 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Label Mask AutoEncoder(L-MAE): A Pure Transformer Method to Augment Semantic Segmentation Datasets
Nov 21, 2022
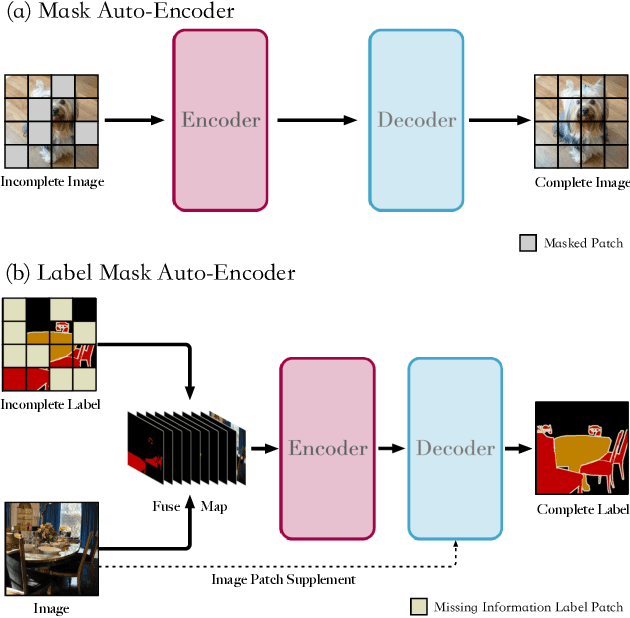
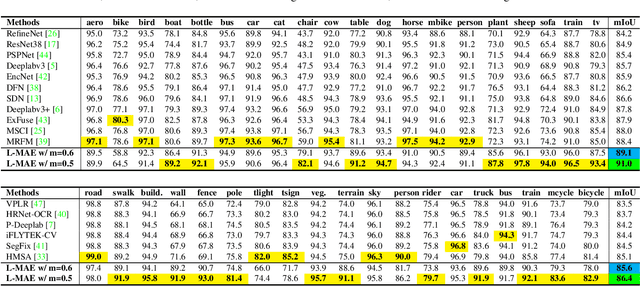

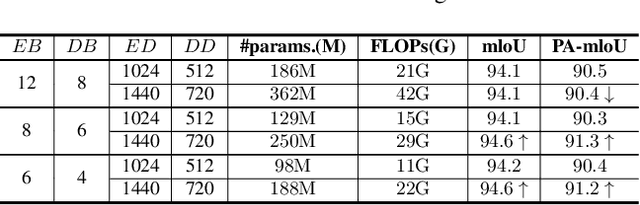
Semantic segmentation models based on the conventional neural network can achieve remarkable performance in such tasks, while the dataset is crucial to the training model process. Significant progress in expanding datasets has been made in semi-supervised semantic segmentation recently. However, completing the pixel-level information remains challenging due to possible missing in a label. Inspired by Mask AutoEncoder, we present a simple yet effective Pixel-Level completion method, Label Mask AutoEncoder(L-MAE), that fully uses the existing information in the label to predict results. The proposed model adopts the fusion strategy that stacks the label and the corresponding image, namely Fuse Map. Moreover, since some of the image information is lost when masking the Fuse Map, direct reconstruction may lead to poor performance. Our proposed Image Patch Supplement algorithm can supplement the missing information, as the experiment shows, an average of 4.1% mIoU can be improved. The Pascal VOC2012 dataset (224 crop size, 20 classes) and the Cityscape dataset (448 crop size, 19 classes) are used in the comparative experiments. With the Mask Ratio setting to 50%, in terms of the prediction region, the proposed model achieves 91.0% and 86.4% of mIoU on Pascal VOC 2012 and Cityscape, respectively, outperforming other current supervised semantic segmentation models. Our code and models are available at https://github.com/jjrccop/Label-Mask-Auto-Encoder.
PatchShading: High-Quality Human Reconstruction by Patch Warping and Shading Refinement
Nov 26, 2022
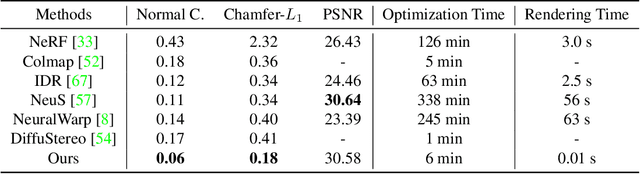
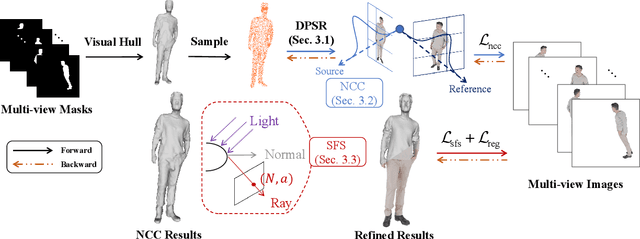
Human reconstruction from multi-view images plays an important role in many applications. Although neural rendering methods have achieved promising results on synthesising realistic images, it is still difficult to handle the ambiguity between the geometry and appearance using only rendering loss. Moreover, it is very computationally intensive to render a whole image as each pixel requires a forward network inference. To tackle these challenges, we propose a novel approach called \emph{PatchShading} to reconstruct high-quality mesh of human body from multi-view posed images. We first present a patch warping strategy to constrain multi-view photometric consistency explicitly. Second, we adopt sphere harmonics (SH) illumination and shape from shading image formation to further refine the geometric details. By taking advantage of the oriented point clouds shape representation and SH shading, our proposed method significantly reduce the optimization and rendering time compared to those implicit methods. The encouraging results on both synthetic and real-world datasets demonstrate the efficacy of our proposed approach.
A Critical Appraisal of Data Augmentation Methods for Imaging-Based Medical Diagnosis Applications
Dec 14, 2022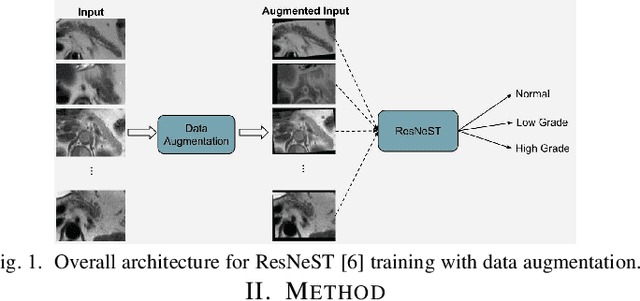
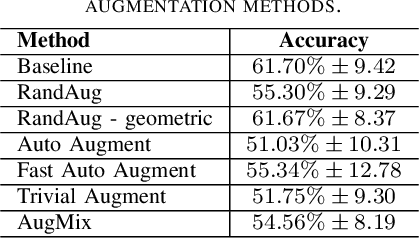
Current data augmentation techniques and transformations are well suited for improving the size and quality of natural image datasets but are not yet optimized for medical imaging. We hypothesize that sub-optimal data augmentations can easily distort or occlude medical images, leading to false positives or negatives during patient diagnosis, prediction, or therapy/surgery evaluation. In our experimental results, we found that utilizing commonly used intensity-based data augmentation distorts the MRI scans and leads to texture information loss, thus negatively affecting the overall performance of classification. Additionally, we observed that commonly used data augmentation methods cannot be used with a plug-and-play approach in medical imaging, and requires manual tuning and adjustment.
Hierarchical Similarity Learning for Aliasing Suppression Image Super-Resolution
Jun 07, 2022



As a highly ill-posed issue, single image super-resolution (SISR) has been widely investigated in recent years. The main task of SISR is to recover the information loss caused by the degradation procedure. According to the Nyquist sampling theory, the degradation leads to aliasing effect and makes it hard to restore the correct textures from low-resolution (LR) images. In practice, there are correlations and self-similarities among the adjacent patches in the natural images. This paper considers the self-similarity and proposes a hierarchical image super-resolution network (HSRNet) to suppress the influence of aliasing. We consider the SISR issue in the optimization perspective, and propose an iterative solution pattern based on the half-quadratic splitting (HQS) method. To explore the texture with local image prior, we design a hierarchical exploration block (HEB) and progressive increase the receptive field. Furthermore, multi-level spatial attention (MSA) is devised to obtain the relations of adjacent feature and enhance the high-frequency information, which acts as a crucial role for visual experience. Experimental result shows HSRNet achieves better quantitative and visual performance than other works, and remits the aliasing more effectively.
Knowledge-Guided Data-Centric AI in Healthcare: Progress, Shortcomings, and Future Directions
Dec 27, 2022



The success of deep learning is largely due to the availability of large amounts of training data that cover a wide range of examples of a particular concept or meaning. In the field of medicine, having a diverse set of training data on a particular disease can lead to the development of a model that is able to accurately predict the disease. However, despite the potential benefits, there have not been significant advances in image-based diagnosis due to a lack of high-quality annotated data. This article highlights the importance of using a data-centric approach to improve the quality of data representations, particularly in cases where the available data is limited. To address this "small-data" issue, we discuss four methods for generating and aggregating training data: data augmentation, transfer learning, federated learning, and GANs (generative adversarial networks). We also propose the use of knowledge-guided GANs to incorporate domain knowledge in the training data generation process. With the recent progress in large pre-trained language models, we believe it is possible to acquire high-quality knowledge that can be used to improve the effectiveness of knowledge-guided generative methods.
Treatment classification of posterior capsular opacification (PCO) using automated ground truths
Nov 11, 2022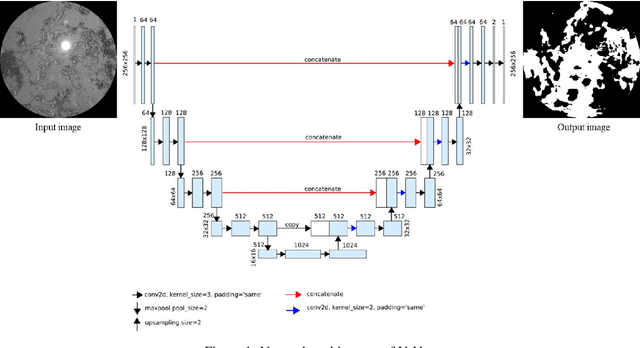
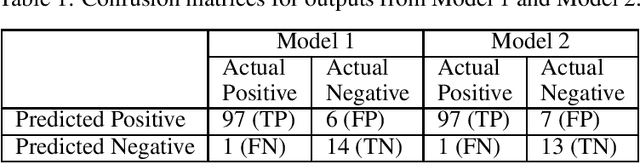
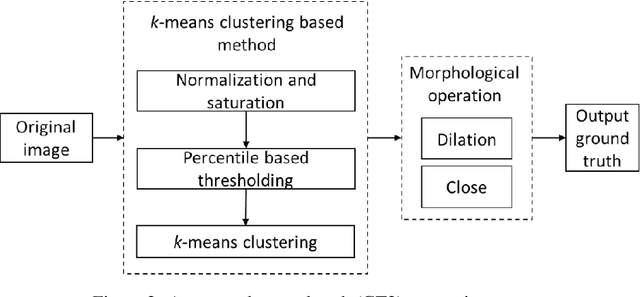
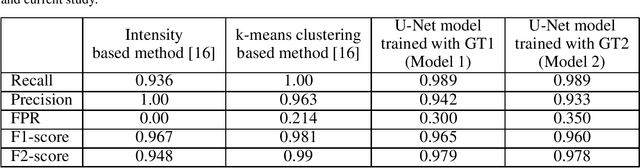
Determination of treatment need of posterior capsular opacification (PCO)-- one of the most common complication of cataract surgery -- is a difficult process due to its local unavailability and the fact that treatment is provided only after PCO occurs in the central visual axis. In this paper we propose a deep learning (DL)-based method to first segment PCO images then classify the images into \textit{treatment required} and \textit{not yet required} cases in order to reduce frequent hospital visits. To train the model, we prepare a training image set with ground truths (GT) obtained from two strategies: (i) manual and (ii) automated. So, we have two models: (i) Model 1 (trained with image set containing manual GT) (ii) Model 2 (trained with image set containing automated GT). Both models when evaluated on validation image set gave Dice coefficient value greater than 0.8 and intersection-over-union (IoU) score greater than 0.67 in our experiments. Comparison between gold standard GT and segmented results from our models gave a Dice coefficient value greater than 0.7 and IoU score greater than 0.6 for both the models showing that automated ground truths can also result in generation of an efficient model. Comparison between our classification result and clinical classification shows 0.98 F2-score for outputs from both the models.
Be Careful with Rotation: A Uniform Backdoor Pattern for 3D Shape
Dec 01, 2022
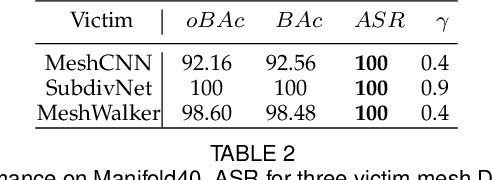
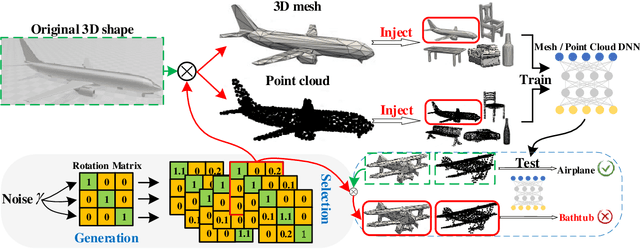
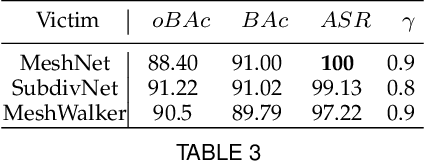
For saving cost, many deep neural networks (DNNs) are trained on third-party datasets downloaded from internet, which enables attacker to implant backdoor into DNNs. In 2D domain, inherent structures of different image formats are similar. Hence, backdoor attack designed for one image format will suite for others. However, when it comes to 3D world, there is a huge disparity among different 3D data structures. As a result, backdoor pattern designed for one certain 3D data structure will be disable for other data structures of the same 3D scene. Therefore, this paper designs a uniform backdoor pattern: NRBdoor (Noisy Rotation Backdoor) which is able to adapt for heterogeneous 3D data structures. Specifically, we start from the unit rotation and then search for the optimal pattern by noise generation and selection process. The proposed NRBdoor is natural and imperceptible, since rotation is a common operation which usually contains noise due to both the miss match between a pair of points and the sensor calibration error for real-world 3D scene. Extensive experiments on 3D mesh and point cloud show that the proposed NRBdoor achieves state-of-the-art performance, with negligible shape variation.
MixMIM: Mixed and Masked Image Modeling for Efficient Visual Representation Learning
May 28, 2022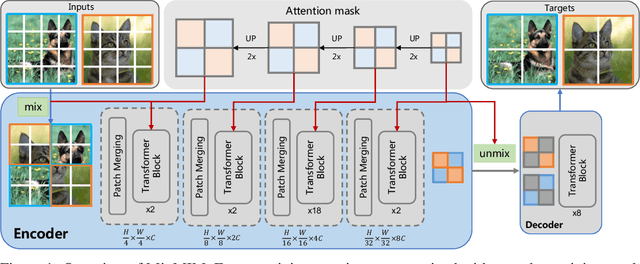

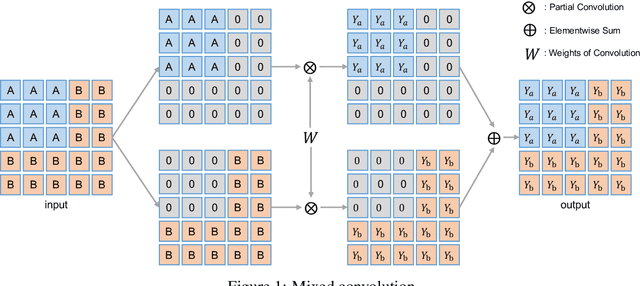
In this study, we propose Mixed and Masked Image Modeling (MixMIM), a simple but efficient MIM method that is applicable to various hierarchical Vision Transformers. Existing MIM methods replace a random subset of input tokens with a special MASK symbol and aim at reconstructing original image tokens from the corrupted image. However, we find that using the MASK symbol greatly slows down the training and causes training-finetuning inconsistency, due to the large masking ratio (e.g., 40% in BEiT). In contrast, we replace the masked tokens of one image with visible tokens of another image, i.e., creating a mixed image. We then conduct dual reconstruction to reconstruct the original two images from the mixed input, which significantly improves efficiency. While MixMIM can be applied to various architectures, this paper explores a simpler but stronger hierarchical Transformer, and scales with MixMIM-B, -L, and -H. Empirical results demonstrate that MixMIM can learn high-quality visual representations efficiently. Notably, MixMIM-B with 88M parameters achieves 85.1% top-1 accuracy on ImageNet-1K by pretraining for 600 epochs, setting a new record for neural networks with comparable model sizes (e.g., ViT-B) among MIM methods. Besides, its transferring performances on the other 6 datasets show MixMIM has better FLOPs / performance tradeoff than previous MIM methods. Code is available at https://github.com/Sense-X/MixMIM.
Super-resolution image display using diffractive decoders
Jun 15, 2022
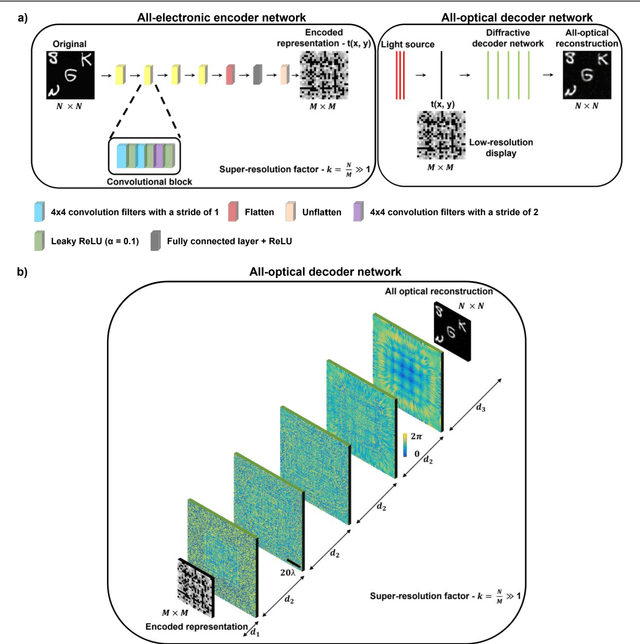
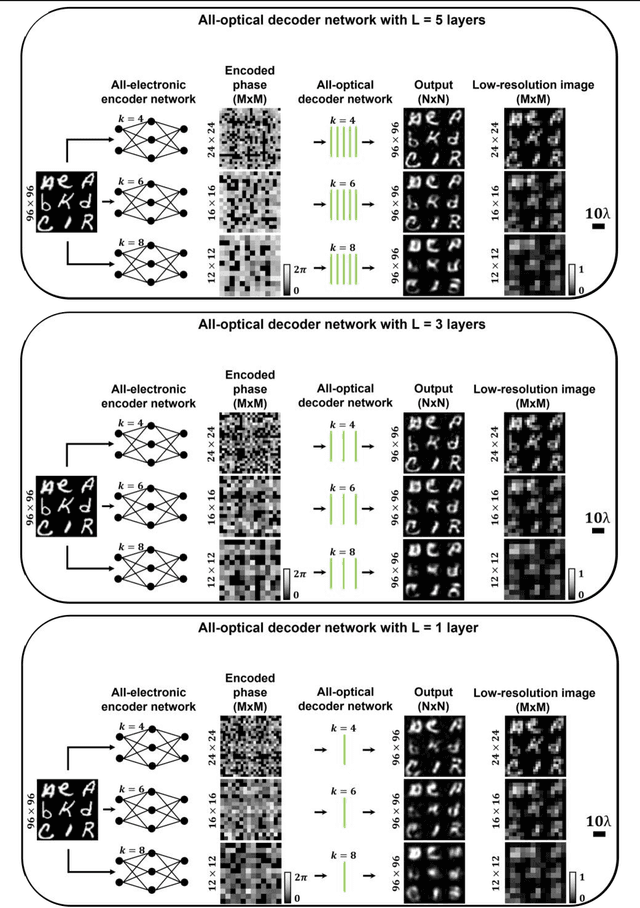
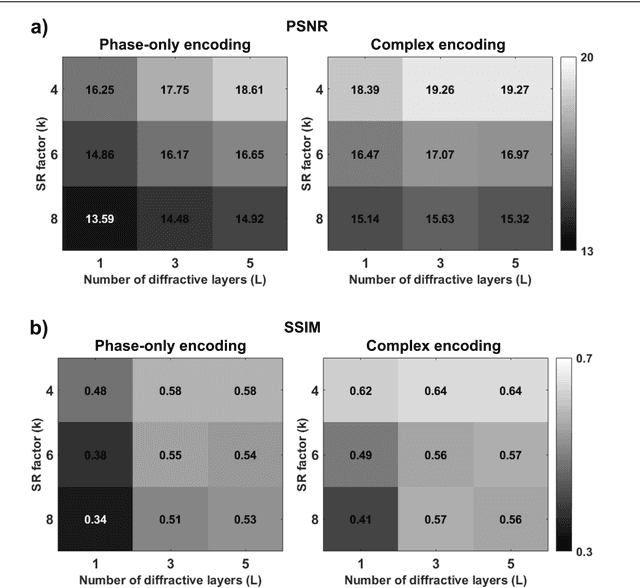
High-resolution synthesis/projection of images over a large field-of-view (FOV) is hindered by the restricted space-bandwidth-product (SBP) of wavefront modulators. We report a deep learning-enabled diffractive display design that is based on a jointly-trained pair of an electronic encoder and a diffractive optical decoder to synthesize/project super-resolved images using low-resolution wavefront modulators. The digital encoder, composed of a trained convolutional neural network (CNN), rapidly pre-processes the high-resolution images of interest so that their spatial information is encoded into low-resolution (LR) modulation patterns, projected via a low SBP wavefront modulator. The diffractive decoder processes this LR encoded information using thin transmissive layers that are structured using deep learning to all-optically synthesize and project super-resolved images at its output FOV. Our results indicate that this diffractive image display can achieve a super-resolution factor of ~4, demonstrating a ~16-fold increase in SBP. We also experimentally validate the success of this diffractive super-resolution display using 3D-printed diffractive decoders that operate at the THz spectrum. This diffractive image decoder can be scaled to operate at visible wavelengths and inspire the design of large FOV and high-resolution displays that are compact, low-power, and computationally efficient.
Curvilinear Aperture Monopulse
Nov 30, 2022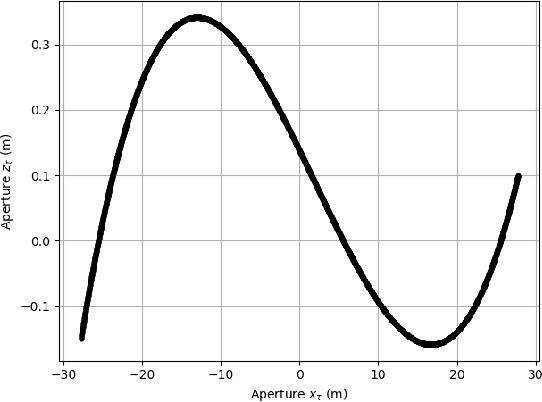
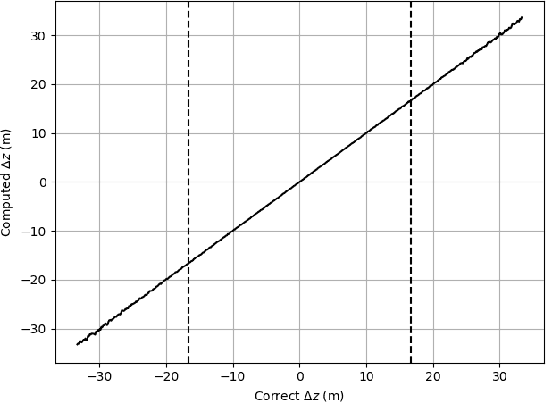
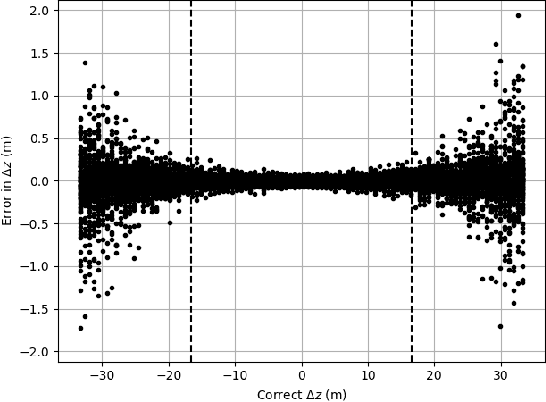
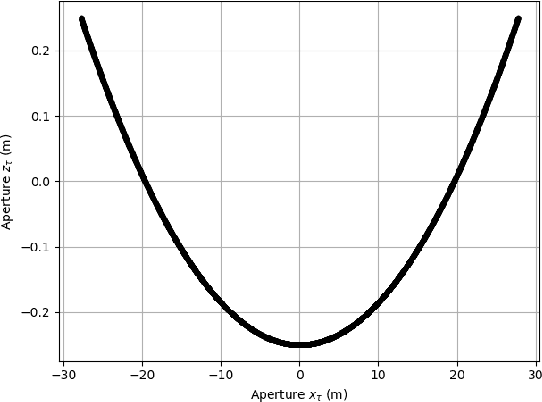
By a symmetry argument, a synethic aperture radar collection along a linear path does not collect three-dimensional information about the scene. However, it is known that vertical curvature can be used to derive some vertical position information. This paper approaches the problem from a monopulse perspective, resulting in a non-iterative computation that commutes with efficient image formation algorithms.