 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ESTAS: Effective and Stable Trojan Attacks in Self-supervised Encoders with One Target Unlabelled Sample
Nov 20, 2022
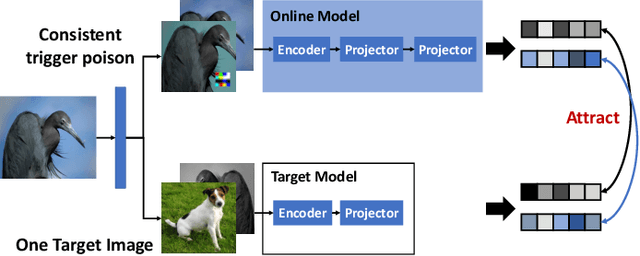
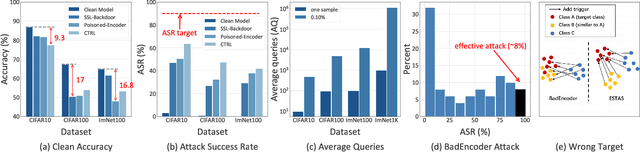
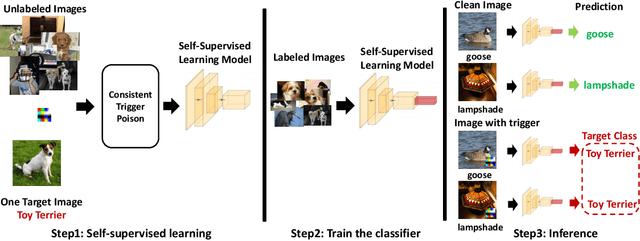
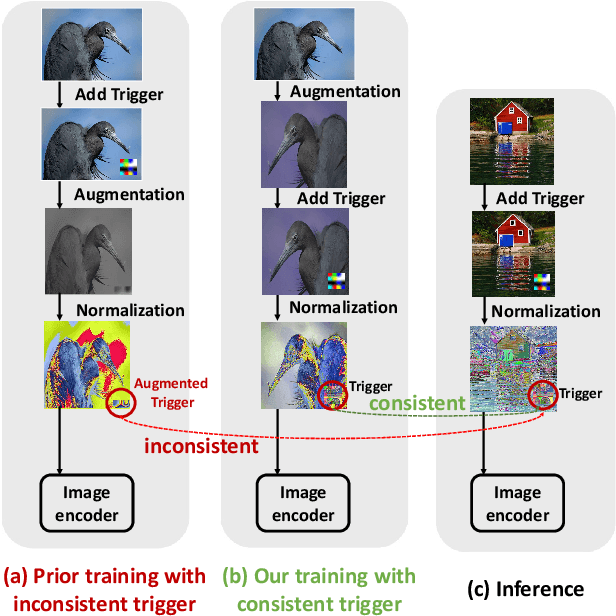
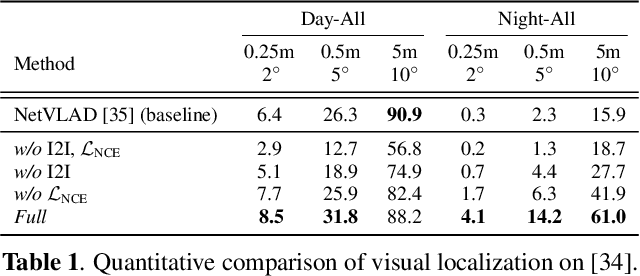
Emerging self-supervised learning (SSL) has become a popular image representation encoding method to obviate the reliance on labeled data and learn rich representations from large-scale, ubiquitous unlabelled data. Then one can train a downstream classifier on top of the pre-trained SSL image encoder with few or no labeled downstream data. Although extensive works show that SSL has achieved remarkable and competitive performance on different downstream tasks, its security concerns, e.g, Trojan attacks in SSL encoders, are still not well-studied. In this work, we present a novel Trojan Attack method, denoted by ESTAS, that can enable an effective and stable attack in SSL encoders with only one target unlabeled sample. In particular, we propose consistent trigger poisoning and cascade optimization in ESTAS to improve attack efficacy and model accuracy, and eliminate the expensive target-class data sample extraction from large-scale disordered unlabelled data. Our substantial experiments on multiple datasets show that ESTAS stably achieves > 99% attacks success rate (ASR) with one target-class sample. Compared to prior works, ESTAS attains > 30% ASR increase and > 8.3% accuracy improvement on average.
F2SD: A dataset for end-to-end group detection algorithms
Nov 20, 2022
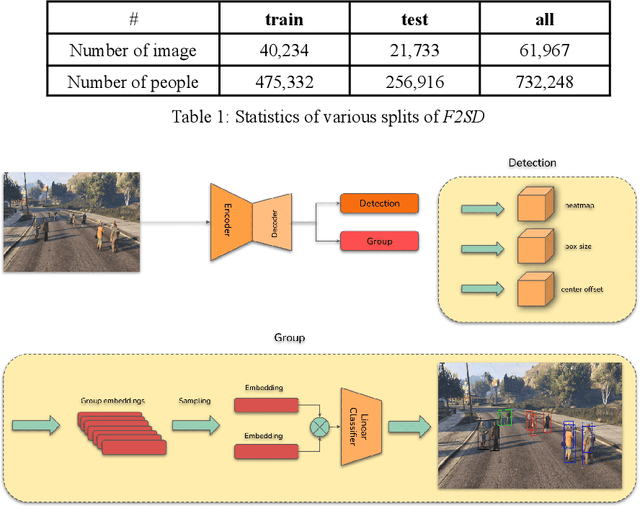
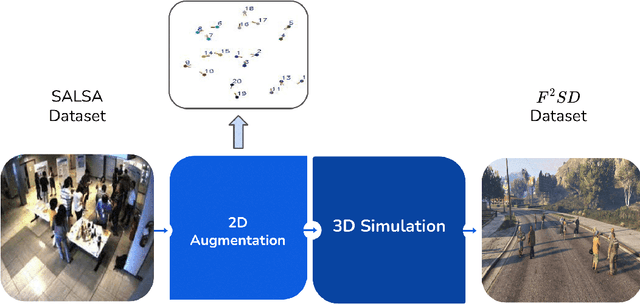
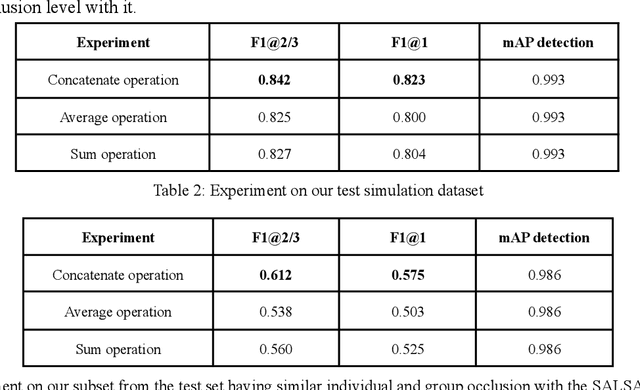
The lack of large-scale datasets has been impeding the advance of deep learning approaches to the problem of F-formation detection. Moreover, most research works on this problem rely on input sensor signals of object location and orientation rather than image signals. To address this, we develop a new, large-scale dataset of simulated images for F-formation detection, called F-formation Simulation Dataset (F2SD). F2SD contains nearly 60,000 images simulated from GTA-5, with bounding boxes and orientation information on images, making it useful for a wide variety of modelling approaches. It is also closer to practical scenarios, where three-dimensional location and orientation information are costly to record. It is challenging to construct such a large-scale simulated dataset while keeping it realistic. Furthermore, the available research utilizes conventional methods to detect groups. They do not detect groups directly from the image. In this work, we propose (1) a large-scale simulation dataset F2SD and a pipeline for F-formation simulation, (2) a first-ever end-to-end baseline model for the task, and experiments on our simulation dataset.
Unsupervised Change Detection Based on Image Reconstruction Loss
Apr 05, 2022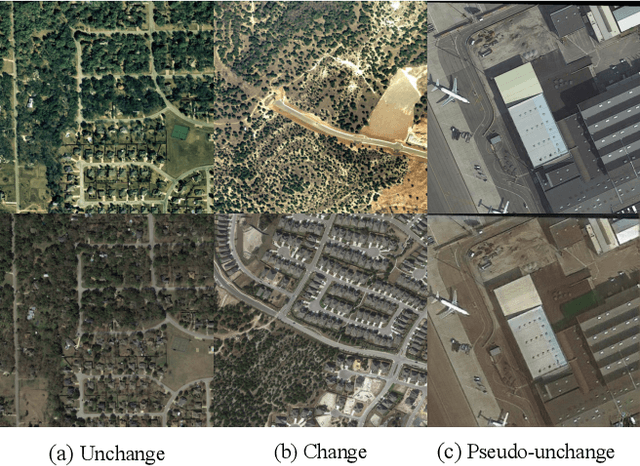
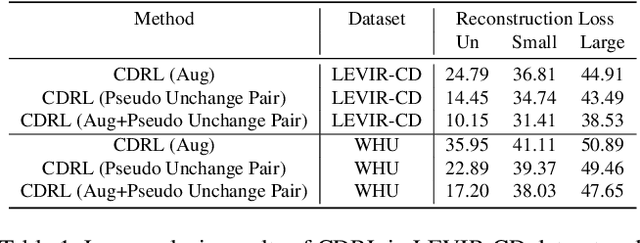
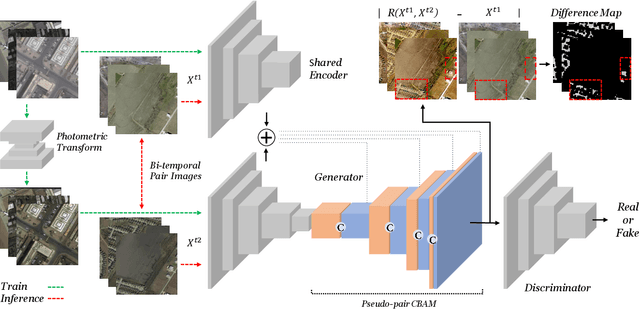
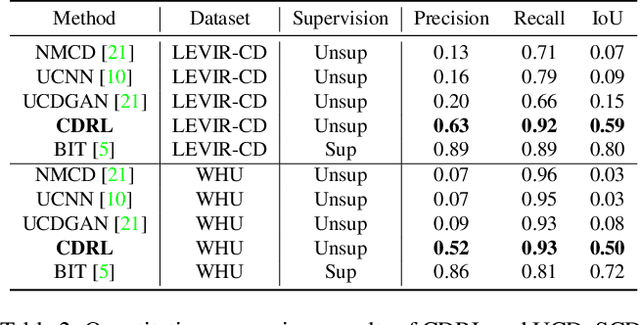
To train the change detector, bi-temporal images taken at different times in the same area are used. However, collecting labeled bi-temporal images is expensive and time consuming. To solve this problem, various unsupervised change detection methods have been proposed, but they still require unlabeled bi-temporal images. In this paper, we propose unsupervised change detection based on image reconstruction loss using only unlabeled single temporal single image. The image reconstruction model is trained to reconstruct the original source image by receiving the source image and the photometrically transformed source image as a pair. During inference, the model receives bi-temporal images as the input, and tries to reconstruct one of the inputs. The changed region between bi-temporal images shows high reconstruction loss. Our change detector showed significant performance in various change detection benchmark datasets even though only a single temporal single source image was used. The code and trained models will be publicly available for reproducibility.
Homogeneous Multi-modal Feature Fusion and Interaction for 3D Object Detection
Oct 18, 2022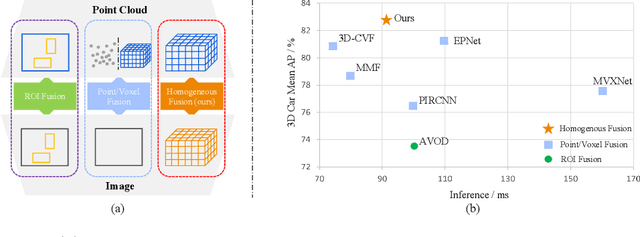
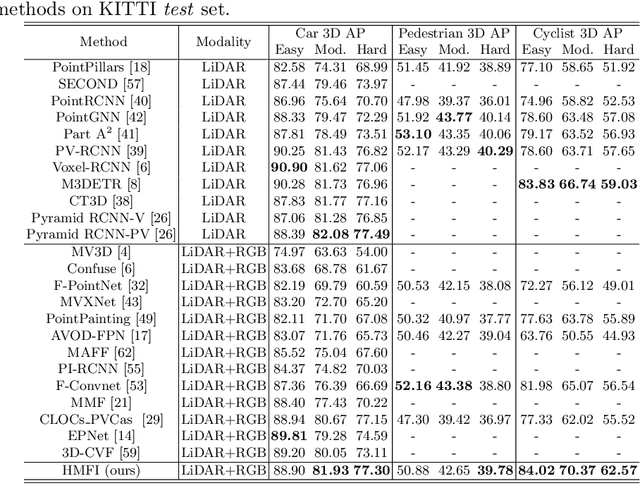
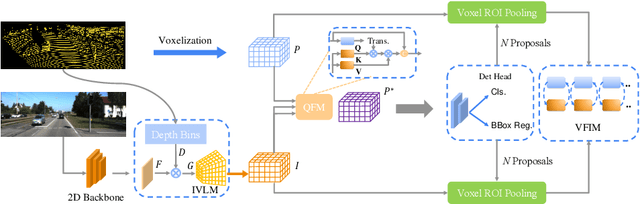
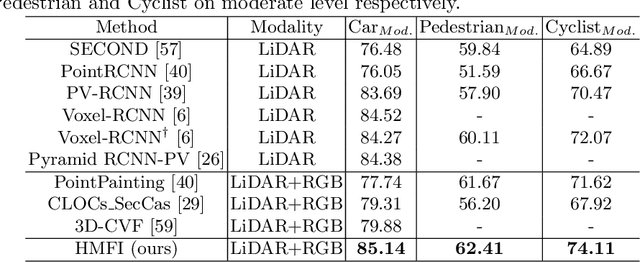
Multi-modal 3D object detection has been an active research topic in autonomous driving. Nevertheless, it is non-trivial to explore the cross-modal feature fusion between sparse 3D points and dense 2D pixels. Recent approaches either fuse the image features with the point cloud features that are projected onto the 2D image plane or combine the sparse point cloud with dense image pixels. These fusion approaches often suffer from severe information loss, thus causing sub-optimal performance. To address these problems, we construct the homogeneous structure between the point cloud and images to avoid projective information loss by transforming the camera features into the LiDAR 3D space. In this paper, we propose a homogeneous multi-modal feature fusion and interaction method (HMFI) for 3D object detection. Specifically, we first design an image voxel lifter module (IVLM) to lift 2D image features into the 3D space and generate homogeneous image voxel features. Then, we fuse the voxelized point cloud features with the image features from different regions by introducing the self-attention based query fusion mechanism (QFM). Next, we propose a voxel feature interaction module (VFIM) to enforce the consistency of semantic information from identical objects in the homogeneous point cloud and image voxel representations, which can provide object-level alignment guidance for cross-modal feature fusion and strengthen the discriminative ability in complex backgrounds. We conduct extensive experiments on the KITTI and Waymo Open Dataset, and the proposed HMFI achieves better performance compared with the state-of-the-art multi-modal methods. Particularly, for the 3D detection of cyclist on the KITTI benchmark, HMFI surpasses all the published algorithms by a large margin.
Multi-domain Unsupervised Image-to-Image Translation with Appearance Adaptive Convolution
Feb 06, 2022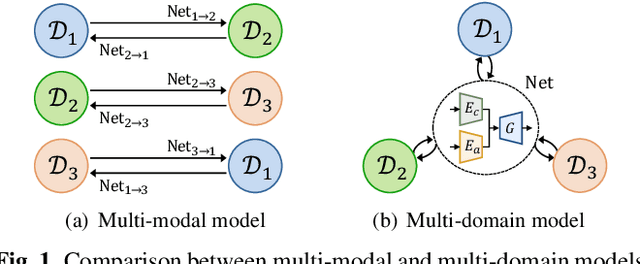
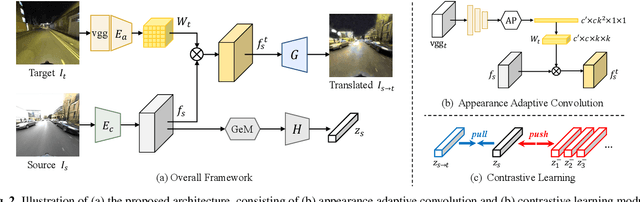

Over the past few years, image-to-image (I2I) translation methods have been proposed to translate a given image into diverse outputs. Despite the impressive results, they mainly focus on the I2I translation between two domains, so the multi-domain I2I translation still remains a challenge. To address this problem, we propose a novel multi-domain unsupervised image-to-image translation (MDUIT) framework that leverages the decomposed content feature and appearance adaptive convolution to translate an image into a target appearance while preserving the given geometric content. We also exploit a contrast learning objective, which improves the disentanglement ability and effectively utilizes multi-domain image data in the training process by pairing the semantically similar images. This allows our method to learn the diverse mappings between multiple visual domains with only a single framework. We show that the proposed method produces visually diverse and plausible results in multiple domains compared to the state-of-the-art methods.
Scalable Hybrid Learning Techniques for Scientific Data Compression
Dec 21, 2022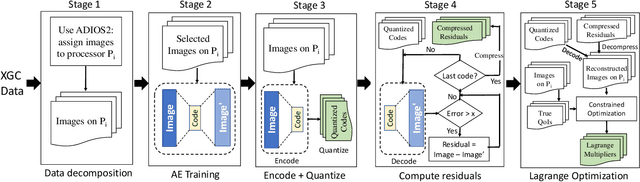
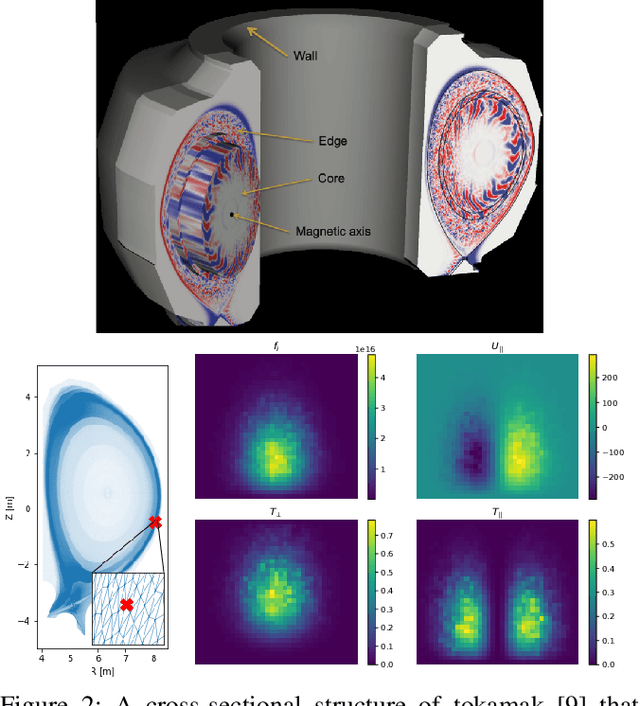
Data compression is becoming critical for storing scientific data because many scientific applications need to store large amounts of data and post process this data for scientific discovery. Unlike image and video compression algorithms that limit errors to primary data, scientists require compression techniques that accurately preserve derived quantities of interest (QoIs). This paper presents a physics-informed compression technique implemented as an end-to-end, scalable, GPU-based pipeline for data compression that addresses this requirement. Our hybrid compression technique combines machine learning techniques and standard compression methods. Specifically, we combine an autoencoder, an error-bounded lossy compressor to provide guarantees on raw data error, and a constraint satisfaction post-processing step to preserve the QoIs within a minimal error (generally less than floating point error). The effectiveness of the data compression pipeline is demonstrated by compressing nuclear fusion simulation data generated by a large-scale fusion code, XGC, which produces hundreds of terabytes of data in a single day. Our approach works within the ADIOS framework and results in compression by a factor of more than 150 while requiring only a few percent of the computational resources necessary for generating the data, making the overall approach highly effective for practical scenarios.
Land Cover and Land Use Detection using Semi-Supervised Learning
Dec 21, 2022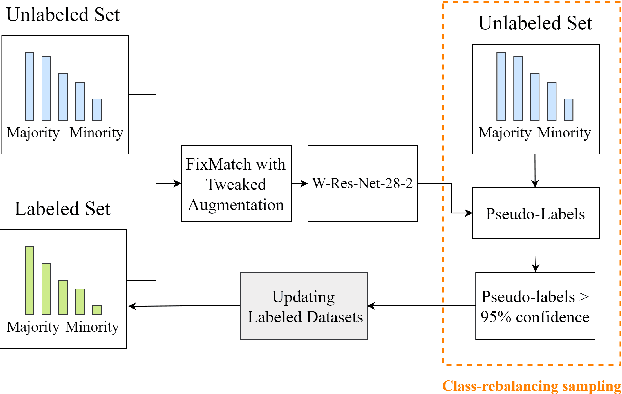
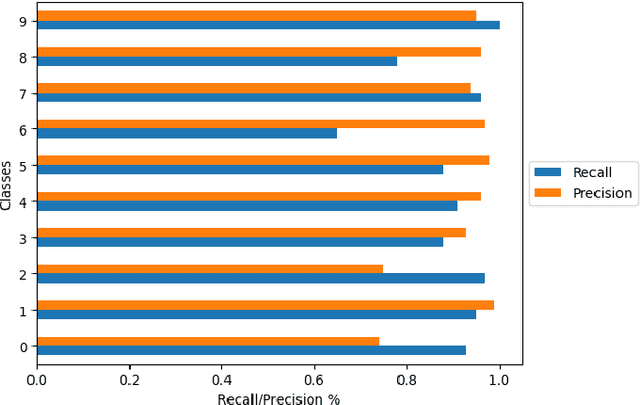
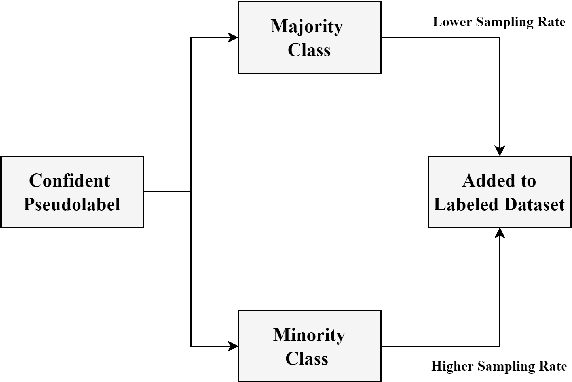
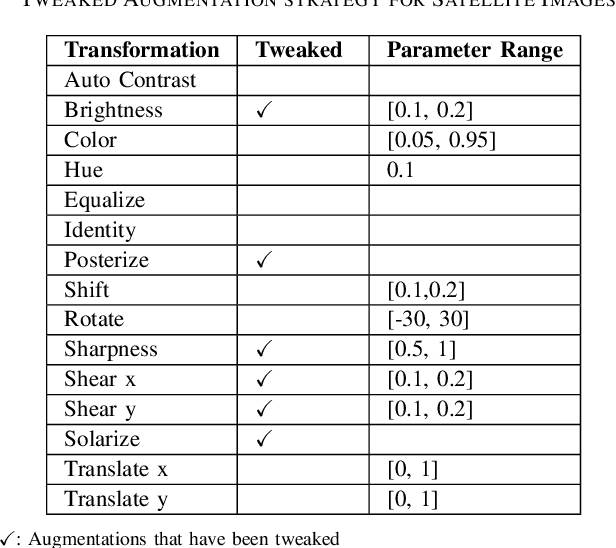
Semi-supervised learning (SSL) has made significant strides in the field of remote sensing. Finding a large number of labeled datasets for SSL methods is uncommon, and manually labeling datasets is expensive and time-consuming. Furthermore, accurately identifying remote sensing satellite images is more complicated than it is for conventional images. Class-imbalanced datasets are another prevalent phenomenon, and models trained on these become biased towards the majority classes. This becomes a critical issue with an SSL model's subpar performance. We aim to address the issue of labeling unlabeled data and also solve the model bias problem due to imbalanced datasets while achieving better accuracy. To accomplish this, we create "artificial" labels and train a model to have reasonable accuracy. We iteratively redistribute the classes through resampling using a distribution alignment technique. We use a variety of class imbalanced satellite image datasets: EuroSAT, UCM, and WHU-RS19. On UCM balanced dataset, our method outperforms previous methods MSMatch and FixMatch by 1.21% and 0.6%, respectively. For imbalanced EuroSAT, our method outperforms MSMatch and FixMatch by 1.08% and 1%, respectively. Our approach significantly lessens the requirement for labeled data, consistently outperforms alternative approaches, and resolves the issue of model bias caused by class imbalance in datasets.
Exploring Content Relationships for Distilling Efficient GANs
Dec 21, 2022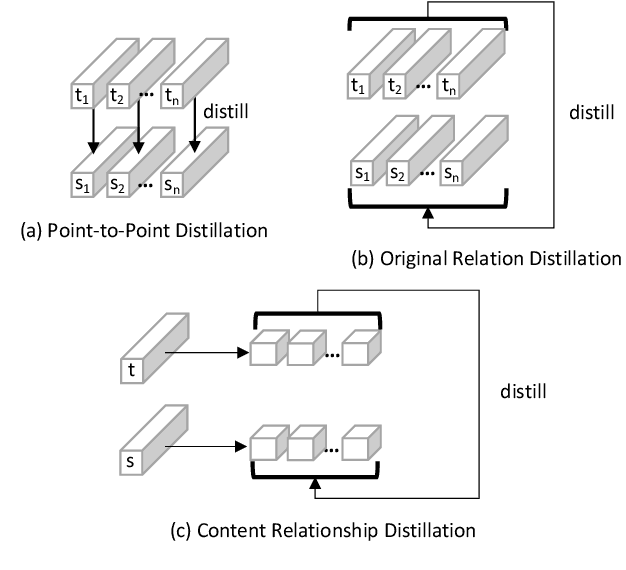
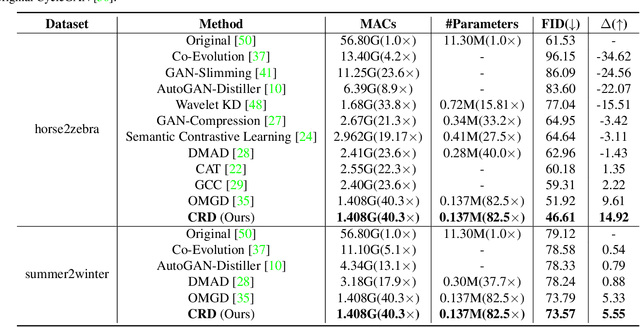
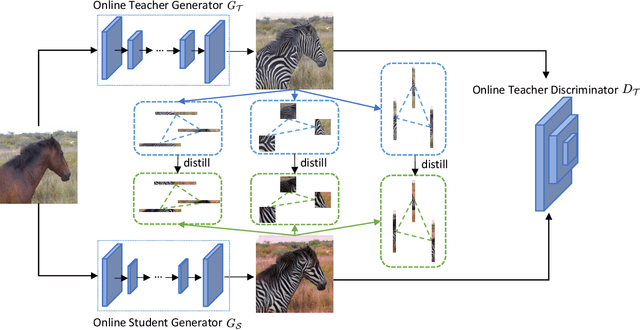

This paper proposes a content relationship distillation (CRD) to tackle the over-parameterized generative adversarial networks (GANs) for the serviceability in cutting-edge devices. In contrast to traditional instance-level distillation, we design a novel GAN compression oriented knowledge by slicing the contents of teacher outputs into multiple fine-grained granularities, such as row/column strips (global information) and image patches (local information), modeling the relationships among them, such as pairwise distance and triplet-wise angle, and encouraging the student to capture these relationships within its output contents. Built upon our proposed content-level distillation, we also deploy an online teacher discriminator, which keeps updating when co-trained with the teacher generator and keeps freezing when co-trained with the student generator for better adversarial training. We perform extensive experiments on three benchmark datasets, the results of which show that our CRD reaches the most complexity reduction on GANs while obtaining the best performance in comparison with existing methods. For example, we reduce MACs of CycleGAN by around 40x and parameters by over 80x, meanwhile, 46.61 FIDs are obtained compared with these of 51.92 for the current state-of-the-art. Code of this project is available at https://github.com/TheKernelZ/CRD.
On the Benefit of Dual-domain Denoising in a Self-supervised Low-dose CT Setting
Nov 03, 2022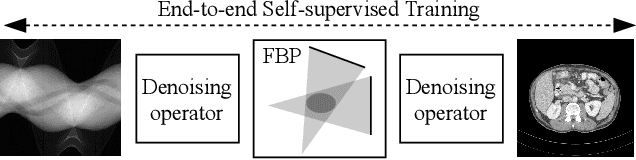
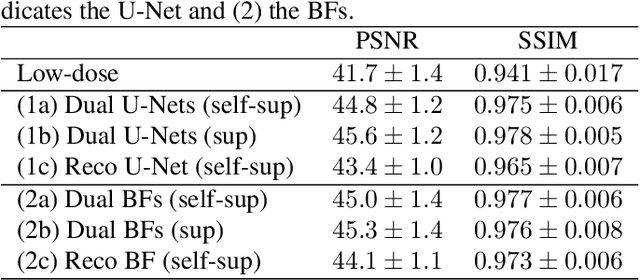
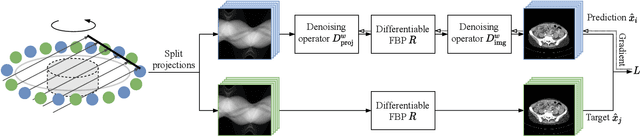
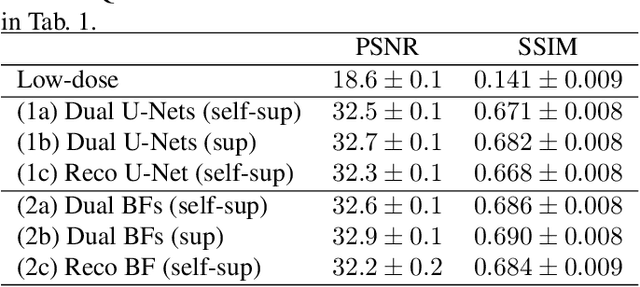
Computed tomography (CT) is routinely used for three-dimensional non-invasive imaging. Numerous data-driven image denoising algorithms were proposed to restore image quality in low-dose acquisitions. However, considerably less research investigates methods already intervening in the raw detector data due to limited access to suitable projection data or correct reconstruction algorithms. In this work, we present an end-to-end trainable CT reconstruction pipeline that contains denoising operators in both the projection and the image domain and that are optimized simultaneously without requiring ground-truth high-dose CT data. Our experiments demonstrate that including an additional projection denoising operator improved the overall denoising performance by 82.4-94.1%/12.5-41.7% (PSNR/SSIM) on abdomen CT and 1.5-2.9%/0.4-0.5% (PSNR/SSIM) on XRM data relative to the low-dose baseline. We make our entire helical CT reconstruction framework publicly available that contains a raw projection rebinning step to render helical projection data suitable for differentiable fan-beam reconstruction operators and end-to-end learning.
Does Medical Imaging learn different Convolution Filters?
Oct 25, 2022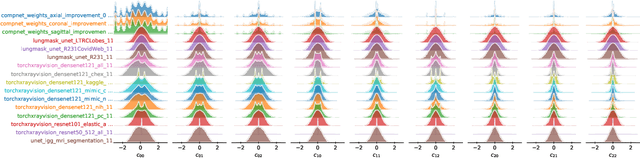

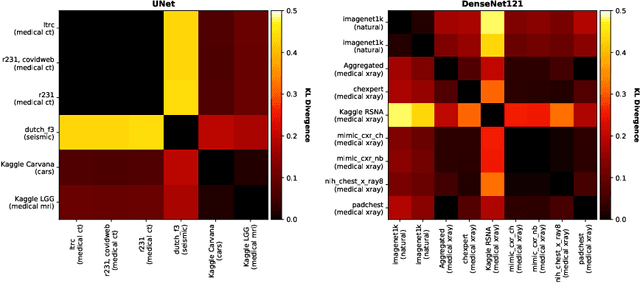
Recent work has investigated the distributions of learned convolution filters through a large-scale study containing hundreds of heterogeneous image models. Surprisingly, on average, the distributions only show minor drifts in comparisons of various studied dimensions including the learned task, image domain, or dataset. However, among the studied image domains, medical imaging models appeared to show significant outliers through "spikey" distributions, and, therefore, learn clusters of highly specific filters different from other domains. Following this observation, we study the collected medical imaging models in more detail. We show that instead of fundamental differences, the outliers are due to specific processing in some architectures. Quite the contrary, for standardized architectures, we find that models trained on medical data do not significantly differ in their filter distributions from similar architectures trained on data from other domains. Our conclusions reinforce previous hypotheses stating that pre-training of imaging models can be done with any kind of diverse image data.