 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Synthetic-to-real Composite Semantic Segmentation in Additive Manufacturing
Oct 14, 2022
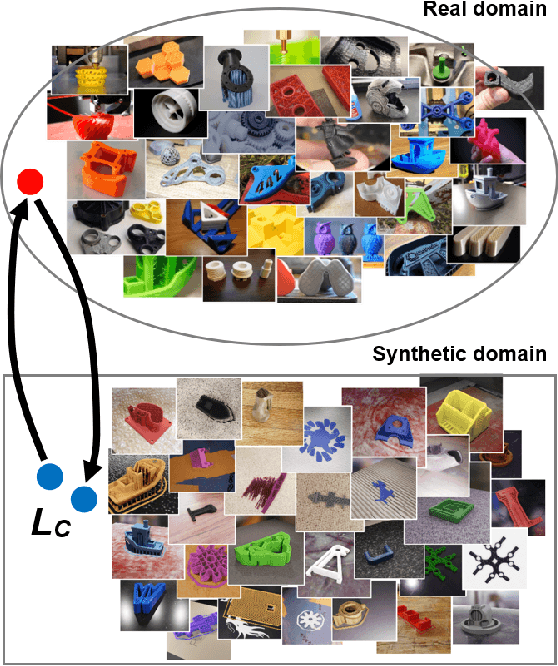


The application of computer vision and machine learning methods in the field of additive manufacturing (AM) for semantic segmentation of the structural elements of 3-D printed products will improve real-time failure analysis systems and can potentially reduce the number of defects by enabling in situ corrections. This work demonstrates the possibilities of using physics-based rendering for labeled image dataset generation, as well as image-to-image translation capabilities to improve the accuracy of real image segmentation for AM systems. Multi-class semantic segmentation experiments were carried out based on the U-Net model and cycle generative adversarial network. The test results demonstrated the capacity of detecting such structural elements of 3-D printed parts as a top layer, infill, shell, and support. A basis for further segmentation system enhancement by utilizing image-to-image style transfer and domain adaptation technologies was also developed. The results indicate that using style transfer as a precursor to domain adaptation can significantly improve real 3-D printing image segmentation in situations where a model trained on synthetic data is the only tool available. The mean intersection over union (mIoU) scores for synthetic test datasets included 94.90% for the entire 3-D printed part, 73.33% for the top layer, 78.93% for the infill, 55.31% for the shell, and 69.45% for supports.
Learning Knowledge Representation with Meta Knowledge Distillation for Single Image Super-Resolution
Jul 18, 2022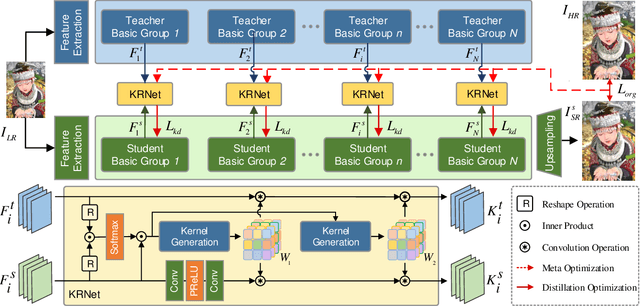
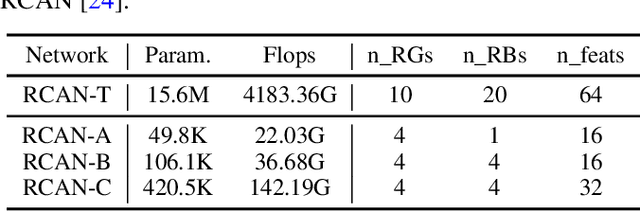
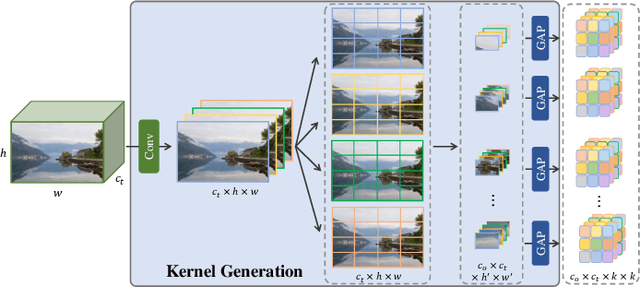
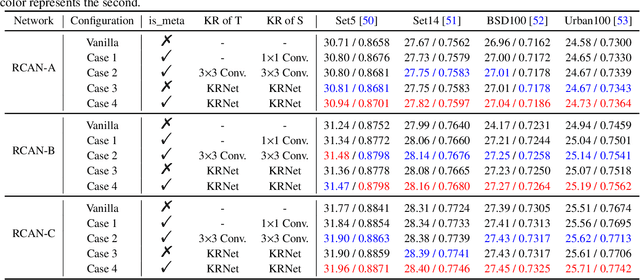
Knowledge distillation (KD), which can efficiently transfer knowledge from a cumbersome network (teacher) to a compact network (student), has demonstrated its advantages in some computer vision applications. The representation of knowledge is vital for knowledge transferring and student learning, which is generally defined in hand-crafted manners or uses the intermediate features directly. In this paper, we propose a model-agnostic meta knowledge distillation method under the teacher-student architecture for the single image super-resolution task. It provides a more flexible and accurate way to help the teachers transmit knowledge in accordance with the abilities of students via knowledge representation networks (KRNets) with learnable parameters. In order to improve the perception ability of knowledge representation to students' requirements, we propose to solve the transformation process from intermediate outputs to transferred knowledge by employing the student features and the correlation between teacher and student in the KRNets. Specifically, the texture-aware dynamic kernels are generated and then extract texture features to be improved and the corresponding teacher guidance so as to decompose the distillation problem into texture-wise supervision for further promoting the recovery quality of high-frequency details. In addition, the KRNets are optimized in a meta-learning manner to ensure the knowledge transferring and the student learning are beneficial to improving the reconstructed quality of the student. Experiments conducted on various single image super-resolution datasets demonstrate that our proposed method outperforms existing defined knowledge representation related distillation methods, and can help super-resolution algorithms achieve better reconstruction quality without introducing any inference complexity.
Motion and Context-Aware Audio-Visual Conditioned Video Prediction
Dec 09, 2022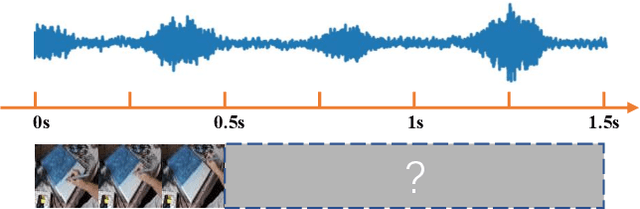



Existing state-of-the-art method for audio-visual conditioned video prediction uses the latent codes of the audio-visual frames from a multimodal stochastic network and a frame encoder to predict the next visual frame. However, a direct inference of per-pixel intensity for the next visual frame from the latent codes is extremely challenging because of the high-dimensional image space. To this end, we propose to decouple the audio-visual conditioned video prediction into motion and appearance modeling. The first part is the multimodal motion estimation module that learns motion information as optical flow from the given audio-visual clip. The second part is the context-aware refinement module that uses the predicted optical flow to warp the current visual frame into the next visual frame and refines it base on the given audio-visual context. Experimental results show that our method achieves competitive results on existing benchmarks.
Towards the Detection of Diffusion Model Deepfakes
Oct 26, 2022
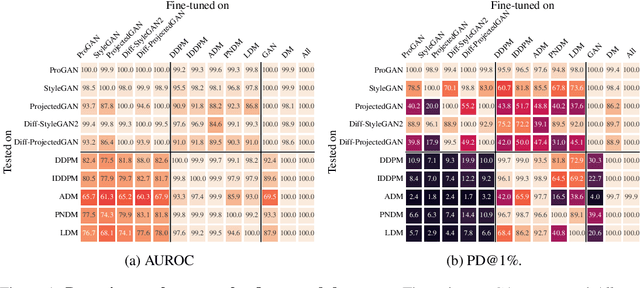
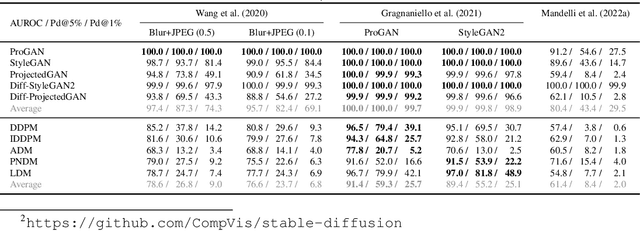
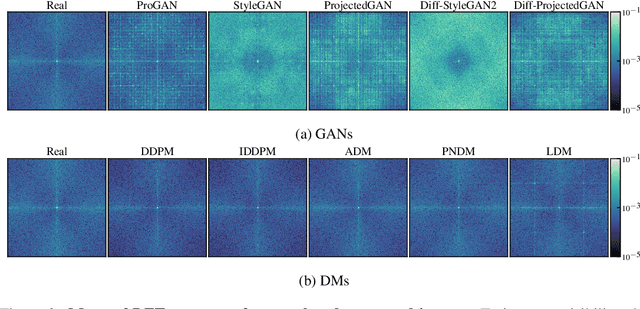
Diffusion models (DMs) have recently emerged as a promising method in image synthesis. They have surpassed generative adversarial networks (GANs) in both diversity and quality, and have achieved impressive results in text-to-image and image-to-image modeling. However, to date, only little attention has been paid to the detection of DM-generated images, which is critical to prevent adverse impacts on our society. Although prior work has shown that GAN-generated images can be reliably detected using automated methods, it is unclear whether the same methods are effective against DMs. In this work, we address this challenge and take a first look at detecting DM-generated images. We approach the problem from two different angles: First, we evaluate the performance of state-of-the-art detectors on a variety of DMs. Second, we analyze DM-generated images in the frequency domain and study different factors that influence the spectral properties of these images. Most importantly, we demonstrate that GANs and DMs produce images with different characteristics, which requires adaptation of existing classifiers to ensure reliable detection. We believe this work provides the foundation and starting point for further research to detect DM deepfakes effectively.
Investigating the Role of Image Retrieval for Visual Localization -- An exhaustive benchmark
May 31, 2022Visual localization, i.e., camera pose estimation in a known scene, is a core component of technologies such as autonomous driving and augmented reality. State-of-the-art localization approaches often rely on image retrieval techniques for one of two purposes: (1) provide an approximate pose estimate or (2) determine which parts of the scene are potentially visible in a given query image. It is common practice to use state-of-the-art image retrieval algorithms for both of them. These algorithms are often trained for the goal of retrieving the same landmark under a large range of viewpoint changes which often differs from the requirements of visual localization. In order to investigate the consequences for visual localization, this paper focuses on understanding the role of image retrieval for multiple visual localization paradigms. First, we introduce a novel benchmark setup and compare state-of-the-art retrieval representations on multiple datasets using localization performance as metric. Second, we investigate several definitions of "ground truth" for image retrieval. Using these definitions as upper bounds for the visual localization paradigms, we show that there is still sgnificant room for improvement. Third, using these tools and in-depth analysis, we show that retrieval performance on classical landmark retrieval or place recognition tasks correlates only for some but not all paradigms to localization performance. Finally, we analyze the effects of blur and dynamic scenes in the images. We conclude that there is a need for retrieval approaches specifically designed for localization paradigms. Our benchmark and evaluation protocols are available at https://github.com/naver/kapture-localization.
Galaxy Image Deconvolution for Weak Gravitational Lensing with Physics-informed Deep Learning
Nov 03, 2022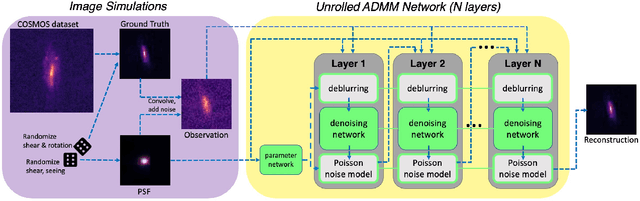
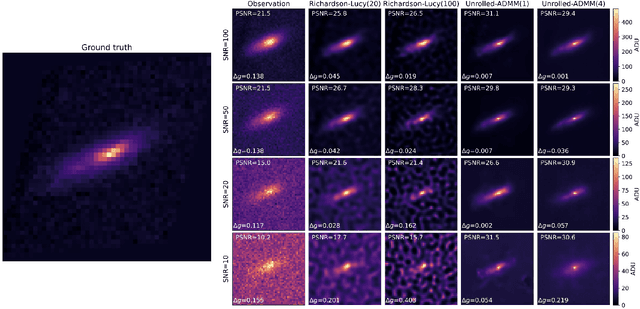
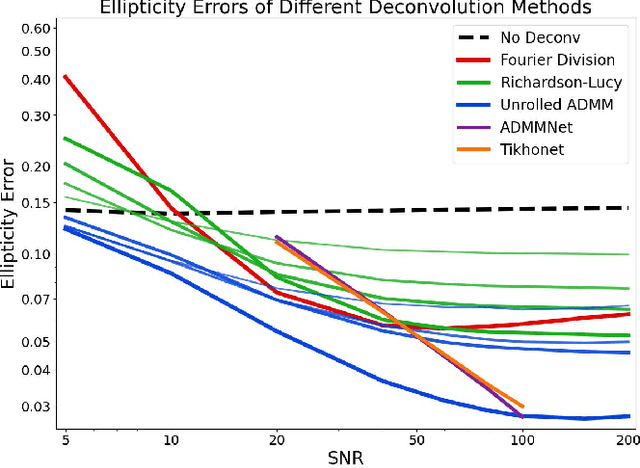
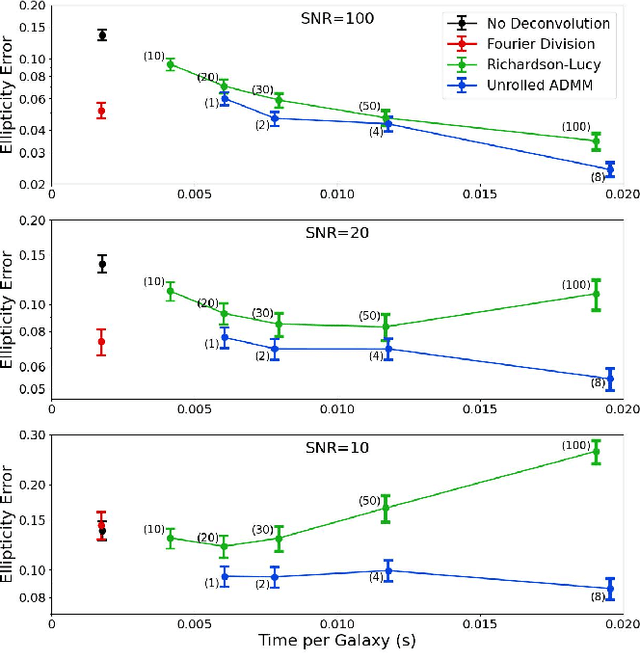
Removing optical and atmospheric blur from galaxy images significantly improves galaxy shape measurements for weak gravitational lensing and galaxy evolution studies. This ill-posed linear inverse problem is usually solved with deconvolution algorithms enhanced by regularisation priors or deep learning. We introduce a so-called "physics-based deep learning" approach to the Point Spread Function (PSF) deconvolution problem in galaxy surveys. We apply algorithm unrolling and the Plug-and-Play technique to the Alternating Direction Method of Multipliers (ADMM) with a Poisson noise model and use a neural network to learn appropriate priors from simulated galaxy images. We characterise the time-performance trade-off of several methods for galaxies of differing brightness levels, showing an improvement of 26% (SNR=20)/48% (SNR=100) compared to standard methods and 14% (SNR=20) compared to modern methods.
Exploring Patch-wise Semantic Relation for Contrastive Learning in Image-to-Image Translation Tasks
Mar 03, 2022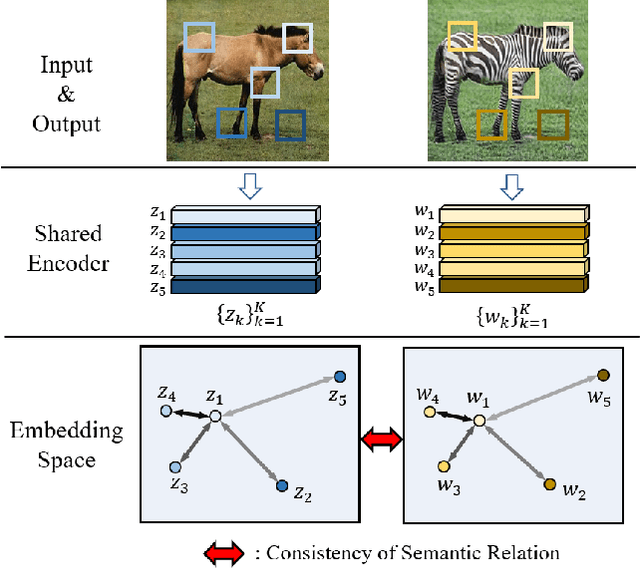
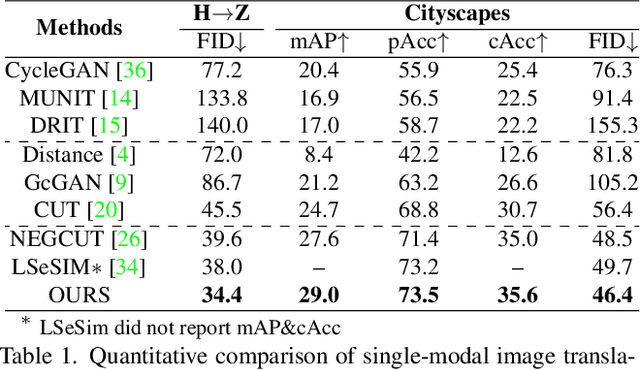
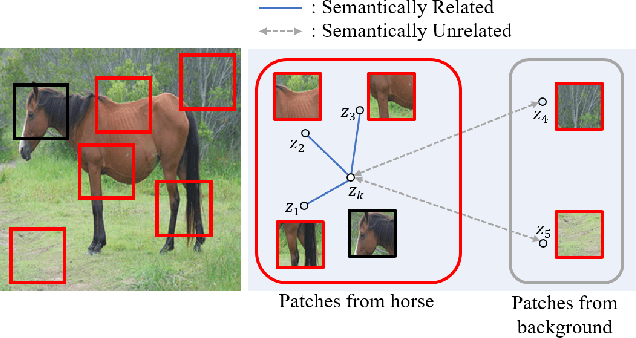
Recently, contrastive learning-based image translation methods have been proposed, which contrasts different spatial locations to enhance the spatial correspondence. However, the methods often ignore the diverse semantic relation within the images. To address this, here we propose a novel semantic relation consistency (SRC) regularization along with the decoupled contrastive learning, which utilize the diverse semantics by focusing on the heterogeneous semantics between the image patches of a single image. To further improve the performance, we present a hard negative mining by exploiting the semantic relation. We verified our method for three tasks: single-modal and multi-modal image translations, and GAN compression task for image translation. Experimental results confirmed the state-of-art performance of our method in all the three tasks.
Style-Hallucinated Dual Consistency Learning: A Unified Framework for Visual Domain Generalization
Dec 18, 2022
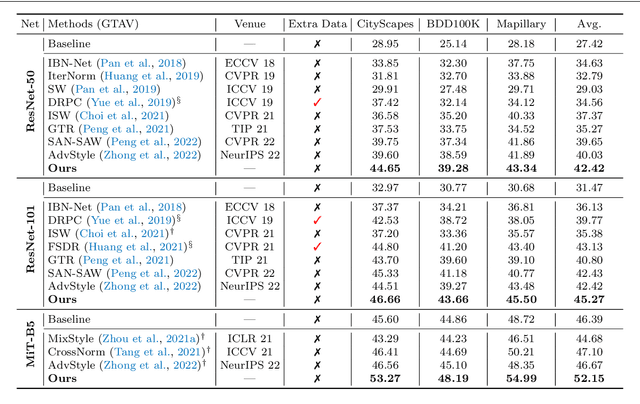
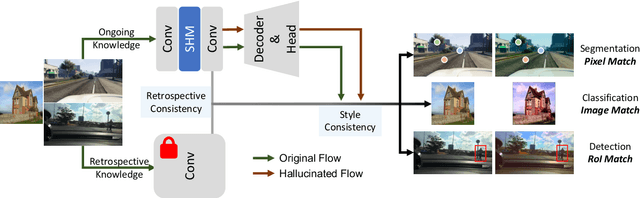
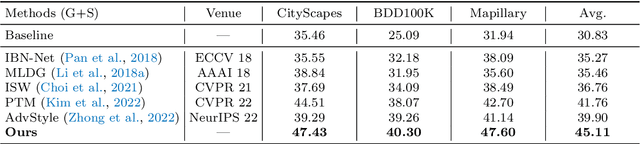
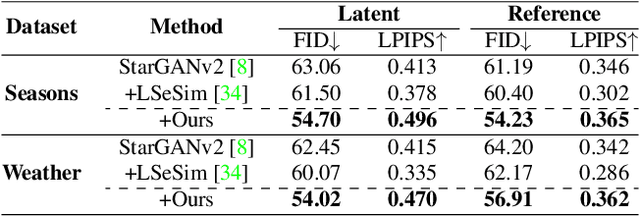
Domain shift widely exists in the visual world, while modern deep neural networks commonly suffer from severe performance degradation under domain shift due to the poor generalization ability, which limits the real-world applications. The domain shift mainly lies in the limited source environmental variations and the large distribution gap between source and unseen target data. To this end, we propose a unified framework, Style-HAllucinated Dual consistEncy learning (SHADE), to handle such domain shift in various visual tasks. Specifically, SHADE is constructed based on two consistency constraints, Style Consistency (SC) and Retrospection Consistency (RC). SC enriches the source situations and encourages the model to learn consistent representation across style-diversified samples. RC leverages general visual knowledge to prevent the model from overfitting to source data and thus largely keeps the representation consistent between the source and general visual models. Furthermore, we present a novel style hallucination module (SHM) to generate style-diversified samples that are essential to consistency learning. SHM selects basis styles from the source distribution, enabling the model to dynamically generate diverse and realistic samples during training. Extensive experiments demonstrate that our versatile SHADE can significantly enhance the generalization in various visual recognition tasks, including image classification, semantic segmentation and object detection, with different models, i.e., ConvNets and Transformer.
Seeing What You Miss: Vision-Language Pre-training with Semantic Completion Learning
Nov 24, 2022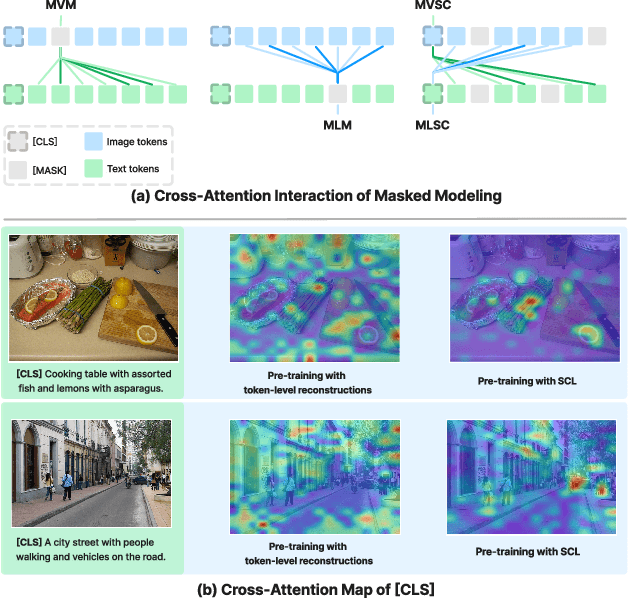
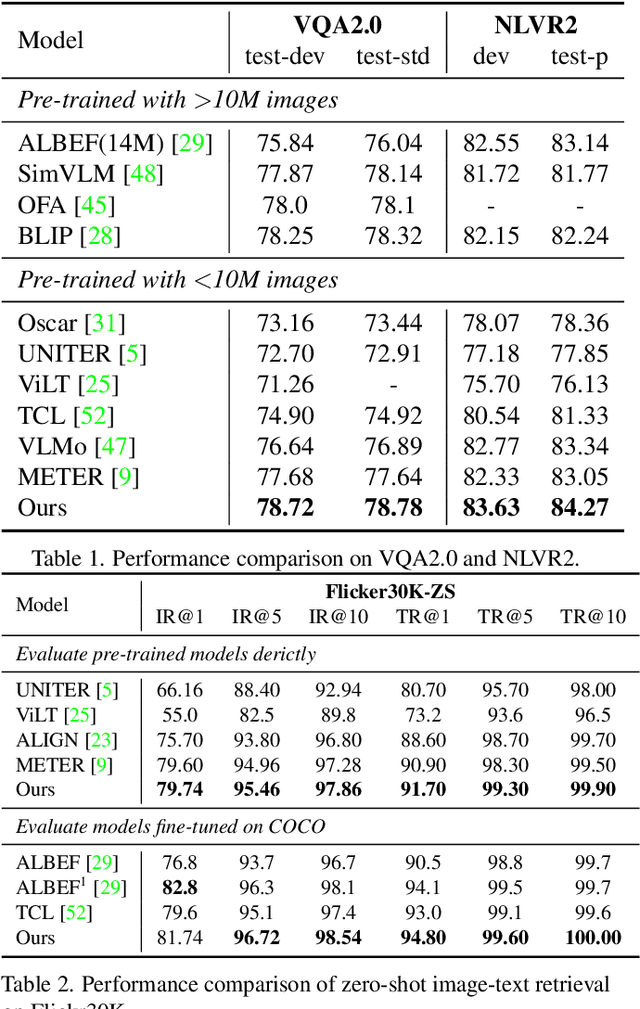
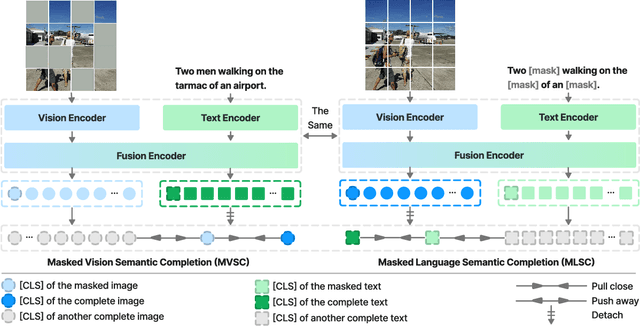
Cross-modal alignment is essential for vision-language pre-training (VLP) models to learn the correct corresponding information across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-to-local alignment. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in the limited cross-modal alignment ability of global representations. Therefore, in this paper, we propose a novel Semantic Completion Learning (SCL) task, complementary to existing masked modeling tasks, to facilitate global-to-local alignment. Specifically, the SCL task complements the missing semantics of masked data by capturing the corresponding information from the other modality, promoting learning more representative global features which have a great impact on the performance of downstream tasks. Moreover, we present a flexible vision encoder, which enables our model to perform image-text and video-text multimodal tasks simultaneously. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.
Residual Swin Transformer Channel Attention Network for Image Demosaicing
Apr 14, 2022
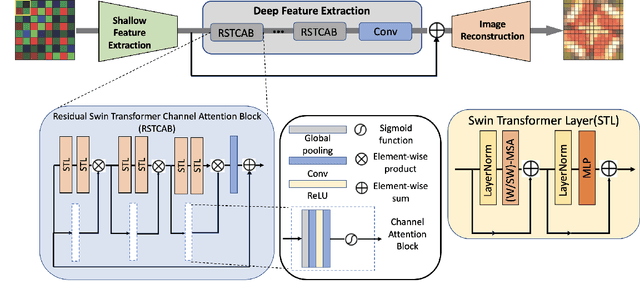
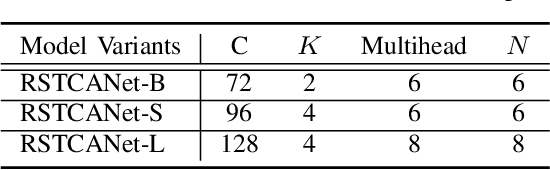
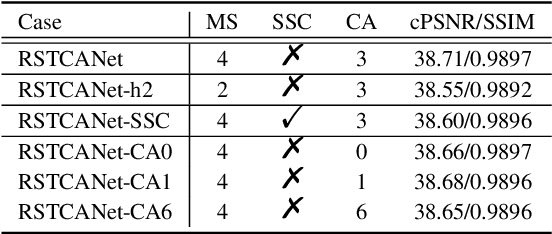
Image demosaicing is problem of interpolating full- resolution color images from raw sensor (color filter array) data. During last decade, deep neural networks have been widely used in image restoration, and in particular, in demosaicing, attaining significant performance improvement. In recent years, vision transformers have been designed and successfully used in various computer vision applications. One of the recent methods of image restoration based on a Swin Transformer (ST), SwinIR, demonstrates state-of-the-art performance with a smaller number of parameters than neural network-based methods. Inspired by the success of SwinIR, we propose in this paper a novel Swin Transformer-based network for image demosaicing, called RSTCANet. To extract image features, RSTCANet stacks several residual Swin Transformer Channel Attention blocks (RSTCAB), introducing the channel attention for each two successive ST blocks. Extensive experiments demonstrate that RSTCANet out- performs state-of-the-art image demosaicing methods, and has a smaller number of parameters.