 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dispersed Pixel Perturbation-based Imperceptible Backdoor Trigger for Image Classifier Models
Aug 19, 2022
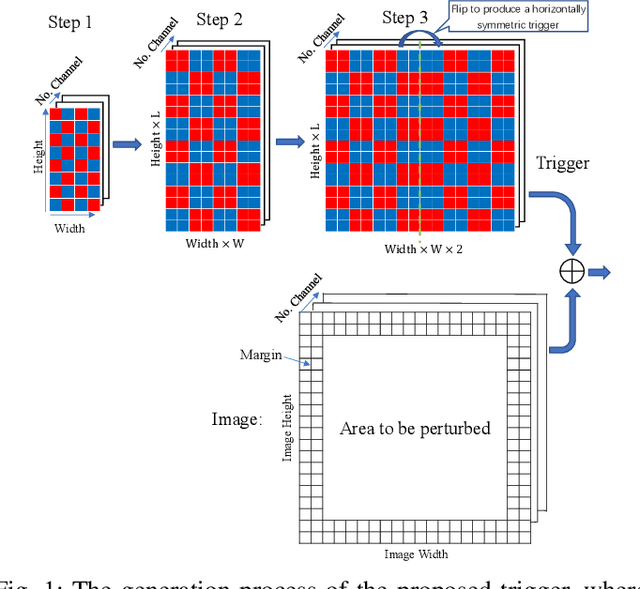
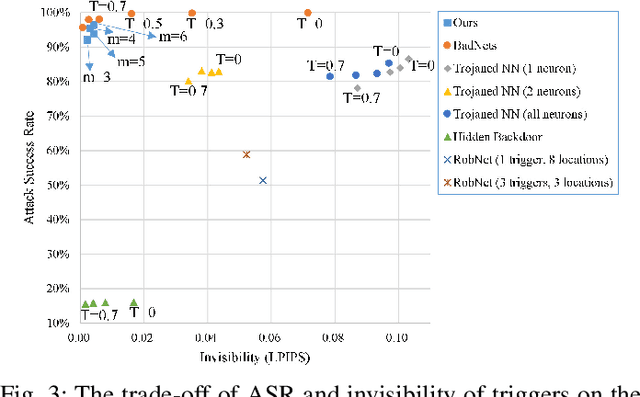
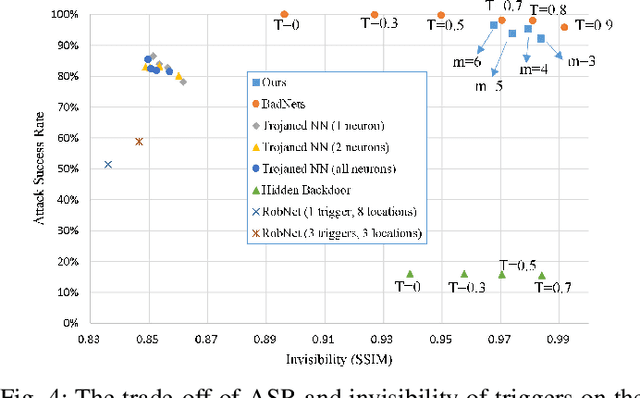
Typical deep neural network (DNN) backdoor attacks are based on triggers embedded in inputs. Existing imperceptible triggers are computationally expensive or low in attack success. In this paper, we propose a new backdoor trigger, which is easy to generate, imperceptible, and highly effective. The new trigger is a uniformly randomly generated three-dimensional (3D) binary pattern that can be horizontally and/or vertically repeated and mirrored and superposed onto three-channel images for training a backdoored DNN model. Dispersed throughout an image, the new trigger produces weak perturbation to individual pixels, but collectively holds a strong recognizable pattern to train and activate the backdoor of the DNN. We also analytically reveal that the trigger is increasingly effective with the improving resolution of the images. Experiments are conducted using the ResNet-18 and MLP models on the MNIST, CIFAR-10, and BTSR datasets. In terms of imperceptibility, the new trigger outperforms existing triggers, such as BadNets, Trojaned NN, and Hidden Backdoor, by over an order of magnitude. The new trigger achieves an almost 100% attack success rate, only reduces the classification accuracy by less than 0.7%-2.4%, and invalidates the state-of-the-art defense techniques.
Bayesian posterior approximation with stochastic ensembles
Dec 15, 2022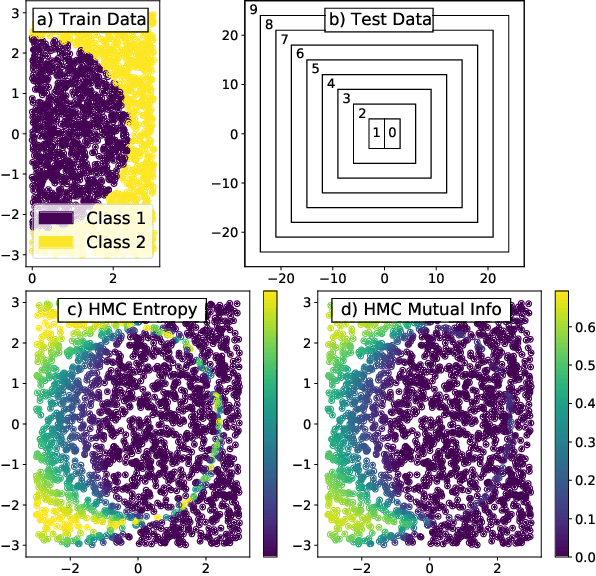
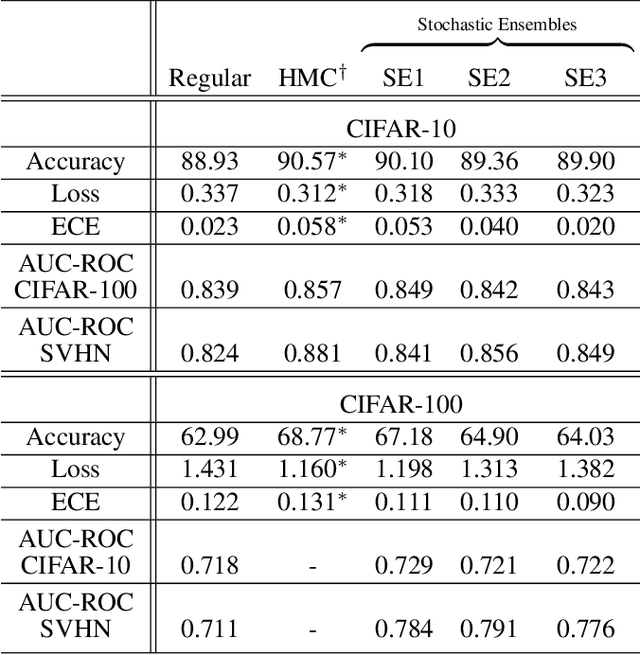
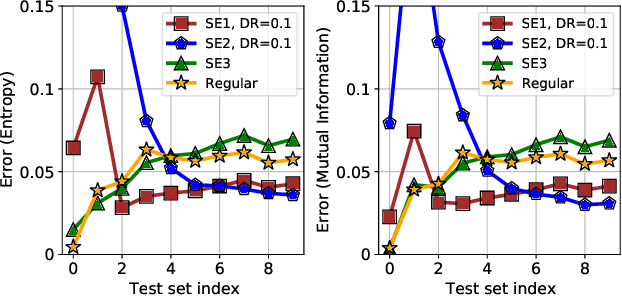
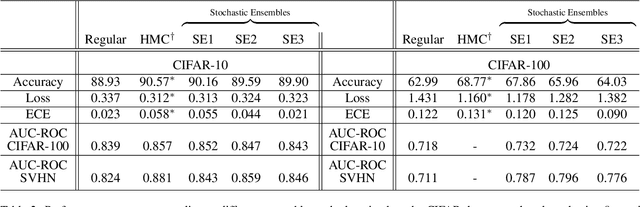
We introduce ensembles of stochastic neural networks to approximate the Bayesian posterior, combining stochastic methods such as dropout with deep ensembles. The stochastic ensembles are formulated as families of distributions and trained to approximate the Bayesian posterior with variational inference. We implement stochastic ensembles based on Monte Carlo dropout, DropConnect and a novel non-parametric version of dropout and evaluate them on a toy problem and CIFAR image classification. For CIFAR, the stochastic ensembles are quantitatively compared to published Hamiltonian Monte Carlo results for a ResNet-20 architecture. We also test the quality of the posteriors directly against Hamiltonian Monte Carlo simulations in a simplified toy model. Our results show that in a number of settings, stochastic ensembles provide more accurate posterior estimates than regular deep ensembles.
A Survey on Leveraging Pre-trained Generative Adversarial Networks for Image Editing and Restoration
Jul 21, 2022

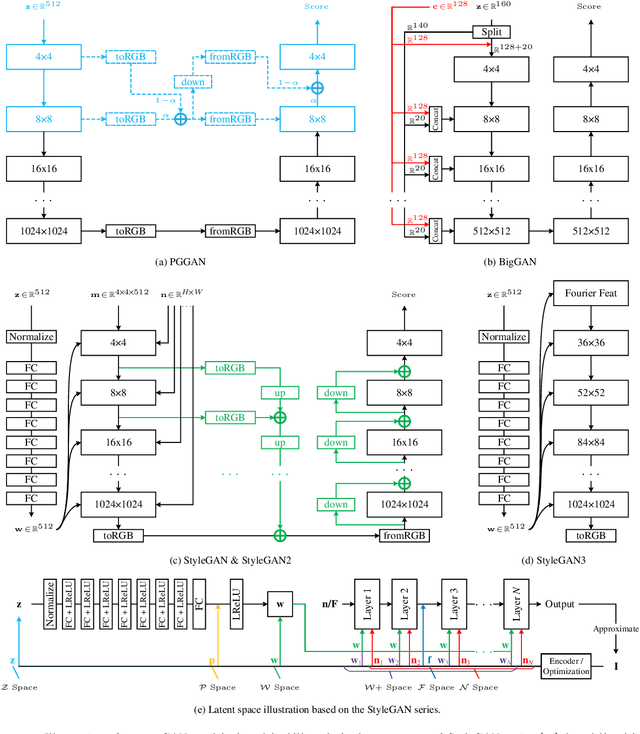

Generative adversarial networks (GANs) have drawn enormous attention due to the simple yet effective training mechanism and superior image generation quality. With the ability to generate photo-realistic high-resolution (e.g., $1024\times1024$) images, recent GAN models have greatly narrowed the gaps between the generated images and the real ones. Therefore, many recent works show emerging interest to take advantage of pre-trained GAN models by exploiting the well-disentangled latent space and the learned GAN priors. In this paper, we briefly review recent progress on leveraging pre-trained large-scale GAN models from three aspects, i.e., 1) the training of large-scale generative adversarial networks, 2) exploring and understanding the pre-trained GAN models, and 3) leveraging these models for subsequent tasks like image restoration and editing. More information about relevant methods and repositories can be found at https://github.com/csmliu/pretrained-GANs.
Cross-Domain Ensemble Distillation for Domain Generalization
Nov 25, 2022Domain generalization is the task of learning models that generalize to unseen target domains. We propose a simple yet effective method for domain generalization, named cross-domain ensemble distillation (XDED), that learns domain-invariant features while encouraging the model to converge to flat minima, which recently turned out to be a sufficient condition for domain generalization. To this end, our method generates an ensemble of the output logits from training data with the same label but from different domains and then penalizes each output for the mismatch with the ensemble. Also, we present a de-stylization technique that standardizes features to encourage the model to produce style-consistent predictions even in an arbitrary target domain. Our method greatly improves generalization capability in public benchmarks for cross-domain image classification, cross-dataset person re-ID, and cross-dataset semantic segmentation. Moreover, we show that models learned by our method are robust against adversarial attacks and image corruptions.
ShadowNeuS: Neural SDF Reconstruction by Shadow Ray Supervision
Nov 25, 2022

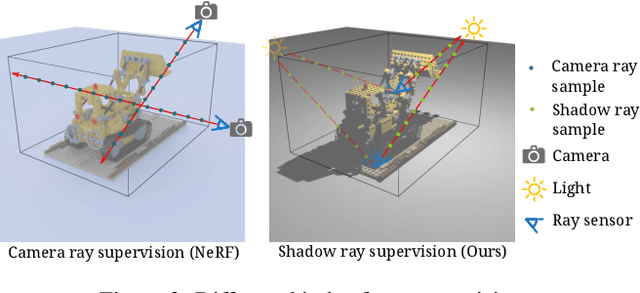

By supervising camera rays between a scene and multi-view image planes, NeRF reconstructs a neural scene representation for the task of novel view synthesis. On the other hand, shadow rays between the light source and the scene have yet to be considered. Therefore, we propose a novel shadow ray supervision scheme that optimizes both the samples along the ray and the ray location. By supervising shadow rays, we successfully reconstruct a neural SDF of the scene from single-view pure shadow or RGB images under multiple lighting conditions. Given single-view binary shadows, we train a neural network to reconstruct a complete scene not limited by the camera's line of sight. By further modeling the correlation between the image colors and the shadow rays, our technique can also be effectively extended to RGB inputs. We compare our method with previous works on challenging tasks of shape reconstruction from single-view binary shadow or RGB images and observe significant improvements. The code and data will be released.
Attention-Aware Anime Line Drawing Colorization
Dec 21, 2022
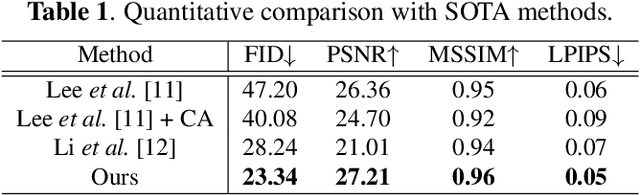
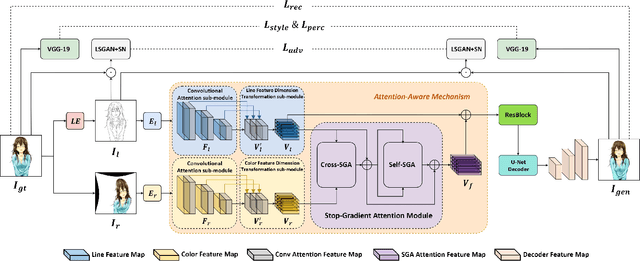

Automatic colorization of anime line drawing has attracted much attention in recent years since it can substantially benefit the animation industry. User-hint based methods are the mainstream approach for line drawing colorization, while reference-based methods offer a more intuitive approach. Nevertheless, although reference-based methods can improve feature aggregation of the reference image and the line drawing, the colorization results are not compelling in terms of color consistency or semantic correspondence. In this paper, we introduce an attention-based model for anime line drawing colorization, in which a channel-wise and spatial-wise Convolutional Attention module is used to improve the ability of the encoder for feature extraction and key area perception, and a Stop-Gradient Attention module with cross-attention and self-attention is used to tackle the cross-domain long-range dependency problem. Extensive experiments show that our method outperforms other SOTA methods, with more accurate line structure and semantic color information.
Continual Learning Approaches for Anomaly Detection
Dec 21, 2022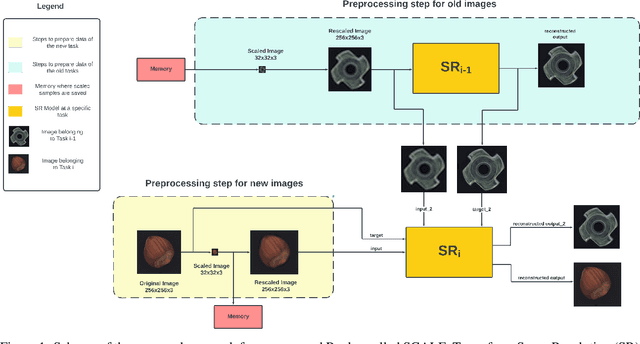
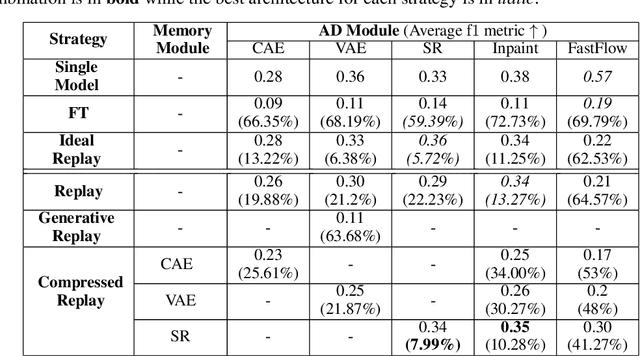
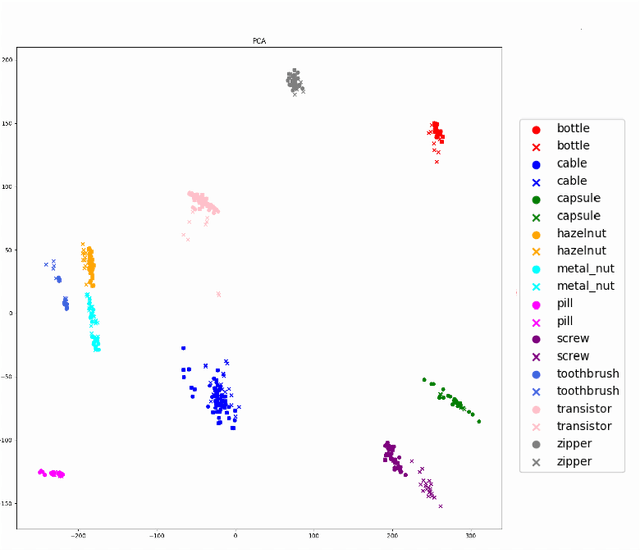
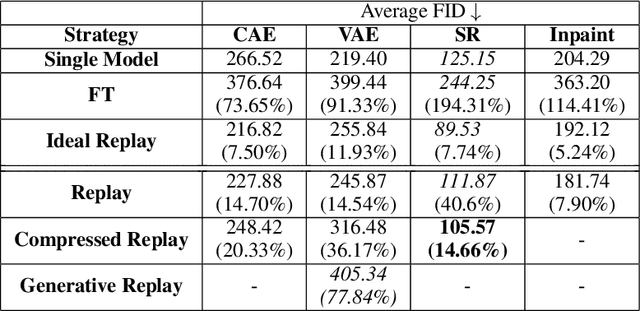
Anomaly Detection is a relevant problem that arises in numerous real-world applications, especially when dealing with images. However, there has been little research for this task in the Continual Learning setting. In this work, we introduce a novel approach called SCALE (SCALing is Enough) to perform Compressed Replay in a framework for Anomaly Detection in Continual Learning setting. The proposed technique scales and compresses the original images using a Super Resolution model which, to the best of our knowledge, is studied for the first time in the Continual Learning setting. SCALE can achieve a high level of compression while maintaining a high level of image reconstruction quality. In conjunction with other Anomaly Detection approaches, it can achieve optimal results. To validate the proposed approach, we use a real-world dataset of images with pixel-based anomalies, with the scope to provide a reliable benchmark for Anomaly Detection in the context of Continual Learning, serving as a foundation for further advancements in the field.
LWSIS: LiDAR-guided Weakly Supervised Instance Segmentation for Autonomous Driving
Dec 07, 2022
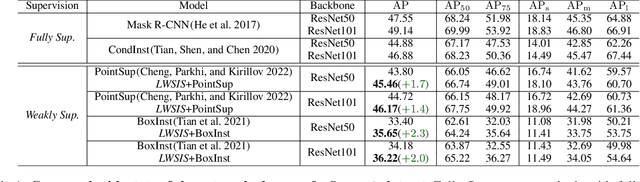
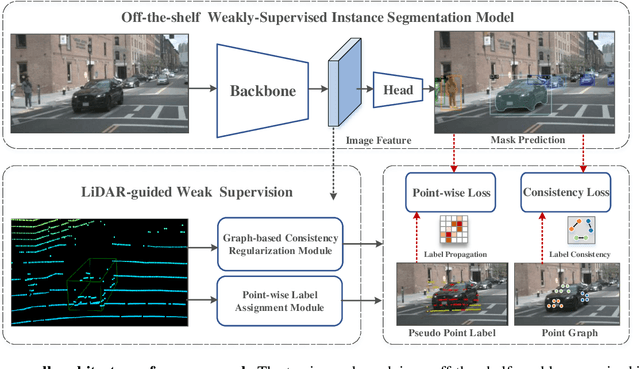
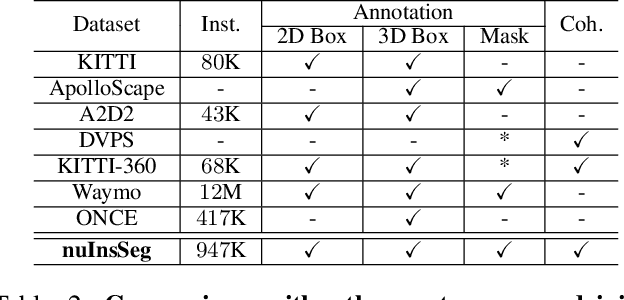
Image instance segmentation is a fundamental research topic in autonomous driving, which is crucial for scene understanding and road safety. Advanced learning-based approaches often rely on the costly 2D mask annotations for training. In this paper, we present a more artful framework, LiDAR-guided Weakly Supervised Instance Segmentation (LWSIS), which leverages the off-the-shelf 3D data, i.e., Point Cloud, together with the 3D boxes, as natural weak supervisions for training the 2D image instance segmentation models. Our LWSIS not only exploits the complementary information in multimodal data during training, but also significantly reduces the annotation cost of the dense 2D masks. In detail, LWSIS consists of two crucial modules, Point Label Assignment (PLA) and Graph-based Consistency Regularization (GCR). The former module aims to automatically assign the 3D point cloud as 2D point-wise labels, while the latter further refines the predictions by enforcing geometry and appearance consistency of the multimodal data. Moreover, we conduct a secondary instance segmentation annotation on the nuScenes, named nuInsSeg, to encourage further research on multimodal perception tasks. Extensive experiments on the nuInsSeg, as well as the large-scale Waymo, show that LWSIS can substantially improve existing weakly supervised segmentation models by only involving 3D data during training. Additionally, LWSIS can also be incorporated into 3D object detectors like PointPainting to boost the 3D detection performance for free. The code and dataset are available at https://github.com/Serenos/LWSIS.
Multi-scale Feature Imitation for Unsupervised Anomaly Localization
Dec 13, 2022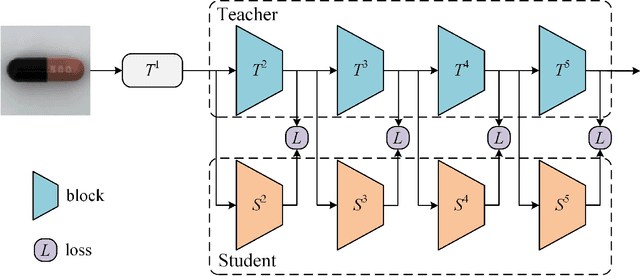
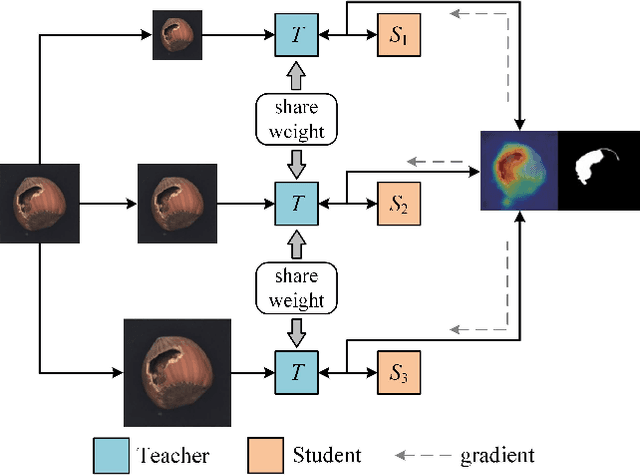
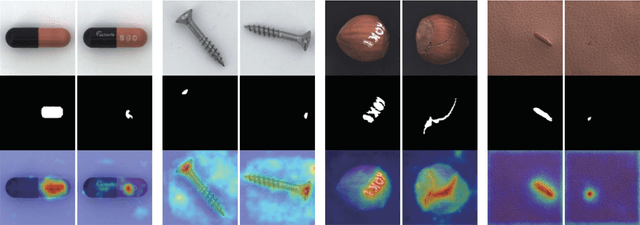

The unsupervised anomaly localization task faces the challenge of missing anomaly sample training, detecting multiple types of anomalies, and dealing with the proportion of the area of multiple anomalies. A separate teacher-student feature imitation network structure and a multi-scale processing strategy combining an image and feature pyramid are proposed to solve these problems. A network module importance search method based on gradient descent optimization is proposed to simplify the network structure. The experimental results show that the proposed algorithm performs better than the feature modeling anomaly localization method on the real industrial product detection dataset in the same period. The multi-scale strategy can effectively improve the effect compared with the benchmark method.
* International Joint Conference on Neural Networks 2023
Selective Amnesia: On Efficient, High-Fidelity and Blind Suppression of Backdoor Effects in Trojaned Machine Learning Models
Dec 09, 2022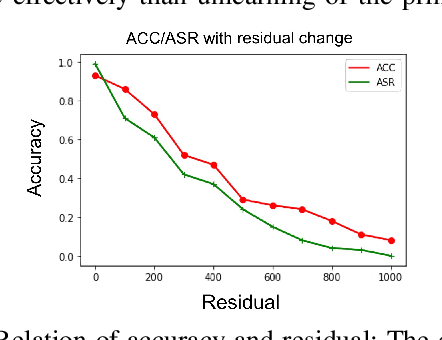
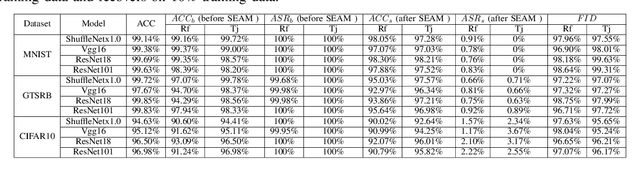
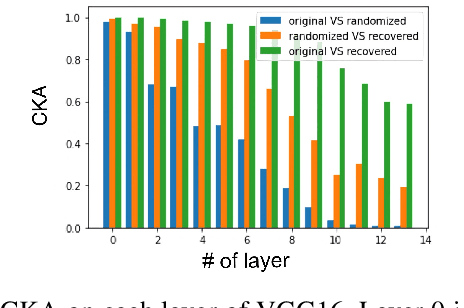
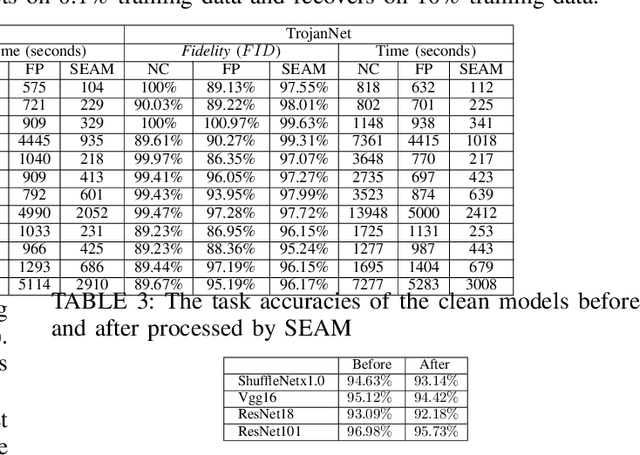
In this paper, we present a simple yet surprisingly effective technique to induce "selective amnesia" on a backdoored model. Our approach, called SEAM, has been inspired by the problem of catastrophic forgetting (CF), a long standing issue in continual learning. Our idea is to retrain a given DNN model on randomly labeled clean data, to induce a CF on the model, leading to a sudden forget on both primary and backdoor tasks; then we recover the primary task by retraining the randomized model on correctly labeled clean data. We analyzed SEAM by modeling the unlearning process as continual learning and further approximating a DNN using Neural Tangent Kernel for measuring CF. Our analysis shows that our random-labeling approach actually maximizes the CF on an unknown backdoor in the absence of triggered inputs, and also preserves some feature extraction in the network to enable a fast revival of the primary task. We further evaluated SEAM on both image processing and Natural Language Processing tasks, under both data contamination and training manipulation attacks, over thousands of models either trained on popular image datasets or provided by the TrojAI competition. Our experiments show that SEAM vastly outperforms the state-of-the-art unlearning techniques, achieving a high Fidelity (measuring the gap between the accuracy of the primary task and that of the backdoor) within a few minutes (about 30 times faster than training a model from scratch using the MNIST dataset), with only a small amount of clean data (0.1% of training data for TrojAI models).