 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models
Dec 12, 2022
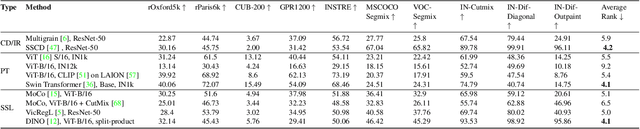


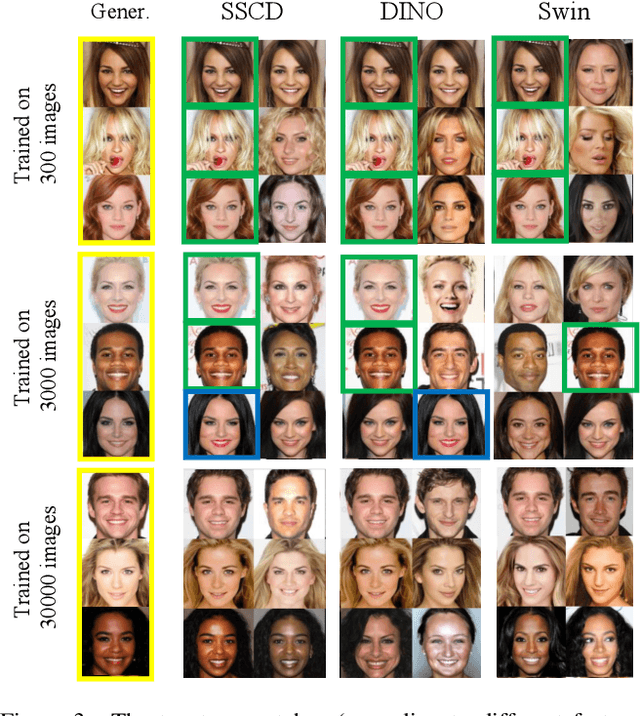
Cutting-edge diffusion models produce images with high quality and customizability, enabling them to be used for commercial art and graphic design purposes. But do diffusion models create unique works of art, or are they replicating content directly from their training sets? In this work, we study image retrieval frameworks that enable us to compare generated images with training samples and detect when content has been replicated. Applying our frameworks to diffusion models trained on multiple datasets including Oxford flowers, Celeb-A, ImageNet, and LAION, we discuss how factors such as training set size impact rates of content replication. We also identify cases where diffusion models, including the popular Stable Diffusion model, blatantly copy from their training data.
Adaptive De-noising of Photoacoustic Signal and Image based on Modified Kalman Filter
Nov 18, 2022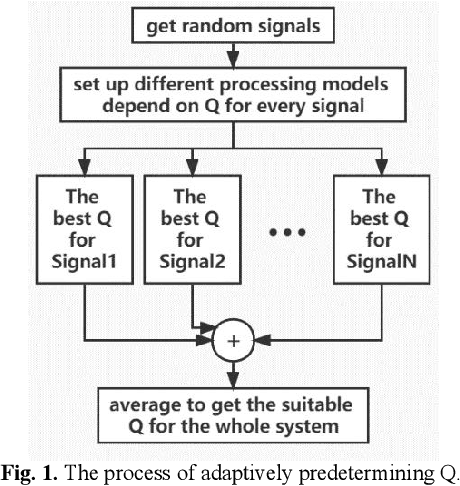
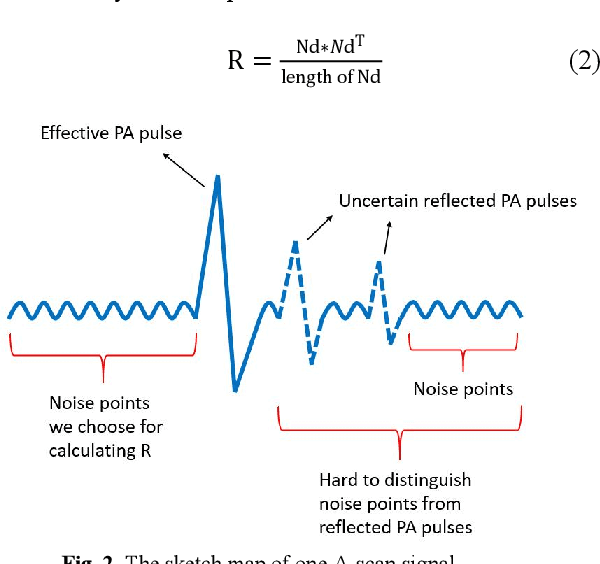
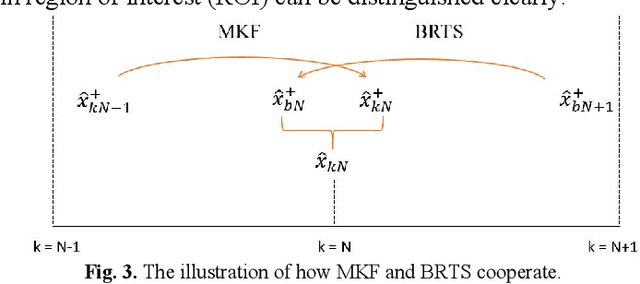
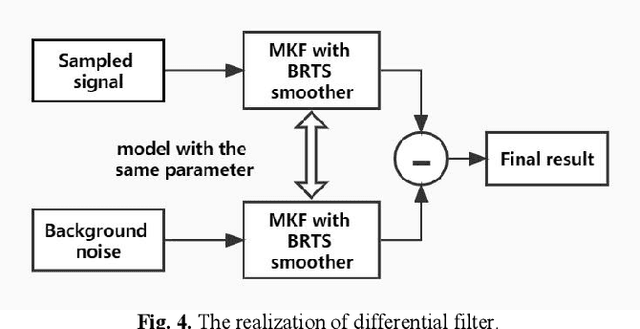
As a burgeoning medical imaging method based on hybrid fusion of light and ultrasound, photoacoustic imaging (PAI) has demonstrated high potential in various biomedical applications recently, especially in revealing the functional and molecular information to improve diagnostic accuracy. However, stemming from weak amplitude and unavoidable random noise, caused by limited laser power and severe attenuation in deep tissue imaging, PA signals are usually of low signal-to-noise ratio (SNR), and reconstructed PA images are of low quality. Despite that conventional Kalman Filter (KF) can remove Gaussian noise in time domain, it lacks adaptability in real-time estimating condition due to its fixed model. Moreover, KF-based de-noising algorithm has not been applied in PAI before. In this paper, we propose an adaptive Modified Kalman Filter (MKF) targeted at PAI de-noising by tuning system noise matrix Q and measurement noise matrix R in the conventional KF model. Additionally, in order to compensate the signal skewing caused by KF, we cascade the backward part of Rauch-Tung-Striebel smoother (BRTS), which also utilizes the newly determined Q. Finally, as a supplement, we add a commonly used differential filter to remove in-band reflection artifacts. Experimental results using phantom and ex vivo colorectal tissue are provided to prove the validity of the algorithm.
Semantic-aware Message Broadcasting for Efficient Unsupervised Domain Adaptation
Dec 06, 2022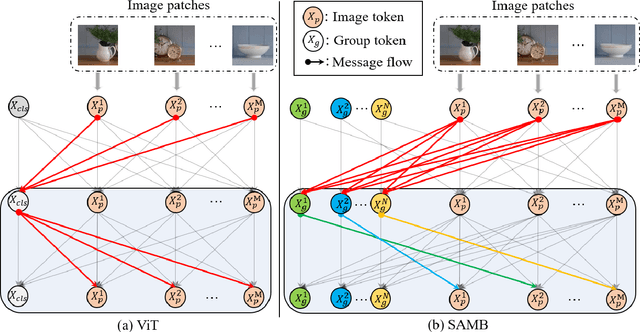
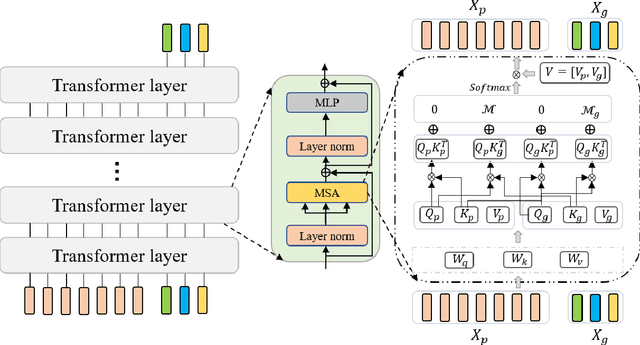

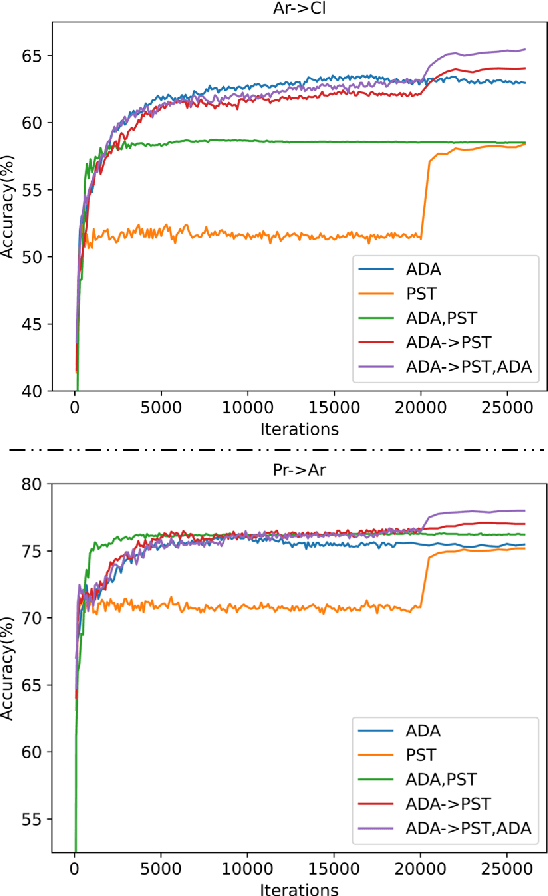
Vision transformer has demonstrated great potential in abundant vision tasks. However, it also inevitably suffers from poor generalization capability when the distribution shift occurs in testing (i.e., out-of-distribution data). To mitigate this issue, we propose a novel method, Semantic-aware Message Broadcasting (SAMB), which enables more informative and flexible feature alignment for unsupervised domain adaptation (UDA). Particularly, we study the attention module in the vision transformer and notice that the alignment space using one global class token lacks enough flexibility, where it interacts information with all image tokens in the same manner but ignores the rich semantics of different regions. In this paper, we aim to improve the richness of the alignment features by enabling semantic-aware adaptive message broadcasting. Particularly, we introduce a group of learned group tokens as nodes to aggregate the global information from all image tokens, but encourage different group tokens to adaptively focus on the message broadcasting to different semantic regions. In this way, our message broadcasting encourages the group tokens to learn more informative and diverse information for effective domain alignment. Moreover, we systematically study the effects of adversarial-based feature alignment (ADA) and pseudo-label based self-training (PST) on UDA. We find that one simple two-stage training strategy with the cooperation of ADA and PST can further improve the adaptation capability of the vision transformer. Extensive experiments on DomainNet, OfficeHome, and VisDA-2017 demonstrate the effectiveness of our methods for UDA.
Dataset vs Reality: Understanding Model Performance from the Perspective of Information Need
Dec 06, 2022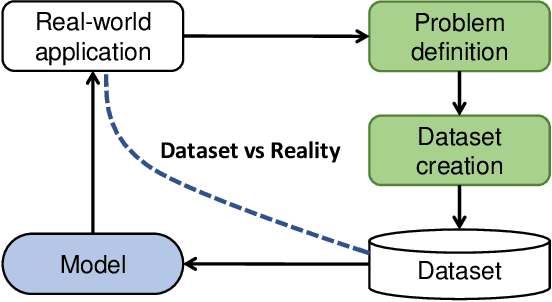

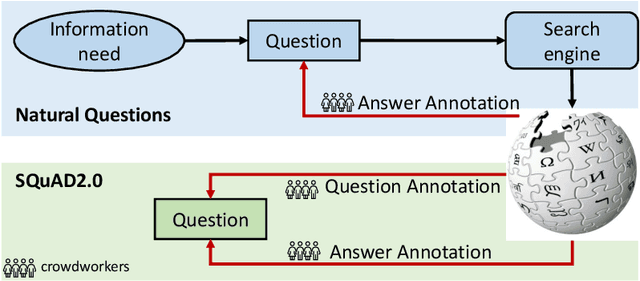

Deep learning technologies have brought us many models that outperform human beings on a few benchmarks. An interesting question is: can these models well solve real-world problems with similar settings (e.g., same input/output) to the benchmark datasets? We argue that a model is trained to answer the same information need for which the training dataset is created. Although some datasets may share high structural similarities, e.g., question-answer pairs for the question answering (QA) task and image-caption pairs for the image captioning (IC) task, not all datasets are created for the same information need. To support our argument, we conduct a comprehensive analysis on widely used benchmark datasets for both QA and IC tasks. We compare the dataset creation process (e.g., crowdsourced, or collected data from real users or content providers) from the perspective of information need in the context of information retrieval. To show the differences between datasets, we perform both word-level and sentence-level analysis. We show that data collected from real users or content providers tend to have richer, more diverse, and more specific words than data annotated by crowdworkers. At sentence level, data by crowdworkers share similar dependency distributions and higher similarities in sentence structure, compared to data collected from content providers. We believe our findings could partially explain why some datasets are considered more challenging than others, for similar tasks. Our findings may also be helpful in guiding new dataset construction.
Image Gradient Decomposition for Parallel and Memory-Efficient Ptychographic Reconstruction
May 12, 2022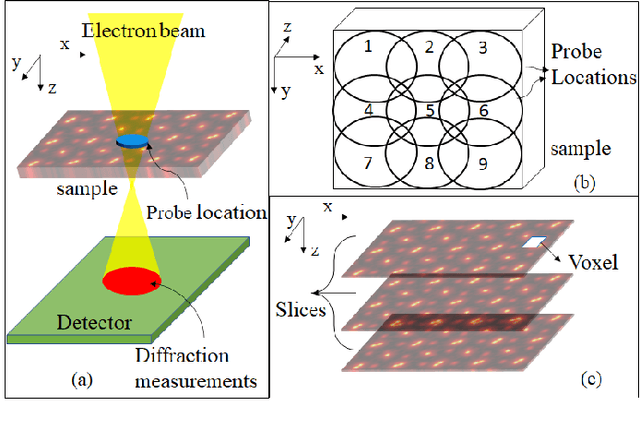
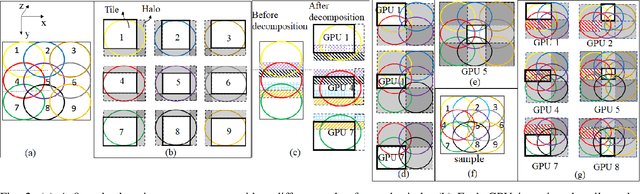
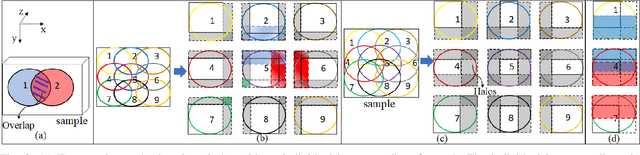
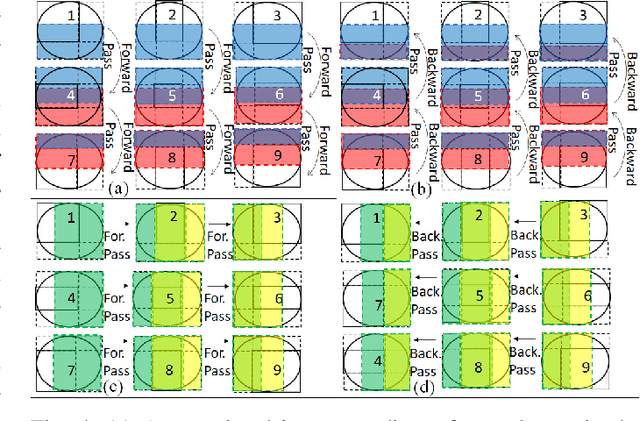
Ptychography is a popular microscopic imaging modality for many scientific discoveries and sets the record for highest image resolution. Unfortunately, the high image resolution for ptychographic reconstruction requires significant amount of memory and computations, forcing many applications to compromise their image resolution in exchange for a smaller memory footprint and a shorter reconstruction time. In this paper, we propose a novel image gradient decomposition method that significantly reduces the memory footprint for ptychographic reconstruction by tessellating image gradients and diffraction measurements into tiles. In addition, we propose a parallel image gradient decomposition method that enables asynchronous point-to-point communications and parallel pipelining with minimal overhead on a large number of GPUs. Our experiments on a Titanate material dataset (PbTiO3) with 16632 probe locations show that our Gradient Decomposition algorithm reduces memory footprint by 51 times. In addition, it achieves time-to-solution within 2.2 minutes by scaling to 4158 GPUs with a super-linear speedup at 364% efficiency. This performance is 2.7 times more memory efficient, 9 times more scalable and 86 times faster than the state-of-the-art algorithm.
TexPose: Neural Texture Learning for Self-Supervised 6D Object Pose Estimation
Dec 25, 2022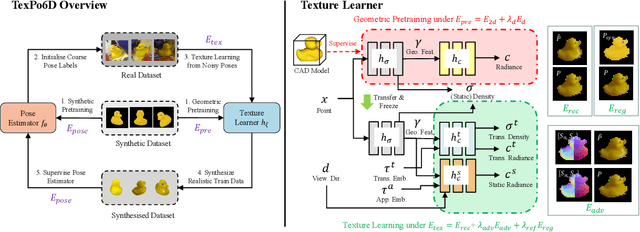
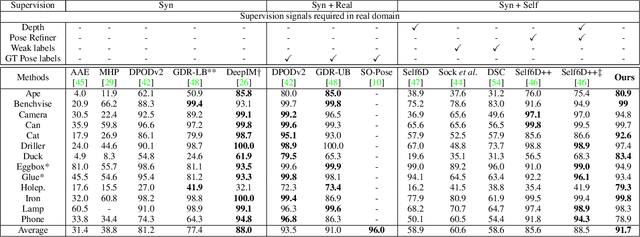

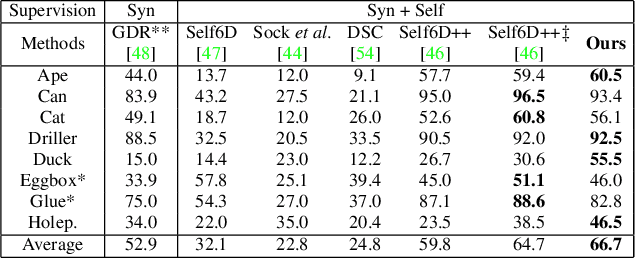
In this paper, we introduce neural texture learning for 6D object pose estimation from synthetic data and a few unlabelled real images. Our major contribution is a novel learning scheme which removes the drawbacks of previous works, namely the strong dependency on co-modalities or additional refinement. These have been previously necessary to provide training signals for convergence. We formulate such a scheme as two sub-optimisation problems on texture learning and pose learning. We separately learn to predict realistic texture of objects from real image collections and learn pose estimation from pixel-perfect synthetic data. Combining these two capabilities allows then to synthesise photorealistic novel views to supervise the pose estimator with accurate geometry. To alleviate pose noise and segmentation imperfection present during the texture learning phase, we propose a surfel-based adversarial training loss together with texture regularisation from synthetic data. We demonstrate that the proposed approach significantly outperforms the recent state-of-the-art methods without ground-truth pose annotations and demonstrates substantial generalisation improvements towards unseen scenes. Remarkably, our scheme improves the adopted pose estimators substantially even when initialised with much inferior performance.
Efficient Multi-Purpose Cross-Attention Based Image Alignment Block for Edge Devices
Jun 01, 2022

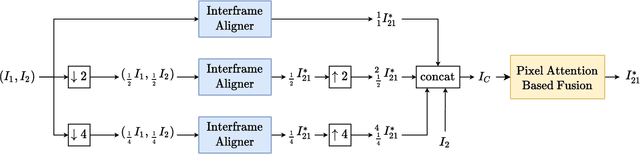
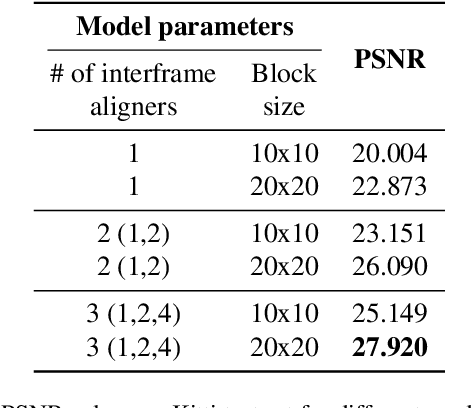
Image alignment, also known as image registration, is a critical block used in many computer vision problems. One of the key factors in alignment is efficiency, as inefficient aligners can cause significant overhead to the overall problem. In the literature, there are some blocks that appear to do the alignment operation, although most do not focus on efficiency. Therefore, an image alignment block which can both work in time and/or space and can work on edge devices would be beneficial for almost all networks dealing with multiple images. Given its wide usage and importance, we propose an efficient, cross-attention-based, multi-purpose image alignment block (XABA) suitable to work within edge devices. Using cross-attention, we exploit the relationships between features extracted from images. To make cross-attention feasible for real-time image alignment problems and handle large motions, we provide a pyramidal block based cross-attention scheme. This also captures local relationships besides reducing memory requirements and number of operations. Efficient XABA models achieve real-time requirements of running above 20 FPS performance on NVIDIA Jetson Xavier with 30W power consumption compared to other powerful computers. Used as a sub-block in a larger network, XABA also improves multi-image super-resolution network performance in comparison to other alignment methods.
Vision Transformers in Medical Imaging: A Review
Nov 18, 2022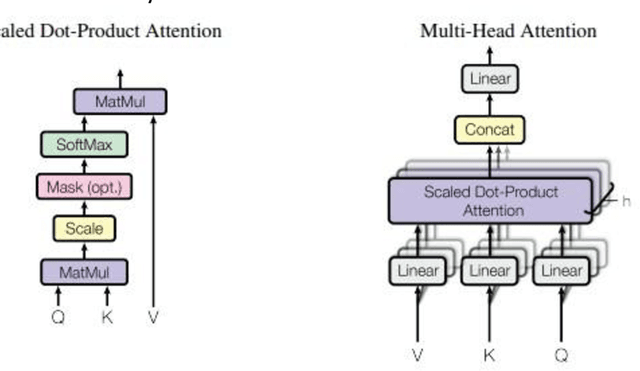
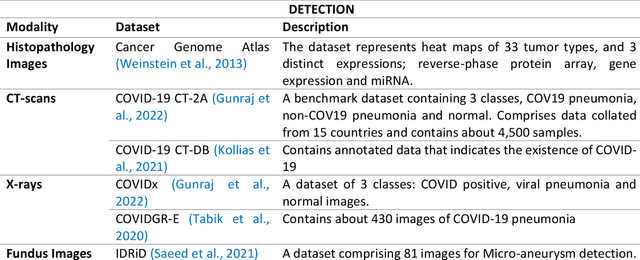
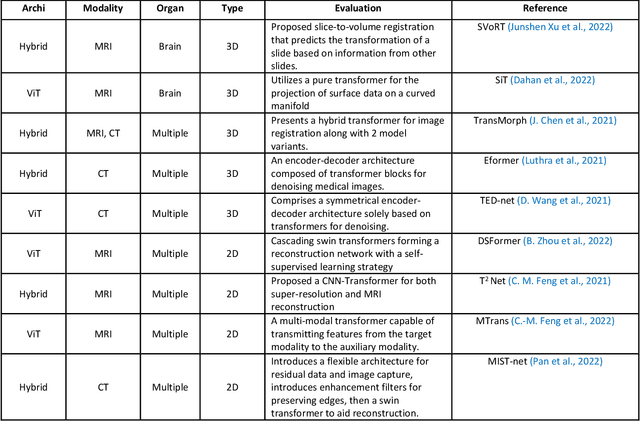
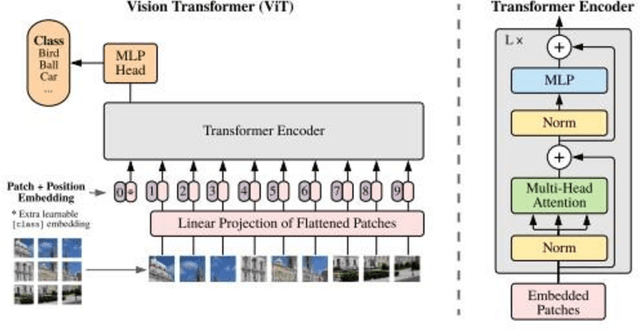
Transformer, a model comprising attention-based encoder-decoder architecture, have gained prevalence in the field of natural language processing (NLP) and recently influenced the computer vision (CV) space. The similarities between computer vision and medical imaging, reviewed the question among researchers if the impact of transformers on computer vision be translated to medical imaging? In this paper, we attempt to provide a comprehensive and recent review on the application of transformers in medical imaging by; describing the transformer model comparing it with a diversity of convolutional neural networks (CNNs), detailing the transformer based approaches for medical image classification, segmentation, registration and reconstruction with a focus on the image modality, comparing the performance of state-of-the-art transformer architectures to best performing CNNs on standard medical datasets.
Learning to Immunize Images for Tamper Localization and Self-Recovery
Oct 28, 2022

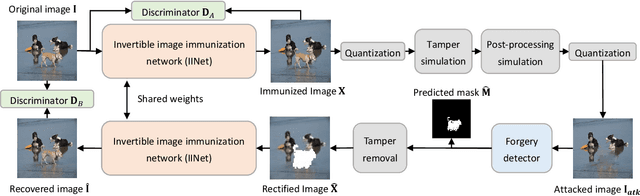
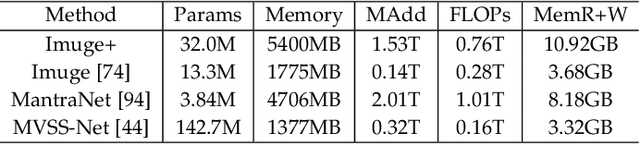
Digital images are vulnerable to nefarious tampering attacks such as content addition or removal that severely alter the original meaning. It is somehow like a person without protection that is open to various kinds of viruses. Image immunization (Imuge) is a technology of protecting the images by introducing trivial perturbation, so that the protected images are immune to the viruses in that the tampered contents can be auto-recovered. This paper presents Imuge+, an enhanced scheme for image immunization. By observing the invertible relationship between image immunization and the corresponding self-recovery, we employ an invertible neural network to jointly learn image immunization and recovery respectively in the forward and backward pass. We also introduce an efficient attack layer that involves both malicious tamper and benign image post-processing, where a novel distillation-based JPEG simulator is proposed for improved JPEG robustness. Our method achieves promising results in real-world tests where experiments show accurate tamper localization as well as high-fidelity content recovery. Additionally, we show superior performance on tamper localization compared to state-of-the-art schemes based on passive forensics.
Machine Learning Challenges of Biological Factors in Insect Image Data
Nov 04, 2022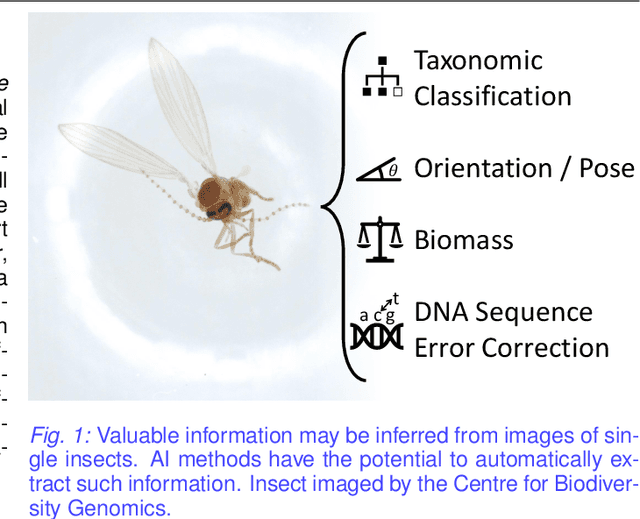

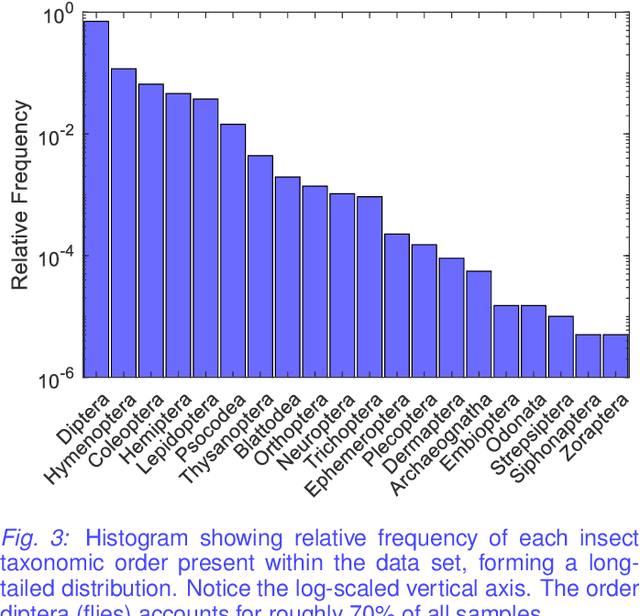
The BIOSCAN project, led by the International Barcode of Life Consortium, seeks to study changes in biodiversity on a global scale. One component of the project is focused on studying the species interaction and dynamics of all insects. In addition to genetically barcoding insects, over 1.5 million images per year will be collected, each needing taxonomic classification. With the immense volume of incoming images, relying solely on expert taxonomists to label the images would be impossible; however, artificial intelligence and computer vision technology may offer a viable high-throughput solution. Additional tasks including manually weighing individual insects to determine biomass, remain tedious and costly. Here again, computer vision may offer an efficient and compelling alternative. While the use of computer vision methods is appealing for addressing these problems, significant challenges resulting from biological factors present themselves. These challenges are formulated in the context of machine learning in this paper.