 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CardioCaps: Attention-based Capsule Network for Class-Imbalanced Echocardiogram Classification
Mar 15, 2024
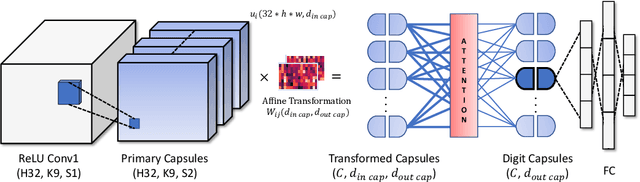
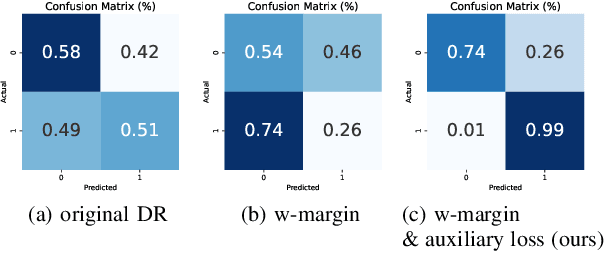
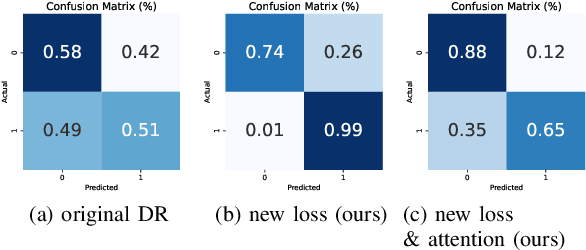
Capsule Neural Networks (CapsNets) is a novel architecture that utilizes vector-wise representations formed by multiple neurons. Specifically, the Dynamic Routing CapsNets (DR-CapsNets) employ an affine matrix and dynamic routing mechanism to train capsules and acquire translation-equivariance properties, enhancing its robustness compared to traditional Convolutional Neural Networks (CNNs). Echocardiograms, which capture moving images of the heart, present unique challenges for traditional image classification methods. In this paper, we explore the potential of DR-CapsNets and propose CardioCaps, a novel attention-based DR-CapsNet architecture for class-imbalanced echocardiogram classification. CardioCaps comprises two key components: a weighted margin loss incorporating a regression auxiliary loss and an attention mechanism. First, the weighted margin loss prioritizes positive cases, supplemented by an auxiliary loss function based on the Ejection Fraction (EF) regression task, a crucial measure of cardiac function. This approach enhances the model's resilience in the face of class imbalance. Second, recognizing the quadratic complexity of dynamic routing leading to training inefficiencies, we adopt the attention mechanism as a more computationally efficient alternative. Our results demonstrate that CardioCaps surpasses traditional machine learning baseline methods, including Logistic Regression, Random Forest, and XGBoost with sampling methods and a class weight matrix. Furthermore, CardioCaps outperforms other deep learning baseline methods such as CNNs, ResNets, U-Nets, and ViTs, as well as advanced CapsNets methods such as EM-CapsNets and Efficient-CapsNets. Notably, our model demonstrates robustness to class imbalance, achieving high precision even in datasets with a substantial proportion of negative cases.
* 8 pages, 6 figures
Visual Foundation Models Boost Cross-Modal Unsupervised Domain Adaptation for 3D Semantic Segmentation
Mar 15, 2024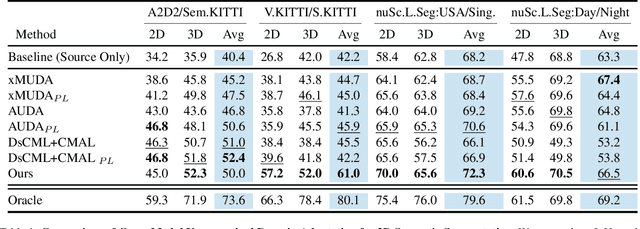
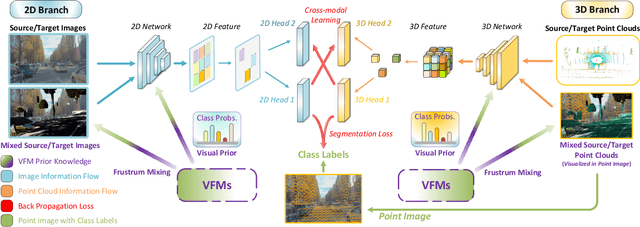
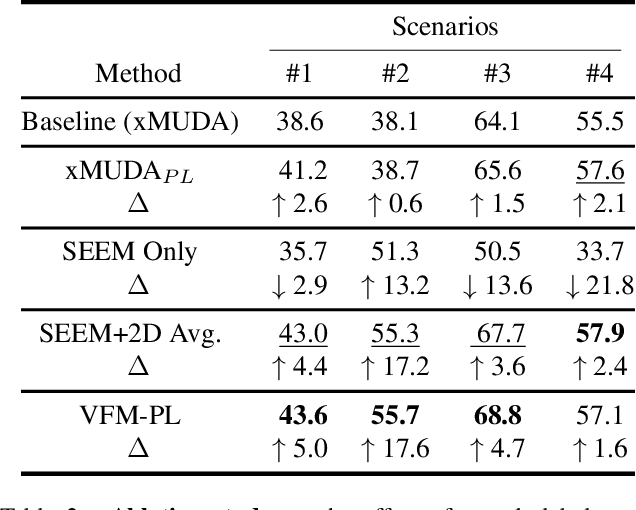
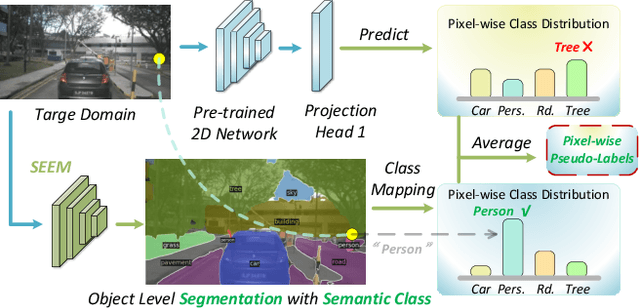
Unsupervised domain adaptation (UDA) is vital for alleviating the workload of labeling 3D point cloud data and mitigating the absence of labels when facing a newly defined domain. Various methods of utilizing images to enhance the performance of cross-domain 3D segmentation have recently emerged. However, the pseudo labels, which are generated from models trained on the source domain and provide additional supervised signals for the unseen domain, are inadequate when utilized for 3D segmentation due to their inherent noisiness and consequently restrict the accuracy of neural networks. With the advent of 2D visual foundation models (VFMs) and their abundant knowledge prior, we propose a novel pipeline VFMSeg to further enhance the cross-modal unsupervised domain adaptation framework by leveraging these models. In this work, we study how to harness the knowledge priors learned by VFMs to produce more accurate labels for unlabeled target domains and improve overall performance. We first utilize a multi-modal VFM, which is pre-trained on large scale image-text pairs, to provide supervised labels (VFM-PL) for images and point clouds from the target domain. Then, another VFM trained on fine-grained 2D masks is adopted to guide the generation of semantically augmented images and point clouds to enhance the performance of neural networks, which mix the data from source and target domains like view frustums (FrustumMixing). Finally, we merge class-wise prediction across modalities to produce more accurate annotations for unlabeled target domains. Our method is evaluated on various autonomous driving datasets and the results demonstrate a significant improvement for 3D segmentation task.
Reliable uncertainty with cheaper neural network ensembles: a case study in industrial parts classification
Mar 15, 2024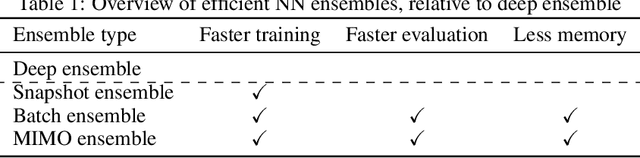
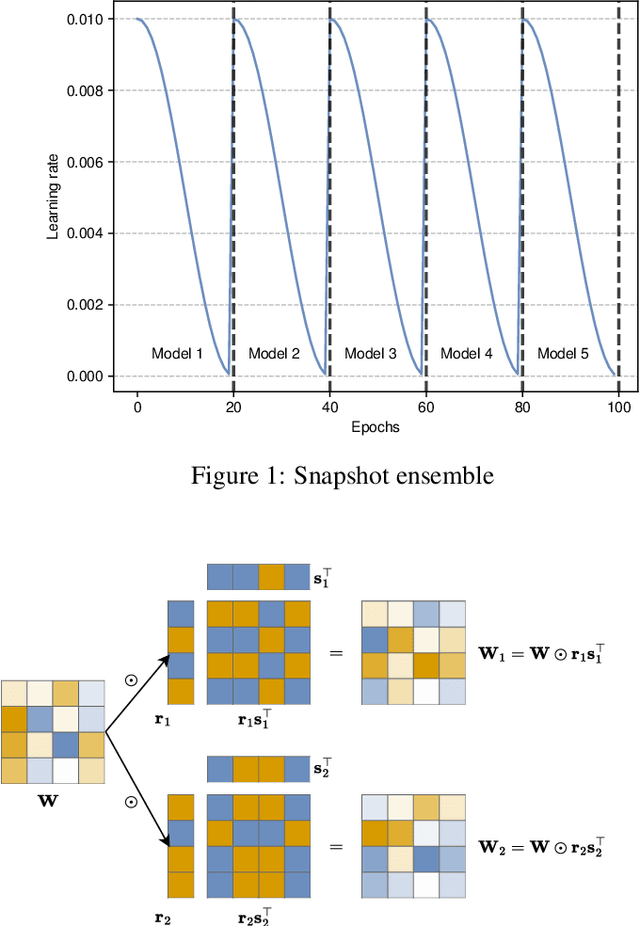
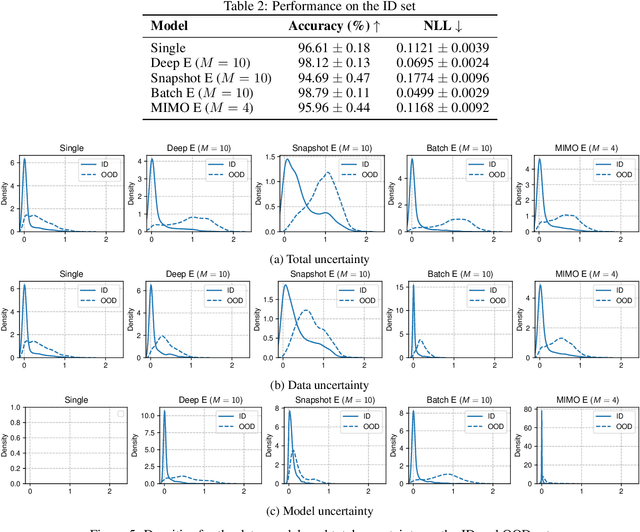
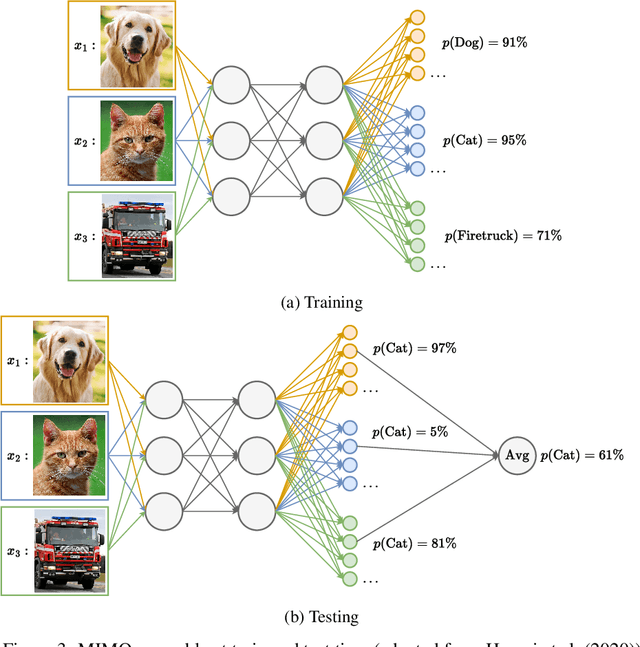
In operations research (OR), predictive models often encounter out-of-distribution (OOD) scenarios where the data distribution differs from the training data distribution. In recent years, neural networks (NNs) are gaining traction in OR for their exceptional performance in fields such as image classification. However, NNs tend to make confident yet incorrect predictions when confronted with OOD data. Uncertainty estimation offers a solution to overconfident models, communicating when the output should (not) be trusted. Hence, reliable uncertainty quantification in NNs is crucial in the OR domain. Deep ensembles, composed of multiple independent NNs, have emerged as a promising approach, offering not only strong predictive accuracy but also reliable uncertainty estimation. However, their deployment is challenging due to substantial computational demands. Recent fundamental research has proposed more efficient NN ensembles, namely the snapshot, batch, and multi-input multi-output ensemble. This study is the first to provide a comprehensive comparison of a single NN, a deep ensemble, and the three efficient NN ensembles. In addition, we propose a Diversity Quality metric to quantify the ensembles' performance on the in-distribution and OOD sets in one single metric. The OR case study discusses industrial parts classification to identify and manage spare parts, important for timely maintenance of industrial plants. The results highlight the batch ensemble as a cost-effective and competitive alternative to the deep ensemble. It outperforms the deep ensemble in both uncertainty and accuracy while exhibiting a training time speedup of 7x, a test time speedup of 8x, and 9x memory savings.
Generative Region-Language Pretraining for Open-Ended Object Detection
Mar 15, 2024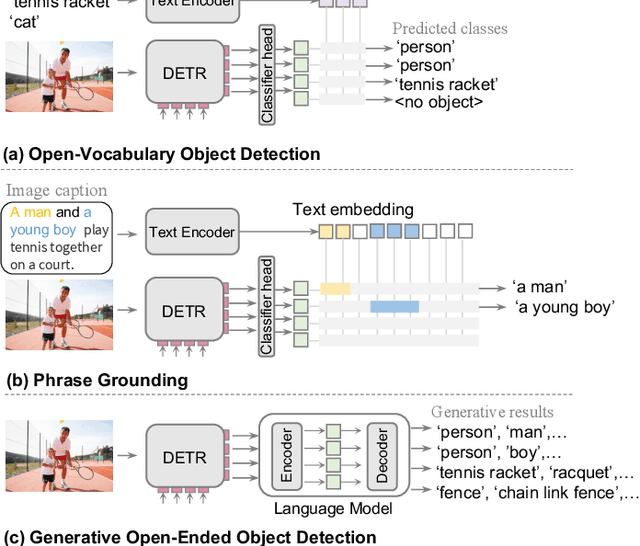

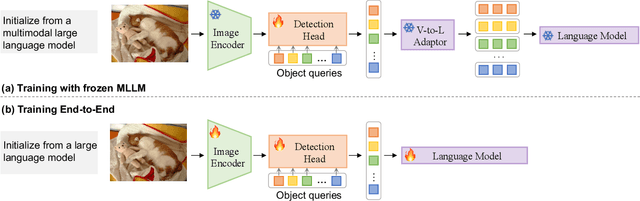

In recent research, significant attention has been devoted to the open-vocabulary object detection task, aiming to generalize beyond the limited number of classes labeled during training and detect objects described by arbitrary category names at inference. Compared with conventional object detection, open vocabulary object detection largely extends the object detection categories. However, it relies on calculating the similarity between image regions and a set of arbitrary category names with a pretrained vision-and-language model. This implies that, despite its open-set nature, the task still needs the predefined object categories during the inference stage. This raises the question: What if we do not have exact knowledge of object categories during inference? In this paper, we call such a new setting as generative open-ended object detection, which is a more general and practical problem. To address it, we formulate object detection as a generative problem and propose a simple framework named GenerateU, which can detect dense objects and generate their names in a free-form way. Particularly, we employ Deformable DETR as a region proposal generator with a language model translating visual regions to object names. To assess the free-form object detection task, we introduce an evaluation method designed to quantitatively measure the performance of generative outcomes. Extensive experiments demonstrate strong zero-shot detection performance of our GenerateU. For example, on the LVIS dataset, our GenerateU achieves comparable results to the open-vocabulary object detection method GLIP, even though the category names are not seen by GenerateU during inference. Code is available at: https:// github.com/FoundationVision/GenerateU .
Towards Unified Multi-Modal Personalization: Large Vision-Language Models for Generative Recommendation and Beyond
Mar 15, 2024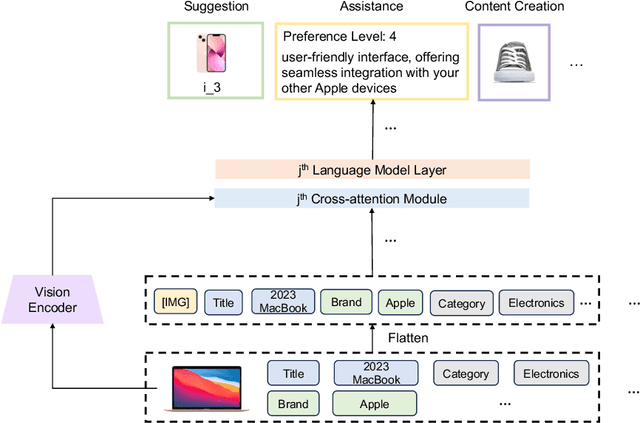
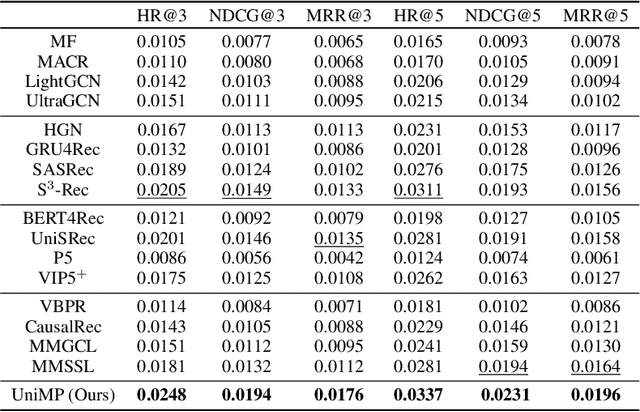
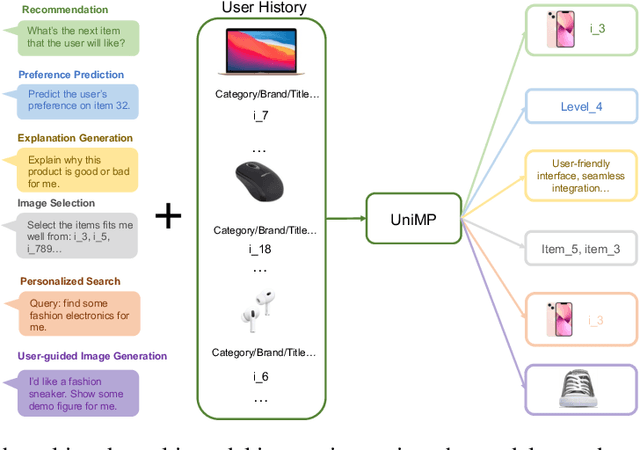
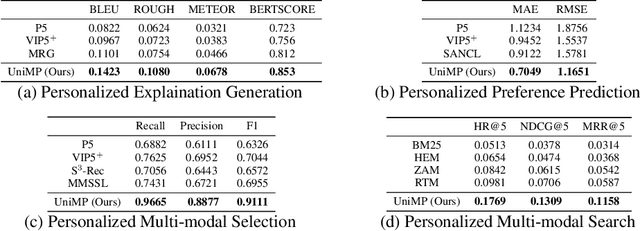
Developing a universal model that can effectively harness heterogeneous resources and respond to a wide range of personalized needs has been a longstanding community aspiration. Our daily choices, especially in domains like fashion and retail, are substantially shaped by multi-modal data, such as pictures and textual descriptions. These modalities not only offer intuitive guidance but also cater to personalized user preferences. However, the predominant personalization approaches mainly focus on the ID or text-based recommendation problem, failing to comprehend the information spanning various tasks or modalities. In this paper, our goal is to establish a Unified paradigm for Multi-modal Personalization systems (UniMP), which effectively leverages multi-modal data while eliminating the complexities associated with task- and modality-specific customization. We argue that the advancements in foundational generative modeling have provided the flexibility and effectiveness necessary to achieve the objective. In light of this, we develop a generic and extensible personalization generative framework, that can handle a wide range of personalized needs including item recommendation, product search, preference prediction, explanation generation, and further user-guided image generation. Our methodology enhances the capabilities of foundational language models for personalized tasks by seamlessly ingesting interleaved cross-modal user history information, ensuring a more precise and customized experience for users. To train and evaluate the proposed multi-modal personalized tasks, we also introduce a novel and comprehensive benchmark covering a variety of user requirements. Our experiments on the real-world benchmark showcase the model's potential, outperforming competitive methods specialized for each task.
Medical Unlearnable Examples: Securing Medical Data from Unauthorized Traning via Sparsity-Aware Local Masking
Mar 15, 2024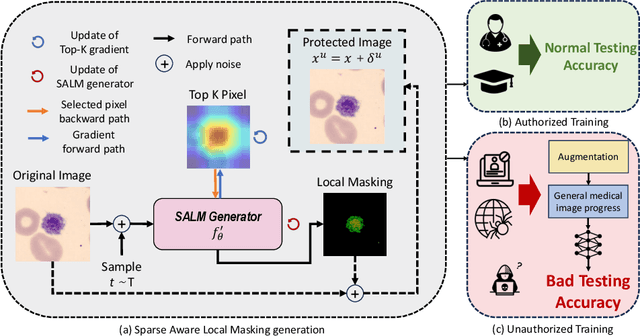
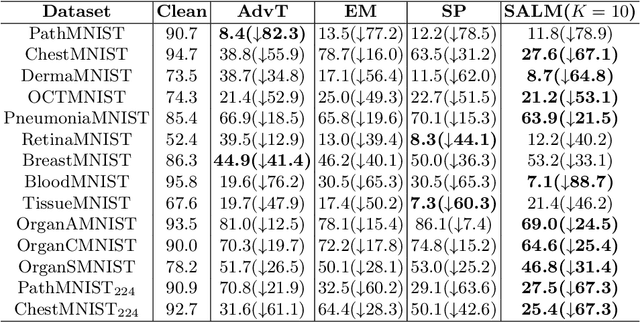
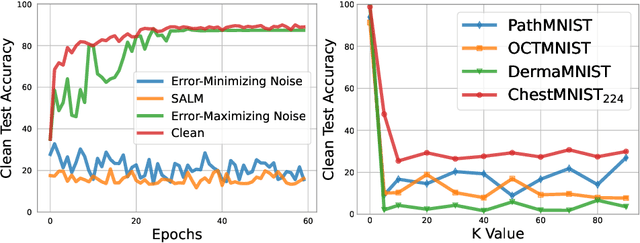
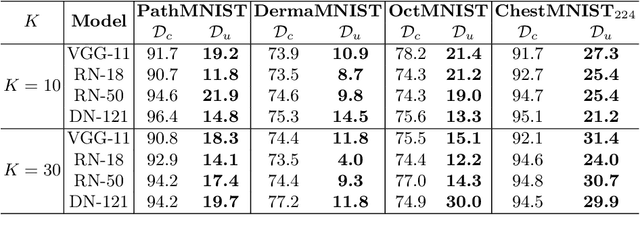
With the rapid growth of artificial intelligence (AI) in healthcare, there has been a significant increase in the generation and storage of sensitive medical data. This abundance of data, in turn, has propelled the advancement of medical AI technologies. However, concerns about unauthorized data exploitation, such as training commercial AI models, often deter researchers from making their invaluable datasets publicly available. In response to the need to protect this hard-to-collect data while still encouraging medical institutions to share it, one promising solution is to introduce imperceptible noise into the data. This method aims to safeguard the data against unauthorized training by inducing degradation in model generalization. Although existing methods have shown commendable data protection capabilities in general domains, they tend to fall short when applied to biomedical data, mainly due to their failure to account for the sparse nature of medical images. To address this problem, we propose the Sparsity-Aware Local Masking (SALM) method, a novel approach that selectively perturbs significant pixel regions rather than the entire image as previous strategies have done. This simple-yet-effective approach significantly reduces the perturbation search space by concentrating on local regions, thereby improving both the efficiency and effectiveness of data protection for biomedical datasets characterized by sparse features. Besides, we have demonstrated that SALM maintains the essential characteristics of the data, ensuring its clinical utility remains uncompromised. Our extensive experiments across various datasets and model architectures demonstrate that SALM effectively prevents unauthorized training of deep-learning models and outperforms previous state-of-the-art data protection methods.
Navigating Beyond Dropout: An Intriguing Solution Towards Generalizable Image Super Resolution
Mar 01, 2024Deep learning has led to a dramatic leap on Single Image Super-Resolution (SISR) performances in recent years. %Despite the substantial advancement% While most existing work assumes a simple and fixed degradation model (e.g., bicubic downsampling), the research of Blind SR seeks to improve model generalization ability with unknown degradation. Recently, Kong et al pioneer the investigation of a more suitable training strategy for Blind SR using Dropout. Although such method indeed brings substantial generalization improvements via mitigating overfitting, we argue that Dropout simultaneously introduces undesirable side-effect that compromises model's capacity to faithfully reconstruct fine details. We show both the theoretical and experimental analyses in our paper, and furthermore, we present another easy yet effective training strategy that enhances the generalization ability of the model by simply modulating its first and second-order features statistics. Experimental results have shown that our method could serve as a model-agnostic regularization and outperforms Dropout on seven benchmark datasets including both synthetic and real-world scenarios.
An Analysis of Human Alignment of Latent Diffusion Models
Mar 13, 2024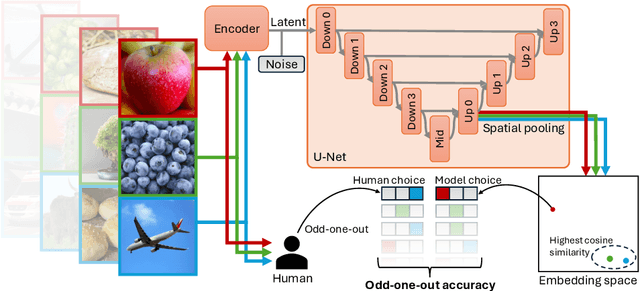
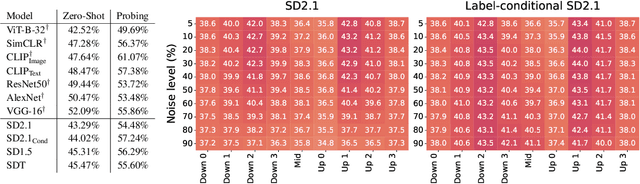
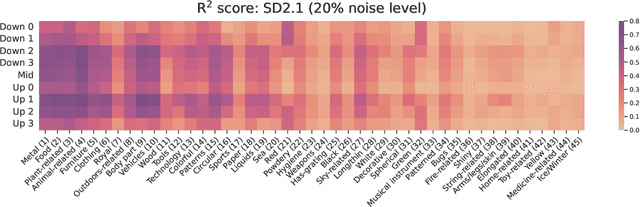
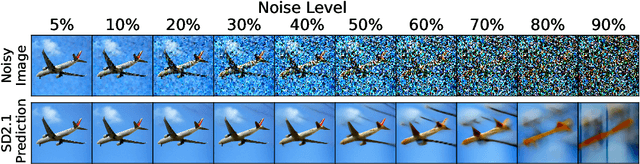
Diffusion models, trained on large amounts of data, showed remarkable performance for image synthesis. They have high error consistency with humans and low texture bias when used for classification. Furthermore, prior work demonstrated the decomposability of their bottleneck layer representations into semantic directions. In this work, we analyze how well such representations are aligned to human responses on a triplet odd-one-out task. We find that despite the aforementioned observations: I) The representational alignment with humans is comparable to that of models trained only on ImageNet-1k. II) The most aligned layers of the denoiser U-Net are intermediate layers and not the bottleneck. III) Text conditioning greatly improves alignment at high noise levels, hinting at the importance of abstract textual information, especially in the early stage of generation.
Infrared and visible Image Fusion with Language-driven Loss in CLIP Embedding Space
Feb 26, 2024Infrared-visible image fusion (IVIF) has attracted much attention owing to the highly-complementary properties of the two image modalities. Due to the lack of ground-truth fused images, the fusion output of current deep-learning based methods heavily depends on the loss functions defined mathematically. As it is hard to well mathematically define the fused image without ground truth, the performance of existing fusion methods is limited. In this paper, we first propose to use natural language to express the objective of IVIF, which can avoid the explicit mathematical modeling of fusion output in current losses, and make full use of the advantage of language expression to improve the fusion performance. For this purpose, we present a comprehensive language-expressed fusion objective, and encode relevant texts into the multi-modal embedding space using CLIP. A language-driven fusion model is then constructed in the embedding space, by establishing the relationship among the embedded vectors to represent the fusion objective and input image modalities. Finally, a language-driven loss is derived to make the actual IVIF aligned with the embedded language-driven fusion model via supervised training. Experiments show that our method can obtain much better fusion results than existing techniques.
Distributionally Generative Augmentation for Fair Facial Attribute Classification
Mar 11, 2024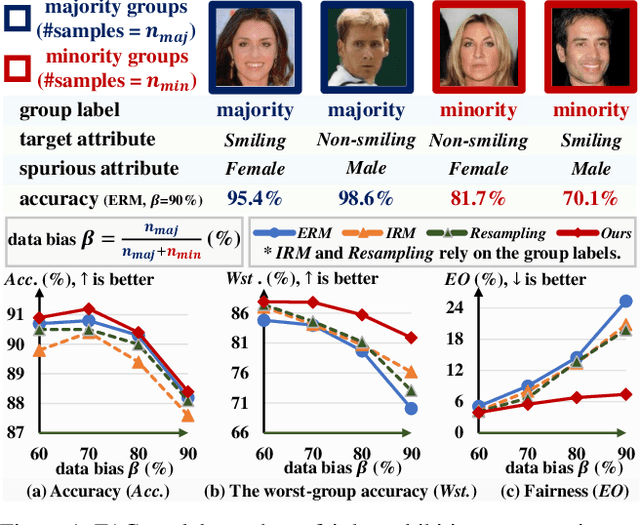
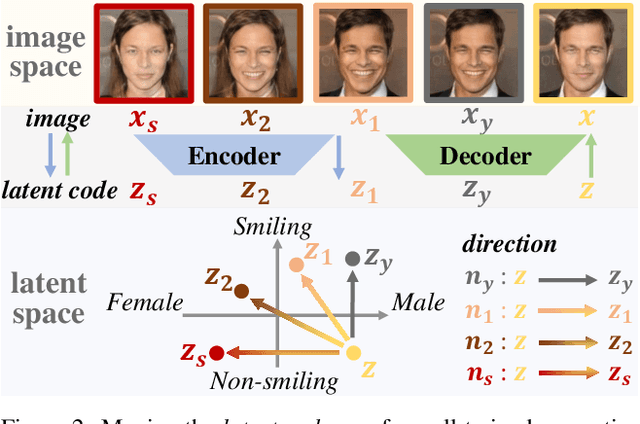

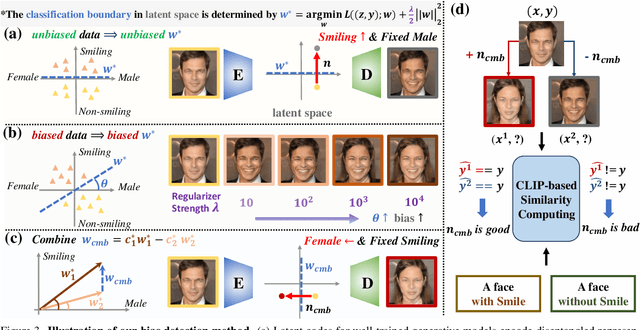
Facial Attribute Classification (FAC) holds substantial promise in widespread applications. However, FAC models trained by traditional methodologies can be unfair by exhibiting accuracy inconsistencies across varied data subpopulations. This unfairness is largely attributed to bias in data, where some spurious attributes (e.g., Male) statistically correlate with the target attribute (e.g., Smiling). Most of existing fairness-aware methods rely on the labels of spurious attributes, which may be unavailable in practice. This work proposes a novel, generation-based two-stage framework to train a fair FAC model on biased data without additional annotation. Initially, we identify the potential spurious attributes based on generative models. Notably, it enhances interpretability by explicitly showing the spurious attributes in image space. Following this, for each image, we first edit the spurious attributes with a random degree sampled from a uniform distribution, while keeping target attribute unchanged. Then we train a fair FAC model by fostering model invariance to these augmentation. Extensive experiments on three common datasets demonstrate the effectiveness of our method in promoting fairness in FAC without compromising accuracy. Codes are in https://github.com/heqianpei/DiGA.