 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Man-recon: manifold learning for reconstruction with deep autoencoder for smart seismic interpretation
Dec 15, 2022
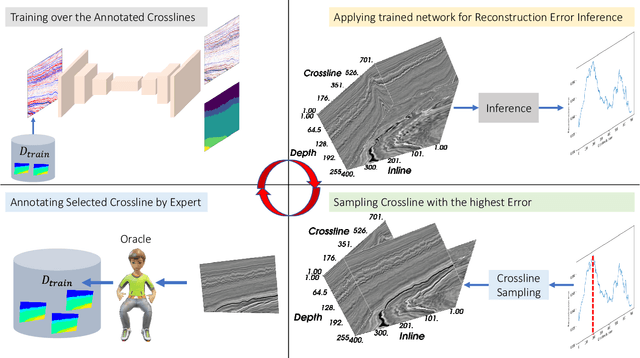
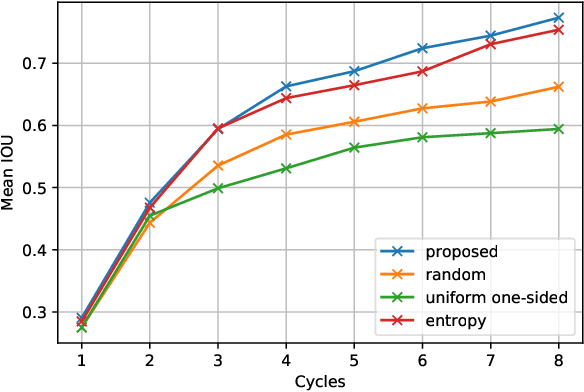
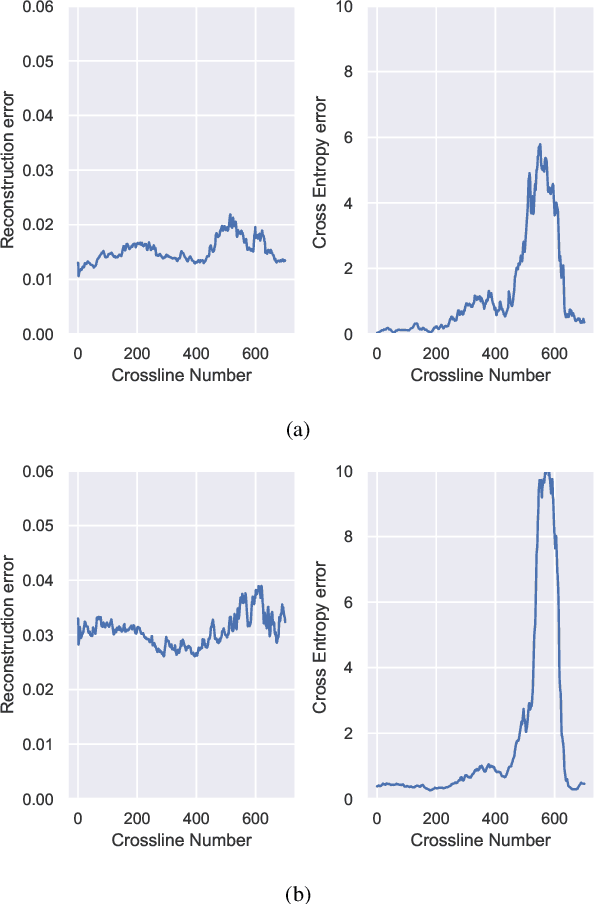
Deep learning can extract rich data representations if provided sufficient quantities of labeled training data. For many tasks however, annotating data has significant costs in terms of time and money, owing to the high standards of subject matter expertise required, for example in medical and geophysical image interpretation tasks. Active Learning can identify the most informative training examples for the interpreter to train, leading to higher efficiency. We propose an Active learning method based on jointly learning representations for supervised and unsupervised tasks. The learned manifold structure is later utilized to identify informative training samples most dissimilar from the learned manifold from the error profiles on the unsupervised task. We verify the efficiency of the proposed method on a seismic facies segmentation dataset from the Netherlands F3 block survey, significantly outperforming contemporary methods to achieve the highest mean Intersection-Over-Union value of 0.773.
Survey on Source-coding technique
Nov 03, 2022Shannon separation theorem lays the foundation for traditional image compression and transmission schemes, which consist of JPEG type image compression methods and the usual channel coding schemes such as Turbo and LDPC codes. One of the advantages of the separate design is that each of the two components, channel coding and source coding can be handled independently without considering the other, which is the base of decades-long technologies.
When CNN Meet with ViT: Towards Semi-Supervised Learning for Multi-Class Medical Image Semantic Segmentation
Aug 12, 2022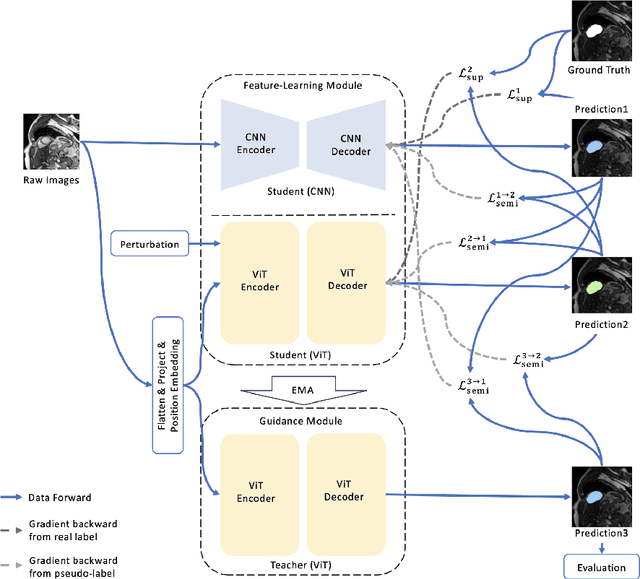
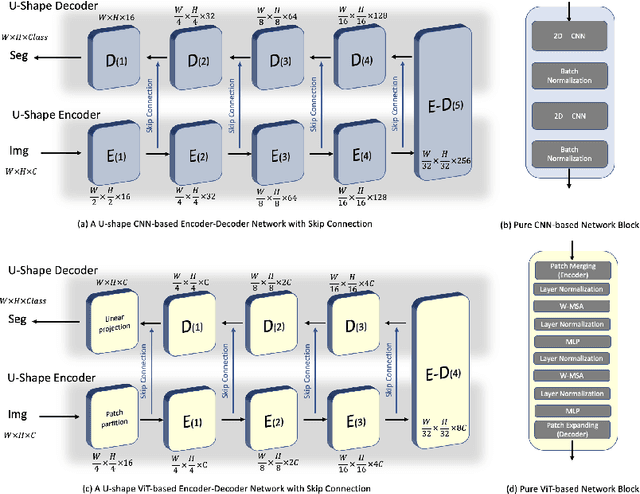
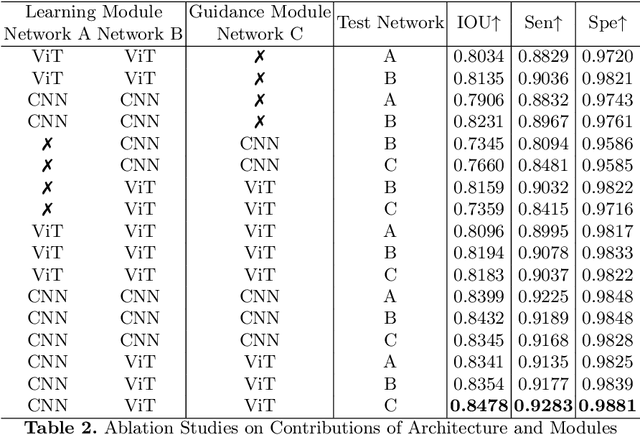
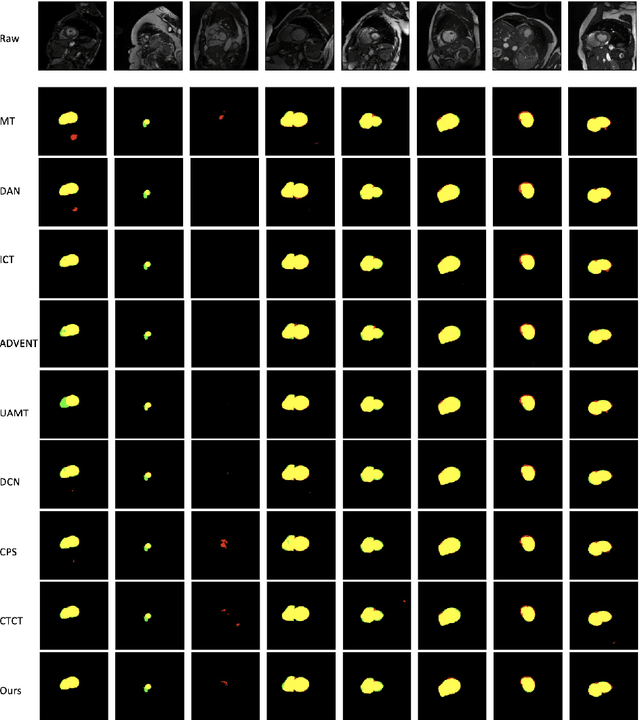
Due to the lack of quality annotation in medical imaging community, semi-supervised learning methods are highly valued in image semantic segmentation tasks. In this paper, an advanced consistency-aware pseudo-label-based self-ensembling approach is presented to fully utilize the power of Vision Transformer(ViT) and Convolutional Neural Network(CNN) in semi-supervised learning. Our proposed framework consists of a feature-learning module which is enhanced by ViT and CNN mutually, and a guidance module which is robust for consistency-aware purposes. The pseudo labels are inferred and utilized recurrently and separately by views of CNN and ViT in the feature-learning module to expand the data set and are beneficial to each other. Meanwhile, a perturbation scheme is designed for the feature-learning module, and averaging network weight is utilized to develop the guidance module. By doing so, the framework combines the feature-learning strength of CNN and ViT, strengthens the performance via dual-view co-training, and enables consistency-aware supervision in a semi-supervised manner. A topological exploration of all alternative supervision modes with CNN and ViT are detailed validated, demonstrating the most promising performance and specific setting of our method on semi-supervised medical image segmentation tasks. Experimental results show that the proposed method achieves state-of-the-art performance on a public benchmark data set with a variety of metrics. The code is publicly available.
AutoLaparo: A New Dataset of Integrated Multi-tasks for Image-guided Surgical Automation in Laparoscopic Hysterectomy
Aug 03, 2022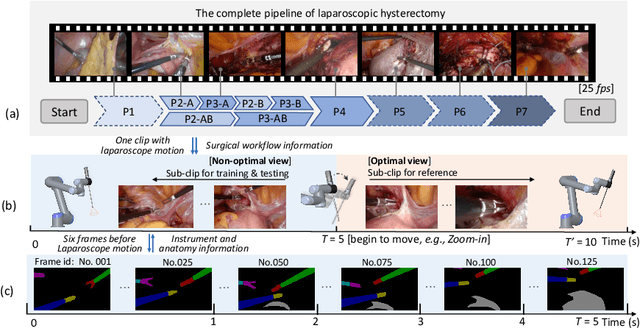

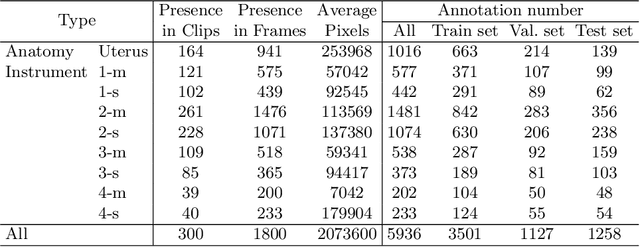

Computer-assisted minimally invasive surgery has great potential in benefiting modern operating theatres. The video data streamed from the endoscope provides rich information to support context-awareness for next-generation intelligent surgical systems. To achieve accurate perception and automatic manipulation during the procedure, learning based technique is a promising way, which enables advanced image analysis and scene understanding in recent years. However, learning such models highly relies on large-scale, high-quality, and multi-task labelled data. This is currently a bottleneck for the topic, as available public dataset is still extremely limited in the field of CAI. In this paper, we present and release the first integrated dataset (named AutoLaparo) with multiple image-based perception tasks to facilitate learning-based automation in hysterectomy surgery. Our AutoLaparo dataset is developed based on full-length videos of entire hysterectomy procedures. Specifically, three different yet highly correlated tasks are formulated in the dataset, including surgical workflow recognition, laparoscope motion prediction, and instrument and key anatomy segmentation. In addition, we provide experimental results with state-of-the-art models as reference benchmarks for further model developments and evaluations on this dataset. The dataset is available at https://autolaparo.github.io.
PointCMC: Cross-Modal Multi-Scale Correspondences Learning for Point Cloud Understanding
Nov 23, 2022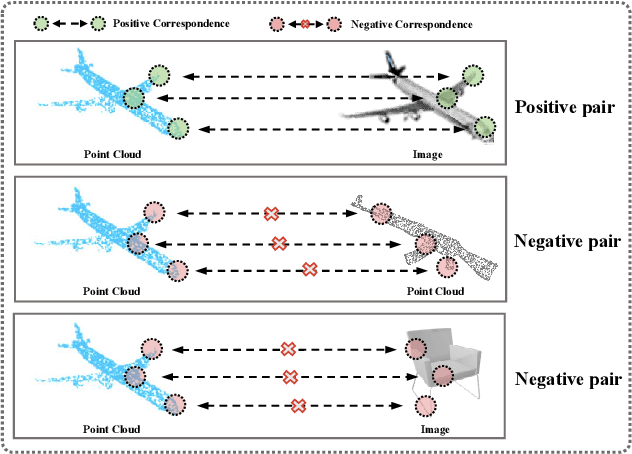

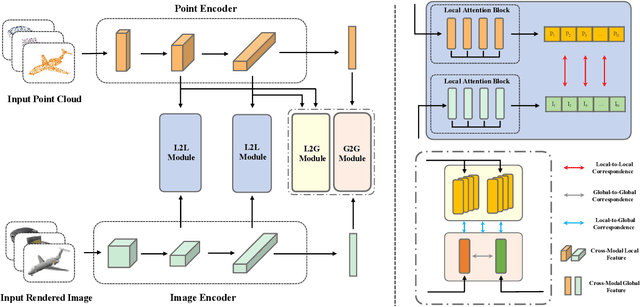
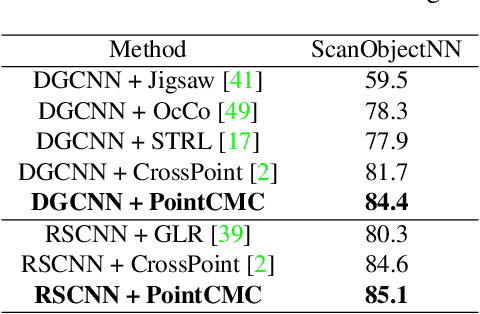
Some self-supervised cross-modal learning approaches have recently demonstrated the potential of image signals for enhancing point cloud representation. However, it remains a question on how to directly model cross-modal local and global correspondences in a self-supervised fashion. To solve it, we proposed PointCMC, a novel cross-modal method to model multi-scale correspondences across modalities for self-supervised point cloud representation learning. In particular, PointCMC is composed of: (1) a local-to-local (L2L) module that learns local correspondences through optimized cross-modal local geometric features, (2) a local-to-global (L2G) module that aims to learn the correspondences between local and global features across modalities via local-global discrimination, and (3) a global-to-global (G2G) module, which leverages auxiliary global contrastive loss between the point cloud and image to learn high-level semantic correspondences. Extensive experiment results show that our approach outperforms existing state-of-the-art methods in various downstream tasks such as 3D object classification and segmentation. Code will be made publicly available upon acceptance.
MetaCLUE: Towards Comprehensive Visual Metaphors Research
Dec 19, 2022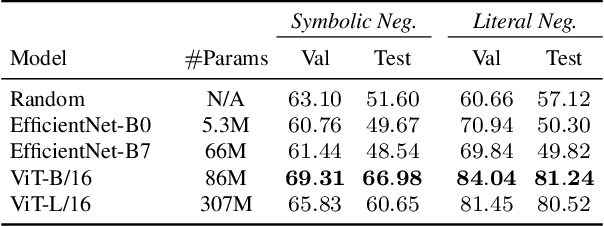


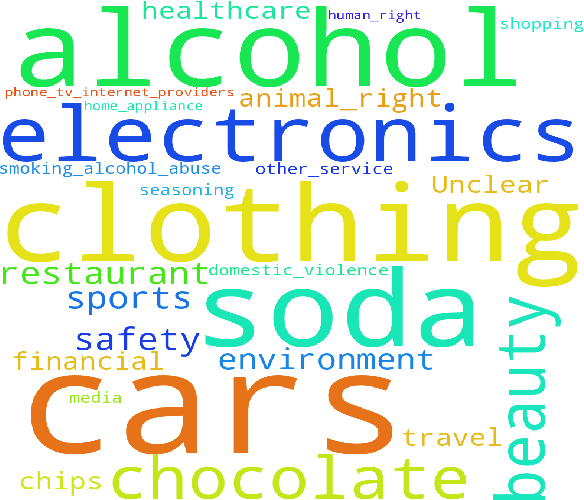
Creativity is an indispensable part of human cognition and also an inherent part of how we make sense of the world. Metaphorical abstraction is fundamental in communicating creative ideas through nuanced relationships between abstract concepts such as feelings. While computer vision benchmarks and approaches predominantly focus on understanding and generating literal interpretations of images, metaphorical comprehension of images remains relatively unexplored. Towards this goal, we introduce MetaCLUE, a set of vision tasks on visual metaphor. We also collect high-quality and rich metaphor annotations (abstract objects, concepts, relationships along with their corresponding object boxes) as there do not exist any datasets that facilitate the evaluation of these tasks. We perform a comprehensive analysis of state-of-the-art models in vision and language based on our annotations, highlighting strengths and weaknesses of current approaches in visual metaphor Classification, Localization, Understanding (retrieval, question answering, captioning) and gEneration (text-to-image synthesis) tasks. We hope this work provides a concrete step towards developing AI systems with human-like creative capabilities.
From a Bird's Eye View to See: Joint Camera and Subject Registration without the Camera Calibration
Dec 19, 2022
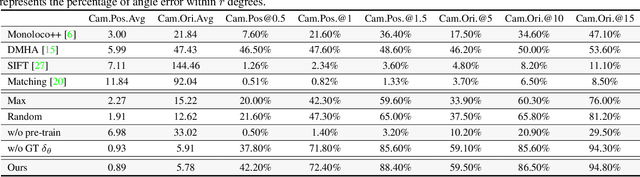
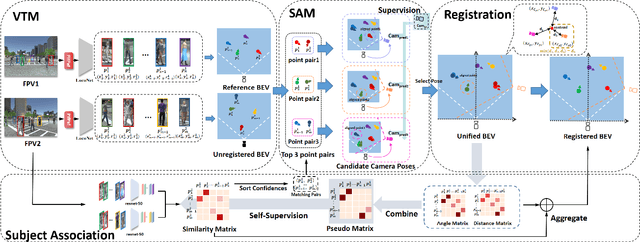
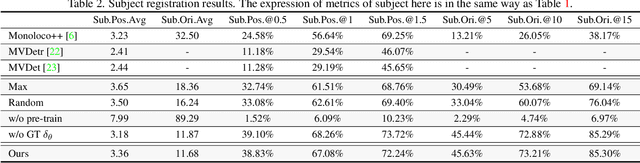
We tackle a new problem of multi-view camera and subject registration in the bird's eye view (BEV) without pre-given camera calibration. This is a very challenging problem since its only input is several RGB images from different first-person views (FPVs) for a multi-person scene, without the BEV image and the calibration of the FPVs, while the output is a unified plane with the localization and orientation of both the subjects and cameras in a BEV. We propose an end-to-end framework solving this problem, whose main idea can be divided into following parts: i) creating a view-transform subject detection module to transform the FPV to a virtual BEV including localization and orientation of each pedestrian, ii) deriving a geometric transformation based method to estimate camera localization and view direction, i.e., the camera registration in a unified BEV, iii) making use of spatial and appearance information to aggregate the subjects into the unified BEV. We collect a new large-scale synthetic dataset with rich annotations for evaluation. The experimental results show the remarkable effectiveness of our proposed method.
LayoutDETR: Detection Transformer Is a Good Multimodal Layout Designer
Dec 19, 2022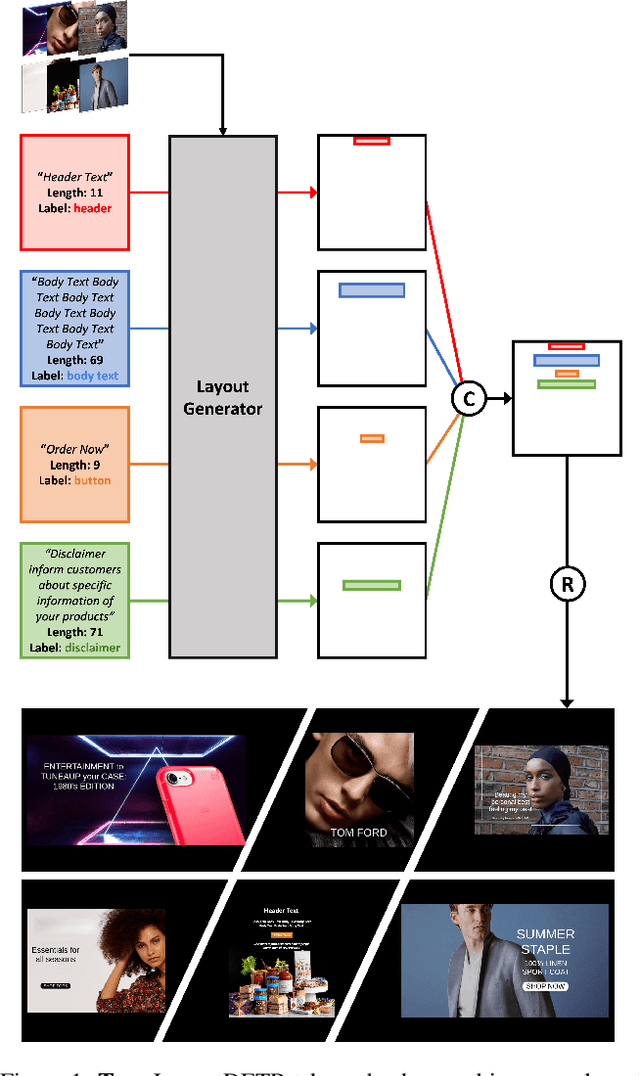
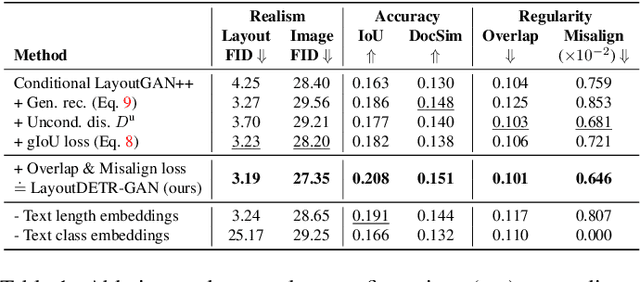
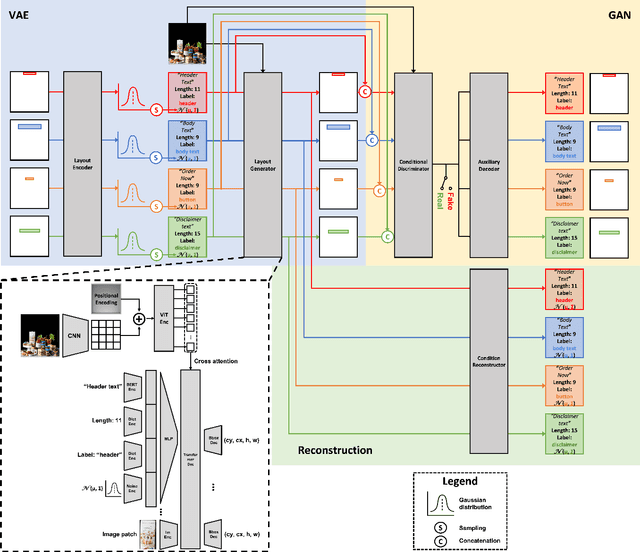
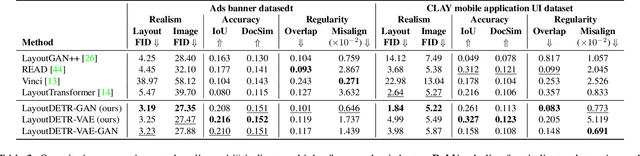
Graphic layout designs play an essential role in visual communication. Yet handcrafting layout designs are skill-demanding, time-consuming, and non-scalable to batch production. Although generative models emerge to make design automation no longer utopian, it remains non-trivial to customize designs that comply with designers' multimodal desires, i.e., constrained by background images and driven by foreground contents. In this study, we propose \textit{LayoutDETR} that inherits the high quality and realism from generative modeling, in the meanwhile reformulating content-aware requirements as a detection problem: we learn to detect in a background image the reasonable locations, scales, and spatial relations for multimodal elements in a layout. Experiments validate that our solution yields new state-of-the-art performance for layout generation on public benchmarks and on our newly-curated ads banner dataset. For practical usage, we build our solution into a graphical system that facilitates user studies. We demonstrate that our designs attract more subjective preference than baselines by significant margins. Our code, models, dataset, graphical system, and demos are available at https://github.com/salesforce/LayoutDETR.
CharFormer: A Glyph Fusion based Attentive Framework for High-precision Character Image Denoising
Jul 16, 2022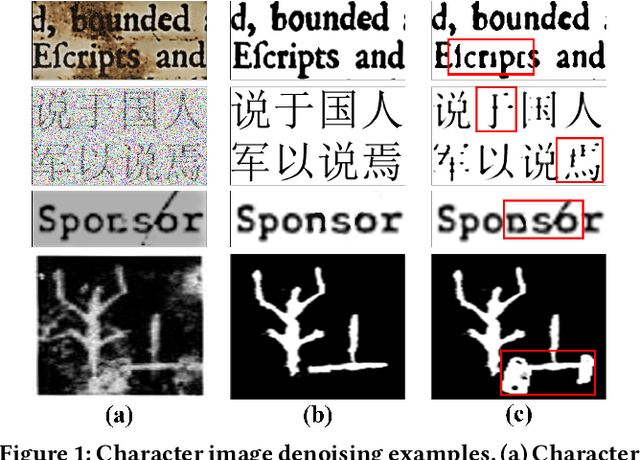
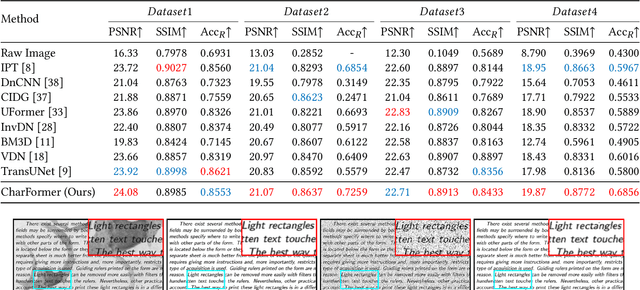
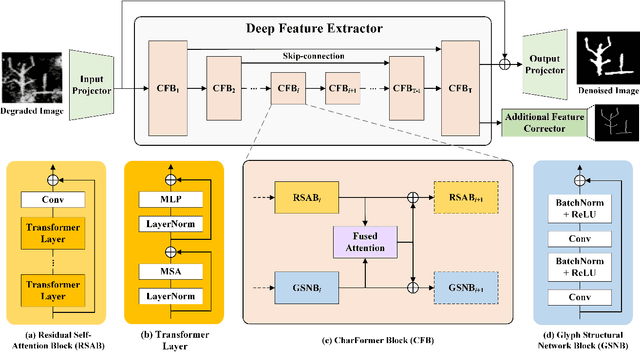
Degraded images commonly exist in the general sources of character images, leading to unsatisfactory character recognition results. Existing methods have dedicated efforts to restoring degraded character images. However, the denoising results obtained by these methods do not appear to improve character recognition performance. This is mainly because current methods only focus on pixel-level information and ignore critical features of a character, such as its glyph, resulting in character-glyph damage during the denoising process. In this paper, we introduce a novel generic framework based on glyph fusion and attention mechanisms, i.e., CharFormer, for precisely recovering character images without changing their inherent glyphs. Unlike existing frameworks, CharFormer introduces a parallel target task for capturing additional information and injecting it into the image denoising backbone, which will maintain the consistency of character glyphs during character image denoising. Moreover, we utilize attention-based networks for global-local feature interaction, which will help to deal with blind denoising and enhance denoising performance. We compare CharFormer with state-of-the-art methods on multiple datasets. The experimental results show the superiority of CharFormer quantitatively and qualitatively.
Novel transfer learning schemes based on Siamese networks and synthetic data
Nov 21, 2022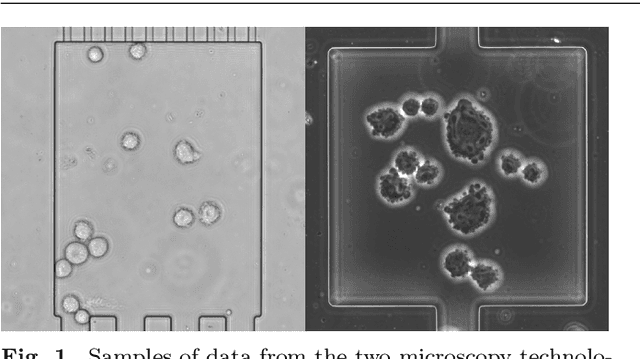
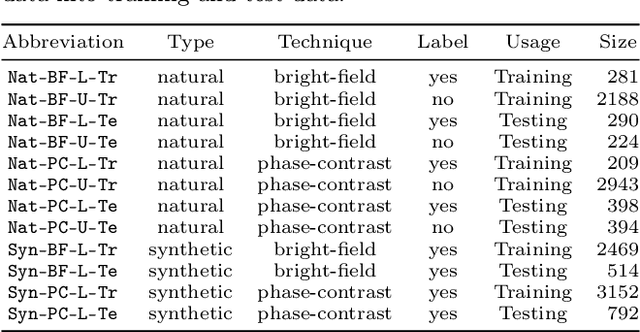
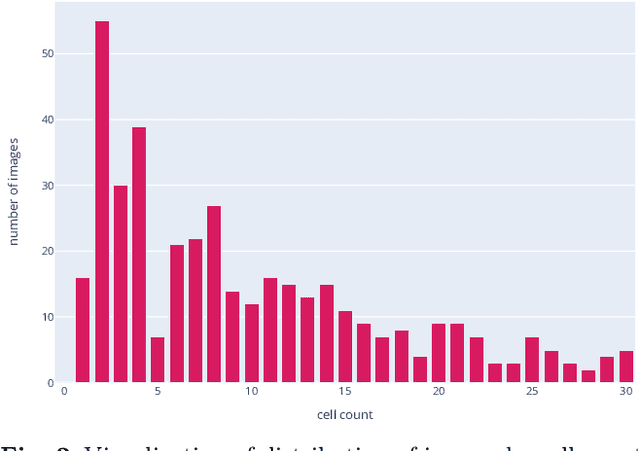
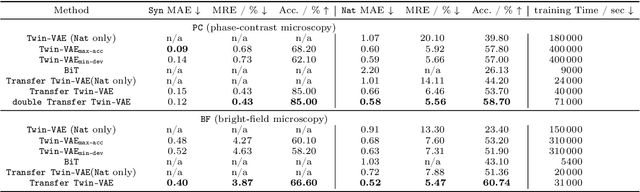
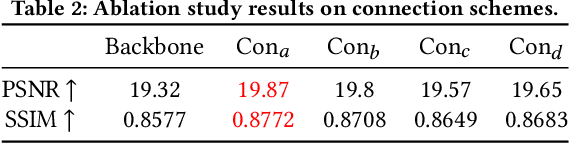
Transfer learning schemes based on deep networks which have been trained on huge image corpora offer state-of-the-art technologies in computer vision. Here, supervised and semi-supervised approaches constitute efficient technologies which work well with comparably small data sets. Yet, such applications are currently restricted to application domains where suitable deepnetwork models are readily available. In this contribution, we address an important application area in the domain of biotechnology, the automatic analysis of CHO-K1 suspension growth in microfluidic single-cell cultivation, where data characteristics are very dissimilar to existing domains and trained deep networks cannot easily be adapted by classical transfer learning. We propose a novel transfer learning scheme which expands a recently introduced Twin-VAE architecture, which is trained on realistic and synthetic data, and we modify its specialized training procedure to the transfer learning domain. In the specific domain, often only few to no labels exist and annotations are costly. We investigate a novel transfer learning strategy, which incorporates a simultaneous retraining on natural and synthetic data using an invariant shared representation as well as suitable target variables, while it learns to handle unseen data from a different microscopy tech nology. We show the superiority of the variation of our Twin-VAE architecture over the state-of-the-art transfer learning methodology in image processing as well as classical image processing technologies, which persists, even with strongly shortened training times and leads to satisfactory results in this domain. The source code is available at https://github.com/dstallmann/transfer_learning_twinvae, works cross-platform, is open-source and free (MIT licensed) software. We make the data sets available at https://pub.uni-bielefeld.de/record/2960030.