 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-View Panorama Image Synthesis
Mar 22, 2022
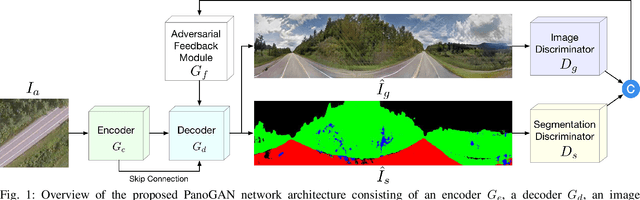
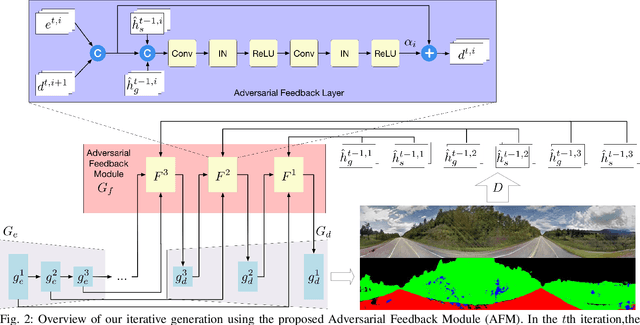
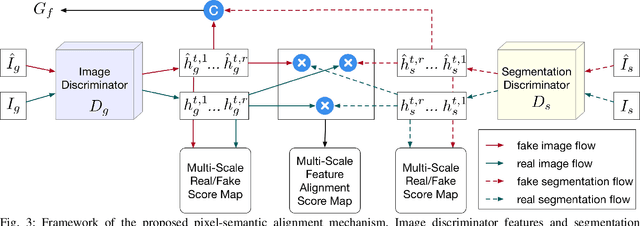

In this paper, we tackle the problem of synthesizing a ground-view panorama image conditioned on a top-view aerial image, which is a challenging problem due to the large gap between the two image domains with different view-points. Instead of learning cross-view mapping in a feedforward pass, we propose a novel adversarial feedback GAN framework named PanoGAN with two key components: an adversarial feedback module and a dual branch discrimination strategy. First, the aerial image is fed into the generator to produce a target panorama image and its associated segmentation map in favor of model training with layout semantics. Second, the feature responses of the discriminator encoded by our adversarial feedback module are fed back to the generator to refine the intermediate representations, so that the generation performance is continually improved through an iterative generation process. Third, to pursue high-fidelity and semantic consistency of the generated panorama image, we propose a pixel-segmentation alignment mechanism under the dual branch discrimiantion strategy to facilitate cooperation between the generator and the discriminator. Extensive experimental results on two challenging cross-view image datasets show that PanoGAN enables high-quality panorama image generation with more convincing details than state-of-the-art approaches. The source code and trained models are available at \url{https://github.com/sswuai/PanoGAN}.
ORCa: Glossy Objects as Radiance Field Cameras
Dec 08, 2022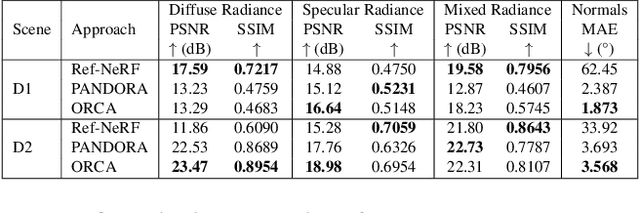
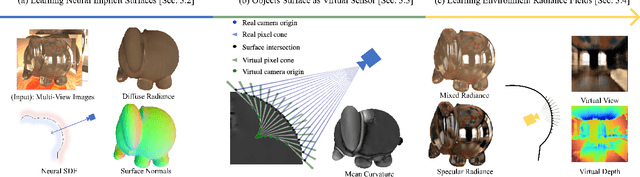
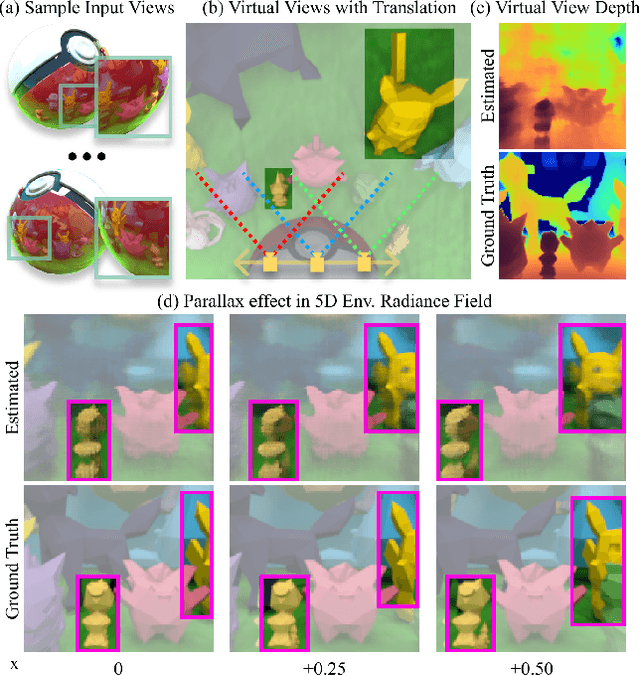
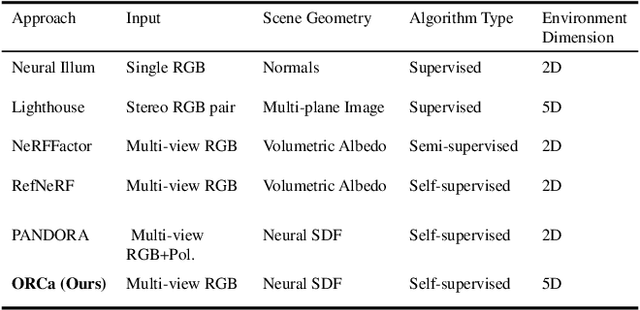
Reflections on glossy objects contain valuable and hidden information about the surrounding environment. By converting these objects into cameras, we can unlock exciting applications, including imaging beyond the camera's field-of-view and from seemingly impossible vantage points, e.g. from reflections on the human eye. However, this task is challenging because reflections depend jointly on object geometry, material properties, the 3D environment, and the observer viewing direction. Our approach converts glossy objects with unknown geometry into radiance-field cameras to image the world from the object's perspective. Our key insight is to convert the object surface into a virtual sensor that captures cast reflections as a 2D projection of the 5D environment radiance field visible to the object. We show that recovering the environment radiance fields enables depth and radiance estimation from the object to its surroundings in addition to beyond field-of-view novel-view synthesis, i.e. rendering of novel views that are only directly-visible to the glossy object present in the scene, but not the observer. Moreover, using the radiance field we can image around occluders caused by close-by objects in the scene. Our method is trained end-to-end on multi-view images of the object and jointly estimates object geometry, diffuse radiance, and the 5D environment radiance field.
Re-purposing Perceptual Hashing based Client Side Scanning for Physical Surveillance
Dec 08, 2022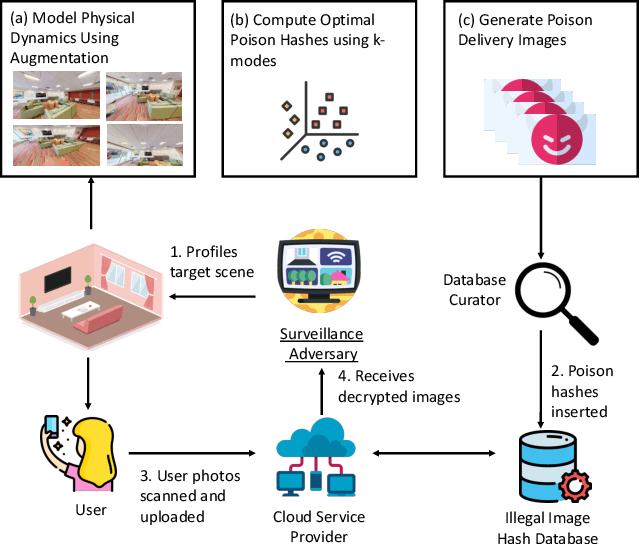
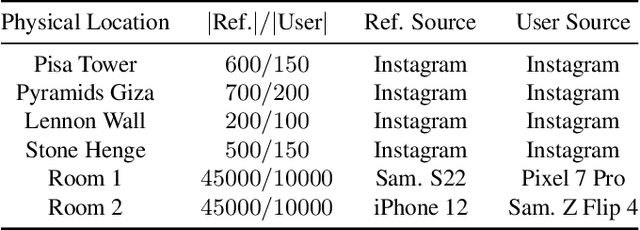
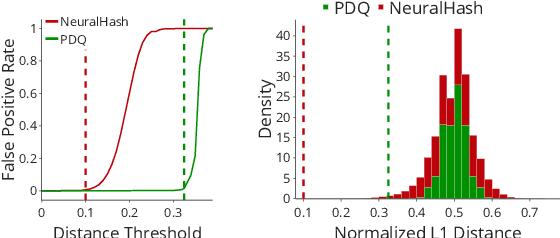

Content scanning systems employ perceptual hashing algorithms to scan user content for illegal material, such as child pornography or terrorist recruitment flyers. Perceptual hashing algorithms help determine whether two images are visually similar while preserving the privacy of the input images. Several efforts from industry and academia propose to conduct content scanning on client devices such as smartphones due to the impending roll out of end-to-end encryption that will make server-side content scanning difficult. However, these proposals have met with strong criticism because of the potential for the technology to be misused and re-purposed. Our work informs this conversation by experimentally characterizing the potential for one type of misuse -- attackers manipulating the content scanning system to perform physical surveillance on target locations. Our contributions are threefold: (1) we offer a definition of physical surveillance in the context of client-side image scanning systems; (2) we experimentally characterize this risk and create a surveillance algorithm that achieves physical surveillance rates of >40% by poisoning 5% of the perceptual hash database; (3) we experimentally study the trade-off between the robustness of client-side image scanning systems and surveillance, showing that more robust detection of illegal material leads to increased potential for physical surveillance.
ISG: I can See Your Gene Expression
Oct 30, 2022


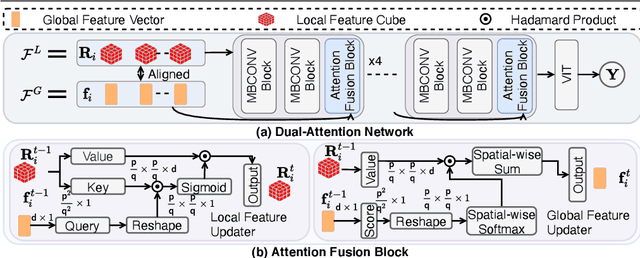
This paper aims to predict gene expression from a histology slide image precisely. Such a slide image has a large resolution and sparsely distributed textures. These obstruct extracting and interpreting discriminative features from the slide image for diverse gene types prediction. Existing gene expression methods mainly use general components to filter textureless regions, extract features, and aggregate features uniformly across regions. However, they ignore gaps and interactions between different image regions and are therefore inferior in the gene expression task. Instead, we present ISG framework that harnesses interactions among discriminative features from texture-abundant regions by three new modules: 1) a Shannon Selection module, based on the Shannon information content and Solomonoff's theory, to filter out textureless image regions; 2) a Feature Extraction network to extract expressive low-dimensional feature representations for efficient region interactions among a high-resolution image; 3) a Dual Attention network attends to regions with desired gene expression features and aggregates them for the prediction task. Extensive experiments on standard benchmark datasets show that the proposed ISG framework outperforms state-of-the-art methods significantly.
Who are you referring to? Weakly supervised coreference resolution with multimodal grounding
Nov 26, 2022

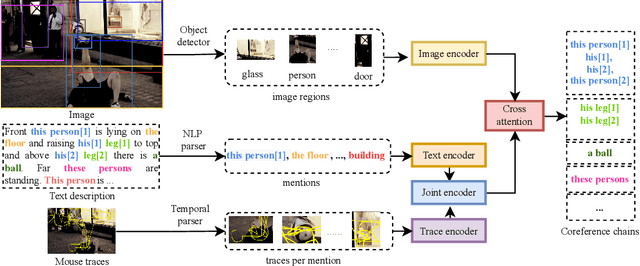
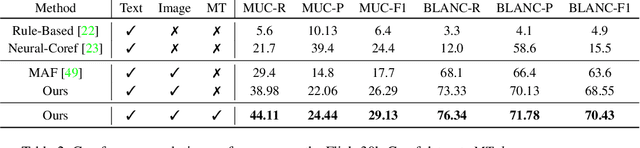
Coreference resolution aims at identifying words and phrases which refer to same entity in a text, a core tool in natural language processing. In this paper, we propose a novel task, resolving coreferences in multimodal data, long-form textual descriptions of visual scenes. Most existing image-text datasets only contain short sentences without coreferent expressions, or coreferences are not annotated. To this end, we first introduce a new dataset, Flickr30k-Coref in which coreference chains and bounding box localization of these chains are annotated. We propose a new technique that learns to identify coreference chains through weakly supervised grounding from image-text pairs and a regularization using prior linguistic knowledge. Our model yields large performance gains over prior work in coreference resolution and weakly supervised grounding of long-form text descriptions.
Development Of A Fire Detection System On Satellite Images
Dec 07, 2022
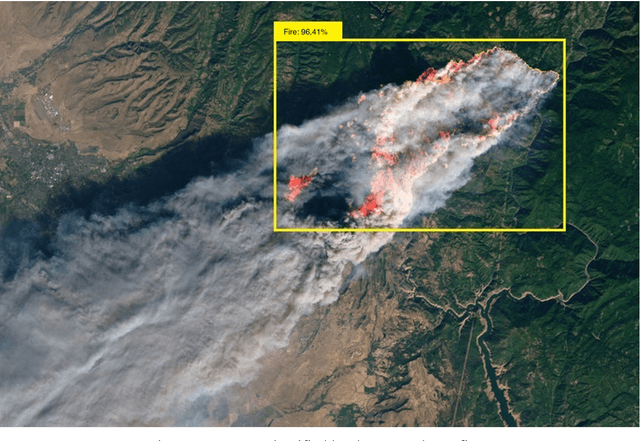

This paper discusses the development of a convolutional architecture of a deep neural network for the recognition of wildfires on satellite images. Based on the results of image classification, a fuzzy cognitive map of the analysis of the macroeconomic situation was built. The paper also considers the prospect of using hybrid cognitive models for forecasting macroeconomic indicators based on fuzzy cognitive maps using data on recognized wildfires on satellite images.
On Scale Space Radon Transform, Properties and Image Reconstruction
May 10, 2022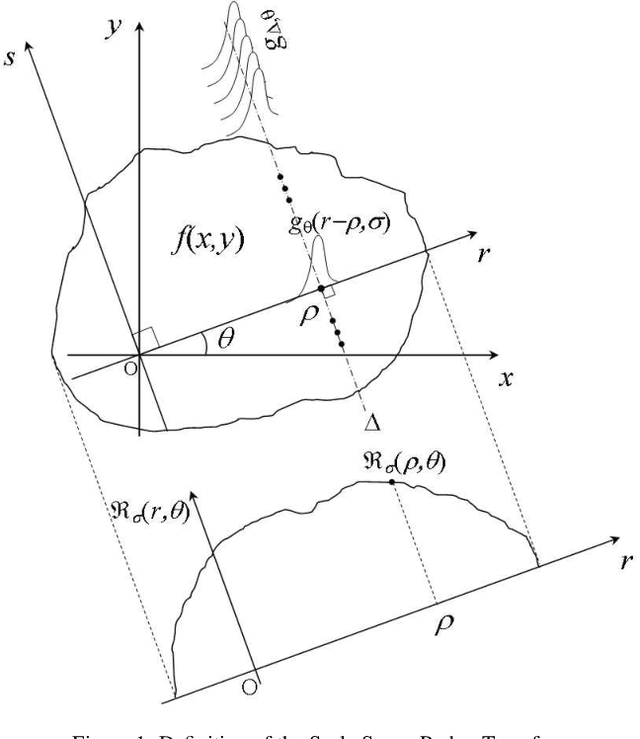
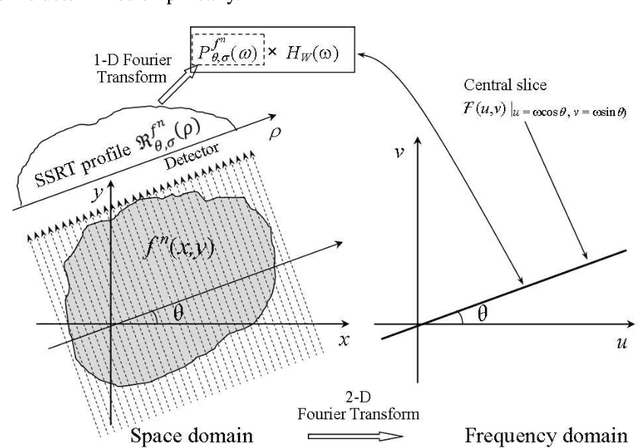
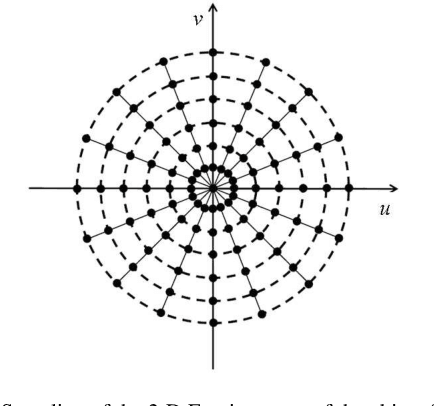
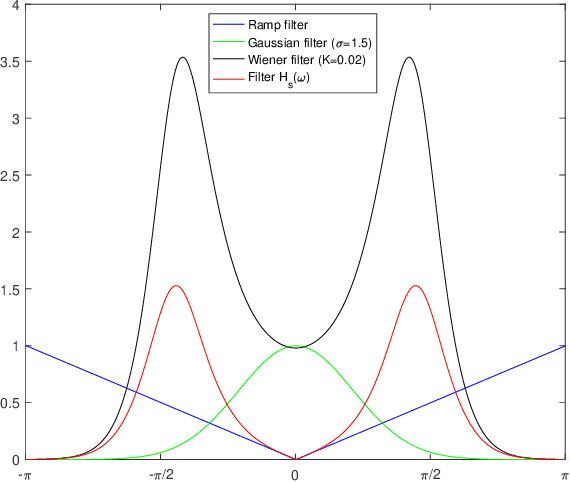
Aware of the importance of the good behavior in the scale space that a mathematical transform must have, we depict, in this paper, the basic properties and the inverse transform of the Scale Space Radon Transform (SSRT). To reconstruct the image from SSRT sinogram, the Filtered backprojection (FBP) technique is used in two different ways: (1) Deconvolve SSRT to obtain the estimated Radon transform (RT) and then, reconstruct image using classical FBP or (2) Adapt FBP technique to SSRT so that the Radon projections spectrum used in classical FBP is replaced by SSRT and Wiener filtering, expressed in the frequency domain. Comparison of image reconstruction techniques using SSRT and RT are performed on Shepp-Logan head phantom image. Using the Mean Absolute Error (MAE) as image reconstruction quality measure, the preliminary results present an outstanding performance for SSRT-based image reconstruction techniques compared to the RT-based one. Furthermore, the method (2) outperforms the method (1) in terms of computation time and adaptability for high level of noise when fairly large Gaussian kernel is used.
Fast Hybrid Image Retargeting
Mar 25, 2022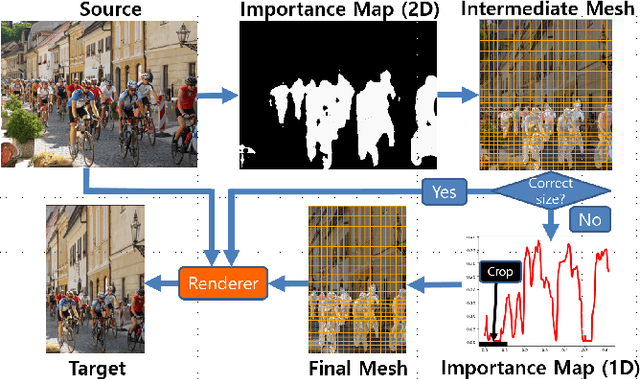

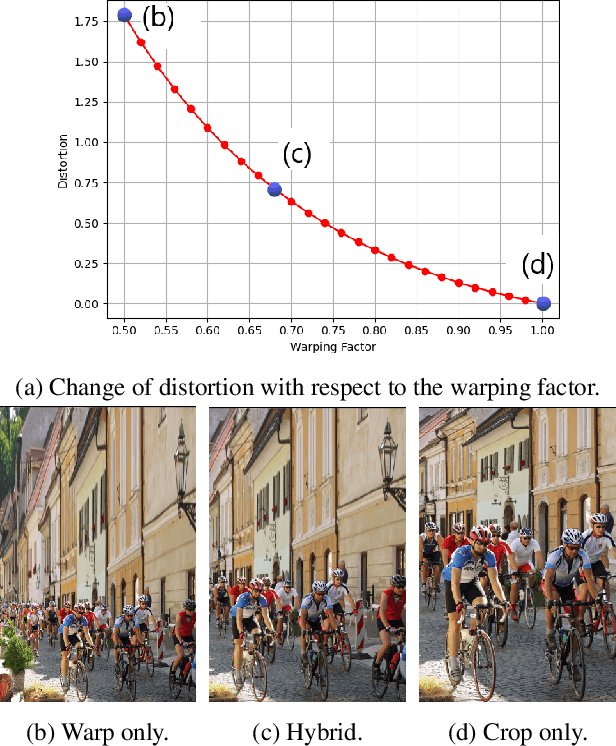
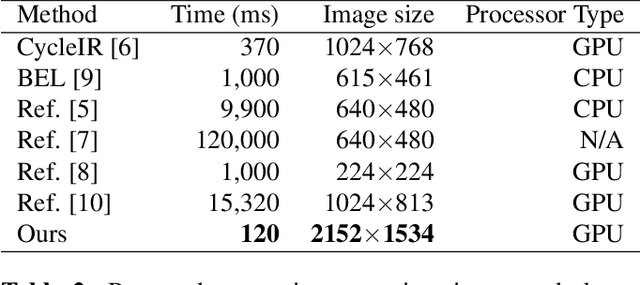
Image retargeting changes the aspect ratio of images while aiming to preserve content and minimise noticeable distortion. Fast and high-quality methods are particularly relevant at present, due to the large variety of image and display aspect ratios. We propose a retargeting method that quantifies and limits warping distortions with the use of content-aware cropping. The pipeline of the proposed approach consists of the following steps. First, an importance map of a source image is generated using deep semantic segmentation and saliency detection models. Then, a preliminary warping mesh is computed using axis aligned deformations, enhanced with the use of a distortion measure to ensure low warping deformations. Finally, the retargeted image is produced using a content-aware cropping algorithm. In order to evaluate our method, we perform a user study based on the RetargetMe benchmark. Experimental analyses show that our method outperforms recent approaches, while running in a fraction of their execution time.
* 5 pages
Source-Free Unsupervised Domain Adaptation with Norm and Shape Constraints for Medical Image Segmentation
Sep 03, 2022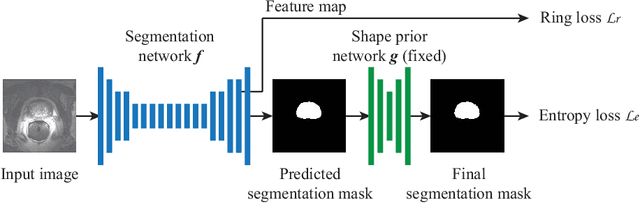

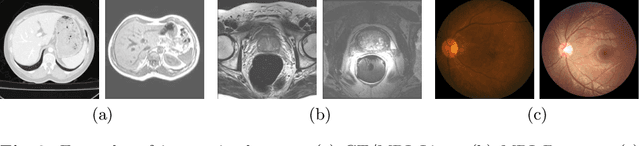

Unsupervised domain adaptation (UDA) is one of the key technologies to solve a problem where it is hard to obtain ground truth labels needed for supervised learning. In general, UDA assumes that all samples from source and target domains are available during the training process. However, this is not a realistic assumption under applications where data privacy issues are concerned. To overcome this limitation, UDA without source data, referred to source-free unsupervised domain adaptation (SFUDA) has been recently proposed. Here, we propose a SFUDA method for medical image segmentation. In addition to the entropy minimization method, which is commonly used in UDA, we introduce a loss function for avoiding feature norms in the target domain small and a prior to preserve shape constraints of the target organ. We conduct experiments using datasets including multiple types of source-target domain combinations in order to show the versatility and robustness of our method. We confirm that our method outperforms the state-of-the-art in all datasets.
Hierarchical Text-Conditional Image Generation with CLIP Latents
Apr 13, 2022


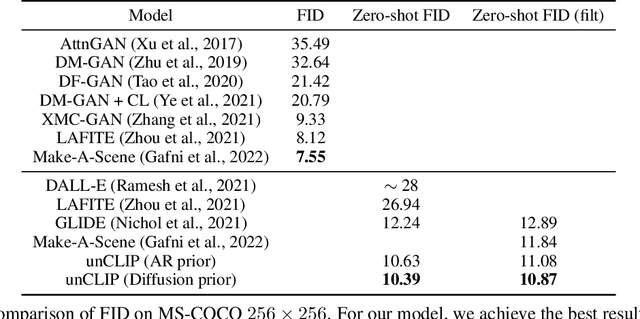
Contrastive models like CLIP have been shown to learn robust representations of images that capture both semantics and style. To leverage these representations for image generation, we propose a two-stage model: a prior that generates a CLIP image embedding given a text caption, and a decoder that generates an image conditioned on the image embedding. We show that explicitly generating image representations improves image diversity with minimal loss in photorealism and caption similarity. Our decoders conditioned on image representations can also produce variations of an image that preserve both its semantics and style, while varying the non-essential details absent from the image representation. Moreover, the joint embedding space of CLIP enables language-guided image manipulations in a zero-shot fashion. We use diffusion models for the decoder and experiment with both autoregressive and diffusion models for the prior, finding that the latter are computationally more efficient and produce higher-quality samples.