 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Degenerate Swin to Win: Plain Window-based Transformer without Sophisticated Operations
Nov 25, 2022


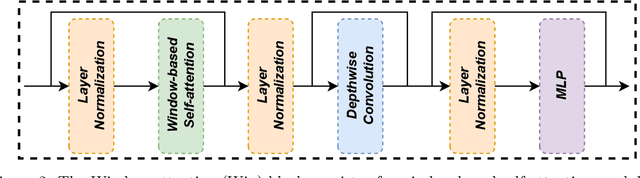
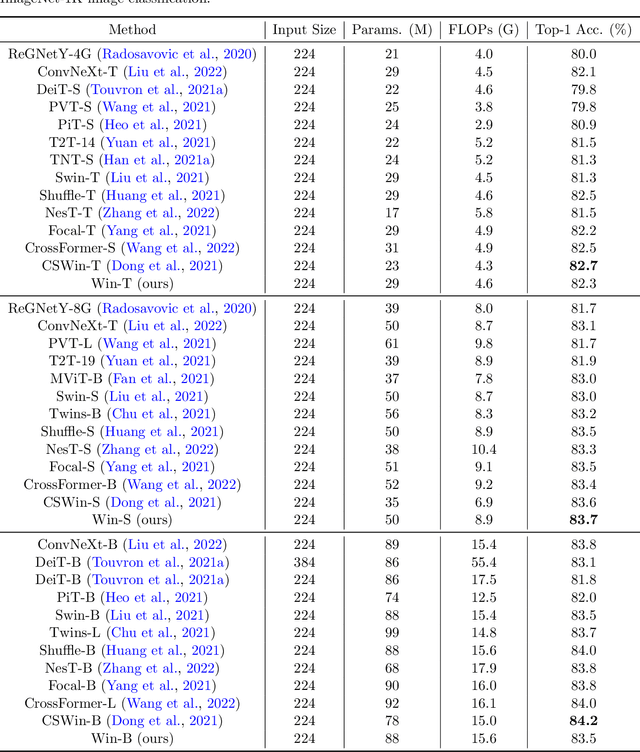
The formidable accomplishment of Transformers in natural language processing has motivated the researchers in the computer vision community to build Vision Transformers. Compared with the Convolution Neural Networks (CNN), a Vision Transformer has a larger receptive field which is capable of characterizing the long-range dependencies. Nevertheless, the large receptive field of Vision Transformer is accompanied by the huge computational cost. To boost efficiency, the window-based Vision Transformers emerge. They crop an image into several local windows, and the self-attention is conducted within each window. To bring back the global receptive field, window-based Vision Transformers have devoted a lot of efforts to achieving cross-window communications by developing several sophisticated operations. In this work, we check the necessity of the key design element of Swin Transformer, the shifted window partitioning. We discover that a simple depthwise convolution is sufficient for achieving effective cross-window communications. Specifically, with the existence of the depthwise convolution, the shifted window configuration in Swin Transformer cannot lead to an additional performance improvement. Thus, we degenerate the Swin Transformer to a plain Window-based (Win) Transformer by discarding sophisticated shifted window partitioning. The proposed Win Transformer is conceptually simpler and easier for implementation than Swin Transformer. Meanwhile, our Win Transformer achieves consistently superior performance than Swin Transformer on multiple computer vision tasks, including image recognition, semantic segmentation, and object detection.
From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models
Dec 21, 2022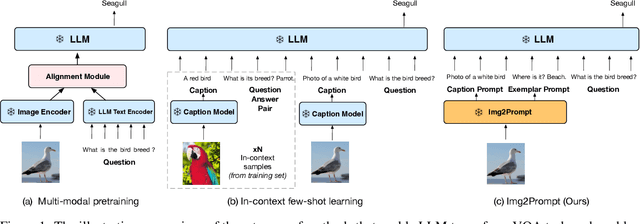
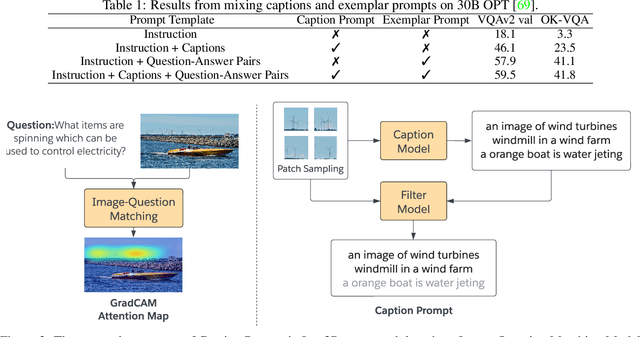

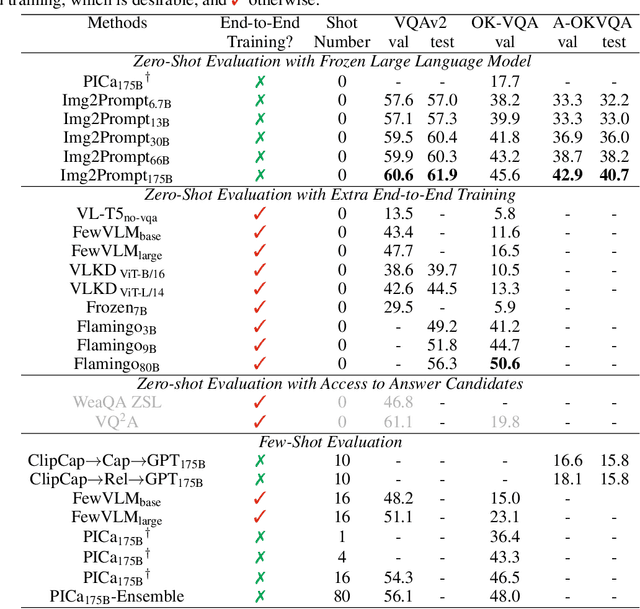
Large language models (LLMs) have demonstrated excellent zero-shot generalization to new language tasks. However, effective utilization of LLMs for zero-shot visual question-answering (VQA) remains challenging, primarily due to the modality disconnection and task disconnection between LLM and VQA task. End-to-end training on vision and language data may bridge the disconnections, but is inflexible and computationally expensive. To address this issue, we propose \emph{Img2Prompt}, a plug-and-play module that provides the prompts that can bridge the aforementioned modality and task disconnections, so that LLMs can perform zero-shot VQA tasks without end-to-end training. In order to provide such prompts, we further employ LLM-agnostic models to provide prompts that can describe image content and self-constructed question-answer pairs, which can effectively guide LLM to perform zero-shot VQA tasks. Img2Prompt offers the following benefits: 1) It can flexibly work with various LLMs to perform VQA. 2)~Without the needing of end-to-end training, it significantly reduces the cost of deploying LLM for zero-shot VQA tasks. 3) It achieves comparable or better performance than methods relying on end-to-end training. For example, we outperform Flamingo~\cite{Deepmind:Flamingo2022} by 5.6\% on VQAv2. On the challenging A-OKVQA dataset, our method even outperforms few-shot methods by as much as 20\%.
Sensitivity analysis of biological washout and depth selection for a machine learning based dose verification framework in proton therapy
Dec 21, 2022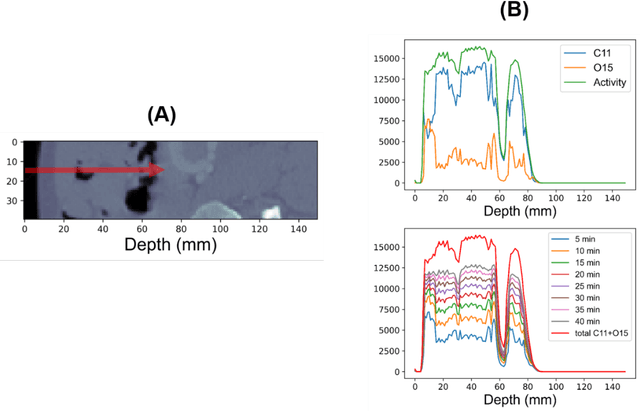
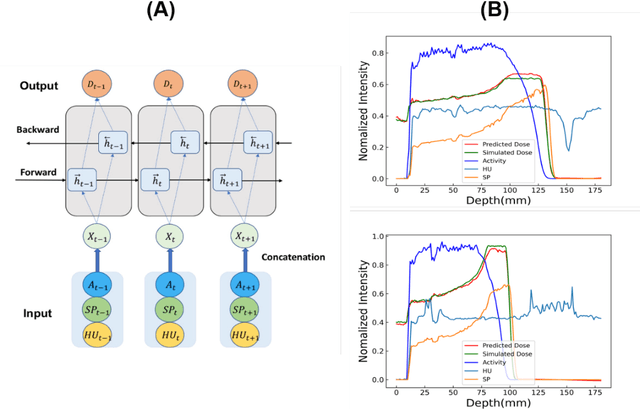
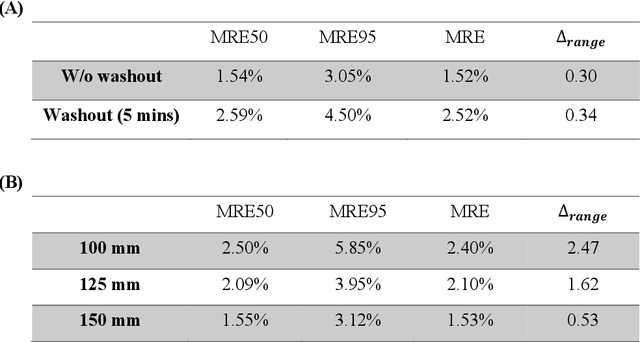
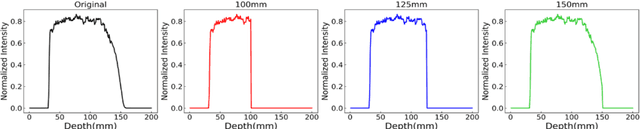
Dose verification based on proton-induced positron emitters is a promising quality assurance tool and may leverage the strength of artificial intelligence. To move a step closer towards practical application, the sensitivity analysis of two factors needs to be performed: biological washout and depth selection. selection. A bi-directional recurrent neural network (RNN) model was developed. The training dataset was generated based upon a CT image-based phantom (abdomen region) and multiple beam energies/pathways, using Monte-Carlo simulation (1 mm spatial resolution, no biological washout). For the modeling of biological washout, a simplified analytical model was applied to change raw activity profiles over a period of 5 minutes, incorporating both physical decay and biological washout. For the study of depth selection (a challenge linked to multi field/angle irradiation), truncations were applied at different window lengths (100, 125, 150 mm) to raw activity profiles. Finally, the performance of a worst-case scenario was examined by combining both factors (depth selection: 125 mm, biological washout: 5 mins). The accuracy was quantitatively evaluated in terms of range uncertainty, mean absolute error (MAE) and mean relative errors (MRE). Our proposed AI framework shows good immunity to the perturbation associated with two factors. The detection of proton-induced positron emitters, combined with machine learning, has great potential to implement online patient-specific verification in proton therapy.
Decision-making and control with metasurface-based diffractive neural networks
Dec 21, 2022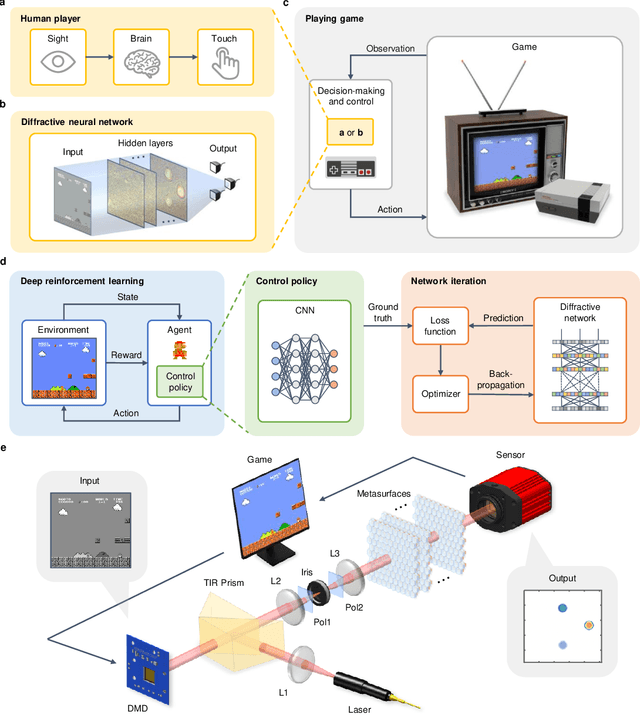
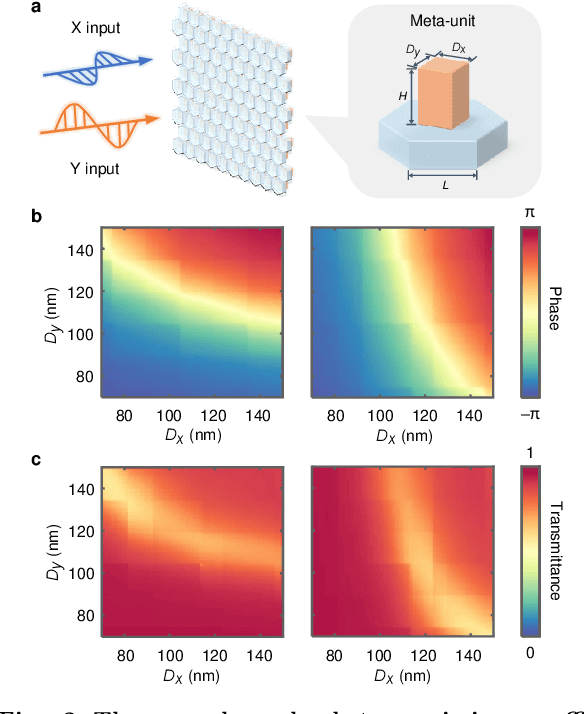

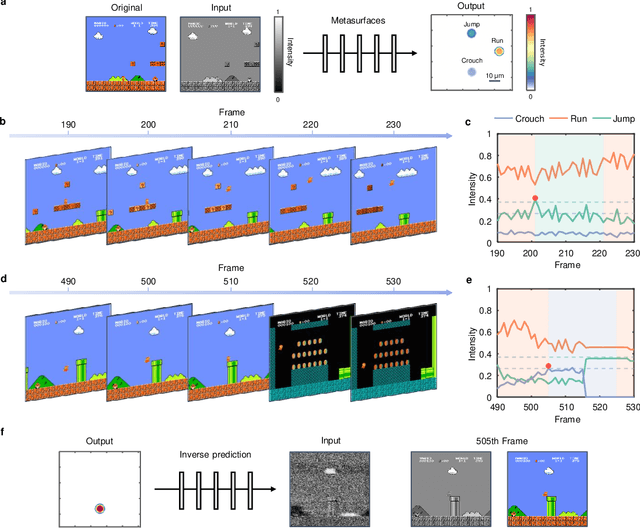
The ultimate goal of artificial intelligence is to mimic the human brain to perform decision-making and control directly from high-dimensional sensory input. All-optical diffractive neural networks provide a promising solution for realizing artificial intelligence with high-speed and low-power consumption. To date, most of the reported diffractive neural networks focus on single or multiple tasks that do not involve interaction with the environment, such as object recognition and image classification, while the networks that can perform decision-making and control, to our knowledge, have not been developed yet. Here, we propose to use deep reinforcement learning to realize diffractive neural networks that enable imitating the human-level capability of decision-making and control. Such networks allow for finding optimal control policies through interaction with the environment and can be readily realized with the dielectric metasurfaces. The superior performances of these networks are verified by engaging three types of classic games, Tic-Tac-Toe, Super Mario Bros., and Car Racing, and achieving the same or even higher levels comparable to human players. Our work represents a solid step of advancement in diffractive neural networks, which promises a fundamental shift from the target-driven control of a pre-designed state for simple recognition or classification tasks to the high-level sensory capability of artificial intelligence. It may find exciting applications in autonomous driving, intelligent robots, and intelligent manufacturing.
A CNN with Noise Inclined Module and Denoise Framework for Hyperspectral Image Classification
May 25, 2022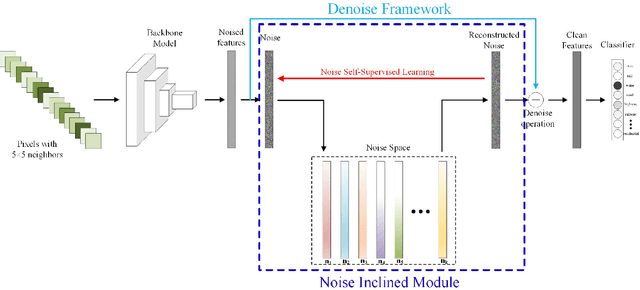
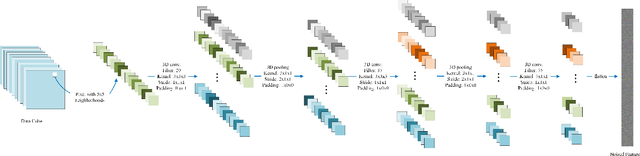
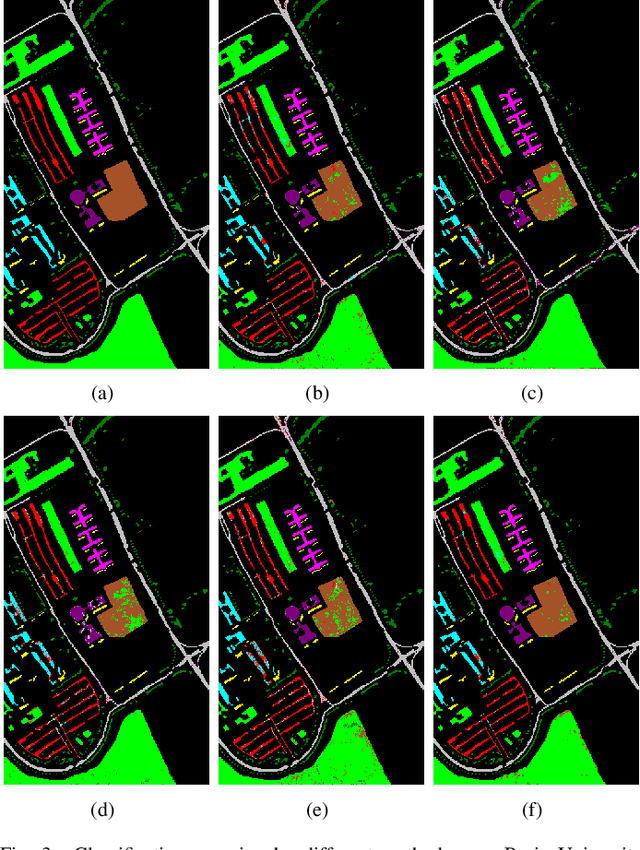
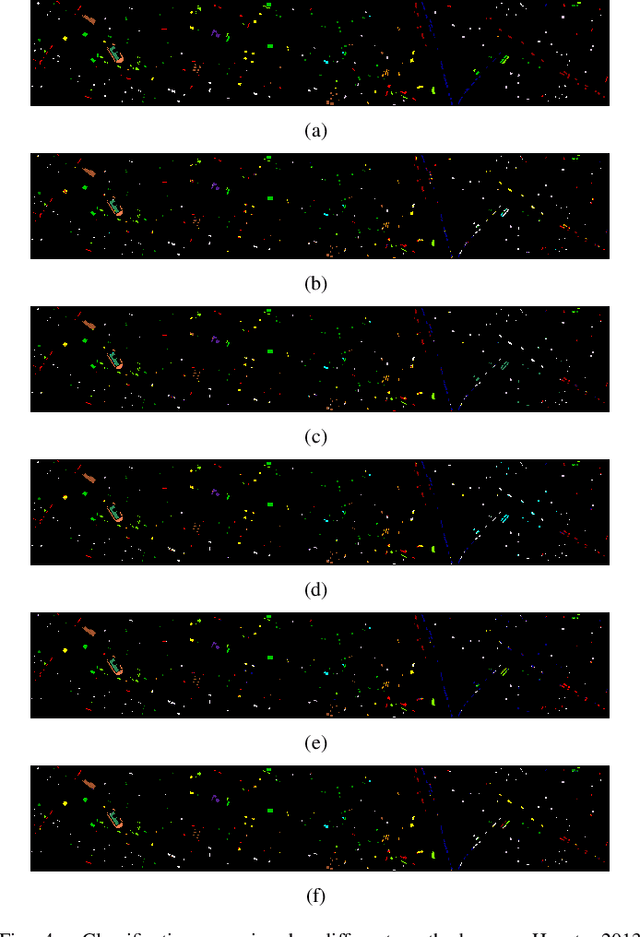
Deep Neural Networks have been successfully applied in hyperspectral image classification. However, most of prior works adopt general deep architectures while ignore the intrinsic structure of the hyperspectral image, such as the physical noise generation. This would make these deep models unable to generate discriminative features and provide impressive classification performance. To leverage such intrinsic information, this work develops a novel deep learning framework with the noise inclined module and denoise framework for hyperspectral image classification. First, we model the spectral signature of hyperspectral image with the physical noise model to describe the high intraclass variance of each class and great overlapping between different classes in the image. Then, a noise inclined module is developed to capture the physical noise within each object and a denoise framework is then followed to remove such noise from the object. Finally, the CNN with noise inclined module and the denoise framework is developed to obtain discriminative features and provides good classification performance of hyperspectral image. Experiments are conducted over two commonly used real-world datasets and the experimental results show the effectiveness of the proposed method. The implementation of the proposed method and other compared methods could be accessed at https://github.com/shendu-sw/noise-physical-framework.
A Dataless FaceSwap Detection Approach Using Synthetic Images
Dec 05, 2022
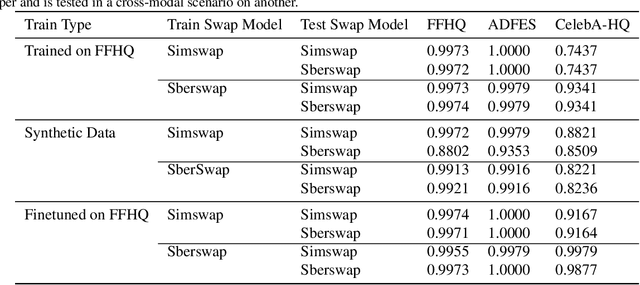

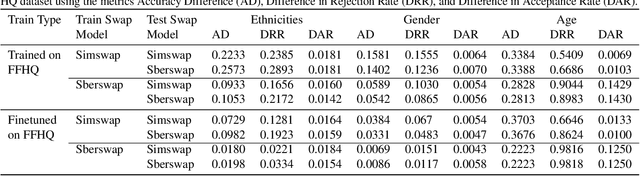
Face swapping technology used to create "Deepfakes" has advanced significantly over the past few years and now enables us to create realistic facial manipulations. Current deep learning algorithms to detect deepfakes have shown promising results, however, they require large amounts of training data, and as we show they are biased towards a particular ethnicity. We propose a deepfake detection methodology that eliminates the need for any real data by making use of synthetically generated data using StyleGAN3. This not only performs at par with the traditional training methodology of using real data but it shows better generalization capabilities when finetuned with a small amount of real data. Furthermore, this also reduces biases created by facial image datasets that might have sparse data from particular ethnicities.
Towards Smooth Video Composition
Dec 14, 2022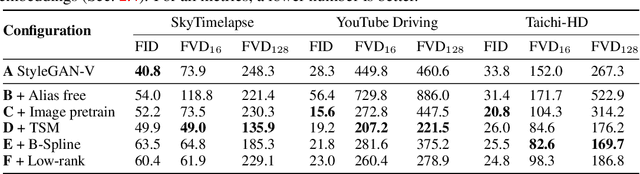

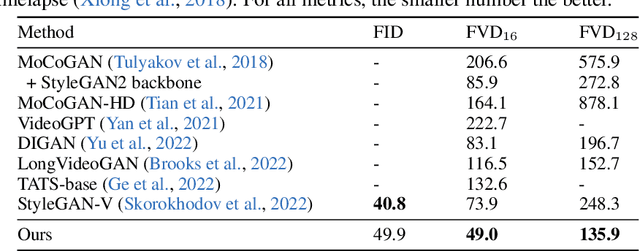

Video generation requires synthesizing consistent and persistent frames with dynamic content over time. This work investigates modeling the temporal relations for composing video with arbitrary length, from a few frames to even infinite, using generative adversarial networks (GANs). First, towards composing adjacent frames, we show that the alias-free operation for single image generation, together with adequately pre-learned knowledge, brings a smooth frame transition without compromising the per-frame quality. Second, by incorporating the temporal shift module (TSM), originally designed for video understanding, into the discriminator, we manage to advance the generator in synthesizing more consistent dynamics. Third, we develop a novel B-Spline based motion representation to ensure temporal smoothness to achieve infinite-length video generation. It can go beyond the frame number used in training. A low-rank temporal modulation is also proposed to alleviate repeating contents for long video generation. We evaluate our approach on various datasets and show substantial improvements over video generation baselines. Code and models will be publicly available at https://genforce.github.io/StyleSV.
Modeling Multimodal Aleatoric Uncertainty in Segmentation with Mixture of Stochastic Expert
Dec 14, 2022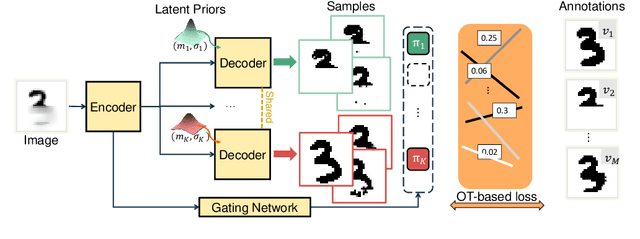
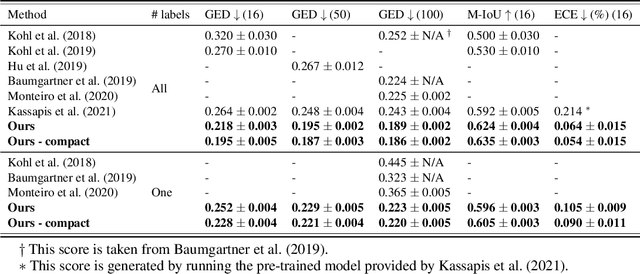
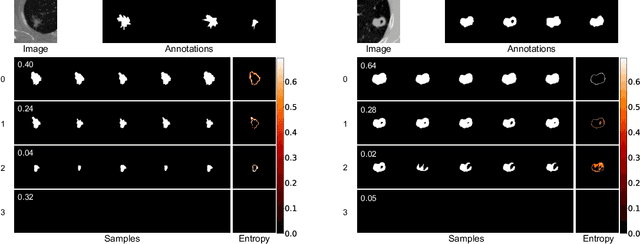
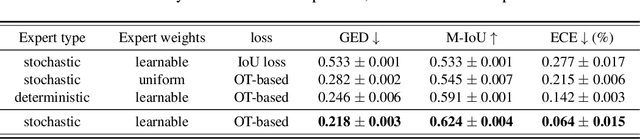
Equipping predicted segmentation with calibrated uncertainty is essential for safety-critical applications. In this work, we focus on capturing the data-inherent uncertainty (aka aleatoric uncertainty) in segmentation, typically when ambiguities exist in input images. Due to the high-dimensional output space and potential multiple modes in segmenting ambiguous images, it remains challenging to predict well-calibrated uncertainty for segmentation. To tackle this problem, we propose a novel mixture of stochastic experts (MoSE) model, where each expert network estimates a distinct mode of the aleatoric uncertainty and a gating network predicts the probabilities of an input image being segmented in those modes. This yields an efficient two-level uncertainty representation. To learn the model, we develop a Wasserstein-like loss that directly minimizes the distribution distance between the MoSE and ground truth annotations. The loss can easily integrate traditional segmentation quality measures and be efficiently optimized via constraint relaxation. We validate our method on the LIDC-IDRI dataset and a modified multimodal Cityscapes dataset. Results demonstrate that our method achieves the state-of-the-art or competitive performance on all metrics.
Explainable Artificial Intelligence in Retinal Imaging for the detection of Systemic Diseases
Dec 14, 2022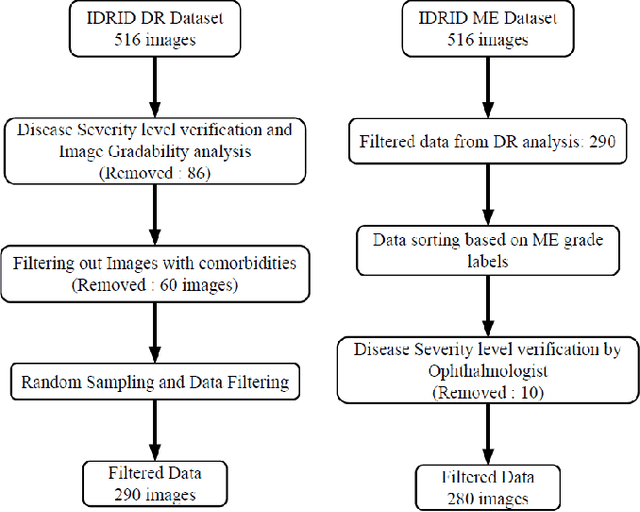
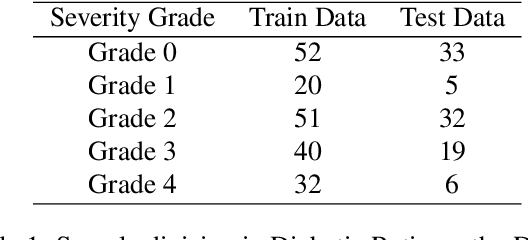
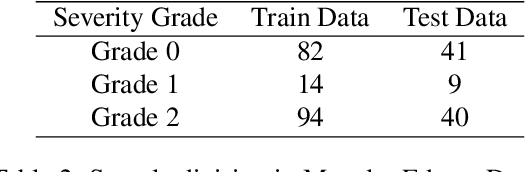
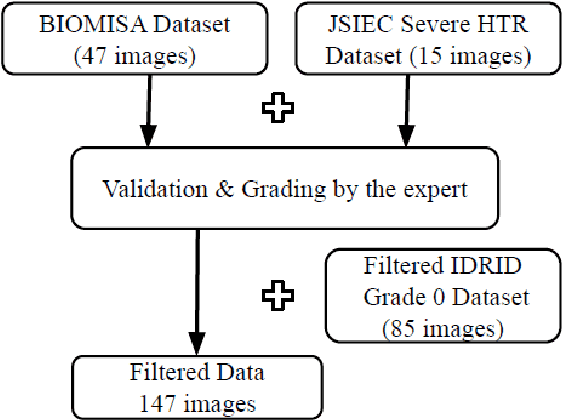
Explainable Artificial Intelligence (AI) in the form of an interpretable and semiautomatic approach to stage grading ocular pathologies such as Diabetic retinopathy, Hypertensive retinopathy, and other retinopathies on the backdrop of major systemic diseases. The experimental study aims to evaluate an explainable staged grading process without using deep Convolutional Neural Networks (CNNs) directly. Many current CNN-based deep neural networks used for diagnosing retinal disorders might have appreciable performance but fail to pinpoint the basis driving their decisions. To improve these decisions' transparency, we have proposed a clinician-in-the-loop assisted intelligent workflow that performs a retinal vascular assessment on the fundus images to derive quantifiable and descriptive parameters. The retinal vessel parameters meta-data serve as hyper-parameters for better interpretation and explainability of decisions. The semiautomatic methodology aims to have a federated approach to AI in healthcare applications with more inputs and interpretations from clinicians. The baseline process involved in the machine learning pipeline through image processing techniques for optic disc detection, vessel segmentation, and arteriole/venule identification.
Privacy-Preserving Image Classification Using Isotropic Network
Apr 16, 2022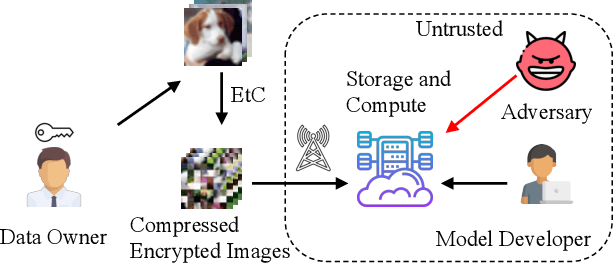
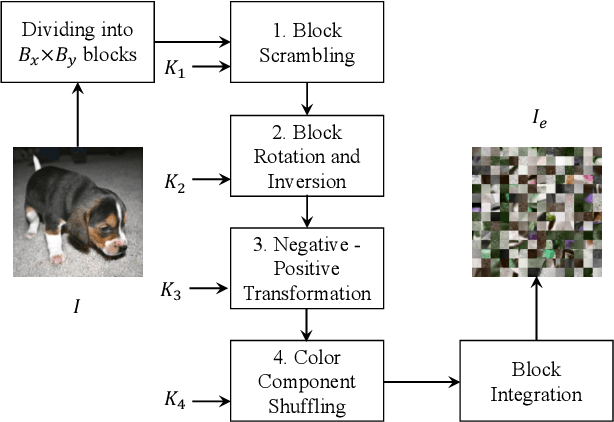
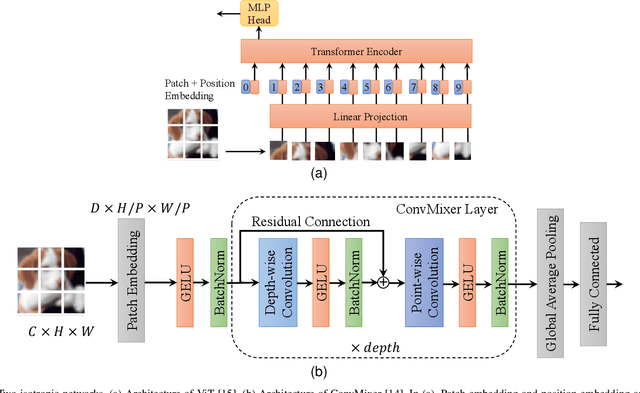
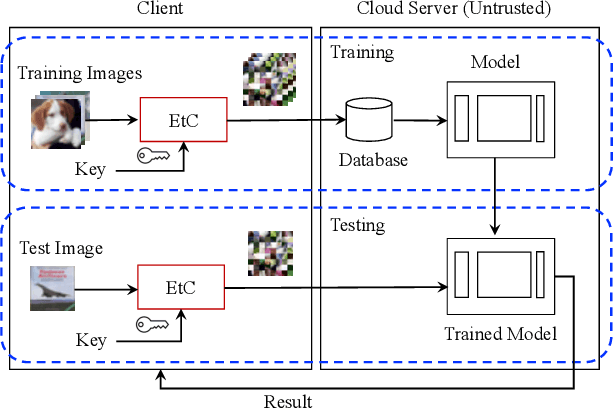
In this paper, we propose a privacy-preserving image classification method that uses encrypted images and an isotropic network such as the vision transformer. The proposed method allows us not only to apply images without visual information to deep neural networks (DNNs) for both training and testing but also to maintain a high classification accuracy. In addition, compressible encrypted images, called encryption-then-compression (EtC) images, can be used for both training and testing without any adaptation network. Previously, to classify EtC images, an adaptation network was required before a classification network, so methods with an adaptation network have been only tested on small images. To the best of our knowledge, previous privacy-preserving image classification methods have never considered image compressibility and patch embedding-based isotropic networks. In an experiment, the proposed privacy-preserving image classification was demonstrated to outperform state-of-the-art methods even when EtC images were used in terms of classification accuracy and robustness against various attacks under the use of two isotropic networks: vision transformer and ConvMixer.