 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
QFF: Quantized Fourier Features for Neural Field Representations
Dec 02, 2022
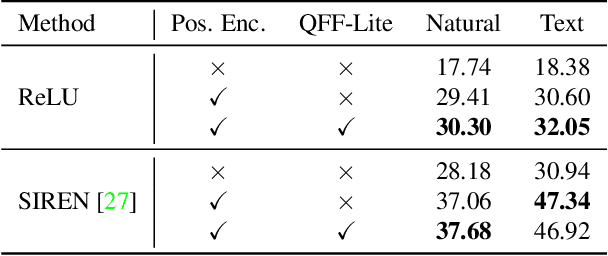
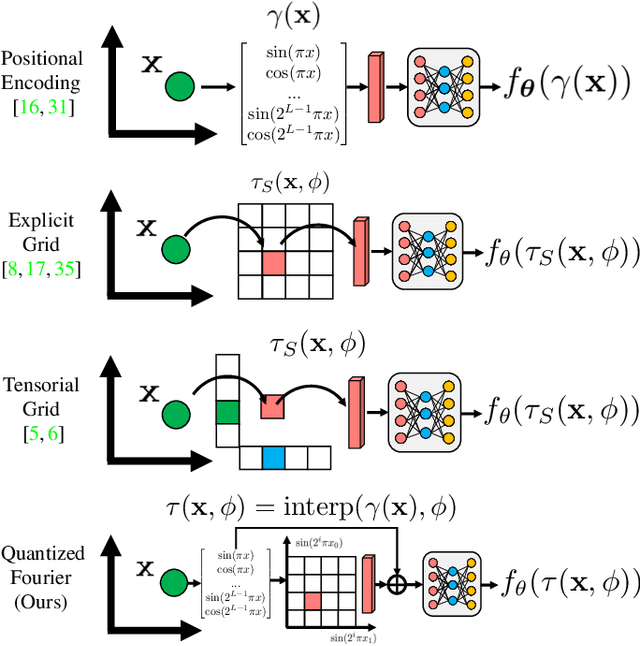
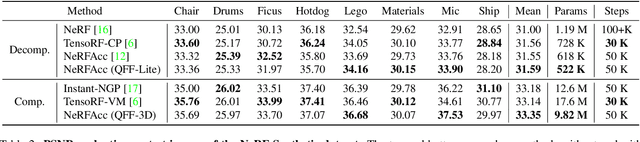
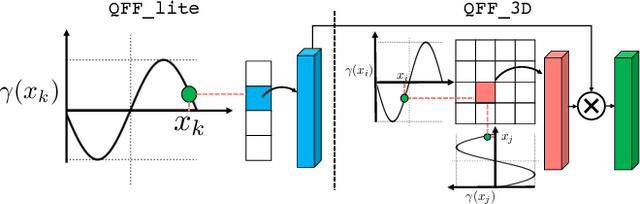
Multilayer perceptrons (MLPs) learn high frequencies slowly. Recent approaches encode features in spatial bins to improve speed of learning details, but at the cost of larger model size and loss of continuity. Instead, we propose to encode features in bins of Fourier features that are commonly used for positional encoding. We call these Quantized Fourier Features (QFF). As a naturally multiresolution and periodic representation, our experiments show that using QFF can result in smaller model size, faster training, and better quality outputs for several applications, including Neural Image Representations (NIR), Neural Radiance Field (NeRF) and Signed Distance Function (SDF) modeling. QFF are easy to code, fast to compute, and serve as a simple drop-in addition to many neural field representations.
Extracting Image Characteristics to Predict Crowdfunding Success
Mar 28, 2022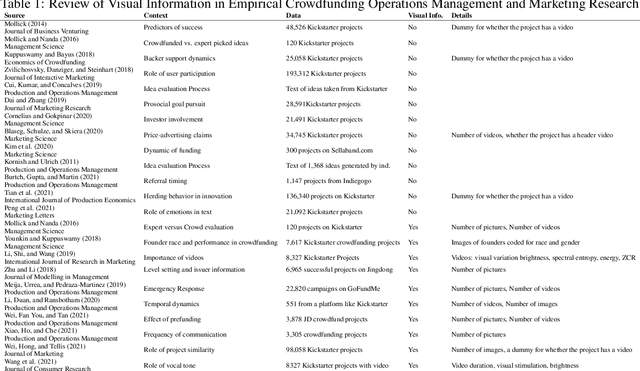
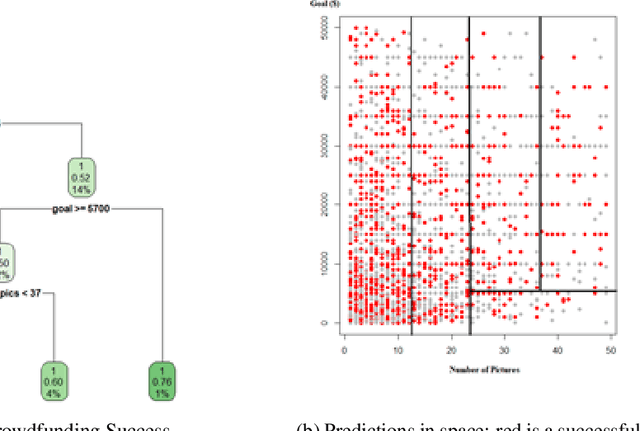
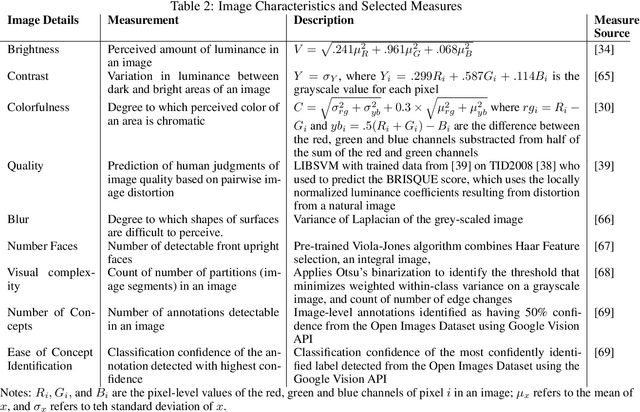
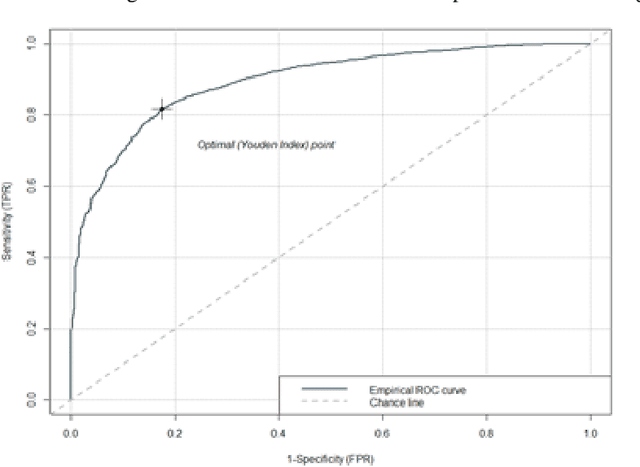
Despite an increase in the empirical study of crowdfunding platforms and the prevalence of visual information, operations management and marketing literature has yet to explore the role that image characteristics play in crowdfunding success. The authors of this manuscript begin by synthesizing literature on visual processing to identify several image characteristics that are likely to shape crowdfunding success. After detailing measures for each image characteristic, they use them as part of a machine-learning algorithm (Bayesian additive trees), along with project characteristics and textual information, to predict crowdfunding success. Results show that the inclusion of these image characteristics substantially improves prediction over baseline project variables, as well as textual features. Furthermore, image characteristic variables exhibit high importance, similar to variables linked to the number of pictures and number of videos. This research therefore offers valuable resources to researchers and managers who are interested in the role of visual information in ensuring new product success.
Human Face Recognition from Part of a Facial Image based on Image Stitching
Mar 10, 2022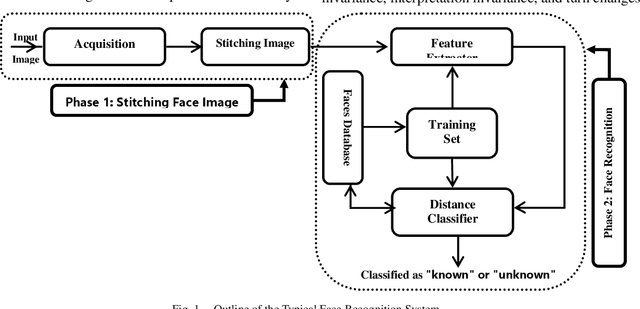
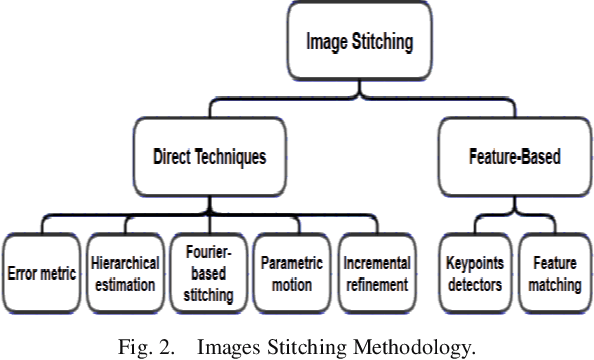


Most of the current techniques for face recognition require the presence of a full face of the person to be recognized, and this situation is difficult to achieve in practice, the required person may appear with a part of his face, which requires prediction of the part that did not appear. Most of the current forecasting processes are done by what is known as image interpolation, which does not give reliable results, especially if the missing part is large. In this work, we adopted the process of stitching the face by completing the missing part with the flipping of the part shown in the picture, depending on the fact that the human face is characterized by symmetry in most cases. To create a complete model, two facial recognition methods were used to prove the efficiency of the algorithm. The selected face recognition algorithms that are applied here are Eigenfaces and geometrical methods. Image stitching is the process during which distinctive photographic images are combined to make a complete scene or a high-resolution image. Several images are integrated to form a wide-angle panoramic image. The quality of the image stitching is determined by calculating the similarity among the stitched image and original images and by the presence of the seam lines through the stitched images. The Eigenfaces approach utilizes PCA calculation to reduce the feature vector dimensions. It provides an effective approach for discovering the lower-dimensional space. In addition, to enable the proposed algorithm to recognize the face, it also ensures a fast and effective way of classifying faces. The phase of feature extraction is followed by the classifier phase.
Instance-level Heterogeneous Domain Adaptation for Limited-labeled Sketch-to-Photo Retrieval
Nov 26, 2022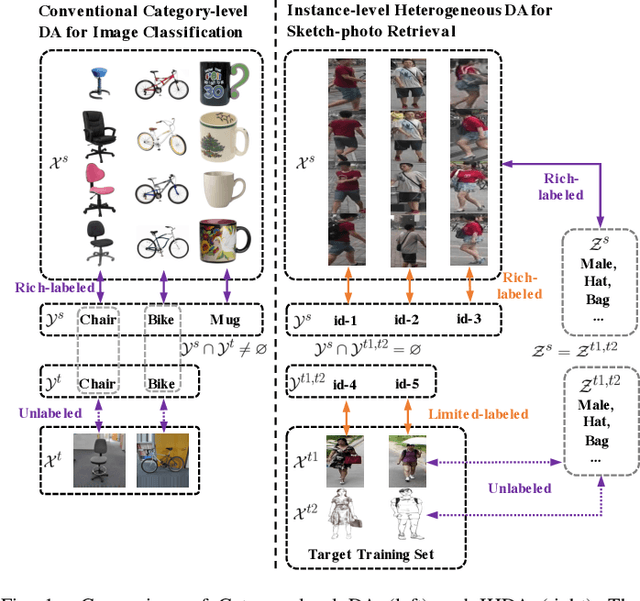
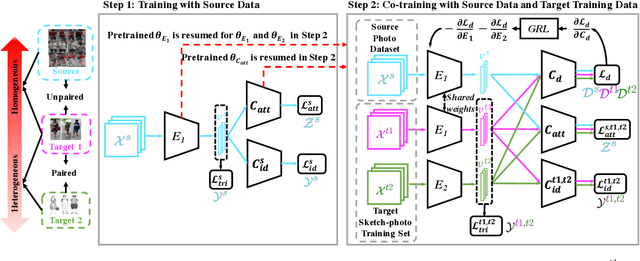

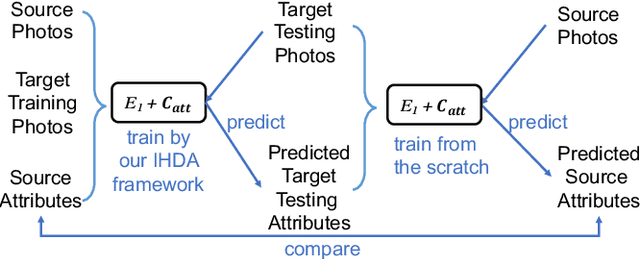
Although sketch-to-photo retrieval has a wide range of applications, it is costly to obtain paired and rich-labeled ground truth. Differently, photo retrieval data is easier to acquire. Therefore, previous works pre-train their models on rich-labeled photo retrieval data (i.e., source domain) and then fine-tune them on the limited-labeled sketch-to-photo retrieval data (i.e., target domain). However, without co-training source and target data, source domain knowledge might be forgotten during the fine-tuning process, while simply co-training them may cause negative transfer due to domain gaps. Moreover, identity label spaces of source data and target data are generally disjoint and therefore conventional category-level Domain Adaptation (DA) is not directly applicable. To address these issues, we propose an Instance-level Heterogeneous Domain Adaptation (IHDA) framework. We apply the fine-tuning strategy for identity label learning, aiming to transfer the instance-level knowledge in an inductive transfer manner. Meanwhile, labeled attributes from the source data are selected to form a shared label space for source and target domains. Guided by shared attributes, DA is utilized to bridge cross-dataset domain gaps and heterogeneous domain gaps, which transfers instance-level knowledge in a transductive transfer manner. Experiments show that our method has set a new state of the art on three sketch-to-photo image retrieval benchmarks without extra annotations, which opens the door to train more effective models on limited-labeled heterogeneous image retrieval tasks. Related codes are available at \url{https://github.com/fandulu/IHDA.
Temporal Output Discrepancy for Loss Estimation-based Active Learning
Dec 20, 2022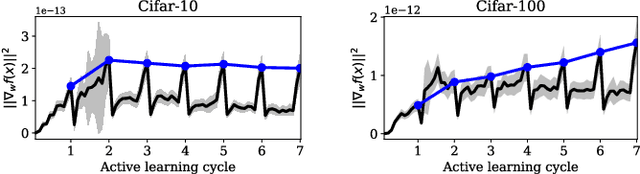
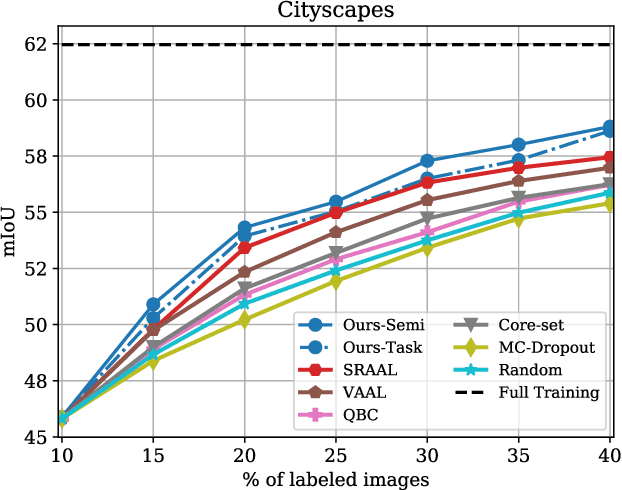
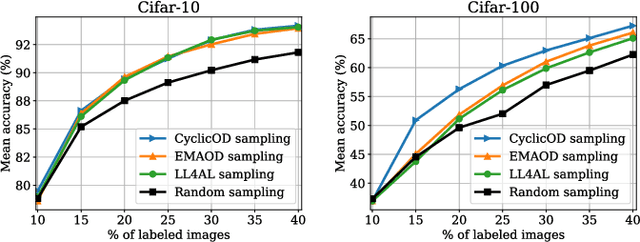
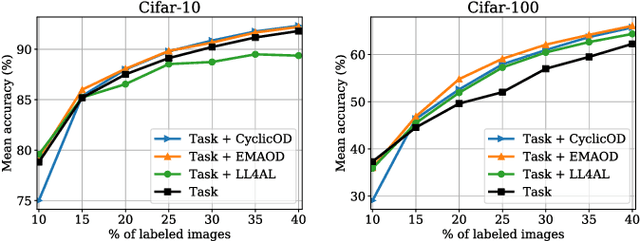
While deep learning succeeds in a wide range of tasks, it highly depends on the massive collection of annotated data which is expensive and time-consuming. To lower the cost of data annotation, active learning has been proposed to interactively query an oracle to annotate a small proportion of informative samples in an unlabeled dataset. Inspired by the fact that the samples with higher loss are usually more informative to the model than the samples with lower loss, in this paper we present a novel deep active learning approach that queries the oracle for data annotation when the unlabeled sample is believed to incorporate high loss. The core of our approach is a measurement Temporal Output Discrepancy (TOD) that estimates the sample loss by evaluating the discrepancy of outputs given by models at different optimization steps. Our theoretical investigation shows that TOD lower-bounds the accumulated sample loss thus it can be used to select informative unlabeled samples. On basis of TOD, we further develop an effective unlabeled data sampling strategy as well as an unsupervised learning criterion for active learning. Due to the simplicity of TOD, our methods are efficient, flexible, and task-agnostic. Extensive experimental results demonstrate that our approach achieves superior performances than the state-of-the-art active learning methods on image classification and semantic segmentation tasks. In addition, we show that TOD can be utilized to select the best model of potentially the highest testing accuracy from a pool of candidate models.
Calibrating Deep Neural Networks using Explicit Regularisation and Dynamic Data Pruning
Dec 20, 2022
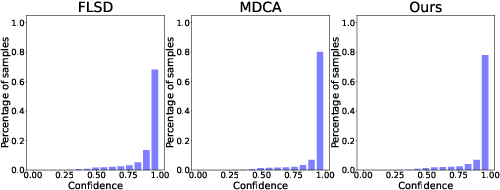
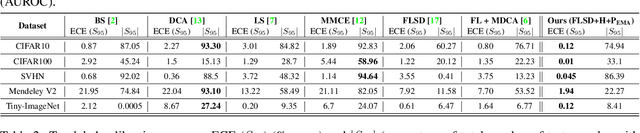

Deep neural networks (DNN) are prone to miscalibrated predictions, often exhibiting a mismatch between the predicted output and the associated confidence scores. Contemporary model calibration techniques mitigate the problem of overconfident predictions by pushing down the confidence of the winning class while increasing the confidence of the remaining classes across all test samples. However, from a deployment perspective, an ideal model is desired to (i) generate well-calibrated predictions for high-confidence samples with predicted probability say >0.95, and (ii) generate a higher proportion of legitimate high-confidence samples. To this end, we propose a novel regularization technique that can be used with classification losses, leading to state-of-the-art calibrated predictions at test time; From a deployment standpoint in safety-critical applications, only high-confidence samples from a well-calibrated model are of interest, as the remaining samples have to undergo manual inspection. Predictive confidence reduction of these potentially ``high-confidence samples'' is a downside of existing calibration approaches. We mitigate this by proposing a dynamic train-time data pruning strategy that prunes low-confidence samples every few epochs, providing an increase in "confident yet calibrated samples". We demonstrate state-of-the-art calibration performance across image classification benchmarks, reducing training time without much compromise in accuracy. We provide insights into why our dynamic pruning strategy that prunes low-confidence training samples leads to an increase in high-confidence samples at test time.
CHAIRS: Towards Full-Body Articulated Human-Object Interaction
Dec 20, 2022

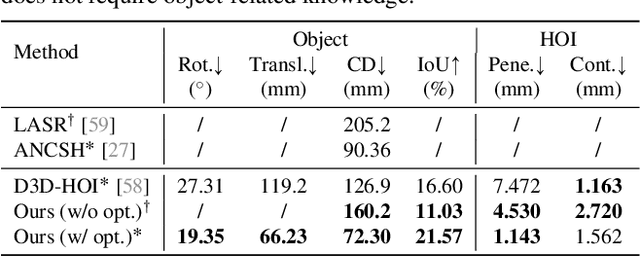
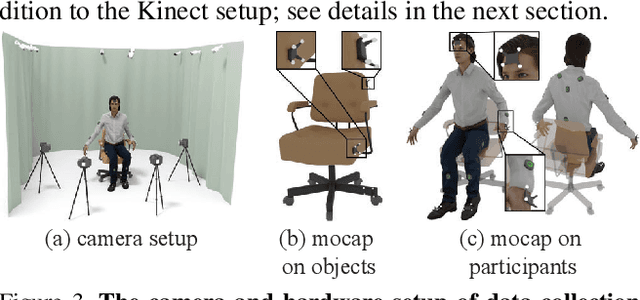
Fine-grained capturing of 3D HOI boosts human activity understanding and facilitates downstream visual tasks, including action recognition, holistic scene reconstruction, and human motion synthesis. Despite its significance, existing works mostly assume that humans interact with rigid objects using only a few body parts, limiting their scope. In this paper, we address the challenging problem of f-AHOI, wherein the whole human bodies interact with articulated objects, whose parts are connected by movable joints. We present CHAIRS, a large-scale motion-captured f-AHOI dataset, consisting of 16.2 hours of versatile interactions between 46 participants and 81 articulated and rigid sittable objects. CHAIRS provides 3D meshes of both humans and articulated objects during the entire interactive process, as well as realistic and physically plausible full-body interactions. We show the value of CHAIRS with object pose estimation. By learning the geometrical relationships in HOI, we devise the very first model that leverage human pose estimation to tackle the estimation of articulated object poses and shapes during whole-body interactions. Given an image and an estimated human pose, our model first reconstructs the pose and shape of the object, then optimizes the reconstruction according to a learned interaction prior. Under both evaluation settings (e.g., with or without the knowledge of objects' geometries/structures), our model significantly outperforms baselines. We hope CHAIRS will promote the community towards finer-grained interaction understanding. We will make the data/code publicly available.
OBMO: One Bounding Box Multiple Objects for Monocular 3D Object Detection
Dec 20, 2022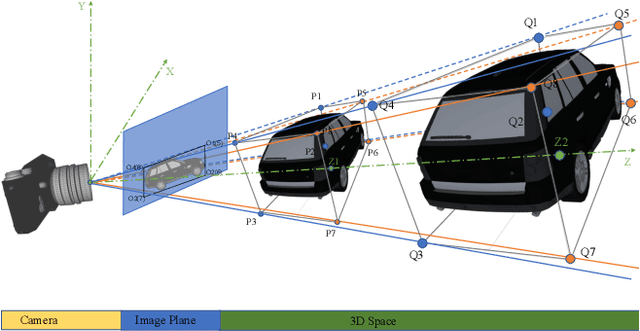
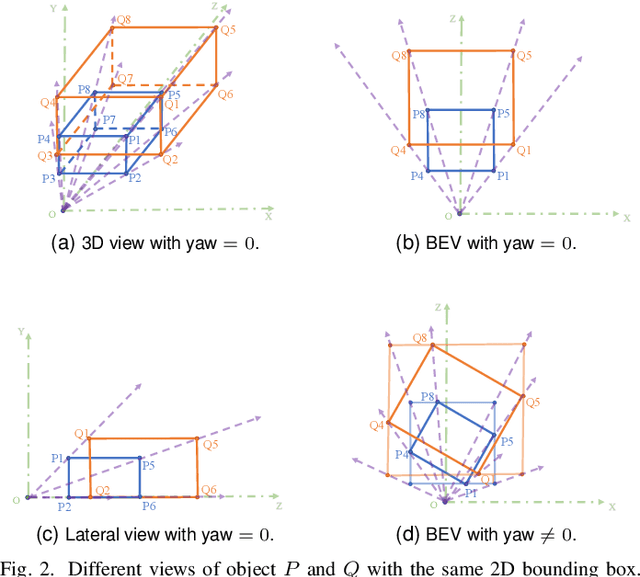
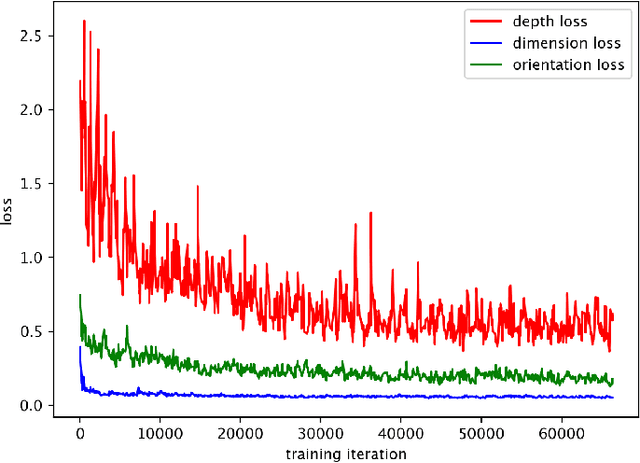
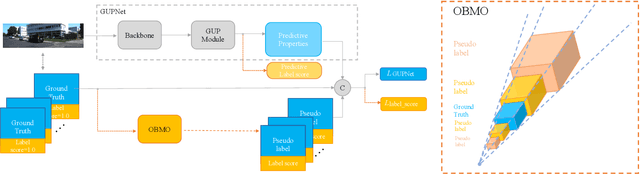
Compared to typical multi-sensor systems, monocular 3D object detection has attracted much attention due to its simple configuration. However, there is still a significant gap between LiDAR-based and monocular-based methods. In this paper, we find that the ill-posed nature of monocular imagery can lead to depth ambiguity. Specifically, objects with different depths can appear with the same bounding boxes and similar visual features in the 2D image. Unfortunately, the network cannot accurately distinguish different depths from such non-discriminative visual features, resulting in unstable depth training. To facilitate depth learning, we propose a simple yet effective plug-and-play module, One Bounding Box Multiple Objects (OBMO). Concretely, we add a set of suitable pseudo labels by shifting the 3D bounding box along the viewing frustum. To constrain the pseudo-3D labels to be reasonable, we carefully design two label scoring strategies to represent their quality. In contrast to the original hard depth labels, such soft pseudo labels with quality scores allow the network to learn a reasonable depth range, boosting training stability and thus improving final performance. Extensive experiments on KITTI and Waymo benchmarks show that our method significantly improves state-of-the-art monocular 3D detectors by a significant margin (The improvements under the moderate setting on KITTI validation set are $\mathbf{1.82\sim 10.91\%}$ mAP in BEV and $\mathbf{1.18\sim 9.36\%}$ mAP in 3D}. Codes have been released at https://github.com/mrsempress/OBMO.
PP-Matting: High-Accuracy Natural Image Matting
Apr 20, 2022
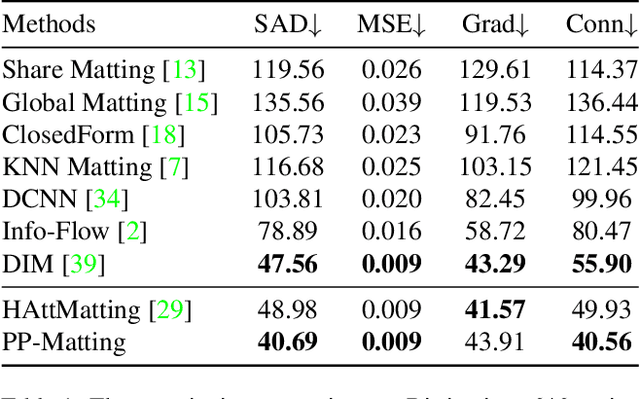
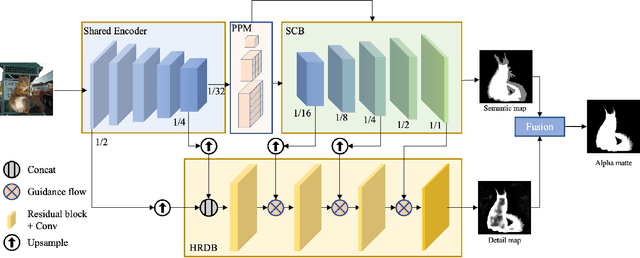
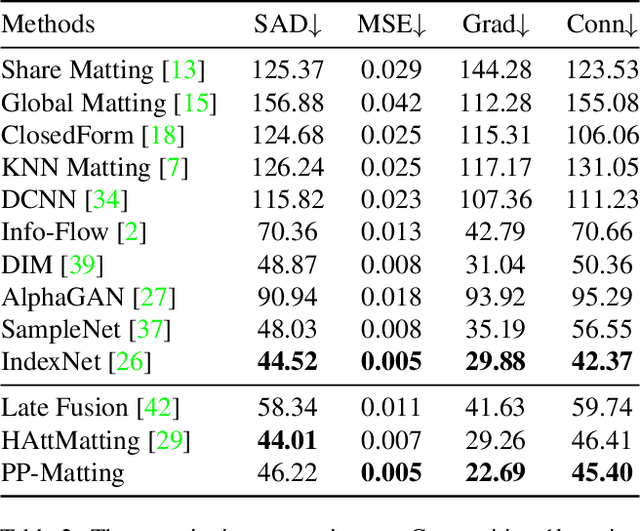
Natural image matting is a fundamental and challenging computer vision task. It has many applications in image editing and composition. Recently, deep learning-based approaches have achieved great improvements in image matting. However, most of them require a user-supplied trimap as an auxiliary input, which limits the matting applications in the real world. Although some trimap-free approaches have been proposed, the matting quality is still unsatisfactory compared to trimap-based ones. Without the trimap guidance, the matting models suffer from foreground-background ambiguity easily, and also generate blurry details in the transition area. In this work, we propose PP-Matting, a trimap-free architecture that can achieve high-accuracy natural image matting. Our method applies a high-resolution detail branch (HRDB) that extracts fine-grained details of the foreground with keeping feature resolution unchanged. Also, we propose a semantic context branch (SCB) that adopts a semantic segmentation subtask. It prevents the detail prediction from local ambiguity caused by semantic context missing. In addition, we conduct extensive experiments on two well-known benchmarks: Composition-1k and Distinctions-646. The results demonstrate the superiority of PP-Matting over previous methods. Furthermore, we provide a qualitative evaluation of our method on human matting which shows its outstanding performance in the practical application. The code and pre-trained models will be available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
Self Supervised Learning for Few Shot Hyperspectral Image Classification
Jun 24, 2022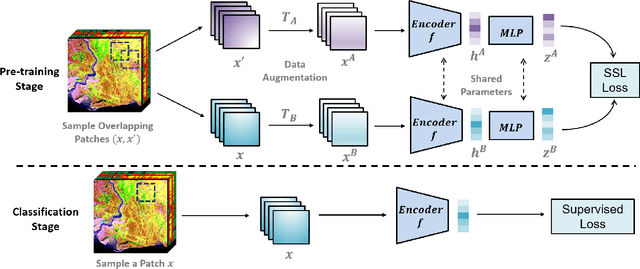
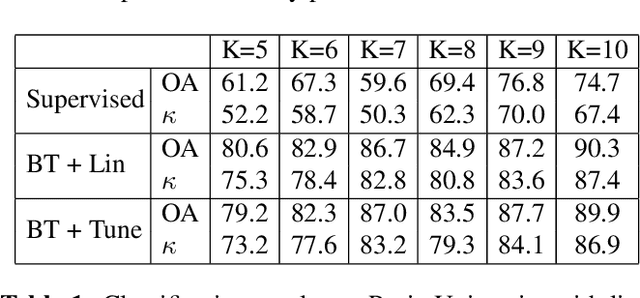
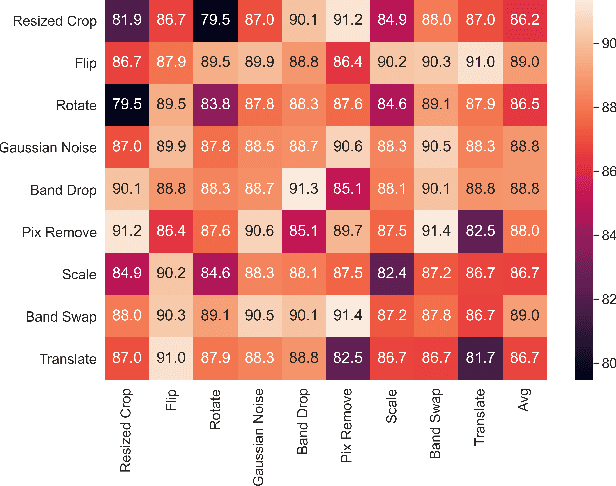
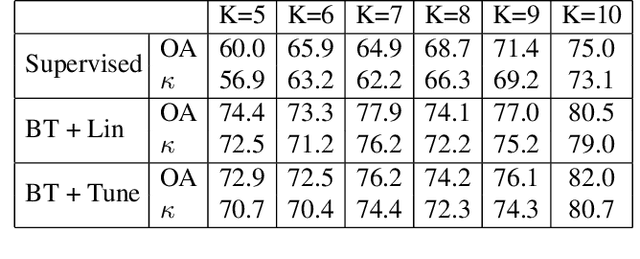
Deep learning has proven to be a very effective approach for Hyperspectral Image (HSI) classification. However, deep neural networks require large annotated datasets to generalize well. This limits the applicability of deep learning for HSI classification, where manually labelling thousands of pixels for every scene is impractical. In this paper, we propose to leverage Self Supervised Learning (SSL) for HSI classification. We show that by pre-training an encoder on unlabeled pixels using Barlow-Twins, a state-of-the-art SSL algorithm, we can obtain accurate models with a handful of labels. Experimental results demonstrate that this approach significantly outperforms vanilla supervised learning.