 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Kidney and Kidney Tumour Segmentation in CT Images
Dec 26, 2022
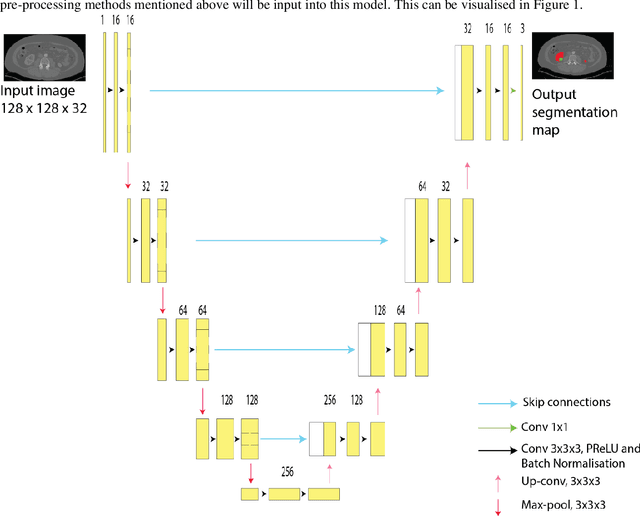
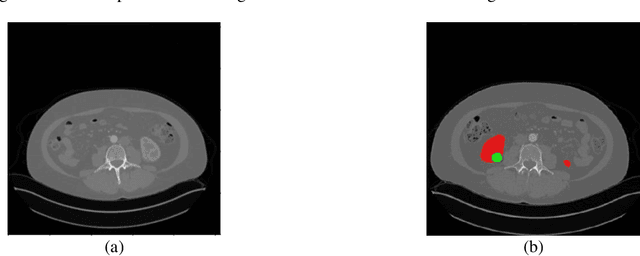
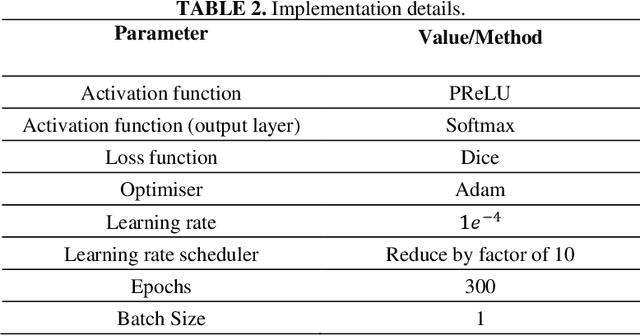

Automatic segmentation of kidney and kidney tumour in Computed Tomography (CT) images is essential, as it uses less time as compared to the current gold standard of manual segmentation. However, many hospitals are still reliant on manual study and segmentation of CT images by medical practitioners because of its higher accuracy. Thus, this study focuses on the development of an approach for automatic kidney and kidney tumour segmentation in contrast-enhanced CT images. A method based on Convolutional Neural Network (CNN) was proposed, where a 3D U-Net segmentation model was developed and trained to delineate the kidney and kidney tumour from CT scans. Each CT image was pre-processed before inputting to the CNN, and the effect of down-sampled and patch-wise input images on the model performance was analysed. The proposed method was evaluated on the publicly available 2021 Kidney and Kidney Tumour Segmentation Challenge (KiTS21) dataset. The method with the best performing model recorded an average training Dice score of 0.6129, with the kidney and kidney tumour Dice scores of 0.7923 and 0.4344, respectively. For testing, the model obtained a kidney Dice score of 0.8034, and a kidney tumour Dice score of 0.4713, with an average Dice score of 0.6374.
SpectNet : End-to-End Audio Signal Classification Using Learnable Spectrograms
Nov 17, 2022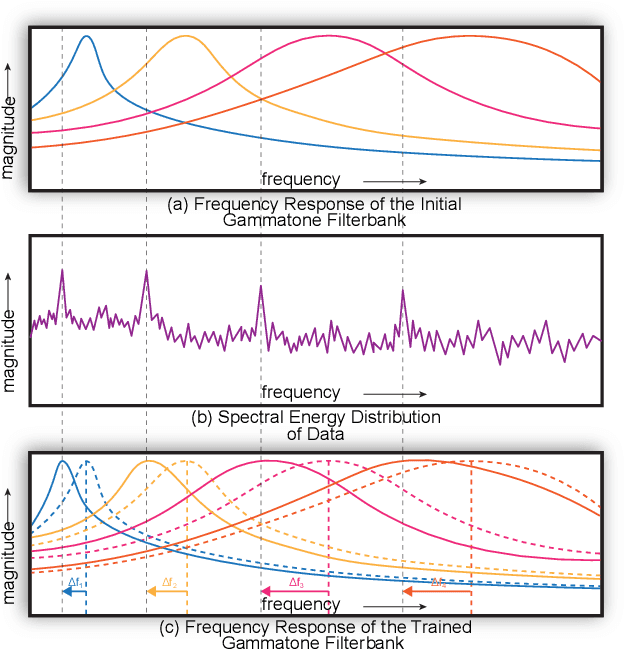
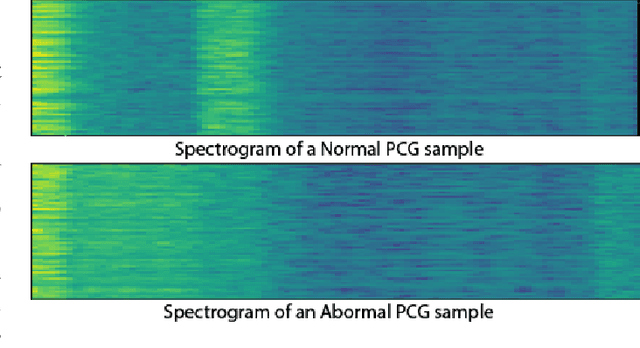
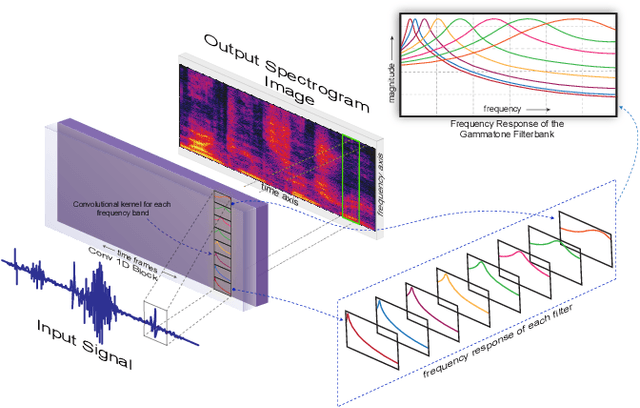
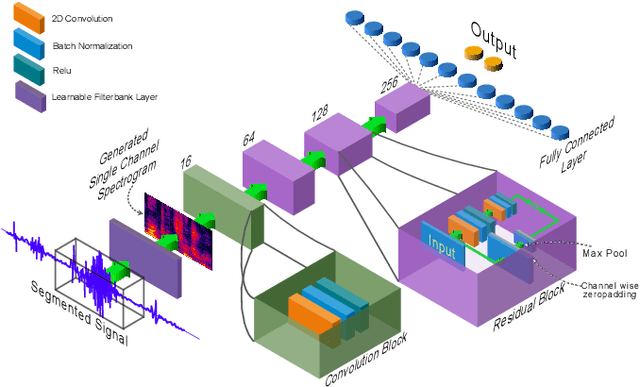
Pattern recognition from audio signals is an active research topic encompassing audio tagging, acoustic scene classification, music classification, and other areas. Spectrogram and mel-frequency cepstral coefficients (MFCC) are among the most commonly used features for audio signal analysis and classification. Recently, deep convolutional neural networks (CNN) have been successfully used for audio classification problems using spectrogram-based 2D features. In this paper, we present SpectNet, an integrated front-end layer that extracts spectrogram features within a CNN architecture that can be used for audio pattern recognition tasks. The front-end layer utilizes learnable gammatone filters that are initialized using mel-scale filters. The proposed layer outputs a 2D spectrogram image which can be fed into a 2D CNN for classification. The parameters of the entire network, including the front-end filterbank, can be updated via back-propagation. This training scheme allows for fine-tuning the spectrogram-image features according to the target audio dataset. The proposed method is evaluated in two different audio signal classification tasks: heart sound anomaly detection and acoustic scene classification. The proposed method shows a significant 1.02\% improvement in MACC for the heart sound classification task and 2.11\% improvement in accuracy for the acoustic scene classification task compared to the classical spectrogram image features. The source code of our experiments can be found at \url{https://github.com/mHealthBuet/SpectNet}
Simple Baselines for Image Restoration
Apr 10, 2022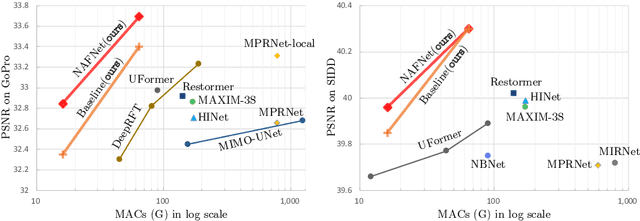

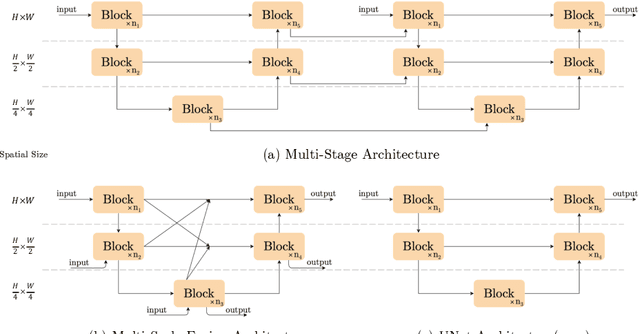
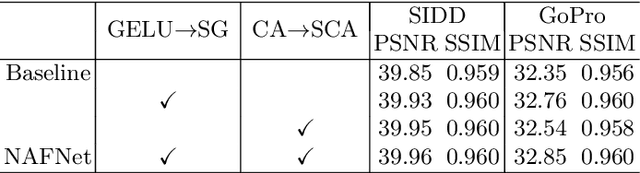
Although there have been significant advances in the field of image restoration recently, the system complexity of the state-of-the-art (SOTA) methods is increasing as well, which may hinder the convenient analysis and comparison of methods. In this paper, we propose a simple baseline that exceeds the SOTA methods and is computationally efficient. To further simplify the baseline, we reveal that the nonlinear activation functions, e.g. Sigmoid, ReLU, GELU, Softmax, etc. are not necessary: they could be replaced by multiplication or removed. Thus, we derive a Nonlinear Activation Free Network, namely NAFNet, from the baseline. SOTA results are achieved on various challenging benchmarks, e.g. 33.69 dB PSNR on GoPro (for image deblurring), exceeding the previous SOTA 0.38 dB with only 8.4% of its computational costs; 40.30 dB PSNR on SIDD (for image denoising), exceeding the previous SOTA 0.28 dB with less than half of its computational costs. The code and the pretrained models will be released at https://github.com/megvii-research/NAFNet.
ExpansionNet v2: Block Static Expansion in fast end to end training for Image Captioning
Aug 19, 2022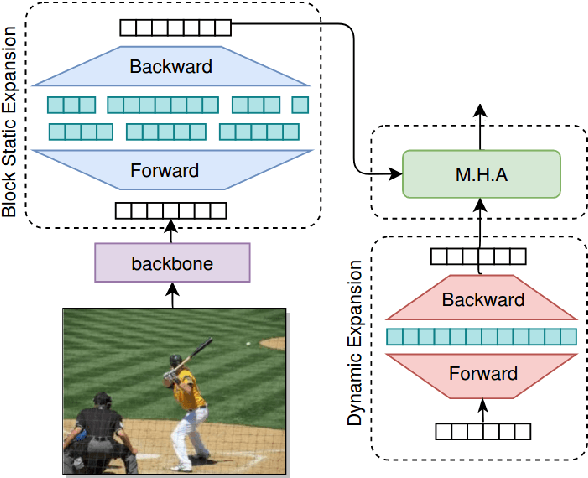
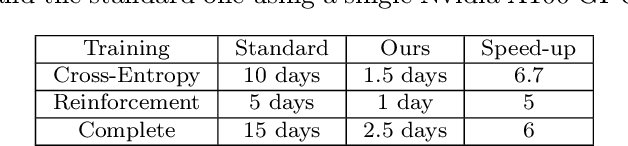
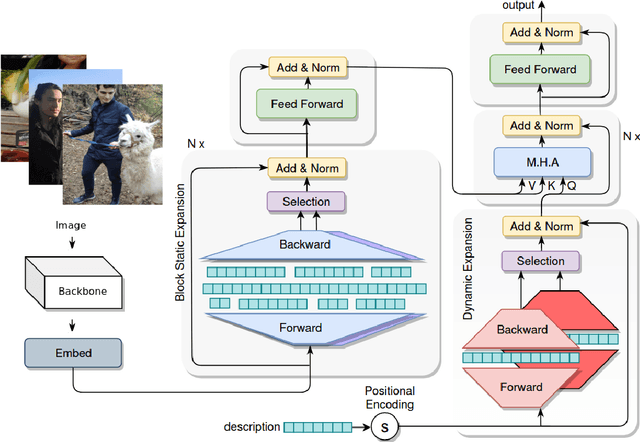
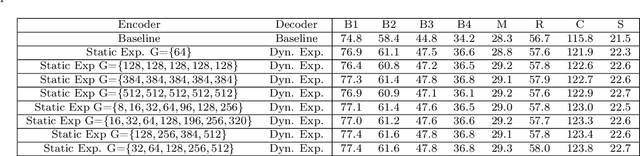
Expansion methods explore the possibility of performance bottlenecks in the input length in Deep Learning methods. In this work, we introduce the Block Static Expansion which distributes and processes the input over a heterogeneous and arbitrarily big collection of sequences characterized by a different length compared to the input one. Adopting this method we introduce a model called ExpansionNet v2, which is trained using our novel training strategy, designed to be not only effective but also 6 times faster compared to the standard approach of recent works in Image Captioning. The model achieves the state of art performance over the MS-COCO 2014 captioning challenge with a score of 143.7 CIDEr-D in the offline test split, 140.8 CIDEr-D in the online evaluation server and 72.9 All-CIDEr on the nocaps validation set. Source code available at: https://github.com/jchenghu/ExpansionNet_v2
Single Stage Multi-Pose Virtual Try-On
Nov 19, 2022
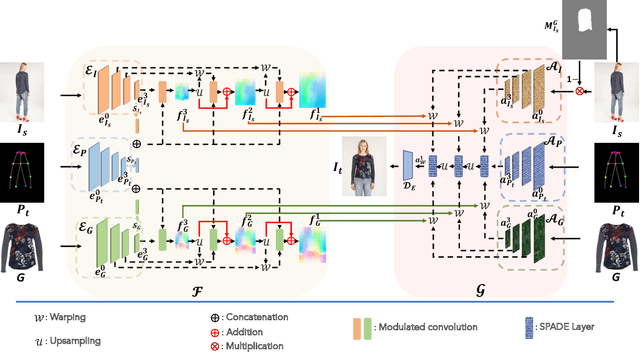


Multi-pose virtual try-on (MPVTON) aims to fit a target garment onto a person at a target pose. Compared to traditional virtual try-on (VTON) that fits the garment but keeps the pose unchanged, MPVTON provides a better try-on experience, but is also more challenging due to the dual garment and pose editing objectives. Existing MPVTON methods adopt a pipeline comprising three disjoint modules including a target semantic layout prediction module, a coarse try-on image generator and a refinement try-on image generator. These models are trained separately, leading to sub-optimal model training and unsatisfactory results. In this paper, we propose a novel single stage model for MPVTON. Key to our model is a parallel flow estimation module that predicts the flow fields for both person and garment images conditioned on the target pose. The predicted flows are subsequently used to warp the appearance feature maps of the person and the garment images to construct a style map. The map is then used to modulate the target pose's feature map for target try-on image generation. With the parallel flow estimation design, our model can be trained end-to-end in a single stage and is more computationally efficient, resulting in new SOTA performance on existing MPVTON benchmarks. We further introduce multi-task training and demonstrate that our model can also be applied for traditional VTON and pose transfer tasks and achieve comparable performance to SOTA specialized models on both tasks.
MSP-Former: Multi-Scale Projection Transformer for Single Image Desnowing
Jul 17, 2022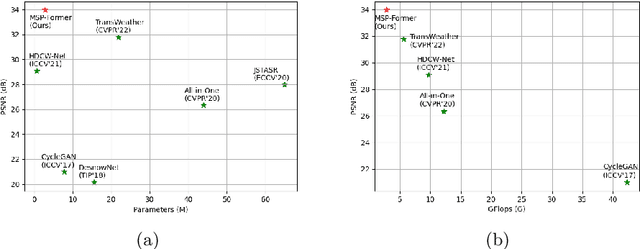
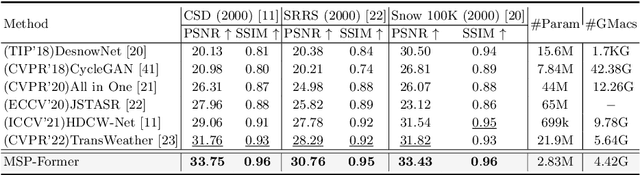

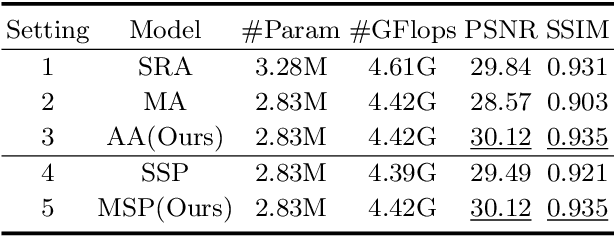
Image restoration of snow scenes in severe weather is a difficult task. Snow images have complex degradations and are cluttered over clean images, changing the distribution of clean images. The previous methods based on CNNs are challenging to remove perfectly in restoring snow scenes due to their local inductive biases' lack of a specific global modeling ability. In this paper, we apply the vision transformer to the task of snow removal from a single image. Specifically, we propose a parallel network architecture split along the channel, performing local feature refinement and global information modeling separately. We utilize a channel shuffle operation to combine their respective strengths to enhance network performance. Second, we propose the MSP module, which utilizes multi-scale avgpool to aggregate information of different sizes and simultaneously performs multi-scale projection self-attention on multi-head self-attention to improve the representation ability of the model under different scale degradations. Finally, we design a lightweight and simple local capture module, which can refine the local capture capability of the model. In the experimental part, we conduct extensive experiments to demonstrate the superiority of our method. We compared the previous snow removal methods on three snow scene datasets. The experimental results show that our method surpasses the state-of-the-art methods with fewer parameters and computation. We achieve substantial growth by 1.99dB and SSIM 0.03 on the CSD test dataset. On the SRRS and Snow100K datasets, we also increased PSNR by 2.47dB and 1.62dB compared with the Transweather approach and improved by 0.03 in SSIM. In the visual comparison section, our MSP-Former also achieves better visual effects than existing methods, proving the usability of our method.
FRA-RIR: Fast Random Approximation of the Image-source Method
Aug 08, 2022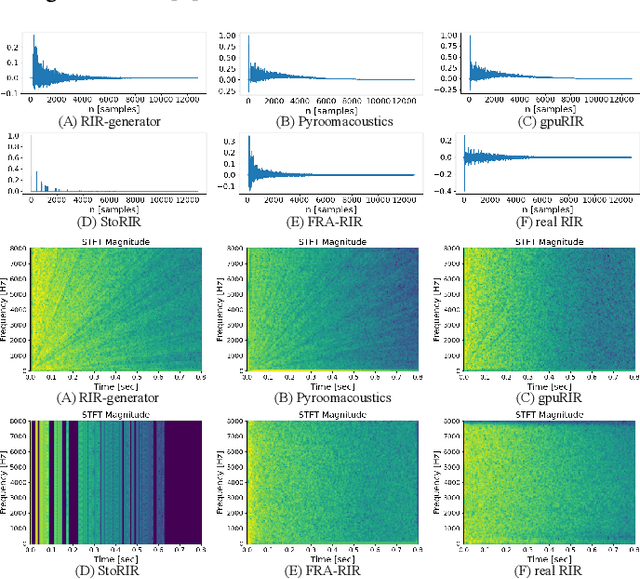
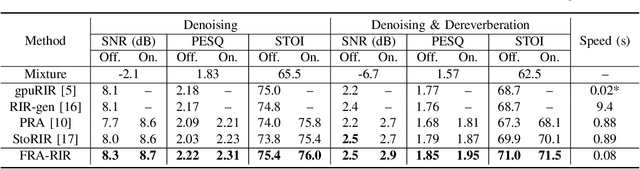
The training of modern speech processing systems often requires a large amount of simulated room impulse response (RIR) data in order to allow the systems to generalize well in real-world, reverberant environments. However, simulating realistic RIR data typically requires accurate physical modeling, and the acceleration of such simulation process typically requires certain computational platforms such as a graphics processing unit (GPU). In this paper, we propose FRA-RIR, a fast random approximation method of the widely-used image-source method (ISM), to efficiently generate realistic RIR data without specific computational devices. FRA-RIR replaces the physical simulation in the standard ISM by a series of random approximations, which significantly speeds up the simulation process and enables its application in on-the-fly data generation pipelines. Experiments show that FRA-RIR can not only be significantly faster than other existing ISM-based RIR simulation tools on standard computational platforms, but also improves the performance of speech denoising systems evaluated on real-world RIR when trained with simulated RIR. A Python implementation of FRA-RIR is available online\footnote{\url{https://github.com/yluo42/FRA-RIR}}.
Learning Disentangled Label Representations for Multi-label Classification
Dec 02, 2022
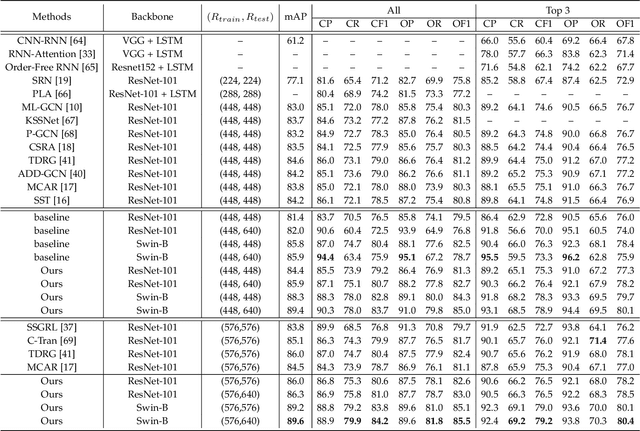
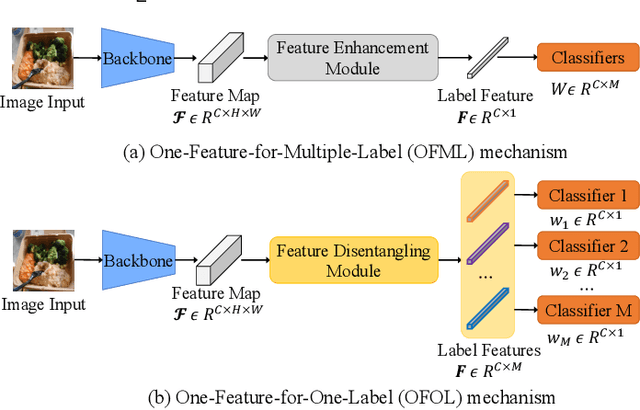
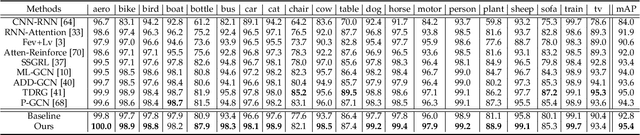
Although various methods have been proposed for multi-label classification, most approaches still follow the feature learning mechanism of the single-label (multi-class) classification, namely, learning a shared image feature to classify multiple labels. However, we find this One-shared-Feature-for-Multiple-Labels (OFML) mechanism is not conducive to learning discriminative label features and makes the model non-robustness. For the first time, we mathematically prove that the inferiority of the OFML mechanism is that the optimal learned image feature cannot maintain high similarities with multiple classifiers simultaneously in the context of minimizing cross-entropy loss. To address the limitations of the OFML mechanism, we introduce the One-specific-Feature-for-One-Label (OFOL) mechanism and propose a novel disentangled label feature learning (DLFL) framework to learn a disentangled representation for each label. The specificity of the framework lies in a feature disentangle module, which contains learnable semantic queries and a Semantic Spatial Cross-Attention (SSCA) module. Specifically, learnable semantic queries maintain semantic consistency between different images of the same label. The SSCA module localizes the label-related spatial regions and aggregates located region features into the corresponding label feature to achieve feature disentanglement. We achieve state-of-the-art performance on eight datasets of three tasks, \ie, multi-label classification, pedestrian attribute recognition, and continual multi-label learning.
Generative Negative Text Replay for Continual Vision-Language Pretraining
Oct 31, 2022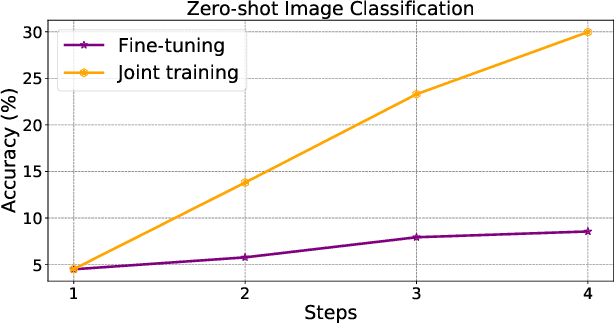
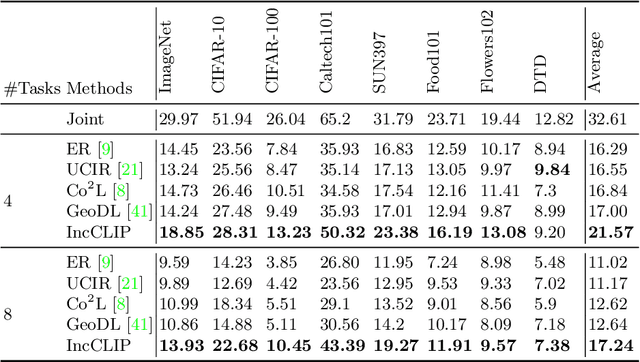
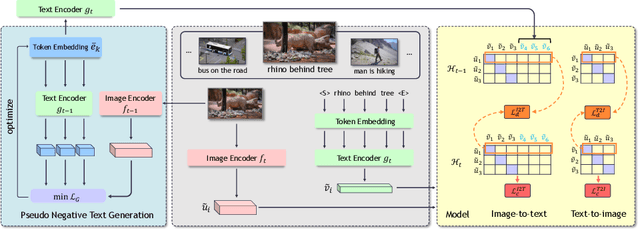
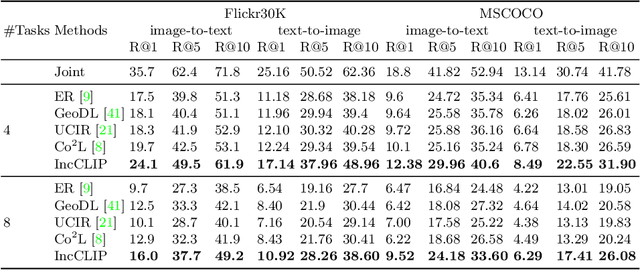
Vision-language pre-training (VLP) has attracted increasing attention recently. With a large amount of image-text pairs, VLP models trained with contrastive loss have achieved impressive performance in various tasks, especially the zero-shot generalization on downstream datasets. In practical applications, however, massive data are usually collected in a streaming fashion, requiring VLP models to continuously integrate novel knowledge from incoming data and retain learned knowledge. In this work, we focus on learning a VLP model with sequential chunks of image-text pair data. To tackle the catastrophic forgetting issue in this multi-modal continual learning setting, we first introduce pseudo text replay that generates hard negative texts conditioned on the training images in memory, which not only better preserves learned knowledge but also improves the diversity of negative samples in the contrastive loss. Moreover, we propose multi-modal knowledge distillation between images and texts to align the instance-wise prediction between old and new models. We incrementally pre-train our model on both the instance and class incremental splits of the Conceptual Caption dataset, and evaluate the model on zero-shot image classification and image-text retrieval tasks. Our method consistently outperforms the existing baselines with a large margin, which demonstrates its superiority. Notably, we realize an average performance boost of $4.60\%$ on image-classification downstream datasets for the class incremental split.
Book Cover Synthesis from the Summary
Nov 03, 2022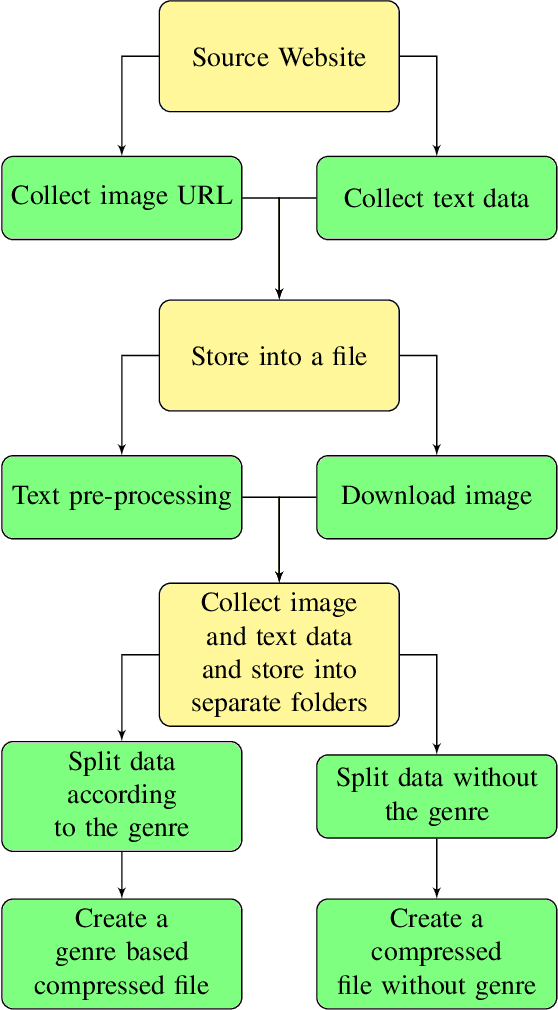
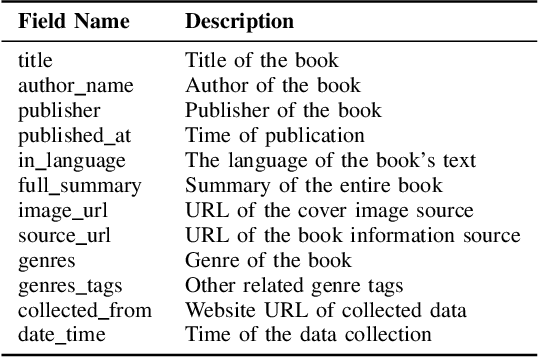
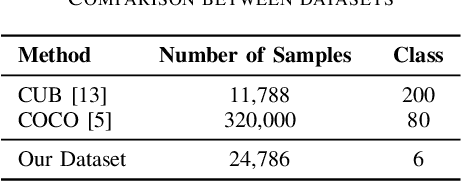

The cover is the face of a book and is a point of attraction for the readers. Designing book covers is an essential task in the publishing industry. One of the main challenges in creating a book cover is representing the theme of the book's content in a single image. In this research, we explore ways to produce a book cover using artificial intelligence based on the fact that there exists a relationship between the summary of the book and its cover. Our key motivation is the application of text-to-image synthesis methods to generate images from given text or captions. We explore several existing text-to-image conversion techniques for this purpose and propose an approach to exploit these frameworks for producing book covers from provided summaries. We construct a dataset of English books that contains a large number of samples of summaries of existing books and their cover images. In this paper, we describe our approach to collecting, organizing, and pre-processing the dataset to use it for training models. We apply different text-to-image synthesis techniques to generate book covers from the summary and exhibit the results in this paper.