 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DisCoScene: Spatially Disentangled Generative Radiance Fields for Controllable 3D-aware Scene Synthesis
Dec 22, 2022
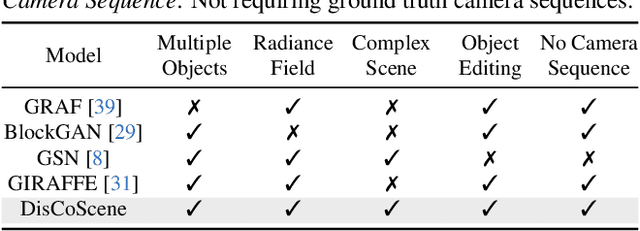
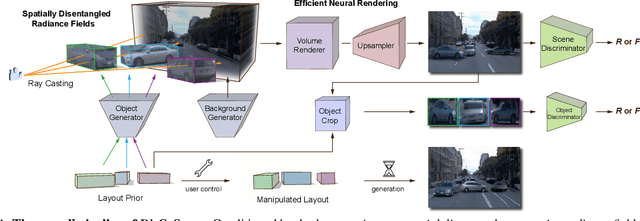

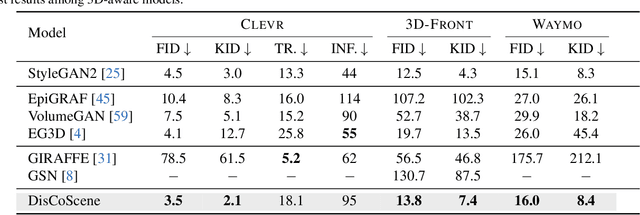
Existing 3D-aware image synthesis approaches mainly focus on generating a single canonical object and show limited capacity in composing a complex scene containing a variety of objects. This work presents DisCoScene: a 3Daware generative model for high-quality and controllable scene synthesis. The key ingredient of our method is a very abstract object-level representation (i.e., 3D bounding boxes without semantic annotation) as the scene layout prior, which is simple to obtain, general to describe various scene contents, and yet informative to disentangle objects and background. Moreover, it serves as an intuitive user control for scene editing. Based on such a prior, the proposed model spatially disentangles the whole scene into object-centric generative radiance fields by learning on only 2D images with the global-local discrimination. Our model obtains the generation fidelity and editing flexibility of individual objects while being able to efficiently compose objects and the background into a complete scene. We demonstrate state-of-the-art performance on many scene datasets, including the challenging Waymo outdoor dataset. Project page: https://snap-research.github.io/discoscene/
Coded Illumination for 3D Lensless Imaging
Dec 22, 2022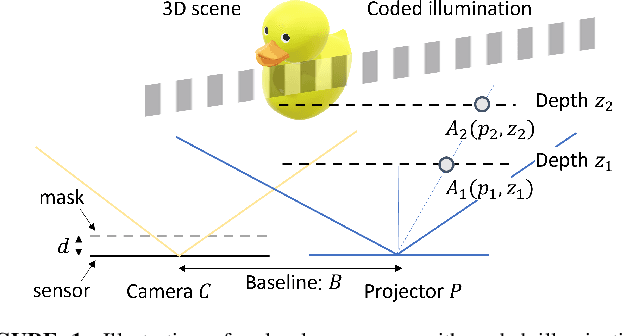
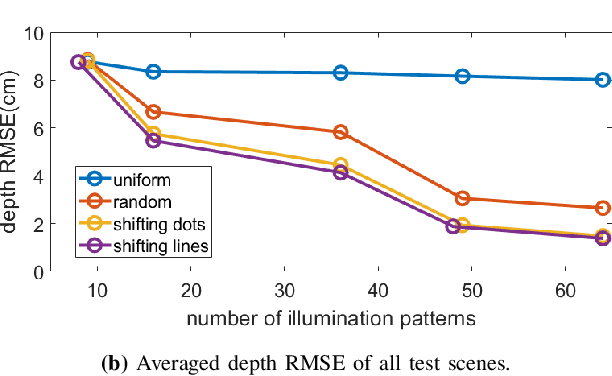
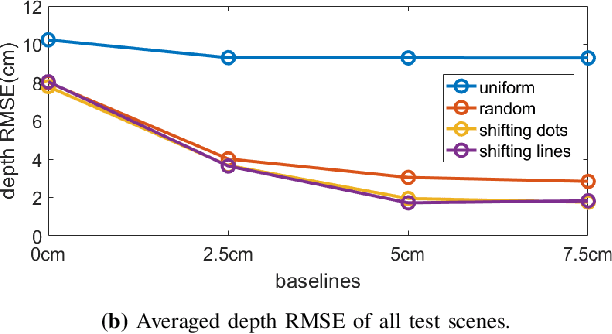
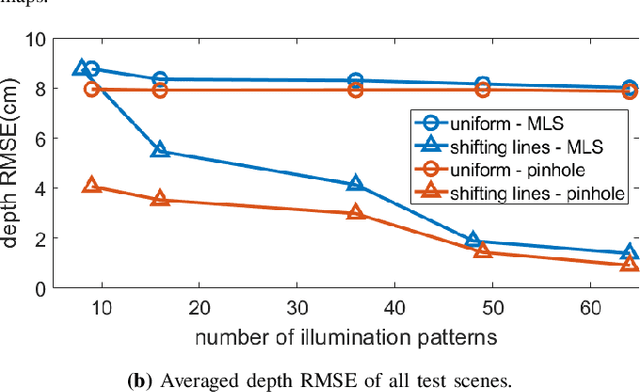
Mask-based lensless cameras offer a novel design for imaging systems by replacing the lens in a conventional camera with a layer of coded mask. Each pixel of the lensless camera encodes the information of the entire 3D scene. Existing methods for 3D reconstruction from lensless measurements suffer from poor spatial and depth resolution. This is partially due to the system ill conditioning that arises because the point-spread functions (PSFs) from different depth planes are very similar. In this paper, we propose to capture multiple measurements of the scene under a sequence of coded illumination patterns to improve the 3D image reconstruction quality. In addition, we put the illumination source at a distance away from the camera. With such baseline distance between the lensless camera and illumination source, the camera observes a slice of the 3D volume, and the PSF of each depth plane becomes more resolvable from each other. We present simulation results along with experimental results with a camera prototype to demonstrate the effectiveness of our approach.
Learn2Trust: A video and streamlit-based educational programme for AI-based medical image analysis targeted towards medical students
Aug 15, 2022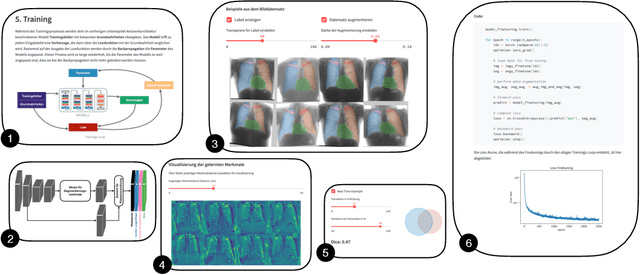
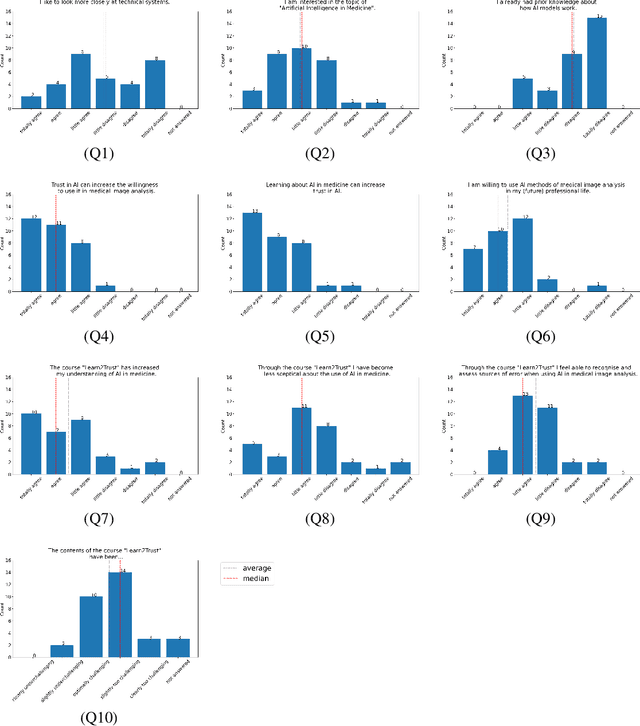
In order to be able to use artificial intelligence (AI) in medicine without scepticism and to recognise and assess its growing potential, a basic understanding of this topic is necessary among current and future medical staff. Under the premise of "trust through understanding", we developed an innovative online course as a learning opportunity within the framework of the German KI Campus (AI campus) project, which is a self-guided course that teaches the basics of AI for the analysis of medical image data. The main goal is to provide a learning environment for a sufficient understanding of AI in medical image analysis so that further interest in this topic is stimulated and inhibitions towards its use can be overcome by means of positive application experience. The focus was on medical applications and the fundamentals of machine learning. The online course was divided into consecutive lessons, which include theory in the form of explanatory videos, practical exercises in the form of Streamlit and practical exercises and/or quizzes to check learning progress. A survey among the participating medical students in the first run of the course was used to analyse our research hypotheses quantitatively.
Rethinking Two Consensuses of the Transferability in Deep Learning
Dec 01, 2022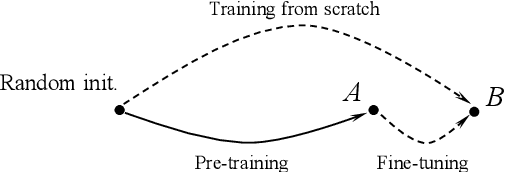
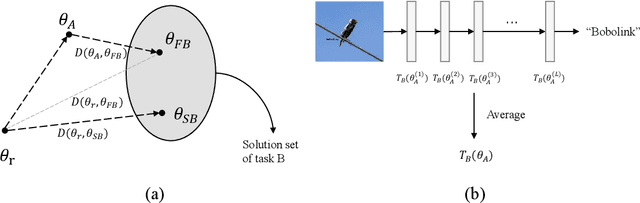

Deep transfer learning (DTL) has formed a long-term quest toward enabling deep neural networks (DNNs) to reuse historical experiences as efficiently as humans. This ability is named knowledge transferability. A commonly used paradigm for DTL is firstly learning general knowledge (pre-training) and then reusing (fine-tuning) them for a specific target task. There are two consensuses of transferability of pre-trained DNNs: (1) a larger domain gap between pre-training and downstream data brings lower transferability; (2) the transferability gradually decreases from lower layers (near input) to higher layers (near output). However, these consensuses were basically drawn from the experiments based on natural images, which limits their scope of application. This work aims to study and complement them from a broader perspective by proposing a method to measure the transferability of pre-trained DNN parameters. Our experiments on twelve diverse image classification datasets get similar conclusions to the previous consensuses. More importantly, two new findings are presented, i.e., (1) in addition to the domain gap, a larger data amount and huge dataset diversity of downstream target task also prohibit the transferability; (2) although the lower layers learn basic image features, they are usually not the most transferable layers due to their domain sensitivity.
Explaining Image Enhancement Black-Box Methods through a Path Planning Based Algorithm
Jul 14, 2022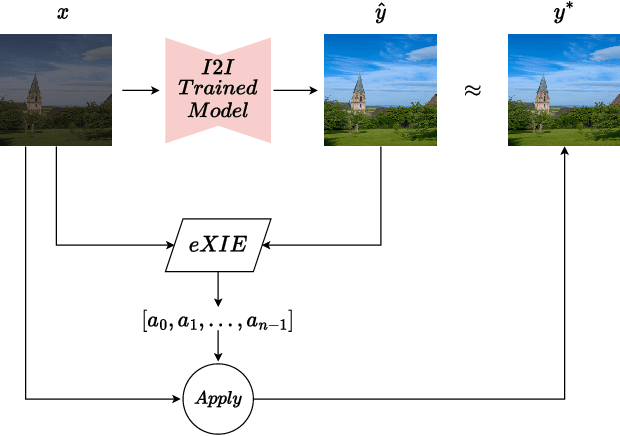
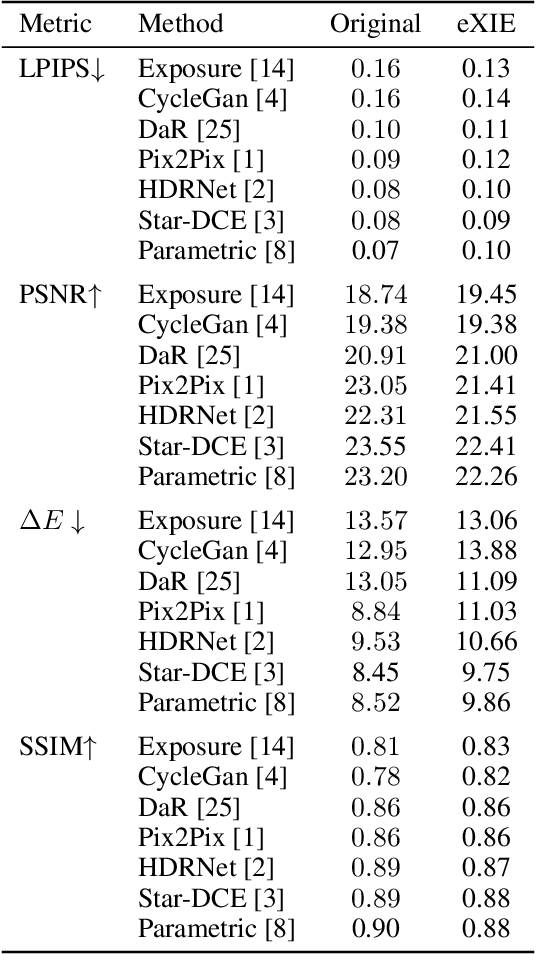
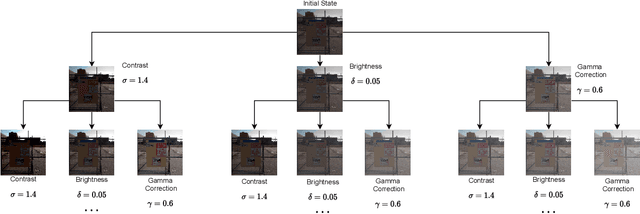
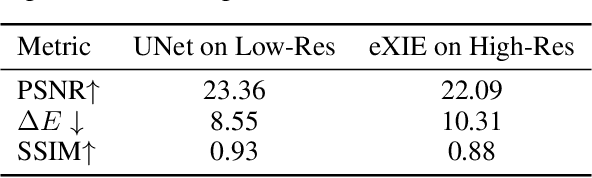
Nowadays, image-to-image translation methods, are the state of the art for the enhancement of natural images. Even if they usually show high performance in terms of accuracy, they often suffer from several limitations such as the generation of artifacts and the scalability to high resolutions. Moreover, their main drawback is the completely black-box approach that does not allow to provide the final user with any insight about the enhancement processes applied. In this paper we present a path planning algorithm which provides a step-by-step explanation of the output produced by state of the art enhancement methods, overcoming black-box limitation. This algorithm, called eXIE, uses a variant of the A* algorithm to emulate the enhancement process of another method through the application of an equivalent sequence of enhancing operators. We applied eXIE to explain the output of several state-of-the-art models trained on the Five-K dataset, obtaining sequences of enhancing operators able to produce very similar results in terms of performance and overcoming the huge limitation of poor interpretability of the best performing algorithms.
StyleTRF: Stylizing Tensorial Radiance Fields
Dec 19, 2022
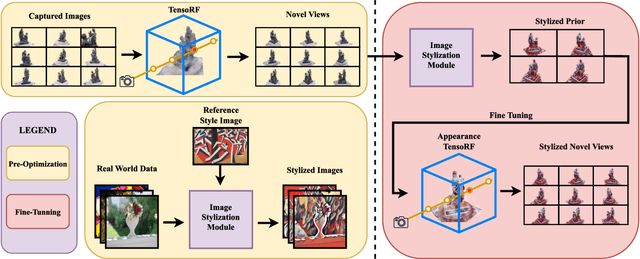
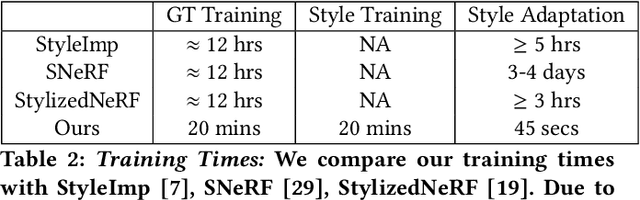

Stylized view generation of scenes captured casually using a camera has received much attention recently. The geometry and appearance of the scene are typically captured as neural point sets or neural radiance fields in the previous work. An image stylization method is used to stylize the captured appearance by training its network jointly or iteratively with the structure capture network. The state-of-the-art SNeRF method trains the NeRF and stylization network in an alternating manner. These methods have high training time and require joint optimization. In this work, we present StyleTRF, a compact, quick-to-optimize strategy for stylized view generation using TensoRF. The appearance part is fine-tuned using sparse stylized priors of a few views rendered using the TensoRF representation for a few iterations. Our method thus effectively decouples style-adaption from view capture and is much faster than the previous methods. We show state-of-the-art results on several scenes used for this purpose.
GAN2X: Non-Lambertian Inverse Rendering of Image GANs
Jun 18, 2022

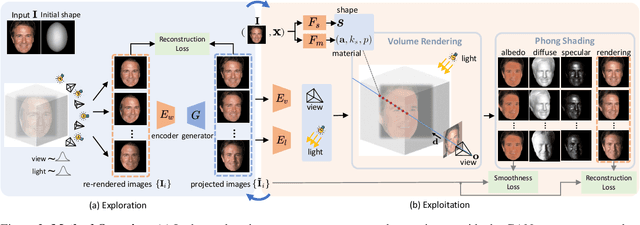

2D images are observations of the 3D physical world depicted with the geometry, material, and illumination components. Recovering these underlying intrinsic components from 2D images, also known as inverse rendering, usually requires a supervised setting with paired images collected from multiple viewpoints and lighting conditions, which is resource-demanding. In this work, we present GAN2X, a new method for unsupervised inverse rendering that only uses unpaired images for training. Unlike previous Shape-from-GAN approaches that mainly focus on 3D shapes, we take the first attempt to also recover non-Lambertian material properties by exploiting the pseudo paired data generated by a GAN. To achieve precise inverse rendering, we devise a specularity-aware neural surface representation that continuously models the geometry and material properties. A shading-based refinement technique is adopted to further distill information in the target image and recover more fine details. Experiments demonstrate that GAN2X can accurately decompose 2D images to 3D shape, albedo, and specular properties for different object categories, and achieves the state-of-the-art performance for unsupervised single-view 3D face reconstruction. We also show its applications in downstream tasks including real image editing and lifting 2D GANs to decomposed 3D GANs.
Cascade Luminance and Chrominance for Image Retouching: More Like Artist
May 31, 2022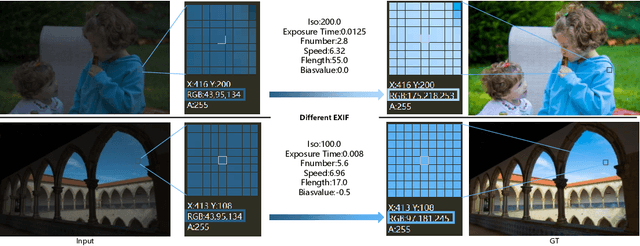

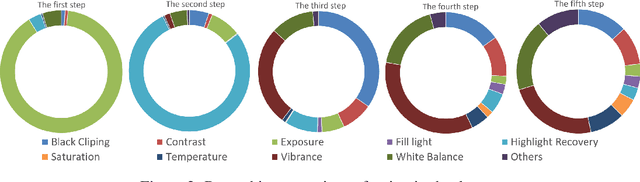
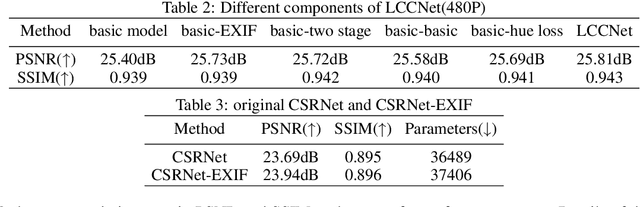
Photo retouching aims to adjust the luminance, contrast, and saturation of the image to make it more human aesthetically desirable. However, artists' actions in photo retouching are difficult to quantitatively analyze. By investigating their retouching behaviors, we propose a two-stage network that brightens images first and then enriches them in the chrominance plane. Six pieces of useful information from image EXIF are picked as the network's condition input. Additionally, hue palette loss is added to make the image more vibrant. Based on the above three aspects, Luminance-Chrominance Cascading Net(LCCNet) makes the machine learning problem of mimicking artists in photo retouching more reasonable. Experiments show that our method is effective on the benchmark MIT-Adobe FiveK dataset, and achieves state-of-the-art performance for both quantitative and qualitative evaluation.
R2FD2: Fast and Robust Matching of Multimodal Remote Sensing Image via Repeatable Feature Detector and Rotation-invariant Feature Descriptor
Dec 06, 2022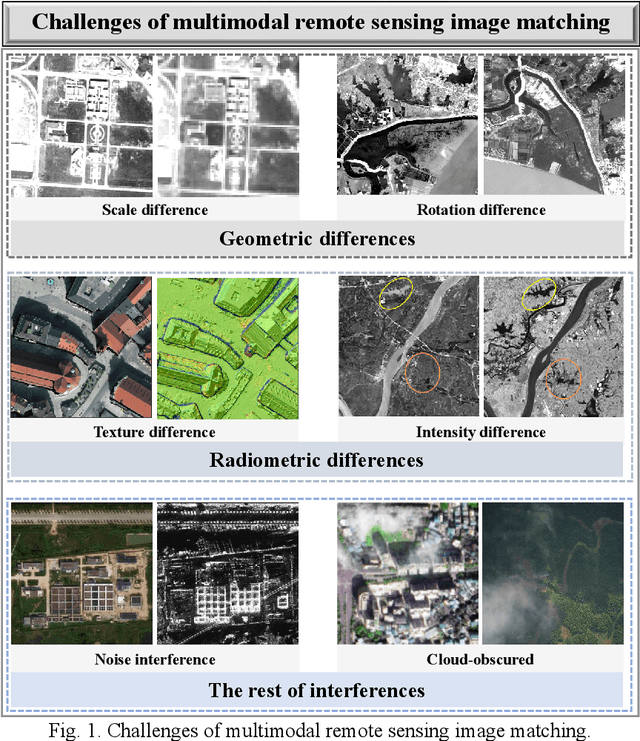

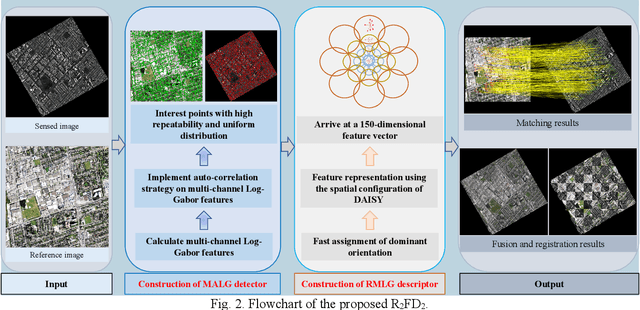
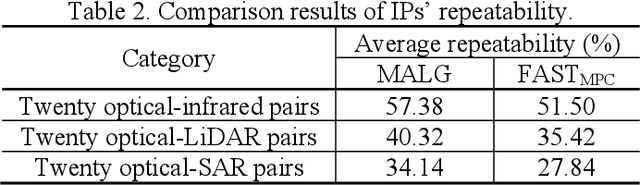
Automatically identifying feature correspondences between multimodal images is facing enormous challenges because of the significant differences both in radiation and geometry. To address these problems, we propose a novel feature matching method (named R2FD2) that is robust to radiation and rotation differences. Our R2FD2 is conducted in two critical contributions, consisting of a repeatable feature detector and a rotation-invariant feature descriptor. In the first stage, a repeatable feature detector called the Multi-channel Auto-correlation of the Log-Gabor (MALG) is presented for feature detection, which combines the multi-channel auto-correlation strategy with the Log-Gabor wavelets to detect interest points (IPs) with high repeatability and uniform distribution. In the second stage, a rotation-invariant feature descriptor is constructed, named the Rotation-invariant Maximum index map of the Log-Gabor (RMLG), which consists of two components: fast assignment of dominant orientation and construction of feature representation. In the process of fast assignment of dominant orientation, a Rotation-invariant Maximum Index Map (RMIM) is built to address rotation deformations. Then, the proposed RMLG incorporates the rotation-invariant RMIM with the spatial configuration of DAISY to depict a more discriminative feature representation, which improves RMLG's resistance to radiation and rotation variances.Experimental results show that the proposed R2FD2 outperforms five state-of-the-art feature matching methods, and has superior advantages in adaptability and universality. Moreover, our R2FD2 achieves the accuracy of matching within two pixels and has a great advantage in matching efficiency over other state-of-the-art methods.
SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting with Neural Radiance Fields
Nov 22, 2022
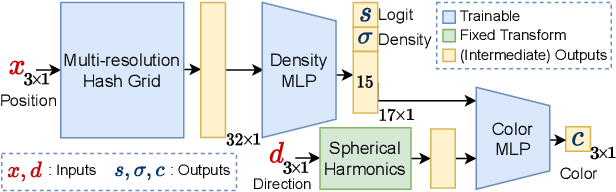
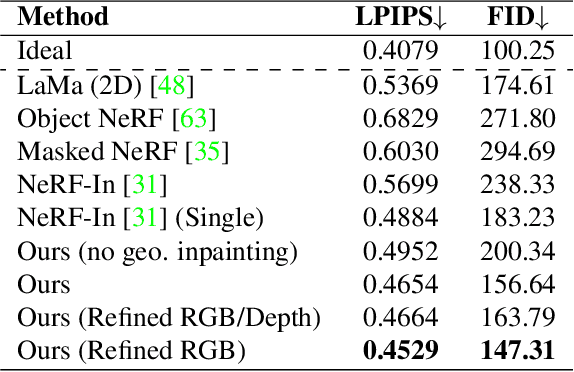
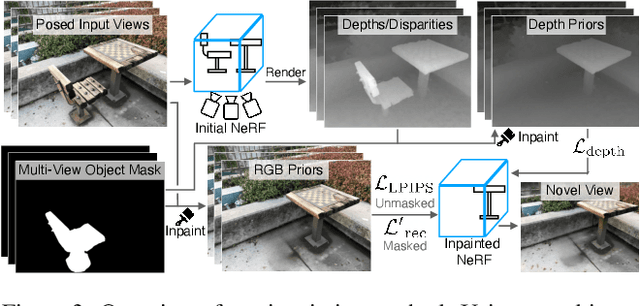
Neural Radiance Fields (NeRFs) have emerged as a popular approach for novel view synthesis. While NeRFs are quickly being adapted for a wider set of applications, intuitively editing NeRF scenes is still an open challenge. One important editing task is the removal of unwanted objects from a 3D scene, such that the replaced region is visually plausible and consistent with its context. We refer to this task as 3D inpainting. In 3D, solutions must be both consistent across multiple views and geometrically valid. In this paper, we propose a novel 3D inpainting method that addresses these challenges. Given a small set of posed images and sparse annotations in a single input image, our framework first rapidly obtains a 3D segmentation mask for a target object. Using the mask, a perceptual optimizationbased approach is then introduced that leverages learned 2D image inpainters, distilling their information into 3D space, while ensuring view consistency. We also address the lack of a diverse benchmark for evaluating 3D scene inpainting methods by introducing a dataset comprised of challenging real-world scenes. In particular, our dataset contains views of the same scene with and without a target object, enabling more principled benchmarking of the 3D inpainting task. We first demonstrate the superiority of our approach on multiview segmentation, comparing to NeRFbased methods and 2D segmentation approaches. We then evaluate on the task of 3D inpainting, establishing state-ofthe-art performance against other NeRF manipulation algorithms, as well as a strong 2D image inpainter baseline