 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Huber-energy measure quantization
Dec 15, 2022
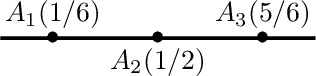
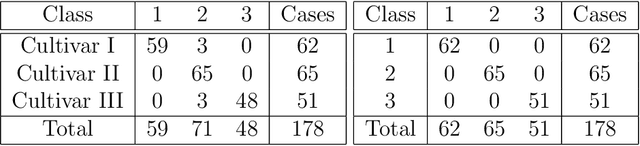
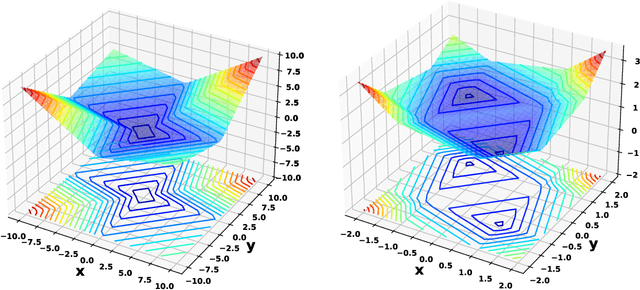
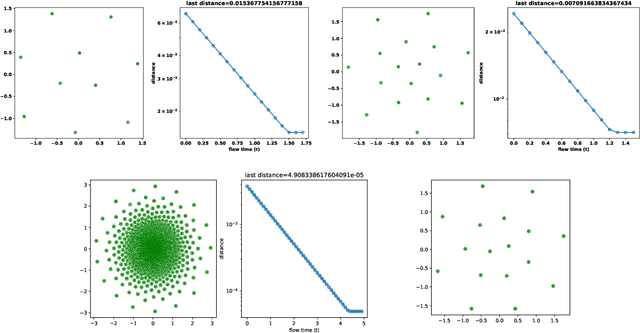
We describe a measure quantization procedure i.e., an algorithm which finds the best approximation of a target probability law (and more generally signed finite variation measure) by a sum of Q Dirac masses (Q being the quantization parameter). The procedure is implemented by minimizing the statistical distance between the original measure and its quantized version; the distance is built from a negative definite kernel and, if necessary, can be computed on the fly and feed to a stochastic optimization algorithm (such as SGD, Adam, ...). We investigate theoretically the fundamental questions of existence of the optimal measure quantizer and identify what are the required kernel properties that guarantee suitable behavior. We test the procedure, called HEMQ, on several databases: multi-dimensional Gaussian mixtures, Wiener space cubature, Italian wine cultivars and the MNIST image database. The results indicate that the HEMQ algorithm is robust and versatile and, for the class of Huber-energy kernels, it matches the expected intuitive behavior.
Learning Topological Interactions for Multi-Class Medical Image Segmentation
Jul 20, 2022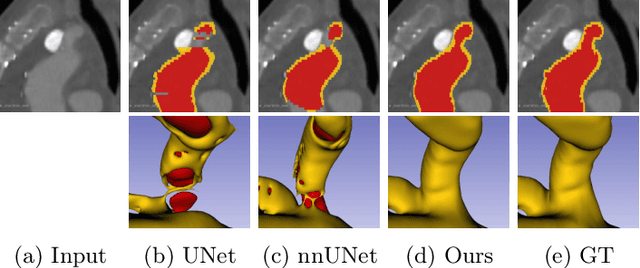
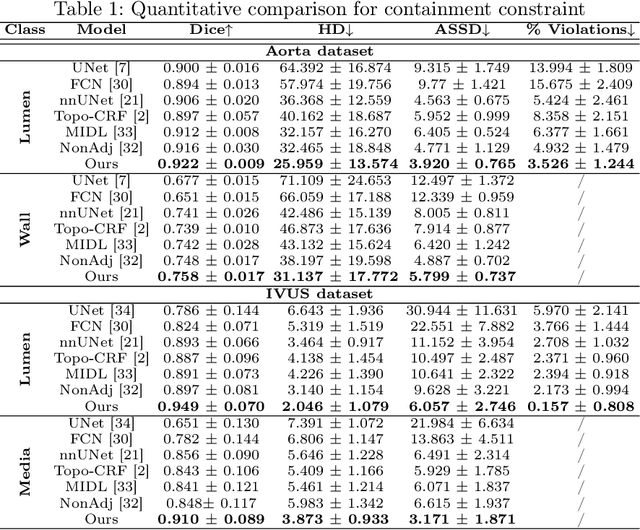
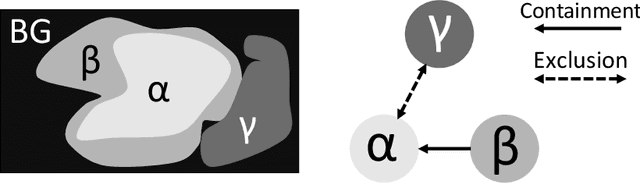
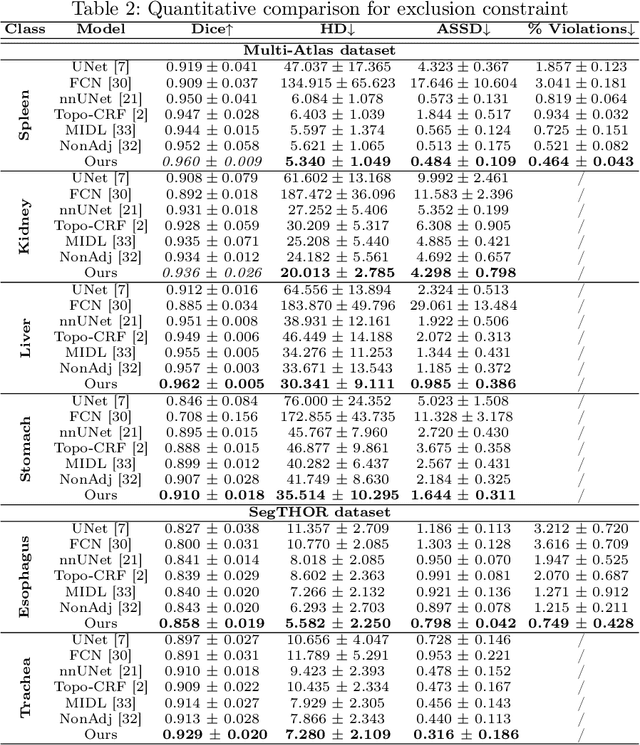
Deep learning methods have achieved impressive performance for multi-class medical image segmentation. However, they are limited in their ability to encode topological interactions among different classes (e.g., containment and exclusion). These constraints naturally arise in biomedical images and can be crucial in improving segmentation quality. In this paper, we introduce a novel topological interaction module to encode the topological interactions into a deep neural network. The implementation is completely convolution-based and thus can be very efficient. This empowers us to incorporate the constraints into end-to-end training and enrich the feature representation of neural networks. The efficacy of the proposed method is validated on different types of interactions. We also demonstrate the generalizability of the method on both proprietary and public challenge datasets, in both 2D and 3D settings, as well as across different modalities such as CT and Ultrasound. Code is available at: https://github.com/TopoXLab/TopoInteraction
VIINTER: View Interpolation with Implicit Neural Representations of Images
Nov 01, 2022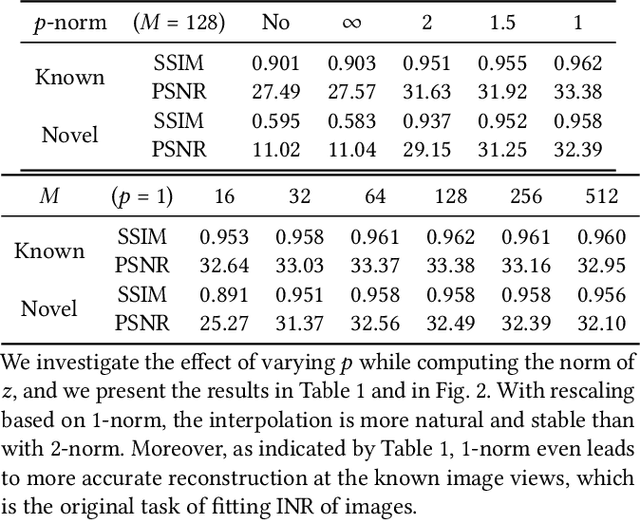

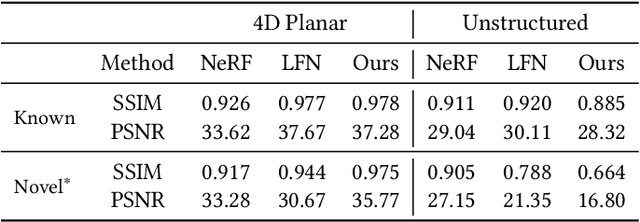
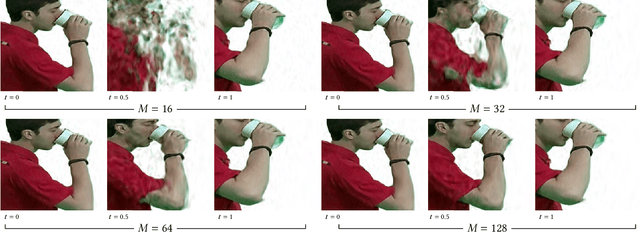
We present VIINTER, a method for view interpolation by interpolating the implicit neural representation (INR) of the captured images. We leverage the learned code vector associated with each image and interpolate between these codes to achieve viewpoint transitions. We propose several techniques that significantly enhance the interpolation quality. VIINTER signifies a new way to achieve view interpolation without constructing 3D structure, estimating camera poses, or computing pixel correspondence. We validate the effectiveness of VIINTER on several multi-view scenes with different types of camera layout and scene composition. As the development of INR of images (as opposed to surface or volume) has centered around tasks like image fitting and super-resolution, with VIINTER, we show its capability for view interpolation and offer a promising outlook on using INR for image manipulation tasks.
HarDNet-DFUS: An Enhanced Harmonically-Connected Network for Diabetic Foot Ulcer Image Segmentation and Colonoscopy Polyp Segmentation
Sep 15, 2022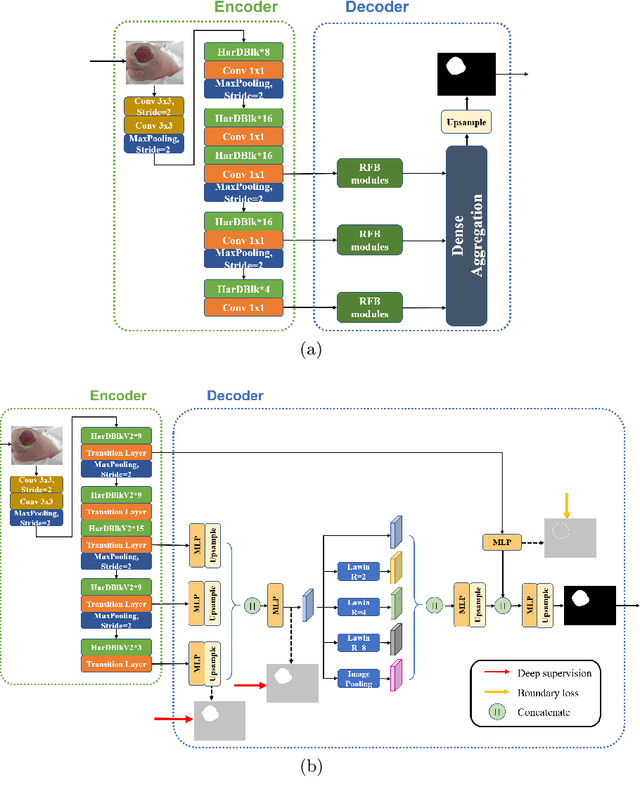

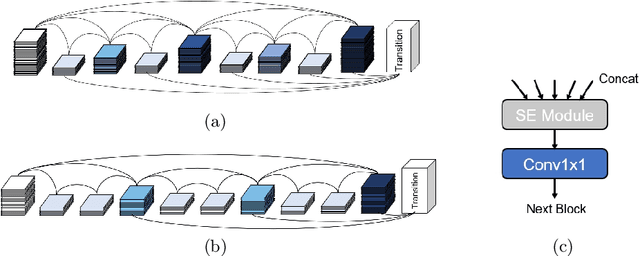

We present a neural network architecture for medical image segmentation of diabetic foot ulcers and colonoscopy polyps. Diabetic foot ulcers are caused by neuropathic and vascular complications of diabetes mellitus. In order to provide a proper diagnosis and treatment, wound care professionals need to extract accurate morphological features from the foot wounds. Using computer-aided systems is a promising approach to extract related morphological features and segment the lesions. We propose a convolution neural network called HarDNet-DFUS by enhancing the backbone and replacing the decoder of HarDNet-MSEG, which was SOTA for colonoscopy polyp segmentation in 2021. For the MICCAI 2022 Diabetic Foot Ulcer Segmentation Challenge (DFUC2022), we train HarDNet-DFUS using the DFUC2022 dataset and increase its robustness by means of five-fold cross validation, Test Time Augmentation, etc. In the validation phase of DFUC2022, HarDNet-DFUS achieved 0.7063 mean dice and was ranked third among all participants. In the final testing phase of DFUC2022, it achieved 0.7287 mean dice and was the first place winner. HarDNet-DFUS also deliver excellent performance for the colonoscopy polyp segmentation task. It achieves 0.924 mean Dice on the famous Kvasir dataset, an improvement of 1.2\% over the original HarDNet-MSEG. The codes are available on https://github.com/kytimmylai/DFUC2022 (for Diabetic Foot Ulcers Segmentation) and https://github.com/YuWenLo/HarDNet-DFUS (for Colonoscopy Polyp Segmentation).
Cross-modal Attention Congruence Regularization for Vision-Language Relation Alignment
Dec 20, 2022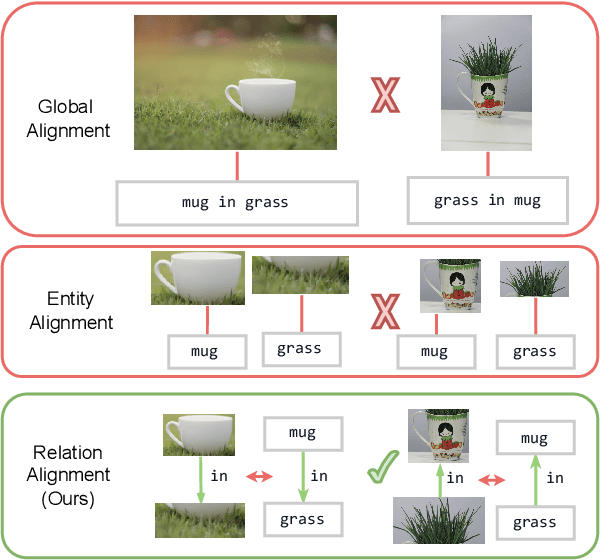
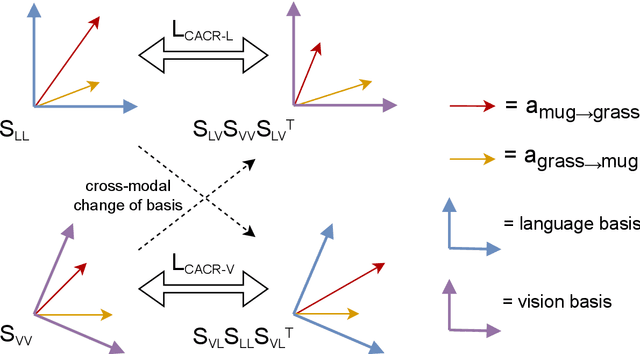
Despite recent progress towards scaling up multimodal vision-language models, these models are still known to struggle on compositional generalization benchmarks such as Winoground. We find that a critical component lacking from current vision-language models is relation-level alignment: the ability to match directional semantic relations in text (e.g., "mug in grass") with spatial relationships in the image (e.g., the position of the mug relative to the grass). To tackle this problem, we show that relation alignment can be enforced by encouraging the directed language attention from 'mug' to 'grass' (capturing the semantic relation 'in') to match the directed visual attention from the mug to the grass. Tokens and their corresponding objects are softly identified using the cross-modal attention. We prove that this notion of soft relation alignment is equivalent to enforcing congruence between vision and language attention matrices under a 'change of basis' provided by the cross-modal attention matrix. Intuitively, our approach projects visual attention into the language attention space to calculate its divergence from the actual language attention, and vice versa. We apply our Cross-modal Attention Congruence Regularization (CACR) loss to UNITER and improve on the state-of-the-art approach to Winoground.
Unsupervised Deraining: Where Asymmetric Contrastive Learning Meets Self-similarity
Nov 02, 2022
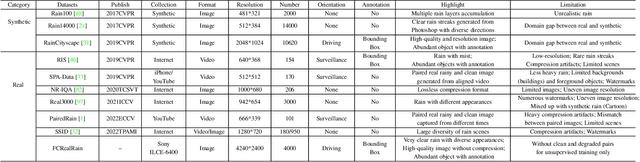

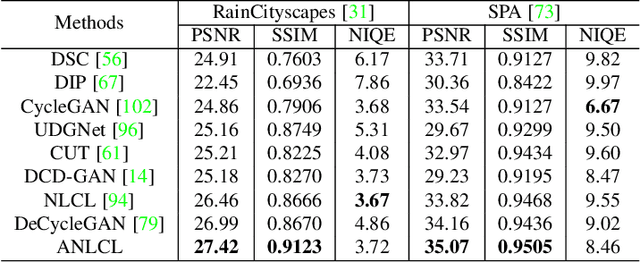
Most of the existing learning-based deraining methods are supervisedly trained on synthetic rainy-clean pairs. The domain gap between the synthetic and real rain makes them less generalized to complex real rainy scenes. Moreover, the existing methods mainly utilize the property of the image or rain layers independently, while few of them have considered their mutually exclusive relationship. To solve above dilemma, we explore the intrinsic intra-similarity within each layer and inter-exclusiveness between two layers and propose an unsupervised non-local contrastive learning (NLCL) deraining method. The non-local self-similarity image patches as the positives are tightly pulled together, rain patches as the negatives are remarkably pushed away, and vice versa. On one hand, the intrinsic self-similarity knowledge within positive/negative samples of each layer benefits us to discover more compact representation; on the other hand, the mutually exclusive property between the two layers enriches the discriminative decomposition. Thus, the internal self-similarity within each layer (similarity) and the external exclusive relationship of the two layers (dissimilarity) serving as a generic image prior jointly facilitate us to unsupervisedly differentiate the rain from clean image. We further discover that the intrinsic dimension of the non-local image patches is generally higher than that of the rain patches. This motivates us to design an asymmetric contrastive loss to precisely model the compactness discrepancy of the two layers for better discriminative decomposition. In addition, considering that the existing real rain datasets are of low quality, either small scale or downloaded from the internet, we collect a real large-scale dataset under various rainy kinds of weather that contains high-resolution rainy images.
Real-Time Physics-Based Object Pose Tracking during Non-Prehensile Manipulation
Nov 24, 2022

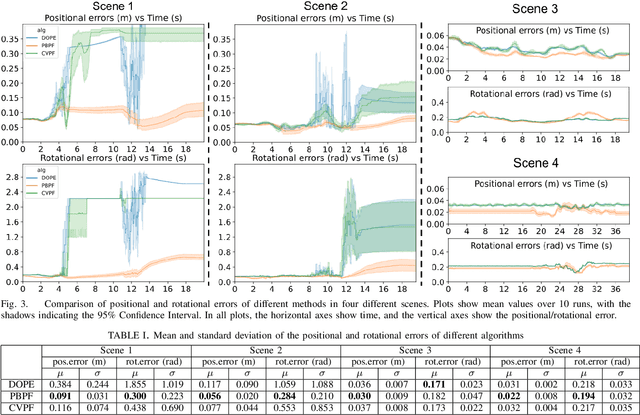
We propose a method to track the 6D pose of an object over time, while the object is under non-prehensile manipulation by a robot. At any given time during the manipulation of the object, we assume access to the robot joint controls and an image from a camera looking at the scene. We use the robot joint controls to perform a physics-based prediction of how the object might be moving. We then combine this prediction with the observation coming from the camera, to estimate the object pose as accurately as possible. We use a particle filtering approach to combine the control information with the visual information. We compare the proposed method with two baselines: (i) using only an image-based pose estimation system at each time-step, and (ii) a particle filter which does not perform the computationally expensive physics predictions, but assumes the object moves with constant velocity. Our results show that making physics-based predictions is worth the computational cost, resulting in more accurate tracking, and estimating object pose even when the object is not clearly visible to the camera.
Object Detection in Foggy Scenes by Embedding Depth and Reconstruction into Domain Adaptation
Nov 24, 2022
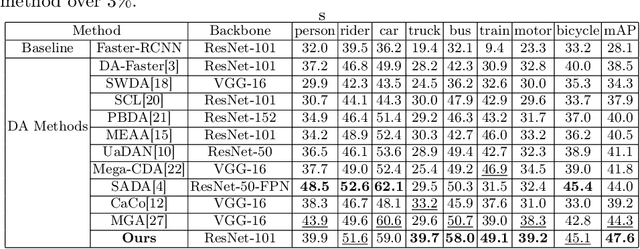
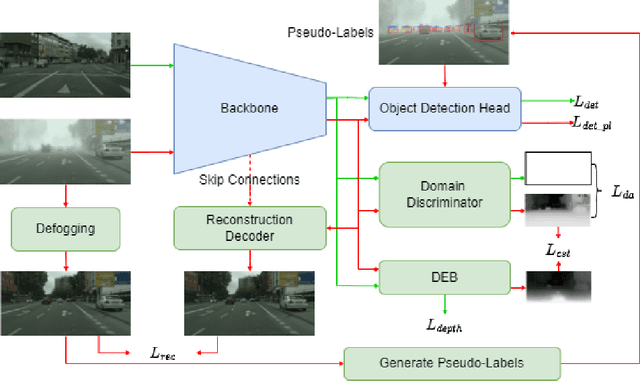
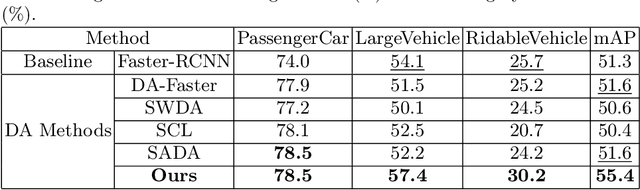
Most existing domain adaptation (DA) methods align the features based on the domain feature distributions and ignore aspects related to fog, background and target objects, rendering suboptimal performance. In our DA framework, we retain the depth and background information during the domain feature alignment. A consistency loss between the generated depth and fog transmission map is introduced to strengthen the retention of the depth information in the aligned features. To address false object features potentially generated during the DA process, we propose an encoder-decoder framework to reconstruct the fog-free background image. This reconstruction loss also reinforces the encoder, i.e., our DA backbone, to minimize false object features.Moreover, we involve our target data in training both our DA module and our detection module in a semi-supervised manner, so that our detection module is also exposed to the unlabeled target data, the type of data used in the testing stage. Using these ideas, our method significantly outperforms the state-of-the-art method (47.6 mAP against the 44.3 mAP on the Foggy Cityscapes dataset), and obtains the best performance on multiple real-image public datasets. Code is available at: https://github.com/VIML-CVDL/Object-Detection-in-Foggy-Scenes
Contextual Learning in Fourier Complex Field for VHR Remote Sensing Images
Oct 28, 2022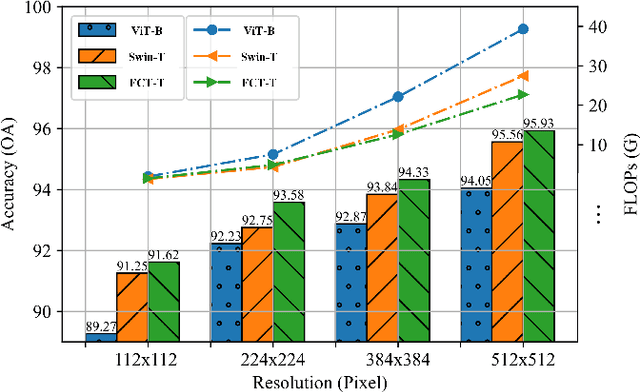
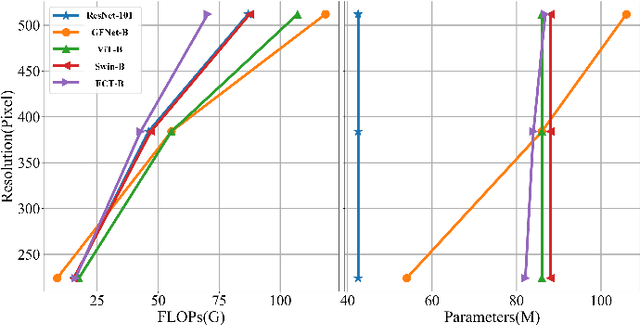
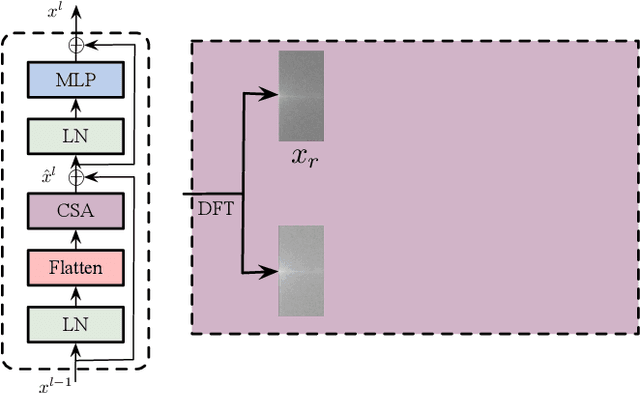
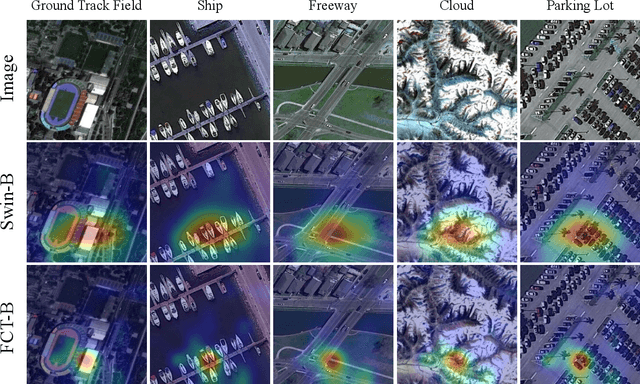
Very high-resolution (VHR) remote sensing (RS) image classification is the fundamental task for RS image analysis and understanding. Recently, transformer-based models demonstrated outstanding potential for learning high-order contextual relationships from natural images with general resolution (224x224 pixels) and achieved remarkable results on general image classification tasks. However, the complexity of the naive transformer grows quadratically with the increase in image size, which prevents transformer-based models from VHR RS image (500x500 pixels) classification and other computationally expensive downstream tasks. To this end, we propose to decompose the expensive self-attention (SA) into real and imaginary parts via discrete Fourier transform (DFT) and therefore propose an efficient complex self-attention (CSA) mechanism. Benefiting from the conjugated symmetric property of DFT, CSA is capable to model the high-order contextual information with less than half computations of naive SA. To overcome the gradient explosion in Fourier complex field, we replace the Softmax function with the carefully designed Logmax function to normalize the attention map of CSA and stabilize the gradient propagation. By stacking various layers of CSA blocks, we propose the Fourier Complex Transformer (FCT) model to learn global contextual information from VHR aerial images following the hierarchical manners. Universal experiments conducted on commonly used RS classification data sets demonstrate the effectiveness and efficiency of FCT, especially on very high-resolution RS images.
MISSU: 3D Medical Image Segmentation via Self-distilling TransUNet
Jun 02, 2022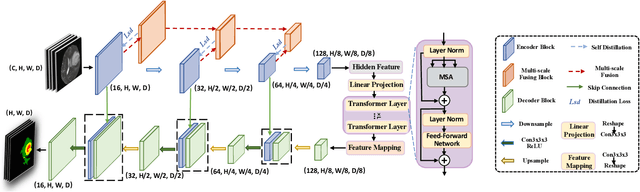
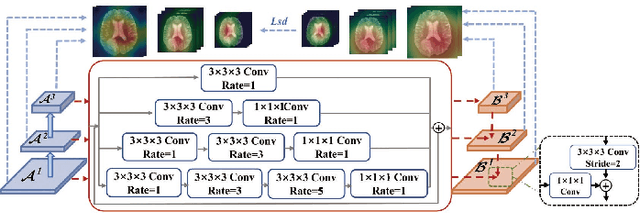
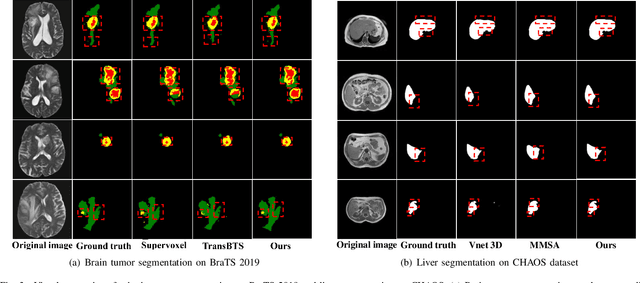
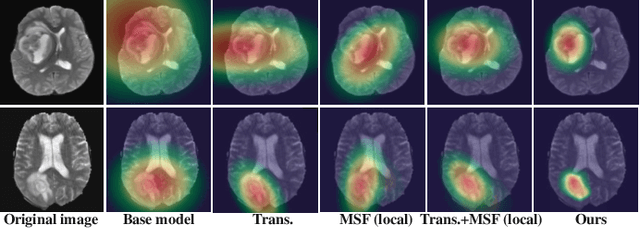
U-Nets have achieved tremendous success in medical image segmentation. Nevertheless, it may suffer limitations in global (long-range) contextual interactions and edge-detail preservation. In contrast, Transformer has an excellent ability to capture long-range dependencies by leveraging the self-attention mechanism into the encoder. Although Transformer was born to model the long-range dependency on the extracted feature maps, it still suffers from extreme computational and spatial complexities in processing high-resolution 3D feature maps. This motivates us to design the efficiently Transformer-based UNet model and study the feasibility of Transformer-based network architectures for medical image segmentation tasks. To this end, we propose to self-distill a Transformer-based UNet for medical image segmentation, which simultaneously learns global semantic information and local spatial-detailed features. Meanwhile, a local multi-scale fusion block is first proposed to refine fine-grained details from the skipped connections in the encoder by the main CNN stem through self-distillation, only computed during training and removed at inference with minimal overhead. Extensive experiments on BraTS 2019 and CHAOS datasets show that our MISSU achieves the best performance over previous state-of-the-art methods. Code and models are available at \url{https://github.com/wangn123/MISSU.git}