 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Out-of-Distribution Detection with Reconstruction Error and Typicality-based Penalty
Dec 24, 2022
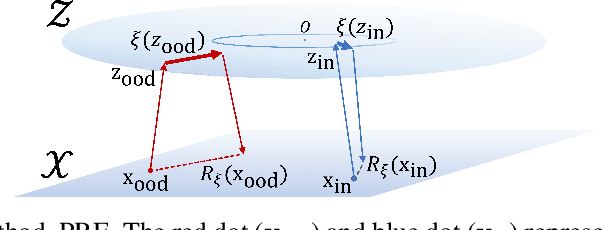
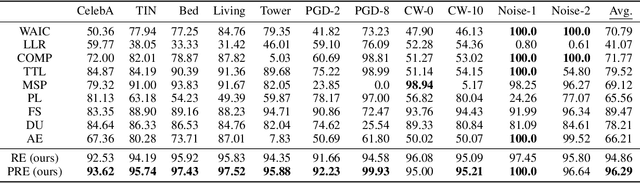
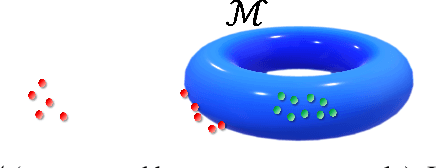
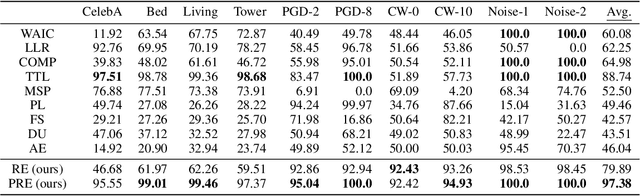
The task of out-of-distribution (OOD) detection is vital to realize safe and reliable operation for real-world applications. After the failure of likelihood-based detection in high dimensions had been shown, approaches based on the \emph{typical set} have been attracting attention; however, they still have not achieved satisfactory performance. Beginning by presenting the failure case of the typicality-based approach, we propose a new reconstruction error-based approach that employs normalizing flow (NF). We further introduce a typicality-based penalty, and by incorporating it into the reconstruction error in NF, we propose a new OOD detection method, penalized reconstruction error (PRE). Because the PRE detects test inputs that lie off the in-distribution manifold, it effectively detects adversarial examples as well as OOD examples. We show the effectiveness of our method through the evaluation using natural image datasets, CIFAR-10, TinyImageNet, and ILSVRC2012.
Cross-Modal Contrastive Representation Learning for Audio-to-Image Generation
Jul 20, 2022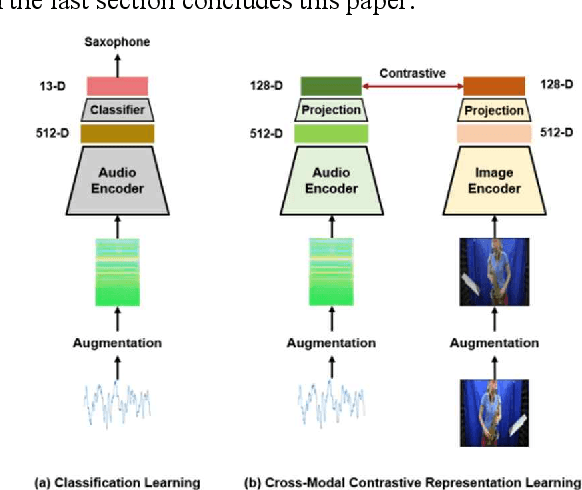

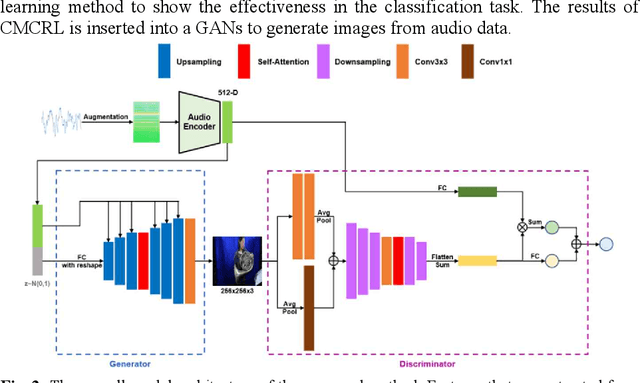

Multiple modalities for certain information provide a variety of perspectives on that information, which can improve the understanding of the information. Thus, it may be crucial to generate data of different modality from the existing data to enhance the understanding. In this paper, we investigate the cross-modal audio-to-image generation problem and propose Cross-Modal Contrastive Representation Learning (CMCRL) to extract useful features from audios and use it in the generation phase. Experimental results show that CMCRL enhances quality of images generated than previous research.
Autoregressive Model for Multi-Pass SAR Change Detection Based on Image Stacks
Jun 05, 2022Change detection is an important synthetic aperture radar (SAR) application, usually used to detect changes on the ground scene measurements in different moments in time. Traditionally, change detection algorithm (CDA) is mainly designed for two synthetic aperture radar (SAR) images retrieved at different instants. However, more images can be used to improve the algorithms performance, witch emerges as a research topic on SAR change detection. Image stack information can be treated as a data series over time and can be modeled by autoregressive (AR) models. Thus, we present some initial findings on SAR change detection based on image stack considering AR models. Applying AR model for each pixel position in the image stack, we obtained an estimated image of the ground scene which can be used as a reference image for CDA. The experimental results reveal that ground scene estimates by the AR models is accurate and can be used for change detection applications.
* 9 pages, 10 figures
FeatureBooster: Boosting Feature Descriptors with a Lightweight Neural Network
Nov 28, 2022
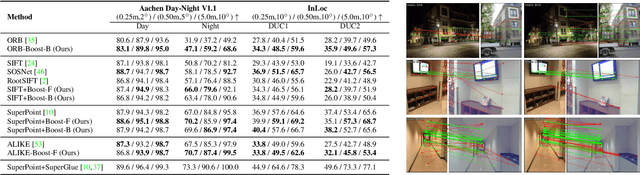
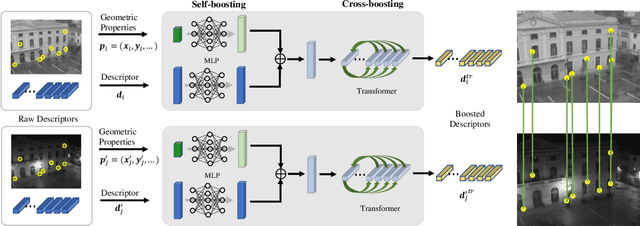
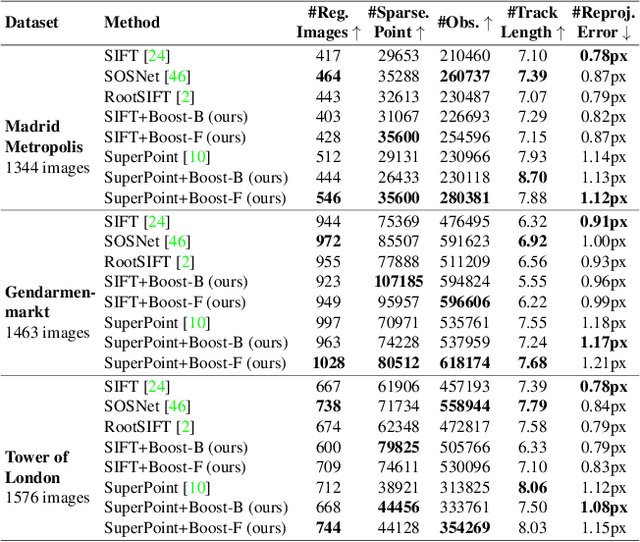
We introduce a lightweight network to improve descriptors of keypoints within the same image. The network takes the original descriptors and the geometric properties of keypoints as the input, and uses an MLP-based self-boosting stage and a Transformer-based cross-boosting stage to enhance the descriptors. The enhanced descriptors can be either real-valued or binary ones. We use the proposed network to boost both hand-crafted (ORB, SIFT) and the state-of-the-art learning-based descriptors (SuperPoint, ALIKE) and evaluate them on image matching, visual localization, and structure-from-motion tasks. The results show that our method significantly improves the performance of each task, particularly in challenging cases such as large illumination changes or repetitive patterns. Our method requires only 3.2ms on desktop GPU and 27ms on embedded GPU to process 2000 features, which is fast enough to be applied to a practical system.
Test-time Adaptation with Calibration of Medical Image Classification Nets for Label Distribution Shift
Jul 02, 2022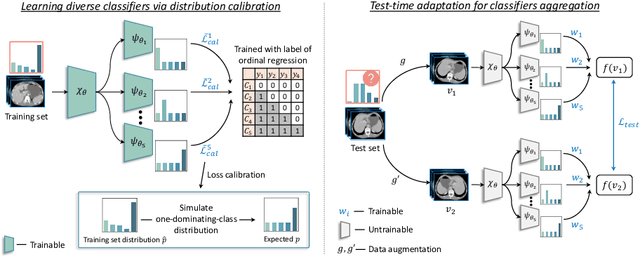
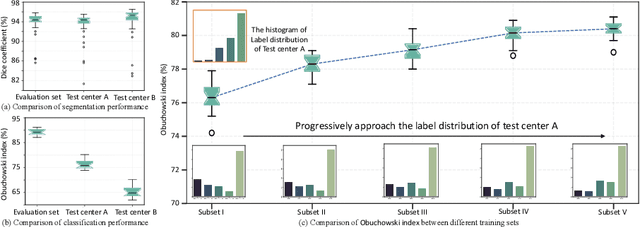
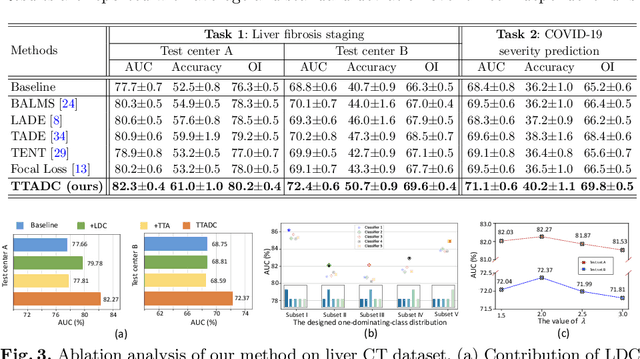
Class distribution plays an important role in learning deep classifiers. When the proportion of each class in the test set differs from the training set, the performance of classification nets usually degrades. Such a label distribution shift problem is common in medical diagnosis since the prevalence of disease vary over location and time. In this paper, we propose the first method to tackle label shift for medical image classification, which effectively adapt the model learned from a single training label distribution to arbitrary unknown test label distribution. Our approach innovates distribution calibration to learn multiple representative classifiers, which are capable of handling different one-dominating-class distributions. When given a test image, the diverse classifiers are dynamically aggregated via the consistency-driven test-time adaptation, to deal with the unknown test label distribution. We validate our method on two important medical image classification tasks including liver fibrosis staging and COVID-19 severity prediction. Our experiments clearly show the decreased model performance under label shift. With our method, model performance significantly improves on all the test datasets with different label shifts for both medical image diagnosis tasks.
Learning a Degradation-Adaptive Network for Light Field Image Super-Resolution
Jun 13, 2022



Recent years have witnessed the great advances of deep neural networks (DNNs) in light field (LF) image super-resolution (SR). However, existing DNN-based LF image SR methods are developed on a single fixed degradation (e.g., bicubic downsampling), and thus cannot be applied to super-resolve real LF images with diverse degradations. In this paper, we propose the first method to handle LF image SR with multiple degradations. In our method, a practical LF degradation model that considers blur and noise is developed to approximate the degradation process of real LF images. Then, a degradation-adaptive network (LF-DAnet) is designed to incorporate the degradation prior into the SR process. By training on LF images with multiple synthetic degradations, our method can learn to adapt to different degradations while incorporating the spatial and angular information. Extensive experiments on both synthetically degraded and real-world LFs demonstrate the effectiveness of our method. Compared with existing state-of-the-art single and LF image SR methods, our method achieves superior SR performance under a wide range of degradations, and generalizes better to real LF images. Codes and models are available at https://github.com/YingqianWang/LF-DAnet.
Deep learning pipeline for image classification on mobile phones
May 31, 2022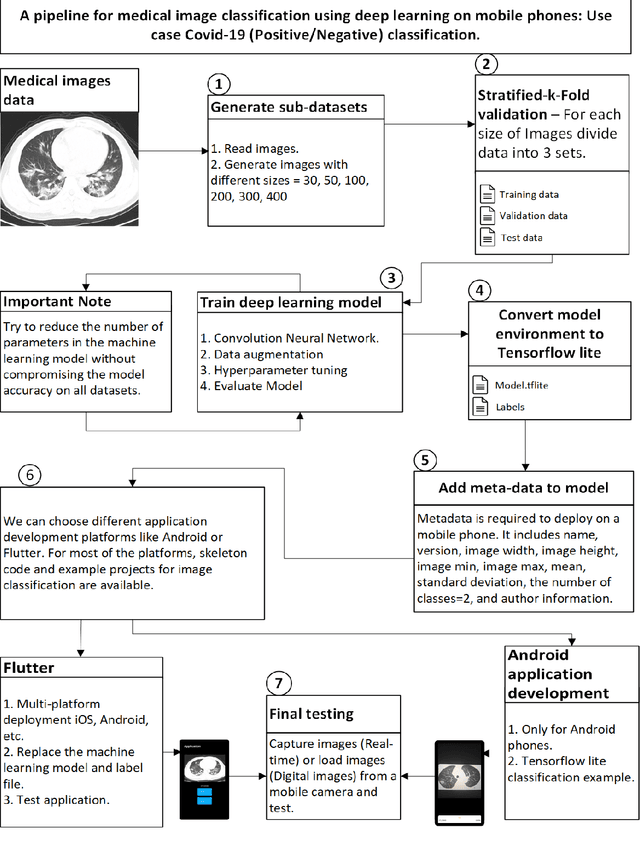
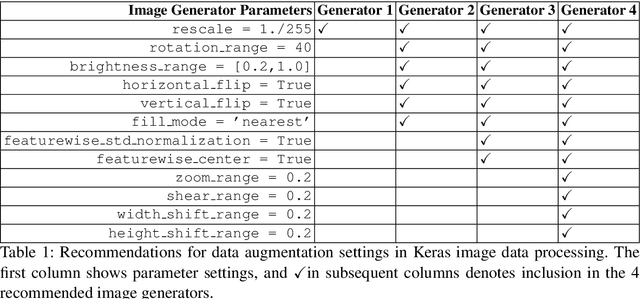
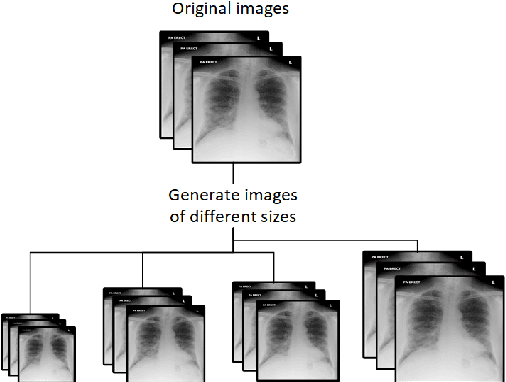
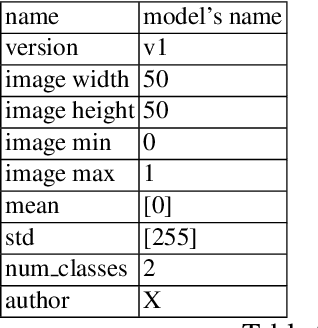
This article proposes and documents a machine-learning framework and tutorial for classifying images using mobile phones. Compared to computers, the performance of deep learning model performance degrades when deployed on a mobile phone and requires a systematic approach to find a model that performs optimally on both computers and mobile phones. By following the proposed pipeline, which consists of various computational tools, simple procedural recipes, and technical considerations, one can bring the power of deep learning medical image classification to mobile devices, potentially unlocking new domains of applications. The pipeline is demonstrated on four different publicly available datasets: COVID X-rays, COVID CT scans, leaves, and colorectal cancer. We used two application development frameworks: TensorFlow Lite (real-time testing) and Flutter (digital image testing) to test the proposed pipeline. We found that transferring deep learning models to a mobile phone is limited by hardware and classification accuracy drops. To address this issue, we proposed this pipeline to find an optimized model for mobile phones. Finally, we discuss additional applications and computational concerns related to deploying deep-learning models on phones, including real-time analysis and image preprocessing. We believe the associated documentation and code can help physicians and medical experts develop medical image classification applications for distribution.
* 20 pages
Detecting Recolored Image by Spatial Correlation
Apr 23, 2022
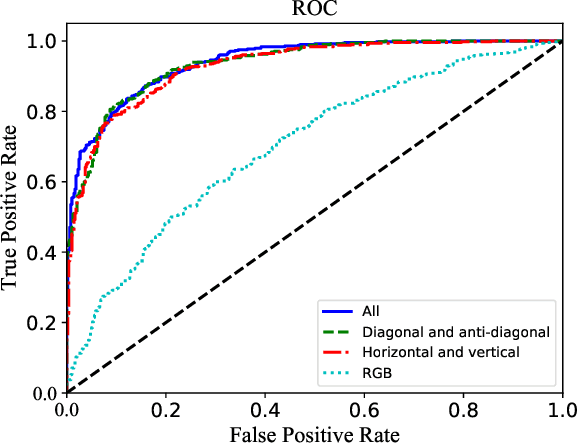
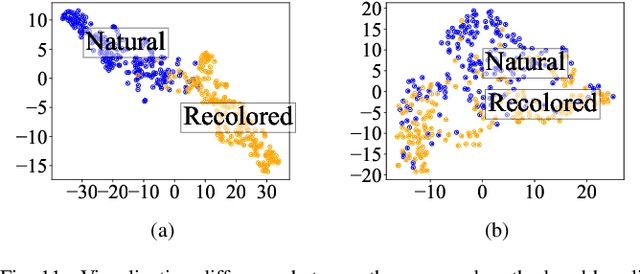
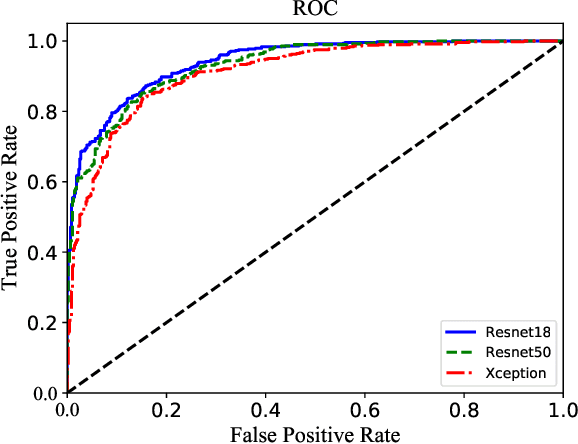
Image forensics, aiming to ensure the authenticity of the image, has made great progress in dealing with common image manipulation such as copy-move, splicing, and inpainting in the past decades. However, only a few researchers pay attention to an emerging editing technique called image recoloring, which can manipulate the color values of an image to give it a new style. To prevent it from being used maliciously, the previous approaches address the conventional recoloring from the perspective of inter-channel correlation and illumination consistency. In this paper, we try to explore a solution from the perspective of the spatial correlation, which exhibits the generic detection capability for both conventional and deep learning-based recoloring. Through theoretical and numerical analysis, we find that the recoloring operation will inevitably destroy the spatial correlation between pixels, implying a new prior of statistical discriminability. Based on such fact, we generate a set of spatial correlation features and learn the informative representation from the set via a convolutional neural network. To train our network, we use three recoloring methods to generate a large-scale and high-quality data set. Extensive experimental results in two recoloring scenes demonstrate that the spatial correlation features are highly discriminative. Our method achieves the state-of-the-art detection accuracy on multiple benchmark datasets and exhibits well generalization for unknown types of recoloring methods.
Multiscale Voxel Based Decoding For Enhanced Natural Image Reconstruction From Brain Activity
May 27, 2022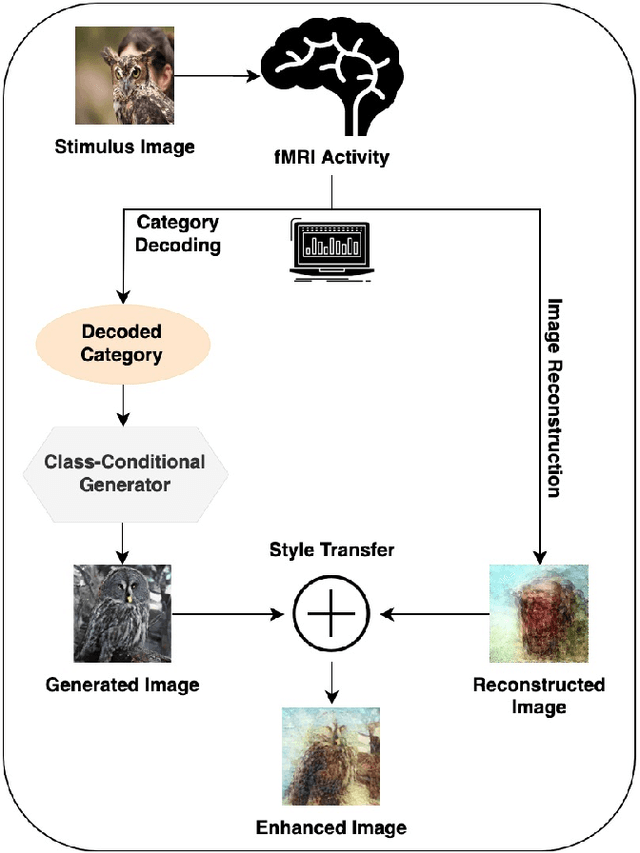



Reconstructing perceived images from human brain activity monitored by functional magnetic resonance imaging (fMRI) is hard, especially for natural images. Existing methods often result in blurry and unintelligible reconstructions with low fidelity. In this study, we present a novel approach for enhanced image reconstruction, in which existing methods for object decoding and image reconstruction are merged together. This is achieved by conditioning the reconstructed image to its decoded image category using a class-conditional generative adversarial network and neural style transfer. The results indicate that our approach improves the semantic similarity of the reconstructed images and can be used as a general framework for enhanced image reconstruction.
DAQE: Enhancing the Quality of Compressed Images by Finding the Secret of Defocus
Nov 20, 2022
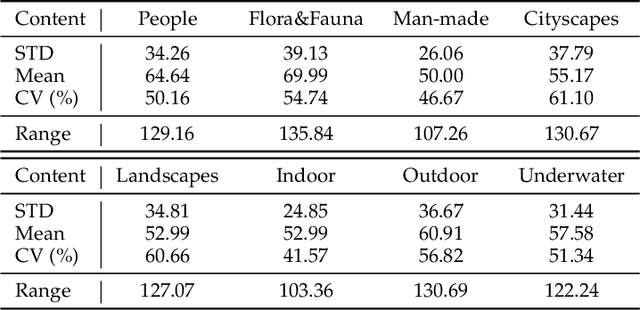

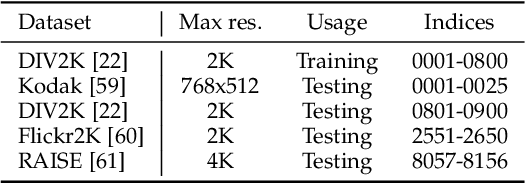
Image defocus is inherent in the physics of image formation caused by the optical aberration of lenses, providing plentiful information on image quality. Unfortunately, the existing quality enhancement approaches for compressed images neglect the inherent characteristic of defocus, resulting in inferior performance. This paper finds that in compressed images, the significantly defocused regions are with better compression quality and two regions with different defocus values possess diverse texture patterns. These findings motivate our defocus-aware quality enhancement (DAQE) approach. Specifically, we propose a novel dynamic region-based deep learning architecture of the DAQE approach, which considers the region-wise defocus difference of compressed images in two aspects. (1) The DAQE approach employs fewer computational resources to enhance the quality of significantly defocused regions, while more resources on enhancing the quality of other regions; (2) The DAQE approach learns to separately enhance diverse texture patterns for the regions with different defocus values, such that texture-wise one-on-one enhancement can be achieved. Extensive experiments validate the superiority of our DAQE approach in terms of quality enhancement and resource-saving, compared with other state-of-the-art approaches.