 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Task Bias in Vision-Language Models
Dec 08, 2022
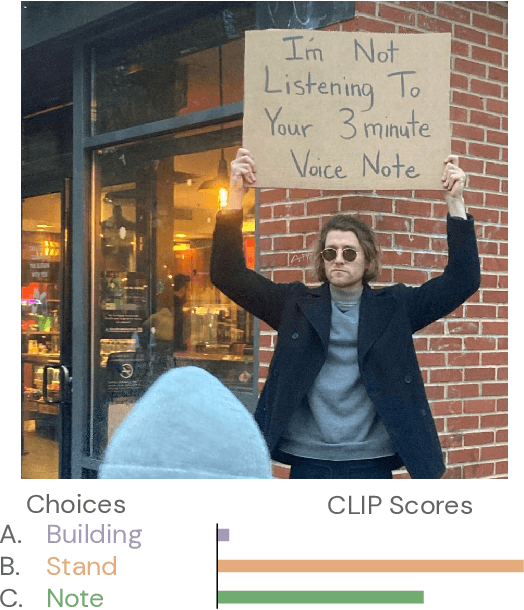
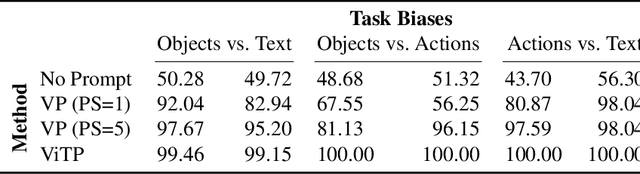
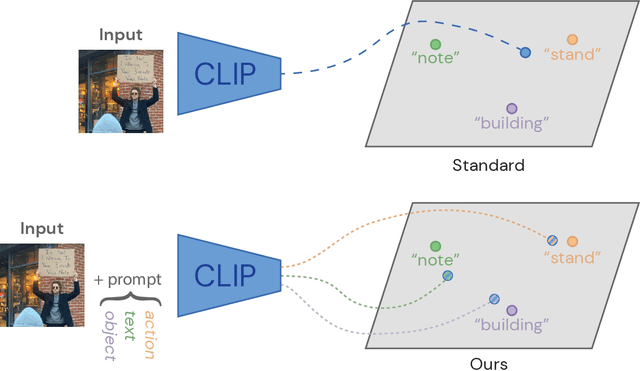
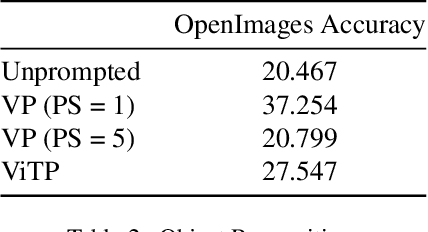
Incidental supervision from language has become a popular approach for learning generic visual representations that can be prompted to perform many recognition tasks in computer vision. We conduct an in-depth exploration of the CLIP model and show that its visual representation is often strongly biased towards solving some tasks more than others. Moreover, which task the representation will be biased towards is unpredictable, with little consistency across images. To resolve this task bias, we show how to learn a visual prompt that guides the representation towards features relevant to their task of interest. Our results show that these visual prompts can be independent of the input image and still effectively provide a conditioning mechanism to steer visual representations towards the desired task.
MicroAST: Towards Super-Fast Ultra-Resolution Arbitrary Style Transfer
Nov 28, 2022
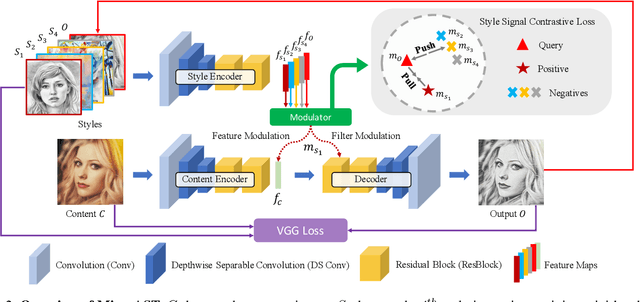
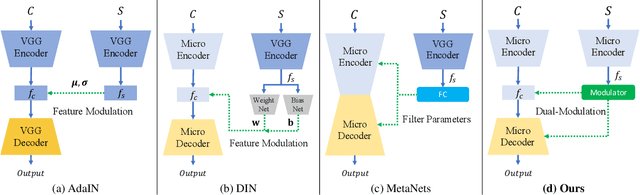
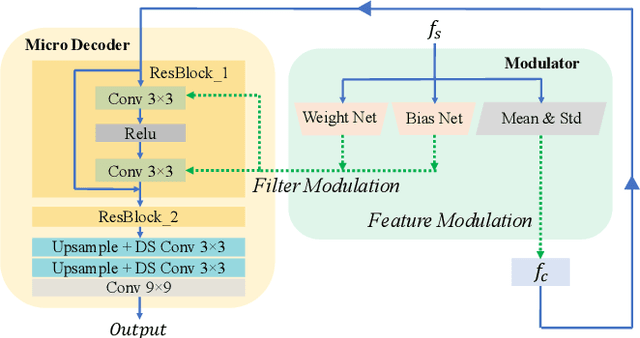
Arbitrary style transfer (AST) transfers arbitrary artistic styles onto content images. Despite the recent rapid progress, existing AST methods are either incapable or too slow to run at ultra-resolutions (e.g., 4K) with limited resources, which heavily hinders their further applications. In this paper, we tackle this dilemma by learning a straightforward and lightweight model, dubbed MicroAST. The key insight is to completely abandon the use of cumbersome pre-trained Deep Convolutional Neural Networks (e.g., VGG) at inference. Instead, we design two micro encoders (content and style encoders) and one micro decoder for style transfer. The content encoder aims at extracting the main structure of the content image. The style encoder, coupled with a modulator, encodes the style image into learnable dual-modulation signals that modulate both intermediate features and convolutional filters of the decoder, thus injecting more sophisticated and flexible style signals to guide the stylizations. In addition, to boost the ability of the style encoder to extract more distinct and representative style signals, we also introduce a new style signal contrastive loss in our model. Compared to the state of the art, our MicroAST not only produces visually superior results but also is 5-73 times smaller and 6-18 times faster, for the first time enabling super-fast (about 0.5 seconds) AST at 4K ultra-resolutions. Code is available at https://github.com/EndyWon/MicroAST.
Unified Contrastive Learning in Image-Text-Label Space
Apr 07, 2022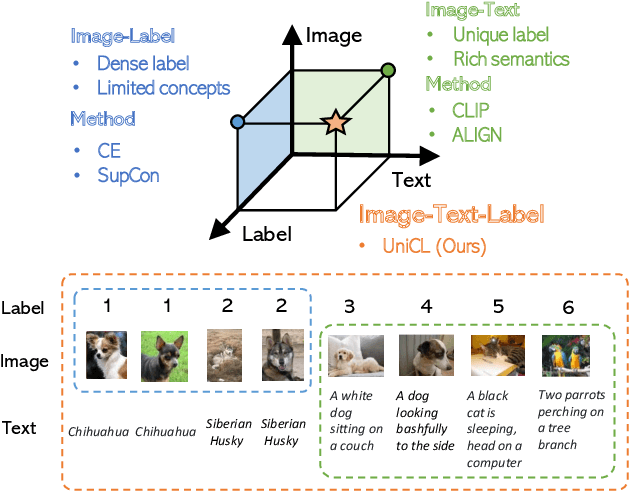
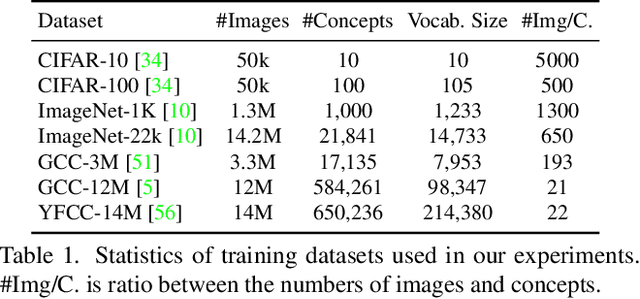
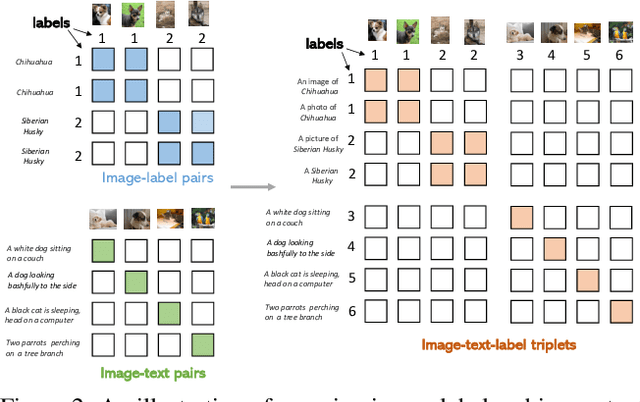

Visual recognition is recently learned via either supervised learning on human-annotated image-label data or language-image contrastive learning with webly-crawled image-text pairs. While supervised learning may result in a more discriminative representation, language-image pretraining shows unprecedented zero-shot recognition capability, largely due to the different properties of data sources and learning objectives. In this work, we introduce a new formulation by combining the two data sources into a common image-text-label space. In this space, we propose a new learning paradigm, called Unified Contrastive Learning (UniCL) with a single learning objective to seamlessly prompt the synergy of two data types. Extensive experiments show that our UniCL is an effective way of learning semantically rich yet discriminative representations, universally for image recognition in zero-shot, linear-probe, fully finetuning and transfer learning scenarios. Particularly, it attains gains up to 9.2% and 14.5% in average on zero-shot recognition benchmarks over the language-image contrastive learning and supervised learning methods, respectively. In linear probe setting, it also boosts the performance over the two methods by 7.3% and 3.4%, respectively. Our study also indicates that UniCL stand-alone is a good learner on pure image-label data, rivaling the supervised learning methods across three image classification datasets and two types of vision backbones, ResNet and Swin Transformer. Code is available at https://github.com/microsoft/UniCL.
Backdoor Attacks for Remote Sensing Data with Wavelet Transform
Nov 15, 2022
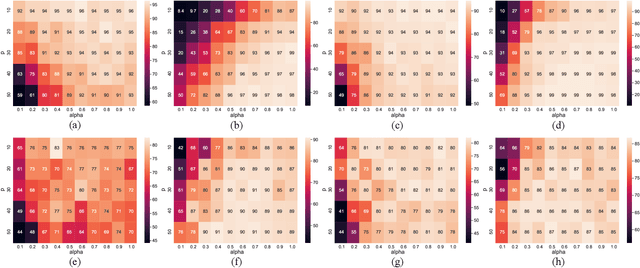

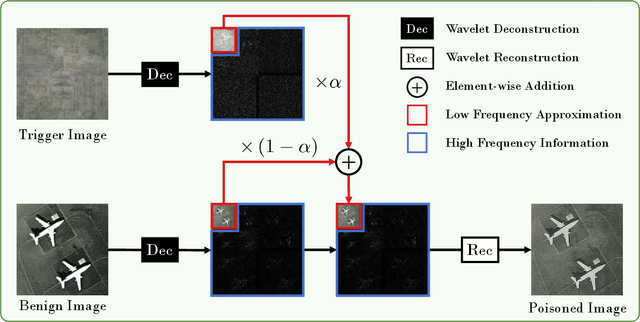
Recent years have witnessed the great success of deep learning algorithms in the geoscience and remote sensing realm. Nevertheless, the security and robustness of deep learning models deserve special attention when addressing safety-critical remote sensing tasks. In this paper, we provide a systematic analysis of backdoor attacks for remote sensing data, where both scene classification and semantic segmentation tasks are considered. While most of the existing backdoor attack algorithms rely on visible triggers like squared patches with well-designed patterns, we propose a novel wavelet transform-based attack (WABA) method, which can achieve invisible attacks by injecting the trigger image into the poisoned image in the low-frequency domain. In this way, the high-frequency information in the trigger image can be filtered out in the attack, resulting in stealthy data poisoning. Despite its simplicity, the proposed method can significantly cheat the current state-of-the-art deep learning models with a high attack success rate. We further analyze how different trigger images and the hyper-parameters in the wavelet transform would influence the performance of the proposed method. Extensive experiments on four benchmark remote sensing datasets demonstrate the effectiveness of the proposed method for both scene classification and semantic segmentation tasks and thus highlight the importance of designing advanced backdoor defense algorithms to address this threat in remote sensing scenarios. The code will be available online at \url{https://github.com/ndraeger/waba}.
Deep Learning for Medical Image Registration: A Comprehensive Review
Apr 24, 2022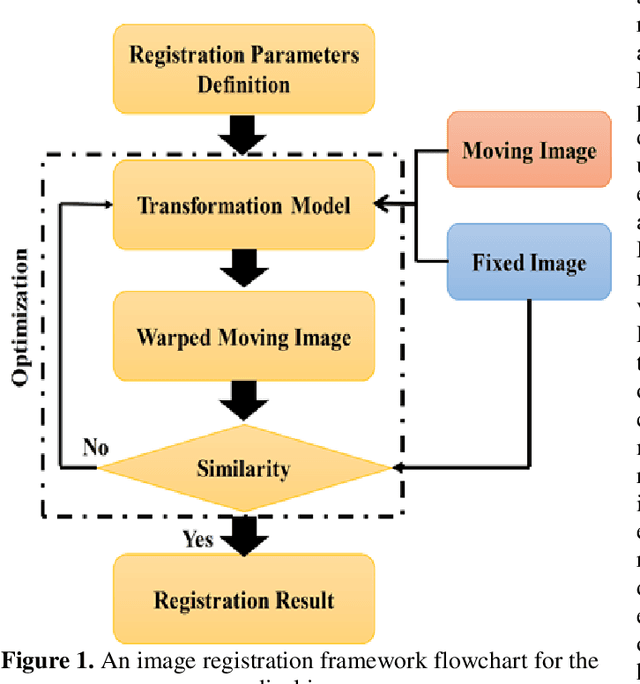
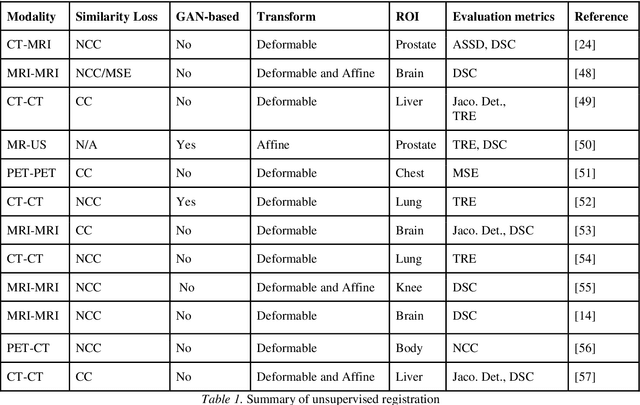
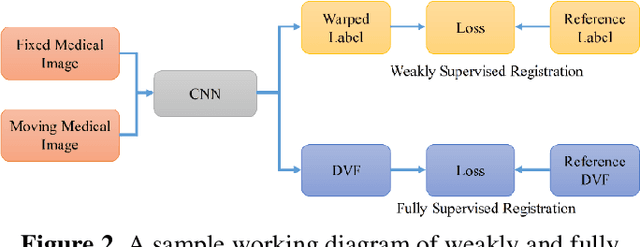
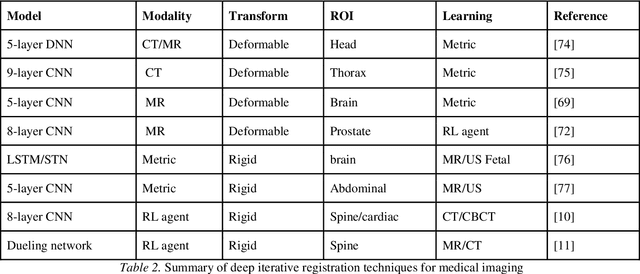
Image registration is a critical component in the applications of various medical image analyses. In recent years, there has been a tremendous surge in the development of deep learning (DL)-based medical image registration models. This paper provides a comprehensive review of medical image registration. Firstly, a discussion is provided for supervised registration categories, for example, fully supervised, dual supervised, and weakly supervised registration. Next, similarity-based as well as generative adversarial network (GAN)-based registration are presented as part of unsupervised registration. Deep iterative registration is then described with emphasis on deep similarity-based and reinforcement learning-based registration. Moreover, the application areas of medical image registration are reviewed. This review focuses on monomodal and multimodal registration and associated imaging, for instance, X-ray, CT scan, ultrasound, and MRI. The existing challenges are highlighted in this review, where it is shown that a major challenge is the absence of a training dataset with known transformations. Finally, a discussion is provided on the promising future research areas in the field of DL-based medical image registration.
* 18 pages, 7 figures
Learning Graph Neural Networks for Image Style Transfer
Jul 24, 2022
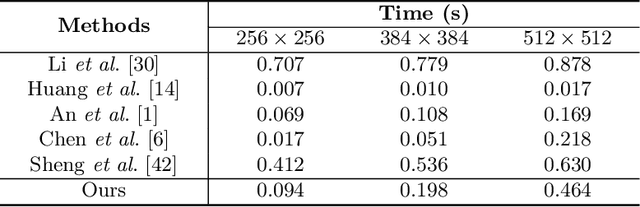
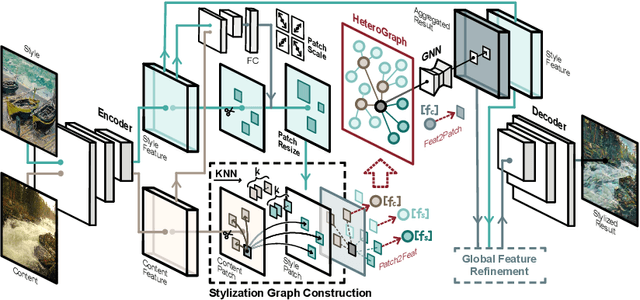

State-of-the-art parametric and non-parametric style transfer approaches are prone to either distorted local style patterns due to global statistics alignment, or unpleasing artifacts resulting from patch mismatching. In this paper, we study a novel semi-parametric neural style transfer framework that alleviates the deficiency of both parametric and non-parametric stylization. The core idea of our approach is to establish accurate and fine-grained content-style correspondences using graph neural networks (GNNs). To this end, we develop an elaborated GNN model with content and style local patches as the graph vertices. The style transfer procedure is then modeled as the attention-based heterogeneous message passing between the style and content nodes in a learnable manner, leading to adaptive many-to-one style-content correlations at the local patch level. In addition, an elaborated deformable graph convolutional operation is introduced for cross-scale style-content matching. Experimental results demonstrate that the proposed semi-parametric image stylization approach yields encouraging results on the challenging style patterns, preserving both global appearance and exquisite details. Furthermore, by controlling the number of edges at the inference stage, the proposed method also triggers novel functionalities like diversified patch-based stylization with a single model.
Rethinking Out-of-Distribution Detection From a Human-Centric Perspective
Nov 30, 2022
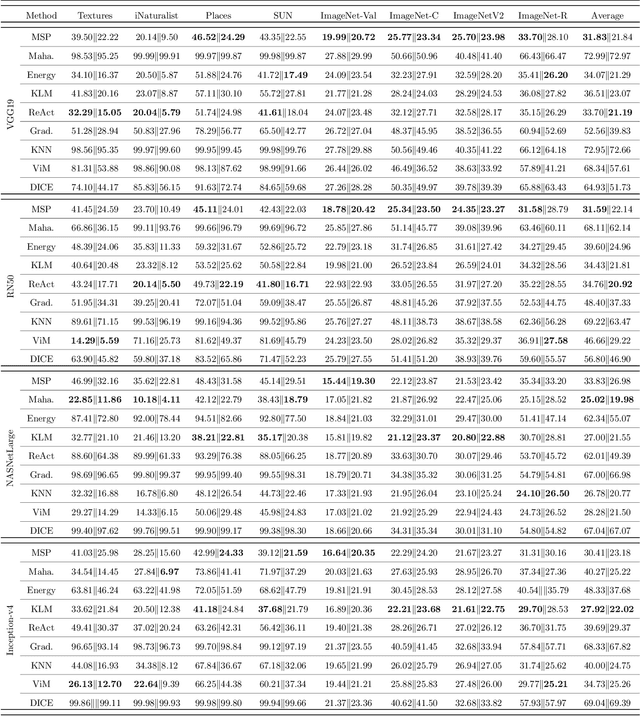
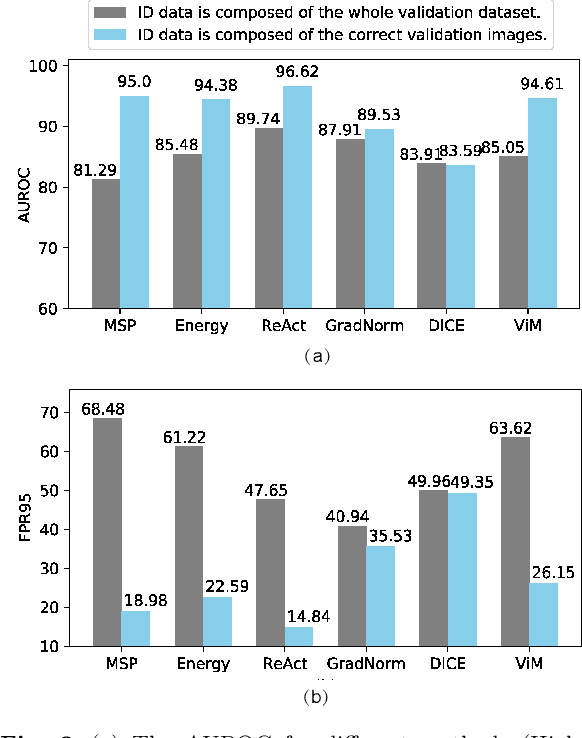
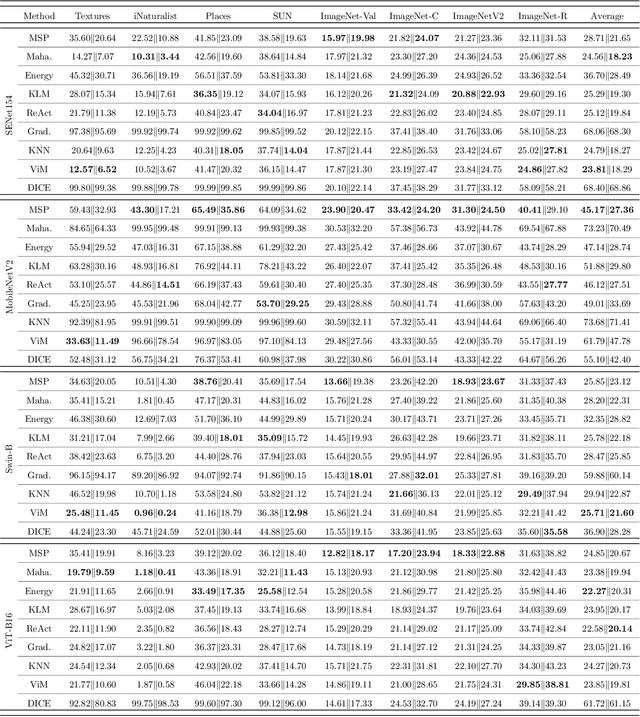
Out-Of-Distribution (OOD) detection has received broad attention over the years, aiming to ensure the reliability and safety of deep neural networks (DNNs) in real-world scenarios by rejecting incorrect predictions. However, we notice a discrepancy between the conventional evaluation vs. the essential purpose of OOD detection. On the one hand, the conventional evaluation exclusively considers risks caused by label-space distribution shifts while ignoring the risks from input-space distribution shifts. On the other hand, the conventional evaluation reward detection methods for not rejecting the misclassified image in the validation dataset. However, the misclassified image can also cause risks and should be rejected. We appeal to rethink OOD detection from a human-centric perspective, that a proper detection method should reject the case that the deep model's prediction mismatches the human expectations and adopt the case that the deep model's prediction meets the human expectations. We propose a human-centric evaluation and conduct extensive experiments on 45 classifiers and 8 test datasets. We find that the simple baseline OOD detection method can achieve comparable and even better performance than the recently proposed methods, which means that the development in OOD detection in the past years may be overestimated. Additionally, our experiments demonstrate that model selection is non-trivial for OOD detection and should be considered as an integral of the proposed method, which differs from the claim in existing works that proposed methods are universal across different models.
Single-Pixel Image Reconstruction Based on Block Compressive Sensing and Deep Learning
Jul 14, 2022
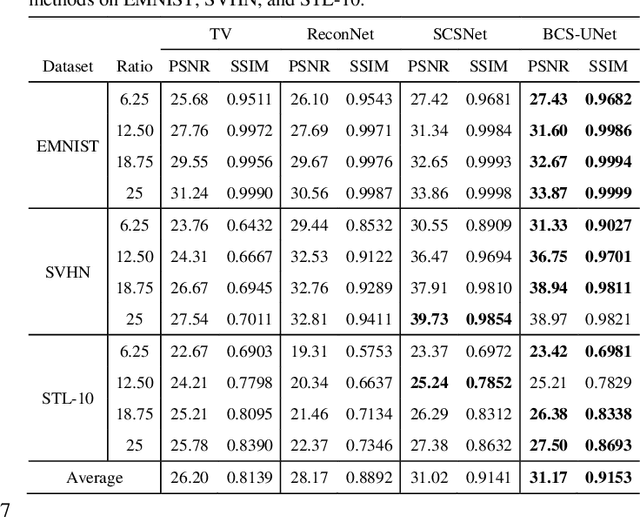
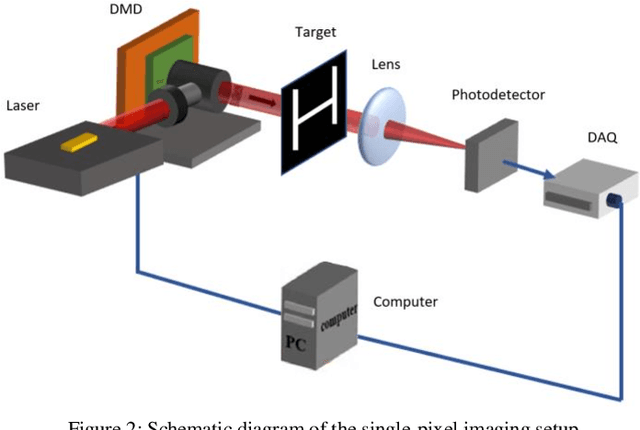

Single-pixel imaging (SPI) is a novel imaging technique whose working principle is based on the compressive sensing (CS) theory. In SPI, data is obtained through a series of compressive measurements and the corresponding image is reconstructed. Typically, the reconstruction algorithm such as basis pursuit relies on the sparsity assumption in images. However, recent advances in deep learning have found its uses in reconstructing CS images. Despite showing a promising result in simulations, it is often unclear how such an algorithm can be implemented in an actual SPI setup. In this paper, we demonstrate the use of deep learning on the reconstruction of SPI images in conjunction with block compressive sensing (BCS). We also proposed a novel reconstruction model based on convolutional neural networks that outperforms other competitive CS reconstruction algorithms. Besides, by incorporating BCS in our deep learning model, we were able to reconstruct images of any size above a certain smallest image size. In addition, we show that our model is capable of reconstructing images obtained from an SPI setup while being priorly trained on natural images, which can be vastly different from the SPI images. This opens up opportunity for the feasibility of pretrained deep learning models for CS reconstructions of images from various domain areas.
Bi-Noising Diffusion: Towards Conditional Diffusion Models with Generative Restoration Priors
Dec 14, 2022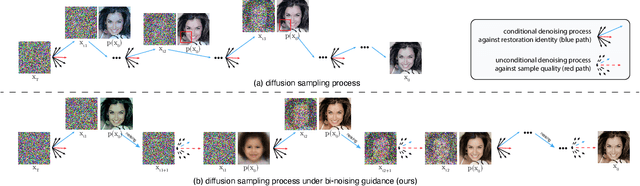
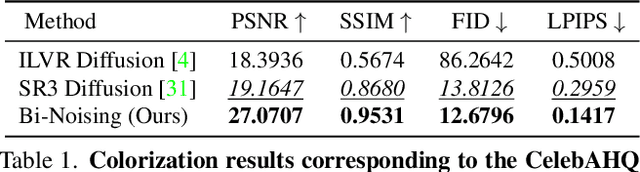

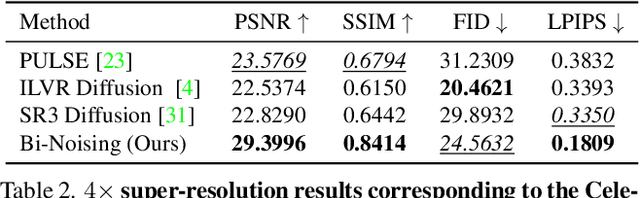
Conditional diffusion probabilistic models can model the distribution of natural images and can generate diverse and realistic samples based on given conditions. However, oftentimes their results can be unrealistic with observable color shifts and textures. We believe that this issue results from the divergence between the probabilistic distribution learned by the model and the distribution of natural images. The delicate conditions gradually enlarge the divergence during each sampling timestep. To address this issue, we introduce a new method that brings the predicted samples to the training data manifold using a pretrained unconditional diffusion model. The unconditional model acts as a regularizer and reduces the divergence introduced by the conditional model at each sampling step. We perform comprehensive experiments to demonstrate the effectiveness of our approach on super-resolution, colorization, turbulence removal, and image-deraining tasks. The improvements obtained by our method suggest that the priors can be incorporated as a general plugin for improving conditional diffusion models.
Recurrent Affine Transformation for Text-to-image Synthesis
Apr 22, 2022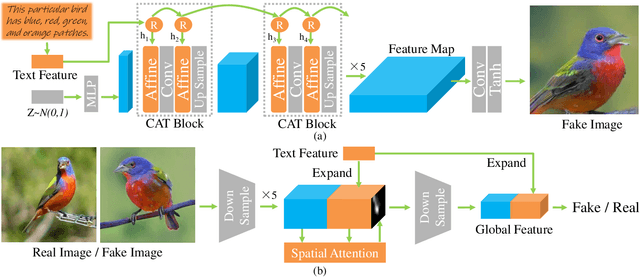
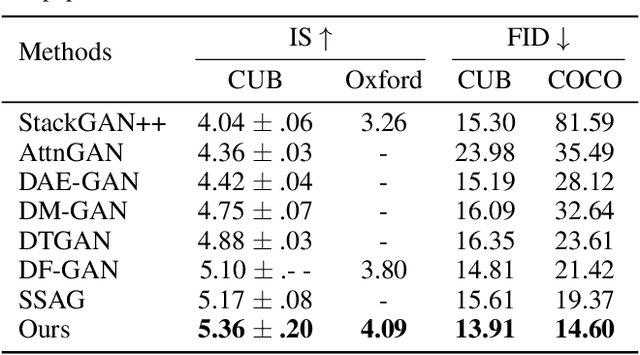

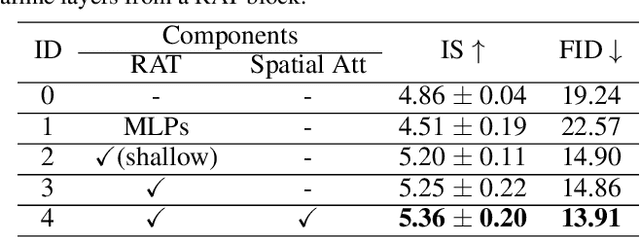
Text-to-image synthesis aims to generate natural images conditioned on text descriptions. The main difficulty of this task lies in effectively fusing text information into the image synthesis process. Existing methods usually adaptively fuse suitable text information into the synthesis process with multiple isolated fusion blocks (e.g., Conditional Batch Normalization and Instance Normalization). However, isolated fusion blocks not only conflict with each other but also increase the difficulty of training (see first page of the supplementary). To address these issues, we propose a Recurrent Affine Transformation (RAT) for Generative Adversarial Networks that connects all the fusion blocks with a recurrent neural network to model their long-term dependency. Besides, to improve semantic consistency between texts and synthesized images, we incorporate a spatial attention model in the discriminator. Being aware of matching image regions, text descriptions supervise the generator to synthesize more relevant image contents. Extensive experiments on the CUB, Oxford-102 and COCO datasets demonstrate the superiority of the proposed model in comparison to state-of-the-art models \footnote{https://github.com/senmaoy/Recurrent-Affine-Transformation-for-Text-to-image-Synthesis.git}