 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Advanced Data Augmentation Approaches: A Comprehensive Survey and Future directions
Jan 07, 2023
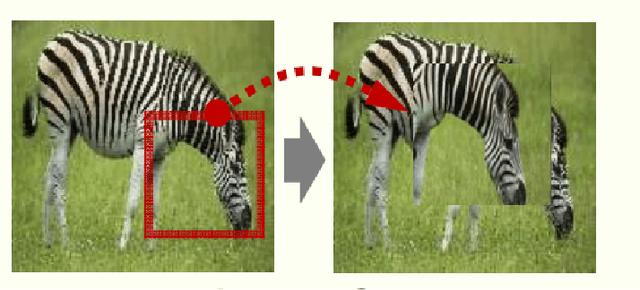
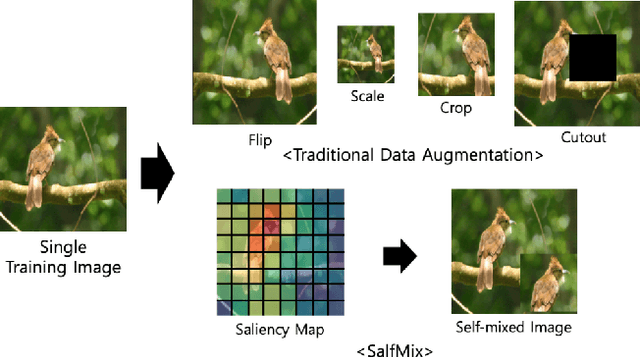


Deep learning (DL) algorithms have shown significant performance in various computer vision tasks. However, having limited labelled data lead to a network overfitting problem, where network performance is bad on unseen data as compared to training data. Consequently, it limits performance improvement. To cope with this problem, various techniques have been proposed such as dropout, normalization and advanced data augmentation. Among these, data augmentation, which aims to enlarge the dataset size by including sample diversity, has been a hot topic in recent times. In this article, we focus on advanced data augmentation techniques. we provide a background of data augmentation, a novel and comprehensive taxonomy of reviewed data augmentation techniques, and the strengths and weaknesses (wherever possible) of each technique. We also provide comprehensive results of the data augmentation effect on three popular computer vision tasks, such as image classification, object detection and semantic segmentation. For results reproducibility, we compiled available codes of all data augmentation techniques. Finally, we discuss the challenges and difficulties, and possible future direction for the research community. We believe, this survey provides several benefits i) readers will understand the data augmentation working mechanism to fix overfitting problems ii) results will save the searching time of the researcher for comparison purposes. iii) Codes of the mentioned data augmentation techniques are available at https://github.com/kmr2017/Advanced-Data-augmentation-codes iv) Future work will spark interest in research community.
Saccade Mechanisms for Image Classification, Object Detection and Tracking
Jun 10, 2022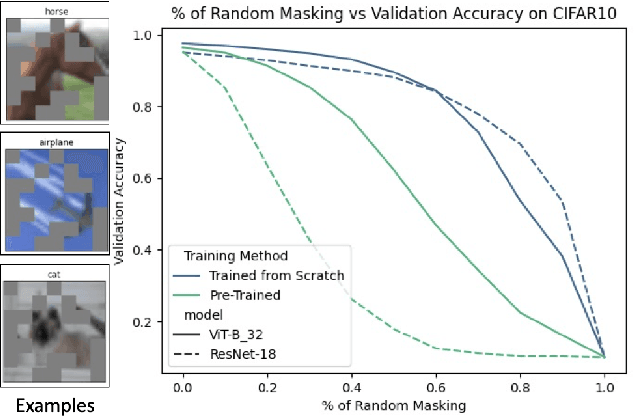
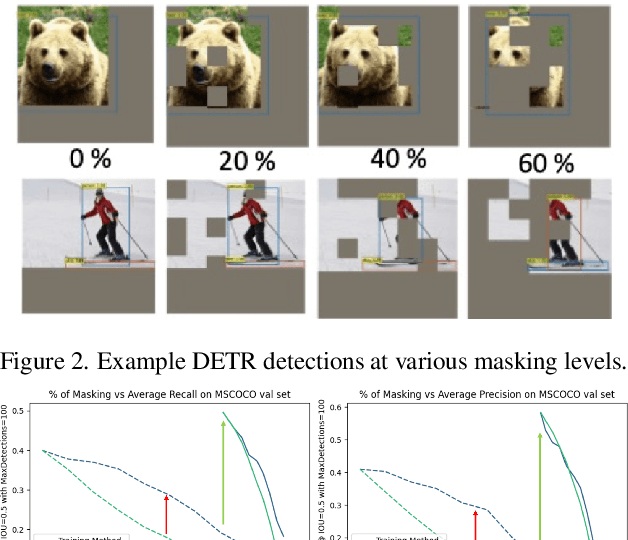

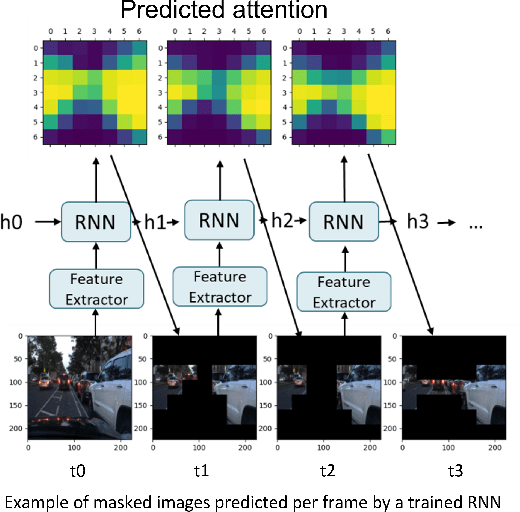
We examine how the saccade mechanism from biological vision can be used to make deep neural networks more efficient for classification and object detection problems. Our proposed approach is based on the ideas of attention-driven visual processing and saccades, miniature eye movements influenced by attention. We conduct experiments by analyzing: i) the robustness of different deep neural network (DNN) feature extractors to partially-sensed images for image classification and object detection, and ii) the utility of saccades in masking image patches for image classification and object tracking. Experiments with convolutional nets (ResNet-18) and transformer-based models (ViT, DETR, TransTrack) are conducted on several datasets (CIFAR-10, DAVSOD, MSCOCO, and MOT17). Our experiments show intelligent data reduction via learning to mimic human saccades when used in conjunction with state-of-the-art DNNs for classification, detection, and tracking tasks. We observed minimal drop in performance for the classification and detection tasks while only using about 30\% of the original sensor data. We discuss how the saccade mechanism can inform hardware design via ``in-pixel'' processing.
High-level semantic feature matters few-shot unsupervised domain adaptation
Jan 05, 2023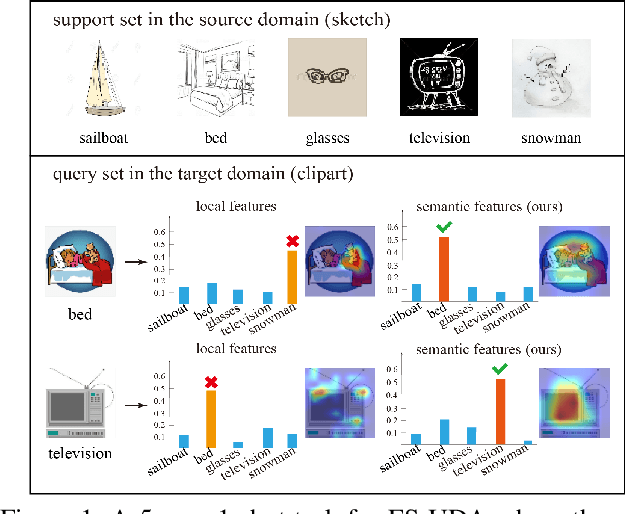
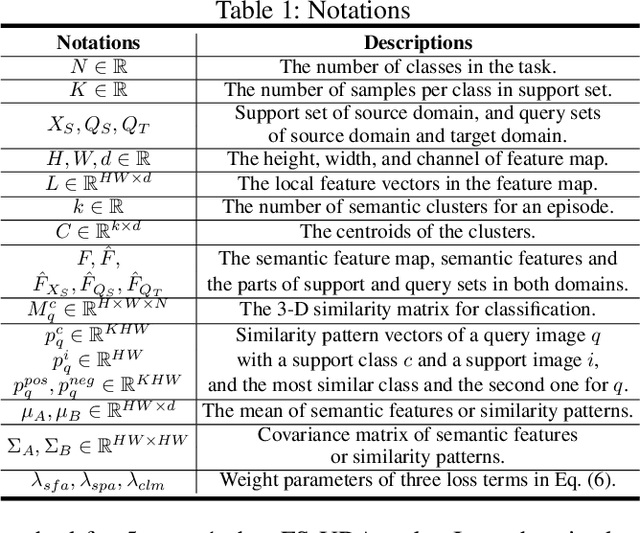
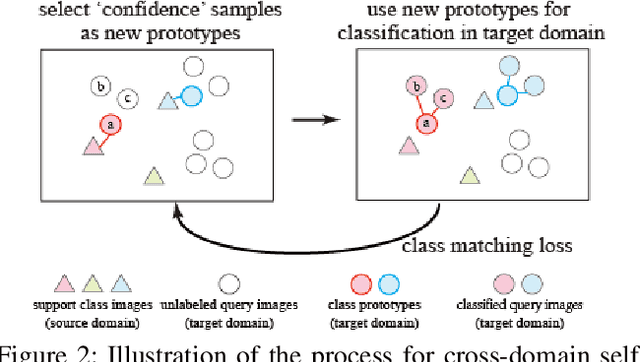
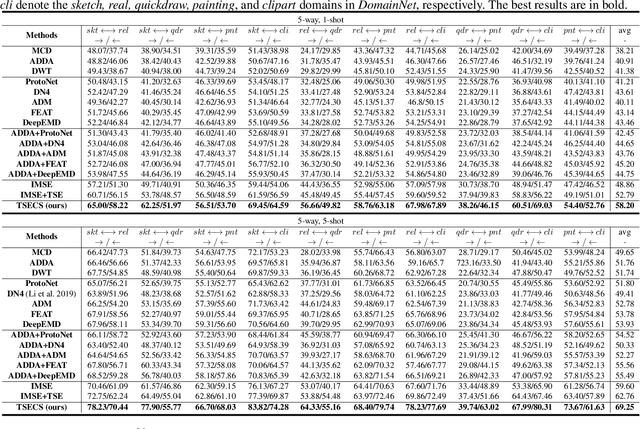
In few-shot unsupervised domain adaptation (FS-UDA), most existing methods followed the few-shot learning (FSL) methods to leverage the low-level local features (learned from conventional convolutional models, e.g., ResNet) for classification. However, the goal of FS-UDA and FSL are relevant yet distinct, since FS-UDA aims to classify the samples in target domain rather than source domain. We found that the local features are insufficient to FS-UDA, which could introduce noise or bias against classification, and not be used to effectively align the domains. To address the above issues, we aim to refine the local features to be more discriminative and relevant to classification. Thus, we propose a novel task-specific semantic feature learning method (TSECS) for FS-UDA. TSECS learns high-level semantic features for image-to-class similarity measurement. Based on the high-level features, we design a cross-domain self-training strategy to leverage the few labeled samples in source domain to build the classifier in target domain. In addition, we minimize the KL divergence of the high-level feature distributions between source and target domains to shorten the distance of the samples between the two domains. Extensive experiments on DomainNet show that the proposed method significantly outperforms SOTA methods in FS-UDA by a large margin (i.e., 10%).
Backdoor Attack is A Devil in Federated GAN-based Medical Image Synthesis
Jul 02, 2022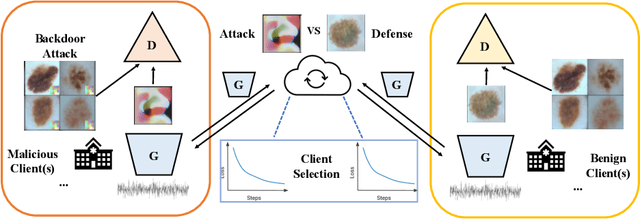
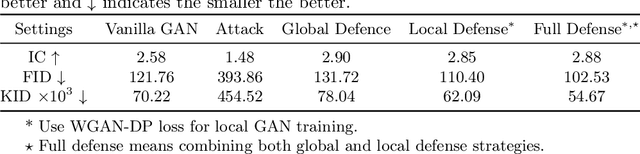
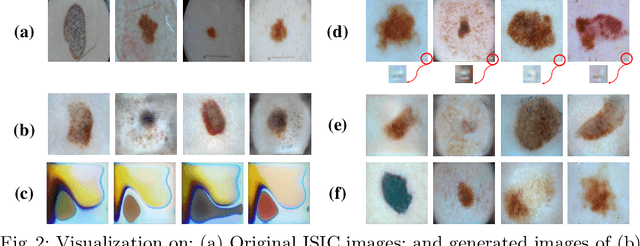
Deep Learning-based image synthesis techniques have been applied in healthcare research for generating medical images to support open research. Training generative adversarial neural networks (GAN) usually requires large amounts of training data. Federated learning (FL) provides a way of training a central model using distributed data from different medical institutions while keeping raw data locally. However, FL is vulnerable to backdoor attack, an adversarial by poisoning training data, given the central server cannot access the original data directly. Most backdoor attack strategies focus on classification models and centralized domains. In this study, we propose a way of attacking federated GAN (FedGAN) by treating the discriminator with a commonly used data poisoning strategy in backdoor attack classification models. We demonstrate that adding a small trigger with size less than 0.5 percent of the original image size can corrupt the FL-GAN model. Based on the proposed attack, we provide two effective defense strategies: global malicious detection and local training regularization. We show that combining the two defense strategies yields a robust medical image generation.
Cross-View Panorama Image Synthesis
Mar 22, 2022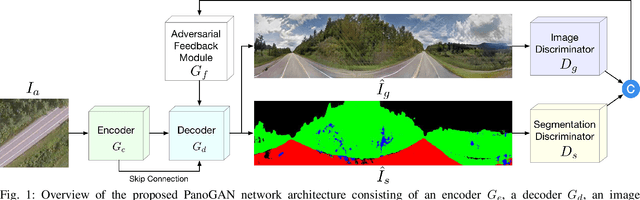
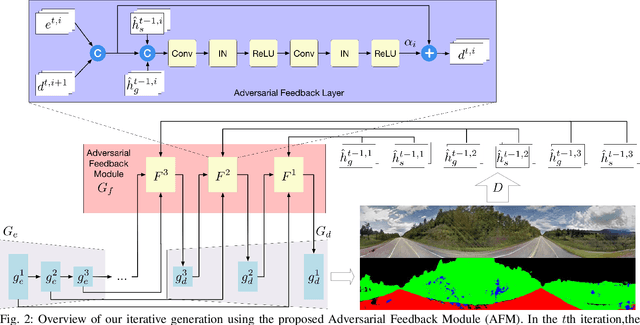
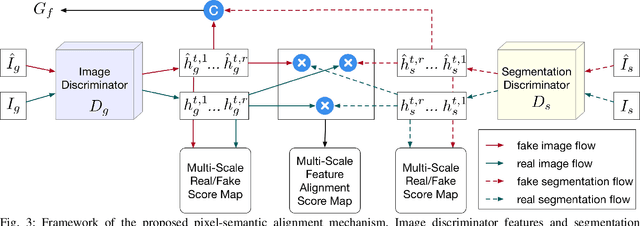

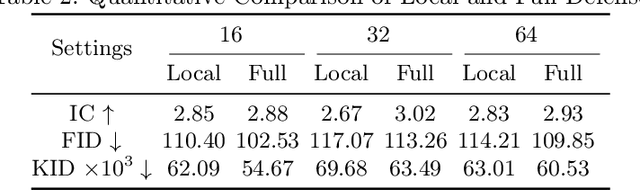
In this paper, we tackle the problem of synthesizing a ground-view panorama image conditioned on a top-view aerial image, which is a challenging problem due to the large gap between the two image domains with different view-points. Instead of learning cross-view mapping in a feedforward pass, we propose a novel adversarial feedback GAN framework named PanoGAN with two key components: an adversarial feedback module and a dual branch discrimination strategy. First, the aerial image is fed into the generator to produce a target panorama image and its associated segmentation map in favor of model training with layout semantics. Second, the feature responses of the discriminator encoded by our adversarial feedback module are fed back to the generator to refine the intermediate representations, so that the generation performance is continually improved through an iterative generation process. Third, to pursue high-fidelity and semantic consistency of the generated panorama image, we propose a pixel-segmentation alignment mechanism under the dual branch discrimiantion strategy to facilitate cooperation between the generator and the discriminator. Extensive experimental results on two challenging cross-view image datasets show that PanoGAN enables high-quality panorama image generation with more convincing details than state-of-the-art approaches. The source code and trained models are available at \url{https://github.com/sswuai/PanoGAN}.
Robustifying Deep Vision Models Through Shape Sensitization
Nov 14, 2022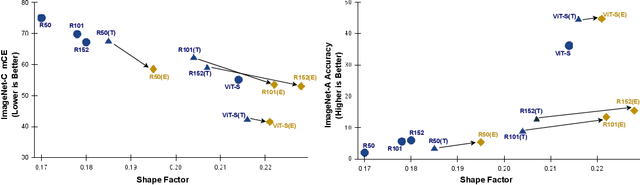
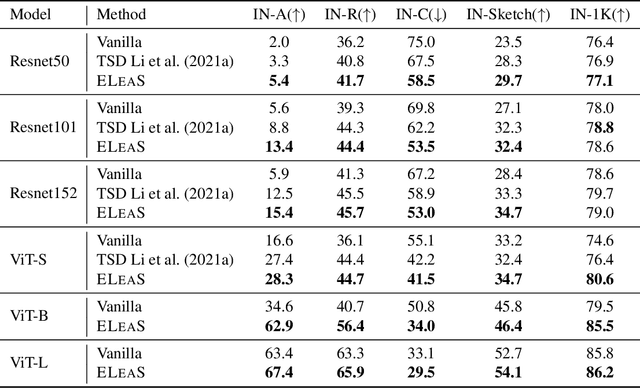
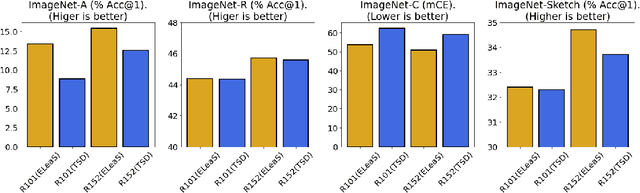
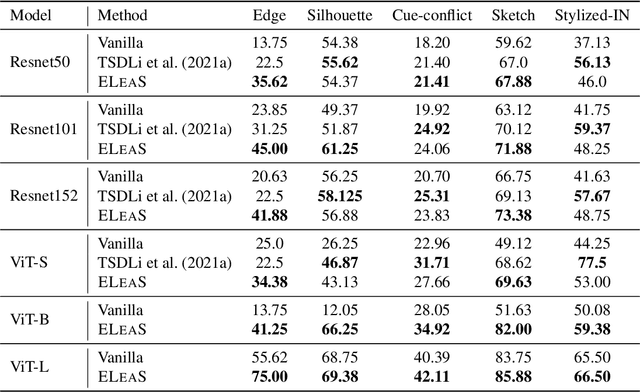
Recent work has shown that deep vision models tend to be overly dependent on low-level or "texture" features, leading to poor generalization. Various data augmentation strategies have been proposed to overcome this so-called texture bias in DNNs. We propose a simple, lightweight adversarial augmentation technique that explicitly incentivizes the network to learn holistic shapes for accurate prediction in an object classification setting. Our augmentations superpose edgemaps from one image onto another image with shuffled patches, using a randomly determined mixing proportion, with the image label of the edgemap image. To classify these augmented images, the model needs to not only detect and focus on edges but distinguish between relevant and spurious edges. We show that our augmentations significantly improve classification accuracy and robustness measures on a range of datasets and neural architectures. As an example, for ViT-S, We obtain absolute gains on classification accuracy gains up to 6%. We also obtain gains of up to 28% and 8.5% on natural adversarial and out-of-distribution datasets like ImageNet-A (for ViT-B) and ImageNet-R (for ViT-S), respectively. Analysis using a range of probe datasets shows substantially increased shape sensitivity in our trained models, explaining the observed improvement in robustness and classification accuracy.
Cross-Modality Image Registration using a Training-Time Privileged Third Modality
Jul 26, 2022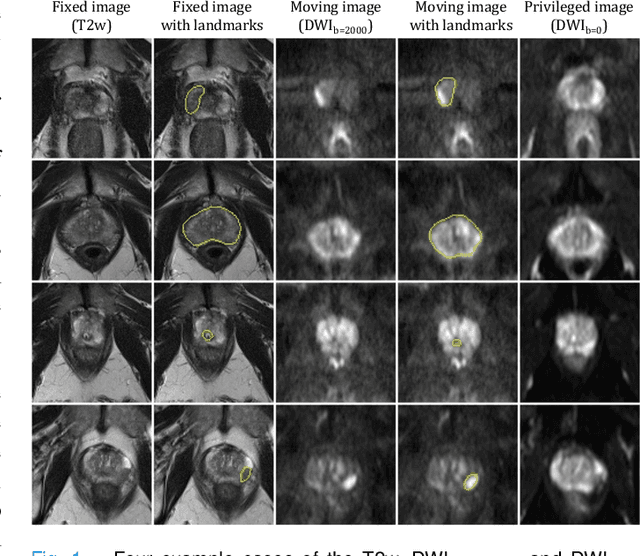
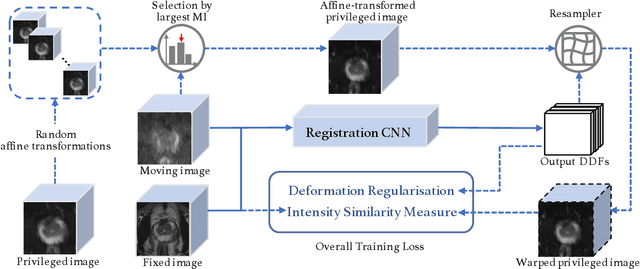
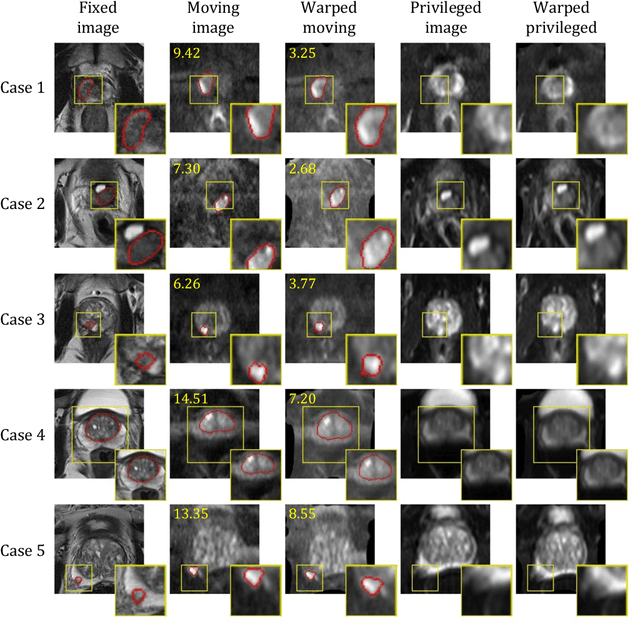
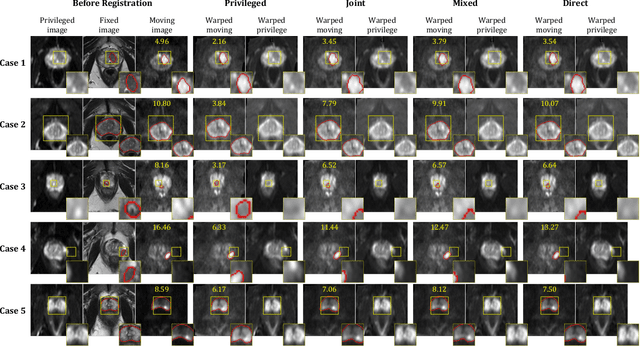
In this work, we consider the task of pairwise cross-modality image registration, which may benefit from exploiting additional images available only at training time from an additional modality that is different to those being registered. As an example, we focus on aligning intra-subject multiparametric Magnetic Resonance (mpMR) images, between T2-weighted (T2w) scans and diffusion-weighted scans with high b-value (DWI$_{high-b}$). For the application of localising tumours in mpMR images, diffusion scans with zero b-value (DWI$_{b=0}$) are considered easier to register to T2w due to the availability of corresponding features. We propose a learning from privileged modality algorithm, using a training-only imaging modality DWI$_{b=0}$, to support the challenging multi-modality registration problems. We present experimental results based on 369 sets of 3D multiparametric MRI images from 356 prostate cancer patients and report, with statistical significance, a lowered median target registration error of 4.34 mm, when registering the holdout DWI$_{high-b}$ and T2w image pairs, compared with that of 7.96 mm before registration. Results also show that the proposed learning-based registration networks enabled efficient registration with comparable or better accuracy, compared with a classical iterative algorithm and other tested learning-based methods with/without the additional modality. These compared algorithms also failed to produce any significantly improved alignment between DWI$_{high-b}$ and T2w in this challenging application.
Deep Joint Source-Channel Coding Over Cooperative Relay Networks
Nov 12, 2022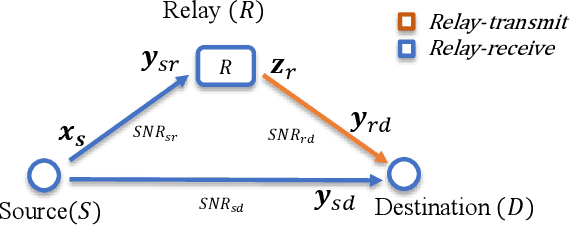
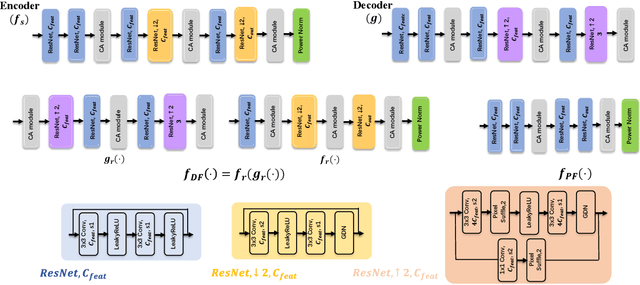
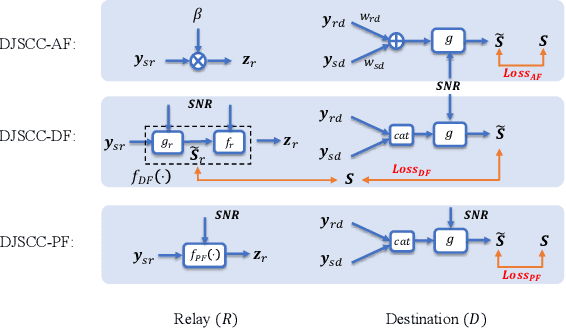
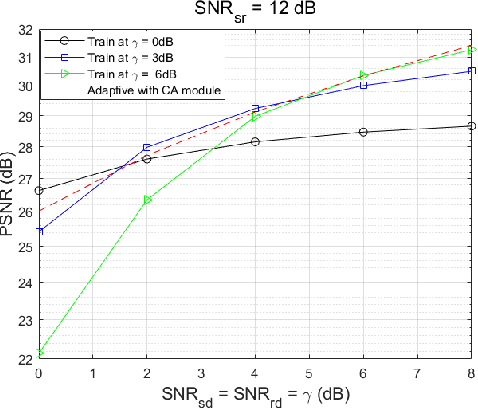
This paper presents a novel deep joint source-channel coding (DeepJSCC) scheme for image transmission over a half-duplex cooperative relay channel. Specifically, we apply DeepJSCC to two basic modes of cooperative communications, namely amplify-and-forward (AF) and decode-and-forward (DF). In DeepJSCC-AF, the relay simply amplifies and forwards its received signal. In DeepJSCC-DF, on the other hand, the relay first reconstructs the transmitted image and then re-encodes it before forwarding. Considering the excessive computation overhead of DeepJSCC-DF for recovering the image at the relay, we propose an alternative scheme, called DeepJSCC-PF, in which the relay processes and forwards its received signal without necessarily recovering the image. Simulation results show that the proposed DeepJSCC-AF, DF, and PF schemes are superior to the digital baselines with BPG compression with polar codes and provides a graceful performance degradation with deteriorating channel quality. Further investigation shows that the PSNR gain of DeepJSCC-DF/PF over DeepJSCC-AF improves as the channel condition between the source and relay improves. Moreover, DeepJSCC-PF scheme achieves a similar performance to DeepJSCC-DF with lower computational complexity.
3D Masked Modelling Advances Lesion Classification in Axial T2w Prostate MRI
Dec 29, 2022
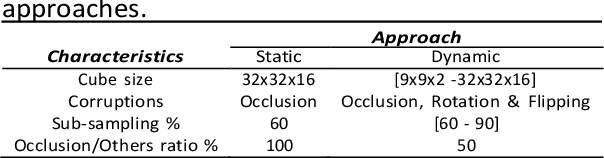
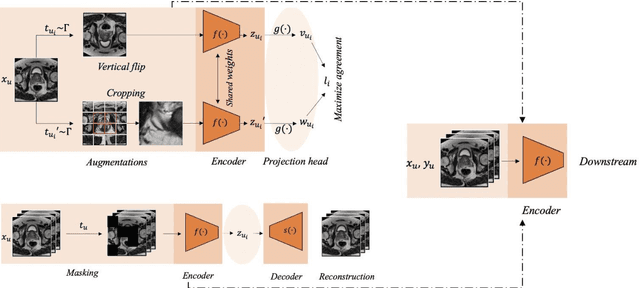

Masked Image Modelling (MIM) has been shown to be an efficient self-supervised learning (SSL) pre-training paradigm when paired with transformer architectures and in the presence of a large amount of unlabelled natural images. The combination of the difficulties in accessing and obtaining large amounts of labeled data and the availability of unlabelled data in the medical imaging domain makes MIM an interesting approach to advance deep learning (DL) applications based on 3D medical imaging data. Nevertheless, SSL and, in particular, MIM applications with medical imaging data are rather scarce and there is still uncertainty. around the potential of such a learning paradigm in the medical domain. We study MIM in the context of Prostate Cancer (PCa) lesion classification with T2 weighted (T2w) axial magnetic resonance imaging (MRI) data. In particular, we explore the effect of using MIM when coupled with convolutional neural networks (CNNs) under different conditions such as different masking strategies, obtaining better results in terms of AUC than other pre-training strategies like ImageNet weight initialization.
Multimodal Wildland Fire Smoke Detection
Dec 29, 2022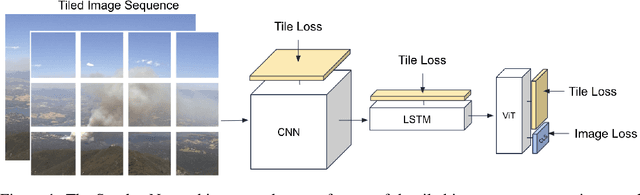
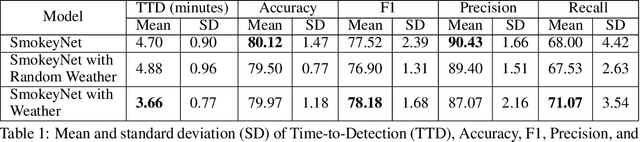
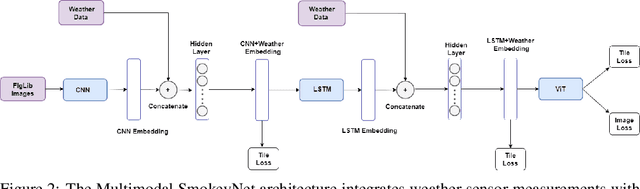
Research has shown that climate change creates warmer temperatures and drier conditions, leading to longer wildfire seasons and increased wildfire risks in the United States. These factors have in turn led to increases in the frequency, extent, and severity of wildfires in recent years. Given the danger posed by wildland fires to people, property, wildlife, and the environment, there is an urgency to provide tools for effective wildfire management. Early detection of wildfires is essential to minimizing potentially catastrophic destruction. In this paper, we present our work on integrating multiple data sources in SmokeyNet, a deep learning model using spatio-temporal information to detect smoke from wildland fires. Camera image data is integrated with weather sensor measurements and processed by SmokeyNet to create a multimodal wildland fire smoke detection system. We present our results comparing performance in terms of both accuracy and time-to-detection for multimodal data vs. a single data source. With a time-to-detection of only a few minutes, SmokeyNet can serve as an automated early notification system, providing a useful tool in the fight against destructive wildfires.