 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UNAEN: Unsupervised Abnomality Extraction Network for MRI Motion Artifact Reduction
Jan 04, 2023
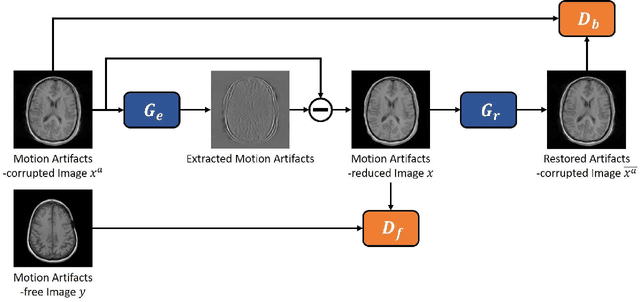
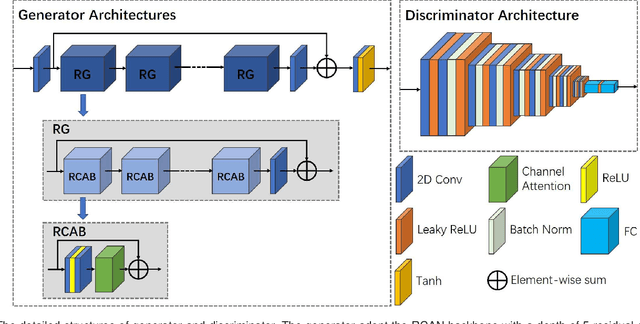
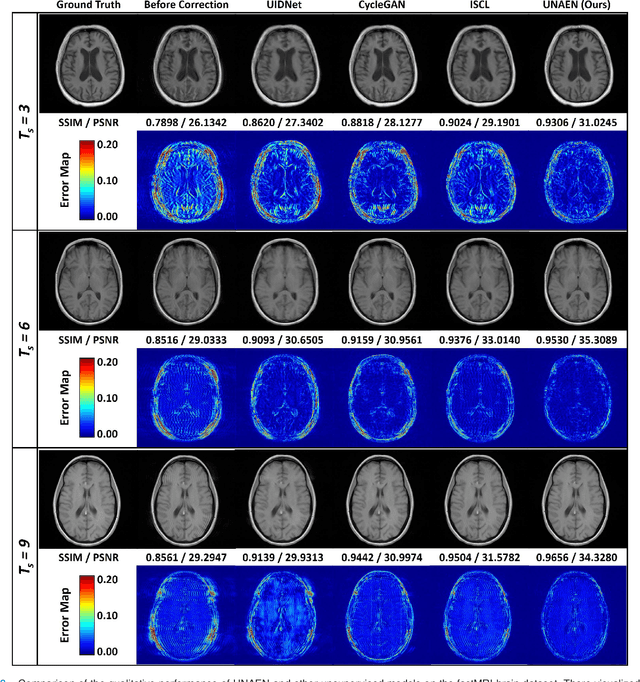
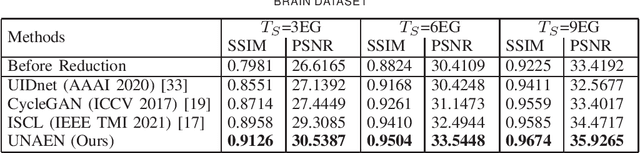
Motion artifact reduction is one of the most concerned problems in magnetic resonance imaging. As a promising solution, deep learning-based methods have been widely investigated for artifact reduction tasks in MRI. As a retrospective processing method, neural network does not cost additional acquisition time or require new acquisition equipment, and seems to work better than traditional artifact reduction methods. In the previous study, training such models require the paired motion-corrupted and motion-free MR images. However, it is extremely tough or even impossible to obtain these images in reality because patients have difficulty in maintaining the same state during two image acquisition, which makes the training in a supervised manner impractical. In this work, we proposed a new unsupervised abnomality extraction network (UNAEN) to alleviate this problem. Our network realizes the transition from artifact domain to motion-free domain by processing the abnormal information introduced by artifact in unpaired MR images. Different from directly generating artifact reduction results from motion-corrupted MR images, we adopted the strategy of abnomality extraction to indirectly correct the impact of artifact in MR images by learning the deep features. Experimental results show that our method is superior to state-of-the-art networks and can potentially be applied in real clinical settings.
Visual Programming: Compositional visual reasoning without training
Nov 18, 2022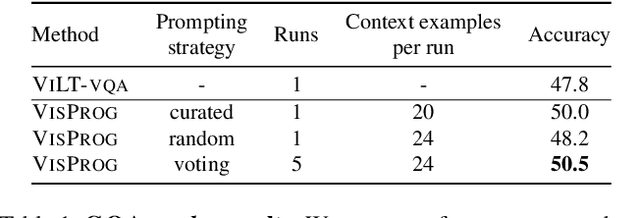
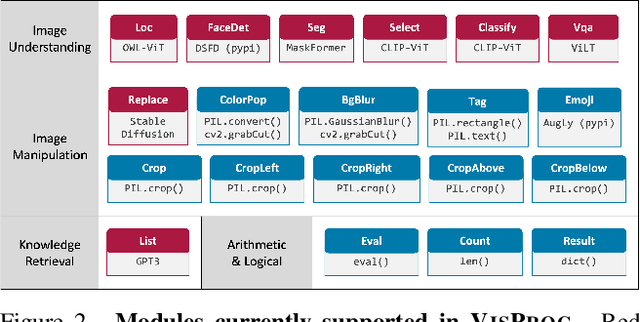

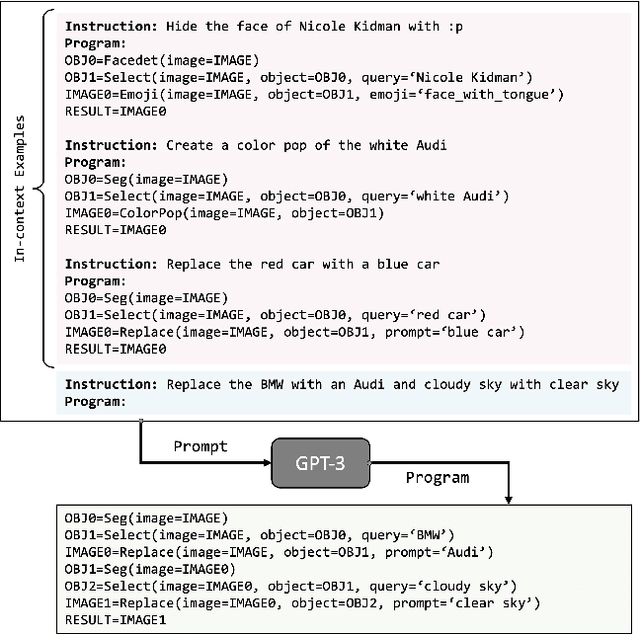
We present VISPROG, a neuro-symbolic approach to solving complex and compositional visual tasks given natural language instructions. VISPROG avoids the need for any task-specific training. Instead, it uses the in-context learning ability of large language models to generate python-like modular programs, which are then executed to get both the solution and a comprehensive and interpretable rationale. Each line of the generated program may invoke one of several off-the-shelf computer vision models, image processing routines, or python functions to produce intermediate outputs that may be consumed by subsequent parts of the program. We demonstrate the flexibility of VISPROG on 4 diverse tasks - compositional visual question answering, zero-shot reasoning on image pairs, factual knowledge object tagging, and language-guided image editing. We believe neuro-symbolic approaches like VISPROG are an exciting avenue to easily and effectively expand the scope of AI systems to serve the long tail of complex tasks that people may wish to perform.
The Fully Convolutional Transformer for Medical Image Segmentation
Jun 01, 2022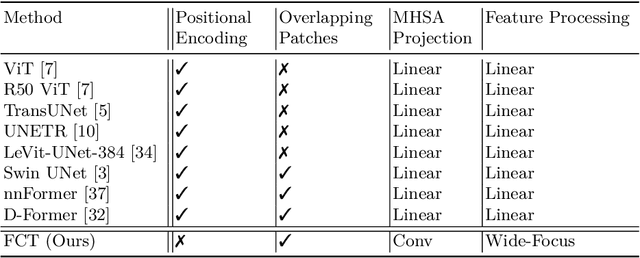
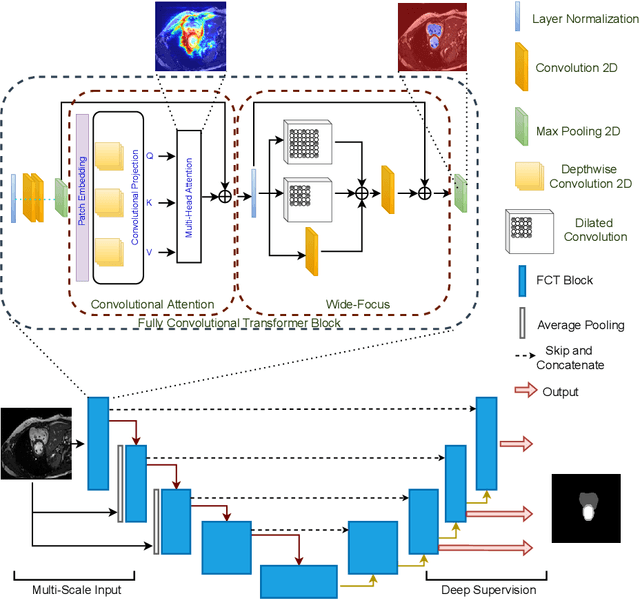
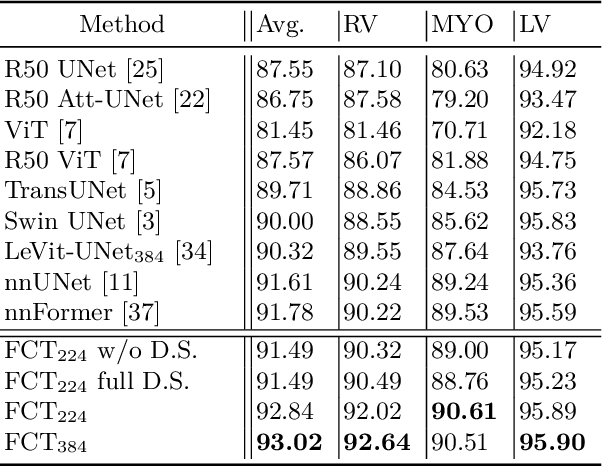
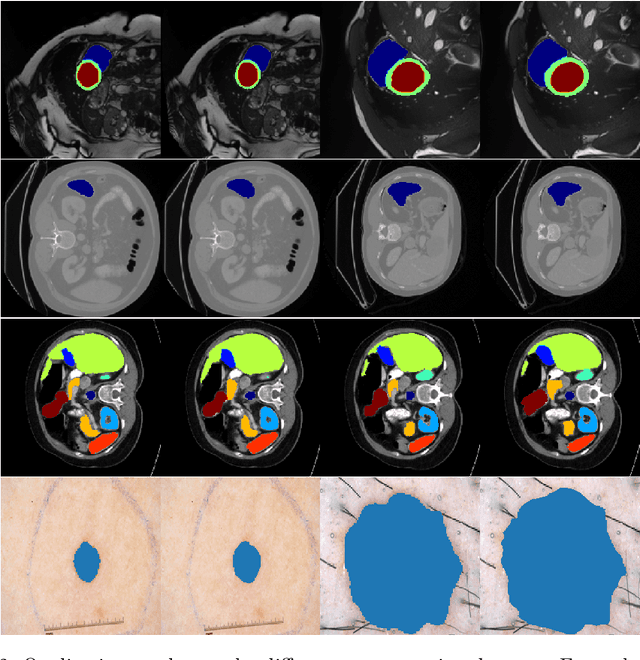
We propose a novel transformer model, capable of segmenting medical images of varying modalities. Challenges posed by the fine grained nature of medical image analysis mean that the adaptation of the transformer for their analysis is still at nascent stages. The overwhelming success of the UNet lay in its ability to appreciate the fine-grained nature of the segmentation task, an ability which existing transformer based models do not currently posses. To address this shortcoming, we propose The Fully Convolutional Transformer (FCT), which builds on the proven ability of Convolutional Neural Networks to learn effective image representations, and combines them with the ability of Transformers to effectively capture long-term dependencies in its inputs. The FCT is the first fully convolutional Transformer model in medical imaging literature. It processes its input in two stages, where first, it learns to extract long range semantic dependencies from the input image, and then learns to capture hierarchical global attributes from the features. FCT is compact, accurate and robust. Our results show that it outperforms all existing transformer architectures by large margins across multiple medical image segmentation datasets of varying data modalities without the need for any pre-training. FCT outperforms its immediate competitor on the ACDC dataset by 1.3%, on the Synapse dataset by 4.4%, on the Spleen dataset by 1.2% and on ISIC 2017 dataset by 1.1% on the dice metric, with up to five times fewer parameters. Our code, environments and models will be available via GitHub.
Object Delineation in Satellite Images
Dec 14, 2022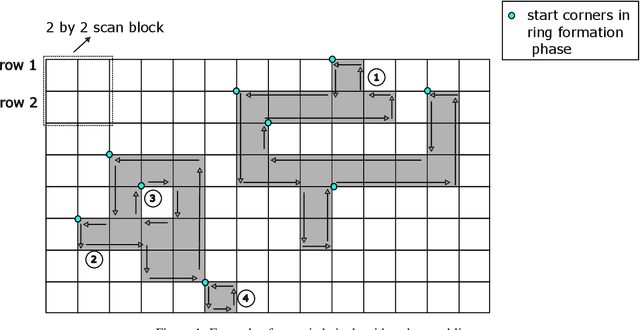
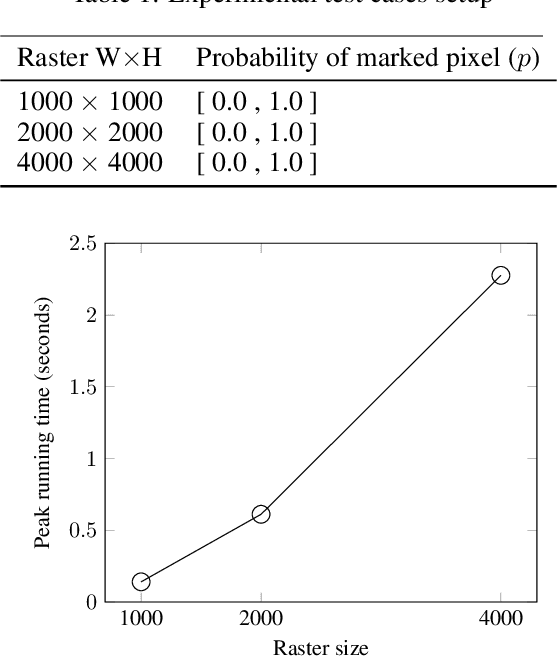
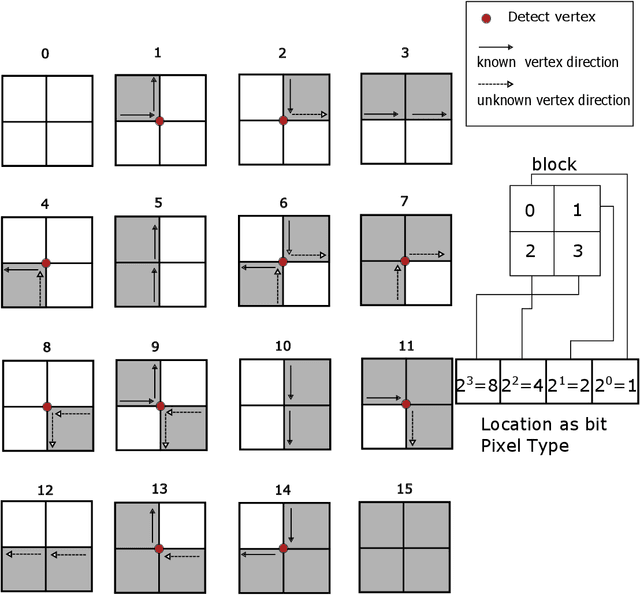
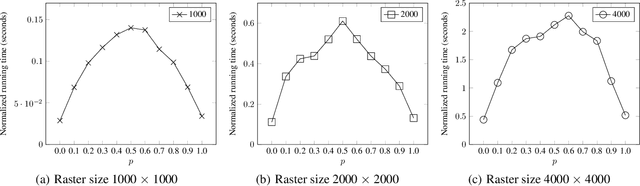
Machine learning is being widely applied to analyze satellite data with problems such as classification and feature detection. Unlike traditional image processing algorithms, geospatial applications need to convert the detected objects from a raster form to a geospatial vector form to further analyze it. This gem delivers a simple and light-weight algorithm for delineating the pixels that are marked by ML algorithms to extract geospatial objects from satellite images. The proposed algorithm is exact and users can further apply simplification and approximation based on the application needs.
Non-uniform Sampling Strategies for NeRF on 360{\textdegree} images
Dec 07, 2022
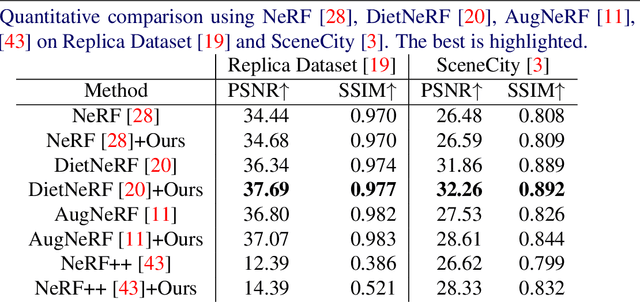
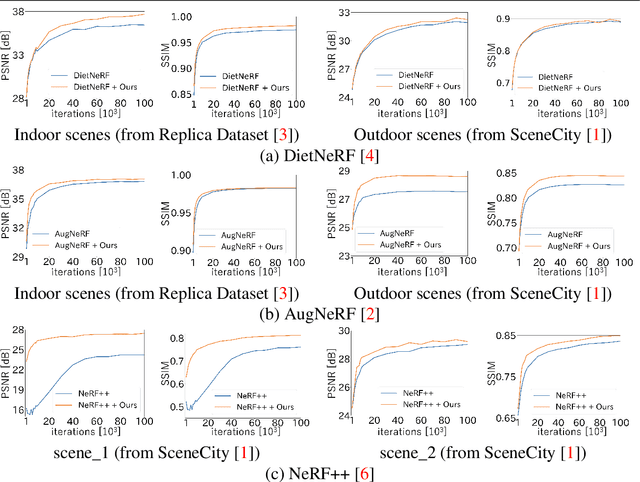

In recent years, the performance of novel view synthesis using perspective images has dramatically improved with the advent of neural radiance fields (NeRF). This study proposes two novel techniques that effectively build NeRF for 360{\textdegree} omnidirectional images. Due to the characteristics of a 360{\textdegree} image of ERP format that has spatial distortion in their high latitude regions and a 360{\textdegree} wide viewing angle, NeRF's general ray sampling strategy is ineffective. Hence, the view synthesis accuracy of NeRF is limited and learning is not efficient. We propose two non-uniform ray sampling schemes for NeRF to suit 360{\textdegree} images - distortion-aware ray sampling and content-aware ray sampling. We created an evaluation dataset Synth360 using Replica and SceneCity models of indoor and outdoor scenes, respectively. In experiments, we show that our proposal successfully builds 360{\textdegree} image NeRF in terms of both accuracy and efficiency. The proposal is widely applicable to advanced variants of NeRF. DietNeRF, AugNeRF, and NeRF++ combined with the proposed techniques further improve the performance. Moreover, we show that our proposed method enhances the quality of real-world scenes in 360{\textdegree} images. Synth360: https://drive.google.com/drive/folders/1suL9B7DO2no21ggiIHkH3JF3OecasQLb.
VeriX: Towards Verified Explainability of Deep Neural Networks
Dec 06, 2022
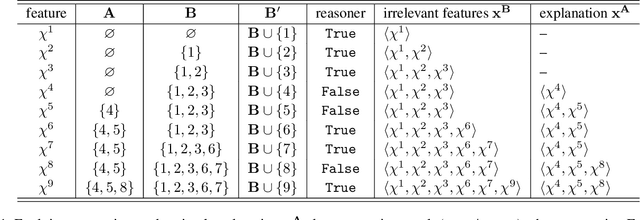
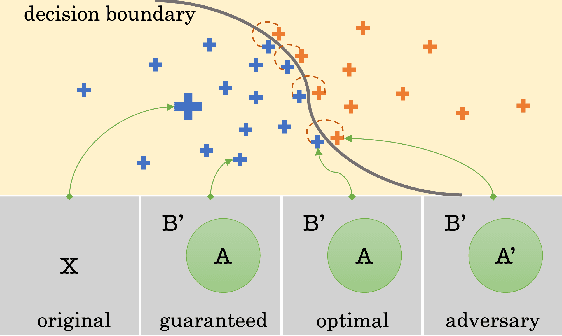
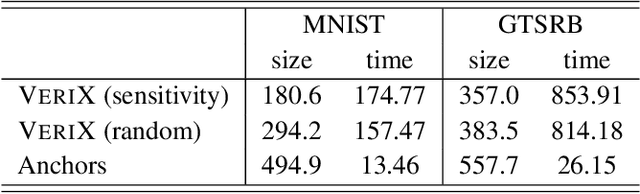
We present VeriX, a first step towards verified explainability of machine learning models in safety-critical applications. Specifically, our sound and optimal explanations can guarantee prediction invariance against bounded perturbations. We utilise constraint solving techniques together with feature sensitivity ranking to efficiently compute these explanations. We evaluate our approach on image recognition benchmarks and a real-world scenario of autonomous aircraft taxiing.
Situational Perception Guided Image Matting
Apr 22, 2022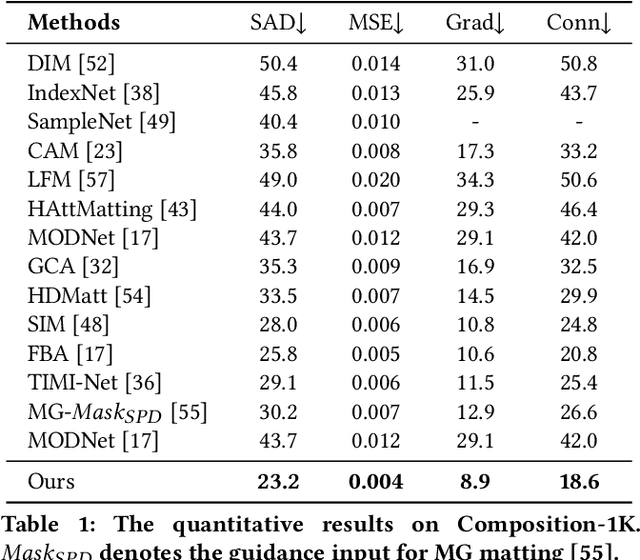
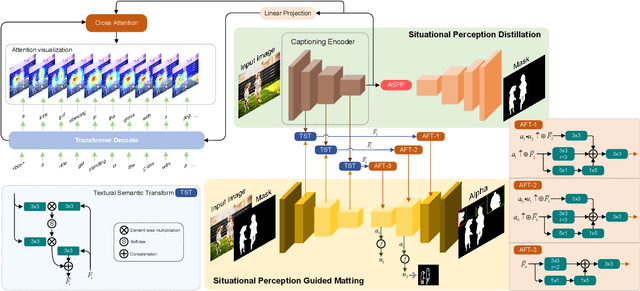
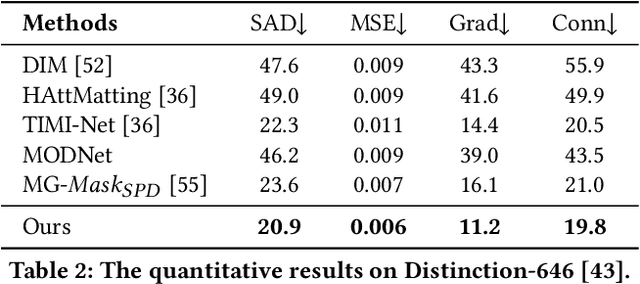
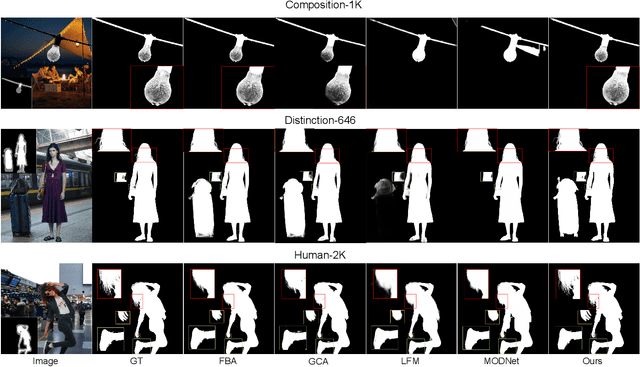
Most automatic matting methods try to separate the salient foreground from the background. However, the insufficient quantity and subjective bias of the current existing matting datasets make it difficult to fully explore the semantic association between object-to-object and object-to-environment in a given image. In this paper, we propose a Situational Perception Guided Image Matting (SPG-IM) method that mitigates subjective bias of matting annotations and captures sufficient situational perception information for better global saliency distilled from the visual-to-textual task. SPG-IM can better associate inter-objects and object-to-environment saliency, and compensate the subjective nature of image matting and its expensive annotation. We also introduce a textual Semantic Transformation (TST) module that can effectively transform and integrate the semantic feature stream to guide the visual representations. In addition, an Adaptive Focal Transformation (AFT) Refinement Network is proposed to adaptively switch multi-scale receptive fields and focal points to enhance both global and local details. Extensive experiments demonstrate the effectiveness of situational perception guidance from the visual-to-textual tasks on image matting, and our model outperforms the state-of-the-art methods. We also analyze the significance of different components in our model. The code will be released soon.
One Size Fits All: Hypernetwork for Tunable Image Restoration
Jun 13, 2022
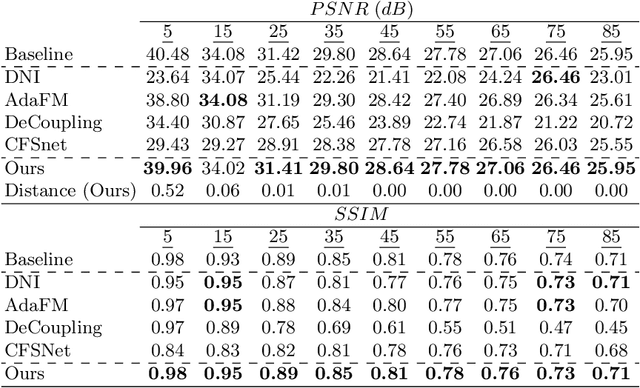
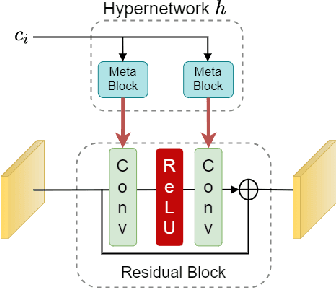

We introduce a novel approach for tunable image restoration that achieves the accuracy of multiple models, each optimized for a different level of degradation, with exactly the same number of parameters as a single model. Our model can be optimized to restore as many degradation levels as required with a constant number of parameters and for various image restoration tasks. Experiments on real-world datasets show that our approach achieves state-of-the art results in denoising, DeJPEG and super-resolution with respect to existing tunable models, allowing smoother and more accurate fitting over a wider range of degradation levels.
BEVDistill: Cross-Modal BEV Distillation for Multi-View 3D Object Detection
Nov 17, 2022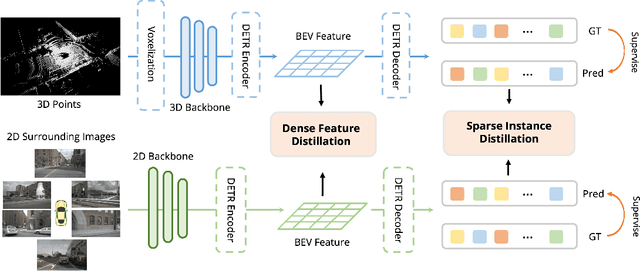
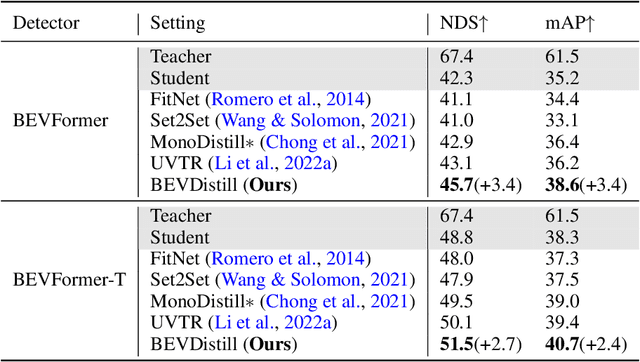
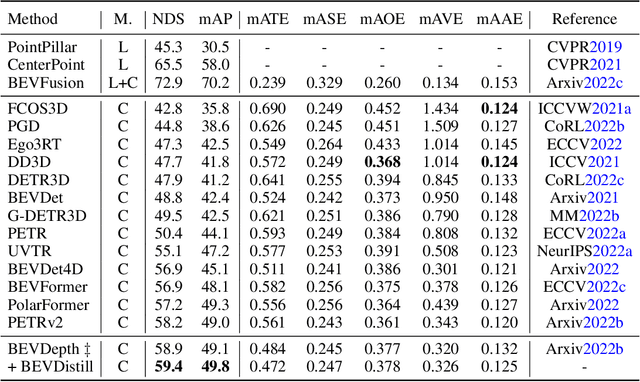

3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Owing to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views is extremely difficult due to the lack of depth information. Current approaches tend to adopt heavy backbones for image encoders, making them inapplicable for real-world deployment. Different from the images, LiDAR points are superior in providing spatial cues, resulting in highly precise localization. In this paper, we explore the incorporation of LiDAR-based detectors for multi-view 3D object detection. Instead of directly training a depth prediction network, we unify the image and LiDAR features in the Bird-Eye-View (BEV) space and adaptively transfer knowledge across non-homogenous representations in a teacher-student paradigm. To this end, we propose \textbf{BEVDistill}, a cross-modal BEV knowledge distillation (KD) framework for multi-view 3D object detection. Extensive experiments demonstrate that the proposed method outperforms current KD approaches on a highly-competitive baseline, BEVFormer, without introducing any extra cost in the inference phase. Notably, our best model achieves 59.4 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various image-based detectors. Code will be available at https://github.com/zehuichen123/BEVDistill.
Deep transfer learning for image classification: a survey
May 20, 2022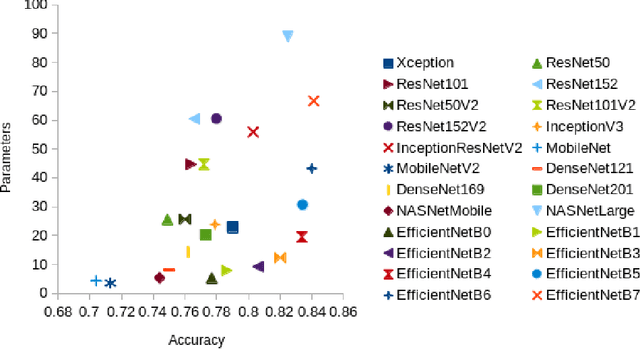

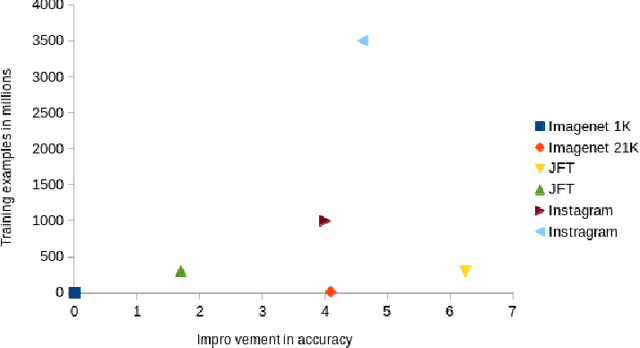
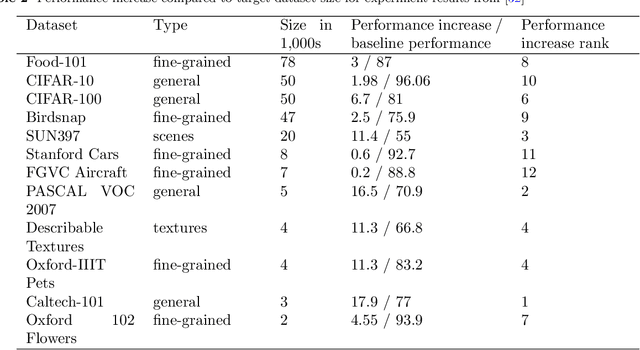
Deep neural networks such as convolutional neural networks (CNNs) and transformers have achieved many successes in image classification in recent years. It has been consistently demonstrated that best practice for image classification is when large deep models can be trained on abundant labelled data. However there are many real world scenarios where the requirement for large amounts of training data to get the best performance cannot be met. In these scenarios transfer learning can help improve performance. To date there have been no surveys that comprehensively review deep transfer learning as it relates to image classification overall. However, several recent general surveys of deep transfer learning and ones that relate to particular specialised target image classification tasks have been published. We believe it is important for the future progress in the field that all current knowledge is collated and the overarching patterns analysed and discussed. In this survey we formally define deep transfer learning and the problem it attempts to solve in relation to image classification. We survey the current state of the field and identify where recent progress has been made. We show where the gaps in current knowledge are and make suggestions for how to progress the field to fill in these knowledge gaps. We present a new taxonomy of the applications of transfer learning for image classification. This taxonomy makes it easier to see overarching patterns of where transfer learning has been effective and, where it has failed to fulfill its potential. This also allows us to suggest where the problems lie and how it could be used more effectively. We show that under this new taxonomy, many of the applications where transfer learning has been shown to be ineffective or even hinder performance are to be expected when taking into account the source and target datasets and the techniques used.