 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Tackling Ambiguity with Images: Improved Multimodal Machine Translation and Contrastive Evaluation
Dec 20, 2022


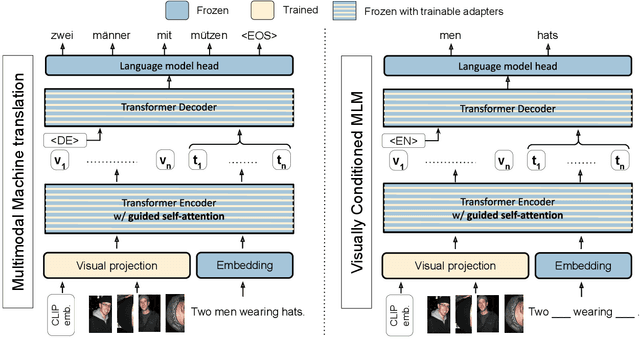
One of the major challenges of machine translation (MT) is ambiguity, which can in some cases be resolved by accompanying context such as an image. However, recent work in multimodal MT (MMT) has shown that obtaining improvements from images is challenging, limited not only by the difficulty of building effective cross-modal representations but also by the lack of specific evaluation and training data. We present a new MMT approach based on a strong text-only MT model, which uses neural adapters and a novel guided self-attention mechanism and which is jointly trained on both visual masking and MMT. We also release CoMMuTE, a Contrastive Multilingual Multimodal Translation Evaluation dataset, composed of ambiguous sentences and their possible translations, accompanied by disambiguating images corresponding to each translation. Our approach obtains competitive results over strong text-only models on standard English-to-French benchmarks and outperforms these baselines and state-of-the-art MMT systems with a large margin on our contrastive test set.
Beyond Cross-view Image Retrieval: Highly Accurate Vehicle Localization Using Satellite Image
Apr 10, 2022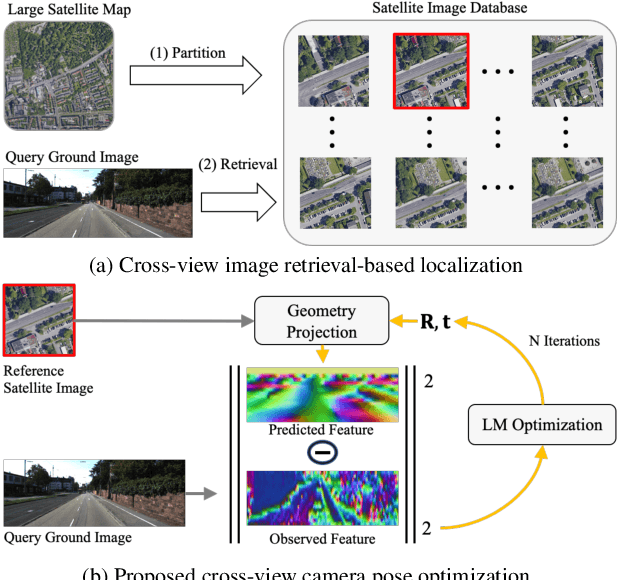
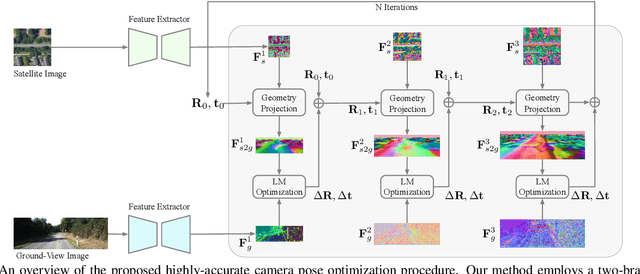


This paper addresses the problem of vehicle-mounted camera localization by matching a ground-level image with an overhead-view satellite map. Existing methods often treat this problem as cross-view image retrieval, and use learned deep features to match the ground-level query image to a partition (eg, a small patch) of the satellite map. By these methods, the localization accuracy is limited by the partitioning density of the satellite map (often in the order of tens meters). Departing from the conventional wisdom of image retrieval, this paper presents a novel solution that can achieve highly-accurate localization. The key idea is to formulate the task as pose estimation and solve it by neural-net based optimization. Specifically, we design a two-branch {CNN} to extract robust features from the ground and satellite images, respectively. To bridge the vast cross-view domain gap, we resort to a Geometry Projection module that projects features from the satellite map to the ground-view, based on a relative camera pose. Aiming to minimize the differences between the projected features and the observed features, we employ a differentiable Levenberg-Marquardt ({LM}) module to search for the optimal camera pose iteratively. The entire pipeline is differentiable and runs end-to-end. Extensive experiments on standard autonomous vehicle localization datasets have confirmed the superiority of the proposed method. Notably, e.g., starting from a coarse estimate of camera location within a wide region of 40m x 40m, with an 80% likelihood our method quickly reduces the lateral location error to be within 5m on a new KITTI cross-view dataset.
TexPose: Neural Texture Learning for Self-Supervised 6D Object Pose Estimation
Dec 25, 2022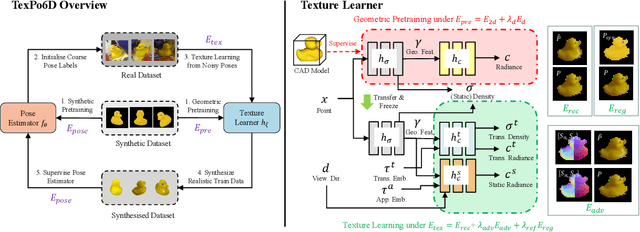
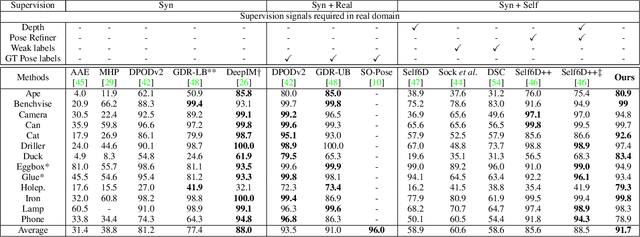

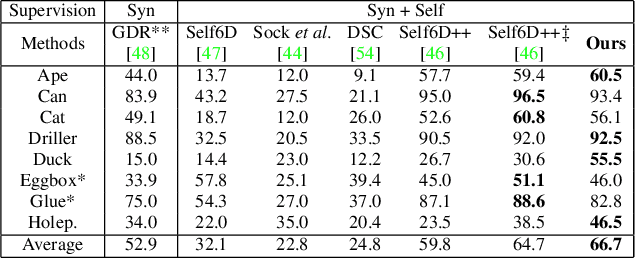
In this paper, we introduce neural texture learning for 6D object pose estimation from synthetic data and a few unlabelled real images. Our major contribution is a novel learning scheme which removes the drawbacks of previous works, namely the strong dependency on co-modalities or additional refinement. These have been previously necessary to provide training signals for convergence. We formulate such a scheme as two sub-optimisation problems on texture learning and pose learning. We separately learn to predict realistic texture of objects from real image collections and learn pose estimation from pixel-perfect synthetic data. Combining these two capabilities allows then to synthesise photorealistic novel views to supervise the pose estimator with accurate geometry. To alleviate pose noise and segmentation imperfection present during the texture learning phase, we propose a surfel-based adversarial training loss together with texture regularisation from synthetic data. We demonstrate that the proposed approach significantly outperforms the recent state-of-the-art methods without ground-truth pose annotations and demonstrates substantial generalisation improvements towards unseen scenes. Remarkably, our scheme improves the adopted pose estimators substantially even when initialised with much inferior performance.
Accurate, Low-latency, Efficient SAR Automatic Target Recognition on FPGA
Jan 04, 2023
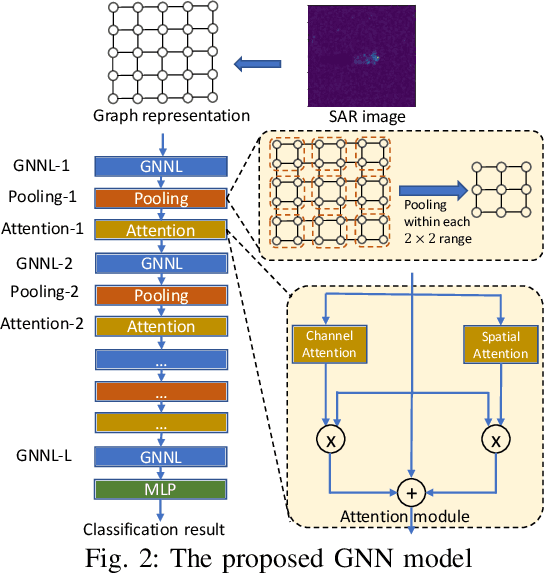
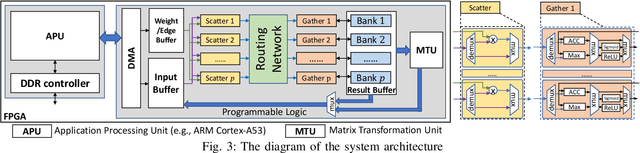
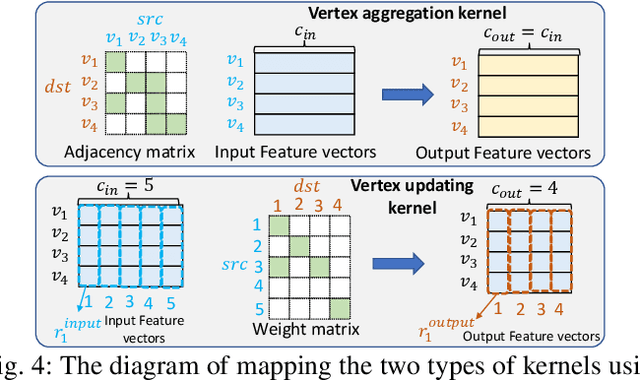
Synthetic aperture radar (SAR) automatic target recognition (ATR) is the key technique for remote-sensing image recognition. The state-of-the-art convolutional neural networks (CNNs) for SAR ATR suffer from \emph{high computation cost} and \emph{large memory footprint}, making them unsuitable to be deployed on resource-limited platforms, such as small/micro satellites. In this paper, we propose a comprehensive GNN-based model-architecture {co-design} on FPGA to address the above issues. \emph{Model design}: we design a novel graph neural network (GNN) for SAR ATR. The proposed GNN model incorporates GraphSAGE layer operators and attention mechanism, achieving comparable accuracy as the state-of-the-art work with near $1/100$ computation cost. Then, we propose a pruning approach including weight pruning and input pruning. While weight pruning through lasso regression reduces most parameters without accuracy drop, input pruning eliminates most input pixels with negligible accuracy drop. \emph{Architecture design}: to fully unleash the computation parallelism within the proposed model, we develop a novel unified hardware architecture that can execute various computation kernels (feature aggregation, feature transformation, graph pooling). The proposed hardware design adopts the Scatter-Gather paradigm to efficiently handle the irregular computation {patterns} of various computation kernels. We deploy the proposed design on an embedded FPGA (AMD Xilinx ZCU104) and evaluate the performance using MSTAR dataset. Compared with the state-of-the-art CNNs, the proposed GNN achieves comparable accuracy with $1/3258$ computation cost and $1/83$ model size. Compared with the state-of-the-art CPU/GPU, our FPGA accelerator achieves $14.8\times$/$2.5\times$ speedup (latency) and is $62\times$/$39\times$ more energy efficient.
NAFSSR: Stereo Image Super-Resolution Using NAFNet
Apr 26, 2022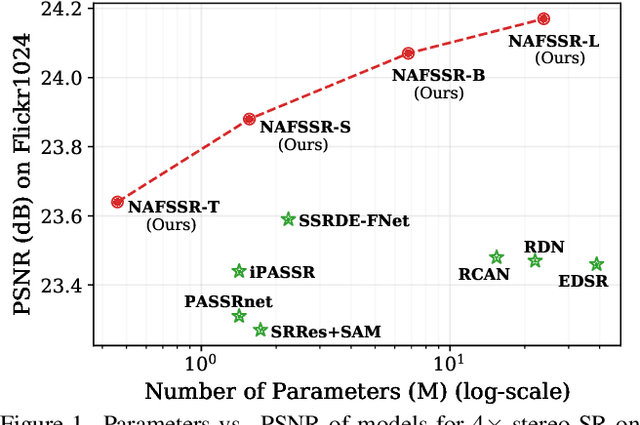
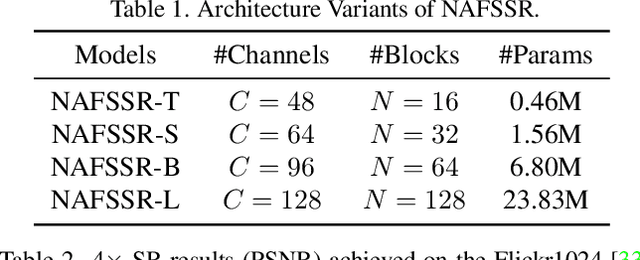
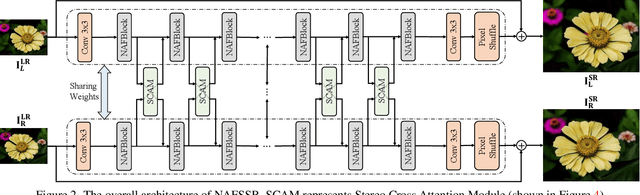
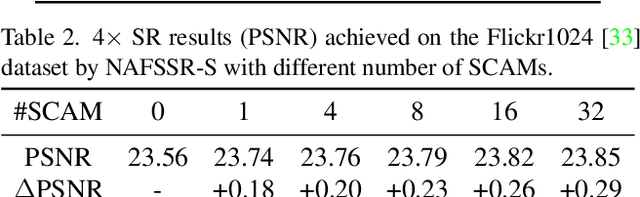
Stereo image super-resolution aims at enhancing the quality of super-resolution results by utilizing the complementary information provided by binocular systems. To obtain reasonable performance, most methods focus on finely designing modules, loss functions, and etc. to exploit information from another viewpoint. This has the side effect of increasing system complexity, making it difficult for researchers to evaluate new ideas and compare methods. This paper inherits a strong and simple image restoration model, NAFNet, for single-view feature extraction and extends it by adding cross attention modules to fuse features between views to adapt to binocular scenarios. The proposed baseline for stereo image super-resolution is noted as NAFSSR. Furthermore, training/testing strategies are proposed to fully exploit the performance of NAFSSR. Extensive experiments demonstrate the effectiveness of our method. In particular, NAFSSR outperforms the state-of-the-art methods on the KITTI 2012, KITTI 2015, Middlebury, and Flickr1024 datasets. With NAFSSR, we won 1st place in the NTIRE 2022 Stereo Image Super-resolution Challenge. Codes and models will be released at https://github.com/megvii-research/NAFNet.
Rethinking Two Consensuses of the Transferability in Deep Learning
Dec 01, 2022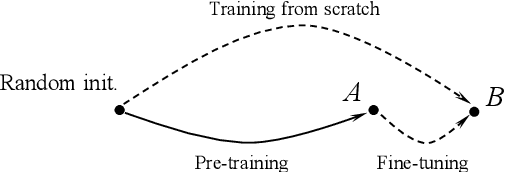
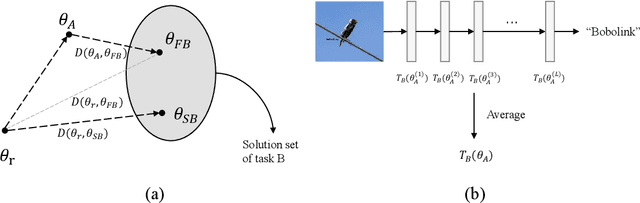

Deep transfer learning (DTL) has formed a long-term quest toward enabling deep neural networks (DNNs) to reuse historical experiences as efficiently as humans. This ability is named knowledge transferability. A commonly used paradigm for DTL is firstly learning general knowledge (pre-training) and then reusing (fine-tuning) them for a specific target task. There are two consensuses of transferability of pre-trained DNNs: (1) a larger domain gap between pre-training and downstream data brings lower transferability; (2) the transferability gradually decreases from lower layers (near input) to higher layers (near output). However, these consensuses were basically drawn from the experiments based on natural images, which limits their scope of application. This work aims to study and complement them from a broader perspective by proposing a method to measure the transferability of pre-trained DNN parameters. Our experiments on twelve diverse image classification datasets get similar conclusions to the previous consensuses. More importantly, two new findings are presented, i.e., (1) in addition to the domain gap, a larger data amount and huge dataset diversity of downstream target task also prohibit the transferability; (2) although the lower layers learn basic image features, they are usually not the most transferable layers due to their domain sensitivity.
A Strategy Optimized Pix2pix Approach for SAR-to-Optical Image Translation Task
Jul 04, 2022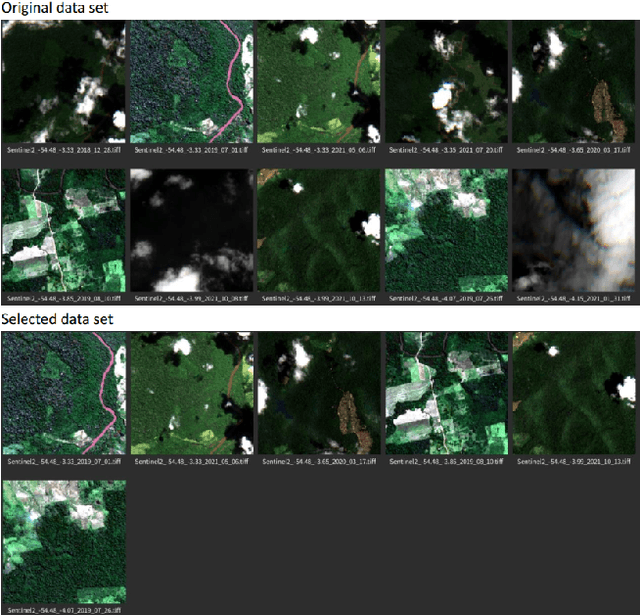
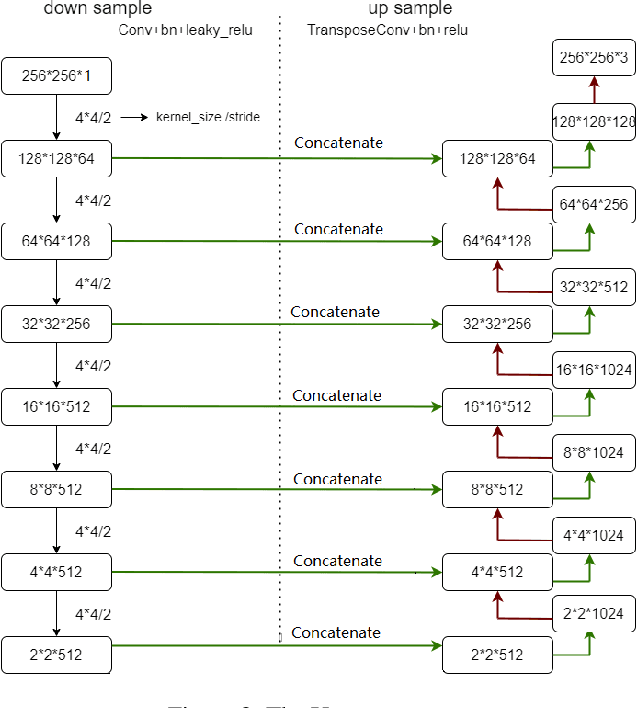


This technical report summarizes the analysis and approach on the image-to-image translation task in the Multimodal Learning for Earth and Environment Challenge (MultiEarth 2022). In terms of strategy optimization, cloud classification is utilized to filter optical images with dense cloud coverage to aid the supervised learning alike approach. The commonly used pix2pix framework with a few optimizations is applied to build the model. A weighted combination of mean squared error and mean absolute error is incorporated in the loss function. As for evaluation, peak to signal ratio and structural similarity were both considered in our preliminary analysis. Lastly, our method achieved the second place with a final error score of 0.0412. The results indicate great potential towards SAR-to-optical translation in remote sensing tasks, specifically for the support of long-term environmental monitoring and protection.
The Hateful Memes Challenge Next Move
Dec 18, 2022
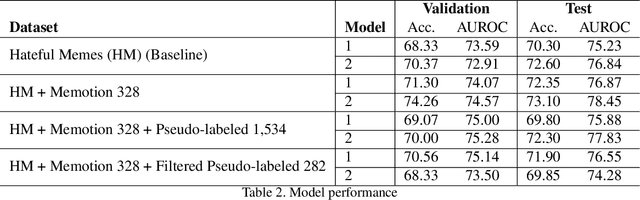
State-of-the-art image and text classification models, such as Convolutional Neural Networks and Transformers, have long been able to classify their respective unimodal reasoning satisfactorily with accuracy close to or exceeding human accuracy. However, images embedded with text, such as hateful memes, are hard to classify using unimodal reasoning when difficult examples, such as benign confounders, are incorporated into the data set. We attempt to generate more labeled memes in addition to the Hateful Memes data set from Facebook AI, based on the framework of a winning team from the Hateful Meme Challenge. To increase the number of labeled memes, we explore semi-supervised learning using pseudo-labels for newly introduced, unlabeled memes gathered from the Memotion Dataset 7K. We find that the semi-supervised learning task on unlabeled data required human intervention and filtering and that adding a limited amount of new data yields no extra classification performance.
Development and Evaluation of a Learning-based Model for Real-time Haptic Texture Rendering
Dec 27, 2022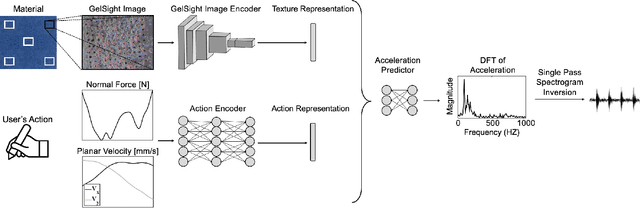

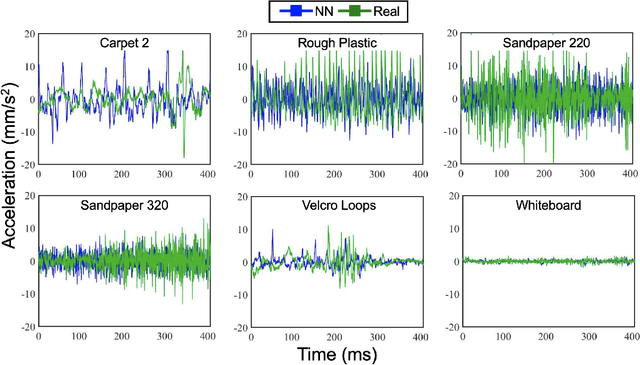

Current Virtual Reality (VR) environments lack the rich haptic signals that humans experience during real-life interactions, such as the sensation of texture during lateral movement on a surface. Adding realistic haptic textures to VR environments requires a model that generalizes to variations of a user's interaction and to the wide variety of existing textures in the world. Current methodologies for haptic texture rendering exist, but they usually develop one model per texture, resulting in low scalability. We present a deep learning-based action-conditional model for haptic texture rendering and evaluate its perceptual performance in rendering realistic texture vibrations through a multi part human user study. This model is unified over all materials and uses data from a vision-based tactile sensor (GelSight) to render the appropriate surface conditioned on the user's action in real time. For rendering texture, we use a high-bandwidth vibrotactile transducer attached to a 3D Systems Touch device. The result of our user study shows that our learning-based method creates high-frequency texture renderings with comparable or better quality than state-of-the-art methods without the need for learning a separate model per texture. Furthermore, we show that the method is capable of rendering previously unseen textures using a single GelSight image of their surface.
Compressive Image Classification using Deterministic Sensing Matrices
Oct 15, 2022
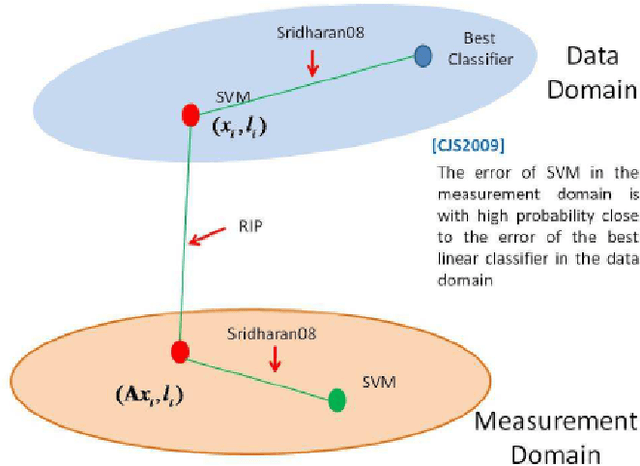
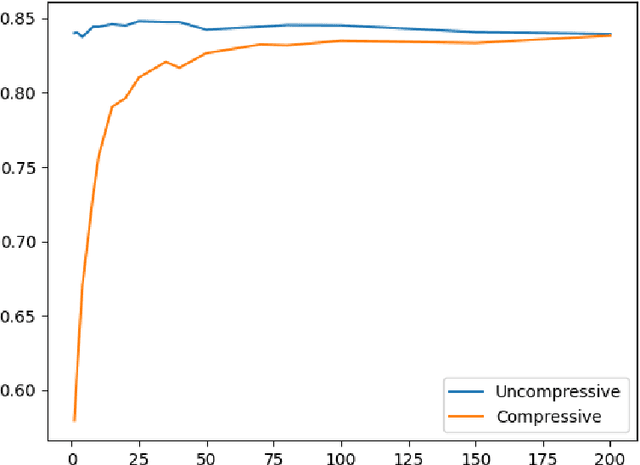
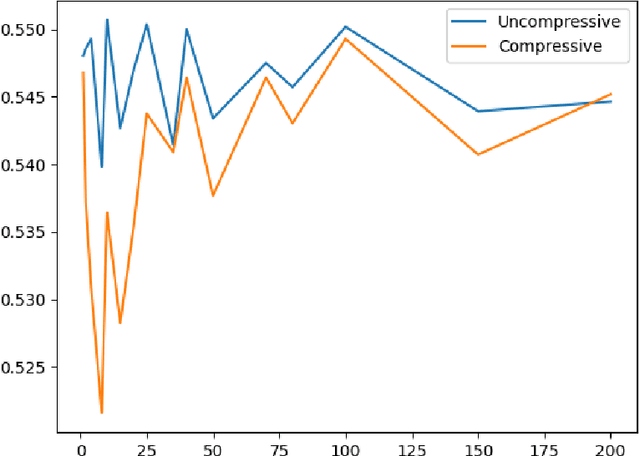
We look at the use of deterministic sensing matrices for compressed sensing and provide worst-case bounds on the classification accuracy of SVMs on compressively sensed data.