 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Linear Transformer for 3D Biomedical Image Segmentation
Jun 01, 2022
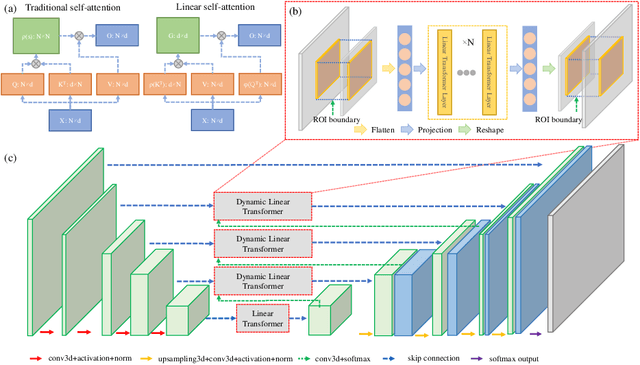
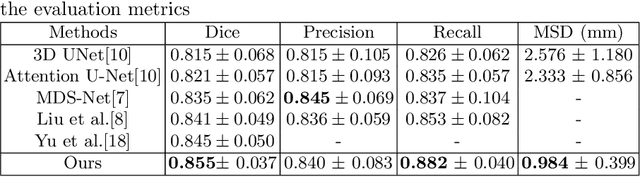
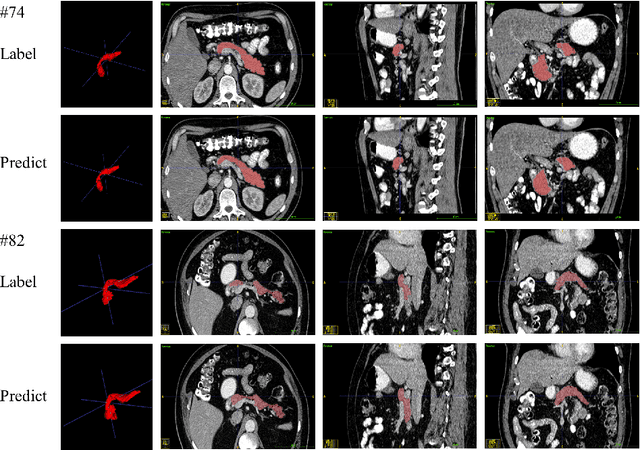
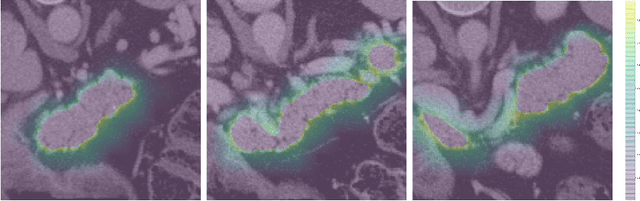
Transformer-based neural networks have surpassed promising performance on many biomedical image segmentation tasks due to a better global information modeling from the self-attention mechanism. However, most methods are still designed for 2D medical images while ignoring the essential 3D volume information. The main challenge for 3D transformer-based segmentation methods is the quadratic complexity introduced by the self-attention mechanism \cite{vaswani2017attention}. In this paper, we propose a novel transformer architecture for 3D medical image segmentation using an encoder-decoder style architecture with linear complexity. Furthermore, we newly introduce a dynamic token concept to further reduce the token numbers for self-attention calculation. Taking advantage of the global information modeling, we provide uncertainty maps from different hierarchy stages. We evaluate this method on multiple challenging CT pancreas segmentation datasets. Our promising results show that our novel 3D Transformer-based segmentor could provide promising highly feasible segmentation performance and accurate uncertainty quantification using single annotation. Code is available https://github.com/freshman97/LinTransUNet.
3D GAN Inversion with Pose Optimization
Oct 17, 2022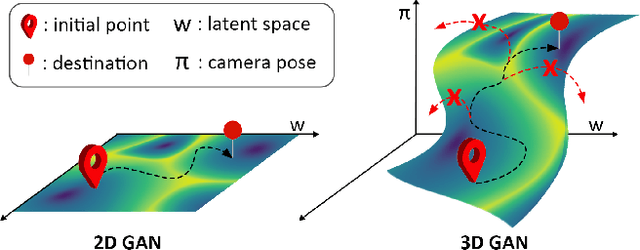
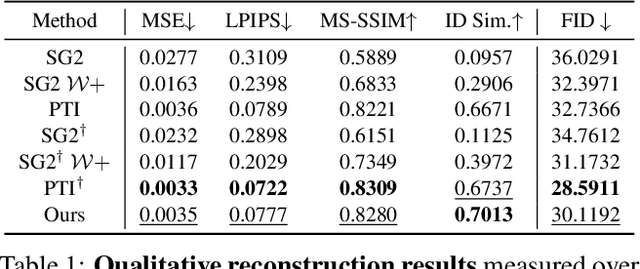

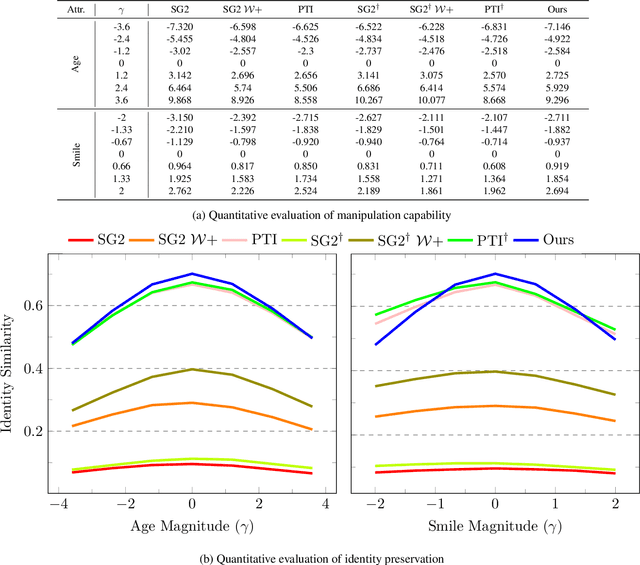
With the recent advances in NeRF-based 3D aware GANs quality, projecting an image into the latent space of these 3D-aware GANs has a natural advantage over 2D GAN inversion: not only does it allow multi-view consistent editing of the projected image, but it also enables 3D reconstruction and novel view synthesis when given only a single image. However, the explicit viewpoint control acts as a main hindrance in the 3D GAN inversion process, as both camera pose and latent code have to be optimized simultaneously to reconstruct the given image. Most works that explore the latent space of the 3D-aware GANs rely on ground-truth camera viewpoint or deformable 3D model, thus limiting their applicability. In this work, we introduce a generalizable 3D GAN inversion method that infers camera viewpoint and latent code simultaneously to enable multi-view consistent semantic image editing. The key to our approach is to leverage pre-trained estimators for better initialization and utilize the pixel-wise depth calculated from NeRF parameters to better reconstruct the given image. We conduct extensive experiments on image reconstruction and editing both quantitatively and qualitatively, and further compare our results with 2D GAN-based editing to demonstrate the advantages of utilizing the latent space of 3D GANs. Additional results and visualizations are available at https://3dgan-inversion.github.io .
MaxStyle: Adversarial Style Composition for Robust Medical Image Segmentation
Jun 02, 2022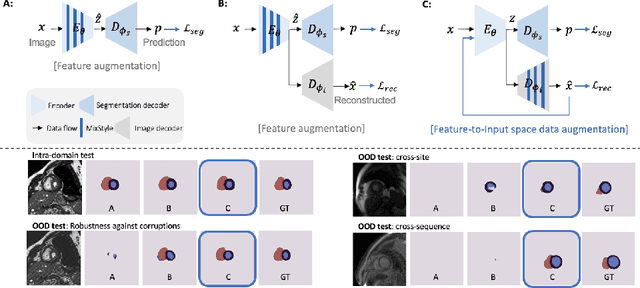

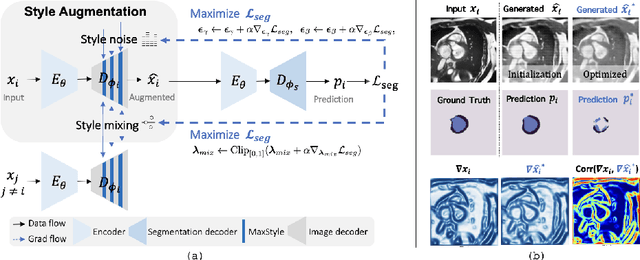
Convolutional neural networks (CNNs) have achieved remarkable segmentation accuracy on benchmark datasets where training and test sets are from the same domain, yet their performance can degrade significantly on unseen domains, which hinders the deployment of CNNs in many clinical scenarios. Most existing works improve model out-of-domain (OOD) robustness by collecting multi-domain datasets for training, which is expensive and may not always be feasible due to privacy and logistical issues. In this work, we focus on improving model robustness using a single-domain dataset only. We propose a novel data augmentation framework called MaxStyle, which maximizes the effectiveness of style augmentation for model OOD performance. It attaches an auxiliary style-augmented image decoder to a segmentation network for robust feature learning and data augmentation. Importantly, MaxStyle augments data with improved image style diversity and hardness, by expanding the style space with noise and searching for the worst-case style composition of latent features via adversarial training. With extensive experiments on multiple public cardiac and prostate MR datasets, we demonstrate that MaxStyle leads to significantly improved out-of-distribution robustness against unseen corruptions as well as common distribution shifts across multiple, different, unseen sites and unknown image sequences under both low- and high-training data settings. The code can be found at https://github.com/cherise215/MaxStyle.
U-Flow: A U-shaped Normalizing Flow for Anomaly Detection with Unsupervised Threshold
Nov 22, 2022
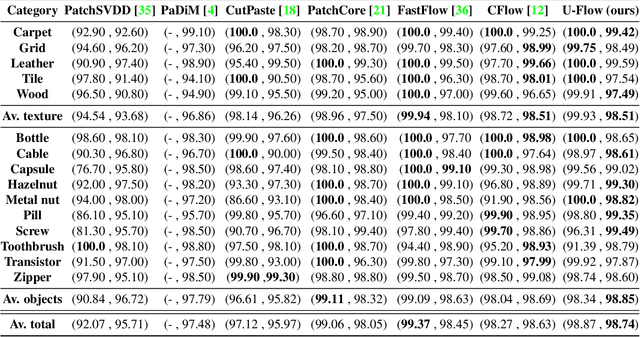
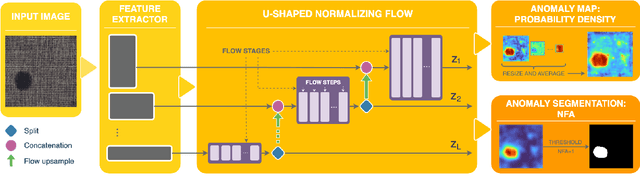
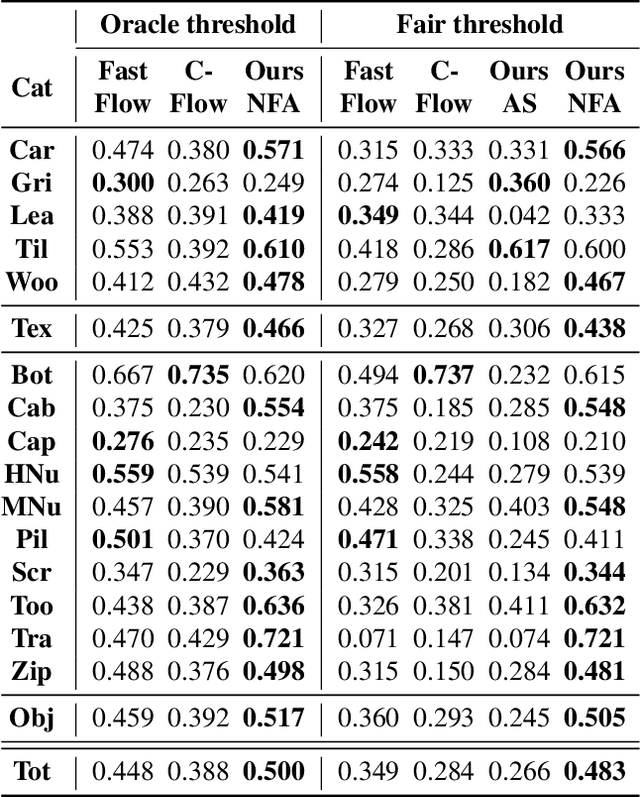
In this work we propose a non-contrastive method for anomaly detection and segmentation in images, that benefits both from a modern machine learning approach and a more classic statistical detection theory. The method consists of three phases. First, features are extracted by making use of a multi-scale image Transformer architecture. Then, these features are fed into a U-shaped Normalizing Flow that lays the theoretical foundations for the last phase, which computes a pixel-level anomaly map, and performs a segmentation based on the a contrario framework. This multiple hypothesis testing strategy permits to derive a robust automatic detection threshold, which is key in many real-world applications, where an operational point is needed. The segmentation results are evaluated using the Intersection over Union (IoU) metric, and for assessing the generated anomaly maps we report the area under the Receiver Operating Characteristic curve (ROC-AUC) at both image and pixel level. For both metrics, the proposed approach produces state-of-the-art results, ranking first in most MvTec-AD categories, with a mean pixel-level ROC- AUC of 98.74%. Code and trained models are available at https://github.com/mtailanian/uflow.
Lung-Net: A deep learning framework for lung tissue segmentation in three-dimensional thoracic CT images
Dec 28, 2022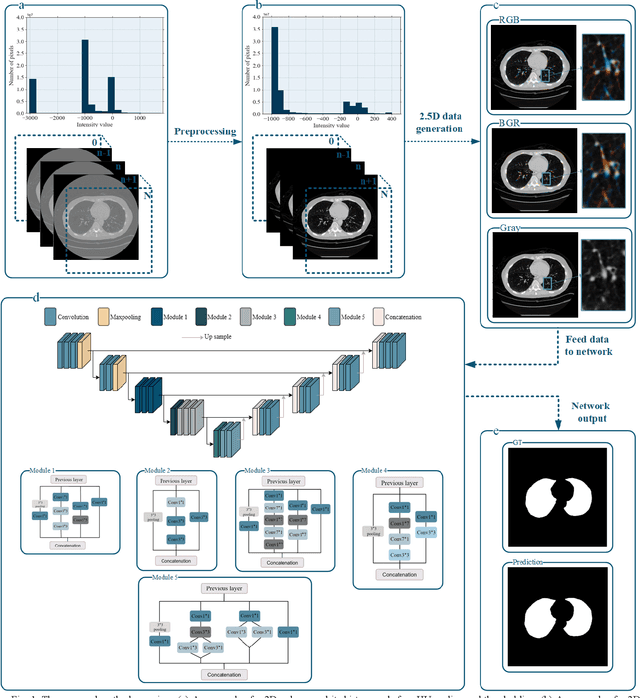
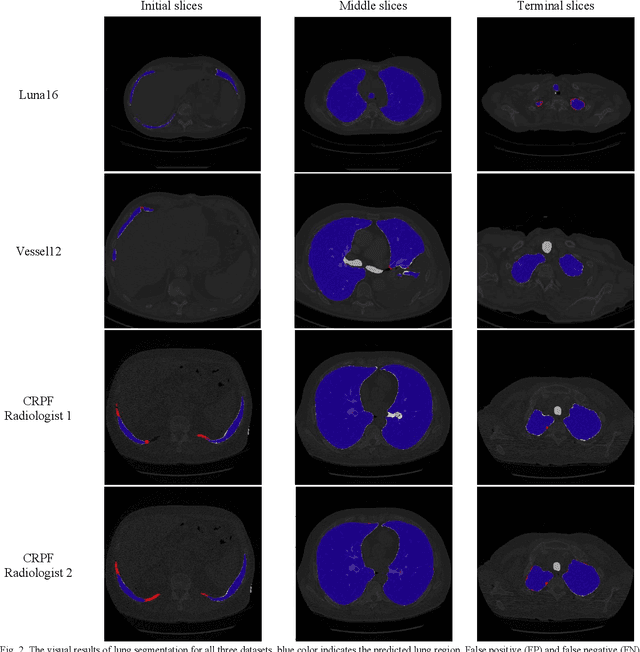
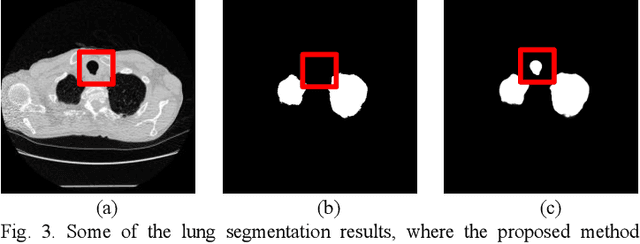
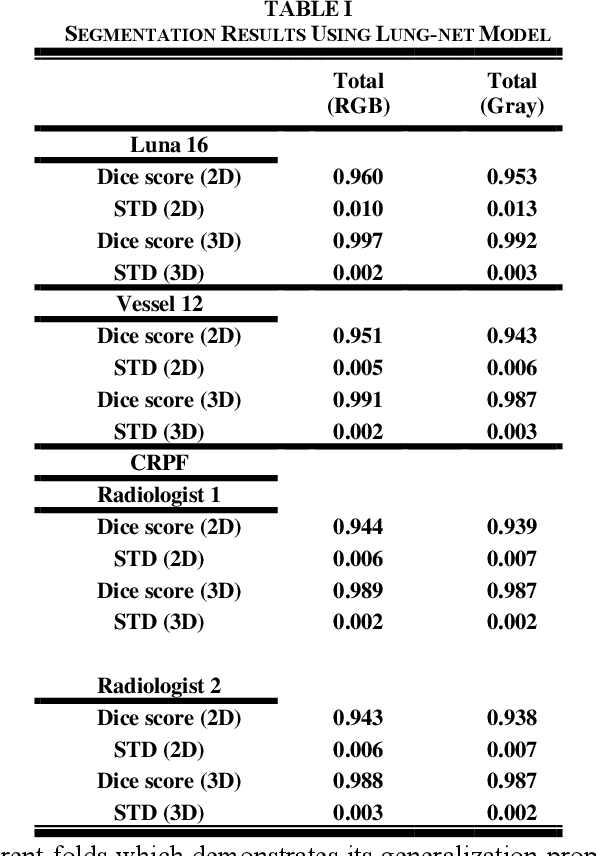
Segmentation of lung tissue in computed tomography (CT) images is a precursor to most pulmonary image analysis applications. Semantic segmentation methods using deep learning have exhibited top-tier performance in recent years. This paper presents a fully automatic method for identifying the lungs in three-dimensional (3D) pulmonary CT images, which we call it Lung-Net. We conjectured that a significant deeper network with inceptionV3 units can achieve a better feature representation of lung CT images without increasing the model complexity in terms of the number of trainable parameters. The method has three main advantages. First, a U-Net architecture with InceptionV3 blocks is developed to resolve the problem of performance degradation and parameter overload. Then, using information from consecutive slices, a new data structure is created to increase generalization potential, allowing more discriminating features to be extracted by making data representation as efficient as possible. Finally, the robustness of the proposed segmentation framework was quantitatively assessed using one public database to train and test the model (LUNA16) and two public databases (ISBI VESSEL12 challenge and CRPF dataset) only for testing the model; each database consists of 700, 23, and 40 CT images, respectively, that were acquired with a different scanner and protocol. Based on the experimental results, the proposed method achieved competitive results over the existing techniques with Dice coefficient of 99.7, 99.1, and 98.8 for LUNA16, VESSEL12, and CRPF datasets, respectively. For segmenting lung tissue in CT images, the proposed model is efficient in terms of time and parameters and outperforms other state-of-the-art methods. Additionally, this model is publicly accessible via a graphical user interface.
SynCLay: Interactive Synthesis of Histology Images from Bespoke Cellular Layouts
Dec 28, 2022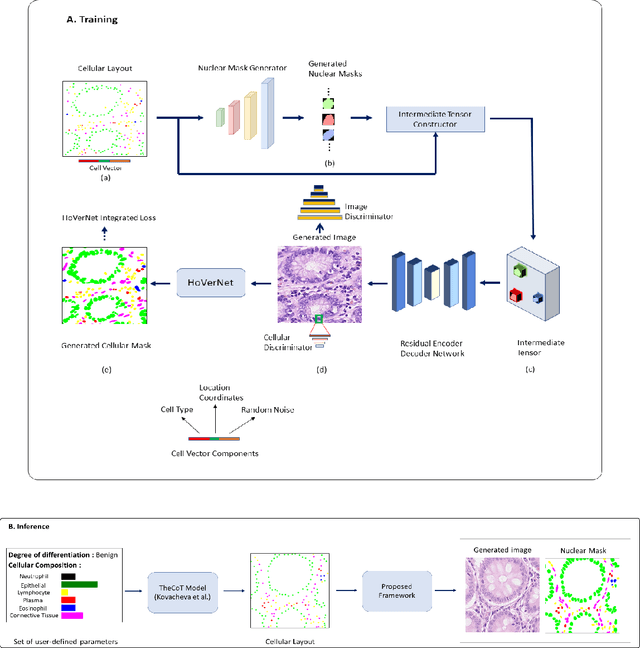
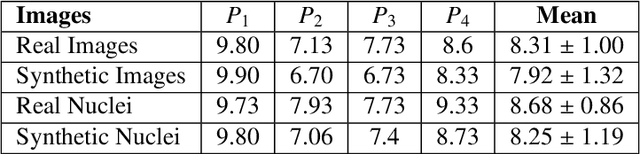
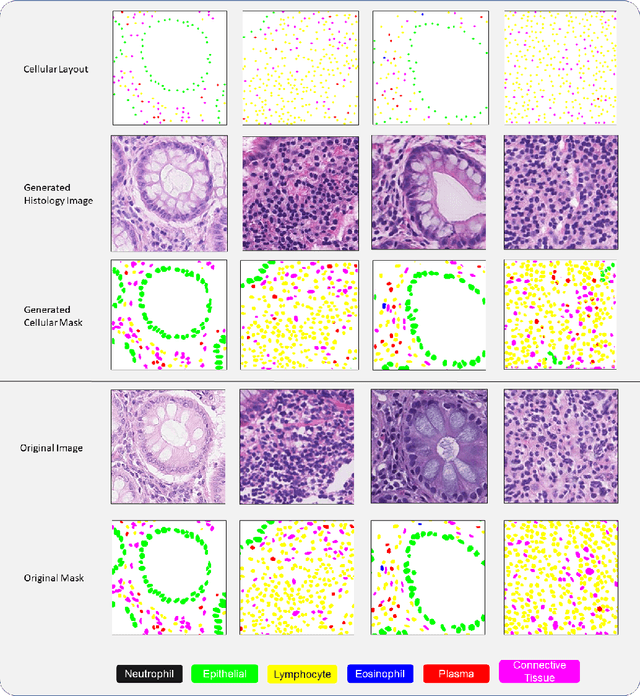
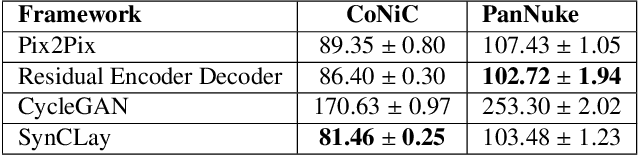
Automated synthesis of histology images has several potential applications in computational pathology. However, no existing method can generate realistic tissue images with a bespoke cellular layout or user-defined histology parameters. In this work, we propose a novel framework called SynCLay (Synthesis from Cellular Layouts) that can construct realistic and high-quality histology images from user-defined cellular layouts along with annotated cellular boundaries. Tissue image generation based on bespoke cellular layouts through the proposed framework allows users to generate different histological patterns from arbitrary topological arrangement of different types of cells. SynCLay generated synthetic images can be helpful in studying the role of different types of cells present in the tumor microenvironmet. Additionally, they can assist in balancing the distribution of cellular counts in tissue images for designing accurate cellular composition predictors by minimizing the effects of data imbalance. We train SynCLay in an adversarial manner and integrate a nuclear segmentation and classification model in its training to refine nuclear structures and generate nuclear masks in conjunction with synthetic images. During inference, we combine the model with another parametric model for generating colon images and associated cellular counts as annotations given the grade of differentiation and cell densities of different cells. We assess the generated images quantitatively and report on feedback from trained pathologists who assigned realism scores to a set of images generated by the framework. The average realism score across all pathologists for synthetic images was as high as that for the real images. We also show that augmenting limited real data with the synthetic data generated by our framework can significantly boost prediction performance of the cellular composition prediction task.
Smart Face Shield: A Sensor-Based Wearable Face Shield Utilizing Computer Vision Algorithms
Dec 18, 2022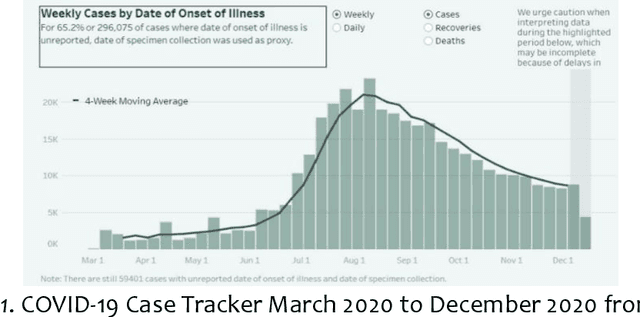


The study aims the development of a wearable device to combat the onslaught of covid-19. Likewise, to enhance the regular face shield available in the market. Furthermore, to raise awareness of the health and safety protocols initiated by the government and its affiliates in the enforcement of social distancing with the integration of computer vision algorithms. The wearable device was composed of various hardware and software components such as a transparent polycarbonate face shield, microprocessor, sensors, camera, thin-film transistor on-screen display, jumper wires, power bank, and python programming language. The algorithm incorporated in the study was object detection under computer vision machine learning. The front camera with OpenCV technology determines the distance of a person in front of the user. Utilizing TensorFlow, the target object identifies and detects the image or live feed to get its bounding boxes. The focal length lens requires the determination of the distance from the camera to the target object. To get the focal length, multiply the pixel width by the known distance and divide it by the known width (Rosebrock, 2020). The deployment of unit testing ensures that the parameters are valid in terms of design and specifications.
The Myth of Culturally Agnostic AI Models
Nov 29, 2022
The paper discusses the potential of large vision-language models as objects of interest for empirical cultural studies. Focusing on the comparative analysis of outputs from two popular text-to-image synthesis models, DALL-E 2 and Stable Diffusion, the paper tries to tackle the pros and cons of striving towards culturally agnostic vs. culturally specific AI models. The paper discusses several examples of memorization and bias in generated outputs which showcase the trade-off between risk mitigation and cultural specificity, as well as the overall impossibility of developing culturally agnostic models.
Probabilistic Compositional Embeddings for Multimodal Image Retrieval
Apr 12, 2022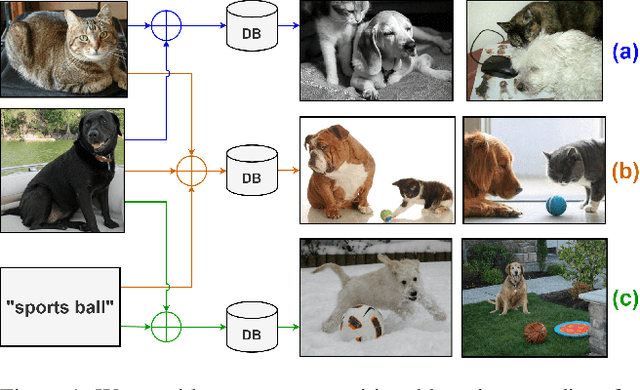
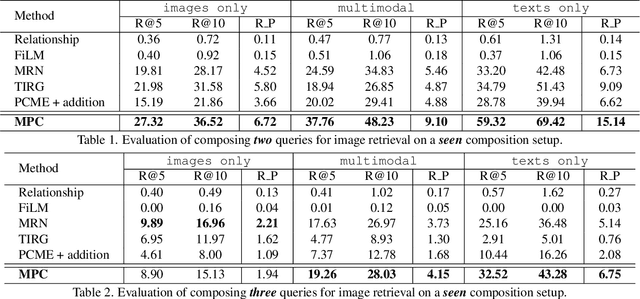


Existing works in image retrieval often consider retrieving images with one or two query inputs, which do not generalize to multiple queries. In this work, we investigate a more challenging scenario for composing multiple multimodal queries in image retrieval. Given an arbitrary number of query images and (or) texts, our goal is to retrieve target images containing the semantic concepts specified in multiple multimodal queries. To learn an informative embedding that can flexibly encode the semantics of various queries, we propose a novel multimodal probabilistic composer (MPC). Specifically, we model input images and texts as probabilistic embeddings, which can be further composed by a probabilistic composition rule to facilitate image retrieval with multiple multimodal queries. We propose a new benchmark based on the MS-COCO dataset and evaluate our model on various setups that compose multiple images and (or) text queries for multimodal image retrieval. Without bells and whistles, we show that our probabilistic model formulation significantly outperforms existing related methods on multimodal image retrieval while generalizing well to query with different amounts of inputs given in arbitrary visual and (or) textual modalities. Code is available here: https://github.com/andreineculai/MPC.
Embedding contrastive unsupervised features to cluster in- and out-of-distribution noise in corrupted image datasets
Jul 18, 2022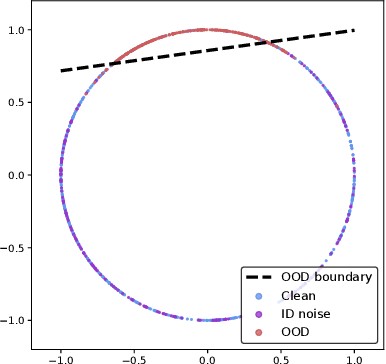
Using search engines for web image retrieval is a tempting alternative to manual curation when creating an image dataset, but their main drawback remains the proportion of incorrect (noisy) samples retrieved. These noisy samples have been evidenced by previous works to be a mixture of in-distribution (ID) samples, assigned to the incorrect category but presenting similar visual semantics to other classes in the dataset, and out-of-distribution (OOD) images, which share no semantic correlation with any category from the dataset. The latter are, in practice, the dominant type of noisy images retrieved. To tackle this noise duality, we propose a two stage algorithm starting with a detection step where we use unsupervised contrastive feature learning to represent images in a feature space. We find that the alignment and uniformity principles of contrastive learning allow OOD samples to be linearly separated from ID samples on the unit hypersphere. We then spectrally embed the unsupervised representations using a fixed neighborhood size and apply an outlier sensitive clustering at the class level to detect the clean and OOD clusters as well as ID noisy outliers. We finally train a noise robust neural network that corrects ID noise to the correct category and utilizes OOD samples in a guided contrastive objective, clustering them to improve low-level features. Our algorithm improves the state-of-the-art results on synthetic noise image datasets as well as real-world web-crawled data. Our work is fully reproducible github.com/PaulAlbert31/SNCF.