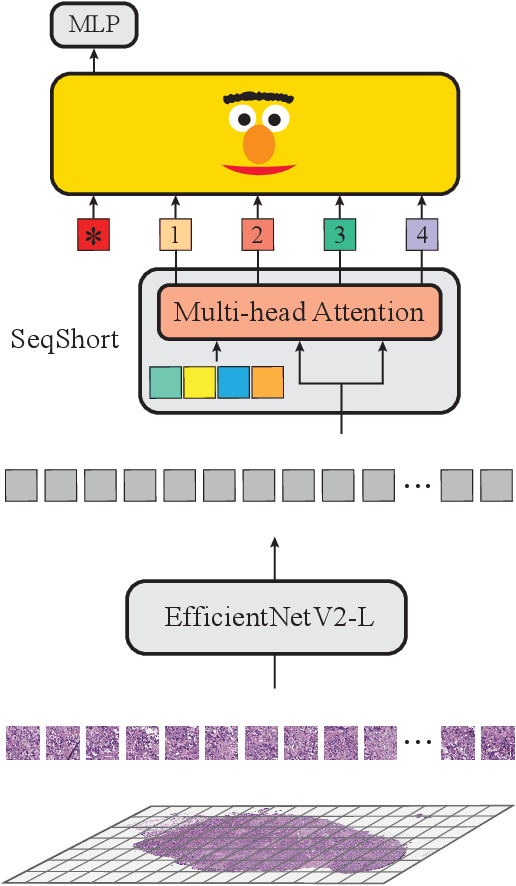

In digital pathology, Whole Slide Image (WSI) analysis is usually formulated as a Multiple Instance Learning (MIL) problem. Although transformer-based architectures have been used for WSI classification, these methods require modifications to adapt them to specific challenges of this type of image data. Despite their power across domains, reference transformer models in classical Computer Vision (CV) and Natural Language Processing (NLP) tasks are not used for pathology slide analysis. In this work we demonstrate the use of standard, frozen, text-pretrained, transformer language models in application to WSI classification. We propose SeqShort, a multi-head attention-based sequence reduction input layer to summarize each WSI in a fixed and short size sequence of instances. This allows us to reduce the computational costs of self-attention on long sequences, and to include positional information that is unavailable in other MIL approaches. We demonstrate the effectiveness of our methods in the task of cancer subtype classification, without the need of designing a WSI-specific transformer or performing in-domain self-supervised pretraining, while keeping a reduced compute budget and number of trainable parameters.