 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Federated Data Model
Mar 13, 2024
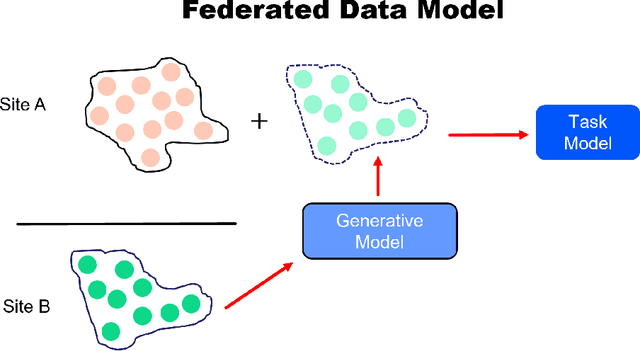
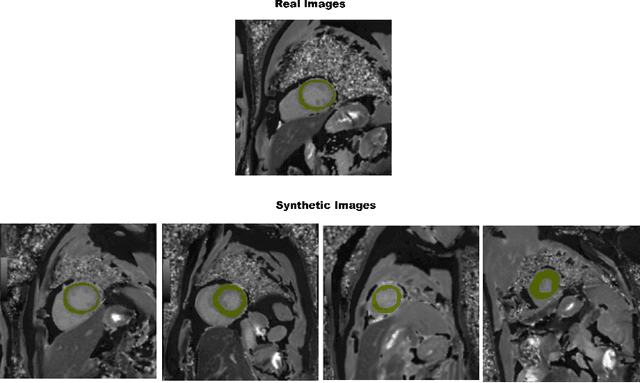
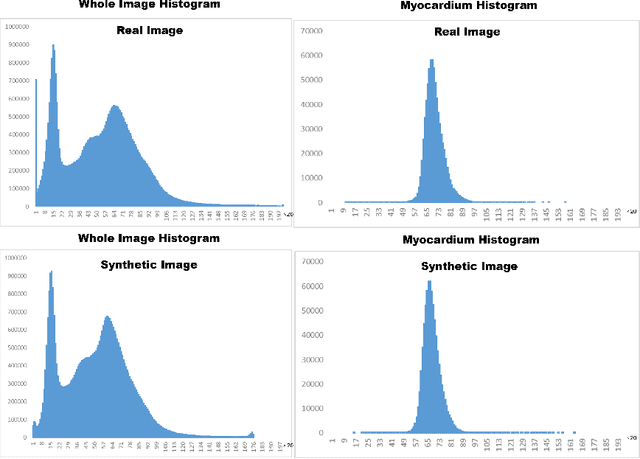
In artificial intelligence (AI), especially deep learning, data diversity and volume play a pivotal role in model development. However, training a robust deep learning model often faces challenges due to data privacy, regulations, and the difficulty of sharing data between different locations, especially for medical applications. To address this, we developed a method called the Federated Data Model (FDM). This method uses diffusion models to learn the characteristics of data at one site and then creates synthetic data that can be used at another site without sharing the actual data. We tested this approach with a medical image segmentation task, focusing on cardiac magnetic resonance images from different hospitals. Our results show that models trained with this method perform well both on the data they were originally trained on and on data from other sites. This approach offers a promising way to train accurate and privacy-respecting AI models across different locations.
Sketch2Manga: Shaded Manga Screening from Sketch with Diffusion Models
Mar 13, 2024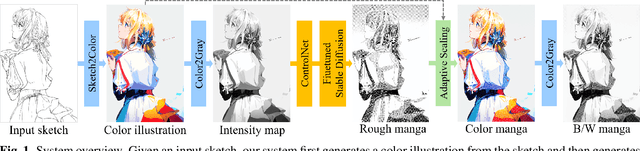

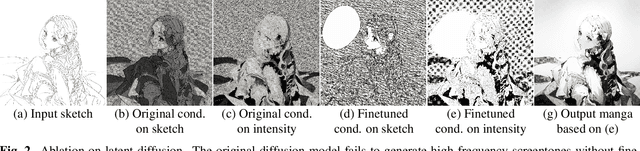
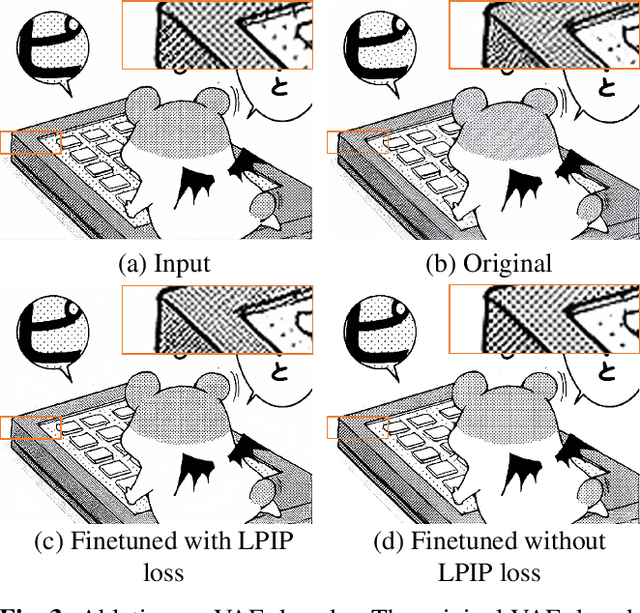
While manga is a popular entertainment form, creating manga is tedious, especially adding screentones to the created sketch, namely manga screening. Unfortunately, there is no existing method that tailors for automatic manga screening, probably due to the difficulty of generating high-quality shaded high-frequency screentones. The classic manga screening approaches generally require user input to provide screentone exemplars or a reference manga image. The recent deep learning models enables the automatic generation by learning from a large-scale dataset. However, the state-of-the-art models still fail to generate high-quality shaded screentones due to the lack of a tailored model and high-quality manga training data. In this paper, we propose a novel sketch-to-manga framework that first generates a color illustration from the sketch and then generates a screentoned manga based on the intensity guidance. Our method significantly outperforms existing methods in generating high-quality manga with shaded high-frequency screentones.
Naming, Describing, and Quantifying Visual Objects in Humans and LLMs
Mar 13, 2024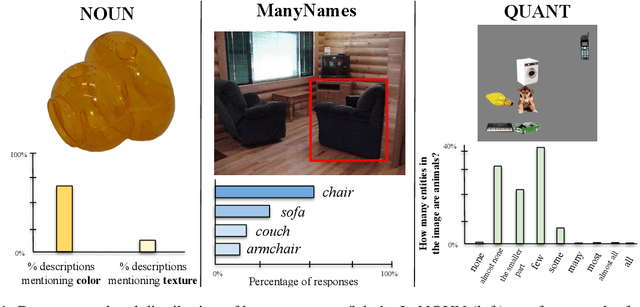
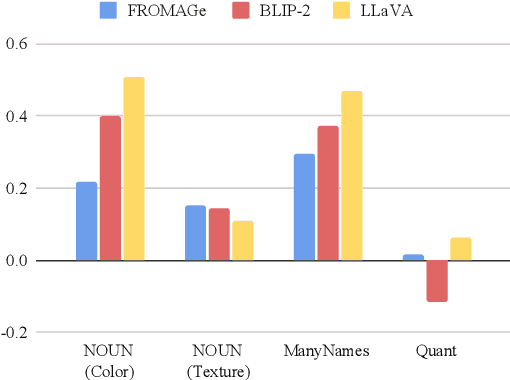
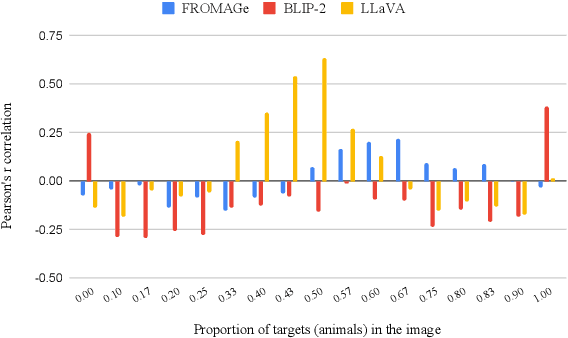
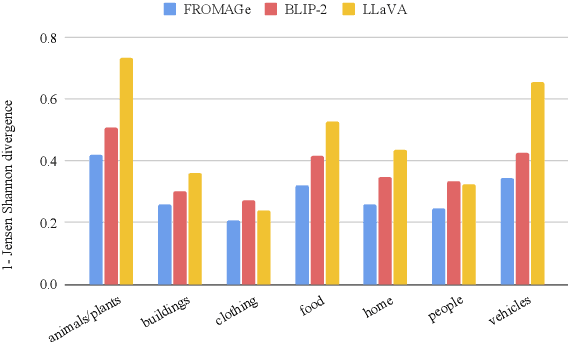
While human speakers use a variety of different expressions when describing the same object in an image, giving rise to a distribution of plausible labels driven by pragmatic constraints, the extent to which current Vision \& Language Large Language Models (VLLMs) can mimic this crucial feature of language use is an open question. This applies to common, everyday objects, but it is particularly interesting for uncommon or novel objects for which a category label may be lacking or fuzzy. Furthermore, humans show clear production preferences for highly context-sensitive expressions, such as the quantifiers `few' or `most'. In our work, we evaluate VLLMs (FROMAGe, BLIP-2, LLaVA) on three categories (nouns, attributes, and quantifiers) where humans show great subjective variability concerning the distribution over plausible labels, using datasets and resources mostly under-explored in previous work. Our results reveal mixed evidence on the ability of VLLMs to capture human naming preferences, with all models failing in tasks that require high-level reasoning such as assigning quantifiers.
A Domain Translation Framework with an Adversarial Denoising Diffusion Model to Generate Synthetic Datasets of Echocardiography Images
Mar 07, 2024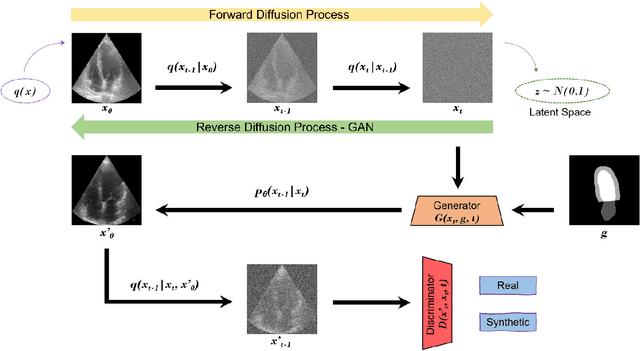
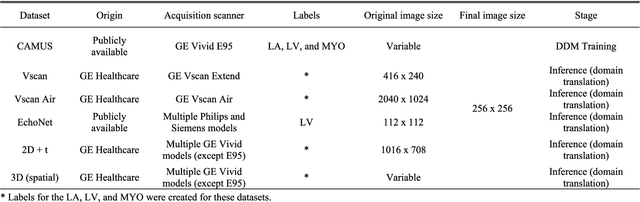
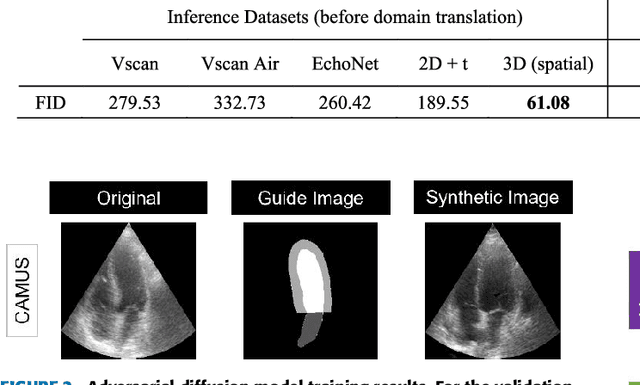
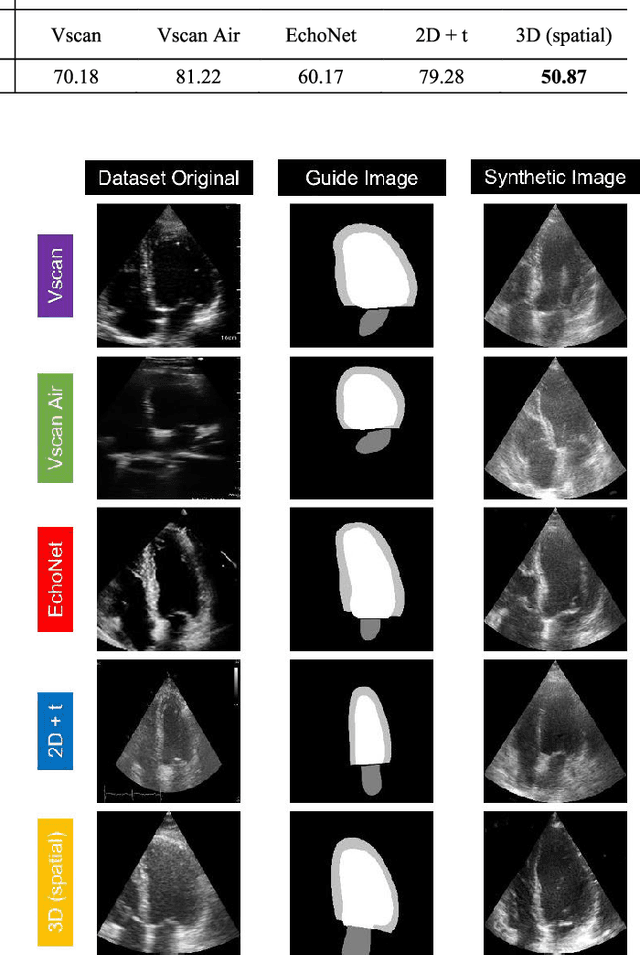
Currently, medical image domain translation operations show a high demand from researchers and clinicians. Amongst other capabilities, this task allows the generation of new medical images with sufficiently high image quality, making them clinically relevant. Deep Learning (DL) architectures, most specifically deep generative models, are widely used to generate and translate images from one domain to another. The proposed framework relies on an adversarial Denoising Diffusion Model (DDM) to synthesize echocardiography images and perform domain translation. Contrary to Generative Adversarial Networks (GANs), DDMs are able to generate high quality image samples with a large diversity. If a DDM is combined with a GAN, this ability to generate new data is completed at an even faster sampling time. In this work we trained an adversarial DDM combined with a GAN to learn the reverse denoising process, relying on a guide image, making sure relevant anatomical structures of each echocardiography image were kept and represented on the generated image samples. For several domain translation operations, the results verified that such generative model was able to synthesize high quality image samples: MSE: 11.50 +/- 3.69, PSNR (dB): 30.48 +/- 0.09, SSIM: 0.47 +/- 0.03. The proposed method showed high generalization ability, introducing a framework to create echocardiography images suitable to be used for clinical research purposes.
Wide-Field, High-Resolution Reconstruction in Computational Multi-Aperture Miniscope Using a Fourier Neural Network
Mar 11, 2024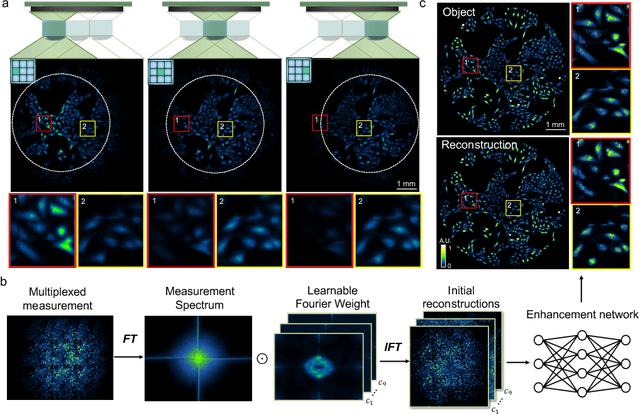
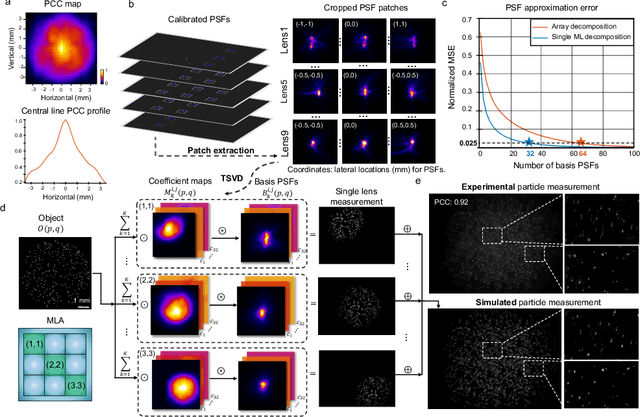
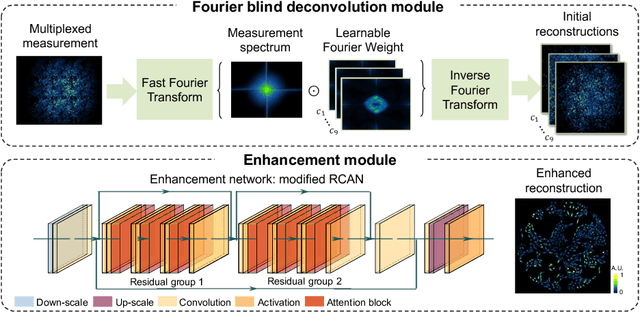
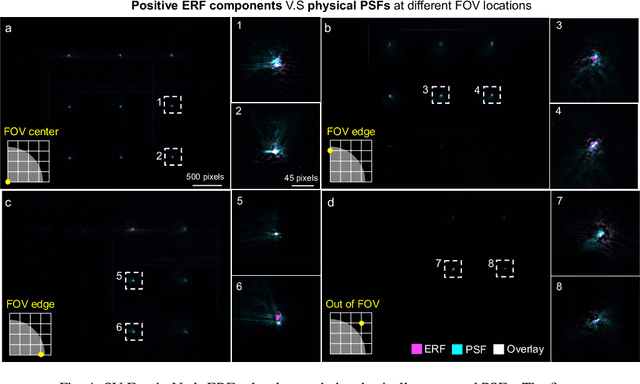
Traditional fluorescence microscopy is constrained by inherent trade-offs among resolution, field-of-view, and system complexity. To navigate these challenges, we introduce a simple and low-cost computational multi-aperture miniature microscope, utilizing a microlens array for single-shot wide-field, high-resolution imaging. Addressing the challenges posed by extensive view multiplexing and non-local, shift-variant aberrations in this device, we present SV-FourierNet, a novel multi-channel Fourier neural network. SV-FourierNet facilitates high-resolution image reconstruction across the entire imaging field through its learned global receptive field. We establish a close relationship between the physical spatially-varying point-spread functions and the network's learned effective receptive field. This ensures that SV-FourierNet has effectively encapsulated the spatially-varying aberrations in our system, and learned a physically meaningful function for image reconstruction. Training of SV-FourierNet is conducted entirely on a physics-based simulator. We showcase wide-field, high-resolution video reconstructions on colonies of freely moving C. elegans and imaging of a mouse brain section. Our computational multi-aperture miniature microscope, augmented with SV-FourierNet, represents a major advancement in computational microscopy and may find broad applications in biomedical research and other fields requiring compact microscopy solutions.
Eliminating Warping Shakes for Unsupervised Online Video Stitching
Mar 11, 2024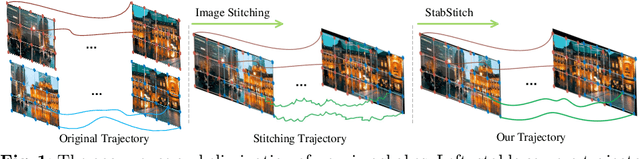

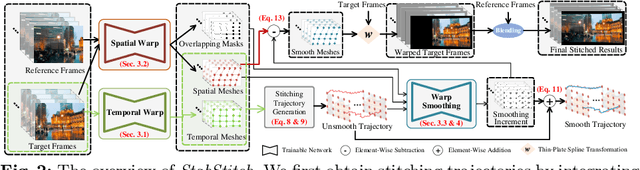

In this paper, we retarget video stitching to an emerging issue, named warping shake, when extending image stitching to video stitching. It unveils the temporal instability of warped content in non-overlapping regions, despite image stitching having endeavored to preserve the natural structures. Therefore, in most cases, even if the input videos to be stitched are stable, the stitched video will inevitably cause undesired warping shakes and affect the visual experience. To eliminate the shakes, we propose StabStitch to simultaneously realize video stitching and video stabilization in a unified unsupervised learning framework. Starting from the camera paths in video stabilization, we first derive the expression of stitching trajectories in video stitching by elaborately integrating spatial and temporal warps. Then a warp smoothing model is presented to optimize them with a comprehensive consideration regarding content alignment, trajectory smoothness, spatial consistency, and online collaboration. To establish an evaluation benchmark and train the learning framework, we build a video stitching dataset with a rich diversity in camera motions and scenes. Compared with existing stitching solutions, StabStitch exhibits significant superiority in scene robustness and inference speed in addition to stitching and stabilization performance, contributing to a robust and real-time online video stitching system. The code and dataset will be available at https://github.com/nie-lang/StabStitch.
Unsupervised Modality-Transferable Video Highlight Detection with Representation Activation Sequence Learning
Mar 14, 2024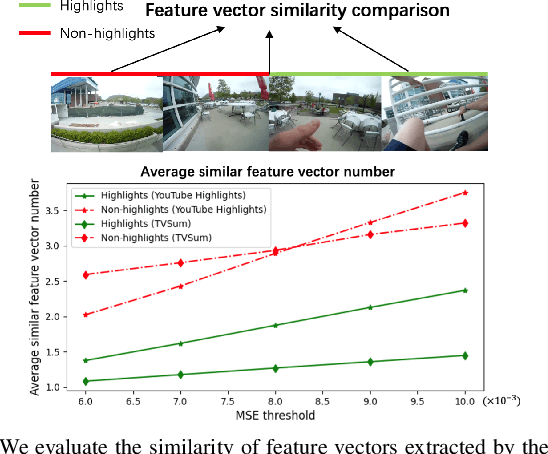
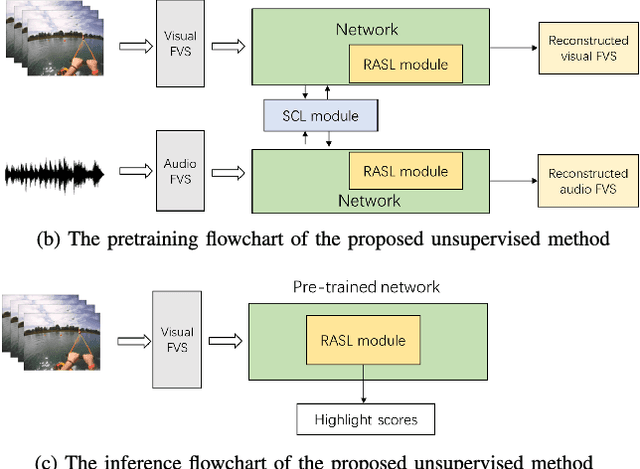
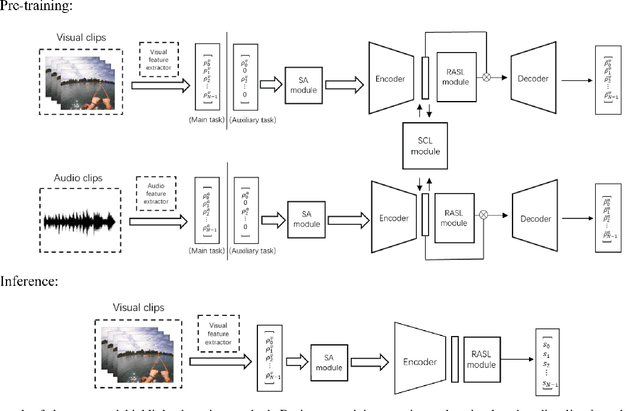
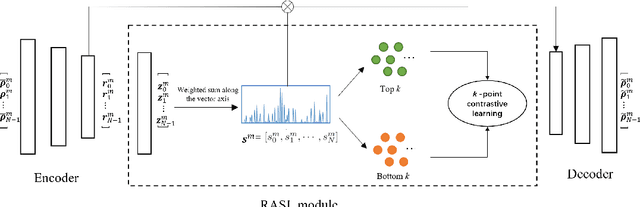
Identifying highlight moments of raw video materials is crucial for improving the efficiency of editing videos that are pervasive on internet platforms. However, the extensive work of manually labeling footage has created obstacles to applying supervised methods to videos of unseen categories. The absence of an audio modality that contains valuable cues for highlight detection in many videos also makes it difficult to use multimodal strategies. In this paper, we propose a novel model with cross-modal perception for unsupervised highlight detection. The proposed model learns representations with visual-audio level semantics from image-audio pair data via a self-reconstruction task. To achieve unsupervised highlight detection, we investigate the latent representations of the network and propose the representation activation sequence learning (RASL) module with k-point contrastive learning to learn significant representation activations. To connect the visual modality with the audio modality, we use the symmetric contrastive learning (SCL) module to learn the paired visual and audio representations. Furthermore, an auxiliary task of masked feature vector sequence (FVS) reconstruction is simultaneously conducted during pretraining for representation enhancement. During inference, the cross-modal pretrained model can generate representations with paired visual-audio semantics given only the visual modality. The RASL module is used to output the highlight scores. The experimental results show that the proposed framework achieves superior performance compared to other state-of-the-art approaches.
SAM-Lightening: A Lightweight Segment Anything Model with Dilated Flash Attention to Achieve 30 times Acceleration
Mar 14, 2024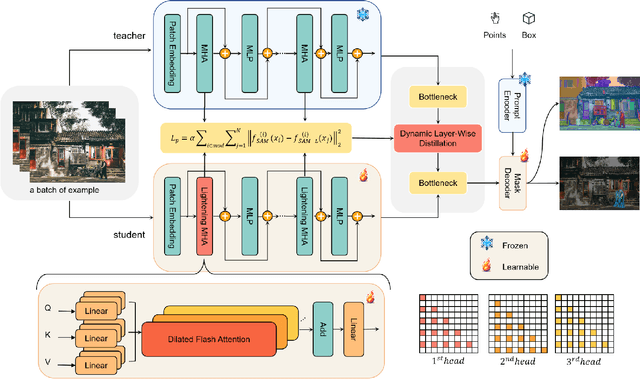
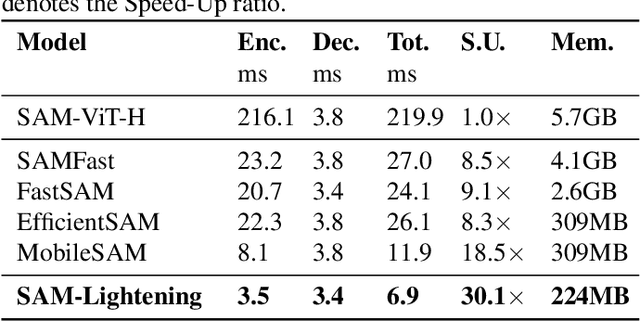

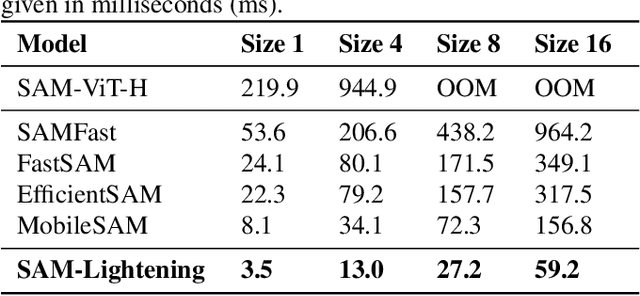
Segment Anything Model (SAM) has garnered significant attention in segmentation tasks due to their zero-shot generalization ability. However, a broader application of SAMs to real-world practice has been restricted by their low inference speed and high computational memory demands, which mainly stem from the attention mechanism. Existing work concentrated on optimizing the encoder, yet has not adequately addressed the inefficiency of the attention mechanism itself, even when distilled to a smaller model, which thus leaves space for further improvement. In response, we introduce SAM-Lightening, a variant of SAM, that features a re-engineered attention mechanism, termed Dilated Flash Attention. It not only facilitates higher parallelism, enhancing processing efficiency but also retains compatibility with the existing FlashAttention. Correspondingly, we propose a progressive distillation to enable an efficient knowledge transfer from the vanilla SAM without costly training from scratch. Experiments on COCO and LVIS reveal that SAM-Lightening significantly outperforms the state-of-the-art methods in both run-time efficiency and segmentation accuracy. Specifically, it can achieve an inference speed of 7 milliseconds (ms) per image, for images of size 1024*1024 pixels, which is 30.1 times faster than the vanilla SAM and 2.1 times than the state-of-the-art. Moreover, it takes only 244MB memory, which is 3.5\% of the vanilla SAM. The code and weights are available at https://anonymous.4open.science/r/SAM-LIGHTENING-BC25/.
When Semantic Segmentation Meets Frequency Aliasing
Mar 14, 2024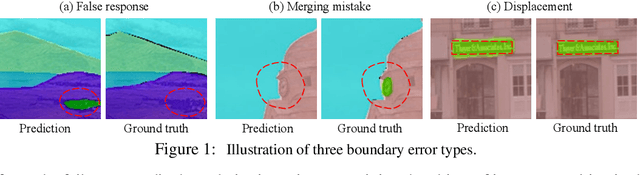
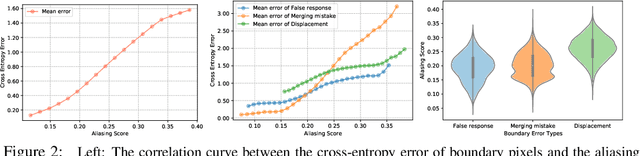

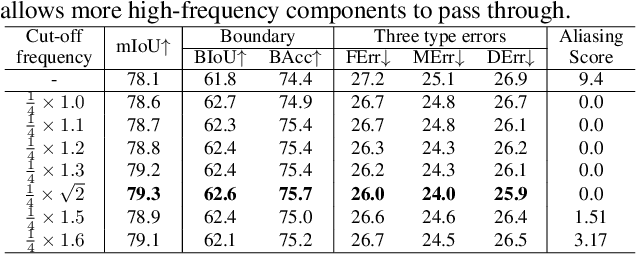
Despite recent advancements in semantic segmentation, where and what pixels are hard to segment remains largely unexplored. Existing research only separates an image into easy and hard regions and empirically observes the latter are associated with object boundaries. In this paper, we conduct a comprehensive analysis of hard pixel errors, categorizing them into three types: false responses, merging mistakes, and displacements. Our findings reveal a quantitative association between hard pixels and aliasing, which is distortion caused by the overlapping of frequency components in the Fourier domain during downsampling. To identify the frequencies responsible for aliasing, we propose using the equivalent sampling rate to calculate the Nyquist frequency, which marks the threshold for aliasing. Then, we introduce the aliasing score as a metric to quantify the extent of aliasing. While positively correlated with the proposed aliasing score, three types of hard pixels exhibit different patterns. Here, we propose two novel de-aliasing filter (DAF) and frequency mixing (FreqMix) modules to alleviate aliasing degradation by accurately removing or adjusting frequencies higher than the Nyquist frequency. The DAF precisely removes the frequencies responsible for aliasing before downsampling, while the FreqMix dynamically selects high-frequency components within the encoder block. Experimental results demonstrate consistent improvements in semantic segmentation and low-light instance segmentation tasks. The code is available at: \url{https://github.com/Linwei-Chen/Seg-Aliasing}.
Towards the Uncharted: Density-Descending Feature Perturbation for Semi-supervised Semantic Segmentation
Mar 14, 2024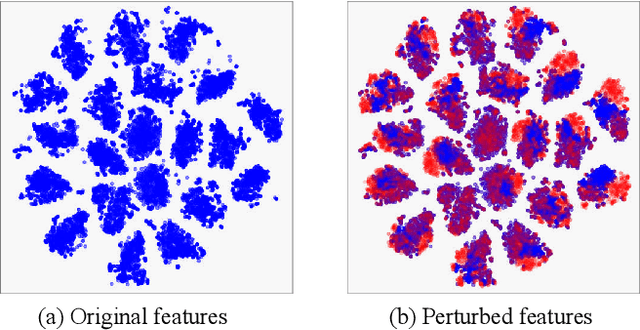
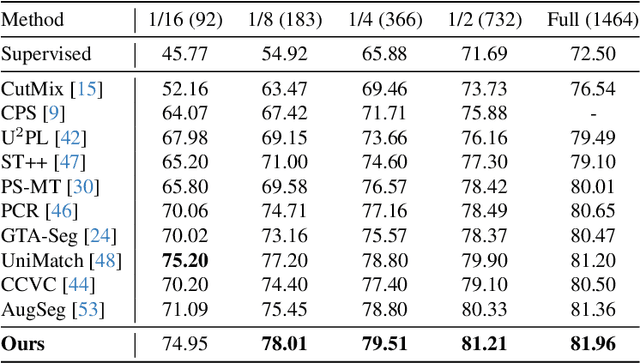
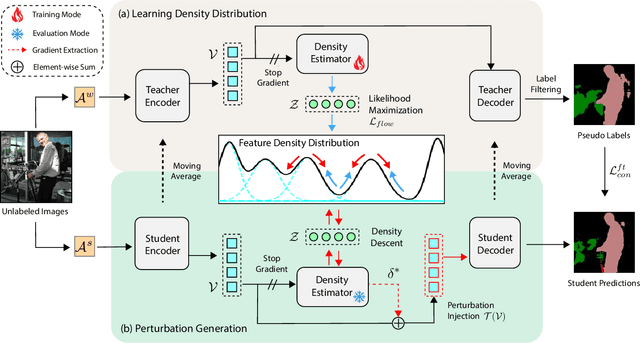
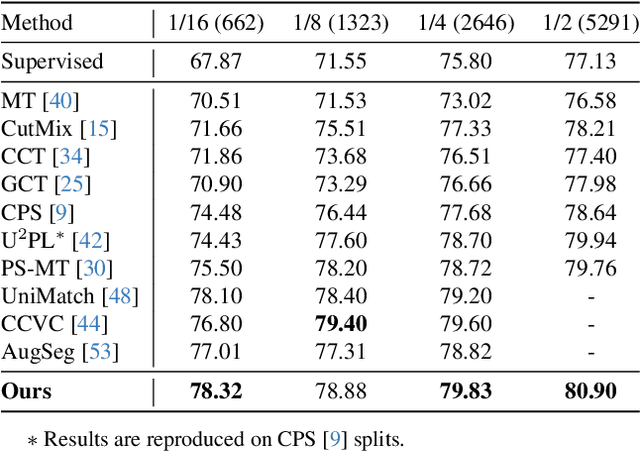
Semi-supervised semantic segmentation allows model to mine effective supervision from unlabeled data to complement label-guided training. Recent research has primarily focused on consistency regularization techniques, exploring perturbation-invariant training at both the image and feature levels. In this work, we proposed a novel feature-level consistency learning framework named Density-Descending Feature Perturbation (DDFP). Inspired by the low-density separation assumption in semi-supervised learning, our key insight is that feature density can shed a light on the most promising direction for the segmentation classifier to explore, which is the regions with lower density. We propose to shift features with confident predictions towards lower-density regions by perturbation injection. The perturbed features are then supervised by the predictions on the original features, thereby compelling the classifier to explore less dense regions to effectively regularize the decision boundary. Central to our method is the estimation of feature density. To this end, we introduce a lightweight density estimator based on normalizing flow, allowing for efficient capture of the feature density distribution in an online manner. By extracting gradients from the density estimator, we can determine the direction towards less dense regions for each feature. The proposed DDFP outperforms other designs on feature-level perturbations and shows state of the art performances on both Pascal VOC and Cityscapes dataset under various partition protocols. The project is available at https://github.com/Gavinwxy/DDFP.