 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Planning Immediate Landmarks of Targets for Model-Free Skill Transfer across Agents
Dec 18, 2022
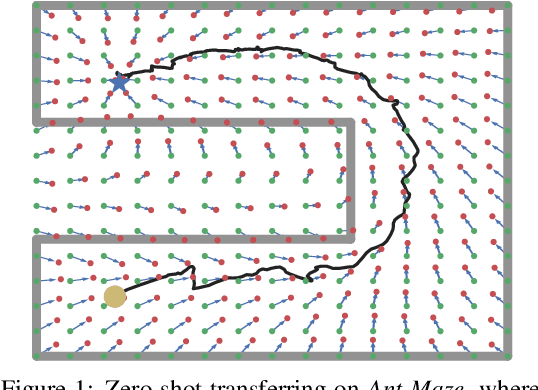
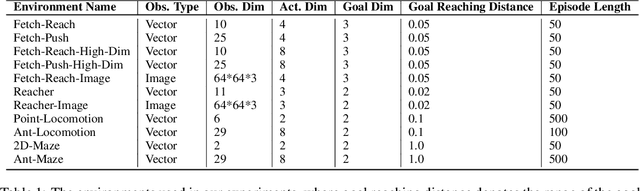
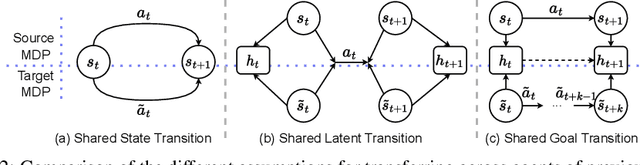
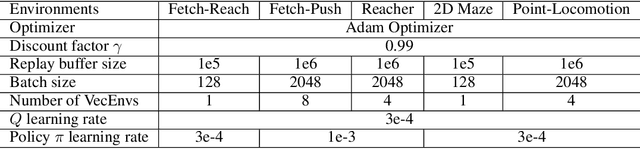
In reinforcement learning applications like robotics, agents usually need to deal with various input/output features when specified with different state/action spaces by their developers or physical restrictions. This indicates unnecessary re-training from scratch and considerable sample inefficiency, especially when agents follow similar solution steps to achieve tasks. In this paper, we aim to transfer similar high-level goal-transition knowledge to alleviate the challenge. Specifically, we propose PILoT, i.e., Planning Immediate Landmarks of Targets. PILoT utilizes the universal decoupled policy optimization to learn a goal-conditioned state planner; then, distills a goal-planner to plan immediate landmarks in a model-free style that can be shared among different agents. In our experiments, we show the power of PILoT on various transferring challenges, including few-shot transferring across action spaces and dynamics, from low-dimensional vector states to image inputs, from simple robot to complicated morphology; and we also illustrate a zero-shot transfer solution from a simple 2D navigation task to the harder Ant-Maze task.
Deep Active Ensemble Sampling For Image Classification
Oct 11, 2022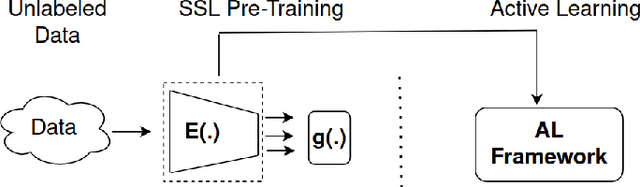
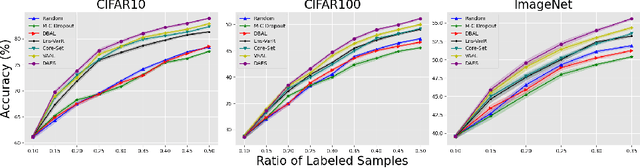
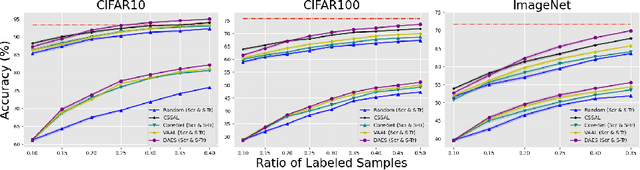
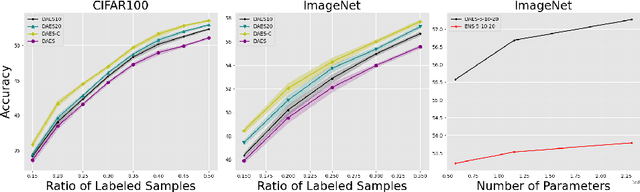
Conventional active learning (AL) frameworks aim to reduce the cost of data annotation by actively requesting the labeling for the most informative data points. However, introducing AL to data hungry deep learning algorithms has been a challenge. Some proposed approaches include uncertainty-based techniques, geometric methods, implicit combination of uncertainty-based and geometric approaches, and more recently, frameworks based on semi/self supervised techniques. In this paper, we address two specific problems in this area. The first is the need for efficient exploitation/exploration trade-off in sample selection in AL. For this, we present an innovative integration of recent progress in both uncertainty-based and geometric frameworks to enable an efficient exploration/exploitation trade-off in sample selection strategy. To this end, we build on a computationally efficient approximate of Thompson sampling with key changes as a posterior estimator for uncertainty representation. Our framework provides two advantages: (1) accurate posterior estimation, and (2) tune-able trade-off between computational overhead and higher accuracy. The second problem is the need for improved training protocols in deep AL. For this, we use ideas from semi/self supervised learning to propose a general approach that is independent of the specific AL technique being used. Taken these together, our framework shows a significant improvement over the state-of-the-art, with results that are comparable to the performance of supervised-learning under the same setting. We show empirical results of our framework, and comparative performance with the state-of-the-art on four datasets, namely, MNIST, CIFAR10, CIFAR100 and ImageNet to establish a new baseline in two different settings.
Domain Enhanced Arbitrary Image Style Transfer via Contrastive Learning
May 19, 2022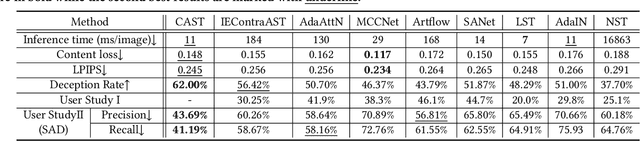

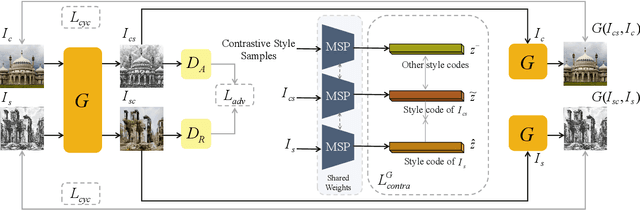
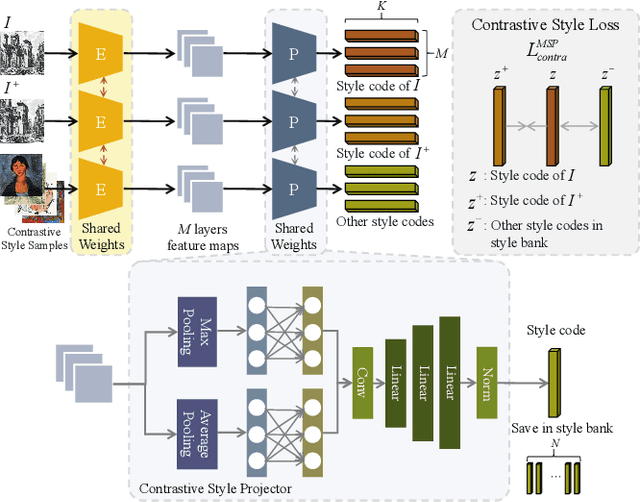
In this work, we tackle the challenging problem of arbitrary image style transfer using a novel style feature representation learning method. A suitable style representation, as a key component in image stylization tasks, is essential to achieve satisfactory results. Existing deep neural network based approaches achieve reasonable results with the guidance from second-order statistics such as Gram matrix of content features. However, they do not leverage sufficient style information, which results in artifacts such as local distortions and style inconsistency. To address these issues, we propose to learn style representation directly from image features instead of their second-order statistics, by analyzing the similarities and differences between multiple styles and considering the style distribution. Specifically, we present Contrastive Arbitrary Style Transfer (CAST), which is a new style representation learning and style transfer method via contrastive learning. Our framework consists of three key components, i.e., a multi-layer style projector for style code encoding, a domain enhancement module for effective learning of style distribution, and a generative network for image style transfer. We conduct qualitative and quantitative evaluations comprehensively to demonstrate that our approach achieves significantly better results compared to those obtained via state-of-the-art methods. Code and models are available at https://github.com/zyxElsa/CAST_pytorch
Transformer-based Hand Gesture Recognition via High-Density EMG Signals: From Instantaneous Recognition to Fusion of Motor Unit Spike Trains
Dec 07, 2022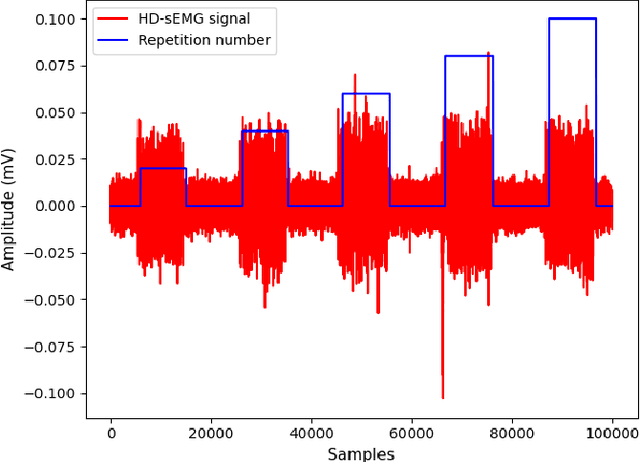
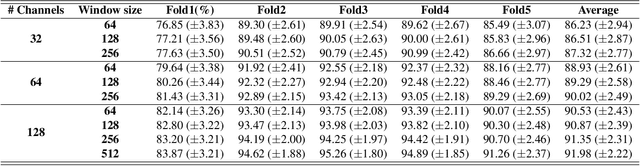

Designing efficient and labor-saving prosthetic hands requires powerful hand gesture recognition algorithms that can achieve high accuracy with limited complexity and latency. In this context, the paper proposes a compact deep learning framework referred to as the CT-HGR, which employs a vision transformer network to conduct hand gesture recognition using highdensity sEMG (HD-sEMG) signals. The attention mechanism in the proposed model identifies similarities among different data segments with a greater capacity for parallel computations and addresses the memory limitation problems while dealing with inputs of large sequence lengths. CT-HGR can be trained from scratch without any need for transfer learning and can simultaneously extract both temporal and spatial features of HD-sEMG data. Additionally, the CT-HGR framework can perform instantaneous recognition using sEMG image spatially composed from HD-sEMG signals. A variant of the CT-HGR is also designed to incorporate microscopic neural drive information in the form of Motor Unit Spike Trains (MUSTs) extracted from HD-sEMG signals using Blind Source Separation (BSS). This variant is combined with its baseline version via a hybrid architecture to evaluate potentials of fusing macroscopic and microscopic neural drive information. The utilized HD-sEMG dataset involves 128 electrodes that collect the signals related to 65 isometric hand gestures of 20 subjects. The proposed CT-HGR framework is applied to 31.25, 62.5, 125, 250 ms window sizes of the above-mentioned dataset utilizing 32, 64, 128 electrode channels. The average accuracy over all the participants using 32 electrodes and a window size of 31.25 ms is 86.23%, which gradually increases till reaching 91.98% for 128 electrodes and a window size of 250 ms. The CT-HGR achieves accuracy of 89.13% for instantaneous recognition based on a single frame of HD-sEMG image.
Compound Multi-branch Feature Fusion for Real Image Restoration
Jun 02, 2022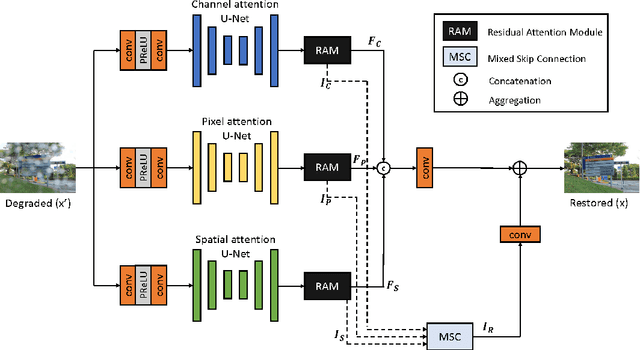
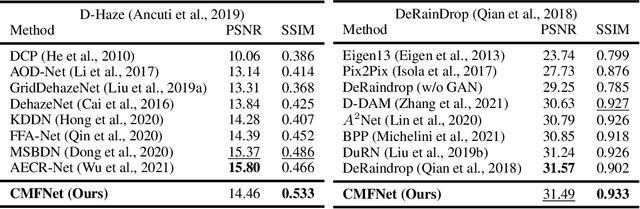
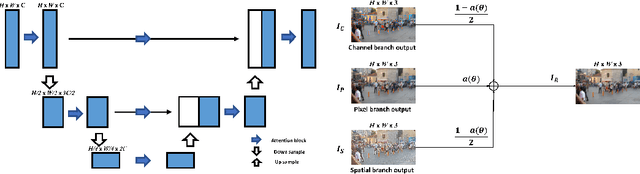
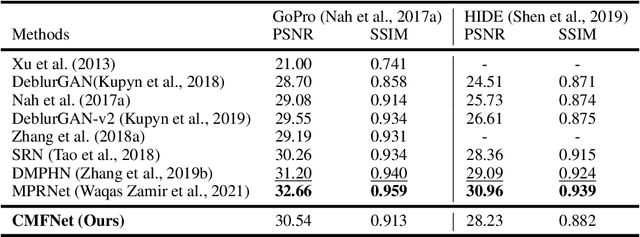
Image restoration is a challenging and ill-posed problem which also has been a long-standing issue. However, most of learning based restoration methods are proposed to target one degradation type which means they are lack of generalization. In this paper, we proposed a multi-branch restoration model inspired from the Human Visual System (i.e., Retinal Ganglion Cells) which can achieve multiple restoration tasks in a general framework. The experiments show that the proposed multi-branch architecture, called CMFNet, has competitive performance results on four datasets, including image dehazing, deraindrop, and deblurring, which are very common applications for autonomous cars. The source code and pretrained models of three restoration tasks are available at https://github.com/FanChiMao/CMFNet.
An adaptive bi-objective optimization algorithm for the satellite image data downlink scheduling problem considering request split
Jun 28, 2022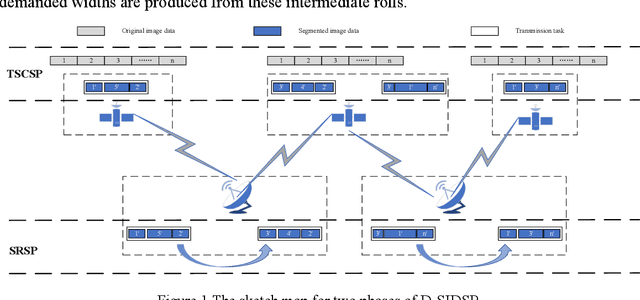
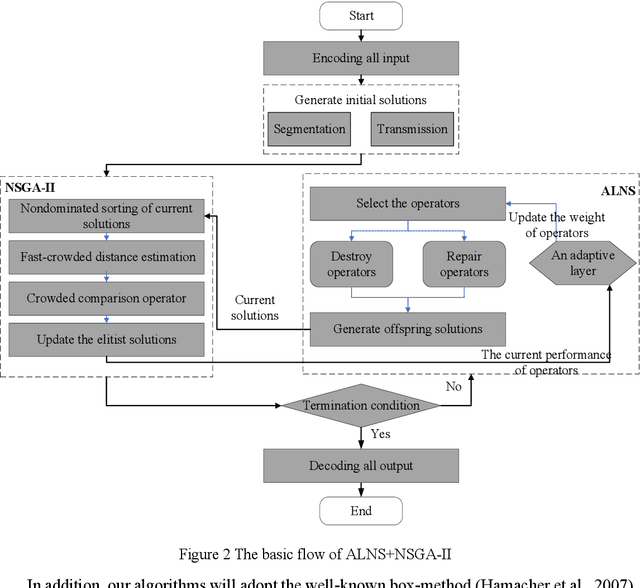
The satellite image data downlink scheduling problem (SIDSP) is well studied in literature for traditional satellites. With recent developments in satellite technology, SIDSP for modern satellites became more complicated, adding new dimensions of complexities and additional opportunities for the effective use of the satellite. In this paper, we introduce the dynamic two-phase satellite image data downlink scheduling problem (D-SIDSP) which combines two interlinked operations of image data segmentation and image data downlink, in a dynamic way, and thereby offering additional modelling flexibility and renewed capabilities. D-SIDSP is formulated as a bi-objective problem of optimizing the image data transmission rate and the service-balance degree. Harnessing the power of an adaptive large neighborhood search algorithm (ALNS) with a nondominated sorting genetic algorithm II (NSGA-II), an adaptive bi-objective memetic algorithm, ALNS+NSGA-II, is developed to solve D-SIDSP. Results of extensive computational experiments carried out using benchmark instances are also presented. Our experimental results disclose that the algorithm ALNS+NSGA-II is a viable alternative to solve D-SIDSP more efficiently and demonstrates superior outcomes based on various performance metrics. The paper also offers new benchmark instances for D-SIDSP that can be used in future research works on the topic.
UIF: An Objective Quality Assessment for Underwater Image Enhancement
May 19, 2022


Due to complex and volatile lighting environment, underwater imaging can be readily impaired by light scattering, warping, and noises. To improve the visual quality, Underwater Image Enhancement (UIE) techniques have been widely studied. Recent efforts have also been contributed to evaluate and compare the UIE performances with subjective and objective methods. However, the subjective evaluation is time-consuming and uneconomic for all images, while existing objective methods have limited capabilities for the newly-developed UIE approaches based on deep learning. To fill this gap, we propose an Underwater Image Fidelity (UIF) metric for objective evaluation of enhanced underwater images. By exploiting the statistical features of these images, we present to extract naturalness-related, sharpness-related, and structure-related features. Among them, the naturalness-related and sharpness-related features evaluate visual improvement of enhanced images; the structure-related feature indicates structural similarity between images before and after UIE. Then, we employ support vector regression to fuse the above three features into a final UIF metric. In addition, we have also established a large-scale UIE database with subjective scores, namely Underwater Image Enhancement Database (UIED), which is utilized as a benchmark to compare all objective metrics. Experimental results confirm that the proposed UIF outperforms a variety of underwater and general-purpose image quality metrics.
MatrixVT: Efficient Multi-Camera to BEV Transformation for 3D Perception
Nov 19, 2022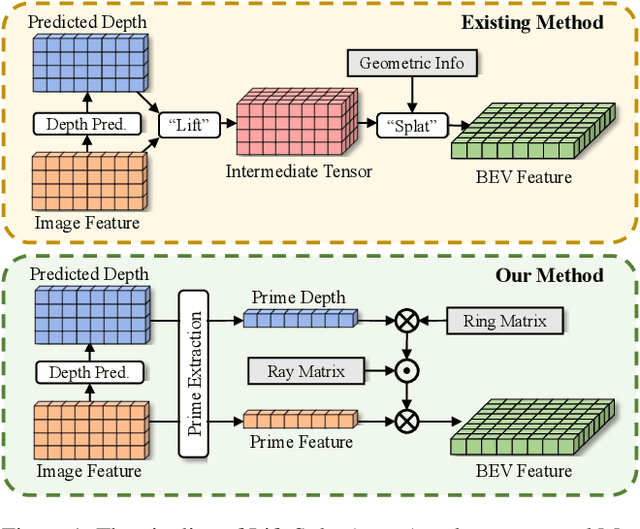
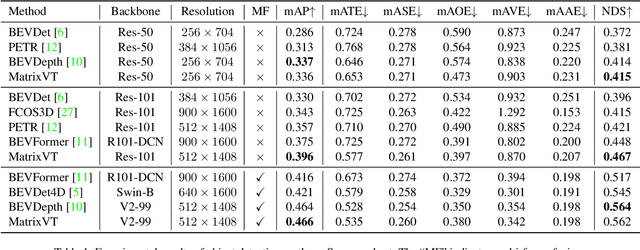
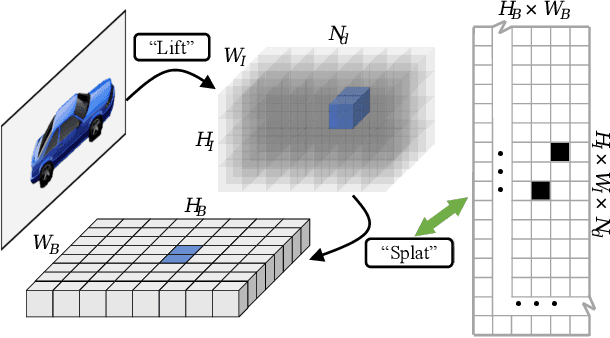
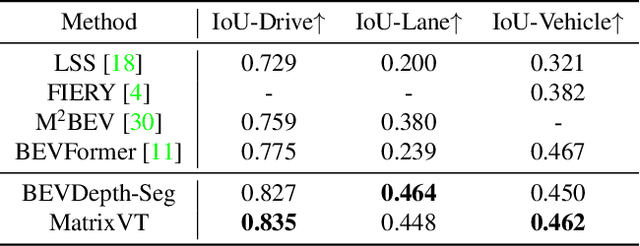
This paper proposes an efficient multi-camera to Bird's-Eye-View (BEV) view transformation method for 3D perception, dubbed MatrixVT. Existing view transformers either suffer from poor transformation efficiency or rely on device-specific operators, hindering the broad application of BEV models. In contrast, our method generates BEV features efficiently with only convolutions and matrix multiplications (MatMul). Specifically, we propose describing the BEV feature as the MatMul of image feature and a sparse Feature Transporting Matrix (FTM). A Prime Extraction module is then introduced to compress the dimension of image features and reduce FTM's sparsity. Moreover, we propose the Ring \& Ray Decomposition to replace the FTM with two matrices and reformulate our pipeline to reduce calculation further. Compared to existing methods, MatrixVT enjoys a faster speed and less memory footprint while remaining deploy-friendly. Extensive experiments on the nuScenes benchmark demonstrate that our method is highly efficient but obtains results on par with the SOTA method in object detection and map segmentation tasks
TORE: Token Reduction for Efficient Human Mesh Recovery with Transformer
Nov 19, 2022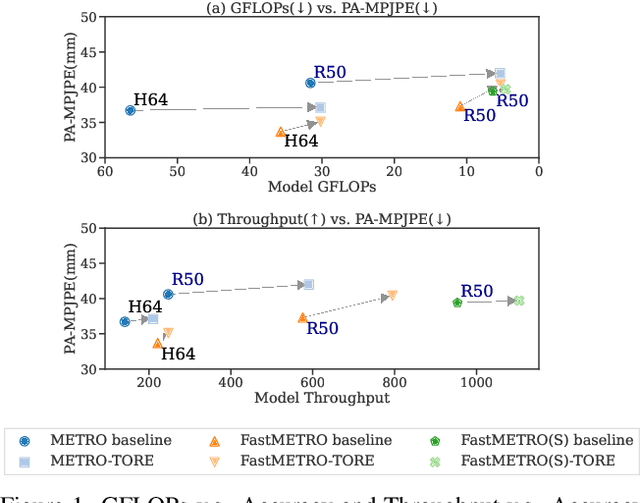
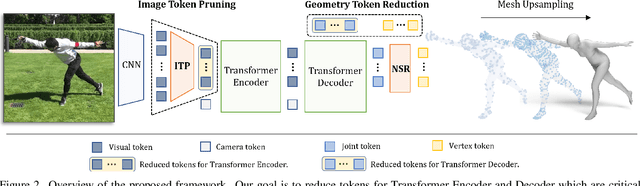
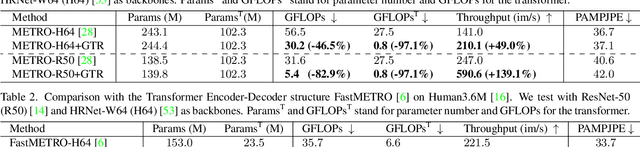
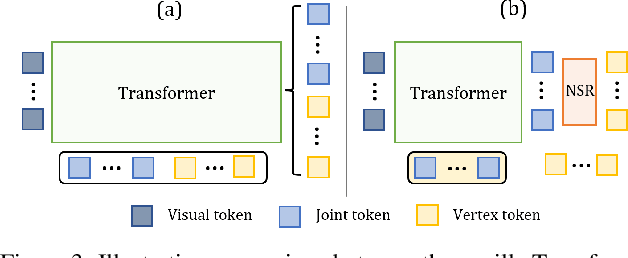
In this paper, we introduce a set of effective TOken REduction (TORE) strategies for Transformer-based Human Mesh Recovery from monocular images. Current SOTA performance is achieved by Transformer-based structures. However, they suffer from high model complexity and computation cost caused by redundant tokens. We propose token reduction strategies based on two important aspects, i.e., the 3D geometry structure and 2D image feature, where we hierarchically recover the mesh geometry with priors from body structure and conduct token clustering to pass fewer but more discriminative image feature tokens to the Transformer. As a result, our method vastly reduces the number of tokens involved in high-complexity interactions in the Transformer, achieving competitive accuracy of shape recovery at a significantly reduced computational cost. We conduct extensive experiments across a wide range of benchmarks to validate the proposed method and further demonstrate the generalizability of our method on hand mesh recovery. Our code will be publicly available once the paper is published.
Learning Topological Interactions for Multi-Class Medical Image Segmentation
Jul 20, 2022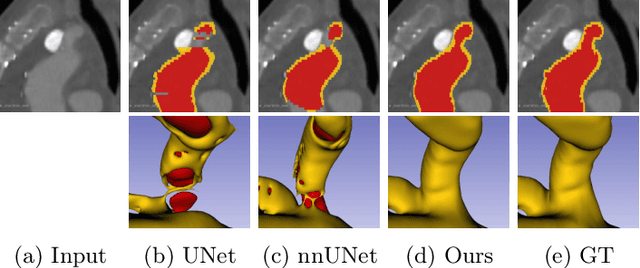
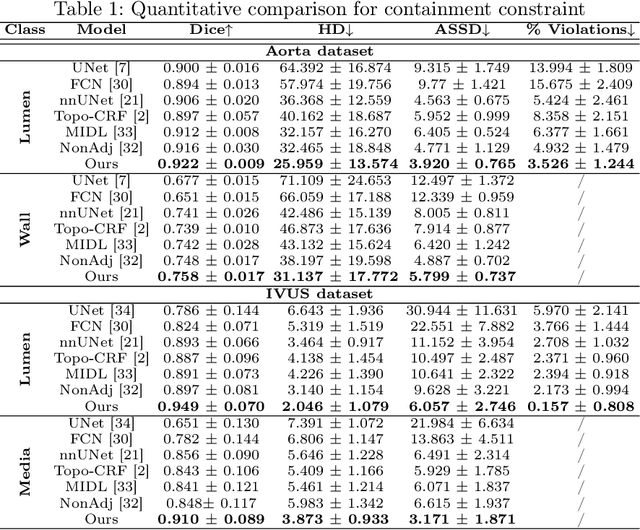
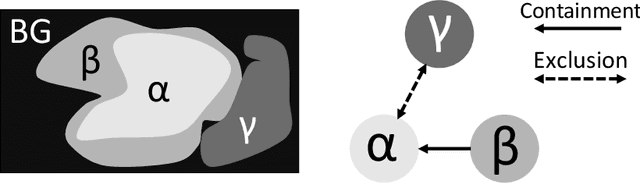
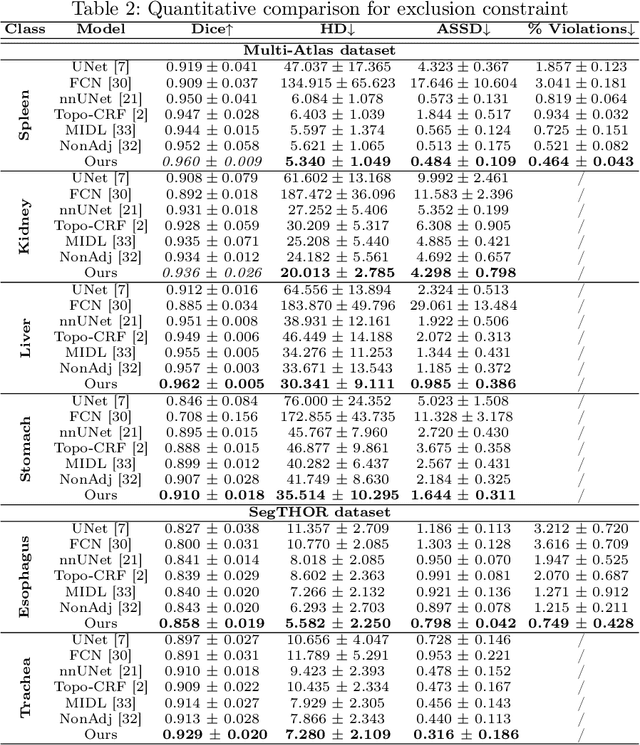
Deep learning methods have achieved impressive performance for multi-class medical image segmentation. However, they are limited in their ability to encode topological interactions among different classes (e.g., containment and exclusion). These constraints naturally arise in biomedical images and can be crucial in improving segmentation quality. In this paper, we introduce a novel topological interaction module to encode the topological interactions into a deep neural network. The implementation is completely convolution-based and thus can be very efficient. This empowers us to incorporate the constraints into end-to-end training and enrich the feature representation of neural networks. The efficacy of the proposed method is validated on different types of interactions. We also demonstrate the generalizability of the method on both proprietary and public challenge datasets, in both 2D and 3D settings, as well as across different modalities such as CT and Ultrasound. Code is available at: https://github.com/TopoXLab/TopoInteraction