 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Point Catacaustics for Novel-View Synthesis of Reflections
Jan 03, 2023
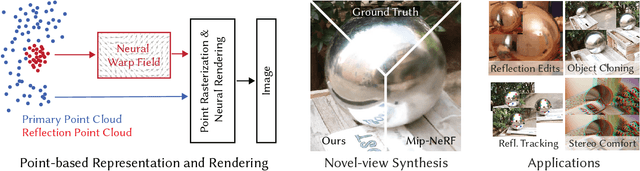
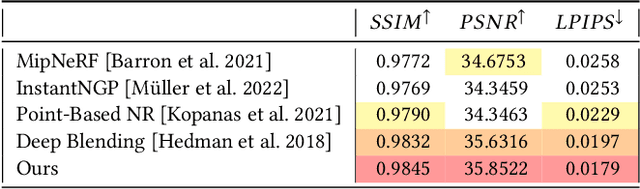

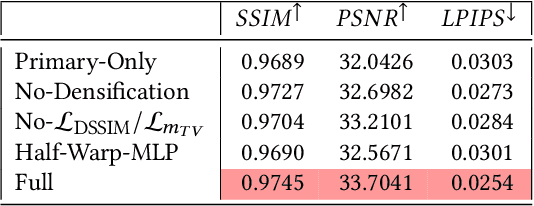
View-dependent effects such as reflections pose a substantial challenge for image-based and neural rendering algorithms. Above all, curved reflectors are particularly hard, as they lead to highly non-linear reflection flows as the camera moves. We introduce a new point-based representation to compute Neural Point Catacaustics allowing novel-view synthesis of scenes with curved reflectors, from a set of casually-captured input photos. At the core of our method is a neural warp field that models catacaustic trajectories of reflections, so complex specular effects can be rendered using efficient point splatting in conjunction with a neural renderer. One of our key contributions is the explicit representation of reflections with a reflection point cloud which is displaced by the neural warp field, and a primary point cloud which is optimized to represent the rest of the scene. After a short manual annotation step, our approach allows interactive high-quality renderings of novel views with accurate reflection flow. Additionally, the explicit representation of reflection flow supports several forms of scene manipulation in captured scenes, such as reflection editing, cloning of specular objects, reflection tracking across views, and comfortable stereo viewing. We provide the source code and other supplemental material on https://repo-sam.inria.fr/ fungraph/neural_catacaustics/
* SIGGRAPH Asia 2022 (ToG) https://repo-sam.inria.fr/fungraph/neural_catacaustics/
Explaining Deepfake Detection by Analysing Image Matching
Jul 20, 2022
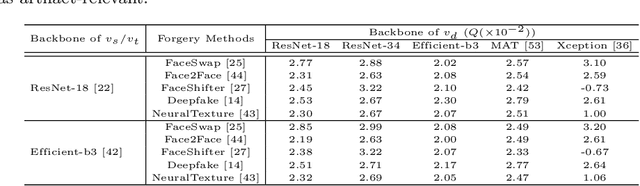
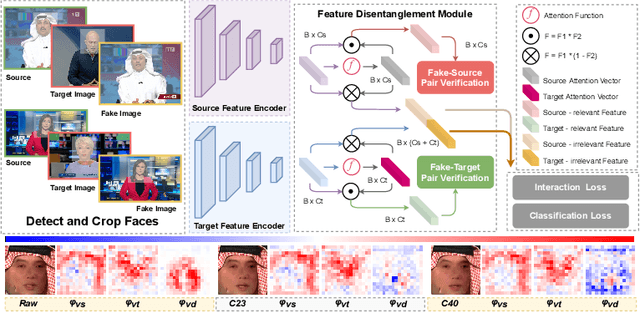
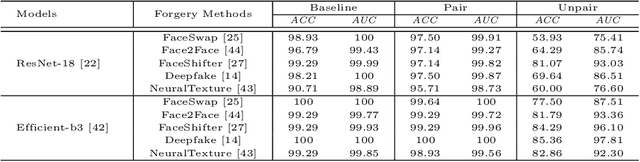
This paper aims to interpret how deepfake detection models learn artifact features of images when just supervised by binary labels. To this end, three hypotheses from the perspective of image matching are proposed as follows. 1. Deepfake detection models indicate real/fake images based on visual concepts that are neither source-relevant nor target-relevant, that is, considering such visual concepts as artifact-relevant. 2. Besides the supervision of binary labels, deepfake detection models implicitly learn artifact-relevant visual concepts through the FST-Matching (i.e. the matching fake, source, target images) in the training set. 3. Implicitly learned artifact visual concepts through the FST-Matching in the raw training set are vulnerable to video compression. In experiments, the above hypotheses are verified among various DNNs. Furthermore, based on this understanding, we propose the FST-Matching Deepfake Detection Model to boost the performance of forgery detection on compressed videos. Experiment results show that our method achieves great performance, especially on highly-compressed (e.g. c40) videos.
Situational Perception Guided Image Matting
Apr 21, 2022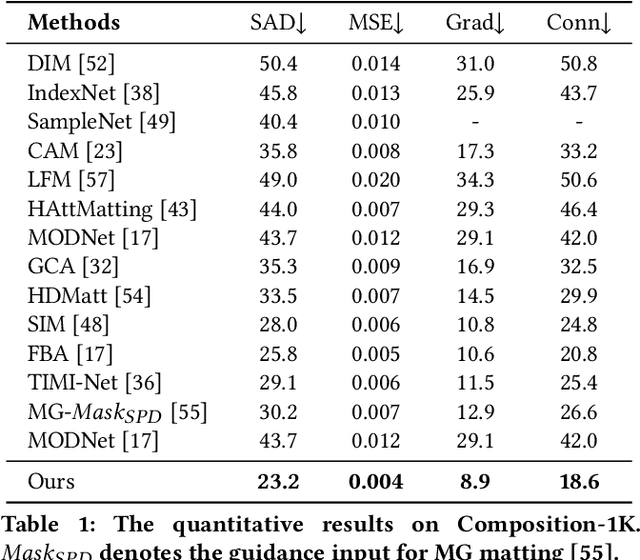
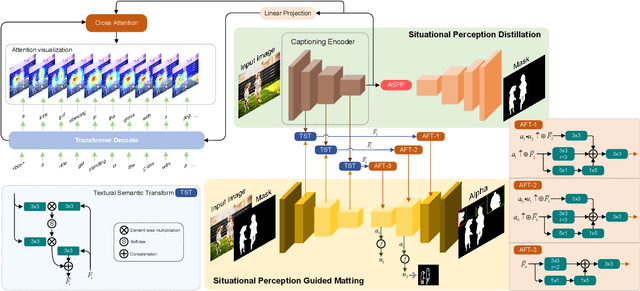
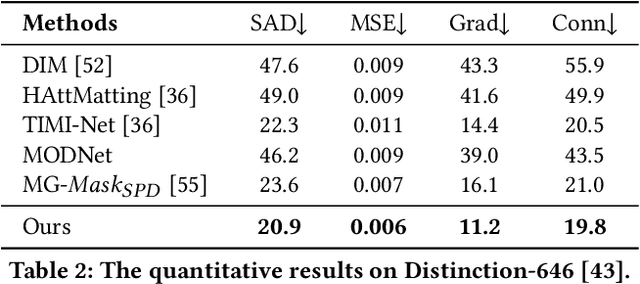
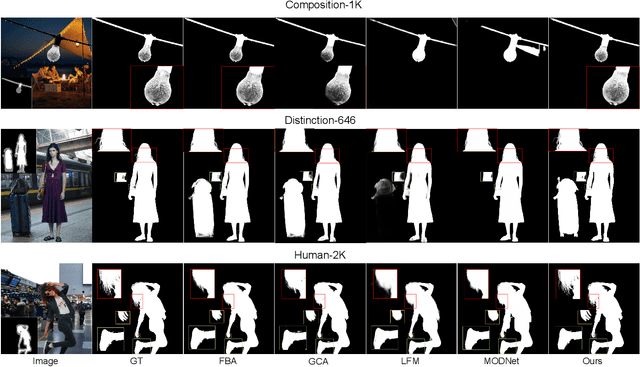
Most automatic matting methods try to separate the salient foreground from the background. However, the insufficient quantity and subjective bias of the current existing matting datasets make it difficult to fully explore the semantic association between object-to-object and object-to-environment in a given image. In this paper, we propose a Situational Perception Guided Image Matting (SPG-IM) method that mitigates subjective bias of matting annotations and captures sufficient situational perception information for better global saliency distilled from the visual-to-textual task. SPG-IM can better associate inter-objects and object-to-environment saliency, and compensate the subjective nature of image matting and its expensive annotation. We also introduce a textual Semantic Transformation (TST) module that can effectively transform and integrate the semantic feature stream to guide the visual representations. In addition, an Adaptive Focal Transformation (AFT) Refinement Network is proposed to adaptively switch multi-scale receptive fields and focal points to enhance both global and local details. Extensive experiments demonstrate the effectiveness of situational perception guidance from the visual-to-textual tasks on image matting, and our model outperforms the state-of-the-art methods. We also analyze the significance of different components in our model. The code will be released soon.
Weakly Supervised Joint Whole-Slide Segmentation and Classification in Prostate Cancer
Jan 07, 2023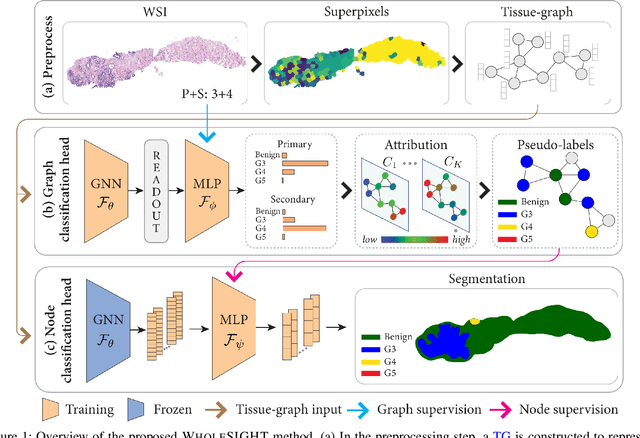
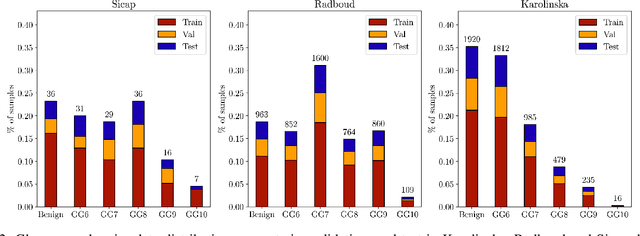
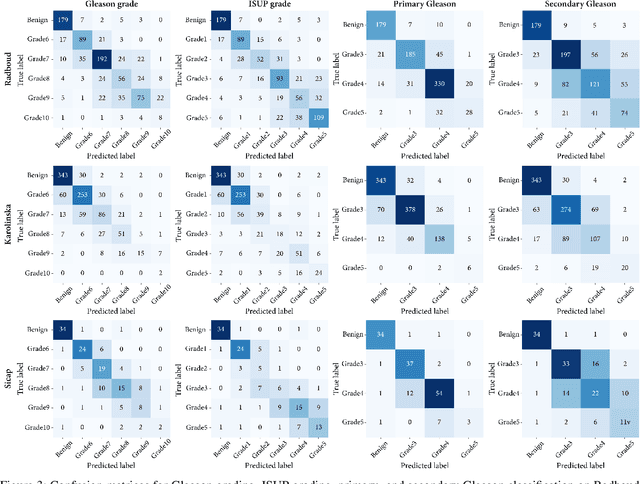
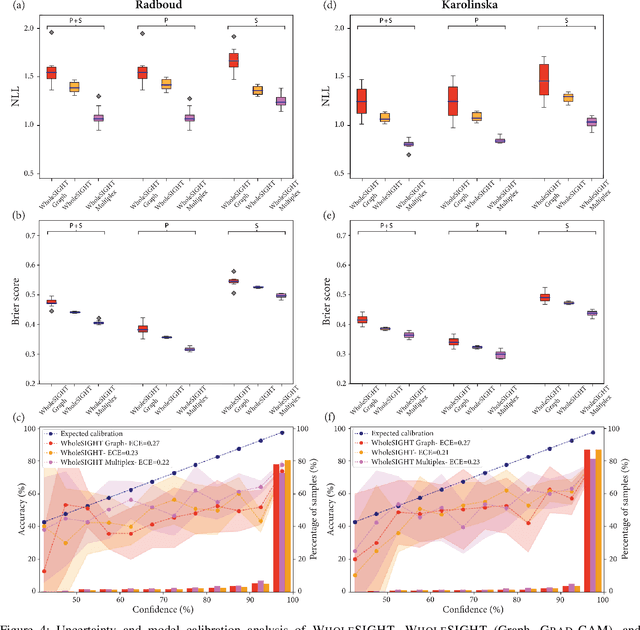
The segmentation and automatic identification of histological regions of diagnostic interest offer a valuable aid to pathologists. However, segmentation methods are hampered by the difficulty of obtaining pixel-level annotations, which are tedious and expensive to obtain for Whole-Slide images (WSI). To remedy this, weakly supervised methods have been developed to exploit the annotations directly available at the image level. However, to our knowledge, none of these techniques is adapted to deal with WSIs. In this paper, we propose WholeSIGHT, a weakly-supervised method, to simultaneously segment and classify WSIs of arbitrary shapes and sizes. Formally, WholeSIGHT first constructs a tissue-graph representation of the WSI, where the nodes and edges depict tissue regions and their interactions, respectively. During training, a graph classification head classifies the WSI and produces node-level pseudo labels via post-hoc feature attribution. These pseudo labels are then used to train a node classification head for WSI segmentation. During testing, both heads simultaneously render class prediction and segmentation for an input WSI. We evaluated WholeSIGHT on three public prostate cancer WSI datasets. Our method achieved state-of-the-art weakly-supervised segmentation performance on all datasets while resulting in better or comparable classification with respect to state-of-the-art weakly-supervised WSI classification methods. Additionally, we quantify the generalization capability of our method in terms of segmentation and classification performance, uncertainty estimation, and model calibration.
Advanced Data Augmentation Approaches: A Comprehensive Survey and Future directions
Jan 07, 2023
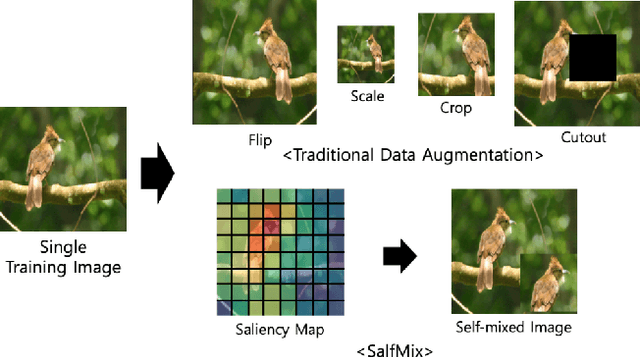


Deep learning (DL) algorithms have shown significant performance in various computer vision tasks. However, having limited labelled data lead to a network overfitting problem, where network performance is bad on unseen data as compared to training data. Consequently, it limits performance improvement. To cope with this problem, various techniques have been proposed such as dropout, normalization and advanced data augmentation. Among these, data augmentation, which aims to enlarge the dataset size by including sample diversity, has been a hot topic in recent times. In this article, we focus on advanced data augmentation techniques. we provide a background of data augmentation, a novel and comprehensive taxonomy of reviewed data augmentation techniques, and the strengths and weaknesses (wherever possible) of each technique. We also provide comprehensive results of the data augmentation effect on three popular computer vision tasks, such as image classification, object detection and semantic segmentation. For results reproducibility, we compiled available codes of all data augmentation techniques. Finally, we discuss the challenges and difficulties, and possible future direction for the research community. We believe, this survey provides several benefits i) readers will understand the data augmentation working mechanism to fix overfitting problems ii) results will save the searching time of the researcher for comparison purposes. iii) Codes of the mentioned data augmentation techniques are available at https://github.com/kmr2017/Advanced-Data-augmentation-codes iv) Future work will spark interest in research community.
TPFNet: A Novel Text In-painting Transformer for Text Removal
Oct 27, 2022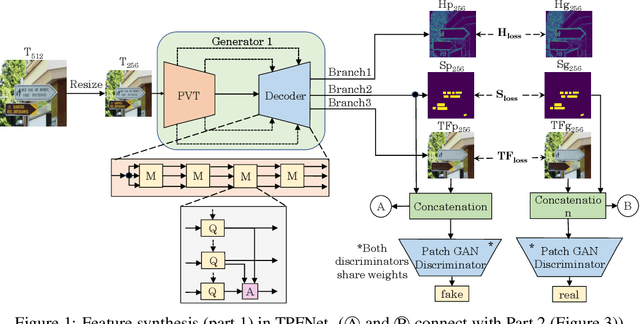
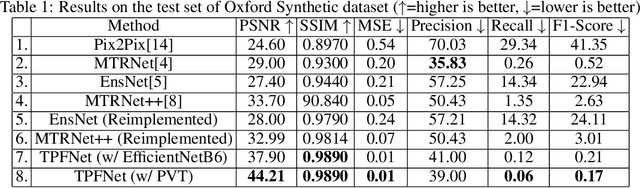
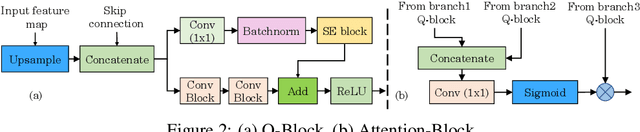
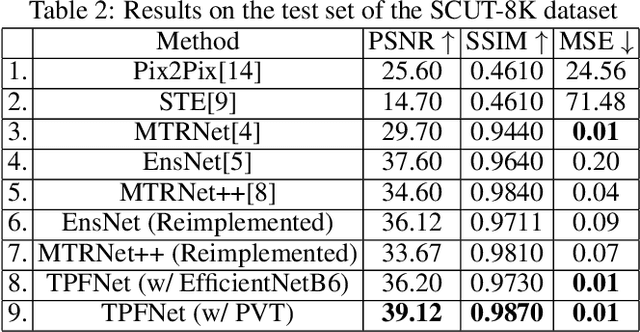
Text erasure from an image is helpful for various tasks such as image editing and privacy preservation. In this paper, we present TPFNet, a novel one-stage (end-toend) network for text removal from images. Our network has two parts: feature synthesis and image generation. Since noise can be more effectively removed from low-resolution images, part 1 operates on low-resolution images. The output of part 1 is a low-resolution text-free image. Part 2 uses the features learned in part 1 to predict a high-resolution text-free image. In part 1, we use "pyramidal vision transformer" (PVT) as the encoder. Further, we use a novel multi-headed decoder that generates a high-pass filtered image and a segmentation map, in addition to a text-free image. The segmentation branch helps locate the text precisely, and the high-pass branch helps in learning the image structure. To precisely locate the text, TPFNet employs an adversarial loss that is conditional on the segmentation map rather than the input image. On Oxford, SCUT, and SCUT-EnsText datasets, our network outperforms recently proposed networks on nearly all the metrics. For example, on SCUT-EnsText dataset, TPFNet has a PSNR (higher is better) of 39.0 and text-detection precision (lower is better) of 21.1, compared to the best previous technique, which has a PSNR of 32.3 and precision of 53.2. The source code can be obtained from https://github.com/CandleLabAI/TPFNet
Improved Cross-view Completion Pre-training for Stereo Matching
Nov 18, 2022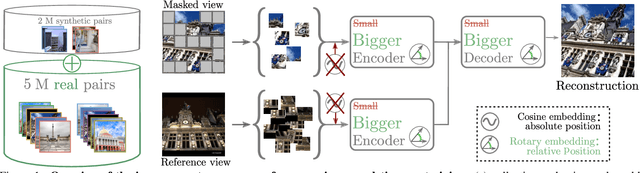



Despite impressive performance for high-level downstream tasks, self-supervised pre-training methods have not yet fully delivered on dense geometric vision tasks such as stereo matching. The application of self-supervised learning concepts, such as instance discrimination or masked image modeling, to geometric tasks is an active area of research. In this work we build on the recent cross-view completion framework: this variation of masked image modeling leverages a second view from the same scene, which is well suited for binocular downstream tasks. However, the applicability of this concept has so far been limited in at least two ways: (a) by the difficulty of collecting real-world image pairs - in practice only synthetic data had been used - and (b) by the lack of generalization of vanilla transformers to dense downstream tasks for which relative position is more meaningful than absolute position. We explore three avenues of improvement: first, we introduce a method to collect suitable real-world image pairs at large scale. Second, we experiment with relative positional embeddings and demonstrate that they enable vision transformers to perform substantially better. Third, we scale up vision transformer based cross-completion architectures, which is made possible by the use of large amounts of data. With these improvements, we show for the first time that state-of-the-art results on deep stereo matching can be reached without using any standard task-specific techniques like correlation volume, iterative estimation or multi-scale reasoning.
High-level semantic feature matters few-shot unsupervised domain adaptation
Jan 05, 2023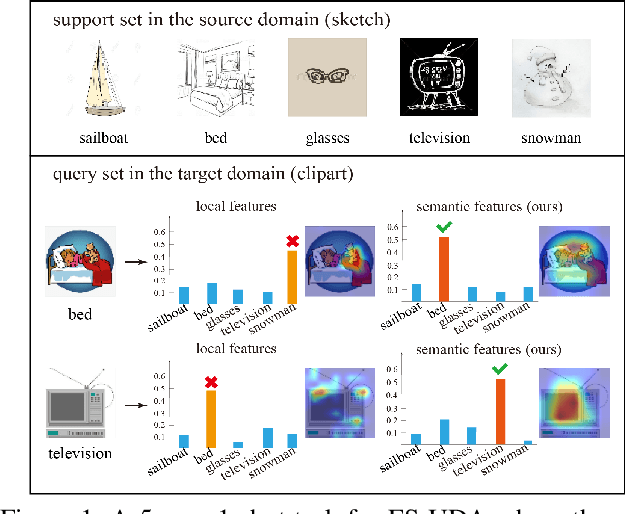
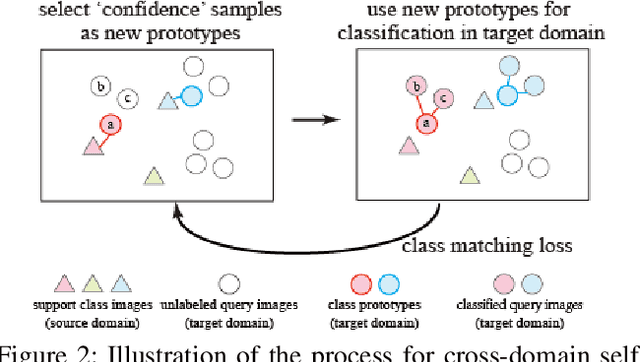
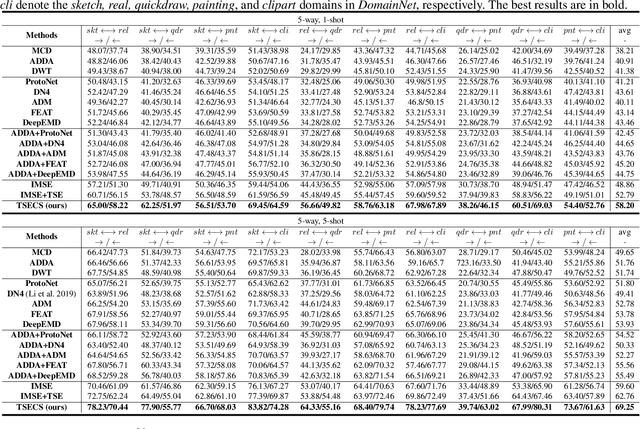
In few-shot unsupervised domain adaptation (FS-UDA), most existing methods followed the few-shot learning (FSL) methods to leverage the low-level local features (learned from conventional convolutional models, e.g., ResNet) for classification. However, the goal of FS-UDA and FSL are relevant yet distinct, since FS-UDA aims to classify the samples in target domain rather than source domain. We found that the local features are insufficient to FS-UDA, which could introduce noise or bias against classification, and not be used to effectively align the domains. To address the above issues, we aim to refine the local features to be more discriminative and relevant to classification. Thus, we propose a novel task-specific semantic feature learning method (TSECS) for FS-UDA. TSECS learns high-level semantic features for image-to-class similarity measurement. Based on the high-level features, we design a cross-domain self-training strategy to leverage the few labeled samples in source domain to build the classifier in target domain. In addition, we minimize the KL divergence of the high-level feature distributions between source and target domains to shorten the distance of the samples between the two domains. Extensive experiments on DomainNet show that the proposed method significantly outperforms SOTA methods in FS-UDA by a large margin (i.e., 10%).
PCCT: Progressive Class-Center Triplet Loss for Imbalanced Medical Image Classification
Jul 11, 2022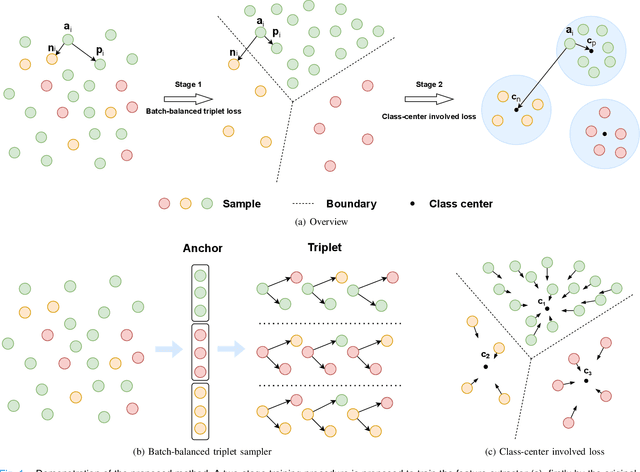
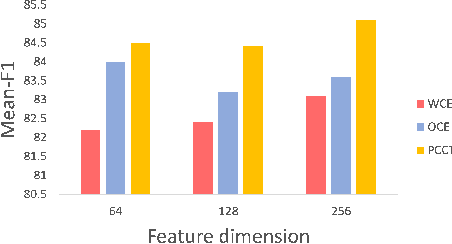

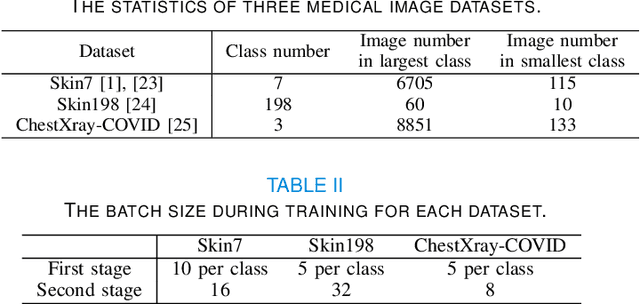
Imbalanced training data is a significant challenge for medical image classification. In this study, we propose a novel Progressive Class-Center Triplet (PCCT) framework to alleviate the class imbalance issue particularly for diagnosis of rare diseases, mainly by carefully designing the triplet sampling strategy and the triplet loss formation. Specifically, the PCCT framework includes two successive stages. In the first stage, PCCT trains the diagnosis system via a class-balanced triplet loss to coarsely separate distributions of different classes. In the second stage, the PCCT framework further improves the diagnosis system via a class-center involved triplet loss to cause a more compact distribution for each class. For the class-balanced triplet loss, triplets are sampled equally for each class at each training iteration, thus alleviating the imbalanced data issue. For the class-center involved triplet loss, the positive and negative samples in each triplet are replaced by their corresponding class centers, which enforces data representations of the same class closer to the class center. Furthermore, the class-center involved triplet loss is extended to the pair-wise ranking loss and the quadruplet loss, which demonstrates the generalization of the proposed framework. Extensive experiments support that the PCCT framework works effectively for medical image classification with imbalanced training images. On two skin image datasets and one chest X-ray dataset, the proposed approach respectively obtains the mean F1 score 86.2, 65.2, and 90.66 over all classes and 81.4, 63.87, and 81.92 for rare classes, achieving state-of-the-art performance and outperforming the widely used methods for the class imbalance issue.
The Swiss Army Knife for Image-to-Image Translation: Multi-Task Diffusion Models
Apr 06, 2022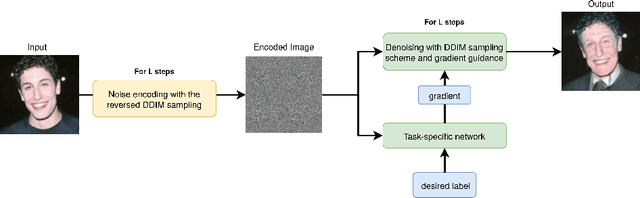



Recently, diffusion models were applied to a wide range of image analysis tasks. We build on a method for image-to-image translation using denoising diffusion implicit models and include a regression problem and a segmentation problem for guiding the image generation to the desired output. The main advantage of our approach is that the guidance during the denoising process is done by an external gradient. Consequently, the diffusion model does not need to be retrained for the different tasks on the same dataset. We apply our method to simulate the aging process on facial photos using a regression task, as well as on a brain magnetic resonance (MR) imaging dataset for the simulation of brain tumor growth. Furthermore, we use a segmentation model to inpaint tumors at the desired location in healthy slices of brain MR images. We achieve convincing results for all problems.