 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PS-Transformer: Learning Sparse Photometric Stereo Network using Self-Attention Mechanism
Nov 21, 2022
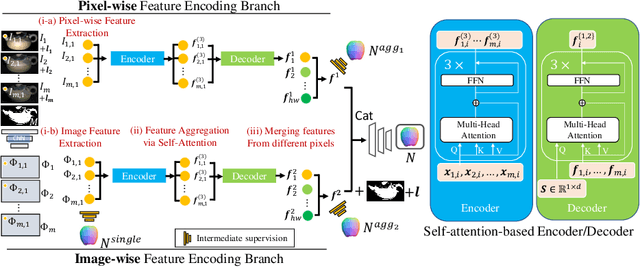
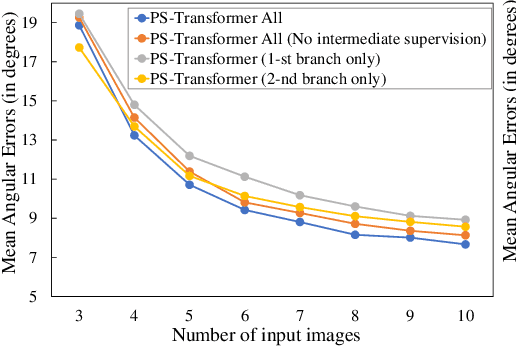
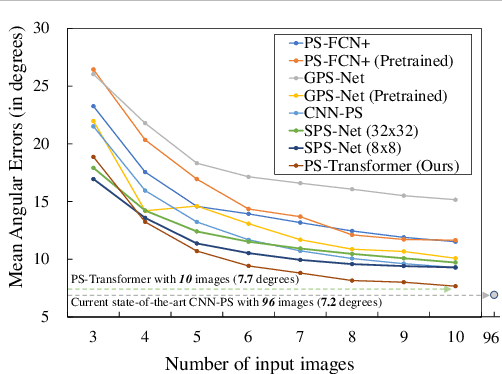
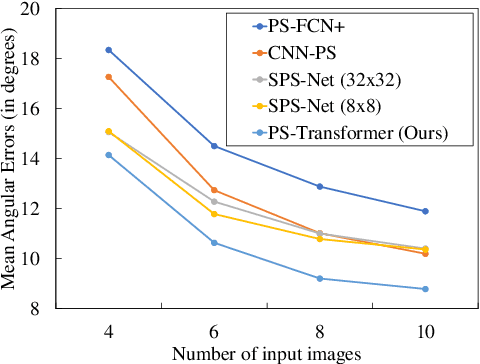
Existing deep calibrated photometric stereo networks basically aggregate observations under different lights based on the pre-defined operations such as linear projection and max pooling. While they are effective with the dense capture, simple first-order operations often fail to capture the high-order interactions among observations under small number of different lights. To tackle this issue, this paper presents a deep sparse calibrated photometric stereo network named {\it PS-Transformer} which leverages the learnable self-attention mechanism to properly capture the complex inter-image interactions. PS-Transformer builds upon the dual-branch design to explore both pixel-wise and image-wise features and individual feature is trained with the intermediate surface normal supervision to maximize geometric feasibility. A new synthetic dataset named CyclesPS+ is also presented with the comprehensive analysis to successfully train the photometric stereo networks. Extensive results on the publicly available benchmark datasets demonstrate that the surface normal prediction accuracy of the proposed method significantly outperforms other state-of-the-art algorithms with the same number of input images and is even comparable to that of dense algorithms which input 10$\times$ larger number of images.
* BMVC2021. Code and Supplementary are available at https://github.com/satoshi-ikehata/PS-Transformer-BMVC2021
Doubly Contrastive End-to-End Semantic Segmentation for Autonomous Driving under Adverse Weather
Nov 21, 2022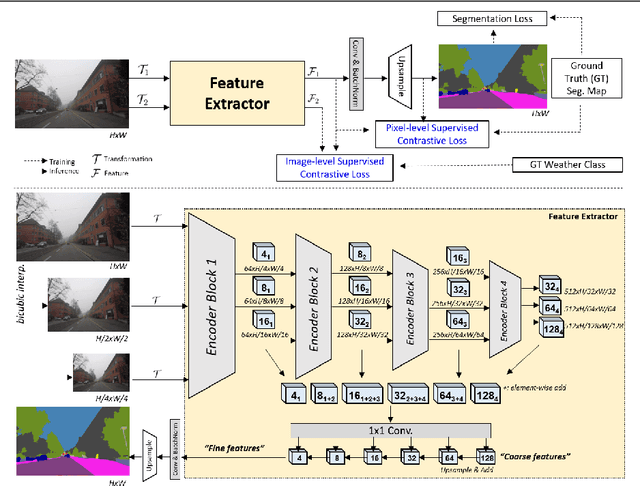
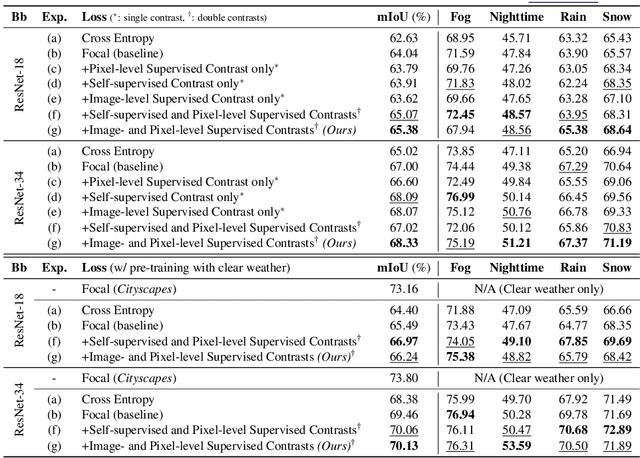

Road scene understanding tasks have recently become crucial for self-driving vehicles. In particular, real-time semantic segmentation is indispensable for intelligent self-driving agents to recognize roadside objects in the driving area. As prior research works have primarily sought to improve the segmentation performance with computationally heavy operations, they require far significant hardware resources for both training and deployment, and thus are not suitable for real-time applications. As such, we propose a doubly contrastive approach to improve the performance of a more practical lightweight model for self-driving, specifically under adverse weather conditions such as fog, nighttime, rain and snow. Our proposed approach exploits both image- and pixel-level contrasts in an end-to-end supervised learning scheme without requiring a memory bank for global consistency or the pretraining step used in conventional contrastive methods. We validate the effectiveness of our method using SwiftNet on the ACDC dataset, where it achieves up to 1.34%p improvement in mIoU (ResNet-18 backbone) at 66.7 FPS (2048x1024 resolution) on a single RTX 3080 Mobile GPU at inference. Furthermore, we demonstrate that replacing image-level supervision with self-supervision achieves comparable performance when pre-trained with clear weather images.
ProtoPFormer: Concentrating on Prototypical Parts in Vision Transformers for Interpretable Image Recognition
Aug 22, 2022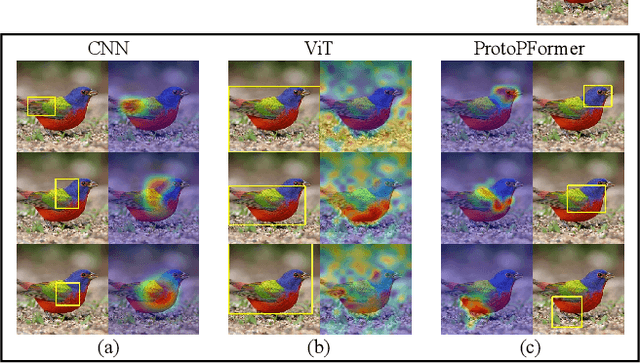
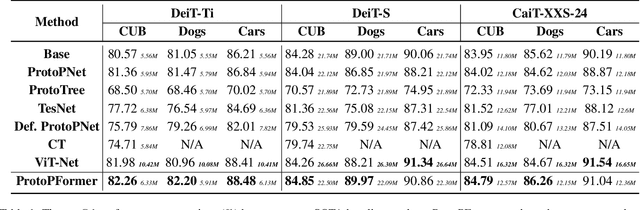
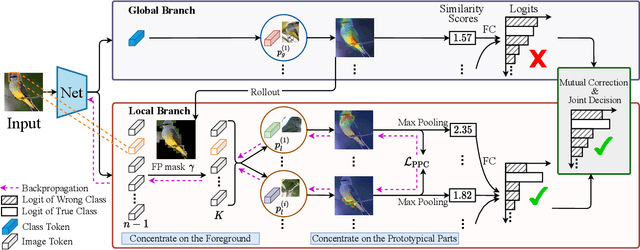
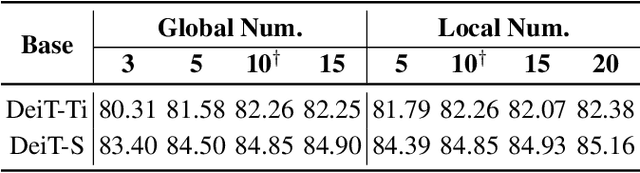
Prototypical part network (ProtoPNet) has drawn wide attention and boosted many follow-up studies due to its self-explanatory property for explainable artificial intelligence (XAI). However, when directly applying ProtoPNet on vision transformer (ViT) backbones, learned prototypes have a ''distraction'' problem: they have a relatively high probability of being activated by the background and pay less attention to the foreground. The powerful capability of modeling long-term dependency makes the transformer-based ProtoPNet hard to focus on prototypical parts, thus severely impairing its inherent interpretability. This paper proposes prototypical part transformer (ProtoPFormer) for appropriately and effectively applying the prototype-based method with ViTs for interpretable image recognition. The proposed method introduces global and local prototypes for capturing and highlighting the representative holistic and partial features of targets according to the architectural characteristics of ViTs. The global prototypes are adopted to provide the global view of objects to guide local prototypes to concentrate on the foreground while eliminating the influence of the background. Afterwards, local prototypes are explicitly supervised to concentrate on their respective prototypical visual parts, increasing the overall interpretability. Extensive experiments demonstrate that our proposed global and local prototypes can mutually correct each other and jointly make final decisions, which faithfully and transparently reason the decision-making processes associatively from the whole and local perspectives, respectively. Moreover, ProtoPFormer consistently achieves superior performance and visualization results over the state-of-the-art (SOTA) prototype-based baselines. Our code has been released at https://github.com/zju-vipa/ProtoPFormer.
Learning an Adaptation Function to Assess Image Visual Similarities
Jun 03, 2022
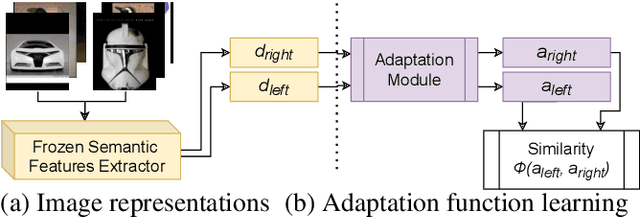
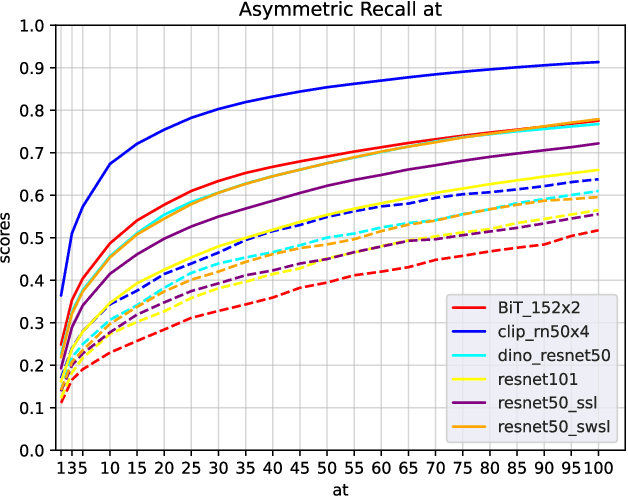

Human perception is routinely assessing the similarity between images, both for decision making and creative thinking. But the underlying cognitive process is not really well understood yet, hence difficult to be mimicked by computer vision systems. State-of-the-art approaches using deep architectures are often based on the comparison of images described as feature vectors learned for image categorization task. As a consequence, such features are powerful to compare semantically related images but not really efficient to compare images visually similar but semantically unrelated. Inspired by previous works on neural features adaptation to psycho-cognitive representations, we focus here on the specific task of learning visual image similarities when analogy matters. We propose to compare different supervised, semi-supervised and self-supervised networks, pre-trained on distinct scales and contents datasets (such as ImageNet-21k, ImageNet-1K or VGGFace2) to conclude which model may be the best to approximate the visual cortex and learn only an adaptation function corresponding to the approximation of the the primate IT cortex through the metric learning framework. Our experiments conducted on the Totally Looks Like image dataset highlight the interest of our method, by increasing the retrieval scores of the best model @1 by 2.25x. This research work was recently accepted for publication at the ICIP 2021 international conference [1]. In this new article, we expand on this previous work by using and comparing new pre-trained feature extractors on other datasets.
Vision Transformers for Single Image Dehazing
Apr 08, 2022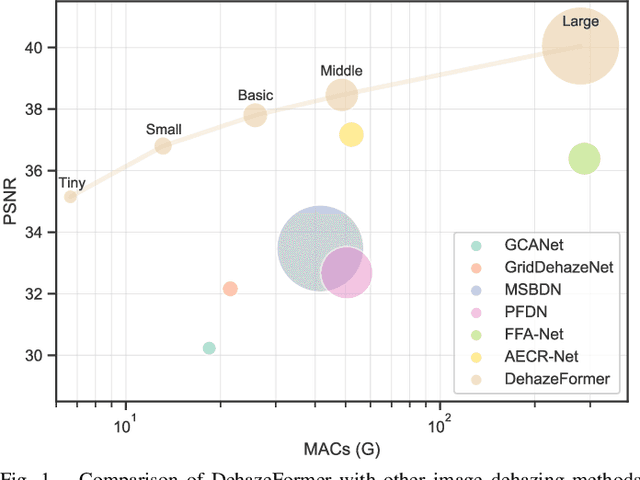


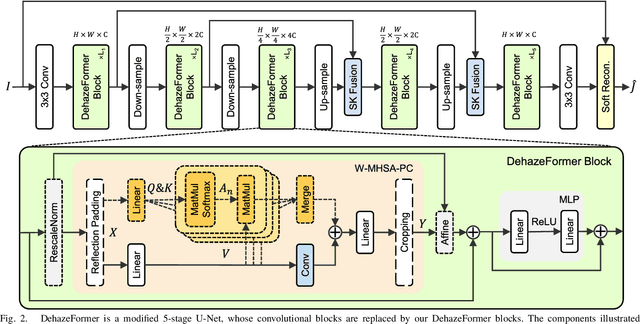
Image dehazing is a representative low-level vision task that estimates latent haze-free images from hazy images. In recent years, convolutional neural network-based methods have dominated image dehazing. However, vision Transformers, which has recently made a breakthrough in high-level vision tasks, has not brought new dimensions to image dehazing. We start with the popular Swin Transformer and find that several of its key designs are unsuitable for image dehazing. To this end, we propose DehazeFormer, which consists of various improvements, such as the modified normalization layer, activation function, and spatial information aggregation scheme. We train multiple variants of DehazeFormer on various datasets to demonstrate its effectiveness. Specifically, on the most frequently used SOTS indoor set, our small model outperforms FFA-Net with only 25% #Param and 5% computational cost. To the best of our knowledge, our large model is the first method with the PSNR over 40 dB on the SOTS indoor set, dramatically outperforming the previous state-of-the-art methods. We also collect a large-scale realistic remote sensing dehazing dataset for evaluating the method's capability to remove highly non-homogeneous haze.
Robust Perception through Equivariance
Dec 12, 2022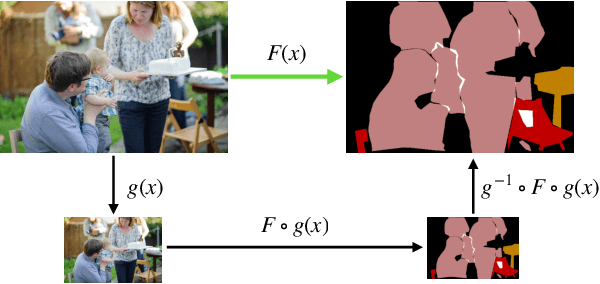
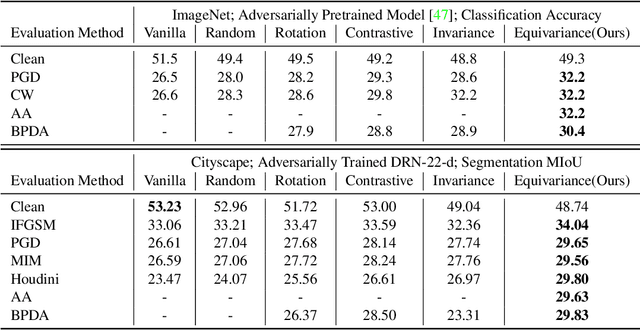

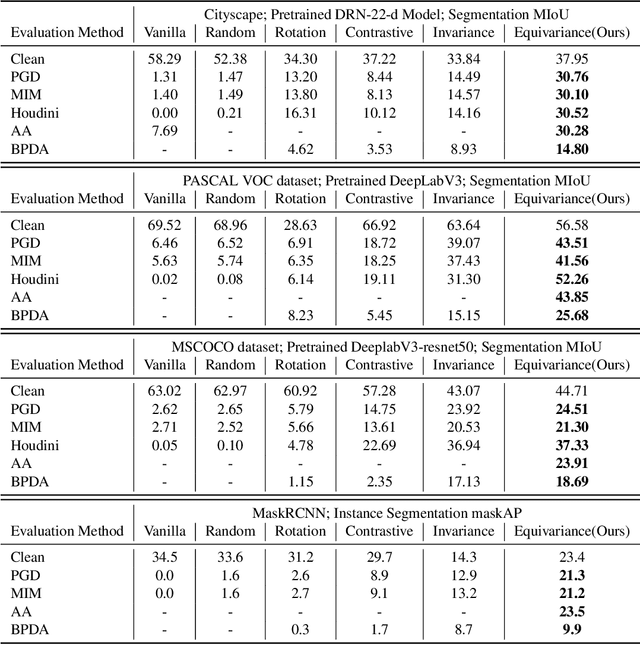
Deep networks for computer vision are not reliable when they encounter adversarial examples. In this paper, we introduce a framework that uses the dense intrinsic constraints in natural images to robustify inference. By introducing constraints at inference time, we can shift the burden of robustness from training to the inference algorithm, thereby allowing the model to adjust dynamically to each individual image's unique and potentially novel characteristics at inference time. Among different constraints, we find that equivariance-based constraints are most effective, because they allow dense constraints in the feature space without overly constraining the representation at a fine-grained level. Our theoretical results validate the importance of having such dense constraints at inference time. Our empirical experiments show that restoring feature equivariance at inference time defends against worst-case adversarial perturbations. The method obtains improved adversarial robustness on four datasets (ImageNet, Cityscapes, PASCAL VOC, and MS-COCO) on image recognition, semantic segmentation, and instance segmentation tasks. Project page is available at equi4robust.cs.columbia.edu.
Quantum Phase Recognition using Quantum Tensor Networks
Dec 12, 2022Machine learning (ML) has recently facilitated many advances in solving problems related to many-body physical systems. Given the intrinsic quantum nature of these problems, it is natural to speculate that quantum-enhanced machine learning will enable us to unveil even greater details than we currently have. With this motivation, this paper examines a quantum machine learning approach based on shallow variational ansatz inspired by tensor networks for supervised learning tasks. In particular, we first look at the standard image classification tasks using the Fashion-MNIST dataset and study the effect of repeating tensor network layers on ansatz's expressibility and performance. Finally, we use this strategy to tackle the problem of quantum phase recognition for the transverse-field Ising and Heisenberg spin models in one and two dimensions, where we were able to reach $\geq 98\%$ test-set accuracies with both multi-scale entanglement renormalization ansatz (MERA) and tree tensor network (TTN) inspired parametrized quantum circuits.
Mushroom image recognition and distance generation based on attention-mechanism model and genetic information
Jun 27, 2022
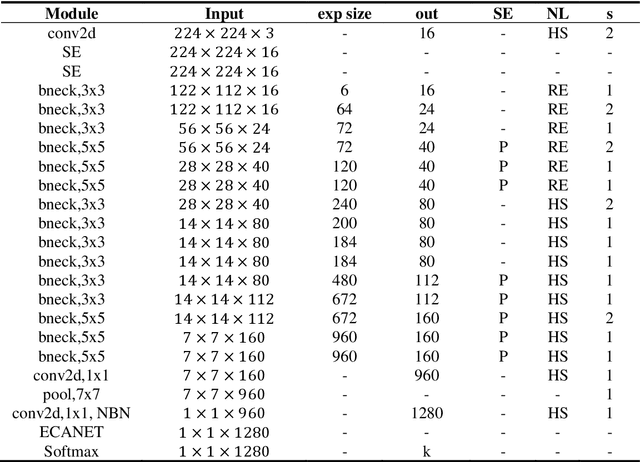

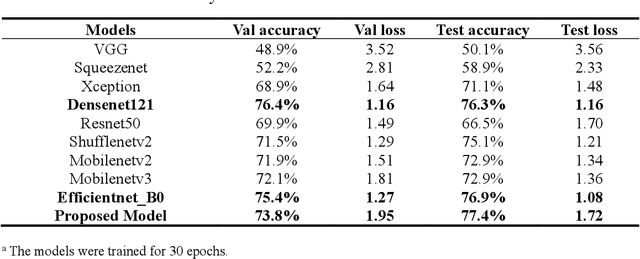
The species identification of Macrofungi, i.e. mushrooms, has always been a challenging task. There are still a large number of poisonous mushrooms that have not been found, which poses a risk to people's life. However, the traditional identification method requires a large number of experts with knowledge in the field of taxonomy for manual identification, it is not only inefficient but also consumes a lot of manpower and capital costs. In this paper, we propose a new model based on attention-mechanism, MushroomNet, which applies the lightweight network MobileNetV3 as the backbone model, combined with the attention structure proposed by us, and has achieved excellent performance in the mushroom recognition task. On the public dataset, the test accuracy of the MushroomNet model has reached 83.9%, and on the local dataset, the test accuracy has reached 77.4%. The proposed attention mechanisms well focused attention on the bodies of mushroom image for mixed channel attention and the attention heat maps visualized by Grad-CAM. Further, in this study, genetic distance was added to the mushroom image recognition task, the genetic distance was used as the representation space, and the genetic distance between each pair of mushroom species in the dataset was used as the embedding of the genetic distance representation space, so as to predict the image distance and species. identify. We found that using the MES activation function can predict the genetic distance of mushrooms very well, but the accuracy is lower than that of SoftMax. The proposed MushroomNet was demonstrated it shows great potential for automatic and online mushroom image and the proposed automatic procedure would assist and be a reference to traditional mushroom classification.
Sparse SPN: Depth Completion from Sparse Keypoints
Dec 02, 2022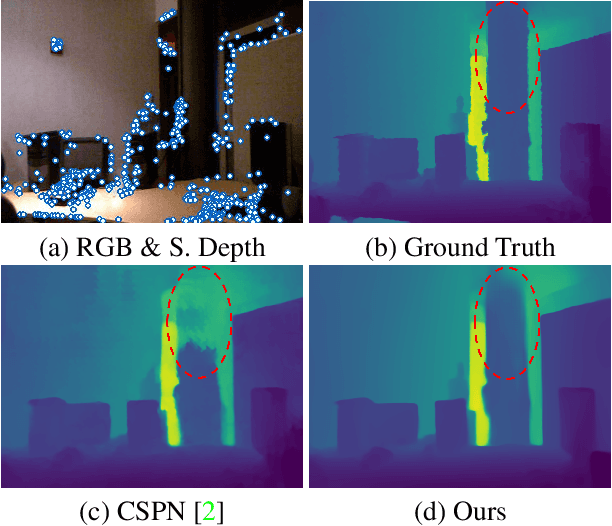
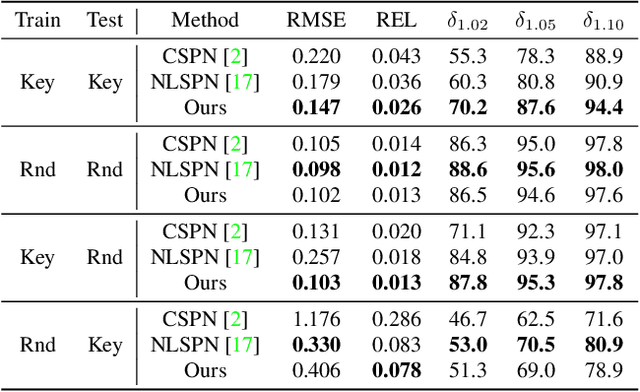

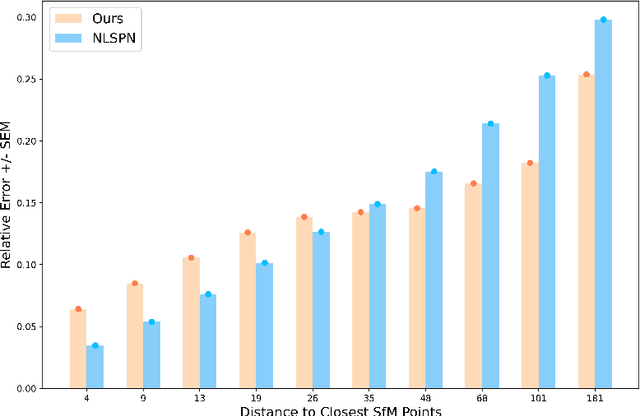
Our long term goal is to use image-based depth completion to quickly create 3D models from sparse point clouds, e.g. from SfM or SLAM. Much progress has been made in depth completion. However, most current works assume well distributed samples of known depth, e.g. Lidar or random uniform sampling, and perform poorly on uneven samples, such as from keypoints, due to the large unsampled regions. To address this problem, we extend CSPN with multiscale prediction and a dilated kernel, leading to much better completion of keypoint-sampled depth. We also show that a model trained on NYUv2 creates surprisingly good point clouds on ETH3D by completing sparse SfM points.
Improving Pixel-Level Contrastive Learning by Leveraging Exogenous Depth Information
Nov 18, 2022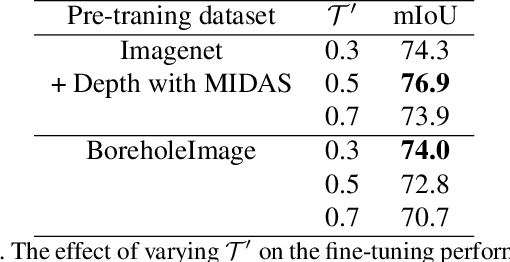
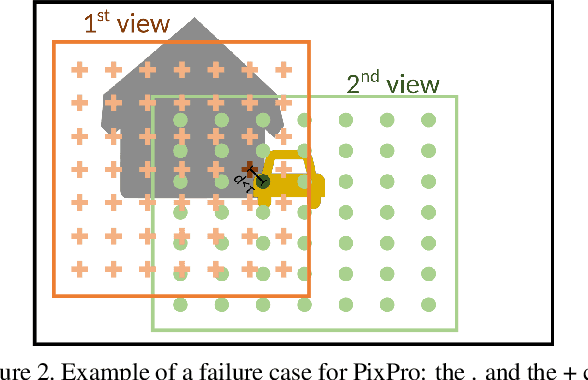
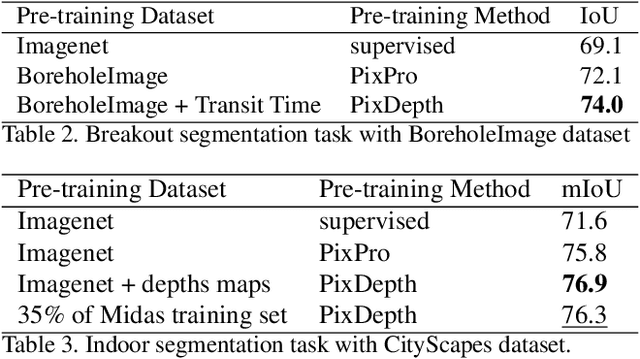
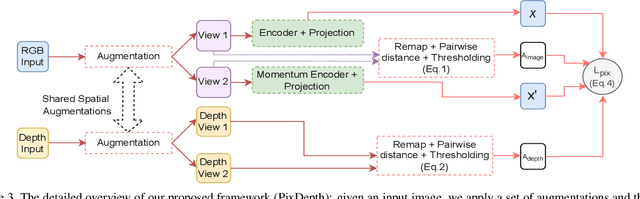
Self-supervised representation learning based on Contrastive Learning (CL) has been the subject of much attention in recent years. This is due to the excellent results obtained on a variety of subsequent tasks (in particular classification), without requiring a large amount of labeled samples. However, most reference CL algorithms (such as SimCLR and MoCo, but also BYOL and Barlow Twins) are not adapted to pixel-level downstream tasks. One existing solution known as PixPro proposes a pixel-level approach that is based on filtering of pairs of positive/negative image crops of the same image using the distance between the crops in the whole image. We argue that this idea can be further enhanced by incorporating semantic information provided by exogenous data as an additional selection filter, which can be used (at training time) to improve the selection of the pixel-level positive/negative samples. In this paper we will focus on the depth information, which can be obtained by using a depth estimation network or measured from available data (stereovision, parallax motion, LiDAR, etc.). Scene depth can provide meaningful cues to distinguish pixels belonging to different objects based on their depth. We show that using this exogenous information in the contrastive loss leads to improved results and that the learned representations better follow the shapes of objects. In addition, we introduce a multi-scale loss that alleviates the issue of finding the training parameters adapted to different object sizes. We demonstrate the effectiveness of our ideas on the Breakout Segmentation on Borehole Images where we achieve an improvement of 1.9\% over PixPro and nearly 5\% over the supervised baseline. We further validate our technique on the indoor scene segmentation tasks with ScanNet and outdoor scenes with CityScapes ( 1.6\% and 1.1\% improvement over PixPro respectively).